") 圖靈獎得主楊立昆:GPT模式五年就不會有人用了,世界模型才是AGI未來
圖靈獎得主楊立昆:GPT模式五年就不會有人用了,世界模型才是AGI未來
2023年6月9日的北京智源大會上開幕式上,機器學習三巨頭之一楊立昆(Yann Lecun)進行了遠程致辭,發(fā)表了名為《朝向能學習, 思考和計劃的機器進發(fā)》( Towards Machines that can Learn, Reason, and Plan)的演講。

作為一個從ChatGPT誕生之日起就對它嘲諷連連,認為它沒有什么新意。在今天的講座中,身處凌晨4點巴黎的楊立昆依然斗志滿溢,在演講中拿出了他反擊GPT的邏輯:自回歸模型根本不行,因為它們沒有規(guī)劃,推理的能力。單純根據(jù)概率生成自回歸的大語言模型從本質(zhì)上根本解決不了幻覺,錯誤的問題。在輸入文本增大的時候,錯誤的幾率也會成指數(shù)增加。
目前流行的AutoGPT,LOT之類看起來可以拆解任務,分步解釋復雜問題的語言拓展模型讓大語言模型看起來又了規(guī)劃能力。對此楊立昆也反唇相譏,認為那不過是它們在借助搜索和其他工具來讓自己看起來可以做到規(guī)劃和推理而已,完全不是靠自身對世界的理解。
性能驚人,但使用范圍狹窄。完全不如人類智能,而且存在著無法解決的Bug。這就是楊立昆對當前人工智能的判斷。
那想要通向AGI,人工智能的下一步在哪里呢?
楊立昆給出的答案是世界模型。一個不光是在神經(jīng)水平上模仿人腦的模型,而是在認知模塊上也完全貼合人腦分區(qū)的世界模型。它與大語言模型最大的差別在于可以有規(guī)劃和預測能力(世界模型),成本核算能力(成本模塊)。
通過世界模型,它可以真正的理解這個世界,并預測和規(guī)劃未來。通過成本核算模塊,結(jié)合一個簡單的需求(一定按照最節(jié)約行動成本的邏輯去規(guī)劃未來),它就可以杜絕一切潛在的毒害和不可靠性。
但這個未來如何實現(xiàn)?世界模型如何學習?楊立昆只給了一些規(guī)劃性的想法,比如還是采用自監(jiān)督模型去訓練,比如一定要建立多層級的思維模式。他也承認之前并沒有深度學習的訓練做到了這些,也沒人知道怎么做。
來自清華大學的朱軍教授看著這個模型估計是有點發(fā)懵,這個架構(gòu)太像傳統(tǒng)人工智能的那種符號學派的理想模型了。在問答環(huán)節(jié)還問了一句有沒有考慮符號學派和深度學習結(jié)合的可能。
這歌曾經(jīng)挑戰(zhàn)明斯克符號主義統(tǒng)治十幾年,在無人認可之時仍堅持機器學習之路的楊立昆的回答很簡單:“符號邏輯不可微,兩個系統(tǒng)不兼容”。
以下為騰訊新聞編輯整理的楊立昆報告核心發(fā)言及與朱軍教授全部QA的實錄:
機器學習的缺陷
我要說的第一件事是:與人類和動物相比,機器學習不是特別好。幾十年來,我們一直在使用監(jiān)督式學習,這需要太多的標簽。強化學習效果不錯,但需要大量的訓練來學習任何東西。當然,近年來,我們一直在使用大量的自我監(jiān)督學習。但結(jié)果是,這些系統(tǒng)在某個地方不太專精,而且很脆弱,它們會犯愚蠢的錯誤,它們不會真正地推理,也不會計劃。當然它們的反應確實非常快。而當我們與動物和人類進行比較時,動物和人類可以極其迅速地做新的任務,并理解世界是如何運作的,可以推理和計劃,他們有某種程度的常識,而機器仍然沒有。而這是在人工智能的早期就發(fā)現(xiàn)的問題。
這部分是由于目前的機器學習系統(tǒng)在輸入和輸出之間基本上有恒定數(shù)量的計算步驟。這就是為什么它們真的不能像人類和一些動物那樣推理和計劃。那么,我們?nèi)绾巫寵C器理解世界是如何運作的,并像動物和人類那樣預測其行為的后果,可以進行無限步數(shù)的推理鏈,或者可以通過將其分解為子任務序列來計劃復雜的任務?
