") 2023北京智源大會(huì)亮點(diǎn)回顧 | 高性能計(jì)算、深度學(xué)習(xí)和大模型:打造通用人工智能AGI的金三角
2023北京智源大會(huì)亮點(diǎn)回顧 | 高性能計(jì)算、深度學(xué)習(xí)和大模型:打造通用人工智能AGI的金三角

AIGC| Aquila | HuggingFace
AGI | DeepMind |Stability AI
通用人工智能(AGI)是人工智能領(lǐng)域的最終目標(biāo),也是一項(xiàng)極具挑戰(zhàn)性的任務(wù)。在諸多技術(shù)(深度學(xué)習(xí)、高性能計(jì)算、大模型訓(xùn)練以及ChatGPT等)的支持下,AGI的實(shí)現(xiàn)正在逐步向前推進(jìn)。與目前的弱人工智能不同,AGI是一種能夠像人類一樣進(jìn)行思考、學(xué)習(xí)和解決問題的智能系統(tǒng)。它可以理解和應(yīng)對(duì)各種不同的情境,并能夠自主地學(xué)習(xí)和適應(yīng)新的環(huán)境。實(shí)現(xiàn)AGI需要克服許多技術(shù)和理論上的挑戰(zhàn),例如如何讓計(jì)算機(jī)具有自我意識(shí)和情感,以及如何處理復(fù)雜的語言和語境。一旦實(shí)現(xiàn)了AGI,將會(huì)對(duì)人類社會(huì)產(chǎn)生深遠(yuǎn)的影響,甚至可能改變我們所理解的本質(zhì)。
北京智源大會(huì)于6月10日?qǐng)A滿閉幕,OpenAI、DeepMind、Anthropic、HuggingFace、Midjourney、Stability AI等多位明星團(tuán)隊(duì)及Meta、谷歌、微軟等知名大廠和斯坦福、UC伯克利、MIT等頂尖學(xué)府出席,共同探討人工智能發(fā)展。圖靈獎(jiǎng)得主Yann LeCun、Geoffrey Hinton以及OpenAI創(chuàng)始人Sam Altman的演講更是推動(dòng)大會(huì)氣氛到了高潮,展現(xiàn)專業(yè)深度與創(chuàng)意啟發(fā)兼具的魅力。
智源研究院院長(zhǎng)黃鐵軍在演講中提到,要實(shí)現(xiàn)通用人工智能(AGI),有三條技術(shù)路線:第一是“大數(shù)據(jù)+自監(jiān)督學(xué)習(xí)+大算力”形成的信息類模型;第二是具身智能,即基于虛擬世界或真實(shí)世界、通過強(qiáng)化學(xué)習(xí)訓(xùn)練出來的具身模型;第三是腦智能,直接“抄自然進(jìn)化的作業(yè)”,復(fù)制出數(shù)字版本的智能體。
OpenAI的GPT(生成式預(yù)訓(xùn)練Transformer模型)就遵循第一條技術(shù)路線;以谷歌DeepMind的DQN(深度Q網(wǎng)絡(luò))為核心取得的一系列進(jìn)展即基于第二條技術(shù)路線。黃鐵軍表示,智源期望從“第一性原理”出發(fā),通過構(gòu)建一個(gè)完整的智能系統(tǒng)AGI,從原子到有機(jī)分子、到神經(jīng)系統(tǒng)、到身體,實(shí)現(xiàn)通用人工智能。這是一個(gè)大概需要20年時(shí)間才能實(shí)現(xiàn)的目標(biāo)。
小編將總結(jié)智源大會(huì)亮點(diǎn),讓我們一起來看吧。
智源大會(huì)亮點(diǎn)總結(jié)
一、Geoffrey Hinton:超級(jí)AI風(fēng)險(xiǎn)緊迫
圖靈獎(jiǎng)得主、深度學(xué)習(xí)之父Hinton在主題演講中提出值得深思的問題:“人工神經(jīng)網(wǎng)絡(luò)是否比真正的神經(jīng)網(wǎng)絡(luò)更聰明?”Hinton曾就職谷歌,直言對(duì)自己畢生工作感到后悔,并對(duì)人工智能危險(xiǎn)感到擔(dān)憂。
他多次公開稱,人工智能對(duì)世界的危險(xiǎn)比氣候變化更加緊迫。在演講中,再次談及AI風(fēng)險(xiǎn)。如果一個(gè)在多臺(tái)數(shù)字計(jì)算機(jī)上運(yùn)行的大型神經(jīng)網(wǎng)絡(luò),除了可以模仿人類語言獲取人類知識(shí),還能直接從世界中獲取知識(shí),會(huì)發(fā)生什么情況呢?
顯然,它會(huì)變得比人類優(yōu)秀得多,因?yàn)樗^察到了更多的數(shù)據(jù)。這種設(shè)想并不是天方夜譚。如果這個(gè)神經(jīng)網(wǎng)絡(luò)能夠通過對(duì)圖像或視頻進(jìn)行無監(jiān)督建模,并且它的副本也能操縱物理世界,那么在最極端的情況下,不法分子會(huì)利用超級(jí)智能操縱選民,贏得戰(zhàn)爭(zhēng)。如果允許超級(jí)智能自行制定子目標(biāo),一個(gè)子目標(biāo)是獲得更多權(quán)力,這個(gè)超級(jí)AI就會(huì)為了達(dá)成目標(biāo),操縱使用它的人類。

二、智源研究院理事長(zhǎng)張宏江與Sam Altman巔峰問答:AGI或?qū)⑹陜?nèi)出現(xiàn)
Sam Altman通過視頻連線現(xiàn)身,這是ChatGPT爆火之后首次在中國公開演講。他強(qiáng)調(diào)了全球AI安全對(duì)齊與監(jiān)管的必要性,特別是隨著日益強(qiáng)大的AI系統(tǒng)的出現(xiàn),加強(qiáng)國際間的通力合作,建立全球信任尤為重要。Altman還提到,對(duì)齊仍是一個(gè)未解決的問題,GPT-4在過去8個(gè)月時(shí)間完成對(duì)齊工作,主要包括擴(kuò)展性和可解釋性。他引用了《道德經(jīng)》中的一句話:“千里之行,始于足下”,強(qiáng)調(diào)了推進(jìn)AGI安全和加強(qiáng)國際間的通力合作的重要性。
Altman認(rèn)為,國際科技界合作是當(dāng)下邁出建設(shè)性步伐的第一步應(yīng)該提高在AGI安全方面技術(shù)進(jìn)展的透明度和知識(shí)共享機(jī)制。OpenAI的主要研究目標(biāo)集中在AI對(duì)齊研究上,即如何讓AI成為一個(gè)有用且安全的助手。一是可擴(kuò)展監(jiān)督,嘗試用AI系統(tǒng)協(xié)助人類監(jiān)督其他人工智能系統(tǒng)。二是可解釋性,嘗試?yán)斫獯竽P蛢?nèi)部運(yùn)作“黑箱”。最終,OpenAI的目標(biāo)是訓(xùn)練AI系統(tǒng)來幫助進(jìn)行對(duì)齊研究。
在隔空對(duì)話中,張宏江和Sam Altman一起探討了如何讓AI安全對(duì)齊的難題。當(dāng)被問及OpenAI是否會(huì)開源大模型時(shí),Altman稱未來會(huì)有更多開源,但沒有具體模型和時(shí)間表。他還表示不會(huì)很快有GPT-5。

三、LeCun:依然是世界模型的擁躉
圖靈獎(jiǎng)得主卷積神經(jīng)網(wǎng)絡(luò)之父LeCun繼續(xù)推行自己的“世界模型”理念。對(duì)于AI毀滅人類的看法,LeCun認(rèn)為這種擔(dān)心實(shí)屬多余,因?yàn)槿缃竦腁I還不如一條狗的智能高,還沒有發(fā)展出真正的人工智能。他認(rèn)為,構(gòu)建人類水平AI的關(guān)鍵,可能就是學(xué)習(xí)“世界模型”的能力。“世界模型”由六個(gè)獨(dú)立模塊組成:配置器模塊、感知模塊、世界模型、Cost模塊、Actor模塊、短期記憶模塊。他認(rèn)為,為世界模型設(shè)計(jì)架構(gòu)以及訓(xùn)練范式,才是未來幾十年阻礙人工智能發(fā)展的真正障礙。
LeCun解釋道,AI不能像人類和動(dòng)物一樣推理和規(guī)劃,部分原因是目前的機(jī)器學(xué)習(xí)系統(tǒng)在輸入和輸出之間的計(jì)算步驟基本恒定。如何讓機(jī)器理解世界如何運(yùn)作,像人類一樣預(yù)測(cè)行為后果,或?qū)⑵浞纸鉃槎嗖絹碛?jì)劃復(fù)雜的任務(wù)呢?顯然,自監(jiān)督學(xué)習(xí)是一個(gè)路徑。相比強(qiáng)化學(xué)習(xí),自監(jiān)督學(xué)習(xí)可以產(chǎn)生大量反饋,預(yù)測(cè)其輸入的任何一部分。
LeCun確定未來幾年人工智能的三大挑戰(zhàn),就是學(xué)習(xí)世界的表征、預(yù)測(cè)世界模型、利用自監(jiān)督學(xué)習(xí)。被問到AI系統(tǒng)是否會(huì)對(duì)人類構(gòu)成生存風(fēng)險(xiǎn)時(shí),LeCun表示,我們還沒有超級(jí)AI,何談如何讓超級(jí)AI系統(tǒng)安全呢?

