


先楫體驗官“RSCN”評測了HPM6750的coremark跑分后(原文請至EEWORLD搜索RSCN)又出干貨!這次“RSCN”將為我們演示如何優化自己手中的HPM6750使它性能提升。
以下正文轉自EEWORLD @RSCN
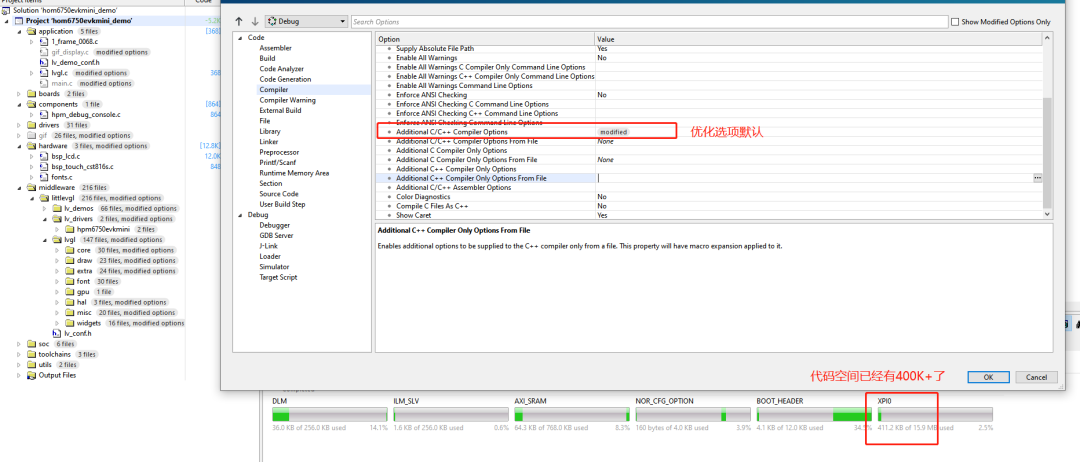
之前的coremark跑分測評中,在flash和ram運行的性能大致一樣,主要的原因還是代碼空間小于32K,這剛好是cache的空間范圍內,HPM6750有32K ICACHE和32K DCACHE,性能上是最高的,所以跑分上,兩者并沒有太大的差距。
但是,如果代碼空間超過了32K,這時候cache總會有用滿的時候,也會有不命中的情況下,這時候需要考慮的正是系統資源和編譯整合利用。
下面以littlevgl的benchmark跑分例子要進行性能提升的一個驗證方法,當然這僅僅作為參考,并不能決定大多數應用場景。
由于上個貼子說明了SPI的一點缺陷,會導致DMA的輔助功能提升并不大,在實際跑lvgl的時候,code放在flash,編譯器使用segger,代碼缺省優化,也其實沒優化的情況下,生成的代碼如下:
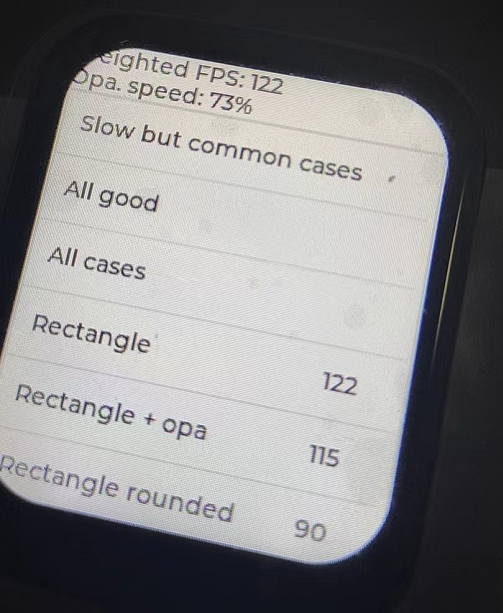
那么按照這樣燒錄進去,weightied fps大概是120多左右
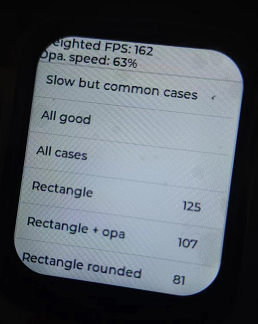
這是有點低了,先從lvgl的配置上去優化,lvgl的刷新周期,從30fps最大刷新率改為100fps刷新率,提升上也并不是很大,大概在160左右變動。

