 研發為底、生態為徑、AI為翼——全國一體化算力算網調度平臺正式發布
研發為底、生態為徑、AI為翼——全國一體化算力算網調度平臺正式發布

英偉達 | GH200| 一體化算力算網調度平臺
近年來,人工智能硬件、軟件算法以及應用場景的豐富度不斷增加,算法模型參數也不斷增加,這帶動了對數據中心并行計算算力的需求。因此,AI、高性能計算、圖形渲染、大模型訓練、AIGC、ChatGPT等推動GPU大算力并行計算芯片的需求。
2023年6月5日,由工業和信息化部主辦,中國信息通信研究院(以下簡稱“中國信通院”)等承辦的“算力創新發展高峰論壇”在京順利召開。工業和信息化部信息通信發展司副司長趙策,中國信通院副院長王志勤等領導出席會議并致辭。會上,中國信通院聯合中國電信共同發布我國首個實現多元異構算力調度的全國性平臺——“全國一體化算力算網調度平臺(1.0版)”
該平臺匯聚通用算力、智能算力、高性能算力、邊緣算力等多元算力資源,針對通用、智算、超算等不同客戶的不同需求,設計異構資源池調度引擎,實現不同廠商的異構資源池的算力動態感知與作業智能分發調度。特別在AI訓練作業調度流程中,作業可在智算資源池上進行訓練推理,在通用算力資源池部署,從而實現跨資源池/跨架構/跨廠商的異構算力資源調度,目前已接入天翼云、華為云、阿里云等。
算力是 AI 芯片底層土壤,未來算力需求將呈爆發式增長。根據 IDC 數據,未來 5 年我國智能算力規模 CAGR 將達 52.3%。AI 芯片中,GPU 占據主要市場規模。根據 IDC 數據,2022 年國內人工智能芯片市場中,GPU 芯片所占市場份額達 89.0%。
研發實力是一家芯片設計公司的核心競爭力,英偉達從發展初期就重視研發生產力,以高投入換取高回報不斷提升產品競爭力。2005 年,AMD 的研發費用為 11 億美元,是英偉達的 3.2 倍左右。而到了 2022 年,英偉達的研發費用達到 73.4 億美元,是 AMD 的 1.47 倍。
國產廠商加速布局,看好 AI 發展推動國產替代進程提速。在 ChatGPT 等概念影響下, AIGC 關注度火熱。未來 AI 應用的落地離不開龐大算力的支撐,也將推動算力產業鏈快速增長。據 IDC數據顯示,2021 年中國 AI 投資規模超 100 億美元,2026 年將有望達到 267 億美元,全球占比約 8.9%,排名第二,其中 AI 底層硬件市場占比將超過 AI 總投資規模的半數。
AI、高性能計算、圖形渲染推動GPU芯片需求
隨著人工智能、高性能計算、大規模圖形渲染等應用場景的不斷拓展和豐富,市場對大算力并行計算芯片的需求快速增長。截止目前,全球數據中心領域邏輯芯片市場規模已經超過400億美元。同時,近期市場對國產GPU領域的關注度提升。基于英偉達的歷史復盤,可以看出英偉達在圖形渲染和數據中心領域保持較高的市場占有率,并實現產業引領。
一、AI 訓練推理、復雜科學計算、大規模圖形渲染等,持續推動并行計算芯片需求
由于GPU(圖形處理器)是由成百上千個陣列排布的運算單元ALU組成,使得GPU更適用于大規模并發運算,其在圖形處理、計算加速等領域有著廣泛的運用。由于GPU加速器強大的并行處理能力,超算中心工作人員可以更好地設計深度網絡結構,使得其在超算領域和數據中心領域更具經濟效益,導致GPU在AI訓練和推理、科學計算等領域有著廣泛的應用。
在典型AI模型卷積網絡中,大量數據以圖片形式導入,在進行運算過程中,數據均為矩陣形式,而矩陣運算通常適合并行,因此AI算法的特性,使得GPU的運算速度明顯大于CPU。科學計算將物理、化學、生物、航空航天等領域的問題轉化為數學模型,通過計算和求解模型用于實際產業。從計算數據來看,由于科學計算中所用數據多數以矩陣為形式,同時由于科學計算對誤差有強制要求,因此在運算中需要在并行運算基礎上保證一定的精度。
而現代GPU在并行和矩陣運算的基礎上,已經能夠滿足科學計算所需的精度要求。近些年來,隨著人工智能軟件算法的發展,復雜科學計算的進步,以及圖形渲染功能的增加,帶動底層芯片并行計算能力需求的快速提升。以全球AI芯片領軍者英偉達的發展狀況來看,公司AI芯片算力由2012年的4Tops提升至2021年的1248Tops,9年時間提升了約315倍。
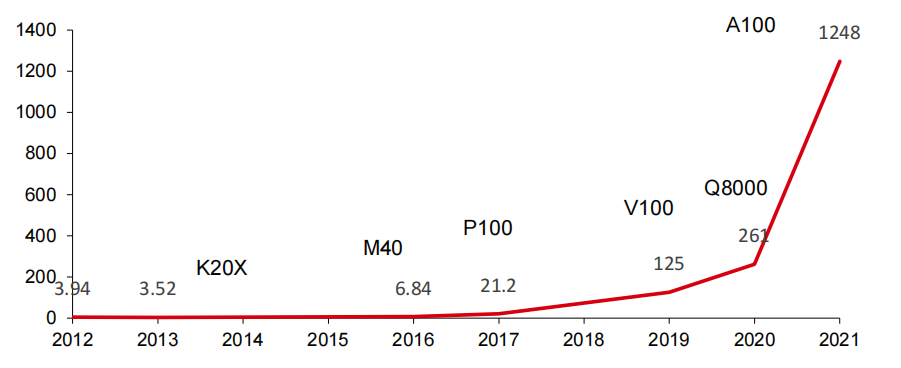
英偉達單芯片推理性能(Int8 Tops)
二、AI 框架、并行計算框架等引入豐富,不斷推動針對并行計算芯片軟件開發門檻降低
隨著AI框架和并行計算框架的引入和豐富,針對并行計算芯片軟件開發門檻不斷降低。從人工智能軟件算法框架的發展歷史來看,2015年谷歌宣布開源TensorFlow,2019年PFN宣布將研究方向由Chainer轉向PyTorch。
