 基于無人機高光譜遙感的水稻氮營養診斷方法-萊森光學
基于無人機高光譜遙感的水稻氮營養診斷方法-萊森光學
引言
氮素是對作物生長、發育,以及最終產量影響最明顯的元素,其含量變化會對光合作用、蛋白質合成以及碳氮代謝產生影響。氮素的缺乏會抑制作物地上部分和根系的生長,限制繁殖器官的形成和發育,并顯著影響作物最終產量以及品質 。因此,快速、精準、大面積地對水稻田間氮素需求情況進行診斷,并依據診斷結果實現精準施肥,是實現水稻田間精準管理和保證水稻產量的重要手段。傳統的水稻氮營養診斷標準主要基于臨界氮濃度曲線。氮營養指數作為作物氮營養診斷的重要指標,能夠定量描述作物的氮營養豐缺狀況,為作物氮虧缺量的確定提供了理論依據。
近年來,隨著高光譜遙感技術的發展,利用無人機高光譜遙感技術獲取水稻氮營養狀況信息成為精準農業領域的重要發展方向。高光譜遙感技術能夠通過分析作物光譜數據來獲得其生長信息,具有快速、無損、準確等優點。對此,國內外已在相關領域取得一定的研究進展。這些研究大多數集中在利用高光譜對水稻氮含量進行反演,而單純的氮含量信息難以反映水稻的氮營養豐缺狀況,因此,結合無人機高光譜遙感技術與臨界氮濃度曲線理論,通過光譜反演氮營養指數的形式對水稻進行氮營養診斷成為當前的研究熱點 。前人研究大都以對水稻進行氮營養診斷為主,而單純的氮營養診斷只能判斷水稻的生長狀況,需要進一步獲取水稻氮虧缺量數據才能以此對精準施 肥做出定量指導。
因此,本文擬以水稻無人機高光譜數據與氮虧缺量為研究對象,以水稻各個時期氮虧缺量約等于0的冠層光譜為標準,對水稻高光譜數據進行比值、差值與歸一化差值變換,然后利用競爭性自適應重加權采樣法處理原始光譜與變換光譜,篩選出效果最佳的光譜特征波段,并建立基于多元線性回歸、極限學習機與蝙蝠算法優化極限學習機的水稻氮虧缺量反演模型,最后比較模型反演效果,確定基于高光譜數據的水稻氮虧缺量最佳反演方法,以期為快速獲取水稻氮虧缺量提供研究方向,也為基于田間水稻氮營養狀況的精準施肥提供定量指導。
數據獲取與反演模型建立
2.1 實驗設計
實驗于2021年6—9月在遼寧省鞍山市海城市耿莊鎮沈陽農業大學精準農業航空科研基地(北緯 40°58′45. 39″,東經 122°43′47. 01″)進行,為避免陰雨多云天氣對遙感數據采集造成誤差,數據采集過程選擇天氣晴好的日期,如遇云量超過20%或不利于遙感數據采集天氣則順延采集。水稻品種為北粳1705。
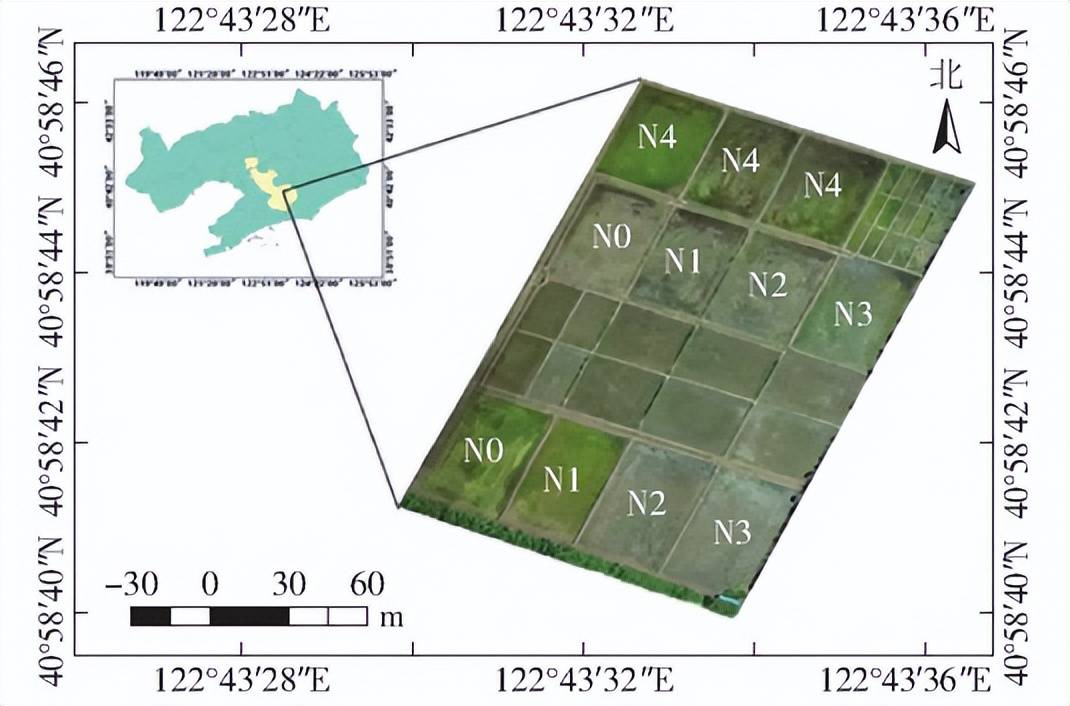
圖1實驗小區分布圖
實驗區域如圖 1 所示,實驗田分為2個大區, 其中實驗區 1 設立5個氮肥梯度,施氮量分別為 N0(0kg/hm 2)、N1(75kg/hm2)、N2(150kg/hm2)、N3(225kg/hm2)、N4(300kg/hm2),實驗區2也設計5個氮肥梯度, 施 氮 量 分 別 為:N0( 0kg/hm2)、 N1(50kg/hm2)、N2(100kg/hm2)、N3(150kg/hm2 )、 N4(200kg/hm2),氮肥基追比為 5∶ 3∶ 2。實驗區 1 對每個梯度設立 3 個重復小區,共設立 3 × 5 = 15 個 小區。每個小區面積為 5m × 8m=40m2 ,實驗區2每個小區面積為660m2,除氮肥梯度外兩組實驗區田間管理一致,磷鉀肥施用量采用當地標準施用量進行,其中磷肥標準施用量為144 kg/hm2,鉀肥標準施用量為192 kg/hm 2,基追比為 1∶ 1,其余田間管理同常規高產管理。田間采樣由分蘗期至抽穗期,采樣間隔9d,每次采樣在各實驗小區選取具有代表性的3穴水稻進行冠層光譜、水稻氮濃度與地上干物質量的獲取,最后結果取平均值作為該小區水稻氮濃度與地上干物質量。實驗區1共采集小區數據120組,實驗區2共采集小區數據88組,共計208 組 樣本。
2.2 數據獲取
2.2.1 水稻光譜參量獲取
采用無人機高光譜成像系統,高光譜波段范圍為400 ~ 1 000nm, 分辨率為3nm,有效波段數為 253 個。
