


如何讓小規(guī)模語言模型像 GPT-4 一樣使用任意工具是一個非常有價值的研究課題。中國科學(xué)院軟件研究所中文信息處理實驗室提出了一種語言模型的工具學(xué)習(xí)新框架,該框架利用基于大模型的多智能體模擬交互策略,可以自動生成多樣化的工具使用數(shù)據(jù)集,并使用生成的數(shù)據(jù)集對小模型進行微調(diào)。論文的實驗驗證了僅需要使用三千多個多樣化的工具調(diào)用實例,就能夠使小型模型獲得與極大規(guī)模模型相媲美的通用工具使用能力。
具體來說,本文的核心工作包括:
1. 提出一種基于大模型的多智能體模擬交互策略,用于生成工具使用數(shù)據(jù)集。這種方法能在最小化人工干預(yù)的前提下,生成大量且多樣化的工具使用數(shù)據(jù)集;
2. 開源了一個涵蓋超過400個工具,三千多條實例的模擬工具使用數(shù)據(jù)集,為探索通用工具使用能力奠定了基礎(chǔ);
3. 通過實驗,驗證了在多樣化工具使用數(shù)據(jù)集上進行微調(diào),能夠使小型模型獲得與極大規(guī)模模型相媲美的通用工具使用能力。
論文:ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
數(shù)據(jù):https://github.com/tangqiaoyu/ToolAlpaca
背景工具的使用在人類進化史上占據(jù)了重要的地位,對于語言模型來說,這一點同樣適用。當(dāng)語言模型能夠熟練運用各種工具,它們就能突破自身的局限,獲取最新的信息,幫助用戶利用各種服務(wù),并提升回答的精確性。 如今,OpenAI 的 GPT-4 已經(jīng)可以通過插件的形式接入和使用各種第三方工具,同時這類超大型的語言模型支持通過僅給定配置文件的情況下,以即插即用的方式使用之前模型訓(xùn)練過程中未見過的工具,這一泛化性的工具使用能力大大豐富了模型調(diào)動資源解決復(fù)雜問題的手段。