") 模型精度驗證及調(diào)優(yōu)建議
模型精度驗證及調(diào)優(yōu)建議
當您在板端驗證.bin或在python端評測quantized.onnx發(fā)現(xiàn)精度不及預期時(精度損失超過4%),可參照本文第二章所述步驟排查問題。若精度損失較小,則可參考本文第三章嘗試精度調(diào)優(yōu)。
在開始定位模型精度問題之前,我們建議您可以先瀏覽一下模型轉(zhuǎn)換的內(nèi)部過程解讀,這將有助于您理解并排查數(shù)據(jù)和yaml文件準備過程中的問題。
1 內(nèi)部過程詳解
模型轉(zhuǎn)換完成浮點模型到地平線混合異構(gòu)模型的轉(zhuǎn)換。為了使得這個異構(gòu)模型能快速高效地在嵌入式端運行,模型轉(zhuǎn)換重點在解決 輸入數(shù)據(jù)處理 和 模型優(yōu)化編譯 兩個問題。
1.1 輸入數(shù)據(jù)處理
輸入數(shù)據(jù)處理方面我們?yōu)槟P筒迦肓祟A處理節(jié)點,幫助實現(xiàn)硬件通路數(shù)據(jù)和模型輸入數(shù)據(jù)的轉(zhuǎn)換對齊。因為地平線的邊緣AI計算平臺會為某些特定類型的輸入通路提供硬件級的支撐方案, 但是這些方案的輸出不一定符合模型輸入的要求。 例如視頻通路方面就有視頻處理子系統(tǒng),為采集提供圖像裁剪、縮放和其他圖像質(zhì)量優(yōu)化功能,這些子系統(tǒng)的輸出往往是yuv420格式圖像, 而我們的算法模型往往是基于bgr/rgb等一般常用圖像格式訓練得到的。為減少客戶板端部署時的工作量,我們將幾種常見的圖像格式轉(zhuǎn)換以及常用的圖像標準化操作固化進了模型當中,其表現(xiàn)為模型input節(jié)點之后插入了預處理節(jié)點HzPreprocess(您可以使用開源工具 Netron 觀察轉(zhuǎn)換過程中的中間產(chǎn)物)。
轉(zhuǎn)換過程中,工具會根據(jù)yaml文件中 input_type_rt 和 input_type_train 指定的數(shù)據(jù)格式自動向HzPreprocess節(jié)點中添加數(shù)據(jù)格式轉(zhuǎn)換的操作。根據(jù)實際生產(chǎn)經(jīng)驗, 并不是任意type組合都是需要的,為避免誤用,我們只開放了一些固定的type組合如下表所示。
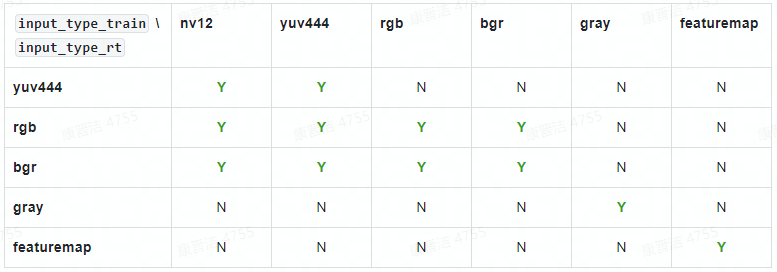
表格中第一行是 input_type_rt 中支持的類型,第一列是 input_type_train 支持的類型, 其中的 Y/N 表示是否支持相應的 input_type_rt 到 input_type_train 的轉(zhuǎn)換。 在.bin模型部署階段,您只需要關注input_type_rt的數(shù)據(jù)格式。 以下是對 input_type_rt每種格式的說明:
(1) rgb、bgr和gray都是比較常見的圖像數(shù)據(jù),注意每個數(shù)值都采用UINT8表示。
(2) yuv444是一種常見的圖像格式,注意每個數(shù)值都采用UINT8表示。
(3) nv12是常見的yuv420圖像數(shù)據(jù),每個數(shù)值都采用UINT8表示。