2.2.2 水稻農學參量獲取
測定樣本氮濃度與地上干物質量時,首先對每個小區的水稻進行破壞性采樣,將樣本帶至實驗室,然后將樣本放入干燥箱中105℃ 殺青30min后, 80℃干燥至恒質量;之后測量干燥后樣本的干物質量,并根據種植密度換算成地上部干物質量;最后將干燥后的樣本磨碎,對研磨后的樣本通過凱氏定氮法測量植株氮濃度。
2.3 基于臨界氮濃度曲線的氮虧缺量計算方法
臨界氮濃度是作物達到最大生物量所需的最小氮濃度,因此以臨界氮濃度為基準可以推導出臨界氮積累量方程,進而建立氮虧缺量方程,并確定水稻氮虧缺量。根據臨界氮濃度曲線構建方法,以所測水稻氮濃度與地上干物質量為基礎構建東北水稻的臨界氮濃度曲線,具體方法如下:對比不同氮肥梯度下測定的氮濃度與干物質量,通過方差分析將樣本分為受氮營養限制組與不受氮營養限制組;對受氮營養限制組的數據,將地上干物質量與氮濃度進行線性擬合;對不受氮營養限制組,對同一時期樣本地上干物質量取平均值代表該時期最大地上干物質量;取各時期擬合曲線于最大地上干物質中位置的截點為該時期的理論臨界氮濃度點;將各時期臨界氮濃度點進行冪函數擬合,構建作物臨界氮濃度曲線
Nc= aM-b(1)
式中 Nc———水稻臨界氮質量比,g / g
M———地上干物質量,t/hm2
a、b———曲線參數
根據臨界氮濃度曲線推導出臨界氮積累量方程 與氮虧缺量方程,推導過程為
Ncna= 10aM1 - b(2)
Nand= Ncna- Nna(3)
式中 Ncna———臨界氮濃度條件下植株氮積累量,kg/hm2。
Nand———氮虧缺量,kg/hm2
Nna———不同施氮量下植株實際氮積累量, kg / hm2。
2.4 光譜數據處理
2.4.1 高光譜數據轉換
由于臨界氮濃度狀態下作物地上部氮營養狀況與冠層葉片結構達到最佳狀態,而這些都是影響水稻冠層光譜反射率的直接因素,因此,相比非臨界氮濃度狀態下的作物,臨界氮濃度下水稻同其余水稻無論在光譜層面還是氮營養狀況層面都存在一定的差異。為了在光譜層面突出臨界氮濃度下水稻與其余水稻的差距,本研究選取各個時期Nand≈ 0 kg/hm2樣本對應的光譜反射率,將其與同時期其余樣本光譜反射率分別做比值、差值和歸一化差值變換,計算方法為
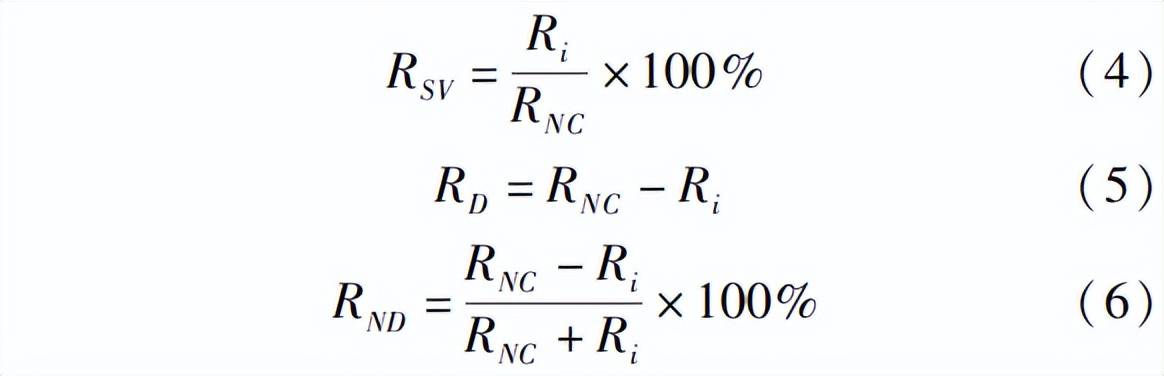
式中 RSV———比值光譜反射率,%
RD———差值光譜反射率,%
RND———歸一化差值光譜反射率,%
RNC———臨界氮濃度狀態下樣本光譜反射 率,Ri———同時期其余光譜反射率,%
2.4.2 高光譜特征波長提取
由于全波段光譜相鄰波段數據相似度較高,且光在大量與所求變量無關的冗余信息,基于全波段譜的建模往往存在運行速度較慢,模型誤差較高,反演精度較低等缺點。為了減少輸入變量個數,降低數據冗余性,提高建模速度與精度,本文采用競爭性自適應重加權采樣法對光譜反射率數據進行特征提取。CARS算法基于達爾文進化論簡單有效的生存原則“適者生存”,對不適應的波長變量進行逐步淘汰。首先,利用蒙特卡羅采樣法采樣N次,再以偏最小二乘回歸系數絕對值作為衡量標準,保留回歸系數絕對值大的波長變量,去除回歸系數絕對值小的波長變量,從而獲得一系列的波長變量子集;然后對比每次產生的PLSR模型的交互驗證均方差值(RMSECV),RMSEVC最小的那個模型所對應的變量子集被選為最優變量子集。
2.5 反演建模方法
選用多元線性回歸(MLR)、 極 限 學 習 機 (ELM)2 種算法進行建模,并通過 2 種模型對訓練集與測試集預測結果的決定系數R2與均方根誤差 (RMSE)來判斷模型的反演精度與魯棒性。多元線性回歸是一種解釋單因變量與多自變量間線性關系的傳統回歸建模方法,模型結果唯一,并能夠更好地體現各個自變量與因變量間的相關程度。極限學習機是一種基于單層前饋神經網絡理論的改進算法,具有學習速率快、泛化能力強、訓練精度較高等優點。但由于極限學習機每 次運行中輸入層與隱含層之間的連接權值和隱含層神經元的閾值都是隨機生成的,其在訓練穩定性上存在不足,且容易陷入局部最優解。因此,本研究采用蝙蝠算法對極限學習機隱含層初始權重進行優化。蝙蝠算法是一種新的元啟發式優化算法。該算 法模擬自然界中蝙蝠利用回聲定位來探測獵物和規 避障礙物的原理,控制蝙蝠發出不同頻率的搜索脈沖來尋找最優解。相較于經典的粒子群算法,蝙蝠算法引入了局部搜索機制,在每輪迭代中最優蝙蝠個體會采用隨機搜索的方式進行局部尋優,有助于算法跳出局部最優 解,增強算法的全局搜索性。