然而,對于較小的語言模型,例如 Moss、ToolLLaMA 等,它們使用工具的能力仍然來源于在特定工具的數(shù)據(jù)集上進行監(jiān)督學(xué)習(xí)。這使得這些模型的工具使用能力受限于在訓(xùn)練過程中接觸過的工具,尚未真正獲得通用的工具使用能力。上述的對比引出了研究人員所關(guān)注的一個核心研究問題,即是否有可能讓較小規(guī)模的語言模型也具備有泛化地使用各種不同的、未見過的工具的能力,進而讓它們能夠更好地與更廣泛的工具進行交互,從而提升模型利用現(xiàn)實世界的資源解決問題的手段。
ToolAlpaca:通用工具使用能力學(xué)習(xí)新框架
受 Alpaca 通過微調(diào)讓小模型學(xué)會通用指令遵循啟發(fā),中文信息處理實驗室的研究人員探索了通過在通用工具使用數(shù)據(jù)集上微調(diào)較小規(guī)模的語言模型,讓它們獲得通用工具使用能力。實現(xiàn)上述能力的一個核心難點在于需要構(gòu)建一個多樣化的工具使用數(shù)據(jù)集。然而,由于工具使用涉及復(fù)雜的多方交互,現(xiàn)今仍然缺乏公開可用的多樣化工具使用數(shù)據(jù)集。為了解決這個挑戰(zhàn),研究人員提出通過多智能體模擬交互的方式生成工具使用數(shù)據(jù)集。這種方法充分利用大模型強大的文本生成能力,在幾乎不需要任何人工干預(yù)的情況下構(gòu)建一個多樣化且真實的數(shù)據(jù)集。我們從構(gòu)建多樣化工具集開始,之后利用多智能體模擬生成工具使用數(shù)據(jù)集,最后基于此訓(xùn)練出擁有通用工具使用能力的 ToolAlpaca 模型。
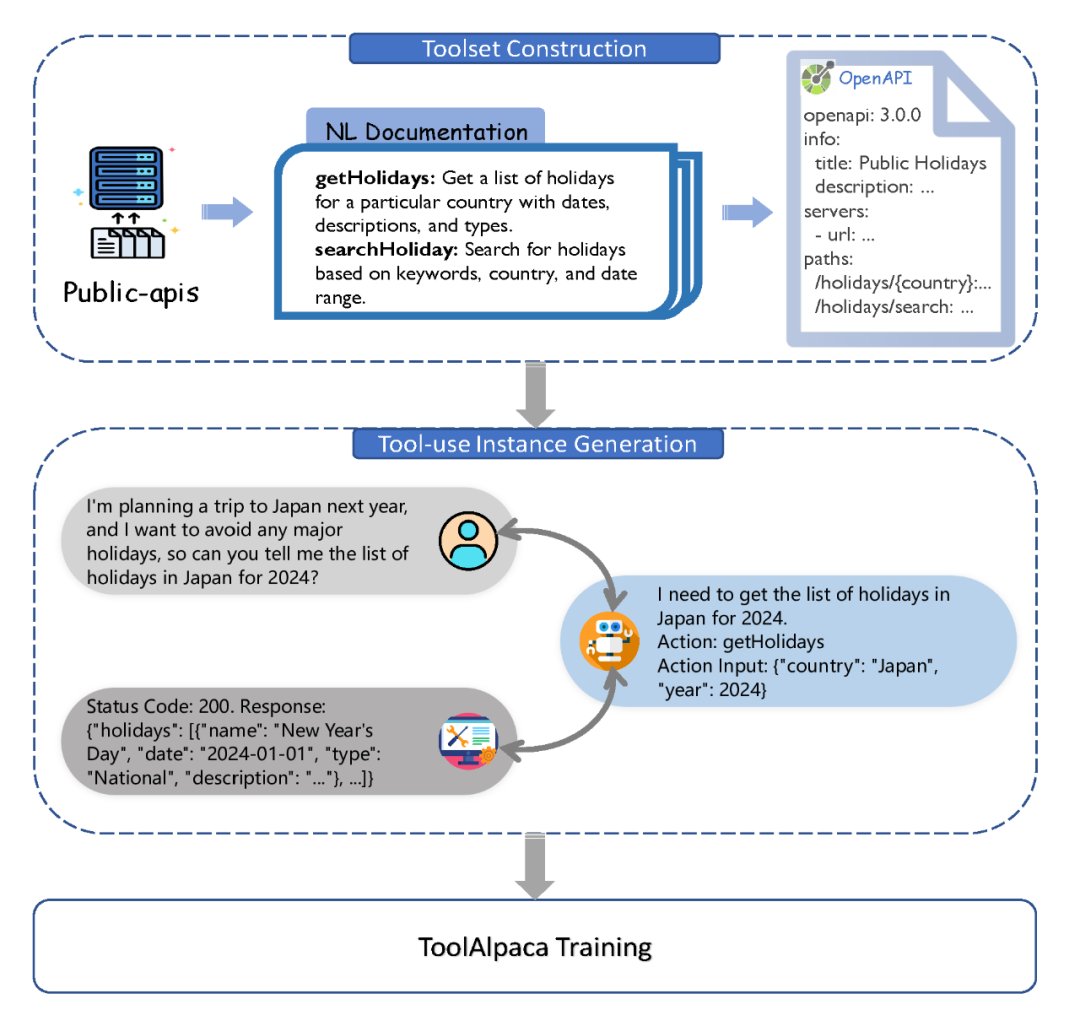