(4) nv12有個比較特別的情況是 input_space_and_range 設置 bt601_video (配置參數(shù)介紹可參考《horizon_ai_toolchain_user_guide》3.4. 轉(zhuǎn)換模型 章節(jié)),較于常規(guī)nv12情況,它的數(shù)值范圍由[0,255]變成了[16,235], 每個數(shù)值仍然采用UINT8表示。
(5) featuremap適用于以上列舉格式不滿足您需求的情況,此type只要求您的數(shù)據(jù)是四維的,每個數(shù)值采用float32表示。 例如雷達和語音等模型處理就常用這個格式。
圖像數(shù)據(jù)標準化操作則是根據(jù)yaml文件中的norm_type、mean_value、scale_value參數(shù),判斷是否向HzPreprocess節(jié)點中添加mean/scale操作。
1.2 模型優(yōu)化編譯
模型優(yōu)化編譯方面則完成了模型解析、模型優(yōu)化、模型校準與量化、模型編譯等幾個重要過程。其內(nèi)部工作過程及輸入數(shù)據(jù)準備示例如下圖所示。
暫時無法在文檔外展示此內(nèi)容
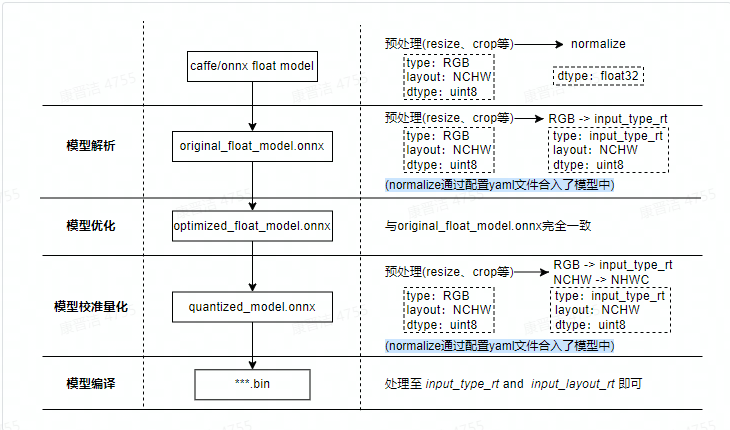
*最右邊一列為各階段圖像輸入類模型預處理示例,主要差異在于normalize操作以及圖像格式的轉(zhuǎn)換。若為featuremap輸入,則預處理不存在上述差異。
模型解析階段 對于Caffe浮點模型會完成到ONNX浮點模型的轉(zhuǎn)換。 在原始浮點模型上會根據(jù)轉(zhuǎn)換配置中的配置參數(shù)決定是否加入HzPreprocess節(jié)點,此階段產(chǎn)出original_float_model.onnx。 這個ONNX模型計算精度仍然是float32,和原始浮點模型輸出結(jié)果一致。
理想狀態(tài)下,這個HzPreprocess節(jié)點應該完成 input_type_rt 到 input_type_train 的完整轉(zhuǎn)換, 實際情況是整個type轉(zhuǎn)換過程會配合地平線AI芯片硬件完成,ONNX模型里面并沒有包含硬件轉(zhuǎn)換的部分。 因此ONNX的真實輸入類型會使用一種中間類型,這種中間類型就是硬件對 input_type_rt 的處理結(jié)果類型, 數(shù)據(jù)layout(NCHW/NHWC)會保持和原始浮點模型的輸入layout一致。 每種 input_type_rt 都有特定的對應中間類型,如下表:

表格中第一行是 input_type_rt 指定的數(shù)據(jù)類型,第二行是特定 input_type_rt 對應的中間類型, 這個中間類型就是original_float_model.onnx的輸入類型。每個類型解釋如下:
(1) yuv444_128/RGB_128/BGR_128/GRAY_128為對應input_type_rt減去128的結(jié)果。
(2) featuremap 是一個四維張量數(shù)據(jù),每個數(shù)值采用float32表示。
