") 基于深度強化學(xué)習(xí)的視覺反饋機械臂抓取系統(tǒng)
基于深度強化學(xué)習(xí)的視覺反饋機械臂抓取系統(tǒng)
機械臂抓取擺放及堆疊物體是智能工廠流水線上常見的工序,可以有效的提升生產(chǎn)效率,本文針對機械臂的抓取擺放、抓取堆疊等常見任務(wù),結(jié)合深度強化學(xué)習(xí)及視覺反饋,采用AprilTag視覺標簽、后視經(jīng)驗回放機制
實現(xiàn)了稀疏獎勵下的機械臂的抓取任務(wù),并針對本文的抓取場景提出了結(jié)合深度確定性策略梯度及后視經(jīng)驗回放的分段學(xué)習(xí)的算法,相比于傳統(tǒng)控制算法,強化學(xué)習(xí)提高了抓取的準確度及穩(wěn)定性,在仿真與實際系統(tǒng)中驗證了效果。
一.仿真與物理環(huán)境搭建
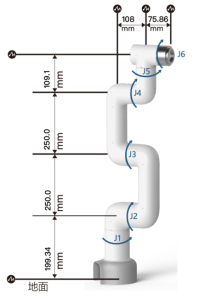
本文采用大象機器人的6自由度的串聯(lián)型機械手臂myCobot Pro-600,根據(jù)myCobot Pro-600的機械結(jié)構(gòu),采用標準D-H參數(shù)法建立機械臂連桿坐標系,如圖所示:
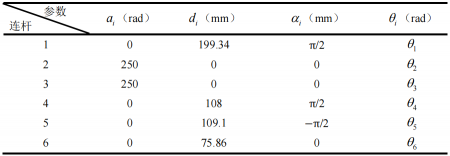
根據(jù)上圖建立的機械臂連桿坐標系,得到D-H參數(shù)表:
根據(jù)模型參數(shù),使用Pybullet搭建抓取擺放任務(wù)仿真環(huán)境如下:

在抓取擺放任務(wù)中,機械臂要實現(xiàn)的就是抓取紫色的物塊,并穩(wěn)定的放置在綠色的目標點處
仿真環(huán)境的狀態(tài)、目標、獎賞和動作的設(shè)置如下:
(1) 狀態(tài)(States):包括機械臂的末端位置、姿態(tài);待抓取物塊位置、姿態(tài)(紫色長方體);目標點位置。
注:仿真環(huán)境中為了減輕算力,沒有使用AprilTag進行姿態(tài)解算,實物中使用AprilTag來定位待抓取物塊位置。
(2) 目標(Goals)(綠色圓錐區(qū)域):目標描述了目標的期望位置,具有一定固定的容差,也就是在這個公式中,表示物體在狀態(tài)s時的位置。
(3) 獎賞(Rewards):獎賞是二進制值,即稀疏獎賞,通過其中是機械臂在狀態(tài)s下執(zhí)行動作a后的狀態(tài)。
(4) 動作(Actions):X(前后),Y(左右),(夾爪旋轉(zhuǎn))方向的運動速度。Z(高度)由時間步控制。
二.基于DDPG與HER的機械臂搬運任務(wù)分段學(xué)習(xí)算法
DeepMind在2016年提出深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法,是結(jié)合了深度學(xué)習(xí)和確定性策略梯度方法的一種算法
DDPG在具有連續(xù)動作空間的決策任務(wù)中已經(jīng)成功應(yīng)用,但是對于一些復(fù)雜的技能學(xué)習(xí)任務(wù),不能設(shè)計合適的獎勵函數(shù),所以不能得到較好的學(xué)習(xí)效果。
然而,將DDPG和HER結(jié)合,可以解決稀疏獎勵的不可學(xué)習(xí)問題。
HER只通過改變經(jīng)驗池中數(shù)據(jù)的狀態(tài)和獎勵,增大正向獎勵的密度,利用DDPG的主策略網(wǎng)絡(luò)采集完軌跡數(shù)據(jù),再將軌跡數(shù)據(jù)重組為經(jīng)驗形式的數(shù)據(jù),利用目標選擇策略修改其中的狀態(tài)和獎勵,最后將經(jīng)驗存放在經(jīng)驗池中。
在實際應(yīng)用中,為了減少內(nèi)存需求,則HER的實施方式也不同,經(jīng)驗池中一般存放的是軌跡,只有再采集小批量數(shù)據(jù)更新網(wǎng)絡(luò)或者歸一化器時才使用目標選擇策略。
在抓取任務(wù)中,開始時DDPG算法在動作空間隨機采樣運動,由于獎勵的稀疏,在多次探索后可能仍然無法獲得獎勵,而HER加入后,在已經(jīng)探索的軌跡中加入虛擬獎勵,刺激價值函數(shù)的增長,以加速強化學(xué)習(xí)的學(xué)習(xí)速率。
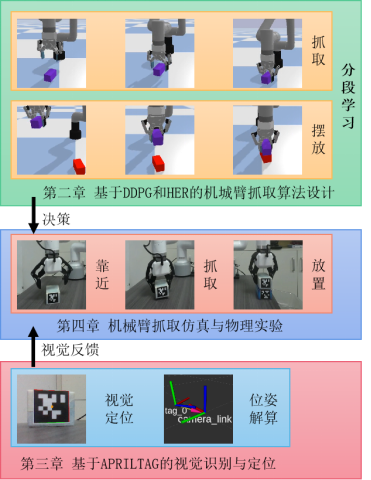
針對抓取任務(wù),本文采用分段學(xué)習(xí)的技巧,第一階段為接近物塊階段,第二階段為物塊搬運階段,有效的消除了傳統(tǒng)HER算法對不需要獎勵的步數(shù)的替換,從而加速了學(xué)習(xí)過程。
結(jié)合HER的DDPG算法的偽代碼如圖所示:

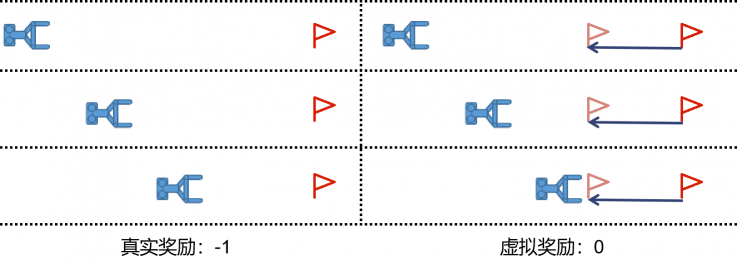
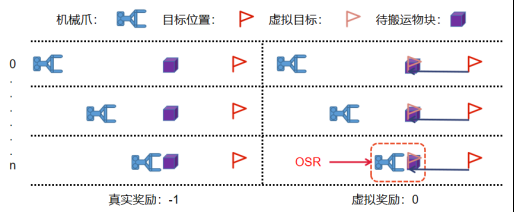
由于抓取擺放任務(wù)的獎勵稀疏性與任務(wù)的層次性,使用傳統(tǒng)的DDPG+HER算法會引起重疊虛假獎勵(OSR)問題
如下圖所示,具體來說當(dāng)HER算法將目標位置虛擬到與物塊位置相同給與虛擬獎勵時,會引起強化學(xué)習(xí)抓取而不搬運的錯誤學(xué)習(xí),這會嚴重影響學(xué)習(xí)過程的穩(wěn)定性,導(dǎo)致價值網(wǎng)絡(luò)不穩(wěn)定甚至無法收斂。
為了解決此問題,本文提出了針對抓取擺放等分層任務(wù)的分段學(xué)習(xí)算法。
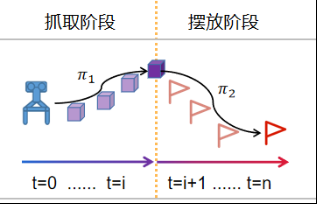
分段學(xué)習(xí)是指通過將問題分解成多個子問題,并針對每個子問題獨立地解決,從而提高了算法的效率和魯棒性。分段學(xué)習(xí)是將原問題分解成若干個子問題,每個子問題對應(yīng)一個狀態(tài)空間和一個動作空間。
然后,針對每個子問題,使用強化學(xué)習(xí)算法進行學(xué)習(xí)和探索,以得到最優(yōu)的策略。
最后,將所有子問題的策略組合起來,得到解決原問題的最優(yōu)策略。分段學(xué)習(xí)算法的優(yōu)點在于,它可以針對復(fù)雜的大規(guī)模問題進行分解,從而使得每個子問題的狀態(tài)空間和動作空間更小,更易于學(xué)習(xí)和探索。
此外,由于子問題之間是獨立的,因此分段學(xué)習(xí)算法具有很好的可擴展性和可并行性。
針對抓取擺放任務(wù),利用分段學(xué)習(xí)將任務(wù)分為抓取階段與擺放階段,下圖為抓取擺放任務(wù)分段學(xué)習(xí)過程示意圖,抓取階段與擺放階段各自采用DDPG+HER進行訓(xùn)練,抓取階段以抓取到物塊作為獎勵
擺放階段以正確擺放作為獎勵,最終得到抓取決策1與擺放決策2,使用機械爪是否抓取到物塊作為策略的切換標志,最終完成了機械臂靠近物塊(決策1),機械爪夾取物塊,機械臂擺放物塊(決策2)的任務(wù)。
三.基于AprilTag的視覺識別與定位
AprilTag是一個基準視覺庫,通過在物體上粘貼Apriltag標簽,利用識別算法,確定標簽坐標系和攝像頭坐標系的關(guān)系,即可得到物體的位姿,在增強實現(xiàn)、機器人和相機校準等領(lǐng)域廣泛使用。
AprilTag視覺標簽與二維碼有相似之處,但是降低了視覺標簽的復(fù)雜度,抗光和抗遮擋性能比較好,能夠快速的檢測視覺標簽信息,并計算相機與標識碼之間的相對位置。
AprilTag的特點是高速、高精度、高穩(wěn)定性。它的高速性表現(xiàn)在在實時應(yīng)用中,AprilTag可以快速地識別目標,并輸出其位姿信息,響應(yīng)速度可以達到幾十毫秒。
常用的AprilTag視覺標簽有以下幾個族:Tag16h5、Tag25h9和Tag36h11,如下所示。
從圖中,我們可以看到Tag16h5族的數(shù)量相對比較少,當(dāng)處于光照較強的環(huán)境中或者被遮擋時容易被誤識別,但在遠距離定位中有較高的精度。
Tag36h11與Tag16h5對比,其族數(shù)量較多,應(yīng)用在復(fù)雜環(huán)境時魯棒性較強,但是在遠距離定位中精度較低。