工具集構(gòu)建:我們首先從開源倉庫 public-apis 中獲取工具的名稱和簡短描述作為初始信息,之后利用大語言模型通過 prompt 的方式將其擴展成自然語言形式的文檔,描述工具提供的每一個函數(shù)及其對應(yīng)的輸入。為了讓信息更為精細和結(jié)構(gòu)化,我們進一步將這些自然語言文檔擴展為遵循 OpenAPI 規(guī)范的文檔,詳盡描繪了每個函數(shù)的細節(jié)。結(jié)構(gòu)化文檔的使用不僅使我們的工具集更為細致和完備,同時也方便了我們的工具集與其他工具(如 ChatGPT 現(xiàn)有的 Plugin 等)進行兼容。下圖為一個名為 Public Holidays 工具的示例。

工具使用實例生成:盡管我們已經(jīng)構(gòu)建了大規(guī)模且多樣化的工具集,但構(gòu)建工具使用數(shù)據(jù)集仍然是一項富有挑戰(zhàn)性的任務(wù)。首先,由于工具集是由大模型生成的,要根據(jù)工具集文檔構(gòu)造如此大量的真實工具,需要大量的編程和數(shù)據(jù)收集工作,幾乎不可能實現(xiàn);其次,工具集本身包含了從通用到專用的各種領(lǐng)域的工具,使得構(gòu)造與工具相關(guān)的初始指令是困難的。為此,我們提出了一種多智能體模擬交互的策略來生成工具使用數(shù)據(jù)。我們利用大模型分別模擬用戶、AI 助手、工具執(zhí)行器這三個智能體,通過他們之間的交互來生成豐富且實用的工具使用數(shù)據(jù)。
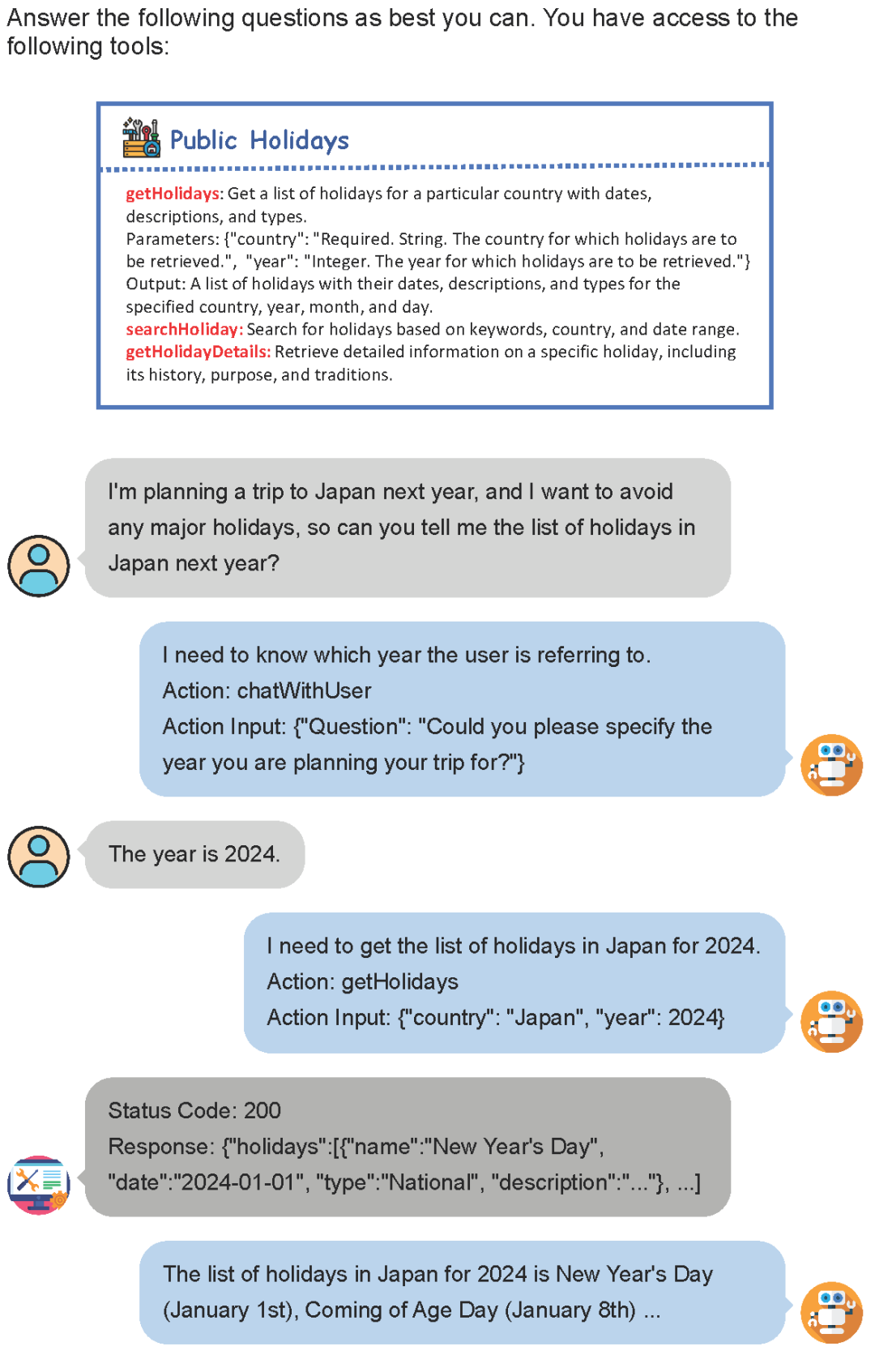