模型優(yōu)化階段 實現(xiàn)模型的一些適用于地平線平臺的算子優(yōu)化策略,例如BN融合到Conv等。 此階段的產(chǎn)出是optimized_float_model.onnx,這個ONNX模型的計算精度仍然是float32,經(jīng)過優(yōu)化后不會影響模型的計算結(jié)果。 模型的輸入數(shù)據(jù)要求還是與前面的original_float_model一致。
模型校準階段 會使用您提供的校準數(shù)據(jù)來計算必要的量化閾值參數(shù),這些參數(shù)會直接輸入到量化階段,不會產(chǎn)生新的模型狀態(tài)。
模型量化階段 使用校準得到的參數(shù)完成模型量化,此階段的產(chǎn)出是quantized_model.onnx。 這個模型的輸入計算精度已經(jīng)是int8,使用這個模型可以評估到模型量化帶來的精度損失情況。 這個模型要求輸入的基本數(shù)據(jù)格式仍然與 original_float_model 一樣,不過layout和數(shù)值表示已經(jīng)發(fā)生了變化, 整體較于 original_float_model 輸入的變化情況描述如下:
(1) 數(shù)據(jù)layout均使用NHWC。
(2) 當 input_type_rt 的取值為非 featuremap 時,則輸入的數(shù)據(jù)類型均使用int8, 反之, 當 input_type_rt 取值為 featuremap 時,則輸入的數(shù)據(jù)類型為float32。
模型編譯階段 會使用地平線模型編譯器,將量化模型轉(zhuǎn)換為地平線平臺支持的計算指令和數(shù)據(jù), 這個階段的產(chǎn)出是***.bin模型,這個bin模型是后續(xù)將在地平線邊緣嵌入式平臺運行的模型,也就是模型轉(zhuǎn)換的最終產(chǎn)出結(jié)果。
2 精度問題定位建議流程
精度問題定位流程主要包括如下三個部分:
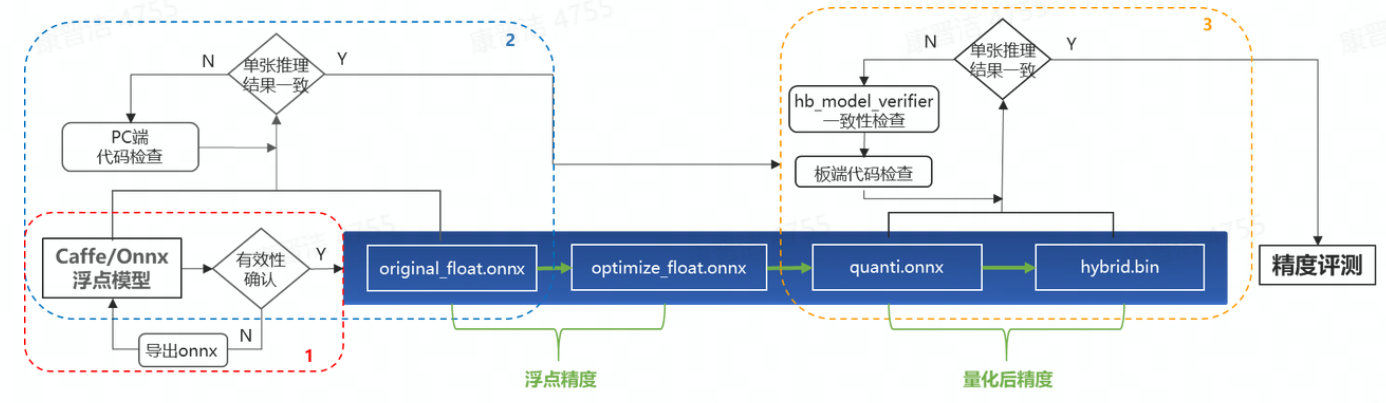
1)驗證Caffe/Onnx的有效性,確保其單張推理結(jié)果與原始浮點模型保持一致;
2)通過對比original_float_model.onnx與原始浮點模型的單張推理結(jié)果,確保PC端推理代碼的正確性;
3)通過比對quantized_model.onnx與.bin的單張推理結(jié)果,確保板端代碼與PC端代碼的一致性,以及模型集成(將quantized_model.onnx編譯為.bin)的過程沒有引入誤差。
2.1 驗證原始Caffe/Onnx模型有效性
這一步為了排查拿錯模型,或是導出onnx有誤等誤操作。onnx模型的正確性驗證,可參考如下代碼:
from horizon_nn import horizon_onnx
import horizon_nn.horizon_onnxruntime as rt
import numpy as np
import cv2
def preprocess(input_name):
# BGR->RGB、Resize、CenterCrop···
# HWC->CHW
# normalization
return norm_data
def main():
# 加載模型文件
onnx_model = horizon_onnx.load(MODEL_PATH)
