

Stable Diffusion (SD)是當(dāng)前最熱門的文本到圖像(text to image)生成擴(kuò)散模型。盡管其強(qiáng)大的圖像生成能力令人震撼,一個明顯的不足是需要的計算資源巨大,推理速度很慢:以 SD-v1.5 為例,即使用半精度存儲,其模型大小也有 1.7GB,近 10 億參數(shù),端上推理時間往往要接近 2min。
為了解決推理速度問題,學(xué)術(shù)界與業(yè)界已經(jīng)開始對 SD 加速的研究,主要集中于兩條路線:(1)減少推理步數(shù),這條路線又可以分為兩條子路線,一是通過提出更好的 noise scheduler 來減少步數(shù),代表作是 DDIM [1],PNDM [2],DPM [3] 等;二是通過漸進(jìn)式蒸餾(Progressive Distillation)來減少步數(shù),代表作是 Progressive Distillation [4] 和 w-conditioning [5] 等。(2)工程技巧優(yōu)化,代表作是 Qualcomm 通過 int8 量化 + 全棧式優(yōu)化實現(xiàn) SD-v1.5 在安卓手機(jī)上 15s 出圖 [6],Google 通過端上 GPU 優(yōu)化將 SD-v1.4 在三星手機(jī)上加速到 12s [7]。
盡管這些工作取得了長足的進(jìn)步,但仍然不夠快。
近日,Snap 研究院推出最新高性能 Stable Diffusion 模型,通過對網(wǎng)絡(luò)結(jié)構(gòu)、訓(xùn)練流程、損失函數(shù)全方位進(jìn)行優(yōu)化,在 iPhone 14 Pro 上實現(xiàn) 2 秒出圖(512x512),且比 SD-v1.5 取得更好的 CLIP score。這是目前已知最快的端上 Stable Diffusion 模型!

論文地址:https://arxiv.org/pdf/2306.00980.pdf
Webpage: https://snap-research.github.io/SnapFusion
核心方法
Stable Diffusion 模型分為三部分:VAE encoder/decoder, text encoder, UNet,其中 UNet 無論是參數(shù)量還是計算量,都占絕對的大頭,因此 SnapFusion 主要是對 UNet 進(jìn)行優(yōu)化。具體分為兩部分:(1)UNet 結(jié)構(gòu)上的優(yōu)化:通過分析原有 UNet 的速度瓶頸,本文提出一套 UNet 結(jié)構(gòu)自動評估、進(jìn)化流程,得到了更為高效的 UNet 結(jié)構(gòu)(稱為 Efficient UNet)。(2)推理步數(shù)上的優(yōu)化:眾所周知,擴(kuò)散模型在推理時是一個迭代的去噪過程,迭代的步數(shù)越多,生成圖片的質(zhì)量越高,但時間代價也隨著迭代步數(shù)線性增加。為了減少步數(shù)并維持圖片質(zhì)量,我們提出一種 CFG-aware 蒸餾損失函數(shù),在訓(xùn)練過程中顯式考慮 CFG (Classifier-Free Guidance)的作用,這一損失函數(shù)被證明是提升 CLIP score 的關(guān)鍵!