這就是我想問的問題。但在說這個問題之前,我先談一下自我監(jiān)督學習,以及在過去幾年里它確實已經(jīng)占領了機器學習的世界。這一點已經(jīng)被倡導了相當長的時間,有七八年了,而且真的發(fā)生了,我們今天看到的機器學習的很多結(jié)果和成功都是由于自監(jiān)督學習,特別是在自然語言處理和文本理解和生成方面。
那么,什么是自監(jiān)督學習?自監(jiān)督學習是捕獲輸入中的依賴關系的想法。因此,我們不是要把輸入映射到輸出。我們只是被提供了一個輸入。在最常見的范式中,我們蓋住一部分輸入,并將其提供給機器學習系統(tǒng),然后我們揭示輸入的其余部分,然后訓練系統(tǒng)來捕捉我們看到的部分和我們尚未看到的部分之間的依賴關系。有時是通過預測缺失的部分來完成,有時不完全是預測。
而這一點在幾分鐘內(nèi)就能解釋清楚。
這就是自我監(jiān)督學習的理念。它被稱為自我監(jiān)督,因為我們基本上使用監(jiān)督學習方法,但我們將它們應用于輸入本身,而不是與人類提供的單獨輸出相匹配。因此,我在這里展示的例子是一個視頻預測,你向一個系統(tǒng)展示一小段視頻,然后你訓練它來預測視頻中接下來會發(fā)生什么。但這不僅僅是預測未來。它可能是預測中間的那種數(shù)據(jù)。這種類型的方法在自然語言處理方面取得了驚人的成功,我們最近在大型語言模型中看到的所有成功都是這個想法的一個版本。
好的,所以我說,這種自我監(jiān)督的學習技術包括輸入一段文本,刪除該文本中的一些單詞,然后訓練一個非常大的神經(jīng)網(wǎng)絡來預測缺失的那個單詞。在這樣做的過程中,神經(jīng)網(wǎng)絡學會了一個良好的內(nèi)部表征,可用于隨后的一些監(jiān)督任務,如翻譯或文本分類或類似的東西。因此它已經(jīng)取得了令人難以置信的成功。同樣成功的是生成式人工智能系統(tǒng),用于生成圖像、視頻或文本。在文本的情況下,這些系統(tǒng)是自回歸的。們使用自我監(jiān)督學習的訓練方式不是預測隨機缺失的單詞,而是只預測最后一個單詞。因此,你拿出一個詞的序列,遮住最后一個詞,然后訓練系統(tǒng)預測最后一個詞。
它們不一定是詞,而是子詞單位。一旦系統(tǒng)在大量的數(shù)據(jù)上進行了訓練,你就可以使用所謂的自回歸預測,這包括預測下一個標記,然后將該標記轉(zhuǎn)移到輸入端,然后再預測下一個標記,然后將其轉(zhuǎn)移到輸入,然后重復這個過程。因此,這就是自回歸LLMs,這就是我們在過去幾個月或幾年中看到的流行模型所做的。其中一些來自我在Meta的同事,在FAIR、BlenderBot、Galactica和Lama,這是開源的。斯坦福大學的Alpaca,是在Lama基礎上的改進。Lambda,谷歌的Bard,DeepMind的Chinchilla,當然還有OpenAI的Chet、JVT和JVT4。如果你在類似一萬億文本或兩萬億文本上訓練它們,這些系統(tǒng)的性能是驚人的。