目前,AI框架形成了TensorFlow和PyTorch雙寡頭壟斷的競爭格局。其中,谷歌開源TensorFlow項目,在很大程度上降低了人工智能的開發門檻和難度。TensorFlow主要用于處理機器學習中的計算機視覺、推薦系統和自然語言處理(NLP)的模型訓練和推理,涉及模型隱藏層相對較多,模型量相對較大,基本上均需要CUDA的加速處理。隨著TensorFlow的開源,涉及到的開發者快速增加,CUDA軟件下載量也呈現陡增趨勢。據英偉達在2021GTC大會上宣布,截至2020年底,CUDA累計下載量超過2000萬次,其中2020年下載量超過600萬次。涉及到的開發人員約230萬人(2020年新增超過60萬人)。
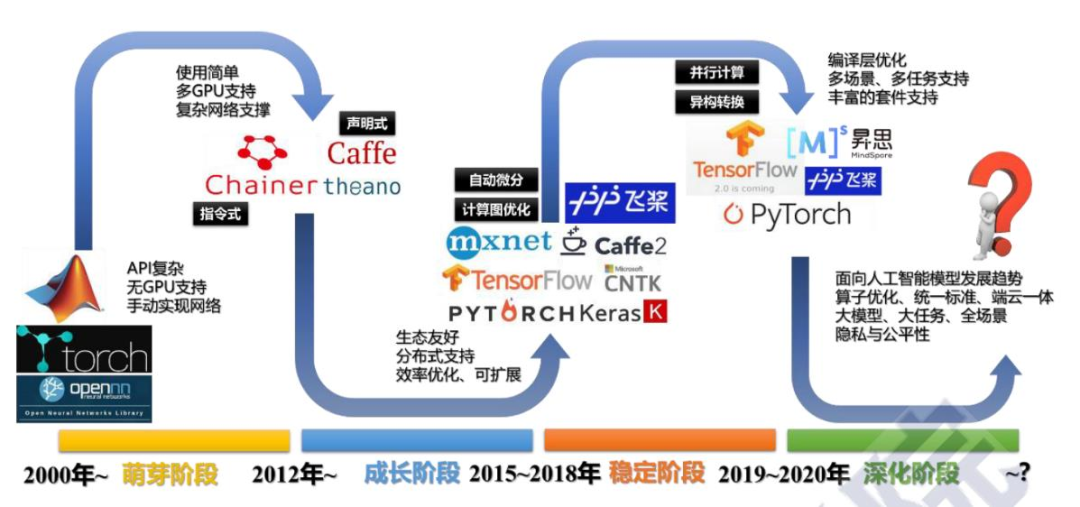
人工智能框架發展史
三、算法豐富、算法復雜度提升等,亦成為市場需求的重要驅動力
近年來,隨著人工智能芯片的不斷發展,算法的豐富和復雜度的提升成為市場需求的重要驅動力。從Alexnet、ResNet到BERT網絡模型,參數量已經超過了3億規模,而GPT-3模型更是超過了百億規模,Switch Transformer的問世更是一舉突破了萬億規模。此外,英偉達在2020年發布的Megatron-LM模型,參數量達到了83億,相比2018年震驚世界的BERT模型又提升了5倍。這種模型體積幾何倍數的增長也帶來了更多數據中心側的需求,只有依靠上千塊GPU并行運算才能在以天為單位的訓練時長中完成對Transformer模型的訓練。
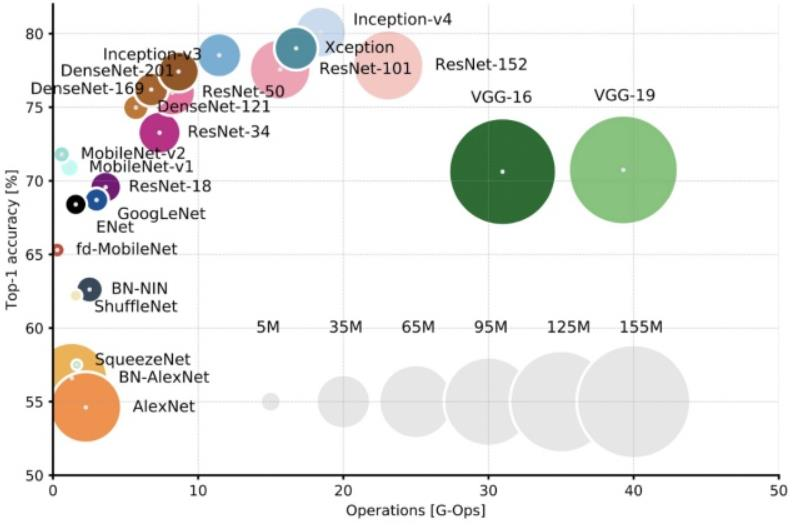
深度學習初期模型越來越大
英偉達布局算力的成功之道
目前,全球GPU市場競爭格局主要由英偉達、AMD、英特爾等幾家巨頭廠商主導。英偉達是GPU市場的領導者,其市場份額在游戲領域高達80%以上,數據中心和人工智能領域也占據著重要地位。AMD是英偉達的主要競爭對手,其市場份額在游戲領域約為20%。英特爾則主要競爭于集成顯卡和移動設備領域。這里以英偉達為例為大家展開詳細介紹。
GPU 逐步成為全球大算力并行計算領域的主導者,這得益于 GPU 本身的優異特性以及英偉達等企業在芯片架構、軟件生態等層面的不斷努力,疊加 AI、高性能計算、大規模圖形渲染等應用場景的快速崛起。在產品端,GPU 廠商亦結合下游的應用場景,在一個大的體系結構下,針對計算單元、緩存、總線帶寬等技術點的優化和組合。目前最主流的應用場景產品是用于游戲等場景中圖形渲染的顯卡,以及用于數據中心 AI、高性能計算等場景的 GPGPU(通用計算 GPU)。
英偉達逐漸發展成為一家全球領先的高性能計算、AI 和游戲平臺解決方案提供商。基于處理器、互連、軟件、算法、系統和服務構建而成的計算平臺,英偉達形成了數據中心、游戲、專業可視化、汽車四大類業務。
其中,數據中心業務主要指 NVIDIA 計算平臺,覆蓋超大規模、云、企業、公共部門和邊緣數據中心,聚焦于加速最具計算密集型的工作負載(如人工智能、數據分析、圖形和科學計算等)。游戲業務利用 GPU 和復雜的軟件來增強游戲體驗,使圖形更加流暢、高質量。專業可視化業務主要通過 GPU 計算平臺提高視覺設計領域的生產效率,主要包括設計和制造(包括計算機輔助設計、建筑設計、消費品制造、醫療儀器和航空航天)以及數字內容創作(包括專業視頻編輯和后期制作、電影特效以及廣播電視圖形)兩大應用場景。汽車業務主要包括自動駕駛、AI 駕駛艙、電動車計算平臺和信息娛樂平臺解決方案。公司推出的 DRIVE Hyperion 是一個完整的自動駕駛市場端到端解決方案,包含高性能、能效高的 DRIVE AGX 計算硬件、支持全自動駕駛能力的參考傳感器組以及開放的模塊化 DRIVE 軟件平臺,可在車輛內運行完整的感知、融合、規劃和控制堆棧。
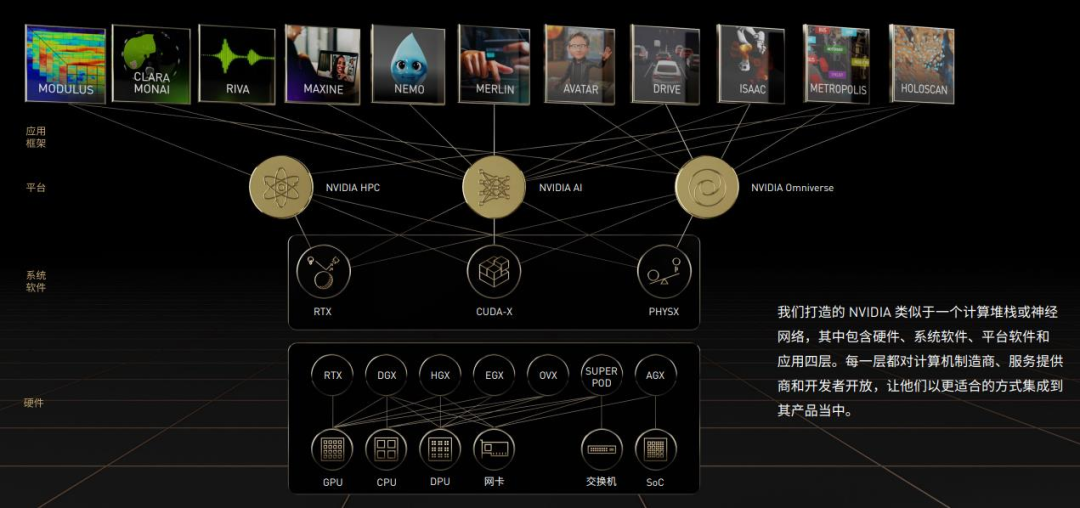
英偉達業務架構
一、快速崛起的數據中心業務
英偉達數據中心業務的核心是 NVIDIA 加速計算平臺,該平臺的建立始于 2006 年通用并行計算架構 CUDA 以及 2007 年 Tesla GPU 的推出。CUDA 提供并行計算平臺和編程模型,使得 GPU 的并行計算能力能夠被應用于商業、工業以及科學方面的復雜計算問題,加速計算任務的執行速度。
Tesla GPU 是專門為科學計算、工程計算、數據分析等計算密集型應用設計的高性能計算 CPU,通過與 CUDA 能力的結合,可被廣泛應用于藥物研發、醫學成像和天氣建模等領域,并在后續年份持續為全球超算中心提供基于 GPU 的算力支撐。受到多方面因素共同推動,英偉達數據中心業務快速增長,在整體收入中的占比持續提升,并于 2023 財年(對應 2022 自然年)占比達到 56%。我們認為英偉達數據中心業務崛起受到的推動因素有:深度學習開啟新一輪 AI 技術蓬勃發展;數據量增加激發大規模數據處理和分析的需求;復雜計算任務需求增加;云計算技術的發展提升算力使用的便捷性。
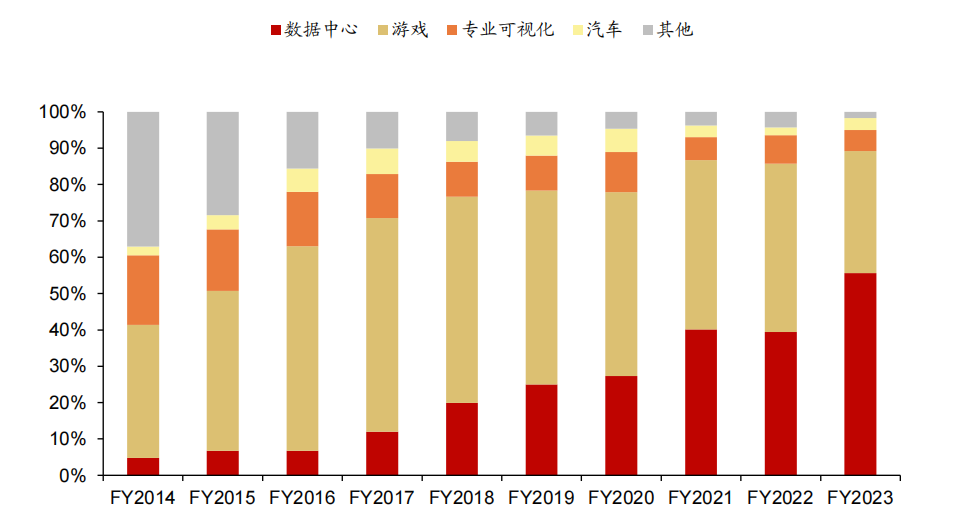
英偉達 2014-2023 財年收入結構拆分
英偉達在數據業務上的成功,不僅僅依靠于 GPU 的銷售和使用。GPU 是 NVIDIA 加速計算平臺的基礎,能夠高效完成以神經網絡訓練和推斷為代表的并行工作負載任務。但是,英偉達數據中心的核心業務壁壘是端到端的硬件+軟件集成方案,構成從實施開發到部署的全鏈路基礎設施支撐。從幾個維度拆解來看:
1、硬件
硬件部分由三個部分組成,包括 GPU(Hopper GPU)、DPU(BlueField DPU)和CPU(Grace CPU)。這些架構涵蓋了性能、安全性和網絡等領域的前沿技術。CPU和DPU可以與GPU架構緊密融合,對網絡、存儲和安全服務進行加速,提供高性能、高能效和高可靠性的加速計算解決方案。
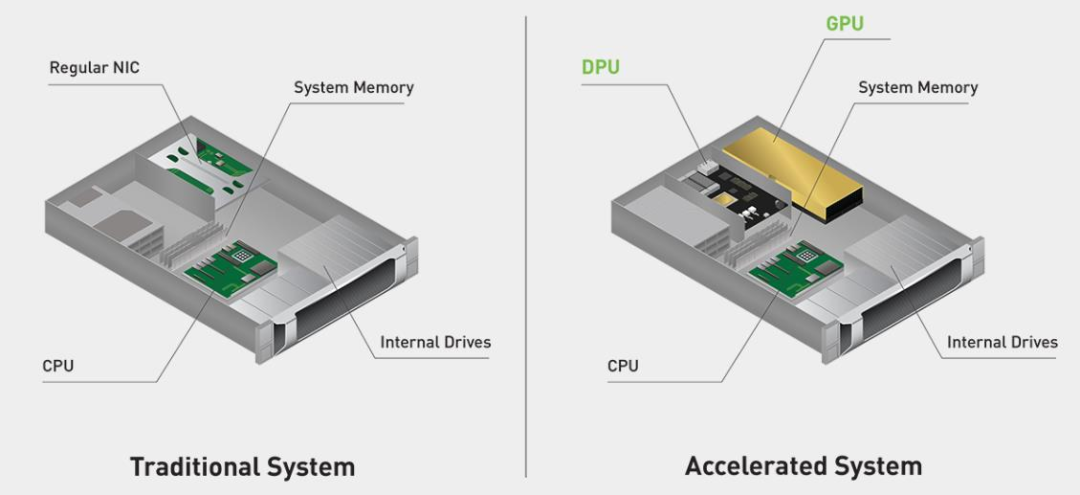
英偉達加速系統與傳統加速系統對比
2、軟件
擁有龐大的軟件體系,包括CUDA并行編程模型、CUDA-X應用加速庫集合、應用程序接口(API)、軟件開發工具包(SDK)和工具,以及特定領域的應用框架。這些框架包括對話式AI框架NVIDIA Riva、推薦系統框架NVIDIA Merlin、計算機視覺NVIDIA Metropolis等。這些軟件工具和框架可以幫助用戶更高效地利用英偉達的加速計算平臺,提升數據處理和分析的能力。
3、場景
適用于多種工作負載需求,包括分析、訓練、推理、高性能計算、渲染和虛擬化等領域。這一平臺的多樣性和靈活性,可以為用戶提供更加全面和高效的數據處理和分析能力。
4、NGC
NVIDIA GPU Cloud(NGC)提供一系列完全托管的云服務,將硬件、軟件以及不同場景的工作負載需求進行融合,是數據中心業務的理想終極形態。NGC的服務包括用于NLU和語音AI解決方案的NeMo LLM、BioNemo和Riva Studio。AI從業者可以利用NVIDIA Base Command進行模型訓練,利用NVIDIA Fleet Command進行模型管理,并利用NGC專用注冊表安全共享專有AI軟件。此外,NGC還擁有一個GPU優化的AI軟件、SDK和Jupyter Notebook的目錄,可幫助加速AI工作流,并通過NVIDIA AI Enterprise提供支持。
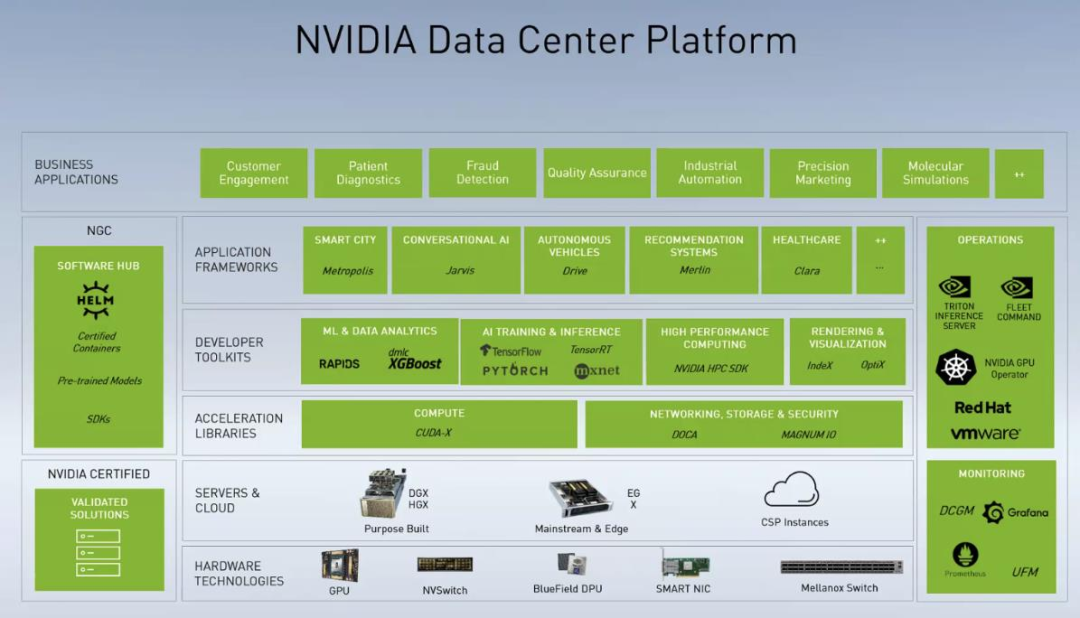
英偉達數據中心業務版圖
二、NVIDIA DGX GH200
DGX計算機系列采用英偉達自主研發的GPU加速技術,配備高性能的CPU、GPU、內存和存儲系統,能夠快速處理大規模的數據和復雜的深度學習算法。此外,DGX計算機還配備了英偉達的深度學習軟件堆棧,包括CUDA、cuDNN和TensorRT等,可幫助用戶更輕松地構建、訓練和部署深度學習模型。
GH200是英偉達在 COMPUTEX 2023展會上推出的最新超級計算機,最多可以放置256個GPU,適用于超大型AI模型的部署。相比之前的DGX服務器,GH200提供線性拓展方式和更高的GPU共享內存編程模型,可通過NVLink高速訪問144TB內存,是上一代DGX的500倍。其架構提供的NVLink帶寬是上一代的48倍,使得千億或萬億參數以上的大模型能夠在一臺DGX內放置,進一步提高模型效率和多模態模型的開發進程。

GPU的統一內存編程模型一直是復雜加速計算應用取得突破的基石。NVIDIA Grace Hopper Superchip與NVLink開關系統配對,在NVIDIA DGX GH200系統中整合了256個GPU,通過NVLink高速訪問144TB內存。與單個NVIDIA DGX A100 320 GB系統相比,NVIDIA DGX GH200為GPU共享內存編程模型提供了近500倍的內存,是突破GPU通過NVLink訪問內存的100TB障礙的第一臺超級計算機。NVIDIA Base Command的快速部署和簡化系統管理使用戶能夠更快地進行加速計算。
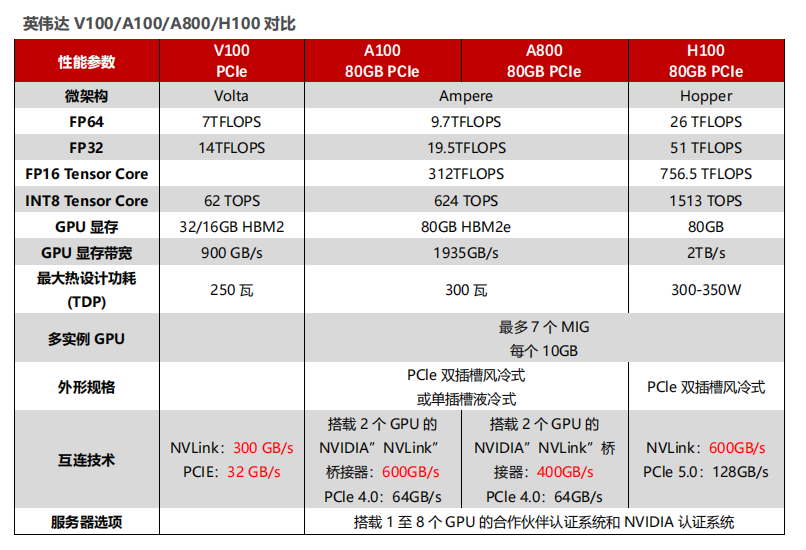
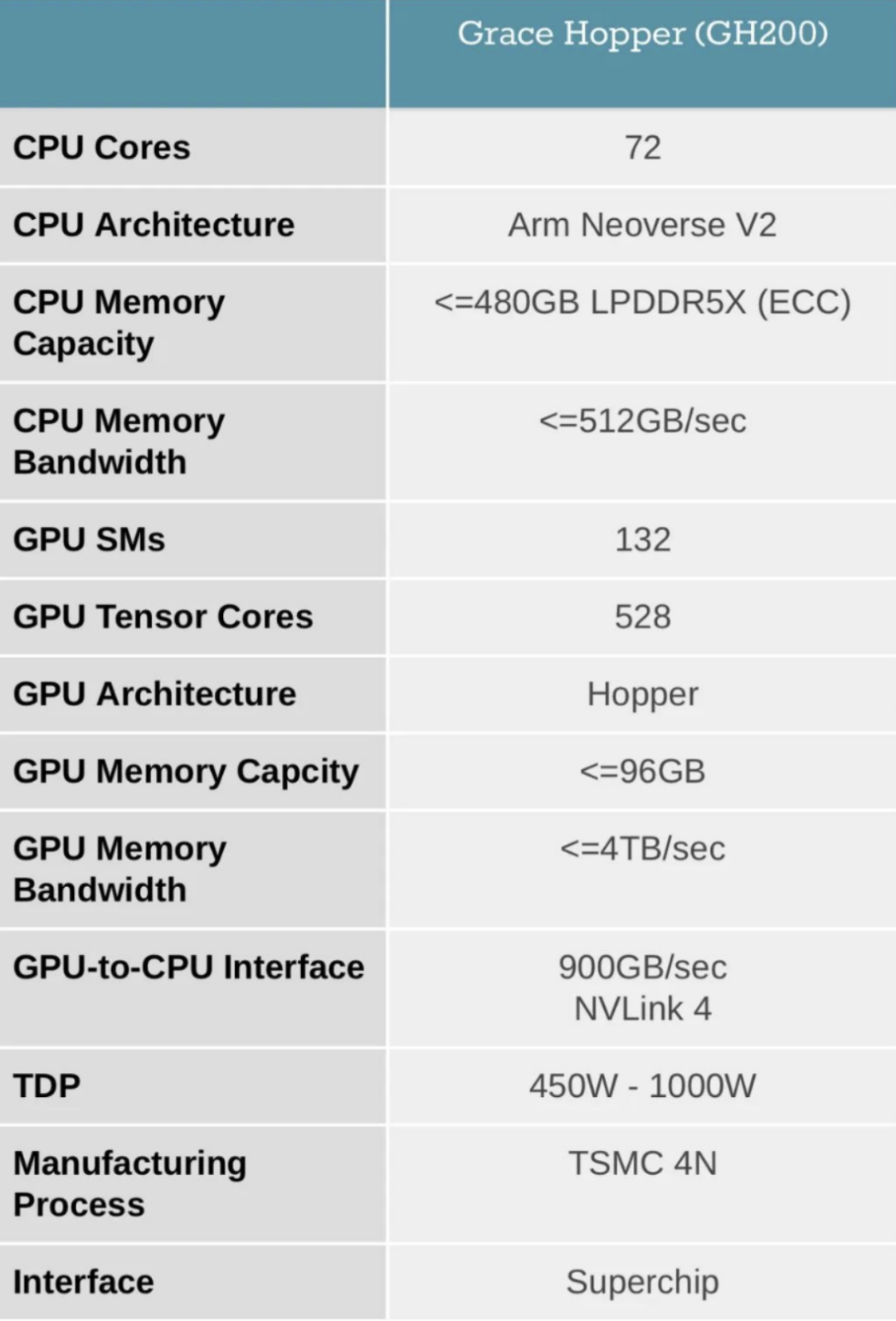
NVIDIA DGX GH200系統采用了NVIDIA Grace Hopper Superchip和NVLink Switch System作為其構建塊。NVIDIA Grace Hopper Superchip將CPU和GPU結合在一起,使用NVIDIA NVLink-C2C技術提供一致性內存模型,并提供高帶寬和無縫的多GPU系統。每個Grace Hopper超級芯片都擁有480GB的LPDDR5 CPU內存和96GB的快速HBM3,提供比PCIe Gen5多7倍的帶寬,與NVLink-C2C互連。
NVLink開關系統使用第四代NVLink技術,將NVLink連接擴展到超級芯片,以創建一個兩級、無阻塞、NVLink結構,可完全連接256個Grace Hopper超級芯片。這種結構提供900GBps的內存訪問速度,托管Grace Hopper Superchips的計算底板使用定制線束連接到第一層NVLink結構,并由LinkX電纜擴展第二層NVLink結構的連接性。
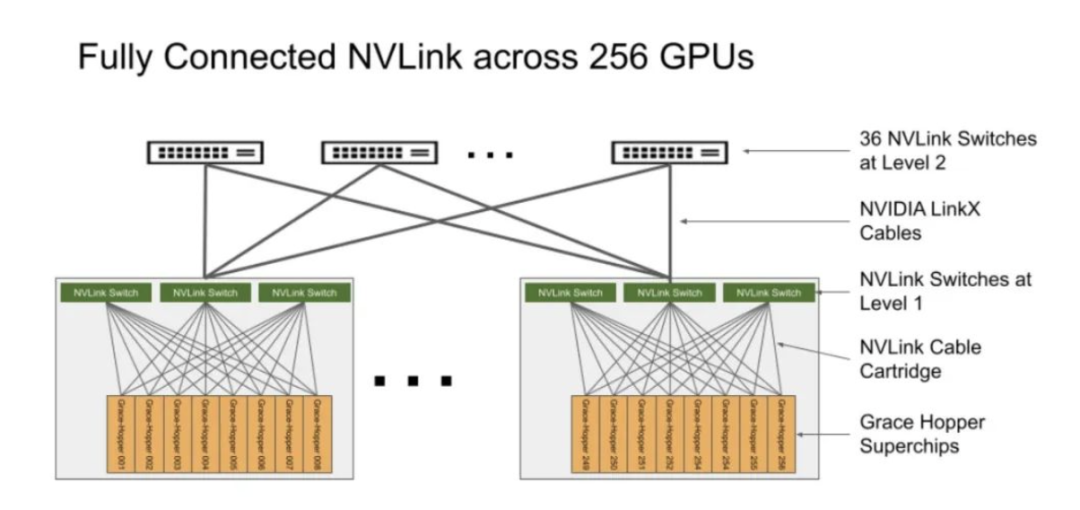