下表是 SD-v1.5 與 SnapFusion 模型的概況對比,可見速度提升來源于 UNet 和 VAE decoder 兩個部分,UNet 部分是大頭。UNet 部分的改進(jìn)有兩方面,一是單次 latency 下降(1700ms -> 230ms,7.4x 加速),這是通過提出的 Efficient UNet 結(jié)構(gòu)得到的;二是 Inference steps 降低(50 -> 8,6.25x 加速),這是通過提出的 CFG-aware Distillation 得到的。VAE decoder 的加速是通過結(jié)構(gòu)化剪枝實現(xiàn)。

下面著重介紹 Efficient UNet 的設(shè)計和 CFG-aware Distillation 損失函數(shù)的設(shè)計。
(1)Efficient UNet
我們通過分析 UNet 中的 Cross-Attention 和 ResNet 模塊,定位速度瓶頸在于 Cross-Attention 模塊(尤其是第一個 Downsample 階段的 Cross-Attention),如下圖所示。這個問題的根源是因為 attention 模塊的復(fù)雜度跟特征圖的 spatial size 成平方關(guān)系,在第一個 Downsample 階段,特征圖的 spatial size 仍然較大,導(dǎo)致計算復(fù)雜度高。
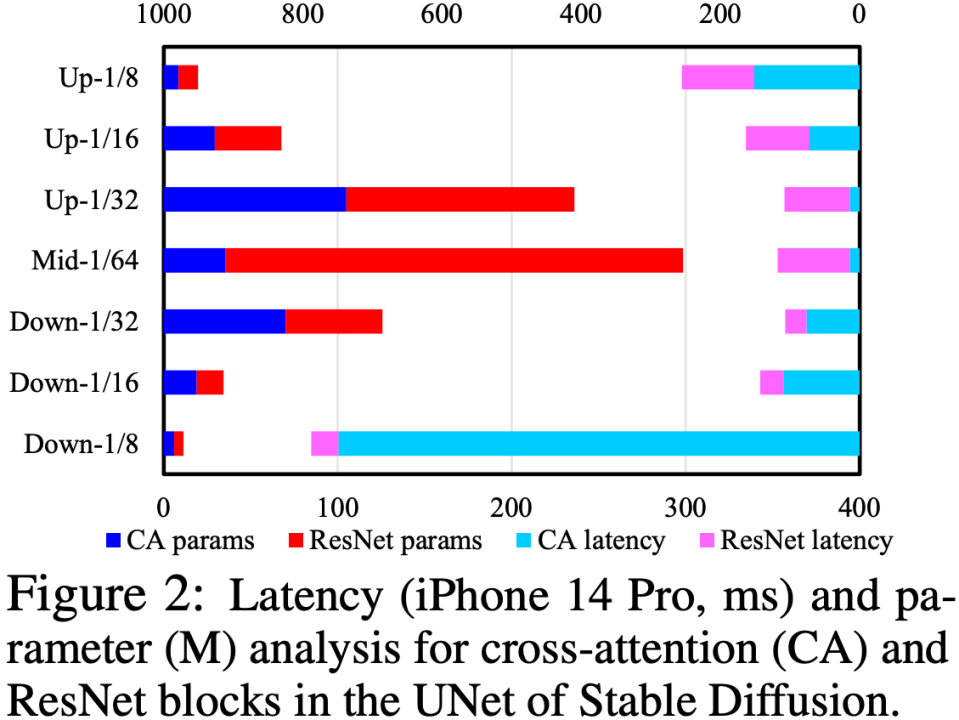
為了優(yōu)化 UNet 結(jié)構(gòu),我們提出一套 UNet 結(jié)構(gòu)自動評估、進(jìn)化流程:先對 UNet 進(jìn)行魯棒性訓(xùn)練(Robust Training),在訓(xùn)練中隨機(jī) drop 一些模塊,以此來測試出每個模塊對性能的真實影響,從而構(gòu)建一個 “對 CLIP score 的影響 vs. latency” 的查找表;然后根據(jù)該查找表,優(yōu)先去除對 CLIP score 影響不大同時又很耗時的模塊。這一套流程是在線自動進(jìn)行,完成之后,我們就得到了一個全新的 UNet 結(jié)構(gòu),稱為 Efficient UNet。相比原版 UNet,實現(xiàn) 7.4x 加速且性能不降。