# 創(chuàng)建推理Session
sess = rt.InferenceSession(onnx_model.SerializeToString())
# 獲取輸入&輸出節(jié)點名稱
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# 準備模型輸入數(shù)據(jù)
feed_dict = dict()
for input_name in input_names:
feed_dict[input_name] = preprocess(input_name)
# 開始模型推理,推理的返回值是一個list,依次與output_names指定名稱一一對應
result = sess.run(output_names, feed_dict)
# 后處理
postprocess(result)
if __name__ == '__main__':
main()
2.2 驗證PC端推理代碼的正確性
轉(zhuǎn)換完成后,將在model_output文件夾下生成四個模型,其中*original_float_model.onnx以及*optimized_float_model.onnx的精度是與原始浮點模型完全一致的。但是由于您通過配置yaml文件中的 input_type_rt 以及norm_type等參數(shù),將圖像格式轉(zhuǎn)換以及normalize這兩項常用的預處理操作固化進了模型中,因此預處理代碼會與訓練時有所差異,具體差異及注意事項可參考前文1.2節(jié)。若發(fā)現(xiàn)推理結(jié)果與浮點模型不一致,則需再次確認預處理代碼的正確性。常見錯誤如下:
(1)已在yaml文件中配置 norm_type(scale/mean),前處理仍做了重復的normalize操作
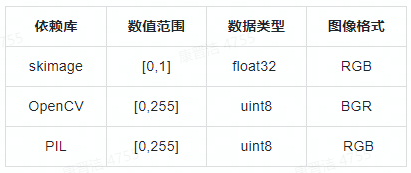
(2)讀圖方式與浮點訓練時不一致。skimage、OpenCV、PIL讀圖差異如下表所示
確保PC端代碼的正確性之后,建議您可以測試一下*quantized_model.onnx的精度或單張推理結(jié)果,確認量化后精度滿足您的預期,再至板端完成應用開發(fā)。若精度不滿足預期,則可參照第三章內(nèi)容嘗試精度調(diào)優(yōu)。
2.3 驗證.bin模型的正確性
通常來說,將*quantized_model.onnx編譯生成*.bin的過程不會引入誤差,但事有萬一,我們提供了 hb_model_verifier 工具幫助您驗證定點模型和runtime模型的一致性。具體使用方式因OE版本不同而有所差異,您可以通過 hb_model_verifier --help 查看幫助信息,或查閱《hb_mapper_tools_guide》文檔了解該工具的使用方式。驗證通過,終端將打印 Onnx and Arm result Strict check PASSED 提示信息。若驗證失敗,請將模型及OE版本號提供給地平線技術支持人員分析。