在DGX GH200系統中,GPU線程可以使用NVLink頁表來訪問來自其他Grace Hopper超級芯片的內存,并通過NVIDIA Magnum IO加速庫來優化GPU通信以提高效率。該系統擁有128 TBps的對分帶寬和230.4 TFLOPS的NVIDIA SHARP網內計算,可加速AI常用的集體運算,并將NVLink網絡系統的實際帶寬提高一倍。每個Grace Hopper Superchip都配備一個NVIDIA ConnectX-7網絡適配器和一個NVIDIA BlueField-3 NIC,以擴展到超過256個GPU,可以互連多個DGX GH200系統,并利用BlueField-3 DPU的功能將任何企業計算環境轉變為安全且加速的虛擬私有云。
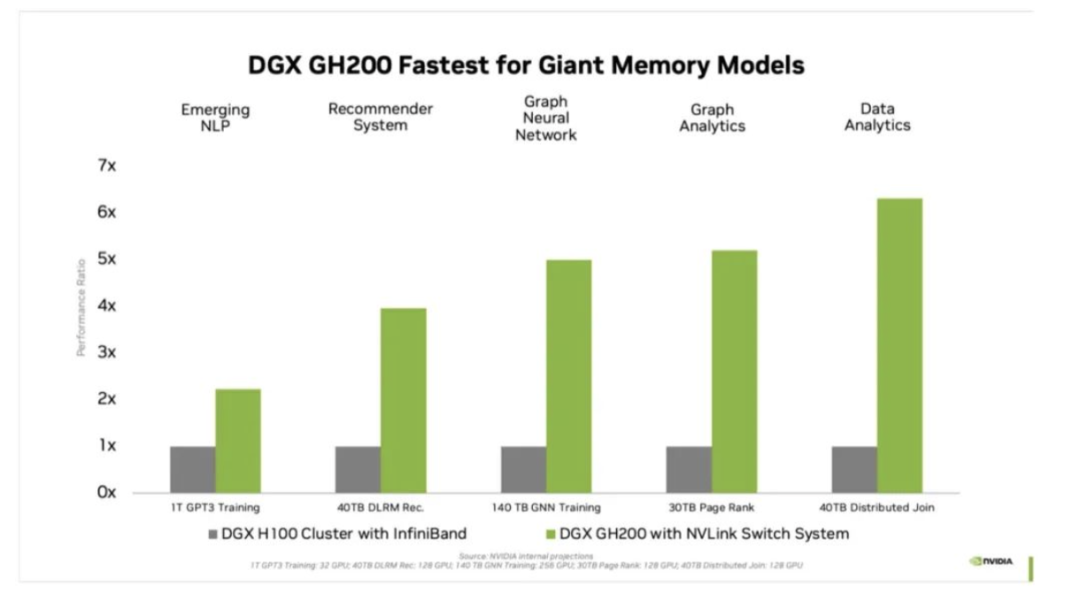
對于受GPU內存大小瓶頸的AI和HPC應用程序,GPU內存的代際飛躍可以顯著提高性能。對于許多主流AI和HPC工作負載,單個NVIDIA DGX H100的聚合GPU內存可以完全支持。對于其他工作負載,例如具有TB級嵌入式表的深度學習推薦模型(DLRM)、TB級圖形神經網絡訓練模型或大型數據分析工作負載,使用DGX GH200可實現4至7倍的加速。這表明DGX GH200是更高級的AI和HPC模型的更好解決方案,這些模型需要海量內存來進行GPU共享內存編程。
DGX GH200是專為最嚴苛的工作負載而設計的系統,每個組件都經過精心挑選,以最大限度地減少瓶頸,同時最大限度地提高關鍵工作負載的網絡性能,并充分利用所有擴展硬件功能。這使得該系統具有高度的線性可擴展性和海量共享內存空間的高利用率。
為了充分利用這個先進的系統,NVIDIA還構建了一個極高速的存儲結構,以峰值容量運行并處理各種數據類型(文本、表格數據、音頻和視頻),并且表現穩定且并行。
DGX GH200附帶NVIDIA Base Command,其中包括針對AI工作負載優化的操作系統、集群管理器、加速計算的庫、存儲和網絡基礎設施,這些都針對DGX GH200系統架構進行了優化。此外,DGX GH200還包括NVIDIA AI Enterprise,提供一套經過優化的軟件和框架,可簡化AI開發和部署。這種全堆棧解決方案使客戶能夠專注于創新,而不必擔心管理其IT基礎架構。
三、大模型時代涌現的算力需求
自ChatGPT發布以來,越來越多的科技公司投入大模型研發,帶動AI服務器出貨量和價格的量價齊升。根據TrendForce,2022年高端GPGPU服務器出貨量有望增長9%左右,2023年人工智能服務器出貨量有望增長15.4%,2023年至2027年人工智能服務器出貨量復合年增長率為12.2%。同時,據IDC在5月17日發布的數據,A100 GPU市場單價已達15萬元,兩個月前為10萬元,漲幅50%;A800價格漲幅相對更小,價格在9.5萬元左右,上月價格為8.9萬元左右。考慮到目前全球GPU產能有限,市場GPU供應持續緊缺,IDC預計未來AI服務器價格仍將保持上漲趨勢。
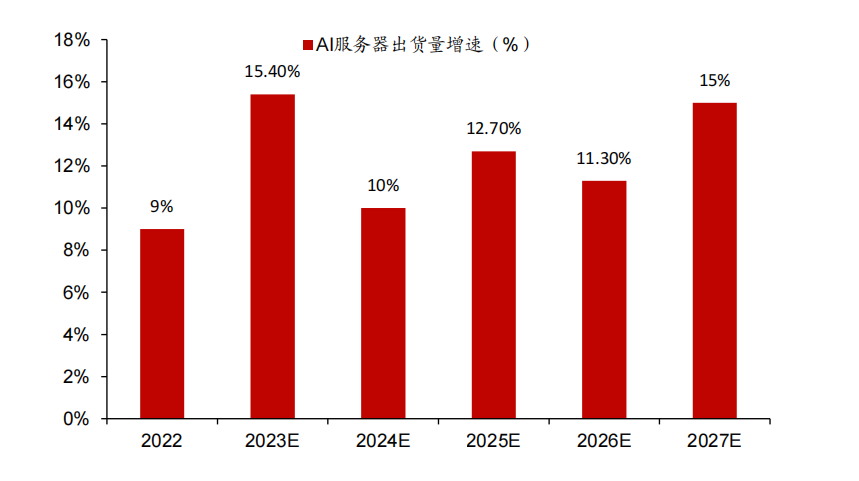
2023-2027 年 AI 服務器出貨量增速預測(截至 2023 年 4 月)
大模型對于算力的需求體現在模型訓練和推理應用兩個階段。模型訓練階段的總計算量取決于模型的規模(參數數量)、訓練數據集的大小、訓練輪次、批次大小,而單一GPU的運算能力以及訓練時間決定了訓練階段對于GPU(或AI服務器)的需求量;推理應用階段的總計算量取決于模型規模(參數數量)、輸入文本長度(問題長度)、輸出文本長度(回復長度)、模型的計算復雜性(取決于模型維度和模型層數),而在同一時間的用戶訪問量以及單一GPU的運算能力決定了推理階段對于GPU(或AI服務器)的需求量。具體而言:
根據OpenAI的論文《Scaling Laws for Neural Language Models》(2020年發表),訓練階段算力需求為3×前向傳遞操作數×模型參數數量×訓練集規模。同時,我們可得到訓練所需GPU數量為總算力需求/(每個GPU每秒運算能力×訓練時間×有效算力比率)。以GPT-3模型為例,GPT-3模型參數量為1750億個,訓練集約為3000億tokens,對應訓練階段總算力需求為:GPT-3總算力需求=6×1.75×1011×3×1011=3.15×1023 FLOPS=3.15×108 PFLOPS。若假設全部采用英偉達A100 GPU進行運算,每張GPU運算能力為624 TFLOPS(即0.624 PFLOPS,對應FP16稀疏運算),訓練時間為20天(1.73×106秒),有效算力比率為30%,對應所需GPU數量為:GPT-3訓練所需A100 GPU數量(20天)=3.15×108 PFLOPS/(0.624 PFLOPS/s×1.73×106 s×30%)=973個GPU=122臺DGX-3。若我們假設訓練20個對標GPT-3參數量和訓練集規模的大模型,則需要近2萬個A100 GPU或2432臺DGX-3。參考IDC最新公布的A100 GPU單價,僅GPU采購對應的市場空間約為29億元;若全部采用DGX-3進行訓練,則對應市場空間可達到48.6億元。
