


來源:DeepHub IMBA
作者:Abhay Parashar
機器學習是人工智能的一個分支領域,致力于構建自動學習和自適應的系統,它利用統計模型來可視化、分析和預測數據。一個通用的機器學習模型包括一個數據集(用于訓練模型)和一個算法(從數據學習)。但是有些模型的準確性通常很低產生的結果也不太準確,克服這個問題的最簡單的解決方案之一是在機器學習模型上使用集成學習。
集成學習是一種元方法,通過組合多個機器學習模型來產生一個優化的模型,從而提高模型的性能。集成學習可以很容易地減少過擬合,避免模型在訓練時表現更好,而在測試時不能產生良好的結果。
總結起來,集成學習有以下的優點:
- 增加模型的性能
- 減少過擬合
- 降低方差
- 與單個模型相比,提供更高的預測精度。
- 可以處理線性和非線性數據。
集成技術可以用來解決回歸和分類問題
下面我們將介紹各種集成學習的方法:
Voting
Voting是一種集成學習,它將來自多個機器學習模型的預測結合起來產生結果。在整個數據集上訓練多個基礎模型來進行預測。每個模型預測被認為是一個“投票”。得到多數選票的預測將被選為最終預測。
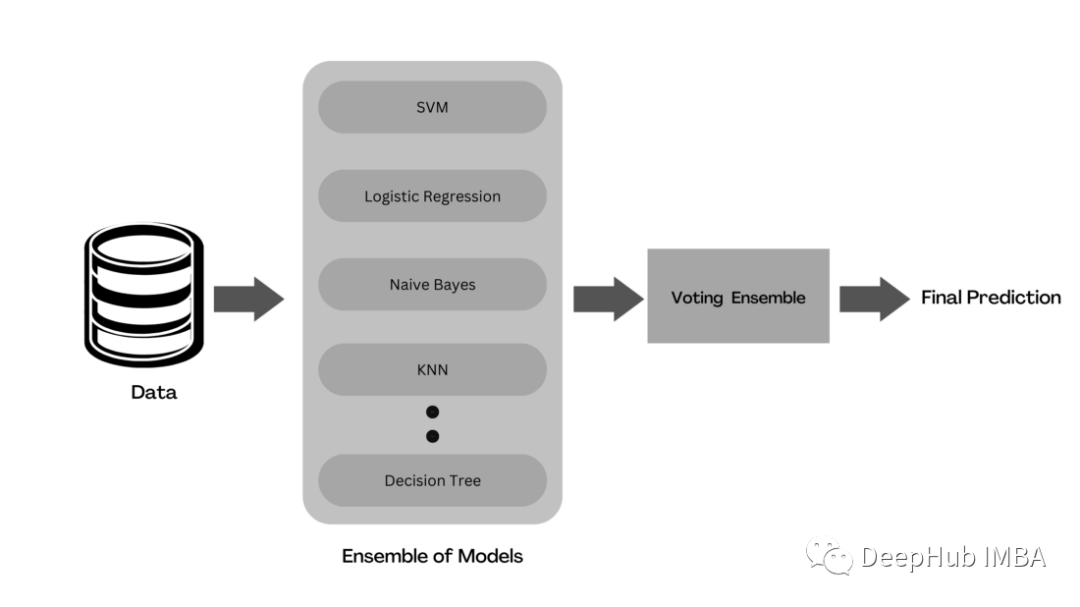
有兩種類型的投票用于匯總基礎預測-硬投票和軟投票。
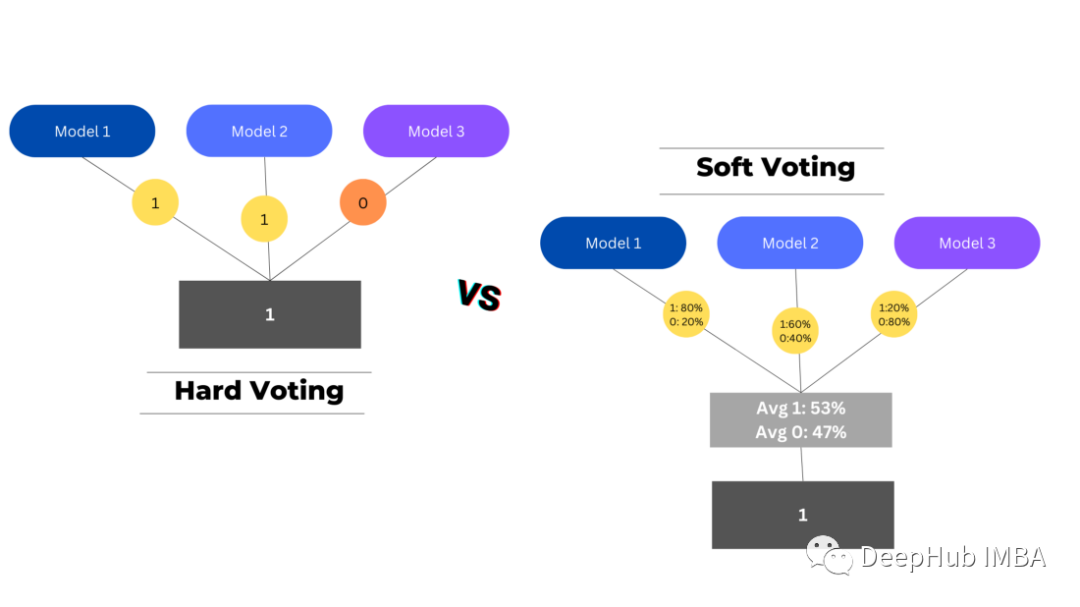
硬投票選擇投票數最高的預測作為最終預測,而軟投票將每個模型中每個類的概率結合起來,選擇概率最高的類作為最終預測。
在回歸問題中,它的工作方式有些不同,因為我們不是尋找頻率最高的類,而是采用每個模型的預測并計算它們的平均值,從而得出最終的預測。
from sklearn.ensemble import VotingClassifier ## Base Models from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC ensemble_voting = VotingClassifier( estimators = [('dtc',DecisionTreeClassifier(random_state=42)), ('lr', LogisticRegression()), ('gnb', GaussianNB()), ('knn',KNeighborsClassifier()), ('svc',SVC())], voting='hard') ensemble_voting.fit(X_train,y_train)Bagging
Bagging是采用幾個弱機器學習模型,并將它們的預測聚合在一起,以產生最佳的預測。它基于bootstrap aggregation,bootstrap 是一種使用替換方法從集合中抽取隨機樣本的抽樣技術。aggregation則是利用將幾個預測結合起來產生最終預測的過程。
隨機森林是利用Bagging的最著名和最常用的模型之一。它由大量的決策樹組成,這些決策樹作為一個整體運行。它使用Bagging和特征隨機性的概念來創建每棵獨立的樹。每棵決策樹都是從數據中隨機抽取樣本進行訓練。在隨機森林中,我們最終得到的樹不僅接受不同數據集的訓練,而且使用不同的特征來預測結果。
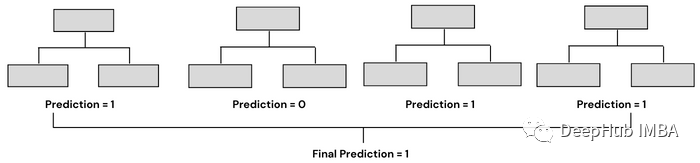
Bagging通常有兩種類型——決策樹的集合(稱為隨機森林)和決策樹以外的模型的集合。兩者的工作原理相似,都使用聚合方法生成最終預測,唯一的區別是它們所基于的模型。在sklearn中,我們有一個BaggingClassifier類,用于創建除決策樹以外的模型。