結果與討論
3.1 植株氮虧缺量確定
3.1.1植株氮濃度與地上部干物質量統計分析
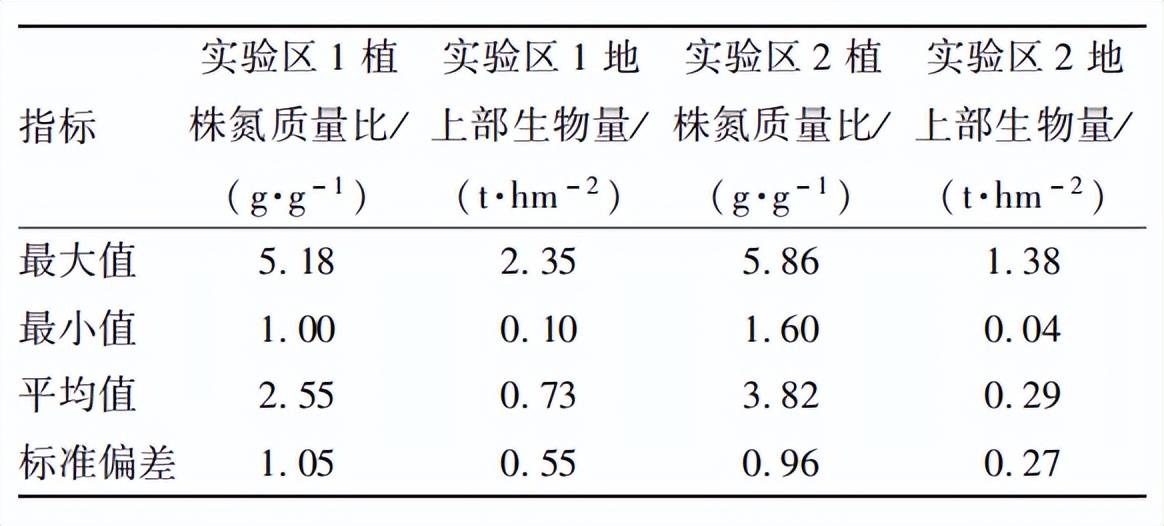
東北水稻全生育期植株氮濃度與地上部干物質量的基本信息如表 1 所示,由于實驗包含全生育期采樣數據,實驗區 1 與實驗區 2 中的植株氮濃度與 地上部干物質量離散程度較高,最大值與最小值差 別較大。其中實驗區 1 由于施氮梯度較高,其整體 氮濃度與地上部干物質量高于實驗區 2。實驗區 2 由于在分蘗期與拔節期采樣密度較高,其平均氮濃度較高,平均地上部干物質量較低。
表1植株氮濃度與地上部生物量統計
3.1.2臨界氮濃度曲線與氮虧缺量計算
根據 1.3 節提出的臨界氮濃度曲線的構建方法,本文將每個采樣日獲得的氮濃度與干物質量進行回歸擬合.計算出每個采樣日的東北水稻臨界氮濃度,之后根據各個臨界氮濃度與對應的干物質量構建東北水稻臨界氮濃度曲線(圖 2)。曲線方程為
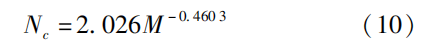
決定系數 R2為 0. 874 7,RMSE 為 0. 382 5 g/g。
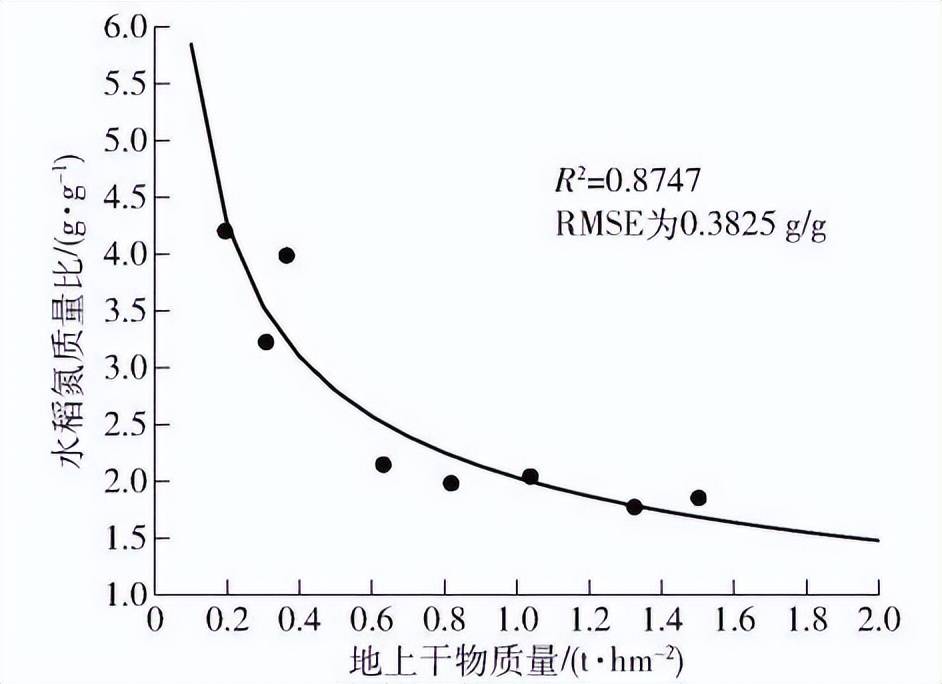
圖2 臨界氮質量比擬合曲線
曲線參數 a、 b 分別為2. 026、 - 0. 460 3,與 SONG等計算出的東北水稻臨界氮濃度曲線參數 a=1. 99、b =-0. 44 非常接近,可進一步用于東北水稻的氮虧缺量計算。根據 1. 3 節中的計算方法,本文結合樣本數據 與臨界氮濃度曲線,計算各樣本的氮虧缺量。各個氮肥梯度的平均氮虧缺量如圖 3 所示,隨著氮肥梯度的增高,氮虧缺量整體呈下降趨勢,綜合實驗區 1 與實驗區 2 氮虧缺量的下降趨勢可知,水稻最佳施 肥量在 150 ~ 200 kg / hm2之間。
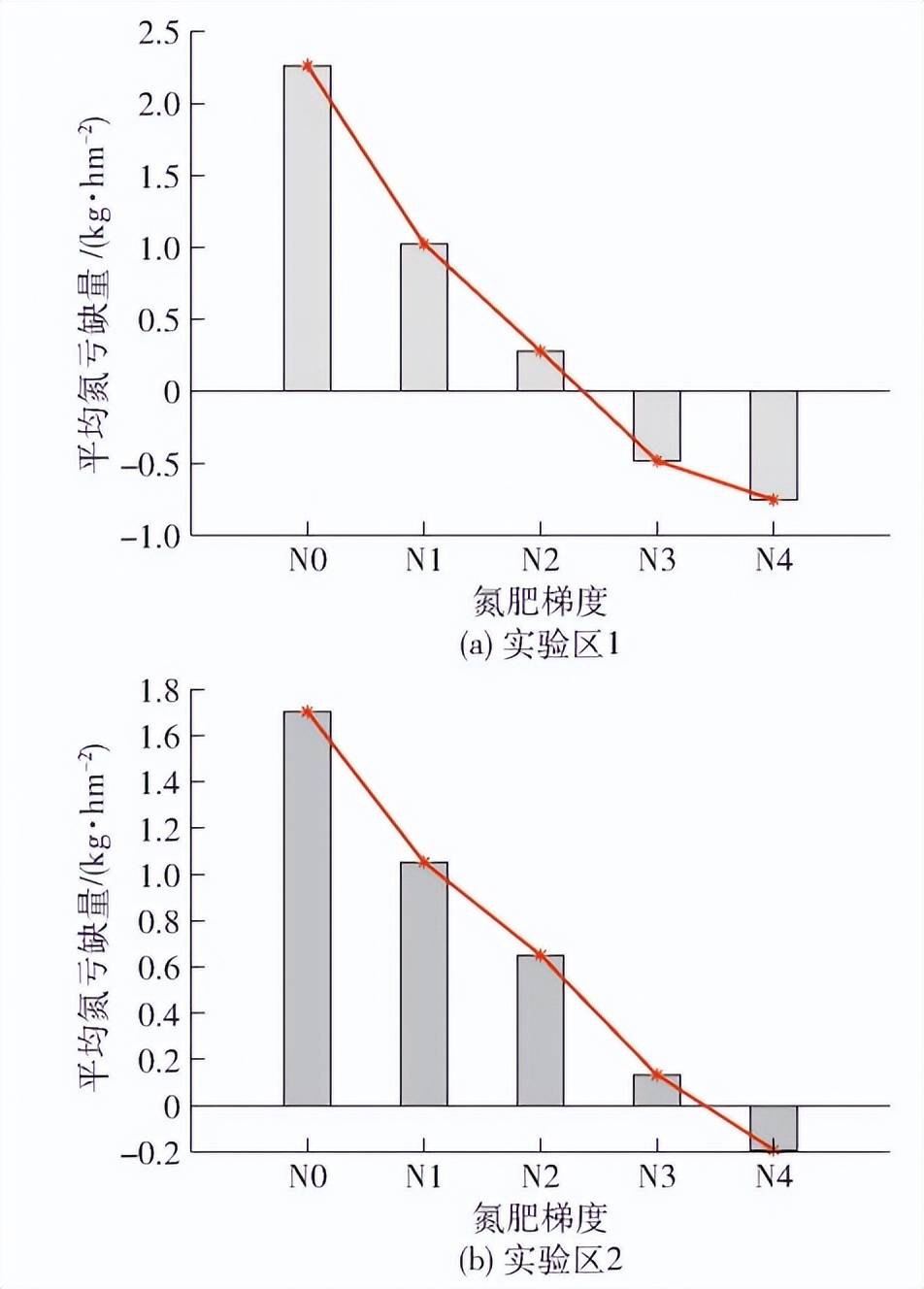
圖3 各氮肥梯度平均氮虧缺量
3.2 光譜數據處理
3.2.1光譜數據變換結果
根據 1. 4. 1 節提出的方法,本研究選取各個時 期Nand≈0kg/hm2的樣本對應光譜反射率,將其與其余樣本光譜反射率分別作比值、差值、歸一化差值變換,變換結果與相關性分析結果如圖 4、5 所示,
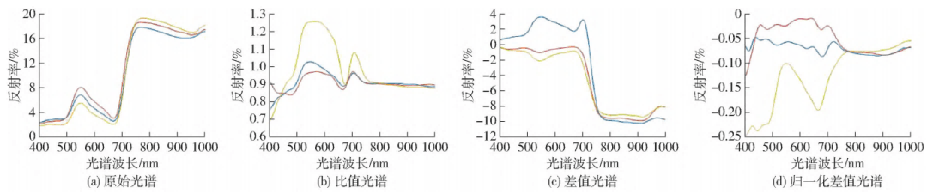
圖4 原始與變換光譜反射率

圖 5 原始與變換光譜相關性
對比可得,不同施氮水平下原始光譜全波段反射率變換趨勢基本一致,在可見光波段(波長400 ~ 700nm)光譜反射率均呈“先升后降” 的變化規律。同時,在綠波段(波長550nm 附近) 出現明顯的反射峰,在紅波段(波長680nm 附近) 出現明顯的吸 收谷。在波長680 ~ 770nm內不同施氮水平的光譜 反射率曲線變化基本一致,反射率急劇升高,在近紅 外波段(770 ~ 1 000nm)形成較高的反射平臺;不同施氮水平下比值、差值與歸一化差值光譜反射率有一定差別,但在綠波段與紅波段差別較為明顯;在與氮虧缺量的相關性方面,4種光譜反射率與氮虧缺量的相關性圖像趨勢基本一致,在紅波段與綠波段形成 2個波峰,其中歸一化差值光譜在2個波峰處相關性最佳,其次分別是比值光譜、差值光譜與原始光譜。
3.2.2 特征波長選擇
利用CARS算法對水稻原始光譜與歸一化差值光譜反射率進行特征波長的篩選,根據交叉驗證集RMSECV確定光譜特征波長后,刪去相鄰的特征波長,并通過相關性分析選取與 Nand相關性最好的波長作為最佳特征波長。