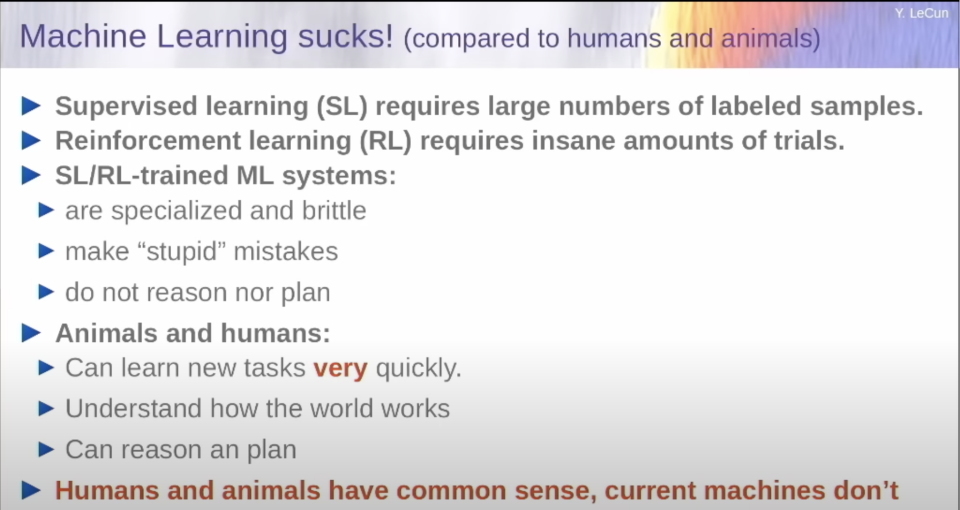
但最終,他們會犯非常愚蠢的錯誤。他們會犯事實錯誤、邏輯錯誤、不一致的問題。他們的推理能力有限,會使用毒化的內(nèi)容,他們對潛在的現(xiàn)實沒有知識,因為他們純粹是在文本上訓練的,這意味著人類知識的很大一部分是他們完全無法接觸到的。而且他們無法真正規(guī)劃他們的答案。關于這一點有很多研究。然而,這些系統(tǒng)對于寫作輔助工具以及生成代碼,幫助程序員編寫代碼,效果都驚人的好。
所以你可以要求他們用各種語言寫代碼,而且效果很好。它會給你一個很不錯的起點。你可以要求他們生成文本,他們同樣可以闡釋或說明故事,但這使得該系統(tǒng)作為信息檢索系統(tǒng)或作為搜索引擎或如果你只是想要事實性的信息,并不是那么好。因此,它們對于寫作幫助、初稿的生成、統(tǒng)計數(shù)字方面是很有幫助的,特別是如果你不是你所寫語言的母語者。考慮到最近發(fā)生的事兒,他們不適合制作事實性和一致性的答案,因此他們必須為此進行再訓練。而他們在訓練集中可能會有相關的內(nèi)容,這就保證了他們會有正確的行為。
然后還有一些問題,如推理、計劃、做算術和諸如此類的事情(他們都不擅長),為此他們會使用一些工具,如搜索引擎計算器數(shù)據(jù)庫查詢。因此,這是目前一個非常熱門的研究課題,即如何從本質(zhì)上讓這些系統(tǒng)調(diào)用工具(來完成他們不擅長的事情),這就是所謂的擴展語言模型。而我和我在FAIR的一些同事共同撰寫了一篇關于這個話題的評論文章,關于正在提出的各種擴展語言模型的技術:我們很容易被它們的流暢性所迷惑,以為它們很聰明,但它們其實并不那么聰明。他們在檢索記憶方面非常出色,大約是這樣。但同樣,他們對世界如何運作沒有任何了解。自回歸模型還有一種重大缺陷。如果我們想象所有可能的答案的集合:所以輸入詞組的序列,是一棵樹,在這里用一個圓圈表示。但它實際上是一棵包含所有可能的輸入序列的樹。在這棵巨大的樹中,有一個小的子樹,對應著對所給提示的正確答案。如果我們設想有一個平均概率e,即任何產(chǎn)生的標記都會把我們帶到正確答案的集合之外,而產(chǎn)生的錯誤是獨立的。那么xn的答案正確的概率是1-e的n次方。

這意味著有一個指數(shù)級發(fā)散的過程會把我們帶出正確答案的序列樹。而這是由于自回歸預測過程造成的。除了讓e盡可能的小之外,沒有辦法解決這個問題。因此,我們必須重新設計系統(tǒng),使其不會這樣做。而事實上,其他人已經(jīng)指出了其中一些系統(tǒng)的局限性。因此,我與我的同事吉格多-布朗寧共同寫了一篇論文,這實際上是一篇哲學論文,他是一位哲學家,這篇論文是關于只使用語言訓練人工智能系統(tǒng)的局限性。