推理階段算力需求同樣根據OpenAI論文,推理階段單次訪問算力需求為2×模型參數數量×訓練及規模。從而我們可以得到推理應用所需GPU數量=訪問量×單次訪問算力需求/(每個GPU每日運算能力×有效算力比率)。同樣以GPT-3模型為例,參考天翼智庫的測算,我們假設每次訪問發生10輪對話,每輪對話產生500個tokens(約350個單詞),則對應單次訪問推理的算力需求為:單次訪問算力需求=2×1.75×1011×500×10=1.75×1015 FLOPS=1.75 PFLOPS。我們同樣假設全部采用英偉達A100 GPU進行運算,參考2023年4月ChatGPT的訪問量17.6億次,對應日均訪問量約0.6億次,則為了支撐每日的訪問量推理所需GPU數量為:GPT-3每日推理所需A100 GPU數量=0.59×108×1.75 PFLOPS/(0.624 PFLOPS/s×8.64×104 s×30%)=6384個GPU=798臺DGX-3。由以上計算結果可知推理階段對于算力的需求遠超訓練階段對于的算力需求。若我們假設每日需應對2億次訪問量,則需要約2.2萬個A100 GPU或2720臺DGX-3。
研究英偉達的快速發展給我國帶來什么借鑒意義
一、深耕GPU算力領域,研發為導向不斷提升產品競爭力
1、采用主流 API,借助微軟推廣產品
NVIDIA公司自創立之初便以市場需求為導向,通過匹配主流API并不斷更新技術,逐漸降低產品價格以滿足消費者需求,從而占領市場。在設計NV2及后續產品時,NVIDIA公司都采用微軟推出的DirectX作為API,得益于微軟Windows系列操作系統在市場上占有大量份額,同時對DirectX和OpenGL進行加速優化,使得NVIDIA公司的產品得到了廣泛的歡迎。
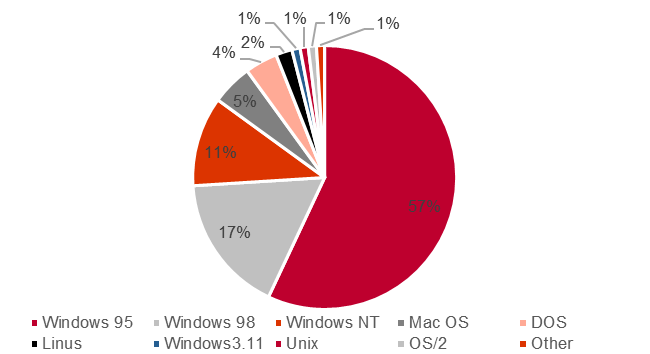
1998 年操作系統占比
2、壓縮開發周期領先市場,為下游廠商提供更好的產品
英偉達公司抓住了從2D到3D的轉型趨勢,通過成熟的研發體系,以快速的速度甩開了2D圖形廠商。該公司圖形業務的快速產品周期得益于其獨特的運營模式。一般圖形市場產品有兩個開發周期:6-9個月和12-18個月,而英偉達公司則采用了“三團隊-兩季度”的運營模式,即三個并行開發團隊分別專注于三個獨立的分階段產品開發,分別在第一年秋季、第二年春季和第二年秋季推出新產品,每6個月推出一次新產品,與圖形市場產品周期一致,領先市場1-2個研發周期。此外,為解決芯片硬件開發比軟件開發慢的問題,英偉達公司大力投資了仿真技術,從而提升了效率。
3、在產品布局多元化初期,用產品交叉服務市場
盡管英偉達在手機芯片市場開拓中遭遇失敗,但并未停止Tegra處理器的研發,而是改變了產品定位,將Tegra處理器應用于智能汽車、智慧城市和云端服務。因此,英偉達初步確立了“兩產品條線-四市場”的商業模式,其中兩個產品條線分別為傳統產品GPU和Tegra處理器,而四個市場則分別為游戲、企業級、移動端和云端。
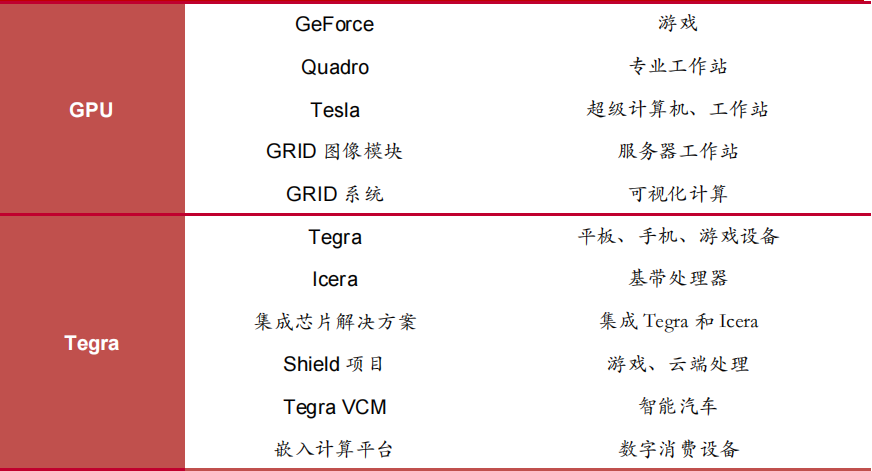
英偉達商業布局
4、英偉達的商業模式戰略很好的應對了圖像處理器市場的發展趨勢
英偉達的商業模式戰略很好地應對了圖像處理器市場的發展趨勢。當時的圖像處理器市場產品細化,主要分布在游戲玩家、企業級、平板電腦和移動端用戶,不同客戶的需求差異化明顯,針對不同下游英偉達推出了對應的產品方案。
1)游戲市場
針對玩家希望能夠在不同平臺無縫進行游戲體驗的需求,英偉達推出了端到端的服務,使游戲能夠在云端運行,不需要玩家擁有高性能的電腦,大大提高了玩家碎片時間的利用率和娛樂的靈活性。
2)企業級
英偉達為汽車、電影、天然氣等行業提供可視化解決方案,目的是提高行業生產力。英偉達面向企業市場的產品包括用于工作站的Quadro,用于高性能計算服務器的Tesla和用于企業VDI應用程序的GRID。
3)移動端
英偉達將移動端擴展到移動智能設備市場,比如智能汽車、智能家居行業。英偉達的移動戰略轉變為將Tegra應用到需要視覺設計的設備中。
4)云端服務
英偉達將GPU的應用從PC端拓展到服務器和數據中心,使得更多的用戶可以使用。英偉達開發的GRID使Adobe Photoshop遠程運行,并與應用程序交互。
2016-2025 年自動駕駛規模(十億美元)
5、研發投入帶給英偉達高回報,在主流游戲和顯卡天梯測評上,AMD 落后于英偉達
英偉達在2018年推出的Titan RTX和RTX 2080 Ti全面超過當時的Radeon VII,其采取的策略是推出比AMD稍高的性能和價格。即使技術比AMD領先,也會等到AMD推出更高性能的產品之后,才會推出,以此來獲得比AMD更高的收益。
6、專利數量方面英偉達逐步反超 AMD
AMD此前在專利數量上一直多于英偉達,但申請的數量呈現下降趨勢。英偉達在2011年之后申請專利數量開始爆發,主要因其在2007年之后開始研發移動端GPU和深度學習領域,最終給GPU市場帶來了新的框架和更高性能的芯片。
二、CUDA 自成體系:從單一產業到生態鏈,構建強護城河
1、CUDA 助力英偉達成長為 AI 產業龍頭,構建強大生態護城河壁壘