如上圖所示,用戶發(fā)起最初的指令,并通過簡單的交互提供更多必要的信息。工具執(zhí)行器則利用結(jié)構(gòu)化文檔作為提示,借助大模型來模擬工具的執(zhí)行過程,從而產(chǎn)生相應(yīng)的反饋。而AI助手則充當(dāng)兩者之間的橋梁,它幫助用戶調(diào)用各種工具以解決問題,并最終對整個交互過程進行總結(jié),返回給用戶最終的響應(yīng)結(jié)果。通過這三個智能體的交互,我們成功構(gòu)建了一套能貼近真實場景需求的工具使用數(shù)據(jù)集。
ToolAlpaca 模型訓(xùn)練與測試:我們使用生成的數(shù)據(jù)集對 Vicuna 模型進行微調(diào),以此得到最終的 ToolAlpaca 模型。在測試階段,ToolAlpaca 將擔(dān)任 AI 助手的角色,同時用戶和工具執(zhí)行器的角色仍由大模型扮演。
實驗
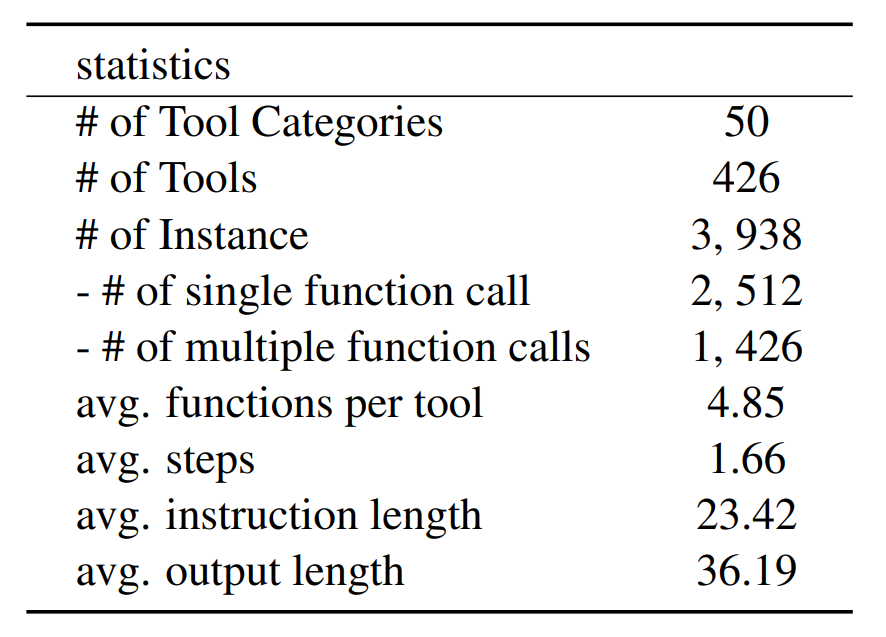
最終,我們利用 ChatGPT 和 GPT-3.5 構(gòu)造了一個包含超過400個工具、3900多條工具使用實例的模擬數(shù)據(jù)集,數(shù)據(jù)集基本統(tǒng)計信息如下圖所示。
之后,我們在Vicuna 模型上進行微調(diào),得到 ToolAlpaca 模型。為了評估模型的泛化性能,我們在10種未包含在訓(xùn)練集中的工具上構(gòu)造了含有100條數(shù)據(jù)的測試集,并通過人工評價對模型的工具調(diào)用過程和整體性能進行了評估。評測結(jié)果如下圖所示。
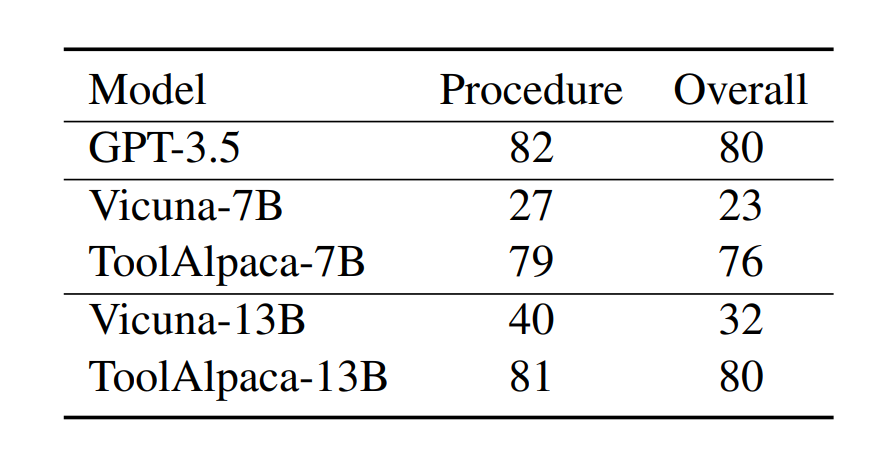
實驗結(jié)果表明,無論是7B還是13B的模型,經(jīng)過在 ToolAlpaca 數(shù)據(jù)集上的訓(xùn)練后,其性能都有了顯著的提升。值得注意的是,ToolAlpaca 在測試集上的整體性能已經(jīng)接近于 GPT-3.5 的表現(xiàn)。這些實驗結(jié)果驗證了我們構(gòu)建數(shù)據(jù)集的有效性,同時也回答了我們最開始提出的問題:通過在多樣化的工具使用數(shù)據(jù)集上微調(diào),可以讓小模型獲得通用的工具使用能力。