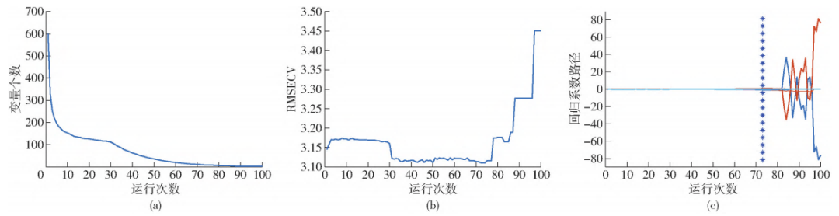
圖6 原始光譜CARS降維結果
以原始光譜選擇過程為例:由圖6a可以看出,隨著運行次數的增加,原始光譜被選出的波段數逐漸減少,圖6b中RMSECV整體呈下降趨勢,說明篩選過程中剔除的變量與SOM去除量無關,而72次迭代以后,RMSECV呈回升趨勢,表明反射率光譜中與SOM無關的大量信息或噪聲被 添加,從而導致RMSECV上升。圖6c為所有變量在每次采樣過程中的回歸系數路徑圖,表示隨著運行次數的增加各波段變量回歸系數的變化趨勢。結合圖6b分析發現 當運行次數為第72次時,RMSECV最小即所選擇的光譜變量子集最優。原始光譜與3種變換光譜的特征選擇結果如表 2 所示。
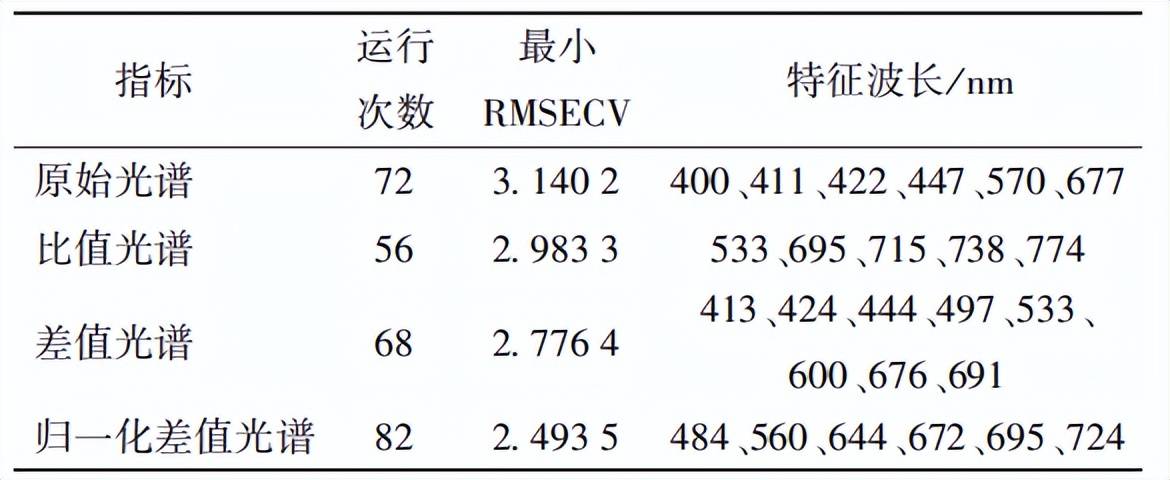
表2 CARS提取后原始光譜與變換后光譜特征波長與運行結果
3.3 氮虧缺量反演模型構建
為比較不同光譜變換方法與反演建模方法的性能,分別以經CARS算法篩選出的原始光譜、比值光譜、差值光譜、歸一化差值光譜特征波長為輸入變 量,水稻氮虧缺量為輸出變量,分別構建基于MLR、ELM 的水稻氮虧缺量反演模型。
3.3.1 基于MLR的氮虧量反演
將 4 種光譜特征波長作為輸入變量,分別構建 基于MLR的反演模型,反演結果如圖 7 所示:
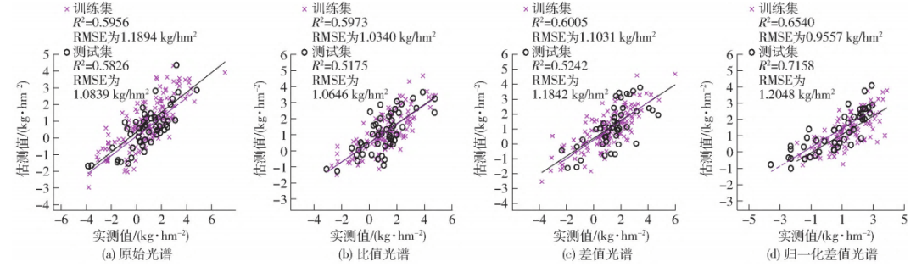
圖7 基于MLR的不同反演模型結果
其中 基于歸一化差值光譜的模型精度最高,訓練集與測試集的 R2分別為 0. 654 0、0. 715 8,RMSE分別為 0. 955 7、1. 204 8 kg/hm2;其次是基于差值光譜反演 模型,其 R2分別為 0. 600 5、0. 524 2,RMSE分別為 1. 103 1、1. 184 2 kg / hm2;然后是基于原始光譜的反演模型,R2分別為 0. 595 6、0. 582 6,RMSE分別為 1. 189 4、1. 083 9 kg/hm2。基于比值光譜的模型精度精度R2分別為0. 597 3、0. 517 5,RMSE分別為 1. 034 0、1. 0646kg/hm2;基于歸一化差值光譜的反演模型反演效果最好。
3.3.2 基于ELM的氮虧量反演
將 4 種光譜特征波長作為輸入變量,分別構建基于 ELM 的反演模型,映射函數為Sigmoid,隱含層個數分別為13、14、12、13,訓練結果如圖 8 所示。
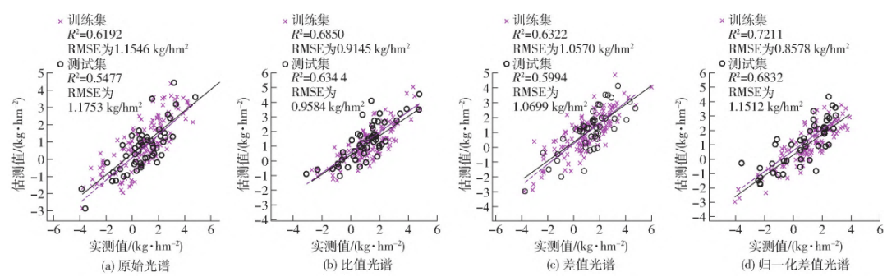
圖8 基于ELM的反演模型結果
其中基于歸一化差值光譜的模型精度最高,訓練集 與測試集的 R2分別為 0. 721 1、0. 683 2,RMSE分別為 0. 857 8、1. 151 2 kg/hm2;其次是基于比值光譜的反演模型,R2分別為 0. 685 0、0. 634 4,RMSE分別為0. 914 5、0. 958 4 kg/hm2;然后是基于差值光譜反演 模型,其 R2分別為 0. 632 2、0599 4,RMSE分別為 1. 057 0、1. 069 9 kg/hm2;最后是原始光譜的模型精度最低,R2分別為 0. 619 2、0. 547 7,RMSE分別為 1. 154 6、1. 175 3 kg/hm2。基于歸一化差值光譜的反演模型R2與 RMSE均優于其余模型。
3.4 針對不同施肥量的模型預測能力
在實驗區 1 與實驗區 2 中,以反演效果最優模 型的氮虧缺量估測值與對應梯度的氮虧缺量實測值 對比,結果如圖9所示:
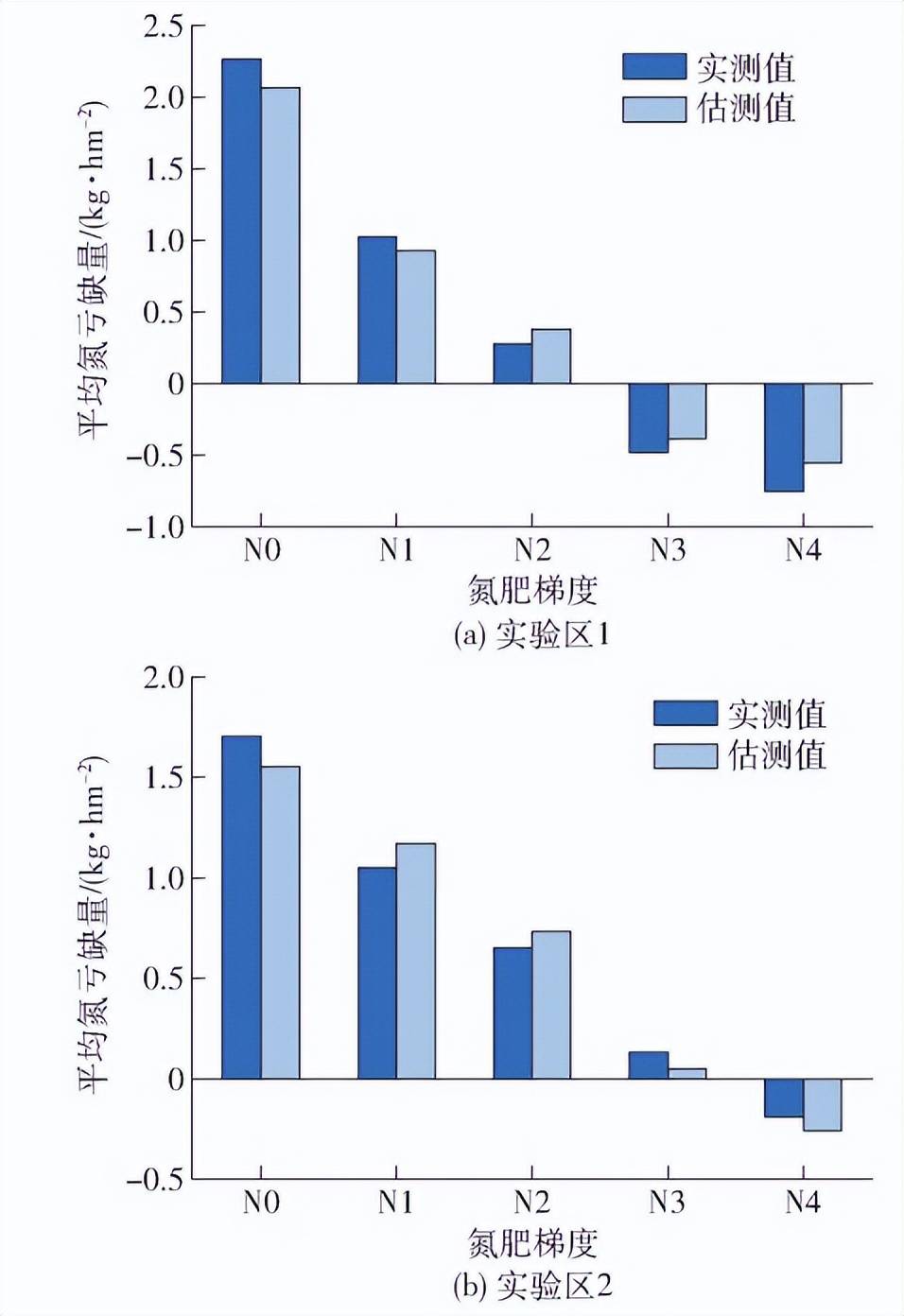
圖9 不同梯度氮虧缺量估測效果
實驗區 1 與實驗區 2 中,整 體上估測值與實測值較為相近,對水稻氮虧缺量的估測能力較強;隨著施氮量梯度的提升,對氮虧缺量的估測精度呈下降趨勢,在臨界氮濃度狀態附近估測能力較差,這可能是因為臨界氮濃度狀態下與非臨界氮濃度狀態下水稻光譜變化規律不一致,模型同時估測 2 種狀態的水稻光譜預測難度較高所致。