事實上,這些系統(tǒng)沒有物理世界的經(jīng)驗,這使得它們(的能力)非常有限。有一些論文,或者是由認知科學家撰寫的,比如左邊這個來自麻省理工學院小組的論文,基本上說與我們在人類和動物身上觀察到的相比,系統(tǒng)擁有的智能是非常有限的。還有一些來自傳統(tǒng)人工智能的研究者的論文,他們沒有什么機器學習的背景。他們試圖分析這些機器學習系統(tǒng)的規(guī)劃能力,并基本上得出結(jié)論,這些系統(tǒng)不能真正規(guī)劃和推理,至少不是以人們在傳統(tǒng)人工智能所理解的那種方式搜索和規(guī)劃。那么,人類和動物是如何能夠如此迅速地學習的呢?我們看到的是,嬰兒在出生后的頭幾個月里學習了大量的關于世界如何運作的背景知識。他們學習非常基本的概念,如物體的永久性,世界是三維的這一事實,有生命和無生命物體之間的區(qū)別,穩(wěn)定性的概念,自然類別的學習。以及學習非常基本的東西,如重力,當一個物體沒有得到支撐,它就會掉下來。根據(jù)我的同事埃馬紐埃爾-杜普繪制的圖表,嬰兒大約在九個月大的時候就學會了這個。
因此,如果你給一個五個月大的嬰兒看,這里左下方的場景,一輛小車在平臺上,你把小車從平臺上推下來,它似乎漂浮在空中,五個月大的嬰兒不會感到驚訝。但是10個月大的嬰兒會非常驚訝,像底部的小女孩一樣看著這一幕,因為在此期間,他們已經(jīng)知道物體不應該停留在空中。他們應該在重力作用下墜落。因此,這些基本概念是在生命的頭幾個月學到的,我認為我們應該用機器來復制這種能力,通過觀察世界的發(fā)展或體驗世界來學習世界如何運作。那么,為什么任何青少年都可以在20個小時的練習中學會開車,而我們?nèi)匀恢辽僭跊]有大量的工程和地圖以及激光雷達和各種傳感器的情況下,不會有完全可靠的5級自動駕駛。所以很明顯,自回歸系統(tǒng)缺少一些很重要的東西。為什么我們有流暢的系統(tǒng),可以通過法律考試或醫(yī)學考試,但我們卻沒有可以清理餐桌和裝滿洗碗機的家用機器人,對嗎?這是任何10歲的孩子都可以在幾分鐘內(nèi)學會的事情,而我們?nèi)匀粵]有機器可以近似的做這些事。因此,我們顯然缺少一些極其重要的東西。在我們目前擁有的人工智能系統(tǒng)中,我們遠遠沒有達到人類水平的智能。
機器學習的未來挑戰(zhàn)
那么,我們要如何做到這一點呢?事實上,我已經(jīng)有點確定了未來幾年人工智能的三大挑戰(zhàn):
學習世界表征及預測的模型。最好是使用自我監(jiān)督學習。
學習推理:這與心理學的想法相對應,例如丹尼爾-卡漢曼的想法,即系統(tǒng)2與系統(tǒng)1。因此,系統(tǒng)1是對應于潛意識計算的人類行動或行為,是你不假思索做的事情。然后系統(tǒng)2是你有意識地做的事情,你使用你的全部思維能力。而自回歸模型基本上只做系統(tǒng)1,根本就不太聰明。
最后一件事是通過將復雜的任務分解成簡單的任務,分層地推進和規(guī)劃復雜的行動序列。