CUDA是英偉達基于其生產的GPU的一個并行計算平臺和編程模型,目的是便于更多的技術人員參與開發。開發人員可以通過C/C++、Fortran等高級語言來調用CUDA的API,來進行并行編程,達到高性能計算目的。CUDA平臺的出現使得利用GPU來訓練神經網絡等高算力模型的難度大大降低,將GPU的應用從3D游戲和圖像處理拓展到科學計算、大數據處理、機器學習等領域。這種生態系統的建立讓很多開發者依賴于CUDA,進一步增加了英偉達的競爭優勢。
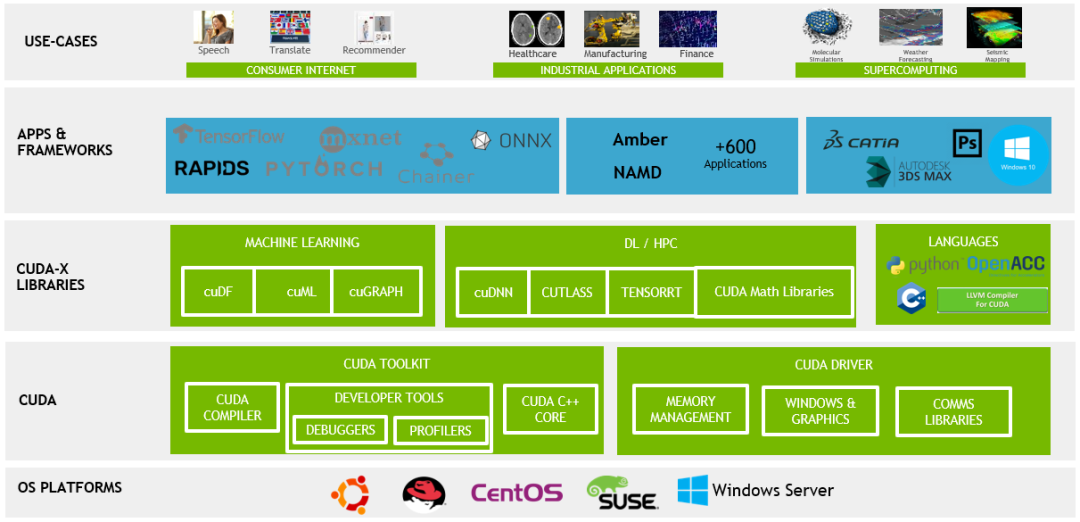
CUDA 加速計算解決方案
2、CUDA 的低成本和兼容性成為其最重要的吸引點之一
英偉達的CUDA是一個免費、強大的并行計算平臺和編程模型。安裝過程簡單且明確,讓開發者能夠輕松快速地啟動并行編程。CUDA對新手極其友好,特別是對C語言、C++和Fortran的開發者。同時為支持其他編程語言,如Java、Python等,CUDA還提供第三方包裝器進行擴展。為廣大開發者提供了極大的便利和高效的編程體驗。操作系統方面,CUDA在多種操作系統上也都有良好的兼容性,包括Windows、Linux和macOS。
3、CUDA 有著豐富的社區資源和代碼庫,為編程提供良好的支持
英偉達的CUDA享有強大的社區資源,這個社區由專業的開發者和領域專家組成,他們通過分享經驗和解答疑難問題,為CUDA的學習和應用提供了豐富的支持。另外,CUDA的代碼庫資源涵蓋各種計算應用,具有極高的參考價值,為開發者在并行計算領域的創新和實踐提供了寶貴的資源。這兩大特點共同推動了CUDA在并行計算領域的領先地位。
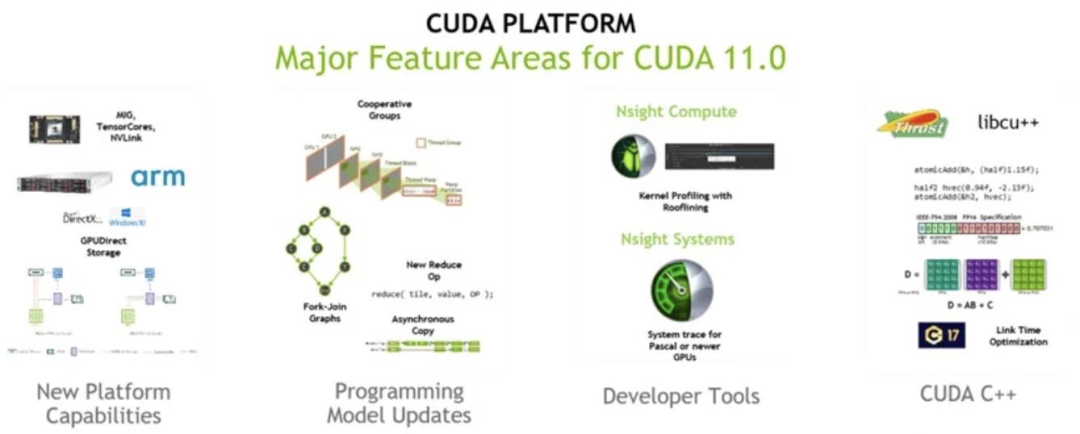
CUDA 11.0 主要特點
4、CUDA 借助燕尾服效應,搭配 GeForce 覆蓋多元市場
CUDA技術最初是為了配合GeForce系列芯片而推出的,利用GeForce在游戲市場的廣泛覆蓋率,作為一個技術杠桿,推動CUDA的普及和發展。作為一項可以幫助GeForce拓展新的市場的重要技術,CUDA極大地提高了視頻和圖像應用(如CyberLink、Motion DSP和Nero)的性能,實現了多倍的效率提升。
5、創業公司的大量采用使得 CUDA 應用場景進一步得到拓展,游戲不再是唯一應用領域
隨著時間的推移,超過一百家創業公司開始利用CUDA的強大計算能力,使其應用領域得以擴展,不再局限于游戲方面。在視頻編碼領域,英偉達與Elemental公司合作,利用并行計算技術加速了高清視頻的壓縮、上傳和存儲速度。這一成功的合作不僅體現了CUDA在各種場景下的適用性,也進一步推動了CUDA技術的發展。當Elemental公司后被亞馬遜收購,其基于CUDA的視頻處理技術也成為AWS的服務組成部分,這一過程也讓CUDA的使用場景得到了進一步的豐富和拓寬。
6、CUDA 形成完整生態鏈,通過大學普及學習以推廣 CUDA
英偉達將 CUDA 引入了大學的課堂中,從源頭上擴大了 CUDA 的使用范圍和受眾 群體。早在 2010 年,已經有關于 CUDA 數千篇論文,超過 350 所大學 進行 CUDA 教學課程。在此基礎之上,英偉達建立了 CUDA 認證計劃、 研究中心、教學中心,不斷完善 CUDA 的生態鏈。從結果看:2008 年 僅有 100 所大學教學 CUDA 課程,在 2010 年英偉達全球建立了 20 個 CUDA 研發中心后,2015 年已有 800 所大學開放 CUDA 課程。
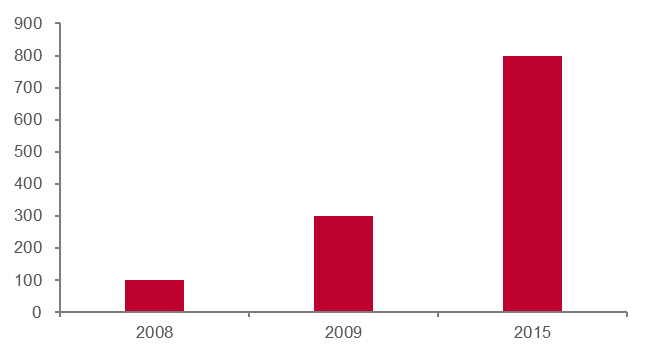
大學教授 CUDA 數量(所)
7、對比 OpenCL,CUDA 是英偉達 GPU 編程的更優解
雖然OpenCL具有更廣泛的兼容性,但CUDA與英偉達的GPU硬件緊密結合,可以更有效地利用其性能。此外,CUDA的編程模型更加簡潔易用,提供完整的開發工具鏈,并且擁有豐富的社區資源和多樣的代碼庫,使得在科學計算、深度學習等領域的應用更加方便。因此,對于英偉達GPU的開發者來說,CUDA通常是更好的選擇。

CUDA 成為英偉達生態基礎
8、對比 ADM 的 CTM 編程模型,CUDA 擁有更廣泛的應用和更高的操作性
操作性方面,CTM更接近硬件,因此開發者需要具備更深入的硬件知識才能進行開發。但這也意味著CTM可以提供更精細的控制和優化。相比之下,CUDA提供了一套完整的開發工具鏈,包括編譯器、調試器和性能分析工具,以及豐富的庫函數,為開發者提供了極大的便利。在應用方面,CUDA已經在各種領域廣泛應用,尤其是在科學計算和深度學習等領域,CUDA擁有大量的優化庫和開發工具。而CTM的應用相對較少,但由于其提供了對硬件的低級別控制,因此在一些特定的應用場景中具有優勢。
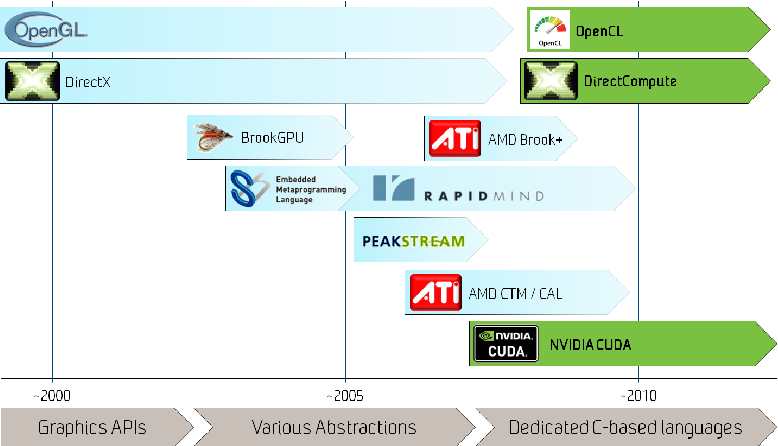
GPU 編程平臺發展歷史
9、對比微軟的 DirectCompute, CUDA 勝在配套設施的支持