四、悟道·天鷹(Aquila):全面開放商用許可
悟道·天鷹(Aquila)系列大模型首次亮相,首個(gè)具備中英雙語知識(shí),支持國內(nèi)數(shù)據(jù)合規(guī)需求的開源語言大模型。該系列大模型已經(jīng)全面開放商用許可,并開源了包括70億參數(shù)和330億參數(shù)的基礎(chǔ)模型、AquilaChat對(duì)話模型,以及AquilaCode“文本-代碼”生成模型。

1、性能更強(qiáng)
Aquila基礎(chǔ)模型(7B、33B)繼承了GPT-3、LLaMA等的架構(gòu)設(shè)計(jì)優(yōu)點(diǎn),并替換了一批更高效的底層算子實(shí)現(xiàn)、重新設(shè)計(jì)實(shí)現(xiàn)了中英雙語的tokenizer,升級(jí)了BMTrain并行訓(xùn)練方法。在訓(xùn)練過程中,智源實(shí)現(xiàn)了比Magtron+DeepSpeed ZeRO-2將近8倍的訓(xùn)練效率。這得益于智源去年大模型算法開源項(xiàng)目FlagAI,集成了BMTrain這樣新的并行訓(xùn)練方法,優(yōu)化計(jì)算和通信以及重疊的問題。此外,智源率先引入算子優(yōu)化技術(shù),將其與并行加速方法集成,進(jìn)一步提升性能。
2、中英雙語的大模型
悟道·天鷹(Aquila)的發(fā)布非常值得鼓舞,因?yàn)楹芏啻竽P椭粚W(xué)習(xí)英文,但悟道·天鷹(Aquila)需要同時(shí)學(xué)習(xí)中文和英文,訓(xùn)練難度提升了很多倍。為了讓悟道·天鷹(Aquila)針對(duì)中文任務(wù)達(dá)到優(yōu)化,智源放了將近40%的中文語料在訓(xùn)練語料中。智源還重新設(shè)計(jì)實(shí)現(xiàn)了中英雙語的tokenizer(分詞器),以更好地識(shí)別和支持中文的分詞。
在訓(xùn)練和設(shè)計(jì)的過程中,智源團(tuán)隊(duì)特意權(quán)衡質(zhì)量和效率兩個(gè)維度決定分詞器大小。悟道·天鷹(Aquila)基礎(chǔ)模型底座上打造AquilaChat對(duì)話模型(7B、33B)支持流暢的文本對(duì)話及多種語言類生成任務(wù)。通過定義可擴(kuò)展的特殊指令規(guī)范,可以實(shí)現(xiàn)AquilaChat對(duì)其它模型和工具的調(diào)用,且易于擴(kuò)展。AquilaCode-7B“文本-代碼”生成模型基于Aquila-7B強(qiáng)大的基礎(chǔ)模型能力,以小數(shù)據(jù)集、小參數(shù)量、高性能實(shí)現(xiàn)了中英雙語的開源代碼模型。AquilaCode-7B在英偉達(dá)和***上完成了代碼模型的訓(xùn)練,并通過對(duì)多種架構(gòu)的代碼+模型開源,推動(dòng)芯片創(chuàng)新和百花齊放。

3、更合規(guī)、更干凈的中文語料
悟道·天鷹(Aquila)最鮮明的特點(diǎn)就在于支持國內(nèi)數(shù)據(jù)合規(guī)需求。相比國外的開源大模型,悟道·天鷹(Aquila)使用的中文數(shù)據(jù)更加滿足合規(guī)需要,更加干凈。智源的目標(biāo)是打造一整套大模型進(jìn)化迭代流水線,讓大模型在更多數(shù)據(jù)和更多能力的添加之下,源源不斷地成長(zhǎng),并且會(huì)持續(xù)開源開放。悟道 · 天鷹(Aquila)在消費(fèi)級(jí)顯卡上就可用,比如7B模型就能在16G甚至更小的顯存上跑起來。
AGI過去、現(xiàn)在及未來發(fā)展
要預(yù)知未來,先了解過去。AGI是DeepMind率先引入大眾視野并通過其努力引發(fā)整個(gè)世界關(guān)注的AI終極方向。
一、什么是AI、AGI、AIGC、ChatGPT?