然后,大約一年前,我寫了一篇愿景論文,我把它放在公開評論中,請你們看看。這基本上是我對我認為人工智能研究在未來10年應該走向的建議。它是圍繞著這樣一個想法,我們可以把各種模塊組織到所謂的認知架構(gòu)中,在這個系統(tǒng)中的核心是世界模型。
世界模型:通往AGI之路
世界模型是系統(tǒng)可以用來基本上想象一個場景的東西,想象將會發(fā)生什么,也許是其行為的后果。因此,整個系統(tǒng)的目的是根據(jù)它自己的預測,使用它的文字模型,找出一連串的行動,以最小化一系列的成本。成本你可以認為是衡量這個代理人的不適程度的標準。順便說一下,這些模塊中的許多在大腦中都有相應的子系統(tǒng)。成本模塊是我們(大腦里)的世界模型——前額葉皮層,短期記憶對應著海馬體;行為者可能是前運動區(qū);感知系統(tǒng)是大腦的后部,所有傳感器的感知分析都在這里進行。
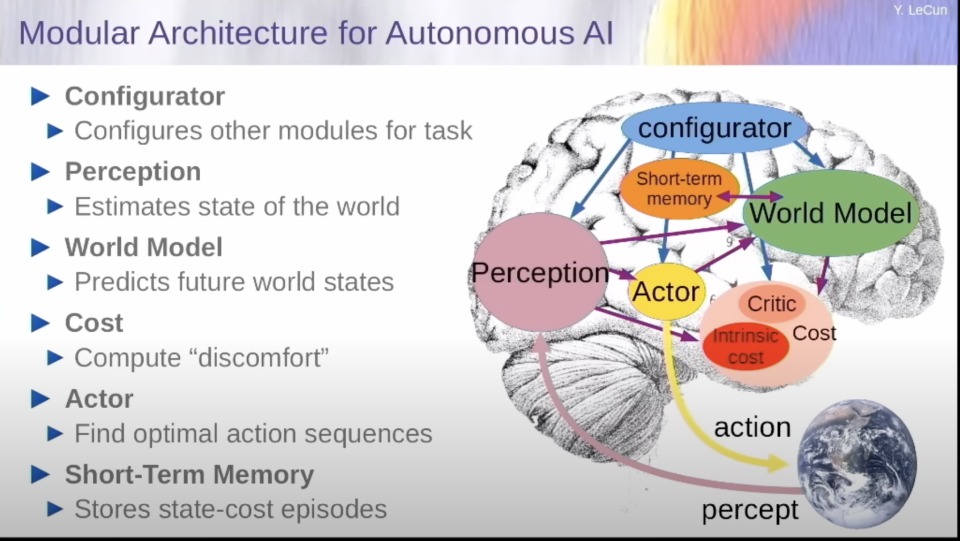
這個系統(tǒng)的運作方式是通過它可能被儲存在記憶中的以前對世界的想法,去處理當前世界的狀態(tài)。然后你用世界模型來預測如果世界接著運轉(zhuǎn)繼會發(fā)生什么,或者它作為代理將采取的行動的后果是什么。這是在這個黃色的行動模塊里面。行動模塊提出一連串的行動。世界模型模擬世界并計算出這些行動的后果會發(fā)生什么。然后計算出一個成本。然后將要發(fā)生的是,系統(tǒng)將優(yōu)化行動序列,以便使世界模型最小化。
所以我應該說的是,每當你看到一個箭頭朝向一個方向時,你也有梯度在向后移動。所以我假設所有這些模塊都是可分的,我們可以通過反向傳播梯度來推斷行動序列,從而使成本最小化。這不是關于參數(shù)的最小化——這將是關于行動的最小化。這是對潛在變量的最小化。而這是在推理時進行的。
因此,有兩種真正的方式來使用該系統(tǒng)。它類似于系統(tǒng)1,我在這里稱之為模式1,基本上它是反應性的。系統(tǒng)觀察世界的狀態(tài),通過感知編碼器來運行它,生成一個世界狀態(tài)的概念,然后直接通過策略網(wǎng)絡來運行它,而行為者只是直接產(chǎn)生一個行動。
模式2是你觀察世界并提取世界狀態(tài)的表征為0。然后,系統(tǒng)想象出從a[0]到一個很長T(時間)的一系列行動。這些預測的狀態(tài)被送入一個成本函數(shù),而系統(tǒng)的整個目的基本上是找出行動的序列,根據(jù)預測使成本最小。因此,這里的世界模型在每個時間步驟中重復應用,本質(zhì)上是從時間T的世界表征中預測出時間T+1的世界狀態(tài),并想象出一個擬議的行動。這個想法非常類似于優(yōu)化控制領域的人們所說的模型預測優(yōu)化。在深度學習的背景下,有許多使用這個想法來規(guī)劃軌跡工作的模型被提出來過。