## Bagging Ensemble of Same Classifiers (Decision Trees) from sklearn.ensemble import RandomForestClassifier classifier= RandomForestClassifier(n_estimators= 10, criterion="entropy") classifier.fit(x_train, y_train) ## Bagging Ensemble of Different Classifiers from sklearn.ensemble import BaggingClassifier from sklearn.svm import SVC clf = BaggingClassifier(base_estimator=SVC(), n_estimators=10, random_state=0) clf.fit(X_train,y_train)Boosting
增強集成方法通過重視先前模型的錯誤,將弱學習者轉化為強學習者。Boosting以順序的方式實現同構ML算法,每個模型都試圖通過減少前一個模型的誤差來提高整個過程的穩定性。
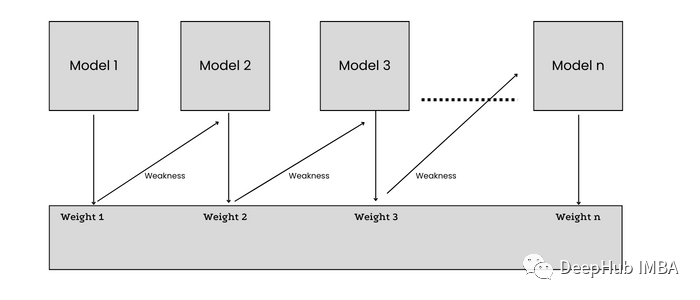
在訓練n+1模型時,數據集中的每個數據點都被賦予了相等的權重,這樣被模型n錯誤分類的樣本就能被賦予更多的權重(重要性)。誤差從n個學習者傳遞給n+1個學習者,每個學習者都試圖減少誤差。
ADA Boost是使用Boost生成預測的最基本模型之一。ADA boost創建一個決策樹樁森林(一個樹樁是一個只有一個節點和兩個葉子的決策樹),不像隨機森林創建整個決策樹森林。它給分類錯誤的樣本分配更高的權重,并繼續訓練模型,直到得到較低的錯誤率。
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import AdaBoostClassifier dt = DecisionTreeClassifier(max_depth=2, random_state=0) adc = AdaBoostClassifier(base_estimator=dt, n_estimators=7, learning_rate=0.1, random_state=0) adc.fit(x_train, y_train)Stacking
Stacking也被稱為疊加泛化,是David H. Wolpert在1992年提出的集成技術的一種形式,目的是通過使用不同的泛化器來減少錯誤。
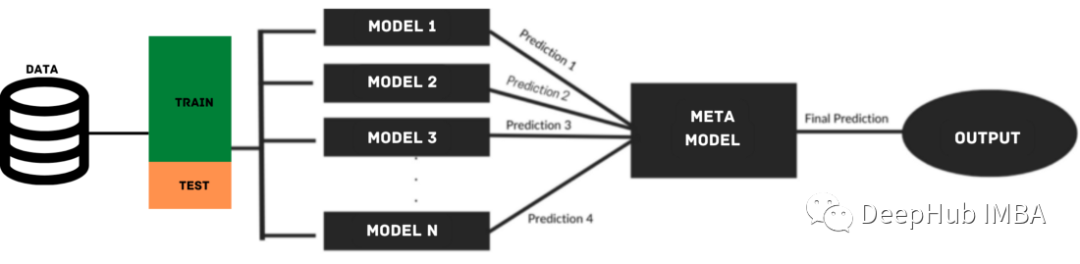
疊加模型利用來自多個基礎模型的預測來構建元模型,用于生成最終的預測。堆疊模型由多層組成,其中每一層由幾個機器學習模型組成,這些模型的預測用于訓練下一層模型。
在疊加過程中,將數據分為訓練集和測試集兩部分。訓練集會被進一步劃分為k-fold。基礎模型在k-1部分進行訓練,在k??部分進行預測。這個過程被反復迭代,直到每一折都被預測出來。然后將基本模型擬合到整個數據集,并計算性能。這個過程也適用于其他基本模型。
來自訓練集的預測被用作構建第二層或元模型的特征。這個第二級模型用于預測測試集。
from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.linear_model import LogisticRegression from sklearn.ensemble import StackingClassifier base_learners = [ ('l1', KNeighborsClassifier()), ('l2', DecisionTreeClassifier()), ('l3',SVC(gamma=2, C=1))) ] model = StackingClassifier(estimators=base_learners, final_estimator=LogisticRegression(),cv=5) model.fit(X_train, y_train)Blending
