 為什么傳統CNN在紋理分類數據集上的效果不好?
為什么傳統CNN在紋理分類數據集上的效果不好?
作者:Trapti Kalra
來源:AI公園,編譯:ronghuaiyang
導讀
本文分析了常見的紋理數據集以及傳統CNN在紋理數據集分類上效果不佳的原因。
在機器視覺任務中,將紋理分析與深度學習結合使用,對于獲得更好的結果起到了重要作用。在前一篇文章中,我們已經討論了什么是紋理的基礎知識,不同類型的紋理,以及紋理分析在解決真正的計算機視覺任務中的適用性。我們還解釋了一些最常用和值得注意的提取紋理的技術,此外,我們還演示了如何將這些紋理提取技術與深度學習結合起來。
深度學習由多種結構組成,可用于圖像分類任務。基于深度學習的模型經常用于圖像分類任務,并在許多不同的用例中產生了出色的結果,展示了它們的有效性。幾年前,遷移學習的概念出現了,它建議使用使用大數據集訓練的模型作為特定用例的骨干,其中,預訓練的骨干模型只是通過使用特定案例的數據集來微調權重以解決特定任務。經過圖像分類訓練的預訓練模型也可用于紋理分類任務。為了檢驗現有傳統的基于cnn的紋理分類模型的效率,我們使用一些公共的基于紋理的數據集對其進行性能基準測試。我們觀察到,傳統的CNN結構(如圖5所示)很難產生較好的結果,并不是很有效地應用于紋理分類任務。
紋理分類以及常用的紋理數據集
紋理分析和分類是地形識別、自動醫療診斷、顯微圖像分析、自動駕駛汽車和爆炸危險檢測等領域的關鍵任務。在執行基于分類的任務時,紋理是一個非常重要的屬性。作為人類,我們可以直觀地看到、理解和區分紋理,但對于基于人工智能的機器來說,情況并非如此。如果一個人工智能模型能夠識別紋理,那么它在分類任務中的應用將會是一個額外的優勢。根據物體的視覺效果來理解和分類物體可以使人工智能模型更加高效和可靠。
因此,我們為紋理分類任務構建了模型,并在基于紋理的基準數據集(如DTD、FMD、和KTH)上測試模型的有效性。基于這些數據集上任何模型的準確性,我們可以理解并在一定程度上預測它在其他類似數據集上的性能。下面我們將提供關于上述數據集的詳細信息。
- DTD:它是一個基于紋理的圖像數據集,由5640張圖像組成,根據受人類感知啟發的47個類別進行組織。每個類別有120張圖片。

圖1,DTD中每個類別的圖
KTH:KTH通常被稱為KTH- tips(在不同的照明、姿勢和比例下的紋理)圖像數據庫被創建來在兩個方向上擴展CUReT數據庫,通過提供在尺度以及姿態和照明上的變化,并通過在不同的設置中對其材料的子集進行成像得到其他樣本。有11類的總樣本量是3195。
 圖2,KTH-TIPS數據集中11個類別,每個類比4張圖
圖2,KTH-TIPS數據集中11個類別,每個類比4張圖
FMD:建立這個數據庫的特定目的是捕捉一系列常見材料(如玻璃、塑料等)在現實世界中的外觀。這個數據庫中的每一張圖片(總共有10個類別,每個類別有100張圖片)都是手動從Flickr.com(在創作共用許可下)中選擇的,以確保各種照明條件、組合、顏色、紋理和材料子類型。

圖3,FMD數據集中每個類比的幾張圖
傳統CNN圖像分類
就現有的傳統CNN而言,這些大多屬于預訓練模型本身或使用這些預訓練層/權值的模型。在我們的博客中,我們將首先簡要概述什么是預訓練模型,以及如何將其應用于圖像分類任務。
現有的幾種CNN模型都是由不同的研究人員針對圖像分類的任務提出的,這些模型也可以作為許多其他圖像分類相關任務的預訓練模型。在圖5中,我們可以看到如何將預訓練的層合并到傳統的基于CNN的架構中。
在紋理分類任務的情況下,這些預先訓練的模型也可以通過遷移它們的知識,并將它們用于基于紋理的數據集。由于這些模型是為特定數據集上的圖像分類任務而建立的,而我們在一些不同的數據集上使用它們進行紋理分類,我們稱它們為預訓練模型。進一步介紹了圖像分類預訓練模型的一些關鍵思想:
什么是預訓練模型?