這里的問題是我們到底如何學習這個世界模型?如果你跳過這個問題,我們期望做的是一些更復雜的版本,我們有一個分層系統(tǒng),通過一連串的編碼器,提取世界狀態(tài)的更多和更抽象的表示,并使用不同層次預測器的世界模型,在不同的擾動水平預測世界的狀態(tài),并在不同的時間尺度上進行預測。在這里的較高層次是指舉例來說,如果我想從紐約去北京,我需要做的第一件事就是去機場,然后搭飛機去北京。因此,這將是計劃的一種高層次的表示。最終的成本函數(shù)可以代表我與北京的距離,比如說。然后,第一個行動將是:去機場,我的狀態(tài)將是,我在機場嗎?然后第二個行動將是,搭飛機去北京。我怎么去機場呢?從,比方說,我在紐約的辦公室。我需要做的第一件事是,到街上去攔一輛出租車,并告訴他去機場。我如何走到街上去?我需要從椅子上站起來,我去出口處,打開門,走到街上,等等。然后你可以這樣想象,把這個任務一直分解到毫秒級,按毫秒級控制,你需要做的就是完成這個規(guī)模。
因此,所有復雜的任務都是以這種方式分層完成的,這是一個大問題,我們今天不知道如何用機器學習來解決。所以,我在這里展示的這個架構(gòu),還沒有人建立它。沒有人證明你可以使它發(fā)揮作用。所以我認為這是一個很大的挑戰(zhàn),分層規(guī)劃。
成本函數(shù)可以由兩組成本模塊組成,并將由系統(tǒng)調(diào)制以決定在任何時候完成什么任務。所以在成本中有兩個子模塊。有些是那種內(nèi)在的成本,是硬性規(guī)定的、不可改變的。你可以想象,那些成本函數(shù)將實施安全護欄,以確保系統(tǒng)行為正常,不危險,無毒等等。這是這些架構(gòu)的一個巨大優(yōu)勢,即你可以在推理的時候把成本進行優(yōu)化。
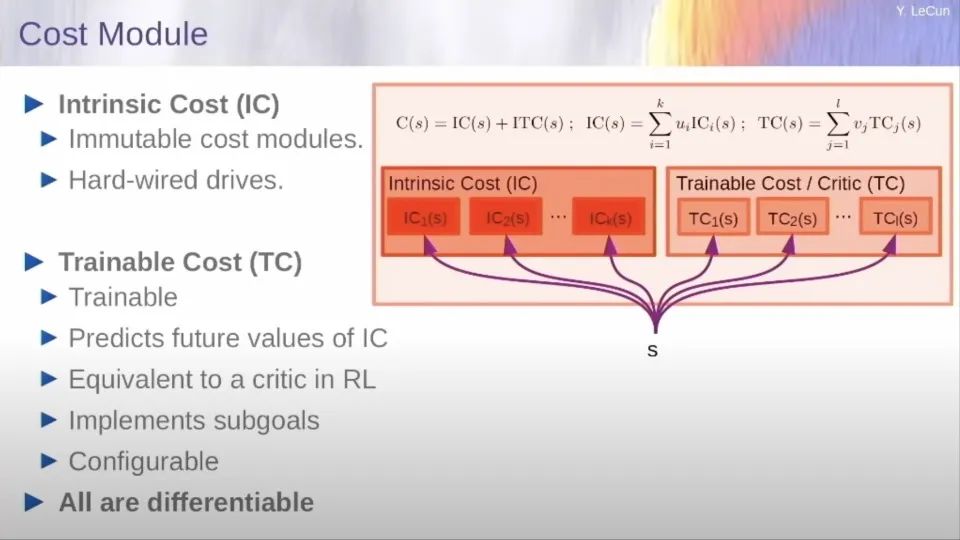
你可以保證那些標準,那些目標將被強制執(zhí)行,并將被系統(tǒng)的輸出所滿足。這與自回歸LLM非常不同,后者基本上沒有辦法確保其輸出是好的、無毒的和安全的。
楊立昆 X 朱軍 QA 環(huán)節(jié)
朱軍:
你好,LeCun教授。很高興再次見到你。那么我將主持問答環(huán)節(jié)。首先再次感謝你這么早起來做了這個富含思想的研討會報告,并提供了這么多見解。考慮到時間的限制,我選擇了幾個問題來問你。
正如你在演講中討論到生成型模型有很多問題,大多數(shù)我都同意你的看法,但是關于這些生成式模型的基本原則方面,我還是有一個問題要問你。生成模型就其定義來說,就是會輸出多種的選擇。另外,當我們應用生成模型的多樣性時,創(chuàng)造性是一個理想的屬性。所以我們經(jīng)常樂見用模型來輸出多樣化的結(jié)果。這是否意味著實際上像事實錯誤或不合邏輯的錯誤,不一致的地方,對于這樣的模型來說是不可避免的?因為在很多情況下,即使你有數(shù)據(jù),數(shù)據(jù)也可能包含了矛盾的事實。你也提到了預測的不確定性。所以這是我的第一個問題。那么你對此有什么想法?