(2)CFG-aware Step Distillation
CFG(Classifier-Free Guidance)是 SD 推理階段的必備技巧,可以大幅提升圖片質(zhì)量,非常關(guān)鍵!盡管已有工作對擴(kuò)散模型進(jìn)行步數(shù)蒸餾(Step Distillation)來加速 [4],但是它們沒有在蒸餾訓(xùn)練中把 CFG 納入優(yōu)化目標(biāo),也就是說,蒸餾損失函數(shù)并不知道后面會用到 CFG。這一點根據(jù)我們的觀察,在步數(shù)少的時候會嚴(yán)重影響 CLIP score。
為了解決這個問題,我們提出在計算蒸餾損失函數(shù)之前,先讓 teacher 和 student 模型都進(jìn)行 CFG,這樣損失函數(shù)是在經(jīng)過 CFG 之后的特征上計算,從而顯式地考慮了不同 CFG scale 的影響。實驗中我們發(fā)現(xiàn),完全使用 CFG-aware Distillation 盡管可以提高 CLIP score, 但 FID 也明顯變差。我們進(jìn)而提出了一個隨機(jī)采樣方案來混合原來的 Step Distillation 損失函數(shù)和 CFG-aware Distillation 損失函數(shù),實現(xiàn)了二者的優(yōu)勢共存,既顯著提高了 CLIP score,同時 FID 也沒有變差。這一步驟,實現(xiàn)進(jìn)一步推理階段加速 6.25 倍,實現(xiàn)總加速約 46 倍。
除了以上兩個主要貢獻(xiàn),文中還有對 VAE decoder 的剪枝加速以及蒸餾流程上的精心設(shè)計,具體內(nèi)容請參考論文。
實驗結(jié)果
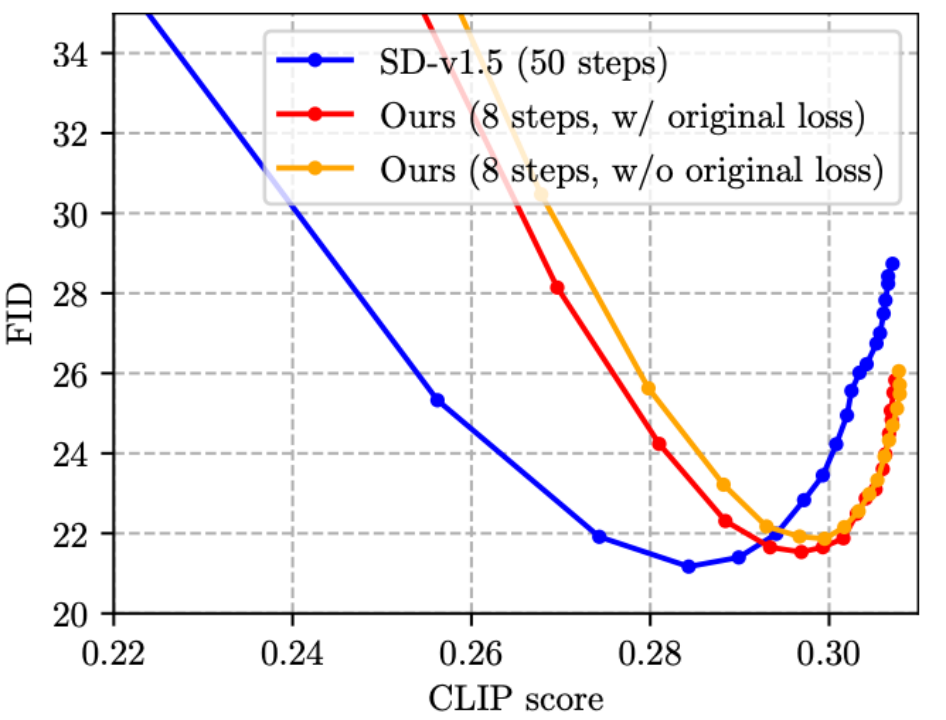
SnapFusion 對標(biāo) SD-v1.5 text to image 功能,目標(biāo)是實現(xiàn)推理時間大幅縮減并維持圖像質(zhì)量不降,最能說明這一點的是下圖:
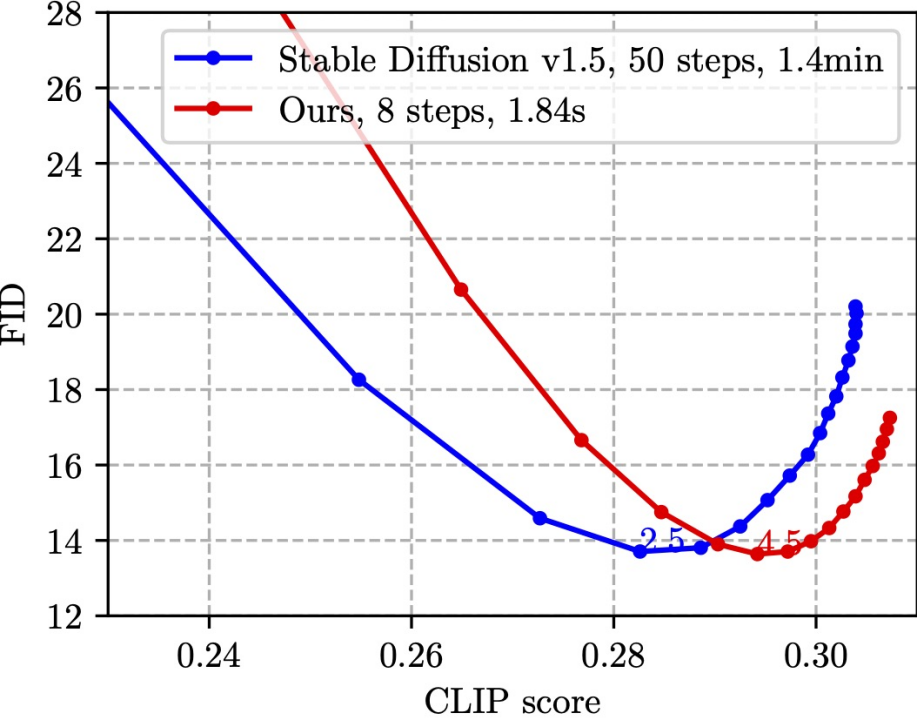