Blending是從Stacking派生出來另一種形式的集成學習技術,兩者之間的唯一區別是它使用來自一個訓練集的保留(驗證)集來進行預測。簡單地說,預測只針對保留的數據集。保留的數據集和預測用于構建第二級模型。
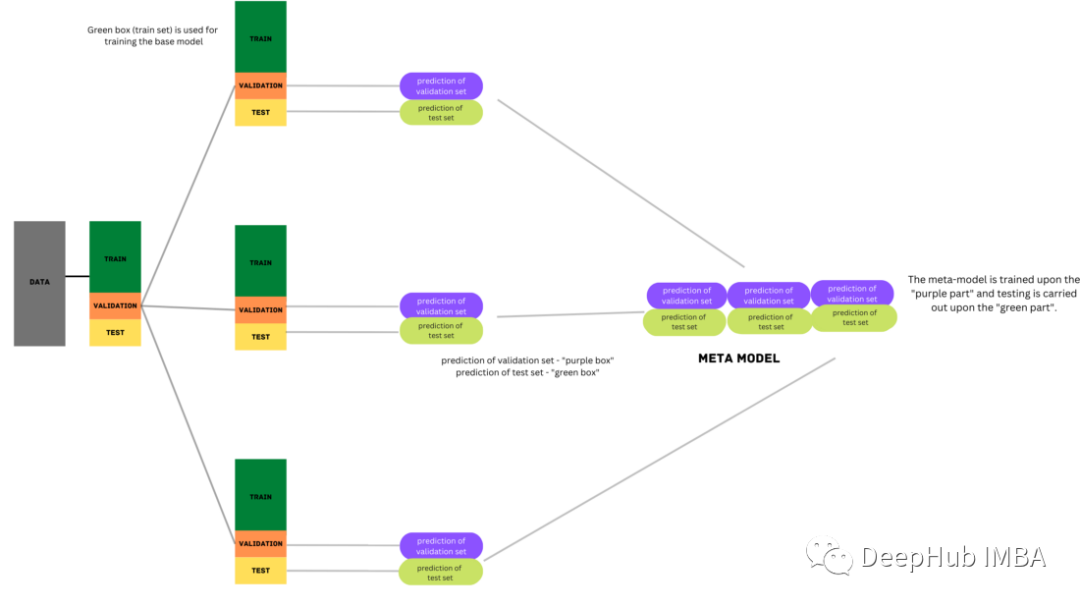
import numpy as np from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score ## Base Models from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC ## Meta Learner from sklearn.linear_model import LogisticRegression ## Creating Sample Data X,y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=42) ## Training a Individual Logistic Regression Model X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) logrec = LogisticRegression() logrec.fit(X_train,y_train) pred = logrec.predict(X_test) score = accuracy_score(y_test, pred) print('Base Model Accuracy: %.3f' % (score*100)) ## Defining Base Models def base_models(): models = list() models.append(('knn', KNeighborsClassifier())) models.append(('dt', DecisionTreeClassifier())) models.append(('svm', SVC(probability=True))) return models ## Fitting Ensemble Blending Model ## Step 1:Splitting Data Into Train, Holdout(Validation) and Test Sets X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.3, random_state=1) X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1) ## Step 2: train base models on train set and make predictions on validation set models = base_models() meta_X = list() for name, model in models: # training base models on train set model.fit(X_train, y_train) # predict on hold out set yhat = model.predict_proba(X_val) # storing predictions meta_X.append(yhat) # horizontal stacking predictions meta_X = np.hstack(meta_X) ## Step 3: Creating Blending Meta Learner blender = LogisticRegression() ## training on base model predictions blender.fit(meta_X, y_val) ## Step 4: Making predictions using blending meta learner meta_X = list() for name, model in models: yhat = model.predict_proba(X_test) meta_X.append(yhat) meta_X = np.hstack(meta_X) y_pred = blender.predict(meta_X) # Evaluate predictions score = accuracy_score(y_test, y_pred) print('Blending Accuracy: %.3f' % (score*100)) --------------------------------- Base Model Accuracy: 82.367 Blending Accuracy: 96.733總結
在閱讀完本文之后,您可能想知道是否有選擇一個更好的模型最好的方法或者如果需要的話,使用哪種集成技術呢?
在這個問題時,我們總是建議從一個簡單的個體模型開始,然后使用不同的建模技術(如集成學習)對其進行測試。在某些情況下,單個模型可能比集成模型表現得更好,甚至好很多。
需要說明并且需要注意的一點是:集成學習絕不應該是第一選擇,而應該是最后一個選擇。原因很簡單:訓練一個集成模型將花費很多時間,并且需要大量的處理能力。
回到我們的問題,集成模型旨在通過組合同一類別的幾個基本模型來提高模型的可預測性。每種集成技術都是最好的,有助于提高模型性能。
如果你正在尋找一種簡單且易于實現的集成方法,那么應該使用Voting。如果你的數據有很高的方差,那么你應該嘗試Bagging。如果訓練的基礎模型在模型預測中有很高的偏差,那么可以嘗試不同的Boosting技術來提高準確性。如果有多個基礎模型在數據上表現都很好好,并且不知道選擇哪一個作為最終模型,那么可以使用Stacking 或Blending的方法。當然具體哪種方法表現得最好還是要取決于數據和特征分布。
最后集成學習技術是提高模型精度和性能的強大工具,它們很容易減少數據過擬合和欠擬合的機會,尤其在參加比賽時這是提分的關鍵。
-
機器學習
+關注
關注
66文章
8507瀏覽量
134758
發布評論請先 登錄
大模型推理顯存和計算量估計方法研究
邊緣計算中的機器學習:基于 Linux 系統的實時推理模型部署與工業集成!

機器學習模型市場前景如何
傳統機器學習方法和應用指導

【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】1.全書概覽與第一章學習
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
PWM信號生成方法 PWM調制原理講解
什么是機器學習?通過機器學習方法能解決哪些問題?

LLM和傳統機器學習的區別
AI大模型與深度學習的關系
AI大模型與傳統機器學習的區別
萬界星空科技MES數據的集成方式





 工商網監
工商網監

評論