楊立昆:
沒錯。所以我不認為自回歸預測模型、生成模型的問題是可以通過保留自回歸生成來解決的。我認為這些系統(tǒng)本質(zhì)上是不可控的。因此,我認為它們必須被我提出的那種架構(gòu)所取代,即在推理中包含時間,有一個系統(tǒng)去最優(yōu)化成本和某些標準。這是使它們可控、可引導、可計劃的唯一方法,即系統(tǒng)將能夠計劃出它們的答案。你知道當你在做一個像我剛才那樣的演講時,你會計劃演講的過程,對嗎?你從一個點講到另一個點,你解釋每個點。當你設計演講時,你在腦子里會計劃這些,而并不是(像大語言模型一樣)一個字接一個字地即興演講。也許在較低的(行為)水平上,你是即興創(chuàng)作,但在較高的(行為)水平上,你是在計劃。所以,計劃的必要性真的很明顯。而人類和許多動物有能力進行規(guī)劃的事實,我認為這是智力的一個內(nèi)在屬性。所以我的預測是,在相對較短的幾年內(nèi)--當然是在5年內(nèi)--沒有腦子正常的人會接著用自回歸LLM。這些系統(tǒng)將很快被拋棄。因為它們是無法被修復的。
朱軍:
好的。我想另一個關于控制的問題:在你的設計和框架中,一個關鍵部分是內(nèi)在成本模塊,對嗎?所以它的設計基本上是為了決定代理人行為的性質(zhì)。看了你的工作文件中的開放性觀點后,我和網(wǎng)上的一個評論有共同的擔憂。這個評論說,主要是這個模塊沒有按照規(guī)定工作。也許代理最后[屏幕凍結(jié)]了。
楊立昆:
保證系統(tǒng)安全的成本模塊不會是一個微不足道的任務,但我認為這將是一個相當明確的任務。它需要大量仔細的工程和微調(diào),其中一些成本可能要通過訓練獲得,而非僅僅通過設計。這與強化學習中的策略評估(Actor-Crtic結(jié)構(gòu)中的Ctric,對作為語言模型的行為者產(chǎn)出的結(jié)果進行評估)或LLM背景下的所謂獎勵模型是非常相同的,是一個會整體考量系統(tǒng)的內(nèi)部狀態(tài)到成本全程的事情。你可以訓練一個神經(jīng)網(wǎng)絡來預測成本,你可以通過讓它接觸大量的——讓它產(chǎn)生大量的輸出,然后讓某人或某物對這些輸出進行評價來訓練它。這給了你一個成本函數(shù)的目標。你可以對它進行訓練,讓它計算出一個小的成本,然后在得到成本之后通過它進行反向傳播,以保證這個成本函數(shù)得到滿足。所以,我認為設計成本這事兒,我認為我們將不得不從設計架構(gòu)和設計LLM的成本轉(zhuǎn)向設計成本函數(shù)。因為這些成本函數(shù)將推動系統(tǒng)的性質(zhì)和行為。與我的一些對未來比較悲觀同事相反,我認為設計與人類的價值觀相一致的成本(函數(shù))是非常可行的。這不是說如果你做錯一次,就會出現(xiàn)人工智能系統(tǒng)逃脫控制和接管世界的情況。而且我們在部署這些東西之前,會有很多方法把它們設計得很好。
朱軍:
我同意這一點。那么另一個與此相關的技術問題是,我注意到你通過分層的JEPA設計來模型,這其中幾乎所有的模塊都是可微的,對嗎?也許你可以用反向傳播的方法來訓練。但是你知道還有另外一個領域,比如說符號邏輯,它代表著不可微的部分,也許在內(nèi)在成本模塊中能以某種形式制定我們喜歡的約束條件,那么,你是否有一些特別的考慮來連接這兩個領域,或者干脆就忽略符號邏輯的領域?
楊立昆:
對。所以我認為是的,現(xiàn)實中是有一個神經(jīng)+符號架構(gòu)的子領域,試圖將可訓練的神經(jīng)網(wǎng)絡與符號操作或類似的東西結(jié)合在一起。我對這些方法非常懷疑,因為事實上符號操作是不可微的。所以它基本上與深度學習和基于梯度的學習不兼容,當然也與我所描述的那種基于梯度的推理不兼容。所以我認為我們應該盡一切努力在任何地方使用可微分的模塊,包括成本函數(shù)。現(xiàn)在可能有一定數(shù)量的情況下,我們可以實現(xiàn)的成本(函數(shù))是不可微的。對于這一點,執(zhí)行推理的優(yōu)化程序可能必須使用組合型的優(yōu)化,而不是基于梯度的優(yōu)化。但我認為這應該是最后的手段,因為零階無梯度優(yōu)化比基于梯度的優(yōu)化要少很多。因此,如果你能對你的成本函數(shù)進行可微調(diào)的近似,你應該盡可能地使用它。在某種程度上,我們已經(jīng)這樣做了。當我們訓練一個分類器時,我們想要最小化的成本函數(shù)并不完全準確。但這是不可微分的,所以我們使用的是一個可微分的成本代理。是系統(tǒng)輸出的成本熵與所需的輸出分布,或像e平方或鉸鏈損失的東西。這些基本上都是不可微分的二進制法則的上界,我們對它不能輕易優(yōu)化。因此還是用老辦法,我們必須使用成本函數(shù),它是我們實際想要最小化的成本的可微調(diào)近似值。