該圖是在 MS COCO’14 驗證集上隨機(jī)選取 30K caption-image pairs 測算 CLIP score 和 FID。CLIP score 衡量圖片與文本的語義吻合程度,越大越好;FID 衡量生成圖片與真實圖片之間的分布距離(一般被認(rèn)為是生成圖片多樣性的度量),越小越好。圖中不同的點是使用不同的 CFG scale 獲得,每一個 CFG scale 對應(yīng)一個數(shù)據(jù)點。從圖中可見,我們的方法(紅線)可以達(dá)到跟 SD-v1.5(藍(lán)線)同樣的最低 FID,同時,我們方法的 CLIP score 更好。值得注意的是,SD-v1.5 需要 1.4min 生成一張圖片,而 SnapFusion 僅需要 1.84s,這也是目前我們已知最快的移動端 Stable Diffusion 模型!
下面是一些 SnapFusion 生成的樣本:

更多樣本請參考文章附錄。
除了這些主要結(jié)果,文中也展示了眾多燒蝕分析(Ablation Study)實驗,希望能為高效 SD 模型的研發(fā)提供參考經(jīng)驗:
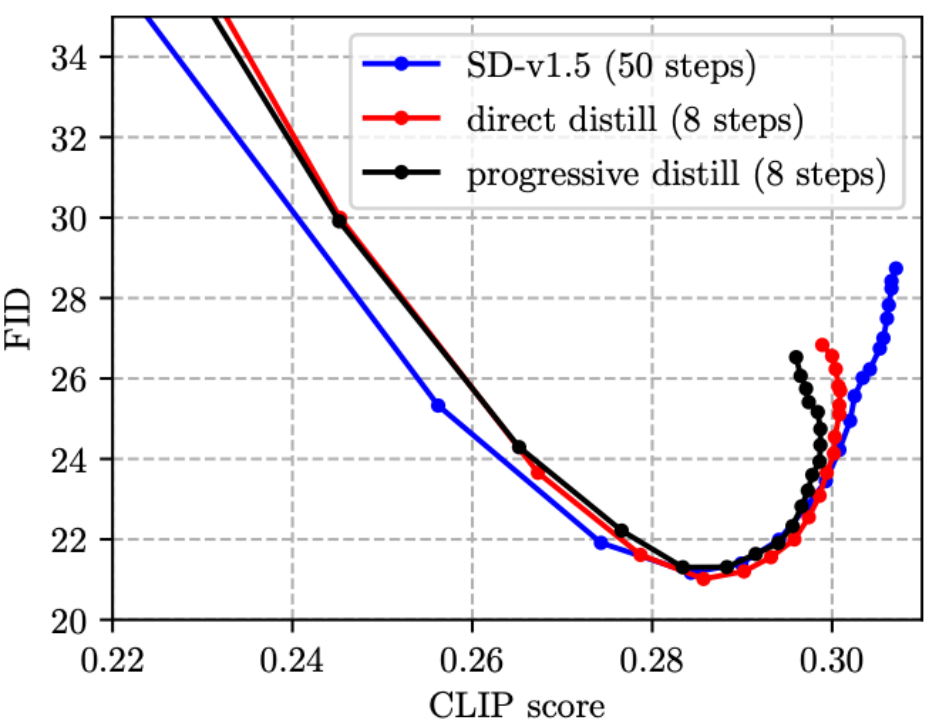
(1)之前 Step Distillation 的工作通常采用漸進(jìn)式方案 [4, 5],但我們發(fā)現(xiàn),在 SD 模型上漸進(jìn)式蒸餾并沒有比直接蒸餾更有優(yōu)勢,且過程繁瑣,因此我們在文中采用的是直接蒸餾方案。
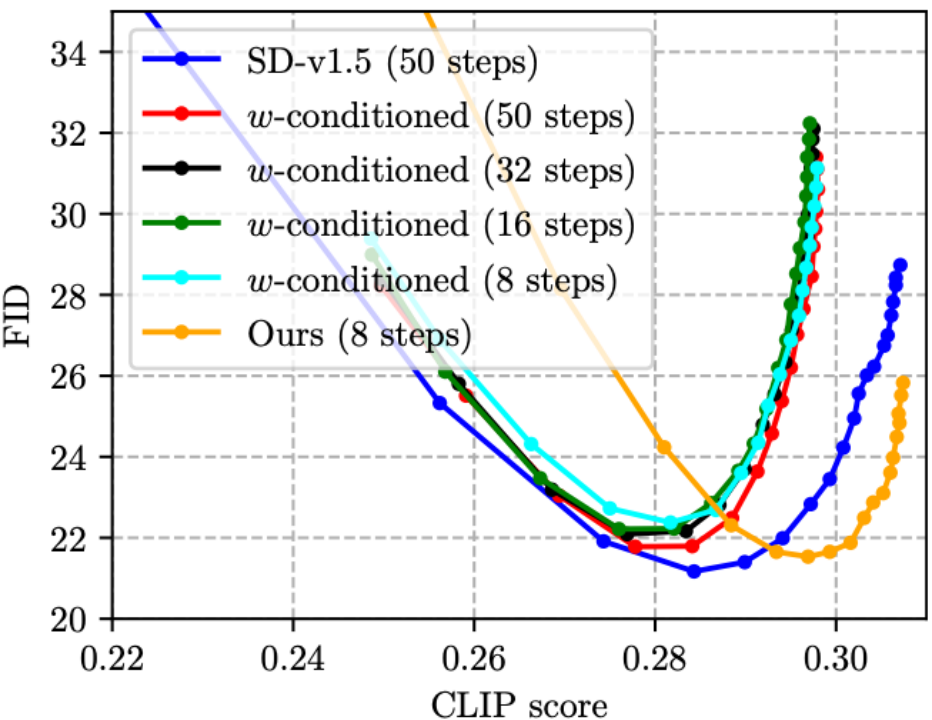
(2)CFG 雖然可以大幅提升圖像質(zhì)量,但代價是推理成本翻倍。今年 CVPR’23 Award Candidate 的 On Distillation 一文 [5] 提出 w-conditioning,將 CFG 參數(shù)作為 UNet 的輸入進(jìn)行蒸餾(得到的模型叫做 w-conditioned UNet),從而在推理時省卻 CFG 這一步,實現(xiàn)推理成本減半。但是我們發(fā)現(xiàn),這樣做其實會造成圖片質(zhì)量下降,CLIP score 降低(如下圖中,四條 w-conditioned 線 CLIP score 均未超過 0.30, 劣于 SD-v1.5)。