討論
以往學者研究焦點往往集中在如何提高獲取水稻田間氮濃度或氮營養指數信息的準確性,然而這些信息只能描述水稻的氮營養狀況,難以對水稻氮虧缺狀況進行精確的定量描述,進而指導精準施肥。本文首先通過田間采樣獲取水稻氮濃度、地上生物量與冠層光譜數據,根據前人提出的方法構建東北水稻臨界氮濃度曲線,并基于臨界氮濃度曲線計算水稻氮虧缺量。
由于臨界氮濃度表示作物達到最大干物質量所需的最小氮濃度,以臨界氮濃度作為判斷水稻氮虧缺量的標準更能反映田間水稻的氮營養狀況與實際氮需求情況。同時本研究還采用了無人機高光譜遙感技術與數據驅動的反演建模方法,通過水稻冠層光譜數據對氮虧缺量進行反演。無人機高光譜遙感技術能夠快速、大面積獲取水稻冠層光譜信息,進而對田間水稻氮營養狀況進行快速診斷,數據驅動的反演建模方法雖然可解釋性與泛化能力較差,但其能夠對光譜與氮虧缺量之間的復雜非線性關系進行準確描述,將二者結合能夠同時滿足追肥決策所需的精確性與時效性,為定量追肥決策的實現提供了解決思路。由于臨界氮濃度狀態下作物地上部氮營養狀況與冠層葉片結構達到最佳狀態,而這些都是影響水稻冠層光譜反射率的直接因素,因此,相比非臨界氮濃度狀態下的作物,臨界氮濃度下作物無論在光譜層面還是氮營養狀況層面都存在一定差異。為了在光譜層面上放大臨界氮濃度下水稻與其余水稻的差距,去除與氮虧缺量無關的冗余信息,本研究以 各時期接近臨界氮濃度狀態下光譜為標準光譜,分 別對原始光譜進行比值、差值、歸一化差值變換,之 后運用 CARS 算法提取變換光譜的特征波長。
由結果可知 2 種光譜變換均提升了其與氮虧缺量之間的相關性,其中歸一化差值變換相關性與反演精度最高,這可能是由于歸一化差值計算既通過差值計算 放大了臨界氮濃度光譜與其余冠層光譜的差異,又 統一了差值光譜數據的量綱,還對光譜數據的統計 分布性進行了歸納。在建模過程中,本文選擇蝙蝠算法優化ELM 算 法的初始權重,并將其與原始 ELM 進行對比建模。
雖然本研究利用無人機高光譜數據對水稻氮虧缺量反演取得了較好的效果,但對于實現基于無人機高光譜遙感的水稻精準追肥仍存在以下幾點問題:①本文采用的歸一化差值處理方法是基于各個采樣期臨界氮濃度狀態的水稻光譜計算的,而這些光譜如果用于其他水稻光譜的計算時,可能會因為采樣時間、水稻品種與發育狀況等因素造成誤差,進而影響氮虧缺量反演效果。②蝙蝠算法優化后的ELM 算法也存在收斂精度不高,容易陷入局部最小值等問題。后續的研究重點應集中在如何在無人機高光 譜數據中實時提取臨界氮濃度狀態下的水稻光譜與對反演算法的精度與魯棒性進行優化這兩方面上。
結論
(1)構建了東北水稻臨界氮濃度曲線,可表示 為 Nc = 2. 026M - 0. 460 3。
(2)通過 CARS 算法提取的原始光譜、比值光 譜、差值光譜與歸一化差值光譜特征波長分別為 400、411、422、447、570、677 nm,533、695、715、738、 774 nm,413、424、444、497、533、600、676、691 nm, 484、560、644、672、695、724 nm。
將馬鈴薯5個生育期的冠層原始光譜和一階微分光譜分別與對應的PNC進行相關性分析,結果如圖2所示。其中,自由度為48時,0.01相關水平閾值是0.36,黑色和紅色縱向虛線分別表示冠層原始光譜和一階微分光譜特征波長。
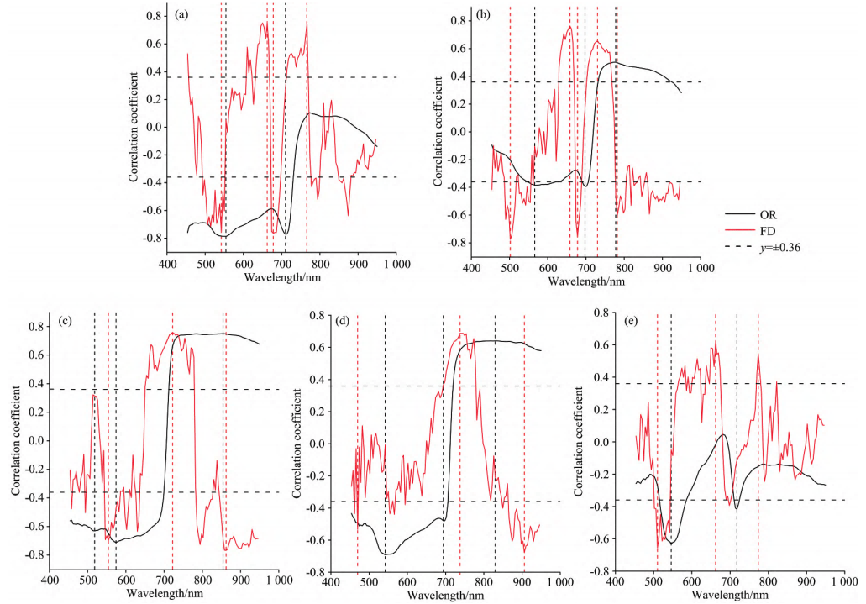
圖2冠層光譜與PNC相關性OR表示冠層原始光譜與PNC相關性曲線,FD表示一階微分光譜與PNC相關性曲線