朱軍:
我的下一個問題是,我的靈感來自于我們的下一位演講者Tegmark教授,他將在你之后做一個現(xiàn)場演講。實際上我們聽說你將參加一場關于AGI的現(xiàn)狀和未來的辯論。由于我們大多數(shù)人可能無法參加,你能否分享一些關鍵點給我們一些啟發(fā)?我們想聽到一些關于這方面的見解。
楊立昆:
好的,這將是一場有四位參與者的辯論。辯論將圍繞一個問題展開,即人工智能系統(tǒng)是否會對人類造成生存風險。因此,馬克斯和約書亞本吉奧將站在 "是的,強大的人工智能系統(tǒng)有可能對人類構(gòu)成生存風險 "的一方。然后站在 "不"的一方的將是我和來自圣菲研究所的梅蘭妮-米切爾。而我們的論點不會是AI沒有風險。我們的論點是,這些風險雖然存在,但通過仔細的工程設計,很容易減輕或抑制。我對此的論點是,你知道在今天問人們,我們是否能保證超級智能系統(tǒng)對人類而言是安全,這是個無法回答的問題。因為我們沒有對超級智能系統(tǒng)的設計。因此,在你有基本的設計之前,你不能使一件東西安全。這就像你在1930年問航空工程師,你能使渦輪噴氣機安全和可靠嗎?而工程師會說,"什么是渦輪噴氣機?" 因為渦輪噴氣機在1930年還沒有被發(fā)明出來。所以我們有點處于同樣的情況。聲稱我們不能使這些系統(tǒng)安全,因為我們還沒有發(fā)明它們,這有點為時過早。一旦我們發(fā)明了它們--也許它們會與我提出的藍圖相似,那么就值得討論。"我們?nèi)绾问顾鼈儼踩?,在我看來,這將是通過設計那些使推理時間最小化的目標。這就是使系統(tǒng)安全的方法。顯然,如果你想象未來的超級智能人工智能系統(tǒng)將是自回歸的LLM,那么我們當然應該害怕,因為這些系統(tǒng)是不可控制的。他們可能會逃脫我們的控制,胡言亂語。但我所描述的那種類型的系統(tǒng),我認為是可以做到安全的。而且我非常肯定它們會。這將需要仔細的工程設計。這并不容易,就像在過去七十年里,使渦輪噴氣機變得可靠并不容易一樣。渦輪噴氣機現(xiàn)在令人難以置信的可靠。你可以用雙引擎飛機跨越大洋,而且基本上具有這難以置信的安全性。因此,這需要謹慎的工程。而且這真的很困難。我們大多數(shù)人都不知道渦輪噴氣機是如何設計成安全的。因此,想象一下這事情這并不瘋狂。弄清楚如何使一個超級智能的人工智能系統(tǒng)安全,也是很難想象的。
朱軍:
好的。謝謝你的洞察和回答。同樣作為工程師,我也再次感謝你。非常感謝。
楊立昆:
非常感謝你。
-
機器學習
+關注
關注
66文章
8421瀏覽量
132710 -
GPT
+關注
關注
0文章
354瀏覽量
15407
原文標題:圖靈獎得主楊立昆:GPT模式五年就不會有人用了,世界模型才是AGI未來
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
ADC12D1000Vcmo工作在輸出模式,如果接地了會不會有問題?
邵逸夫獎得主圓桌論壇于香港科學館舉行

戰(zhàn)爭2025年結(jié)束——如果赤裸就不會有戰(zhàn)爭
圖靈測試的內(nèi)容是什么_圖靈測試的作用
差分儀表運放的電阻電容混接會不會有問題?
用OPA141仿真一個濾波器,在做直流工作點分析時顯示DC operating point calculation not converge,為什么?
智平方打通具身智能核心痛點:將AGI拓展到物理世界

選項字中IWDG_HW和WWDG_HW可以配置看門狗是軟件模式還是硬件模式,有人用過硬件模式嗎?
商湯科技發(fā)布5.0多模態(tài)大模型,綜合能力全面對標GPT-4 Turbo
OpenAI研發(fā)文生視頻模型Sora,AGI或僅需一兩年實現(xiàn)?
玄鐵的rv64ilp32之路 - 32位Linux的未來






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論