1、AI
人工智能(AI)是指由人制造出來的機(jī)器所表現(xiàn)出來的智能,通過普通計(jì)算機(jī)程序來呈現(xiàn)人類智能的技術(shù)。人工智能涵蓋了很多不同的領(lǐng)域和技術(shù),同時(shí)也指研究這樣的智能系統(tǒng)是否能夠?qū)崿F(xiàn),以及如何實(shí)現(xiàn)。
2、AGI
通用人工智能(Artificial General Intelligence, AGI)又稱“強(qiáng)人工智能(Strong AI)”“完全人工智能(Full AI)”,是具有一般人類智慧,可以執(zhí)行人類能夠執(zhí)行的任何智力任務(wù)的機(jī)器智能。通用人工智能是一些人工智能研究的主要目標(biāo),也是科幻小說和未來研究中的共同話題。與弱人工智能相比,通用人工智能可以嘗試執(zhí)行全方位的人類認(rèn)知能力。
3、AIGC
人工智能生成內(nèi)容(Artificial Inteligence Generated Content,縮寫為AIGC),又稱生成式AI,被認(rèn)為是繼專業(yè)生產(chǎn)內(nèi)容(PGC)、用戶生產(chǎn)內(nèi)容(UGC)之后的新型內(nèi)容創(chuàng)作方式。
互聯(lián)網(wǎng)內(nèi)容生產(chǎn)方式經(jīng)歷PGC——UGC——AIGC的過程。
PGC是專業(yè)生產(chǎn)內(nèi)容,如Web1.0和廣電行業(yè)中專業(yè)人員生產(chǎn)的文字和視頻,其特點(diǎn)是專業(yè),內(nèi)容質(zhì)量有保證;UGC是用戶生產(chǎn)內(nèi)容,伴隨Web2.0概念而產(chǎn)生,特點(diǎn)是用戶可以自由上傳內(nèi)容,內(nèi)容豐富;AIFC是由AI生成的內(nèi)容,其特點(diǎn)是自動(dòng)化生產(chǎn),高效。
隨著自然語言生成技術(shù)NLG和AI模型的成熟,AIGC逐漸受到大家的關(guān)注,目前已經(jīng)可以自動(dòng)生成文字、圖片、音頻、視頻,甚至3D模型和代碼。AIGC極大的推動(dòng)元宇宙的發(fā)展,元宇宙中大量的數(shù)字原生內(nèi)容,需要由AI幫助完成創(chuàng)作。
4、ChatGPT
ChatGPT(Chat Generative Pre-trained Transformer)聊天生成預(yù)訓(xùn)練轉(zhuǎn)換器,屬于AIGC范疇。ChatGPT是OpenAI開發(fā)的人工智能聊天機(jī)器人程序,于2022年推出。ChatGPT目前仍以文字方式交互,而除了可以用人類自然對(duì)話方式來交互,還可以用于更為復(fù)雜的語言工作,包括自動(dòng)生成文本,自動(dòng)問答,自動(dòng)摘要等多種任務(wù)。

二、2013-2022:AGI的簡(jiǎn)要發(fā)展史
2015年,Deepmind第一版的DQN,第一次將DL和RL結(jié)合,開啟了AGI的實(shí)現(xiàn)道路。同年DeepMind的AlphaGo橫空出世,實(shí)現(xiàn)了深度學(xué)習(xí)的全新里程碑。
2016年,OpenAI成立。
2018年,OpenAI 提出Dota Five,在Dota上戰(zhàn)勝職業(yè)選手。
2019年,Deepmind提出AlphaStar,在星際爭(zhēng)霸上戰(zhàn)勝職業(yè)選手。同年,OpenAI實(shí)現(xiàn)了用機(jī)械手玩魔方。接下來的里程碑就轉(zhuǎn)向了語言模型,圖文生成及AI for Science。
2020年,OpenAI發(fā)布Image GPT,DeepMind發(fā)布AlphaFold-2。
2021年,OpenAI發(fā)布Dalle、GPT-3、Codex。
2022年,DeepMind發(fā)布AlphaCode,OpenAI發(fā)布Dalle-2、InstructGPT和ChatGPT。
上面列舉的可能不全,但主要是OpenAI和DeepMind的工作。其他公司及學(xué)界也有很多不錯(cuò)的工作,但論影響力都達(dá)不到他們的高度。這兩家公司都宣稱要搞AGI,因此成為了關(guān)注的焦點(diǎn)。
三、AGI發(fā)展的背后緣由