這里通過AprilTagROS庫來進行定位與目標姿態(tài)解算
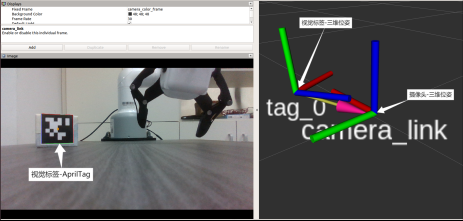
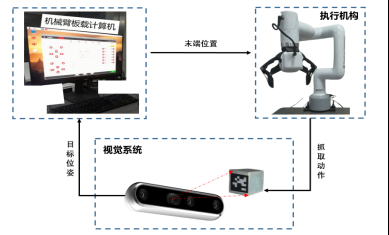
通過深度相機經(jīng)過目標物塊Tag的檢測與世界坐標系下的映射,可以得出待抓取物塊的位置坐標和姿態(tài)信息,此時將該目標位姿作為所提決策算法的輸入
經(jīng)過機械臂板載計算機的計算輸出各關(guān)節(jié)動作,該動作經(jīng)過機械臂逆運動學(xué)的解算映射成機械臂末端位置到達目標物塊位置實現(xiàn)一次的抓取動作
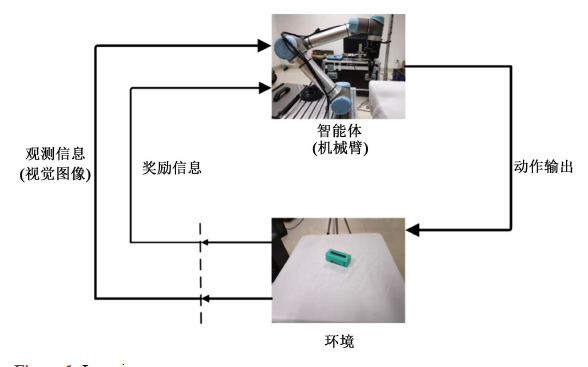
在運行該決策流程時,目標位置可隨時變化,深度相機再次解算目標物塊變化之后的位姿并輸入給決策算法,如此循環(huán),直到終止程序。視覺反饋系統(tǒng)工作流程圖如下所示。
四.機械臂抓取仿真與物理實驗
仿真實驗
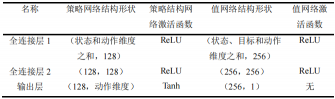
在仿真中采用結(jié)合HER的DDPG算法,其網(wǎng)絡(luò)設(shè)計如下。DDPG有策略網(wǎng)絡(luò)和值網(wǎng)絡(luò)兩種。
策略網(wǎng)絡(luò)是以輸入作為狀態(tài),輸出作為動作;而值網(wǎng)絡(luò)的輸入是狀態(tài)-動作對,輸出的是一維的Q值,在引入HER后,狀態(tài)則變?yōu)榱藸顟B(tài)-目標對。
在此次實驗中,所用到的狀態(tài)信息主要是機械臂和目標物等的狀態(tài)信息,所以網(wǎng)絡(luò)結(jié)構(gòu)只包含全連接層,策略網(wǎng)絡(luò)的輸出層的激活函數(shù)選擇雙曲正切函數(shù)
則動作值的映射區(qū)間為-1到1,其余的各層激活函數(shù)用修正線性單元(Recitified Linear Unit,ReLU)。策略網(wǎng)絡(luò)和值網(wǎng)絡(luò)的結(jié)構(gòu)如表所示。
在學(xué)習(xí)和策略更新中使用的學(xué)習(xí)率為0.001。使用Adam優(yōu)化器訓(xùn)練網(wǎng)絡(luò),學(xué)習(xí)率為2.5e-4,訓(xùn)練批次大小是256。后視經(jīng)驗的回放策略為未來策略(future)。