為了簡單地定義一個預先訓練的模型,我們可以將其稱為由其他人訓練的神經網絡模型,并為特定的用例提供給其他開發人員使用。
流行的預訓練模型通常是通過使用一個龐大的數據集來解決一個復雜的任務。然后,這些模型被貢獻為開放源碼,因此其他開發人員可以進一步構建或在他們的工作中使用這些模型。通常情況下,使用預先訓練的模型來解決類似的問題是一個好主意,而預先訓練的模型是為這些問題開發的。在圖4中,一個模型為一個源任務訓練,這個源模型已經訓練(預訓練模型)的權值被用于目標任務。對新開發的模型進行了一些修改,將預先訓練的模型的權值進行轉移,以獲得更好和更精確的預測結果。
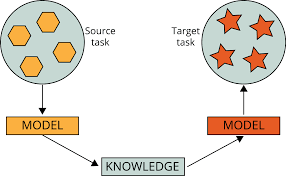
圖4,使用預訓練模型的方法
使用預訓練的模型作為計算機視覺和自然語言處理的各種問題的起點是非常常見的。從零開始構建一個神經網絡需要巨大的計算能力、時間和熟練的勞動力。
在這個文章中,我們將著重于應用預訓練模型(訓練用于圖像分類任務)來解決紋理分類任務。
常用的預訓練模型
下面是對預訓練模型的概述,這些模型經常用于許多圖像分類相關的任務。
VGG-16: 2015年發布的最受歡迎的預訓練圖像分類模型之一。VGG-16是一個深度為16層可調的神經網絡,它在ImageNet數據庫中的100萬張圖像上訓練。它能夠對1000個物體進行分類。
Inception v3:一個由谷歌在同一個ImageNet數據庫上開發的預訓練模型。它也被稱為GoogLeNet。Inception v3是一個深度為50層的神經網絡。在2014年的ImageNet競賽中,InceptionV3獲得了第一,而VGG-16獲得了亞軍。它只有700萬個參數,這比以前的模型要小得多,除此之外,它的錯誤率很低,這是該模型的一個主要成就。
ResNet50:原始模型稱為殘差網或ResNet,它是微軟在2015年開發的。ResNet50是一個深度為50層的神經網絡。ResNet50還訓練了來自ImageNet數據庫的100萬張圖像。與VGG16相比,ResNet復雜度更低,結果優于VGG16。ResNet50旨在解決梯度消失的問題。
EfficientNet:它是谷歌于2019年訓練并向公眾發布的最先進的卷積神經網絡。在EfficientNet中,作者使用了一種新的縮放方法,稱為復合縮放,我們在同一時間縮放固定數量的維度,并且我們均勻地縮放。通過這樣做,我們可以獲得更好的性能,縮放系數可以由用戶自己決定。EfficientNet有8種實現(從B0到B7)。
為我們的用例利用和調整預訓練模型的方法
由于我們所處理的數據與預訓練模型所訓練的數據不同,因此需要根據我們的數據更新模型的權重,以了解特定領域的信息。因此,我們需要對數據的模型進行微調。
下面我們將討論一些在特定用例中使用預先訓練過的模型的機制。
特征提取- 使用預訓練模型作為特征提取機制。我們可以移除輸出層(即給出了1000個類中每個類的概率),然后使用整個網絡作為新數據集的固定特征提取器。
訓練一些層,同時凍結其他層- 預訓練的模型可以用來部分訓練我們的模型,其中我們保持初始層的權重凍結,并重新訓練更高層的權重。根據一些實驗,我們可以看到有多少層需要凍結,有多少層需要訓練。
使用預訓練模型的體系結構- 我們可以從模型的體系結構中獲得幫助,并使用它隨機初始化模型的權重。然后我們可以根據我們的數據集和任務訓練模型,這樣我們就有了一個很好的架構,可以為我們的任務帶來很好的結果。
在處理任何類型的圖像分類問題時,微調和使用預先訓練的模型是一個聰明的解決方案。此外,這些傳統的/預先訓練的CNN模型也產生了良好的結果,然而,這些架構在對基于紋理的數據集進行分類時表現不佳。
為什么傳統的CNN架構在基于紋理的數據集的分類任務中表現不佳?