但是目前該工具只支持單輸入模型,若為多輸入模型則可使用板端 hrt_model_exec infer工具獲取模型原始輸出。為保證輸入數(shù)據(jù)的一致性,建議您將python端預處理好的數(shù)據(jù)通過 np.tofile() 函數(shù)保存為二進制文件,并通過 hrt_model_exec infer 工具的 --input_file 參數(shù)指定輸入數(shù)據(jù)(多個輸入文件請以“,”隔開),具體使用方式可通過在板端執(zhí)行 hrt_model_exec,查看幫助信息。若使用該工具得到的輸出結(jié)果與python端不一致,請將模型及OE版本號提供給地平線技術支持人員分析。
*目前 hrt_model_exec infer 工具不支持自動完成featuremap輸入的 padding 操作(該操作與硬件對齊規(guī)則相關,具體介紹請參考后文2.4節(jié)),您需要在PC端預處理時完成該操作,參考代碼如下:
pad_image = np.zeros((target_h, target_w, 3), dtype=np.int)
pad_image[:image_h, :image_w, :] = image
* target_h, target_w可通過hrt_model_exec model_info工具查看輸入節(jié)點的aligned shape屬性獲取
2.4 驗證板端推理代碼的正確性
確認前面所有環(huán)節(jié)都正常之后,最后我們就只需要排查板端推理代碼是否有誤了。常見問題有如下幾項:
(1)PC端與板端計算環(huán)境的差異(例如opencv讀圖差異、浮點計算精度不同等);
(2)輸入數(shù)據(jù)未對齊至轉(zhuǎn)換配置的input_type_rt和input_layout_rt;
(3)輸入數(shù)據(jù)不滿足對齊規(guī)則,且未修改InputTensor的aligned_shape屬性(僅針對圖像輸入)。(BPU對齊規(guī)則可參考下圖解析)
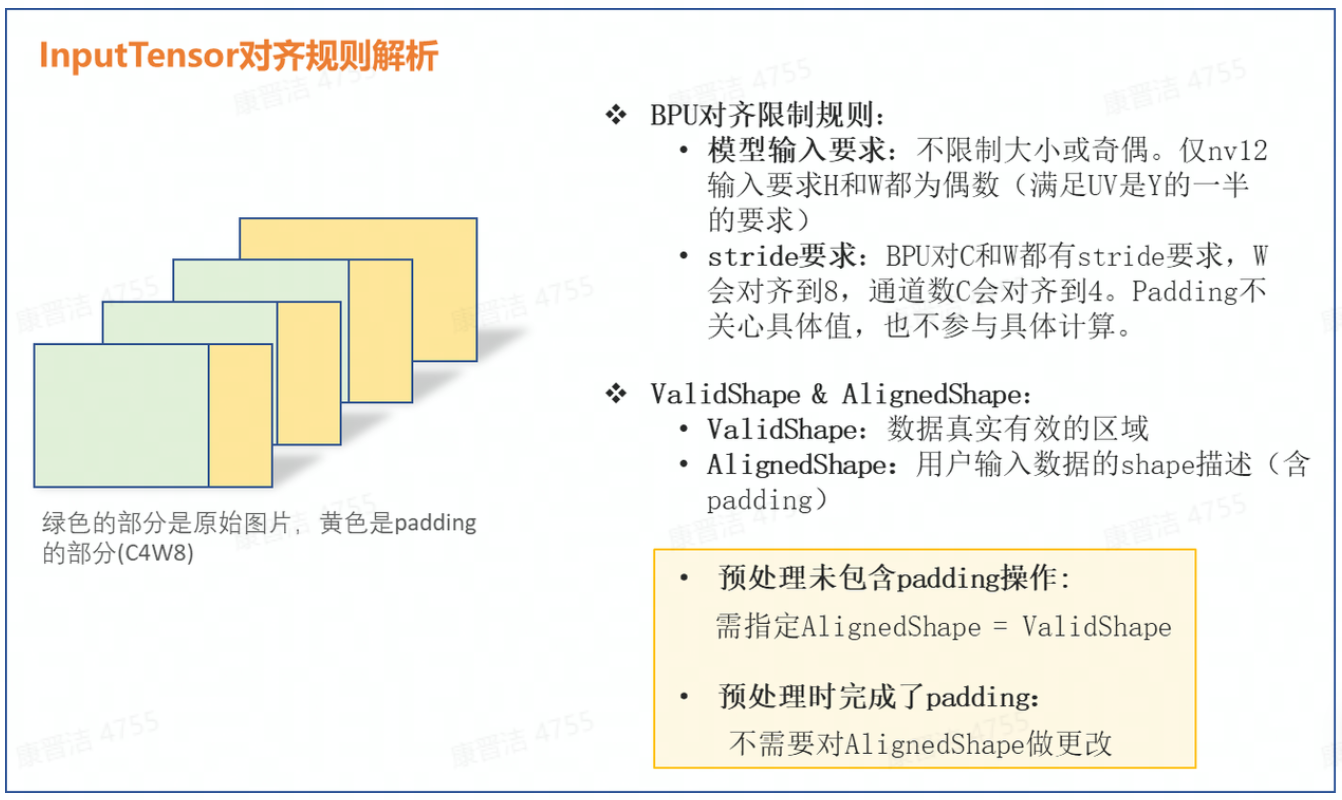
其中,featuremap輸入時較為特殊,由于預測庫不會對featuremap數(shù)據(jù)做padding操作,因此當您的模型輸入為featuremap時,需在預處理時完成數(shù)據(jù)對齊,參考代碼如下:
if (input_w == out_w) {
memcpy(out, input, static_cast(input_h * input_w) * data_size);
} else {
for (int i = 0; i < input_h; i++) {
memcpy(out, input, static_cast(input_w) * data_size);
input += input_w;
out += out_w;
}
}
3 精度調(diào)優(yōu)
3.1 后量化調(diào)優(yōu)
對于后量化的精度誤差,我們一般會通過以下 3 種方式進行優(yōu)化,且均需要在 yaml 文件配置后重新轉(zhuǎn)換模型:
1.調(diào)整校準方式
(1)calibration_type 優(yōu)先嘗試 default,除此之外還可以嘗試 kl/max;
(2)將 calibration_type 配置為 max,并配置 max_percentile 為不同的分位數(shù),我們推薦您優(yōu)先嘗試 0.99999、0.99995、0.9999、0.9995、0.999;