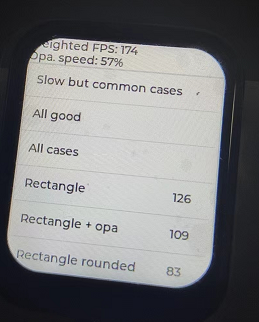
那么開O3優化的效果又是如何,再次燒錄進去,weightied fps大概是174多左右
當然也試了以下方法,實驗過程也忘了拍照,但是其實效果性能并沒有提升多少,也就180左右變動
1、改為全尺寸雙緩沖,但是其實這種對MCU屏幕有用,對于SPI屏幕上,效果并沒多少。
2、改為非全尺寸雙緩沖,大概五分之一局部刷新。
3、改為單緩沖局部刷新和單緩沖全尺寸刷新,效果均不大。
于是試著找了官方的技術,放假期間的,技術也在中午跟著我遠程調試了下,換為GCC編譯器,以及開啟了相關優化,優化提升也不明顯,大概也是180fps變動。
在調試的過程中,有個idea讓樓主茅塞頓開,也就是官方技術建議把中斷isr放在ram運行,但實際提升也不大。
于是樓主照著這個思路來看下性能有沒有增加,也就是把核心的代碼加載到ram中運行。好在HPM6750有足夠的RAM來加載,根據手冊可知道,兩核心有SLV各512K,SRAM一共1M,這是足夠加載很多核心代碼。

說干就干,在代碼上去實現的話,可以使用ATTR_RAMFUNC修飾符放在定義的函數前面,這樣編譯的時候就會加載到RAM運行。
在實際調試中,單純幾個函數的修飾并不能解決問題。也不可能去手動一個一個修飾,好在與SES可以可視化去操作加載。從ATTR_RAMFUNC,Link文件可看到。
ATTR_RAMFUNC是把函數放在了section的.fast中
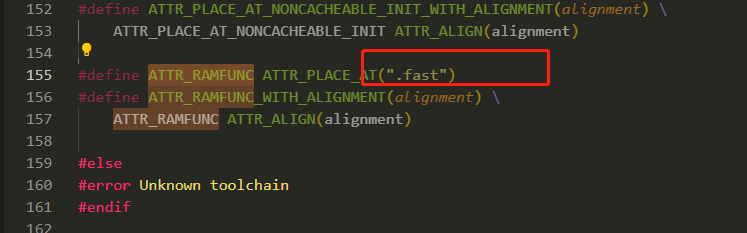
從Link可看到,fast是放在了ILM_SLV的256K空間中。

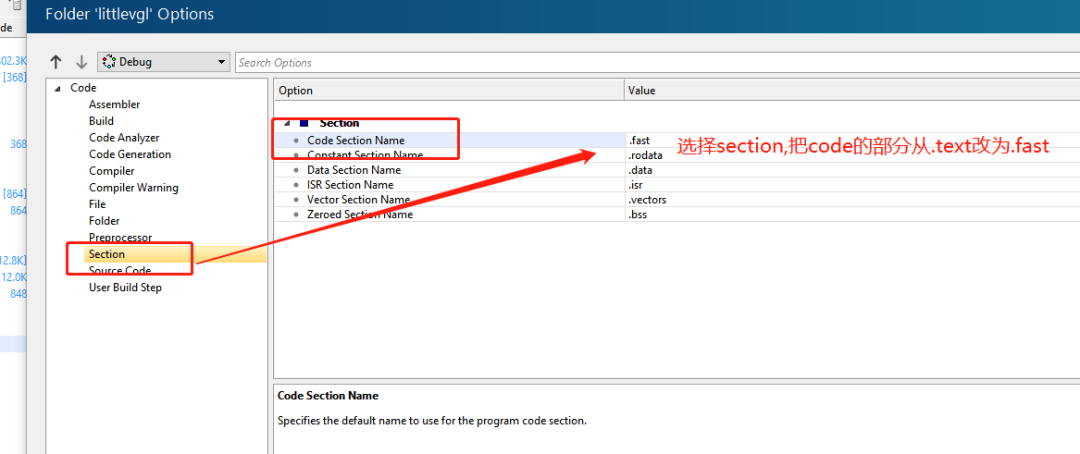
于是我們可以參考Link,自己在copy個link,把fast放在更大的RAM上,也就是SRAM上