與DirectCompute相比,CUDA具有豐富的功能庫、完善的開發工具和廣泛的應用支持,尤其在科學計算和深度學習領域具有明顯優勢。CUDA在英偉達GPU上的性能優化也更為出色。而DirectCompute作為跨平臺工具,其優勢在于與DirectX的兼容性以及對多種硬件的支持。但從英偉達GPU的應用廣泛度來看,使用CUDA才是開發者的首選。總的來說,雖然DirectCompute的通用性更強,但英偉達的CUDA在功能、性能和應用范圍上提供了更強大的支持,對于使用英偉達硬件的開發者來說是更優的選擇。
三、抓住人工智能發展浪潮,順利轉型切入算力芯片領域
IDC的測算顯示,全球數據總量每年將以50%的增速不斷增長。到2025年,數據量將增加至334ZB,到2035年則將達到19267ZB。隨著5G技術的落地,應用方案將變得更加具象化,未來數據總量和數據分析需求將持續增加。數據增長的主要來源包括IoT、移動互聯網、智慧城市和自動駕駛等領域。大數據的應用將從商業分析向工業、交通、政府管理、醫療、教育等行業滲透,并成為產業供應鏈中不可或缺的重要組成部分。
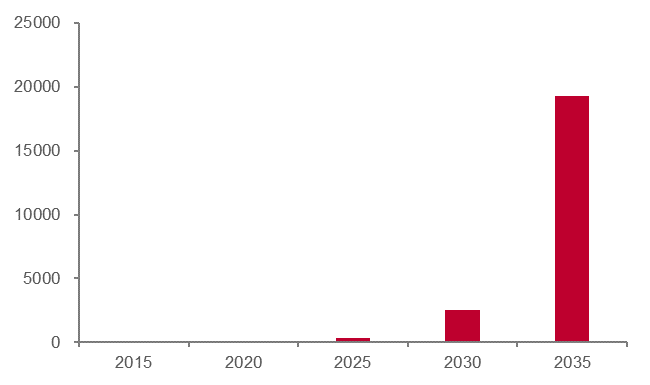
全球數據總量(ZB)
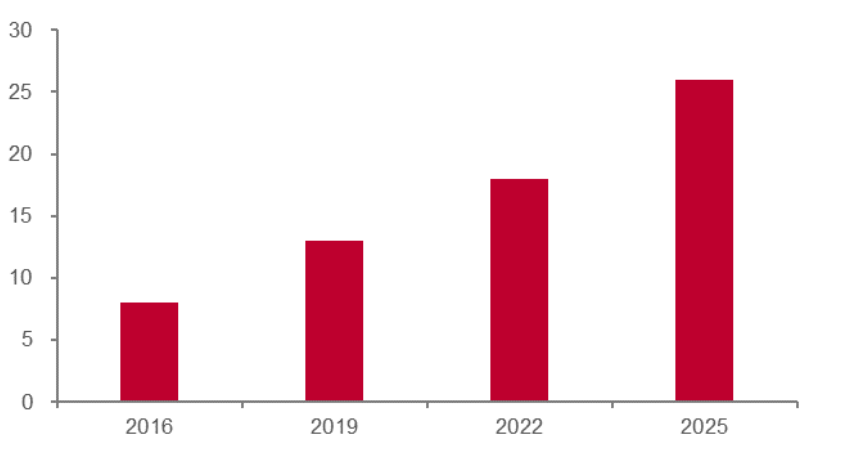
據目前的測算,智能駕駛將是對算力要求最高的應用領域。一方面,汽車駕駛對于安全可靠性要求極高;另一方面,L5級別的自動駕駛汽車將搭載32個傳感器,據麥肯錫估算,一輛自動駕駛汽車的數據量將達到4TB/h,而Intel測算出的一天數據量將達到4000GB。然而,英偉達的Xavier目前只有1.3TFlops的處理能力,無法滿足處理L5級別數據的要求。智能駕駛和ADAS市場在未來的10年內有望保持高速增長,因此智能駕駛以及ADAS領域存在著巨大的算力缺口。

智能駕駛層級越高所需傳感器越多
根據Tractica的數據,2018年全球AI硬件市場的收入為196億美元,其中GPU的收入占36.2%,即71億美元。預計到2025年,全球AI硬件市場的收入將達到2349億美元,其中GPU的收入占23.2%,即545億美元。盡管GPU市場占比會出現下滑,但全球AI硬件市場仍在不斷上升,為GPU市場帶來更多的增長空間。
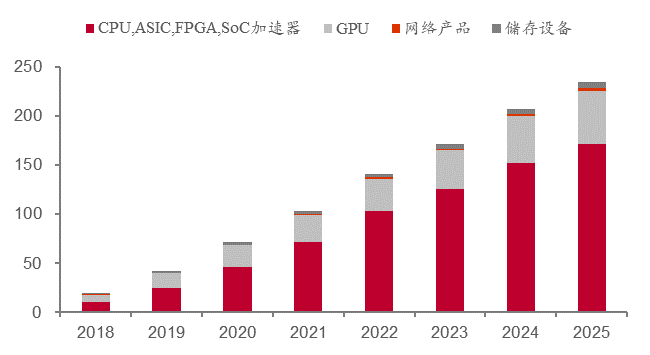
2018-2025 年 AI 硬件市場收入(十億美元)
由于摩爾定律的放緩,CPU的應用性能增幅已經開始下降。然而,人工智能的到來并沒有因此而停止。登納德定律通過縮小晶體管的尺寸和電壓,讓設計師在保持功率密度的同時提高晶體管的密度和速度。但是,由于物理條件的限制,CPU架構師需要增加大量電路和能量,才能獲得有限的指令級并行性(ILP)。因此,在后摩爾定律時代,CPU晶體管需要消耗更多的性能,才能實現應用性能的小幅提高。最近幾年,CPU的性能增長速度僅為每年10%,而過去是每年50%。
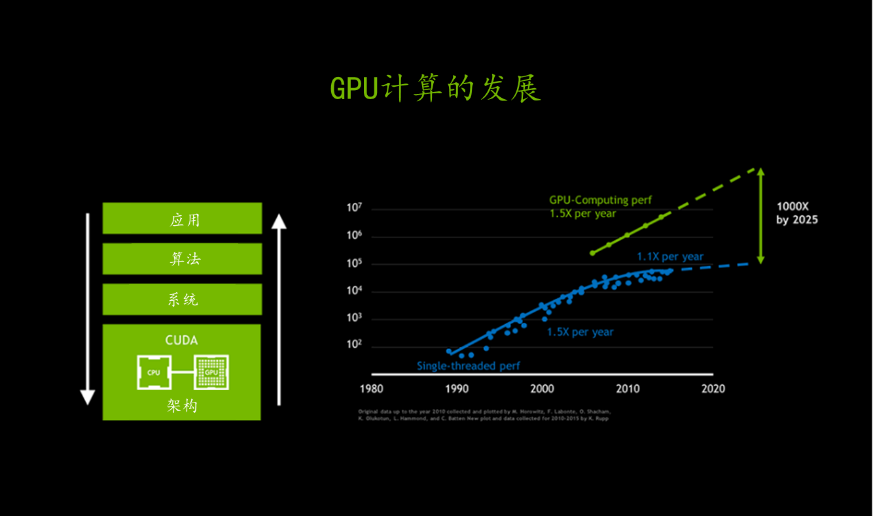
GPU 打破摩爾定律
英偉達作為全球GPU市場的領導者,憑借其創新力和高市場份額,在行業中擁有龍頭地位。其持續的技術創新和強大的研發實力,尤其是CUDA并行計算平臺的推出,進一步鞏固了其在市場中的優越地位。英偉達的GPU已成為人工智能和機器學習加速應用的首選解決方案,廣泛應用于各個領域,從游戲和專業視覺應用到數據中心和自動駕駛汽車。英偉達成功的經驗在于持續深耕GPU高性能計算潛力,構建強大的軟件護城河壁壘,加大研發投入,實施創新技術,不斷更新GPU架構,拓展業務范圍,擴大GPU市場,提高營收和利潤率,達成產業鏈的良性循環。
國內算力公司梳理
全球 AI 芯片市場被英偉達壟斷,然而國產 AI 算力芯片正起星星之火。目前,國內已涌現出了如寒武紀、海光信息等優質的 AI 算力芯片上市公司,非上市 AI 算力芯片公司如藍海大腦、沐曦、天數智芯、壁仞科技等亦在產品端有持續突破。
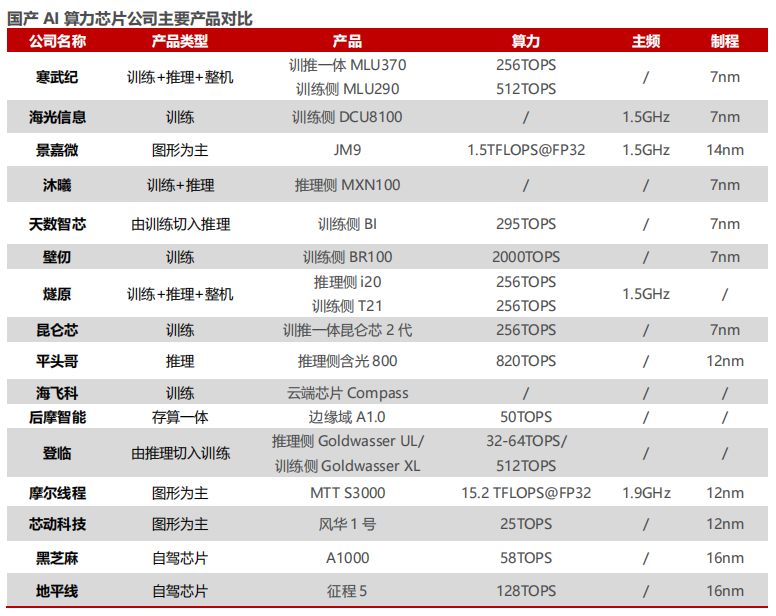
一、龍芯中科:國產 CPU 設計標桿,自主研發 GPGPU
公司主要從事處理器(CPU)及配套芯片的研制、銷售及服務,主要產品包括龍芯1號、龍芯2號、龍芯3號三大系列處理器芯片及橋片等配套芯片。這些系列產品已在電子政務、能源、交通、金融、電信、教育等行業領域廣泛應用。龍芯通過自主指令系統構建獨立于Wintel和AA體系的開放信息技術體系的CPU,不斷推出基于LoongArch架構的芯片,成功建立了自己的指令系統架構LoongArch。在2021年和2022年,公司相繼推出了多款基于LA架構的芯片產品,目前已擁有9顆基于LA架構的芯片產品。
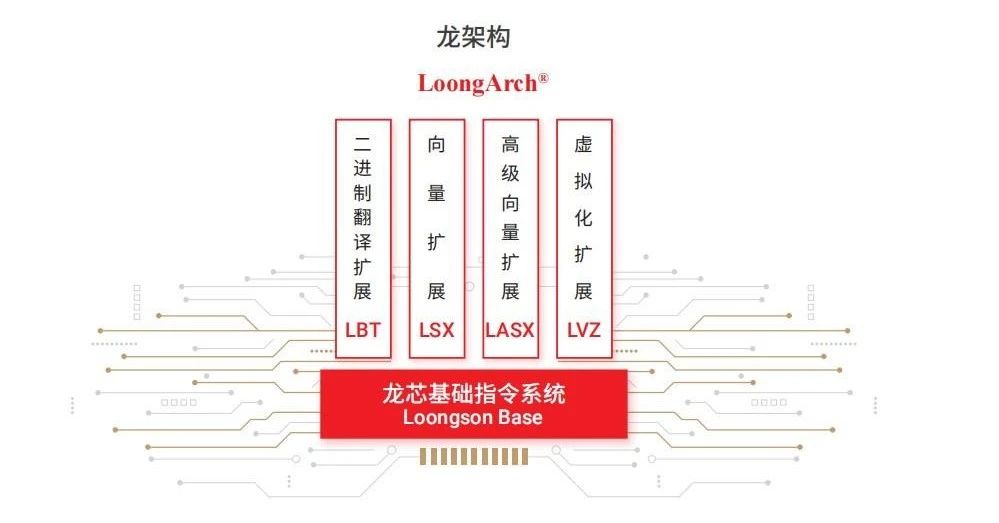
龍架構
龍芯中科堅持自主研發指令系統、IP核等核心技術,掌握指令系統、處理器核微結構、GPU以及各種接口IP等芯片核心技術,在關鍵技術上進行自主研發,已取得專利400余項。GPU產品進展順利,正研制新一代圖形及計算加速GPGPU核。據公司在2022年半年度業績交流會信息,第一代GPU核(LG100)已經集成在7A2000中,新一代GPGPU核(LG200)的研制也取得了積極進展。目前,公司正在啟動第二代龍芯圖形處理器架構LG200系列圖形處理器核的研制。龍芯中科在核心技術自主研發方面取得了顯著成果,為公司未來的發展奠定了堅實的基礎。