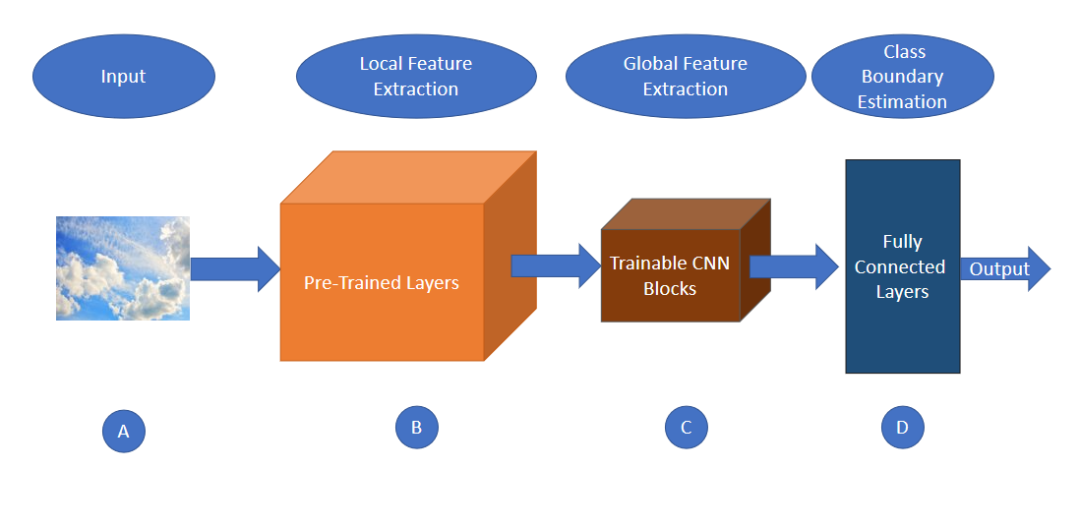
圖5,傳統CNN結構的4個主要部分傳統的CNN架構通常包括預訓練層,在此基礎上添加一些CNN層的可訓練塊,然后將其輸出傳遞到全連接層進行類預測。由圖5可以看出,傳統的CNN架構主要有四個主要組件,用A、B、C、和D四個塊來描述。第一個分量是輸入層(描述為塊A),第二個是預先訓練的層/權值(描述為塊B),第三個分量是可訓練的CNN塊(描述為塊C),它的輸出傳遞給第四個分量(描述為塊D)的全連接層。傳遞給全連接層的輸入通常包括全局特征而不是局部特征。這種通用架構適用于大多數需要圖像全局特征來對圖像進行分類的任務。然而,這些類型的架構很無法很準確的預測類別,在這些類中,全局特征和局部特征都參與了類的預測。
CNN模型的復雜性隨著網絡深度的增加而增加,最后一層通常傾向于捕捉圖像的復雜特征。從卷積層捕獲的特征被發送到全連接層,以獲取圖像中物體的形狀信息并預測其類別。這些關于整體形狀和高度復雜特征的信息不適合用于紋理分析,因為紋理是基于復雜度較低的重復局部位置模式,這需要豐富的基于局部的特征提取。
為了利用為圖像分類而開發的基于CNN的模型進行紋理分類,利用網絡的CNN層輸出中提取的特征進行域轉移。在使用預先訓練的CNN進行基于紋理的分類時,我們面臨三個主要缺點,如下所示。
眾所周知,任何圖像的紋理都是通過其局部結構和局部像素分布來定義的。要分析任何圖像的紋理特征,必須研究其基于局部的特征,并將其傳遞給全連接層。但是傳統的CNN不能將基于局部的特征傳遞給全連接層,因為傳統CNN架構的最后一個CNN層是利用復雜的特征來捕捉物體的整體形狀,并提取全局特征(如圖5所示),而不是捕捉局部特征的模式。這就是傳統CNN架構在基于紋理的數據集上表現不佳的原因。
預訓練的CNN的更深層可能是非常具體的領域,可能不是很有用的紋理分類
一個固定大小的輸入需要發送到CNN,以便它與全連接層兼容。這通常是一項昂貴的任務
全連接的層發布卷積層捕捉圖像的空間布局,這對于表示物體的形狀很有用,但對于表示紋理卻不太有用