而我們的方法則可以減少步數(shù),同時將 CLIP score 提高,得益于所提出的 CFG-aware 蒸餾損失函數(shù)!尤其值得主要的是,下圖中綠線(w-conditioned, 16 steps)與橙線(Ours,8 steps)的推理代價是一樣的,但明顯橙線更優(yōu),說明我們的技術(shù)路線比 w-conditioning [5] 在蒸餾 CFG guided SD 模型上更為有效。
(3)既有 Step Distillation 的工作 [4, 5] 沒有將原有的損失函數(shù)和蒸餾損失函數(shù)加在一起,熟悉圖像分類知識蒸餾的朋友應(yīng)該知道,這種設(shè)計直覺上來說是欠優(yōu)的。于是我們提出把原有的損失函數(shù)加入到訓(xùn)練中,如下圖所示,確實有效(小幅降低 FID)。
總結(jié)與未來工作
本文提出 SnapFusion,一種移動端高性能 Stable Diffusion 模型。SnapFusion 有兩點核心貢獻(xiàn):(1)通過對現(xiàn)有 UNet 的逐層分析,定位速度瓶頸,提出一種新的高效 UNet 結(jié)構(gòu)(Efficient UNet),可以等效替換原 Stable Diffusion 中的 UNet,實現(xiàn) 7.4x 加速;(2)對推理階段的迭代步數(shù)進(jìn)行優(yōu)化,提出一種全新的步數(shù)蒸餾方案(CFG-aware Step Distillation),減少步數(shù)的同時可顯著提升 CLIP score,實現(xiàn) 6.25x 加速。總體來說,SnapFusion 在 iPhone 14 Pro 上實現(xiàn) 2 秒內(nèi)出圖,這是目前已知最快的移動端 Stable Diffusion 模型。
未來工作:
1.SD 模型在多種圖像生成場景中都可以使用,本文囿于時間,目前只關(guān)注了 text to image 這個核心任務(wù),后期將跟進(jìn)其他任務(wù)(如 inpainting,ControlNet 等等)。