由圖2可知,現蕾期,冠層原始光譜在波段454~730nm 范圍內與PNC呈0.01相 關 水 平,一階微分光譜主要在波段492~550、630~666、674~694和710~766nm范圍內與PNC呈0.01相關水平,因此,選取相關性較高的波長554和710nm 為冠層原始光譜特征波長,波長542、662、 678和766nm為一階微分光譜特征波長;塊莖形成期,冠層原始光譜主要在波段550~618、694~706和734~922nm范圍內與PNC呈0.01相關水平,一階微分光譜主要在波段 486~550、626~662、670~682、698~762和774~798nm范圍內與PNC呈0.01相關水平,因此選取相關性較高的波長566、698和778nm為冠層原始光譜特征波長,波長502、 658、678、730和782nm為一階微分光譜特征波長;塊莖增 長期,冠層原始光譜主要在波段454~698和714~950nm 范圍內與PNC呈0.01相關水平,一階微分光譜主要在波段546~582、650~778和846~946nm范圍內與PNC呈0.01 相關水平,因此,選取相關性較高的波長518、574和854nm為冠層原始光譜的特征波長,波長554、722和862nm 為一 階微分光譜的特征波長;淀粉積累期,冠層原始光譜主要在波段454~706和722~950nm范圍內與PNC呈0.01水平 相關,一階微分光譜主要在波長470nm、波 段694~778和866~946nm范圍內與PNC呈0.01相關水 平,因此,選取相關性較高的波長542、694和830nm為冠層原始光譜的特征波長,波長470、738和906nm為一階微分光譜的特征波長;成熟期,冠層原始光譜主要在波段 518~582和 714~ 722nm范圍內與PNC呈0.01相關水平,一階微分光譜主要在波段502~542、650~674和770~778nm范圍內與PNC呈0.01相關水平,因此,選取相關性較高的波長546和718 nm為冠層原始光譜的特征波長,波長510、662和774nm為一階微分光譜的特征波長。
3.2 圖像特征與PNC相關性分析
為探究高光譜圖像特征對估算馬鈴薯PNC的影響,利用GLCM和顏色矩分別提取了冠層原始光譜特征波長對應的圖像的紋理和顏色特征,并分析與PNC的相關性,結果如圖3所示。由圖3可知,馬鈴薯現蕾期,與 PNC相關性較高的前5個圖像特征分別是710Var(波長701nm 對應的 Var紋 理)、554Var、554Mea、710Cor和 554Ent,相關系數絕對值位于 0.78~0.86之間;塊莖形成期,相關性較高的前5個圖像特 征分別是698Hom 、698Sec、698Ent、698Cor和566Mea,相 關 系 數 絕對值位于0.79~0.85之間;塊莖增長期,相關性較高的前 5個圖像特征 分 別 是518Ske、518Var、854Ent、854Sec和574Con, 相關系數絕對值位于0.65~0.75之間;淀粉積累期,相關性 較高的前5個圖像特征分別是542Mea、542Ske、542Ent、542Sec 和542Cor,相關系數絕 對 值 位 于 0.60~0.69之 間;成 熟 期, 相關性較高的前5個圖像特征分別是546Mea、546Ent、546Sec、 546Cor和546Con,相關系數絕對值位于0.53~0.63之間。5個生育期篩選的相關性較高的前5個圖像特征均與 PNC 達 到 0.01相關水平,且都含有紋理和顏色2種特征,這說明紋理和顏色特征與馬鈴薯PNC的聯系較為密切。
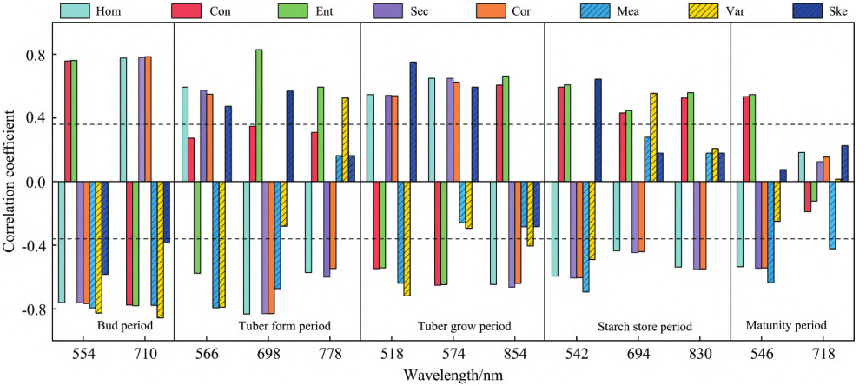
圖3圖像特征與PNC相關性
3.3 馬鈴薯PNC估算
3.3.1 單一模型變量估算馬鈴薯 PNC
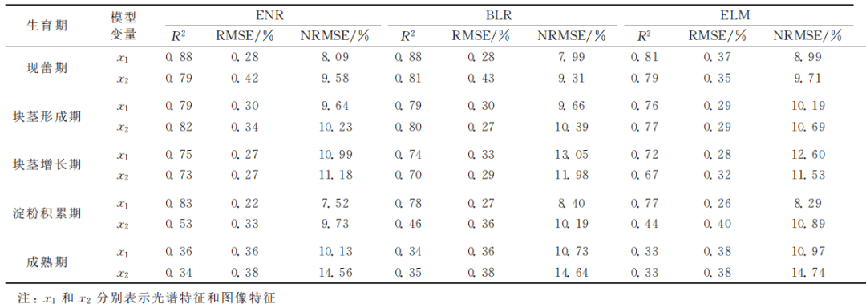
