


一、下載LIBSVM工具包
首先將LIBSVM工具包下載至SVM EXAMPLE的目錄下。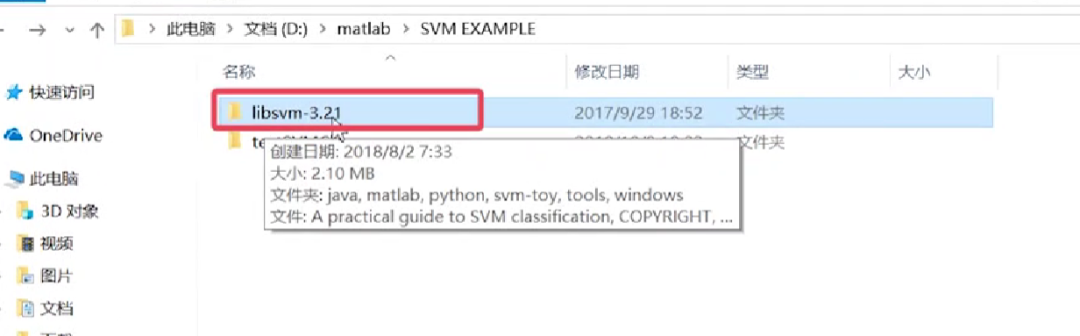
圖片來源:中國慕課大學《機器學習概論》
然后將LIBSVM的路徑加載至MATLAB的路徑中,以使MATLAB可找到LIBSVM工具包中所有與MATLAB有接口的函數(個人理解:經過此步驟后,MATLAB可以調用LIBSVM工具包中的函數)。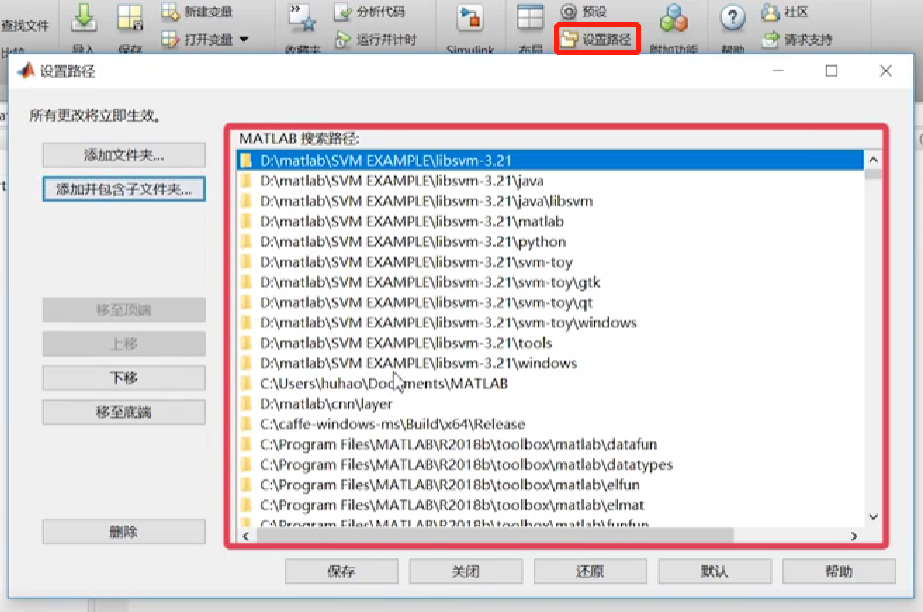
圖片來源:中國慕課大學《機器學習概論》
二、數據預處理
處理兵(車)王問題的MATLAB程序文件名稱為:testSVMChessLibSVM.m。該MATLAB程序采用讀文件的方式獲取數據,并將六維數據(六維數據表示三個棋子的位置)存儲于xapp中,一維數據(一維數據表示某一情況下,兵(車)王問題返回結果)存儲于yapp中。 
圖片來源:中國慕課大學《機器學習概論》
獲取數據后,首先需所有28056個數據順序打亂,再將5000個數據作為訓練集,將23056個數據作為測試集,以保證訓練集和測試集的選擇完全隨機。之后將訓練集和測試集歸一化。 