2. 本文主要關(guān)注速度上的提升,并未對模型存儲進(jìn)行優(yōu)化。我們相信所提出的 Efficient UNet 仍然具備壓縮的空間,結(jié)合其他的高性能優(yōu)化方法(如剪枝,量化),有望縮小存儲,并將時間降低到 1 秒以內(nèi),離端上實時 SD 更進(jìn)一步。
-
iPhone
+關(guān)注
關(guān)注
28文章
13498瀏覽量
204541 -
模型
+關(guān)注
關(guān)注
1文章
3471瀏覽量
49874 -
網(wǎng)絡(luò)結(jié)構(gòu)
+關(guān)注
關(guān)注
0文章
48瀏覽量
11443
原文標(biāo)題:iPhone兩秒出圖,目前已知的最快移動端Stable Diffusion模型來了
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Stable Diffusion的完整指南:核心基礎(chǔ)知識、制作AI數(shù)字人視頻和本地部署要求
uCOS-II中斷延遲小于兩秒
Stability AI開源圖像生成模型Stable Diffusion
大腦視覺信號被Stable Diffusion復(fù)現(xiàn)圖像!“人類的謀略和謊言不存在了”
大腦視覺信號被Stable Diffusion復(fù)現(xiàn)圖像!
一文讀懂Stable Diffusion教程,搭載高性能PC集群,實現(xiàn)生成式AI應(yīng)用

使用OpenVINO?在算力魔方上加速stable diffusion模型
優(yōu)化 Stable Diffusion 在 GKE 上的啟動體驗
基于一種移動端高性能 Stable Diffusion 模型

美格智能高算力AI模組成功運行Stable Diffusion大模型
使用OpenVINO在Stable Diffusion V2.1上實現(xiàn)AI硬件加速的方法
樹莓派能跑Stable Diffusion了?
Stable Diffusion的完整指南:核心基礎(chǔ)知識、制作AI數(shù)字人視頻和本地部署要求
Stability AI試圖通過新的圖像生成人工智能模型保持領(lǐng)先地位







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論