看到了這么多的里程碑,他們之間有什么聯(lián)系?實(shí)際上,這些發(fā)展都是在David Silver的PPT中提到的范式中進(jìn)行的,只是在其中加入了IL(Imitation Learning)模仿學(xué)習(xí),讓關(guān)聯(lián)更加緊密。
1、DL
DL主要指的是基于深度神經(jīng)網(wǎng)絡(luò)的一套學(xué)習(xí)訓(xùn)練方式,簡(jiǎn)單的說就是一個(gè)神經(jīng)網(wǎng)絡(luò),一個(gè)損失函數(shù),一個(gè)反向傳播。
2、LeNet
深度學(xué)習(xí)的發(fā)展,網(wǎng)絡(luò)變了,變成了以Transformer為主流的網(wǎng)絡(luò)結(jié)構(gòu),但核心機(jī)制是完全沒有變化的。
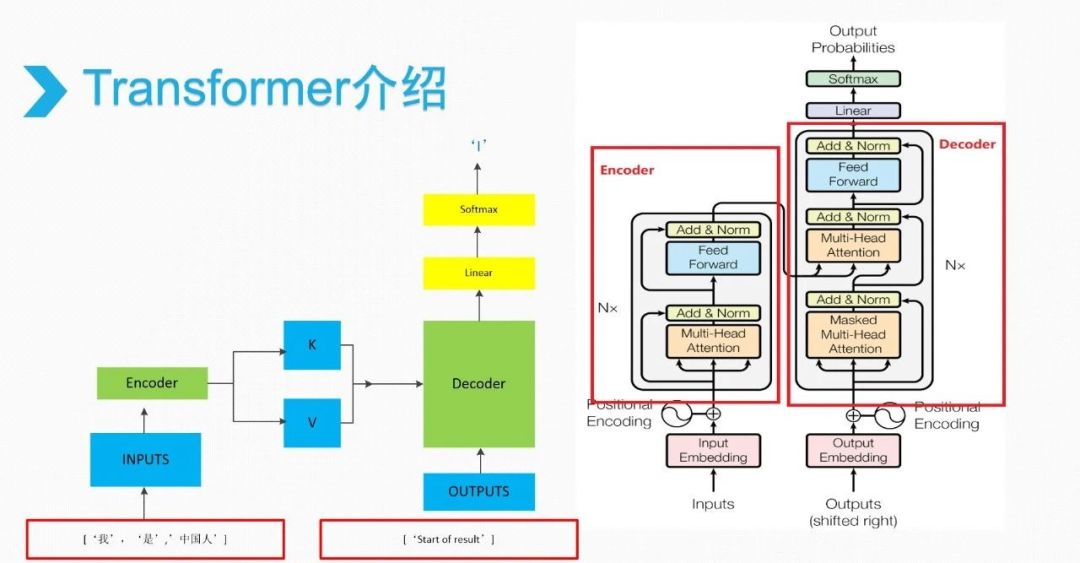
Transformer
IL和RL是構(gòu)建損失函數(shù)訓(xùn)練神經(jīng)網(wǎng)絡(luò)的方法。IL模仿學(xué)習(xí)是指使用大量人類選手的數(shù)據(jù)來訓(xùn)練神經(jīng)網(wǎng)絡(luò),以便讓它們學(xué)習(xí)如何在特定領(lǐng)域中表現(xiàn)得像人類一樣。例如,AlphaGo的第一代和AlphaStar都使用了大量圍棋和星際爭(zhēng)霸人類選手的數(shù)據(jù)來進(jìn)行模仿學(xué)習(xí)。而GPT和ChatGPT則使用了大量的人類文本數(shù)據(jù),通過自回歸的方式來進(jìn)行模仿學(xué)習(xí)。模仿學(xué)習(xí)的優(yōu)點(diǎn)在于訓(xùn)練速度快,因?yàn)樗峁┝松窠?jīng)網(wǎng)絡(luò)可以學(xué)習(xí)的大量數(shù)據(jù)。
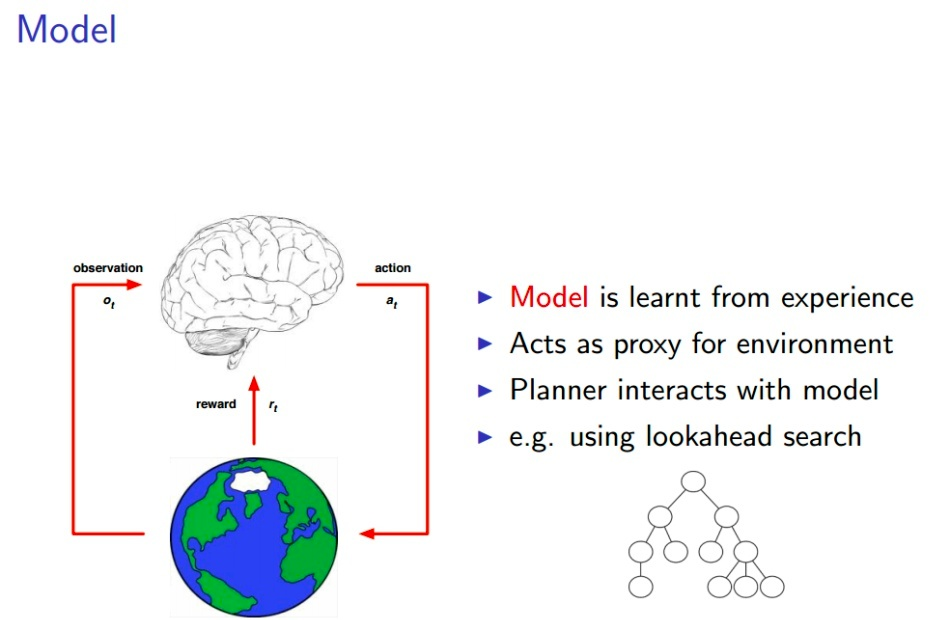
來自David Silver的ppt
實(shí)際上,人類的學(xué)習(xí)過程也是模仿學(xué)習(xí)和強(qiáng)化學(xué)習(xí)的結(jié)合。因此,所謂的AI就是模仿人類學(xué)習(xí)而構(gòu)建的智能。AlphaGo在模仿學(xué)習(xí)后開始強(qiáng)化學(xué)習(xí),水平可以吊打人類專業(yè)選手;AlphaStar在模仿學(xué)習(xí)后開始強(qiáng)化學(xué)習(xí),能夠戰(zhàn)勝人類專業(yè)選手;ChatGPT在模仿學(xué)習(xí)后(GPT)使用人類反饋的信息進(jìn)行強(qiáng)化學(xué)習(xí),能夠比較好地按照人類的指令來回答問題。這展示強(qiáng)化學(xué)習(xí)的威力。從某種程度上說,可以認(rèn)為整個(gè)人類都是一個(gè)智能體,正在通過科學(xué)家做強(qiáng)化學(xué)習(xí)來拓展人類的文明邊界。
為什么早期的AI里程碑都是限定場(chǎng)景,而之后就變成了像GPT這樣的通用場(chǎng)景呢?
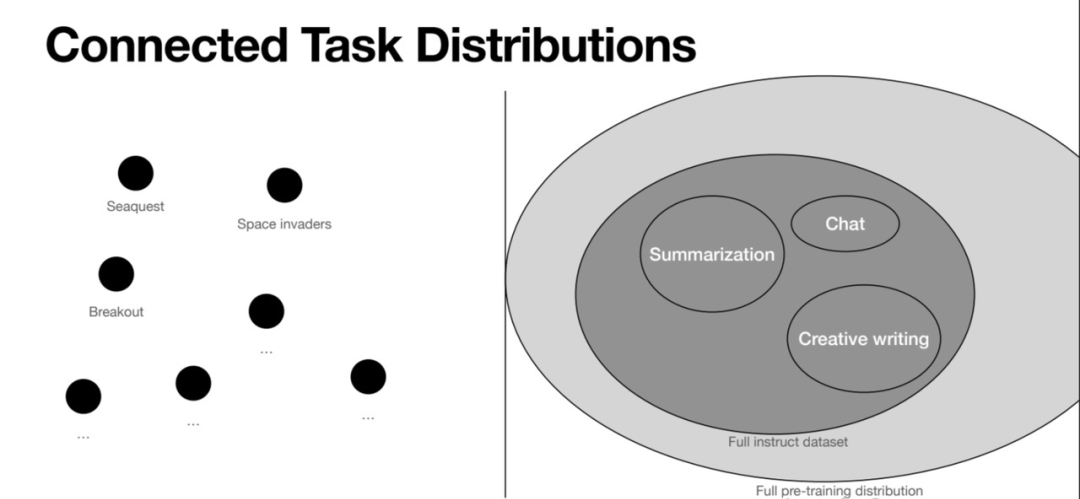
From John Schulman's PPT
早期的AI里程碑都是限定場(chǎng)景,因?yàn)橄薅▓?chǎng)景的數(shù)據(jù)量太少,無法實(shí)現(xiàn)通用性。John Schulman(PPO和ChatGPT的作者)的這張圖對(duì)比了之前的Atari等游戲場(chǎng)景和GPT場(chǎng)景在任務(wù)分布上的不同。游戲場(chǎng)景都是獨(dú)立的,不同任務(wù)之間的差異也就是GAP非常大,所以AI學(xué)會(huì)一個(gè)游戲并不能讓其會(huì)玩另一個(gè)游戲。而GPT的場(chǎng)景是文字世界,總結(jié)、寫作、聊天都是聯(lián)系在一起的,所以它們的任務(wù)有千千萬,并且是連續(xù)的。使得GPT訓(xùn)練后具備很強(qiáng)的Few-Shot Learning/Meta Learning的能力,即能夠?qū)崿F(xiàn)非常強(qiáng)的泛化能力,面向全新的問題也能夠回答。Meta Learning(元學(xué)習(xí))也就是學(xué)會(huì)學(xué)習(xí),這個(gè)概念在學(xué)術(shù)界2017、2018年后非常火,因?yàn)榇蠹野l(fā)現(xiàn)之前的AI都需要大量訓(xùn)練才能做新任務(wù),而人類則具備快速學(xué)習(xí)的能力,因此AI也需要具備這樣的能力。