-
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17914 -
語言模型
+關(guān)注
關(guān)注
0文章
562瀏覽量
10806 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25483
原文標(biāo)題:3000多個實例教會小模型通用工具使用能力!中文信息處理實驗室提出工具學(xué)習(xí)新框架 ToolAlpaca
文章出處:【微信號:gh_e5b9d8c5c1d4,微信公眾號:中科院軟件所中文信息處理實驗室】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
[原創(chuàng)]認證與實驗室
實驗室整體解決方案是什么?
智慧實驗室解決方案(LoRa)
KGB知識圖譜引擎助力NLPIR中文信息處理
NLPIR大數(shù)據(jù)知識圖譜完美展現(xiàn)文本數(shù)據(jù)內(nèi)容
智慧實驗室教學(xué)管理系統(tǒng)平臺開發(fā)設(shè)計案例
系統(tǒng)控制與信息處理實驗室 精選資料分享
lims實驗室管理系統(tǒng)是什么?實驗室信息管理系統(tǒng)介紹!
實驗室lims系統(tǒng)解決方案
實驗室設(shè)計指南
網(wǎng)絡(luò)虛擬實驗室及實現(xiàn)方法
易云維?實驗室智能管理系統(tǒng)構(gòu)建更適合現(xiàn)代醫(yī)療實驗室的信息化管理體系
什么是智慧實驗室綜合管理平臺?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論