使用百度飛槳(PaddlePaddle)深度學(xué)習(xí)框架進行訓(xùn)練,在16GB內(nèi)存,8核心i7-7700處理器,Tesla V100顯卡的Linux的系統(tǒng)下進行訓(xùn)練,訓(xùn)練輪數(shù)為2000,單個算法的運行時間10小時,仿真訓(xùn)練效果如圖所示,截取訓(xùn)練次數(shù)在第200、440、680和840次的效果。
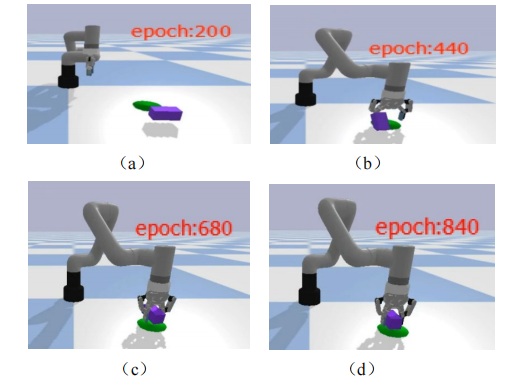
從圖的仿真結(jié)果可以看到,在訓(xùn)練200、440次的時候,機械臂能夠成功抓取b并放置在目標點的成功率并不高,隨著訓(xùn)練次數(shù)的增加,對于隨機的物塊放置位置,機械臂成功抓取并放置的概率越來越大。
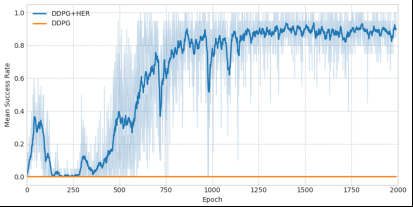
(1) 深度確定性策略梯度算法在抓取擺放任務(wù)環(huán)境中并不收斂,成功率一直為0。說明在沒有后視經(jīng)驗回放(HER)的機制下算法很難探索到目標區(qū)域,經(jīng)驗池中有限的目標點不足以支持算法的計算收斂。
(2) 在兩個算法中DDPG+HER相比于DDPG收斂速度更快,成功率更高,說明本文提出針對機械臂抓取任務(wù)分段學(xué)習(xí)的后視回放機制算法相比于傳統(tǒng)的強化學(xué)習(xí)算法性能有了較大提升。
物理實驗
為了將仿真訓(xùn)練的網(wǎng)絡(luò)能夠用于實際機械臂系統(tǒng),本文搭建了和仿真中較為一致的抓取實驗平臺。采用的是大象機器人的myCobot Pro600協(xié)作機械臂,其采用樹莓派微處理器,內(nèi)嵌robotFlow可視化編程軟件,操作簡單。
上位機采用的是ThinkPad T490筆記本電腦。在硬件方面,采用D435i的RGBD相機作為手眼相機,D435i結(jié)合了寬視場和全局快門傳感器,在機器人導(dǎo)航和物體識別等領(lǐng)域廣泛應(yīng)用。
在軟件方面,在Windows10系統(tǒng)中使用Python3.6、paddlepaddle2.3.0版本搭建神經(jīng)網(wǎng)絡(luò),與訓(xùn)練時配置一致,則可以直接載入訓(xùn)練好的模型參數(shù)運行控制程序。