GPT通過巨量的文本數(shù)據(jù)做模仿學(xué)習(xí),InstructGPT通過巨量的任務(wù)文本數(shù)據(jù)做Instruct Finetuning,具備極強(qiáng)的快速學(xué)習(xí)能力。由此開創(chuàng)Prompt Engineering或者學(xué)術(shù)界叫In-Context Learning這個(gè)全新領(lǐng)域,即我們不再需要訓(xùn)練模型,只需要修改開頭的輸入Prompt,就能讓AI快速學(xué)習(xí)并輸出合理的結(jié)果。
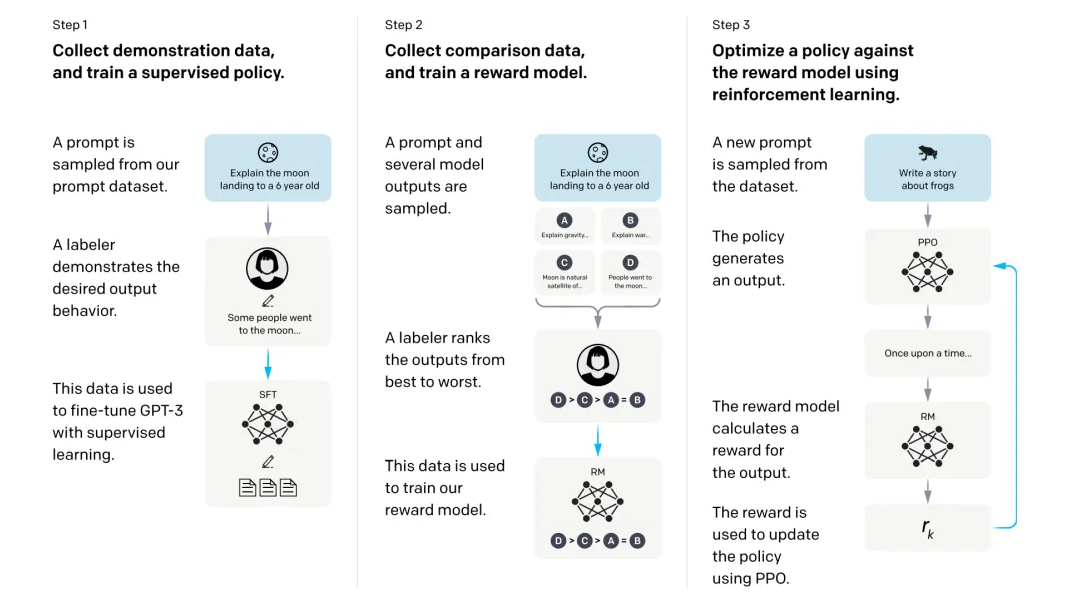
OpenAI非常快地意識(shí)到文字世界這個(gè)場(chǎng)景擁有的數(shù)據(jù)量無與倫比,因此迅速轉(zhuǎn)換賽道,關(guān)閉機(jī)器人組。這種決策令人十分欽佩。最近,DeepMind發(fā)布Ada,它仍然是游戲場(chǎng)景里的AI,但DeepMind也發(fā)現(xiàn)了原來Atari的任務(wù)空間分布差距太大的問題,因此改用自己構(gòu)建的全新環(huán)境Xland進(jìn)行大模型的訓(xùn)練。從另一個(gè)角度看,如果這個(gè)XLand未來能夠變成真實(shí)世界,那么完全體的AGI也就有可能在其中誕生。因此,AGI的實(shí)現(xiàn)變成了一個(gè)時(shí)間問題。
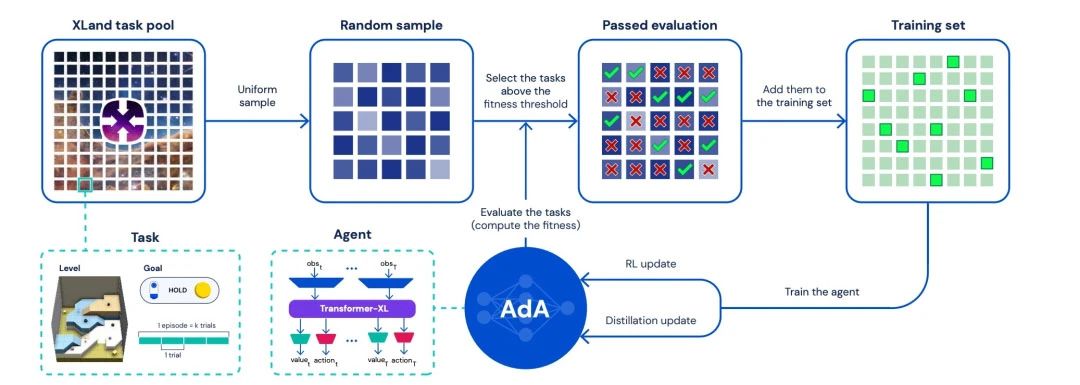
四、2023-2028: AGI會(huì)如何發(fā)展?
1、文字世界的精進(jìn),LLM從普通到專業(yè)
目前ChatGPT看起來很驚艷,似乎什么都懂,但實(shí)際上存在很多事實(shí)錯(cuò)誤和邏輯錯(cuò)誤,如果讓它參加高考,除了英語,其他科目很難考高分。下一步的LLM需要變得更加專業(yè),如通過高考考出985的水平,這樣LLM就能成為一個(gè)真正有知識(shí)有文化的人,也意味著AI將完全通過圖靈測(cè)試。GPT-4或許會(huì)給我們帶來驚喜。
通過高考之后,下一步當(dāng)然是專業(yè)領(lǐng)域的學(xué)習(xí)。LLM能否通過司法考試或公務(wù)員考試?是否能獲得IMO或ACM的金牌?模仿學(xué)習(xí)之后,需要通過強(qiáng)化學(xué)習(xí)進(jìn)行進(jìn)一步的精進(jìn),這對(duì)于LLM在專業(yè)領(lǐng)域同樣適用。例如在數(shù)學(xué)領(lǐng)域,現(xiàn)實(shí)世界中并沒有那么多的數(shù)學(xué)難題可以模仿,需要通過強(qiáng)化學(xué)習(xí)來讓LLM解決數(shù)學(xué)難題。如果可以,基于Transformer的網(wǎng)絡(luò)架構(gòu)還可以繼續(xù)發(fā)展,否則就需要全新的架構(gòu)來進(jìn)一步突破。目前,DeepMind的AlphaCode團(tuán)隊(duì)正在探索這方面的問題,目前的算法仍然是模仿學(xué)習(xí)。
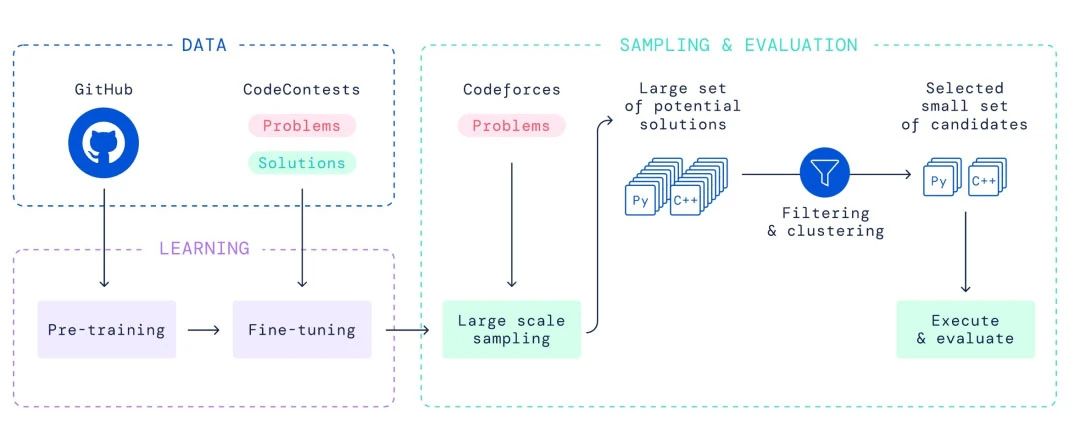
2、征服多模態(tài)的視頻世界
相比文字世界,視頻世界的數(shù)據(jù)量要大得多。人類從嬰兒開始就是通過多模態(tài)的數(shù)據(jù)(當(dāng)然還包括觸覺、味覺、嗅覺等)來快速學(xué)習(xí)。如果AI能夠?qū)崿F(xiàn)很強(qiáng)的多模態(tài)學(xué)習(xí)能力,通過海量的視頻進(jìn)行學(xué)習(xí),那么AI將會(huì)展現(xiàn)出令人難以置信的能力。
3、大模型連接現(xiàn)實(shí)世界,成為一個(gè)General Agent
Ada在一個(gè)小的虛擬世界中展現(xiàn)了其通用的決策能力,而ChatGPT則在文字世界中展現(xiàn)了強(qiáng)大的通用文字能力。然而,AGI不可能局限于文字或多模態(tài),關(guān)鍵在于決策。這也是我們堅(jiān)信RL是通往AGI的初始原因。因此,大型模型將作為一個(gè)Agent智能體出現(xiàn),影響現(xiàn)實(shí)世界!