分別基于馬鈴薯5個生育期冠層光譜特征波長和相關性較高的前5個圖像特征,利用ENR、BLR 和 ELM3種方法構建PNC估算模型并驗證,建模和驗證結果如表1和 表2 所示。由表1和 表 2可 知,基 于 光 譜 特 征 (x1)和 圖 像 特 征 (x2)利用3種方法構建的馬鈴薯各生育期PNC估算模型均表現為現蕾期到淀粉積累期估算效果較好,成熟期估算效果較差。其中,現蕾期到塊莖增長期,利用3種方法基于光譜特征構建的模型效果略優于圖像特征,但相差不大;淀 粉積累期,基于圖像特征的估算效果開始變差,這一時期,光 譜特征構建的模型效果明顯優于圖像特征;成熟期,基于2種 模型變量的估算效果均明顯變差,基于光譜特征的建模效果優于圖像特征,驗證效果二者相差不大。綜合5個生育期的建模和驗證結果可知,基于同種模型變量,利用ENR構建的PNC估算模型效果較優,BLR方法次之,ELM方法較差。
表1 各生育期基于單一模型變量估算馬鈴薯PNC的建模結果
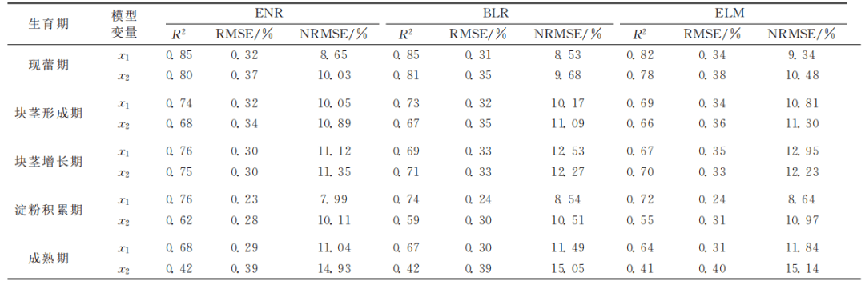
表2 各生育期基于單一模型變量估算馬鈴薯PNC的驗證結果
3.3.2 結合光譜和圖像特征估算馬鈴薯
PNC為探究結合高光譜圖像和光譜特征估算馬鈴薯PNC的效果,基于冠層光譜特征波長及篩選的與PNC相關性較高的紋理和顏色特征,分別利用3種方法構建馬鈴薯5個生育期的PNC估算模型并驗證,結果如表3和圖4所示。由表3和圖4可知,與單一模型變量相似,基于圖譜融合特征(x3) 構建的馬鈴薯PNC估算模型在現蕾期到淀粉積累期效果較好,成熟期效果較差。綜合表1、表2、表3和圖4的結果可 知,現蕾期到淀粉積累期,以圖譜融合特征為模型變量的PNC估算模型的精度和穩定性均明顯高于單一光譜特征和圖像特征,而成熟期,圖譜融合特征的估算效果與單一光譜特征相差不大。基于圖譜融合特征利用3種方法估算馬鈴薯PNC的效果為ENR較優,BLR次之,ELM 較差。
表3各生育期基于融合特征估算馬鈴薯PNC的建模結果
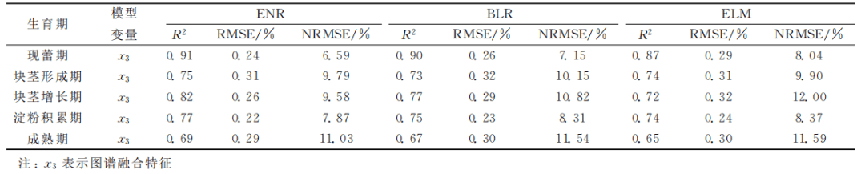
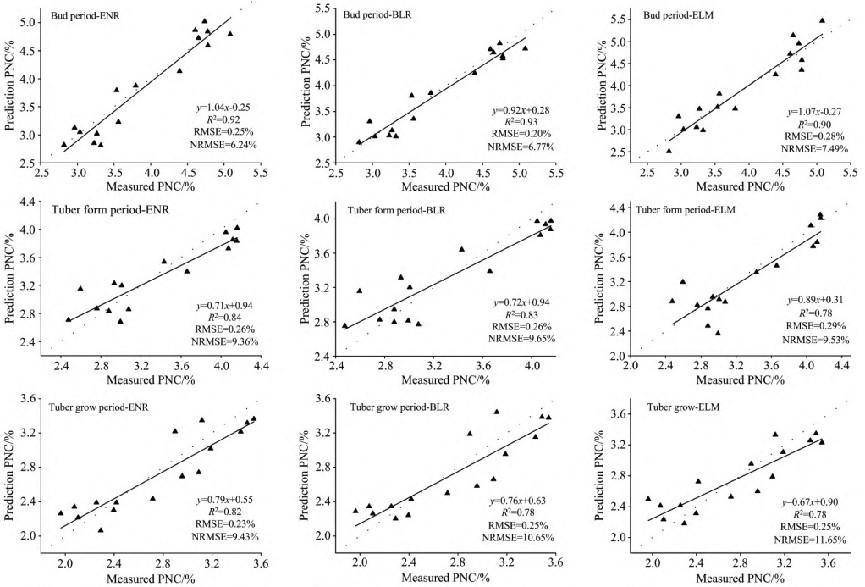
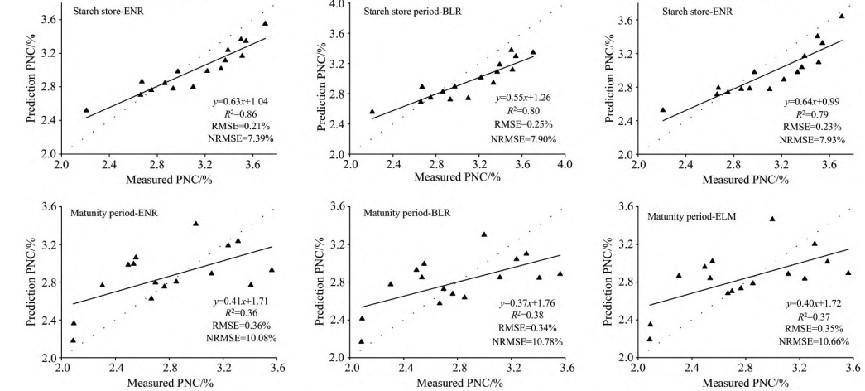
圖4 各生育期基于融合特征估算馬鈴薯PNC的驗證效果
為探究高光譜圖像特征估算馬鈴薯PNC的效果,分別基于光譜特征和圖像特征利用3種方法構建馬鈴薯5個生育期的PNC估算模型。由結果可知,現蕾期到塊莖增長期,以圖像特征為模型變量構建的PNC估算模型的估算效果與光譜特征相差不大,這表明圖像特征能較好地反映馬鈴薯的PNC狀況,其原因是,作物植株氮含量的變化不僅會引起冠層光譜特性發生改變,也會導致冠層凸凹部分的灰度值及亮度值出現差異,即圖像的紋理和顏色差異,因此,圖像特征也能較好地估算PNC;淀粉積累期,光譜特征估算PNC的效果明顯優于圖像特征,其原因是,淀粉積累期,部分馬鈴薯植株開始衰老,葉片逐漸枯黃,紋理減少,顏色特征減弱,導致圖像特征與PNC的相關性降低。成熟期,2種模型變量構建的PNC估算模型均未取得較好的效果,其原因是,馬鈴薯生長后期,受降雨較 多影響,部分馬鈴薯植株枯死凋零, 葉片迅速脫落,這一時期提取的光譜和圖像特征均不能反映馬鈴薯真實的生長狀態,故模型估算效果較差。
為探究圖譜融合特征估算馬鈴薯PNC的效果,以光譜特征結合圖像特征為模型變量,利用3種方法構建馬鈴薯5個生育期的PNC估算模型。由結果可知,現蕾期到淀粉積累 期,相較于單一光譜特征和圖像特征,圖譜融合特征構建的模型R2均有所提高,RMSE和NRMSE均有所下降,其原因是,圖譜融合特征包含不同氮營養狀況的作物冠層光譜和圖像兩方面的信息,為估算PNC提供了更多的有效信息,能更準確地反映PNC的變化情況。
成熟期,圖譜融合特征估算PNC的效果明顯變差,其原因是,受降雨等因素的影響,這一時期提取的光譜和圖像特征不能反映馬鈴薯真實的生長狀態,二者結合也未能提高模型的精度。利用ENR、BLR和 ELM3種方法構建馬鈴薯PNC估 算模型,綜合各生育期的建模和驗證結果可知,基于同種模型變量,利用ENR方法估算馬鈴薯PNC效果最優,BLR 次 之,ELM最差。其原因是,ENR在損失函數中同時引入L1和L2懲罰項,提高了對自變量的篩選和縮減能力,能更有效地利用多個光譜和圖像特征對PNC進行估算;BLR雖能充分利用樣本數據,但效果不如 ENR,可 能 原 因 是 BLR過于依賴先驗信息,導致模型的精度有所降低;ELM雖具有良好的泛化性能,但對較小的數據集優勢不明顯,導致模型精度不高。此外,本研究僅采用 了1年的馬鈴薯數據,后續將采用不同地點及年限的馬鈴薯數據驗證所得結論,以期得到普適的馬鈴薯PNC估算模型。