在機械臂的抓取放置實驗中,抓取物為一個長方體的物塊,在該物塊上粘貼AprilTag碼,實驗?zāi)繕耸菍⒃撐飰K放置到目標位置的盒子中:

機械臂抓取堆疊的任務(wù)是將兩個相同的物塊堆疊放置,即將白色的物塊安全的放置在藍色物塊上,在白色和藍色物塊上貼有不同的AprilTag碼,實現(xiàn)過程如圖所示:

通過物理實驗驗證了強化學(xué)習(xí)算法的有效性,在實物上實現(xiàn)了與仿真相同的效果,能夠?qū)崿F(xiàn)將物塊穩(wěn)定的堆疊放置在另一個物塊上,具體實驗效果視頻請查看。

審核編輯:湯梓紅
-
機器人
+關(guān)注
關(guān)注
211文章
28380瀏覽量
206916 -
機械臂
+關(guān)注
關(guān)注
12文章
513瀏覽量
24554 -
智能工廠
+關(guān)注
關(guān)注
3文章
997瀏覽量
42407 -
深度強化學(xué)習(xí)
+關(guān)注
關(guān)注
0文章
14瀏覽量
2300
原文標題:基于深度強化學(xué)習(xí)的視覺反饋機械臂抓取系統(tǒng)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
使用Isaac Gym 來強化學(xué)習(xí)mycobot 抓取任務(wù)

什么是深度強化學(xué)習(xí)?深度強化學(xué)習(xí)算法應(yīng)用分析

什么是相機標定?視覺機械臂自主抓取全流程
【瑞芯微RK1808計算棒試用申請】基于機器學(xué)習(xí)的視覺機械臂研究與設(shè)計
深度強化學(xué)習(xí)實戰(zhàn)
將深度學(xué)習(xí)和強化學(xué)習(xí)相結(jié)合的深度強化學(xué)習(xí)DRL
薩頓科普了強化學(xué)習(xí)、深度強化學(xué)習(xí),并談到了這項技術(shù)的潛力和發(fā)展方向
深度強化學(xué)習(xí)將如何控制機械臂的靈活動作
如何使用深度強化學(xué)習(xí)進行機械臂視覺抓取控制的優(yōu)化方法概述
83篇文獻、萬字總結(jié)強化學(xué)習(xí)之路
基于深度強化學(xué)習(xí)仿真集成的壓邊力控制模型
《自動化學(xué)報》—多Agent深度強化學(xué)習(xí)綜述

ESP32上的深度強化學(xué)習(xí)

模擬矩陣在深度強化學(xué)習(xí)智能控制系統(tǒng)中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論