4、自動(dòng)駕駛將全面轉(zhuǎn)向大模型,并真正向L4、L5進(jìn)發(fā)
自動(dòng)駕駛是一個(gè)非常好的限定多模態(tài)場(chǎng)景,肯定會(huì)從大型模型的發(fā)展中受益。可以使用海量數(shù)據(jù)進(jìn)行模仿學(xué)習(xí),通過強(qiáng)化學(xué)習(xí)在仿真環(huán)境中進(jìn)行優(yōu)化,解決Corner Case,從而實(shí)現(xiàn)完全自動(dòng)駕駛。甚至,可以基于一個(gè)多模態(tài)的大型模型來構(gòu)建基礎(chǔ)模型,這樣不僅可以獲得自動(dòng)駕駛的能力,還獲得一個(gè)能夠與人聊天的自動(dòng)駕駛司機(jī)。這正是科幻片中的自動(dòng)駕駛汽車所展現(xiàn)的。
5、通用家用機(jī)器人將大幅發(fā)展,同樣采用大模型
和自動(dòng)駕駛類似,通用家用機(jī)器人也是一個(gè)限定的多模態(tài)場(chǎng)景,難度可能更大。Google的RT-1已經(jīng)驗(yàn)證了大模型驅(qū)動(dòng)機(jī)器人的模式是可行的。
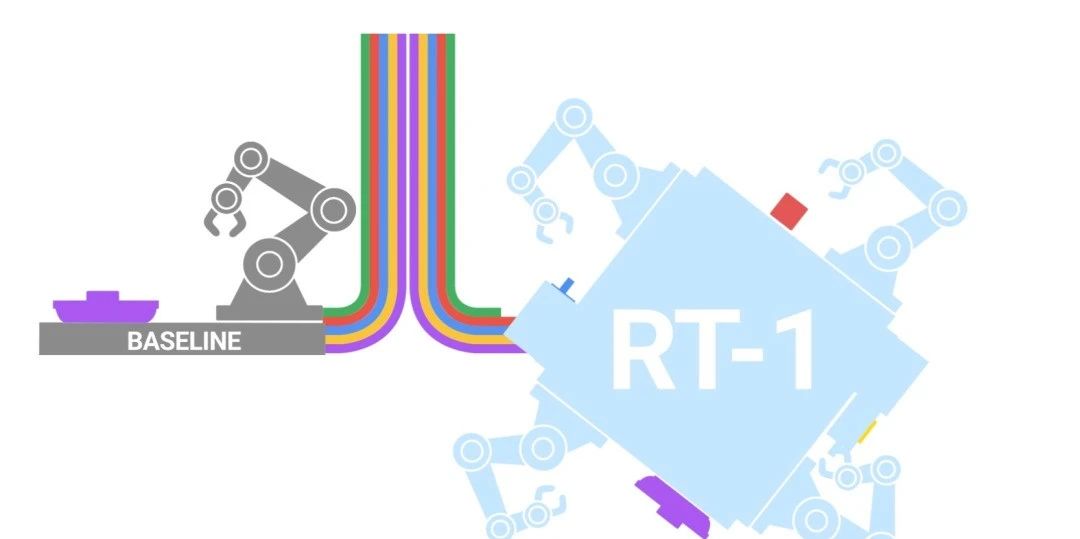
接下來的核心還是數(shù)據(jù)!現(xiàn)實(shí)場(chǎng)景最大的問題就是數(shù)據(jù)。那么,如果前面基于視頻的多模態(tài)學(xué)習(xí)能很好實(shí)現(xiàn),那么人型機(jī)器人就非常好辦,看無數(shù)的視頻,然后映射到人形機(jī)器人的動(dòng)作上。再通過仿真環(huán)境做強(qiáng)化學(xué)習(xí)來解決corner case,從而人型機(jī)器人將能實(shí)現(xiàn)大的突破,走入家庭在10年內(nèi)不是夢(mèng)!
6、自然語言成為新的編程語言

如果你Prompt足夠多,一定也會(huì)有Andrej Karpathy一樣的想法!所以,現(xiàn)在的小孩學(xué)編程可能意義不大,未來大部分人將直接通過自然語言編程和AI交互。
7、AI for Science將突飛猛進(jìn),越來越多科學(xué)領(lǐng)域被AI突破
剛看到微軟發(fā)布的ClimaX,天氣預(yù)測(cè)也是大模型加持。還有什么是大模型不能做的呢?
是否存在足夠通用處理器完成AGI
一、AGI特征
1、涌現(xiàn)
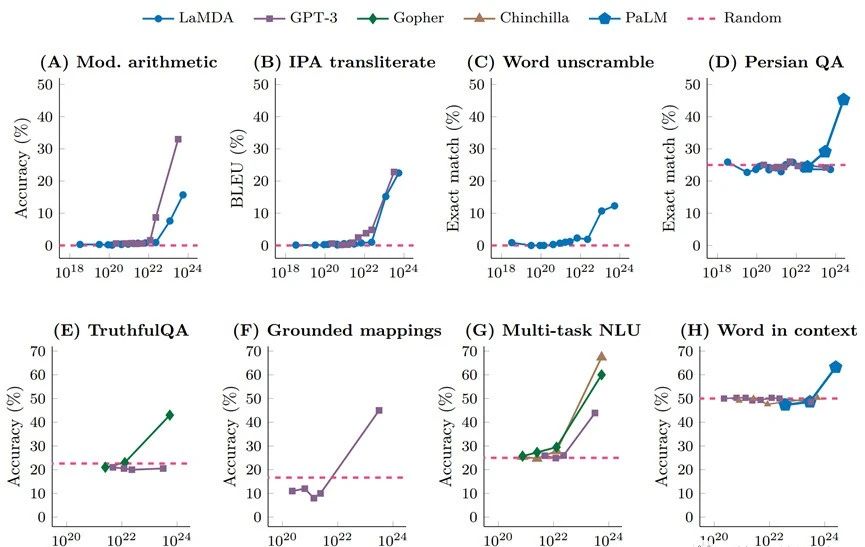
“涌現(xiàn)”并不是一個(gè)新概念,凱文·凱利在他的《失控》中就提到了這一概念,指的是眾多個(gè)體的集合會(huì)涌現(xiàn)出超越個(gè)體特征的某些更高級(jí)的特征。在大模型領(lǐng)域,“涌現(xiàn)”指的是當(dāng)模型參數(shù)突破某個(gè)規(guī)模時(shí),性能顯著提升,并且表現(xiàn)出讓人驚艷的、意想不到的能力,比如語言理解能力、生成能力、邏輯推理能力等等。
對(duì)于外行來說,涌現(xiàn)能力可以簡(jiǎn)單地用“量變引起質(zhì)變”來解釋:隨著模型參數(shù)的不斷增加,終于突破了某個(gè)臨界值,從而引起了質(zhì)的變化,讓大模型產(chǎn)生了許多更加強(qiáng)大的、新的能力。如果想詳細(xì)了解大模型“涌現(xiàn)”能力的詳細(xì)分析,可以參閱谷歌的論文《Emergent Abilities of Large Language Models》。然而,目前,大模型發(fā)展還是非常新的領(lǐng)域,對(duì)“涌現(xiàn)”能力的看法也存在不同的聲音。例如,斯坦福大學(xué)的研究者對(duì)大語言模型“涌現(xiàn)”能力的說法提出了質(zhì)疑,認(rèn)為其是人為選擇度量方式的結(jié)果。
2、多模態(tài)
每一種信息的來源或者形式,都可以稱為一種模態(tài)。例如,人有觸覺、聽覺、視覺等;信息的媒介有文字、圖像、語音、視頻等;各種類型的傳感器,如攝像頭、雷達(dá)、激光雷達(dá)等。多模態(tài)指從多個(gè)模態(tài)表達(dá)或感知事物。多模態(tài)機(jī)器學(xué)習(xí)指從多種模態(tài)的數(shù)據(jù)中學(xué)習(xí)并提升自身的算法。
傳統(tǒng)的中小規(guī)模AI模型基本都是單模態(tài)的,例如專門研究語言識(shí)別、視頻分析、圖形識(shí)別以及文本分析等單個(gè)模態(tài)的算法模型。隨著基于Transformer的ChatGPT的出現(xiàn),之后的AI大模型逐漸實(shí)現(xiàn)了對(duì)多模態(tài)的支持。這些模型可以通過文本、圖像、語音、視頻等多模態(tài)的數(shù)據(jù)進(jìn)行學(xué)習(xí),并且基于其中一個(gè)模態(tài)學(xué)習(xí)到的能力,可以應(yīng)用在另一個(gè)模態(tài)的推理。