研究方法
(1)利用相關系數法篩選的馬鈴薯5個生育期的冠層光譜特征波長存在差異,但多數集中于可見光區域。
(2)基于冠層原始光譜特征波長圖像篩選的5個圖像特征與馬鈴薯PNC均達到0.01相關水平,且都包含紋理和顏色2種特征。
(3)基于光譜特征、圖像特征和圖譜融合特征構建的馬鈴薯 PNC估算模型均表現為現蕾期到淀粉積累期估算效果較好,成熟期效果較差,且現蕾期到淀粉積累期圖譜融合特征的估算效果明顯優于單一光譜特征和單一圖像特征。
(4)馬鈴薯各生育期基于同種模型變量利用ENR方法構建的PNC估算模型效果較優,BLR方法次之,ELM方法較差。其中,以圖譜融合特征為模型變量,利用ENR構建的PNC估算模型效 果最好。該研究可為馬鈴薯氮肥的精準管理提供一種新的技術參考。
推薦:
便攜式地物光譜儀iSpecField-NIR/WNIR
專門用于野外遙感測量、土壤環境、礦物地質勘探等領域的最新明星產品,由于其操作靈活、便攜方便、光譜測試速度快、光譜數據準確是一款真正意義上便攜式地物光譜儀。
無人機機載高光譜成像系統iSpecHyper-VM100
一款基于小型多旋翼無人機機載高光譜成像系統,該系統由高光譜成像相機、穩定云臺、機載控制與數據采集模塊、機載供電模塊等部分組成。無人機機載高光譜成像系統通過獨特的內置式或外部掃描和穩定控制,有效地解決了在微型無人機搭載推掃式高光譜照相機時,由于振動引起的圖像質量較差的問題,并具備較高的光譜分辨率和良好的成像性能。

便攜式高光譜成像系統iSpecHyper-VS1000
專門用于公安刑偵、物證鑒定、醫學醫療、精準農業、礦物地質勘探等領域的最新產品,主要優勢具有體積小、幀率高、高光譜分辨率高、高像質等性價比特點采用了透射光柵內推掃原理高光譜成像,系統集成高性能數據采集與分析處理系統,高速USB3.0接口傳輸,全靶面高成像質量光學設計,物鏡接口為標準C-Mount,可根據用戶需求更換物鏡。

審核編輯黃宇
-
光譜
+關注
關注
4文章
819瀏覽量
35155 -
成像系統
+關注
關注
2文章
195瀏覽量
13924 -
無人機
+關注
關注
229文章
10420瀏覽量
180156
發布評論請先 登錄
相關推薦
基于無人機高光譜影像的水稻分蘗數監測方法研究

基于無人機高光譜遙感的河湖水環境探測
基于無人機多光譜遙感的棉花生長參數和產量估算
無人機機載高光譜成像系統的應用及優勢
地物光譜儀:水稻高光譜與葉綠素含量研究

基于無人機高光譜謠感的蘊地退化指示物種的識別
從哪些角度選擇高光譜遙感成像光譜儀?這些廠家比較有實力!
基于無人機遙感的作物長勢監測研究進展

基于無人機高光譜遙感的荒漠化草原地物分類研究2.0
基于無人機高光譜遙感的典型草原打草對植被表型差異分析
基于無人機高光譜遙感的荒漠化草原地物分類研究1.0
比較基于無人機高光譜影像和傳統方法的土壤類型分類精度

無人機高光譜影像在地質勘探中的應用

無人機高光譜影像是否真的可以提升農業生產效率?

[萊森光學]使用無人機高光譜成像系統進行地表監測
![[<b class='flag-5'>萊</b><b class='flag-5'>森</b><b class='flag-5'>光學</b>]使用<b class='flag-5'>無人機</b><b class='flag-5'>高</b><b class='flag-5'>光譜</b>成像系統進行地表監測](https://file1.elecfans.com//web2/M00/BD/DC/wKgaomWnauWAWwIWAAIKWf6e6I8527.png)





 工商網監
工商網監
評論