那么ses如何去加載這些函數到RAM上了,跟keil類似
右鍵點擊需要加載的文件夾,選擇options
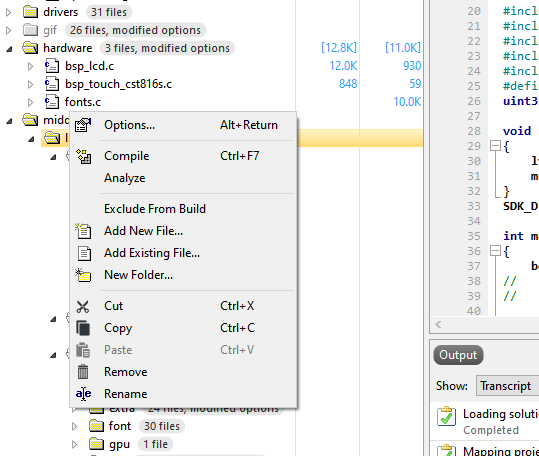
選擇code段改為.fast,這樣就可以一次搞定加載所有需要到RAM運行的函數。
根據之前的調試性能,再加載核心的放在RAM中運行,燒錄代碼進去,奇跡的時刻,從122fps提升到286,整整提升了兩倍性能,這已經對于SPI這個稍微缺陷IP,足夠有幫助了。
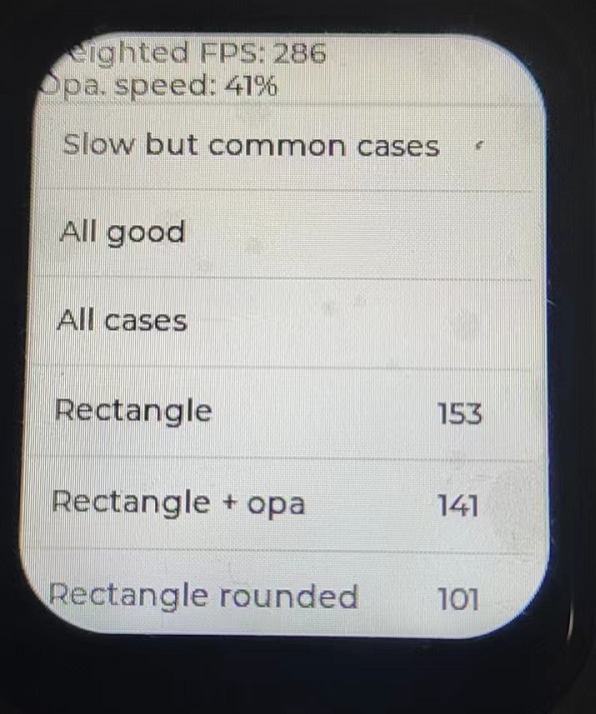
于此總結:
1、在從代碼優化,編譯器優化上,可以提高性能。
2、在1的基礎上,隨著代碼空間的增多,32k cache總有用完的時候,xip flash 也會有所損失性能,最好就是可以把主要的代碼加載到RAM中運行,更可提高性能。
3、除了32K cache的加持,內部RAM整合也有足夠2M,對于系統而言,是足夠性能整合的。
-
嵌入式
+關注
關注
5152文章
19686瀏覽量
317923
發布評論請先 登錄
CSC7137B 應用指南:小功率電源管理革新方案
【EASY EAI Orin Nano開發板試用體驗】移植LVGL9.1(C語言工程)
Silicon Labs BG2xL精簡版藍牙SoC開辟信道探測、邊緣智能應用新天地
如何在linux小核下運行lvgl?
任意波形發生器在電光調制器、量子光學和脈沖激光二極管中的應用
重磅更新 | 先楫半導體HPM_SDK v1.9.0 發布

養老機器人功能融合,芯片企業將狂卷出新天地?

基于RTThread nano的LVGL線程卡頓是什么原因引起的?
圖撲 HT 總線式拓撲圖的可視化實現
高速鏈路設計難?利用HPM6750雙千兆以太網透傳實現LED大屏實時控制





 工商網監
工商網監

評論