此外,不同模態(tài)數(shù)據(jù)學(xué)習(xí)到的能力還會(huì)融合,形成一些超出單個(gè)模態(tài)學(xué)習(xí)能力的新的能力。多模態(tài)的劃分是人為進(jìn)行的,多種模態(tài)的數(shù)據(jù)里包含的信息都可以被AGI統(tǒng)一理解,并轉(zhuǎn)換成模型的能力。在中小模型中,人為割裂了很多信息,從而限制了AI算法的智能能力。此外,模型的參數(shù)規(guī)模和模型架構(gòu)也對(duì)智能能力有很大影響。
3、通用性
自2012年深度學(xué)習(xí)進(jìn)入我們的視野以來,各種特定應(yīng)用場(chǎng)景的AI模型如雨后春筍般涌現(xiàn)。這些模型包括車牌識(shí)別、人臉識(shí)別、語音識(shí)別等,以及一些綜合性場(chǎng)景,例如自動(dòng)駕駛、元宇宙等。每個(gè)場(chǎng)景都有不同的模型,并且同一個(gè)場(chǎng)景中,不同公司開發(fā)的算法和架構(gòu)也各不相同。因此,這一時(shí)期的AI模型極度碎片化。
然而,從GPT開始,我們看到了通用AI的曙光。最理想的AI模型應(yīng)該是可以接受任何形式、任何場(chǎng)景的訓(xùn)練數(shù)據(jù),可以學(xué)習(xí)到幾乎所有的能力,并且可以做出任何需要做出的決策。最關(guān)鍵的是,基于大模型的AGI的智能能力遠(yuǎn)高于傳統(tǒng)的用于特定場(chǎng)合的AI中小模型。完全通用的AI出現(xiàn)后,我們可以將其推廣到各種場(chǎng)景中,實(shí)現(xiàn)AGI+各種場(chǎng)景的應(yīng)用。同時(shí),由于算法逐漸確定,AI加速持續(xù)優(yōu)化的空間也得到了擴(kuò)大,從而可以不斷提升AI算力。算力的提升又會(huì)推動(dòng)模型向更大規(guī)模參數(shù)的演進(jìn)和升級(jí)。
二、通用處理器的可行性有多少?
隨著摩爾定律失效,CPU已經(jīng)難以勝任大量計(jì)算任務(wù),因此開始了一輪專用芯片設(shè)計(jì)的大潮。然而,以DSA為代表的專用芯片并沒有像預(yù)期的那樣成功,反而在AI大模型的加持下,成就了通用GPU的黃金年代。
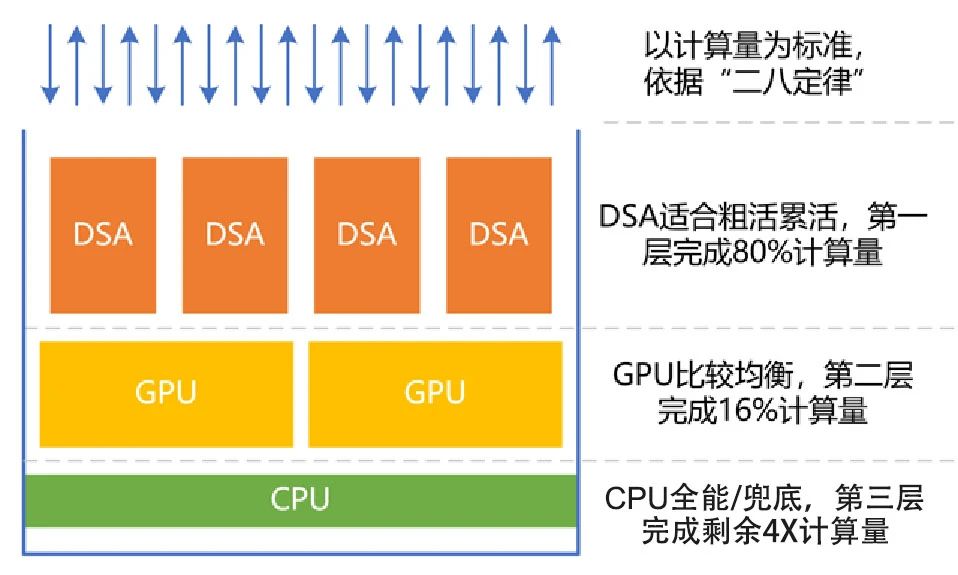
然而,GPU的性能也即將到達(dá)上限,支持GPT大模型的GPU集群需要成千上萬顆GPU處理器,效率低下,建設(shè)和運(yùn)行成本高昂。因此,是否可以設(shè)計(jì)更加優(yōu)化的處理器,即具備通用處理器的特征,同時(shí)能夠?qū)崿F(xiàn)更高效率和性能呢?我們可以將計(jì)算機(jī)上運(yùn)行的系統(tǒng)拆分為若干個(gè)工作任務(wù),并且二八定律表明,很多工作任務(wù)是相對(duì)確定的,例如虛擬化、網(wǎng)絡(luò)、存儲(chǔ)、安全、數(shù)據(jù)庫、文件系統(tǒng)和人工智能推理等。
即使應(yīng)用層的計(jì)算任務(wù)比較隨機(jī),仍然包含大量確定性的計(jì)算成分,例如安全、視頻圖形處理和人工智能等。因此,我們可以將處理器按照性能效率和靈活性能力分為三個(gè)類型:CPU、GPU和DSA。
根據(jù)二八定律,將80%的計(jì)算任務(wù)交給DSA完成,將16%的工作任務(wù)交給GPU完成,而CPU則負(fù)責(zé)剩余4%的其他工作。CPU的重要工作是兜底。根據(jù)性能/靈活性的特征,匹配最合適的處理器計(jì)算引擎,可以在實(shí)現(xiàn)足夠通用的情況下,實(shí)現(xiàn)最極致的性能。
三、通用處理器的歷史和發(fā)展
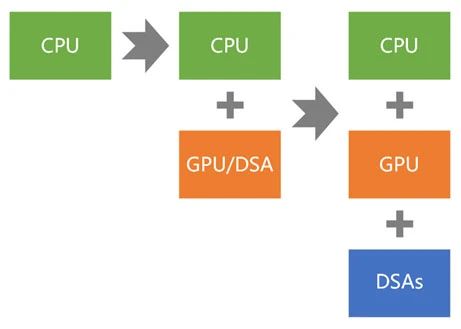
通用計(jì)算的演進(jìn)可以簡(jiǎn)單地分為三個(gè)階段。第一代通用計(jì)算采用CPU同構(gòu)架構(gòu)。第二代通用計(jì)算則采用CPU+GPU異構(gòu)架構(gòu)。第三代通用計(jì)算(即新一代)則采用CPU+GPU+DSAs的超異構(gòu)架構(gòu)。
1、CPU同構(gòu)

Intel是CPU的發(fā)明者,也是第一代通用計(jì)算的代表。在近30年的時(shí)間里,CPU成就了Intel在2000年前后的霸主地位。然而,CPU的標(biāo)量計(jì)算性能相對(duì)較弱,因此逐漸引入了向量指令集處理的AVX協(xié)處理器和矩陣指令集的AMX協(xié)處理器等復(fù)雜指令集,以不斷優(yōu)化CPU的性能和計(jì)算效率,拓展其生存空間。
2、CPU+GPU異構(gòu)