圖片來源:中國慕課大學《機器學習概論》
該MATLAB程序選擇的核函數是RBF核函數(高斯徑向基函數核),并根據LIBSVM網站,將超參數c的取值范圍選定為2-5~215,超參數g(gamma,gamma代表RBF核函數中1/σ2的值)取值范圍選定為2-15~23。
三、確定超參數c和g的值
在上述超參數c和g的取值范圍內遍歷所有c和g的組合,尋找識別率最大的c和g組合的機器學習模型。
為估計識別率,需要在5000個訓練集中選取部分數據作為估計識別率的數據。所選取估計識別率的數據不能與訓練機器學習模型的數據相同,否則會導致過擬合(OVERFITTING),從而導致估計識別率高于實際識別率。估計識別率的數據與訓練機器學習模型的數據相同類似于學生考試的題目與日常練習題目相同,若學生考試的題目與日常練習題目相同,則學生的考試成績將偏高。
為充分利用訓練集數據,機器學習模型訓練常采用交叉驗證的方式估計識別率。在該MATLAB程序中,訓練集數據被等分為5份,每份1000個數據,分別以A、B、C、D、E標號,然后進行下述訓練和估計:
(1)采用A、B、C、D訓練,采用E估計識別率;
(2)采用A、B、C、E訓練,采用D估計識別率;
(3)采用A、B、D、E訓練,采用C估計識別率;
(4)采用A、C、D、E訓練,采用B估計識別率;
(5)采用B、C、D、E訓練,采用A估計識別率; 最后將五個識別率取平均值,得出總識別率,該過程被稱為五折交叉驗證(5-fold cross validation),LIBSVM工具包中“-v 5”表示五折交叉驗證。 
圖片來源:中國慕課大學《機器學習概論》
交叉驗證在訓練數據數量不變的情況下,保證采用更多的數據訓練和估計識別率,從而估計出更準確的識別率。交叉驗證的劣勢是增加模型訓練的時間。
交叉驗證的形式之一是留一法(LEAVE-ONE-OUT),即每次采用一個數據估計識別率,剩余數據均參與訓練。留一法常被用于訓練數據較少且需要精確估計識別率的情況。
在該MATLAB程序中,共包含兩次交叉驗證,第一次交叉驗證初步確定超參數c和g的組合,第二次交叉驗證更精確地確定超參數c和g的組合。
四、訓練機器學習模型
在確定超參數c和g的組合后,使用該超參數c和g的組合和5000個訓練樣本得出最終的機器學習模型,圖一為所得出的機器學習模型的參數,其中,“nr_class:2”表示此機器學習模型是二分類模型,“totalSV:220”表示此機器學習模型具有220個支持向量,“rho:39.9485”表示b的值為39.9485。

圖一,圖片來源:中國慕課大學《機器學習概論》
最后,采用測試集的數據測試模型,得出識別率為99.61%。
審核編輯:劉清
-
存儲器
+關注
關注
38文章
7653瀏覽量
167585 -
MATLAB仿真
+關注
關注
4文章
176瀏覽量
20401 -
機器學習
+關注
關注
66文章
8507瀏覽量
134731 -
LibSvm
+關注
關注
0文章
5瀏覽量
6565
原文標題:機器學習相關介紹(17)——支持向量機(兵(車)王問題MATLAB程序)
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

四種支持向量機用于函數擬合與模式識別的Matlab示例程序
基于改進支持向量機的貨幣識別研究
基于支持向量機(SVM)的工業過程辨識
支持向量機的故障預測模型
MATLAB的循環向量化編程方法的詳細資料研究
什么是支持向量機 什么是支持向量
支持向量機(原問題和對偶問題)

支持向量機(兵(車)王問題程序設計)






 工商網監
工商網監

評論