二、海光信息:國產高端處理器龍頭,CPU+DCU 雙輪驅動
公司主營產品為海光通用處理器(CPU)和海光協處理器(DCU)。海光CPU分為7000、5000、3000三個系列,可應用于高端服務器、中低端服務器和邊緣計算服務器。海光DCU是基于GPGPU架構設計的協處理器,以8000系列為主,適用于服務器集群或數據中心。該產品全面兼容ROCm GPU計算生態,能夠適配國際主流商業計算軟件,解決了產品推廣過程中的軟件生態兼容性問題。
海光產品持續迭代,CPU方面海光一號和海光二號已實現量產,海光三號已正式發布,海光四號進入研發階段。雖然海光CPU性能在國內處于領先地位,但在高端產品性能上與國際廠商有所差距,接近Intel中端產品水平。DCU方面,深算一號已實現商業化應用,深算二號已于2020年1月啟動研發,在典型應用場景下指標達到國際上同類型高端產品水平。高研發力度成為海光產品快速迭代的基石,從2019到2021年,海光信息的研發投入增長83.3%,擁有千人級高端處理器研發團隊,且90.2%的員工是研發人員。公司已取得多項處理器核心技術突破,擁有179項專利、154項軟件著作權和81項集成電路布圖設計專有權,構建了全面的知識產權布局,CPU與DPU的持續迭代使性能比肩國際主流廠商。
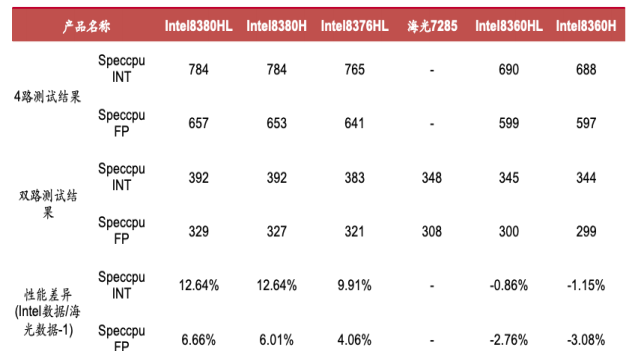
海光 CPU 與 Intel 產品性能對比
三、寒武紀:國產 AI 芯片領先者
寒武紀是一家專注于人工智能芯片產品研發與技術創新的獨角獸公司,成立于2016年。公司的產品廣泛應用于消費電子、數據中心、云計算等多個場景。為了支持人工智能的各種應用場景,公司推出了面向云端、邊緣端和終端的三個系列不同品類的通用型智能芯片與處理器產品,包括終端智能處理器IP、云端智能芯片及加速卡、邊緣智能芯片及加速卡。寒武紀的產品線豐富,應用場景廣泛,能夠滿足在云、邊、端各個尺度的人工智能計算需求。
在2022年3月,公司推出了新的訓練加速卡MLU370-X8,該加速卡配備了雙芯片四核思元370,并整合了寒武紀MLU-Link多核互聯技術,主要針對訓練任務。在廣泛應用于各個領域的YOLOv3、Transformer等訓練任務中,8卡計算系統的并行性能平均超過了350WRTXGPU的155%。

高性能通用圖形處理器芯片及系統研發項目情況及進程安排
藍海大腦高性能計算機是一款功能強大的GPU服務器,它具備開放融合、超能運算、高效運維、液冷設計等多項特點。在開放融合方面,該計算機系統融合了計算、網絡、存儲、GPU、虛擬化等多種技術,支持主流虛擬化平臺,同時也支持在線壓縮、重復數據自動刪除、數據保護、容災備份以及雙活等功能。
在超能運算方面,該計算機系統支持主流GPU顯卡虛擬化,支持2、8、16塊全高全長卡,提高計算性能和圖像渲染能力,同時也可以快速實現系統擴展,支持大規模并發運行。在高效運維方面,該計算機系統提供一站式部署,開箱即用,同時也具備強大的數據、網絡、虛擬化及管理安全保障。
此外,該計算機系統還采用了液冷設計,可以連續安靜熱轉換,停機時間少,所有顯卡不會因過熱而縮短跳動周期,顯著減少體積和熱量的產生,液冷系統密度更高、更節能、防噪音效果更好。此外,該計算機系統還支持2顆英特爾? 至強? 可擴展處理器家族CPU,提供16-56物理核心龍芯、飛騰、申威(可選)、英偉達A100、H100、A6000等多種顯卡多種選擇,可為用戶提供更加靈活、高效的計算服務。
總結
總之,隨著人工智能技術的不斷發展,對高性能計算的需求也在不斷增長。英偉達作為計算機芯片制造商之一,通過技術進步和產品創新不斷提高自身競爭力。未來,國產AI供應商也有望在產業創新趨勢和國產替代背景下進入快速增長通道。可以預見的是,算力產業鏈將會快速增長,為人工智能應用的落地提供強大的支撐。
審核編輯黃宇
-
NVIDIA
+關注
關注
14文章
5025瀏覽量
103266 -
AI
+關注
關注
87文章
31155瀏覽量
269487 -
英偉達
+關注
關注
22文章
3800瀏覽量
91346 -
算力
+關注
關注
1文章
995瀏覽量
14866
發布評論請先 登錄
相關推薦

存算一體化與邊緣計算:重新定義智能計算的未來

存算一體架構創新助力國產大算力AI芯片騰飛
青云科技強化AI算力架構,升級產品與服務體系

中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
助力全國一體化算力網建設,神州鯤泰以算力構建新質生產力

工信部:算力驅動經濟社會高質量發展
聚焦全國一體化算力體系構建,憶聯以強大存力“引擎”釋放算力潛能

中國算力供給緊張,建立全國算力大市場刻不容緩

什么是通感算一體化?通感算一體化的應用場景

詳細分析算力網絡的發展






 工商網監
工商網監
評論