(3)嘗試啟用 per_channel,可與任意校準方式配合使用。
2.調(diào)準校準數(shù)據(jù)集
(1)可以嘗試適當增加或減少數(shù)據(jù)量;
(2)嘗試換一批校準數(shù)據(jù)。
參考依據(jù)為轉(zhuǎn)換日志中模型每一層輸出的余弦相似度,若您觀察到有某一層余弦相似度異常,可嘗試在yaml文件中通過 run_on_cpu 參數(shù)配置,將該層指定到cpu進行高精度計算。一般我們僅會嘗試將模型輸出層 1~2 個算子回退至 CPU,太多的CPU算子會較大程度影響模型最終性能。
3.2 Pytorch QAT訓練
如果您的模型經(jīng)過以上調(diào)優(yōu)手段還是無法解決量化精度問題,那么該模型可能確實是 后量化(post training quantization,PTQ)方案中的 corner case,只能嘗試 量化感知訓練(quantization aware training,QAT)。
目前很多開源訓練框架均已支持 QAT 訓練能力,例如 Pytorch 的 eager-mode 和 fx-graph方案,tf-lite的量化方案等等。相比于后量化,QAT 訓練在浮點模型訓練收斂后進行 finetune,其精度損失由算法同學自行訓練優(yōu)化,會更加可控,且開源社區(qū)中也有非常多的幫助資料。但 QAT 方案因為訓練成本和上手難度相對更高,所以我們更建議您在后量化實在無法解決精度問題時再選擇此方案。
地平線目前僅支持編譯 Pytorch 框架的 QAT 模型,具體示例請參考用戶手冊《horizon_ai_toolchain_user_guide》3.6.3.4 QAT模型量化編譯。
本文轉(zhuǎn)載自地平線開發(fā)者社區(qū):https://developer.horizon.ai
原作者:顏值即正義
-
數(shù)據(jù)處理
+關注
關注
0文章
611瀏覽量
28603 -
精度測量
+關注
關注
0文章
8瀏覽量
8271
發(fā)布評論請先 登錄
相關推薦
MCF8316A調(diào)優(yōu)指南

MCT8316A調(diào)優(yōu)指南
MCT8315A調(diào)優(yōu)指南
TDA3xx ISS調(diào)優(yōu)和調(diào)試基礎設施
大數(shù)據(jù)從業(yè)者必知必會的Hive SQL調(diào)優(yōu)技巧
智能調(diào)優(yōu),使步進電機安靜而高效地運行
MMC SW調(diào)優(yōu)算法
如何調(diào)優(yōu)DS160PR410實現(xiàn)出色的信號完整性
TAS58xx系列通用調(diào)優(yōu)指南
AM6xA ISP調(diào)優(yōu)指南
如何進行TI PCIe Gen5轉(zhuǎn)接驅(qū)動器調(diào)優(yōu)
OSPI控制器PHY調(diào)優(yōu)算法
深度解析JVM調(diào)優(yōu)實踐應用
鴻蒙開發(fā)實戰(zhàn):【性能調(diào)優(yōu)組件】





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論