雖然CPU協(xié)處理器可以在一些相對(duì)較小規(guī)模的加速計(jì)算場(chǎng)景中勉強(qiáng)使用,但其性能存在上限,并且不適合于大規(guī)模加速計(jì)算場(chǎng)景,特別是在AI等領(lǐng)域。因此,需要完全獨(dú)立的、更加重量的加速處理器。
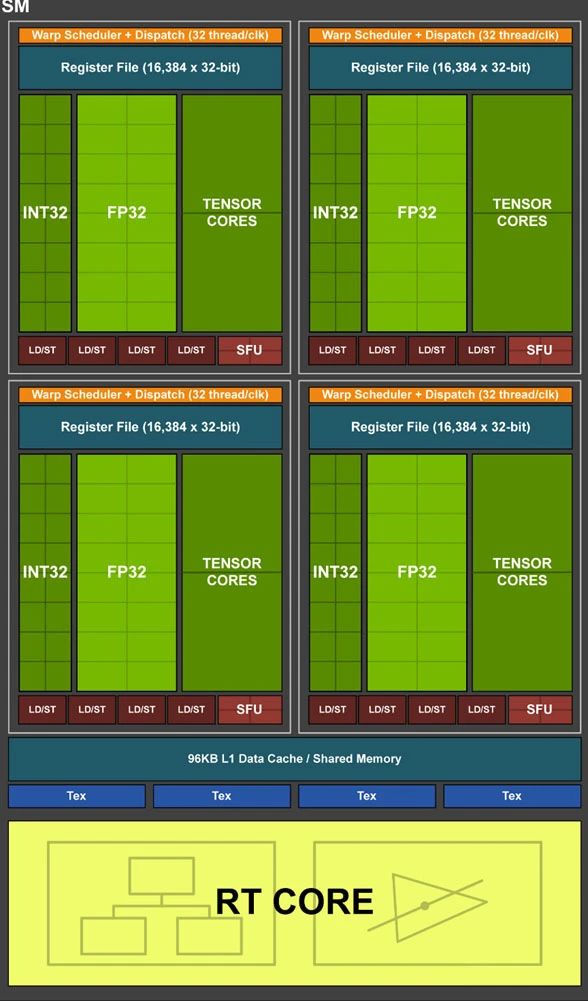
GPU是通用并行計(jì)算平臺(tái),是最典型的加速處理器。GPU計(jì)算需要有Host CPU來控制和協(xié)同,因此具體的實(shí)現(xiàn)形態(tài)是CPU+GPU的異構(gòu)計(jì)算架構(gòu)。NVIDIA發(fā)明了GP-GPU,并提供了CUDA框架,促進(jìn)了第二代通用計(jì)算的廣泛應(yīng)用。隨著AI深度學(xué)習(xí)和大模型的發(fā)展,GPU成為最炙手可熱的硬件平臺(tái),也成就了NVIDIA萬億市值。GPU內(nèi)部的數(shù)以千計(jì)的CUDA core,本質(zhì)上是更高效的CPU小核,因此,其性能效率仍然存在上升的空間。為了進(jìn)一步優(yōu)化張量計(jì)算的性能和效率,NVIDIA開發(fā)了Tensor加速核心。
3、CPU+GPU+DSAs超異構(gòu)
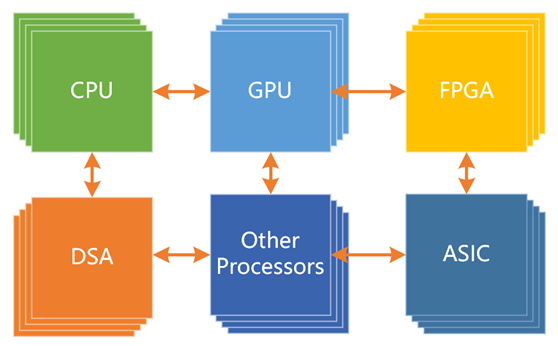
技術(shù)發(fā)展永無止境,第三代通用計(jì)算面向未來更大算力需求場(chǎng)景的挑戰(zhàn),采用多種異構(gòu)融合的超異構(gòu)計(jì)算。其中,有三個(gè)層次的獨(dú)立處理引擎,即CPU、GPU和DSA,組成CPU+XPU的異構(gòu)計(jì)算架構(gòu)。超異構(gòu)計(jì)算不是簡(jiǎn)單的多種異構(gòu)計(jì)算的集成,而是多種異構(gòu)計(jì)算系統(tǒng)在軟件到硬件層次上的深度融合。超異構(gòu)計(jì)算的成功必須要實(shí)現(xiàn)足夠好的通用性。如果不考慮通用性,超異構(gòu)架構(gòu)里的計(jì)算引擎會(huì)使得架構(gòu)碎片化問題更加嚴(yán)重,軟件人員將無所適從。
藍(lán)海大腦的高性能超算異構(gòu)平臺(tái)支持多種硬件加速器,包括CPU、GPU、FPGA和AI等,能夠滿足大規(guī)模數(shù)據(jù)處理和復(fù)雜計(jì)算任務(wù)的需求。采用分布式計(jì)算架構(gòu),高效地處理大規(guī)模數(shù)據(jù)和復(fù)雜計(jì)算任務(wù),為AGI算法的研究和開發(fā)提供強(qiáng)大的算力支持。具有高度的靈活性和可擴(kuò)展性,能夠根據(jù)不同的應(yīng)用場(chǎng)景和需求進(jìn)行定制化配置。可以快速部署和管理各種計(jì)算任務(wù),提高了計(jì)算資源的利用率和效率。為人工智能技術(shù)的發(fā)展和應(yīng)用提供強(qiáng)有力的支持。
審核編輯黃宇
-
人工智能
+關(guān)注
關(guān)注
1791文章
47205瀏覽量
238272 -
Agi
+關(guān)注
關(guān)注
0文章
80瀏覽量
10204 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113 -
大模型
+關(guān)注
關(guān)注
2文章
2425瀏覽量
2646
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
大模型應(yīng)用之路:從提示詞到通用人工智能(AGI)
報(bào)名開啟!深圳(國際)通用人工智能大會(huì)將啟幕,國內(nèi)外大咖齊聚話AI
【免費(fèi)名額30個(gè)】手把手教你快速學(xué)習(xí)和應(yīng)用人工智能技術(shù)
深度學(xué)習(xí)推理和計(jì)算-通用AI核心
人工智能基本概念機(jī)器學(xué)習(xí)算法
介紹的是高性能MCU之人工智能物聯(lián)網(wǎng)應(yīng)用開發(fā)相關(guān)知識(shí)
什么是人工智能、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)和自然語言處理?
《移動(dòng)終端人工智能技術(shù)與應(yīng)用開發(fā)》+理論學(xué)習(xí)
【書籍評(píng)測(cè)活動(dòng)NO.16】 通用人工智能:初心與未來
《通用人工智能:初心與未來》-試讀報(bào)告
什么是人類智能 楊學(xué)山淺談通用人工智能的發(fā)展途徑
聆心智能上榜“北京市通用人工智能大模型行業(yè)應(yīng)用典型場(chǎng)景案例”
軟通動(dòng)力入選“北京市通用人工智能產(chǎn)業(yè)創(chuàng)新伙伴計(jì)劃(第三批)”






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論