在已有的CNNs中加入紋理提取特征技術,可以提高紋理分類任務的結果。表1比較了傳統的CNN方法vs方法使用Resnet-50骨干以及一些特征提取技術。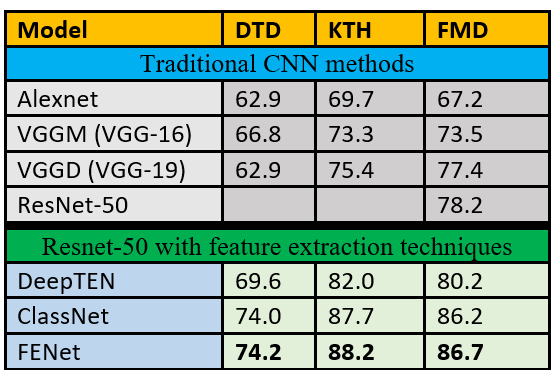 表1,傳統CNN模型和使用特征提取技術的Resnet-50在基準數據集上的結果比較將紋理特征提取策略與深度學習相結合的模型往往比傳統的深度學習方法產生更好的結果。這是因為傳統的CNN模型捕捉了通常對目標檢測有用的復雜特征,而紋理是使用局部重復的模式/特征識別的。可以使用自定義的深度卷積網絡來改進CNN,在卷積層之后,隨著CNN引入各種紋理提取技術。將紋理提取層和預訓練層結合在一起的自定義深度卷積網絡不如單獨使用預訓練模型或統計地使用紋理特征提取器靈活。我們將在后面的文章中討論紋理特征提取和預訓練模型。
表1,傳統CNN模型和使用特征提取技術的Resnet-50在基準數據集上的結果比較將紋理特征提取策略與深度學習相結合的模型往往比傳統的深度學習方法產生更好的結果。這是因為傳統的CNN模型捕捉了通常對目標檢測有用的復雜特征,而紋理是使用局部重復的模式/特征識別的。可以使用自定義的深度卷積網絡來改進CNN,在卷積層之后,隨著CNN引入各種紋理提取技術。將紋理提取層和預訓練層結合在一起的自定義深度卷積網絡不如單獨使用預訓練模型或統計地使用紋理特征提取器靈活。我們將在后面的文章中討論紋理特征提取和預訓練模型。
原文:https://medium.com/@trapti.kalra_ibm/why-traditional-cnns-may-fail-for-texture-based-classification-3b49d6b94b6f
-
cnn
+關注
關注
3文章
352瀏覽量
22237
發布評論請先 登錄
相關推薦
使用卷積神經網絡進行圖像分類的步驟
如何評估AI大模型的效果
逆變器的效果不好和電容有關系嗎
CNN的定義和優勢
yolox_bytetrack_osd_encode示例自帶的yolox模型效果不好是怎么回事?
cnn卷積神經網絡分類有哪些
cnn卷積神經網絡三大特點是什么
CNN模型的基本原理、結構、訓練過程及應用領域
卷積神經網絡cnn模型有哪些
深度神經網絡模型cnn的基本概念、結構及原理
卷積神經網絡在文本分類領域的應用
基于毫米波雷達的手勢識別神經網絡
咳嗽檢測深度神經網絡算法
基于毫米波的人體跟蹤和識別算法
比較基于無人機高光譜影像和傳統方法的土壤類型分類精度






 工商網監
工商網監
評論