 機器學習回歸模型相關重要知識點總結
機器學習回歸模型相關重要知識點總結
來源:機器學習研習院
回歸分析為許多機器學習算法提供了堅實的基礎。在這篇文章中,我們將總結 10 個重要的回歸問題和5個重要的回歸問題的評價指標。
1、線性回歸的假設是什么?
線性回歸有四個假設
- 線性:自變量(x)和因變量(y)之間應該存在線性關系,這意味著x值的變化也應該在相同方向上改變y值。
- 獨立性:特征應該相互獨立,這意味著最小的多重共線性。
- 正態性:殘差應該是正態分布的。
- 同方差性:回歸線周圍數據點的方差對于所有值應該相同。
2、什么是殘差,它如何用于評估回歸模型?
殘差是指預測值與觀測值之間的誤差。它測量數據點與回歸線的距離。它是通過從觀察值中減去預測值的計算機。
殘差圖是評估回歸模型的好方法。它是一個圖表,在垂直軸上顯示所有殘差,在 x 軸上顯示特征。如果數據點隨機散布在沒有圖案的線上,那么線性回歸模型非常適合數據,否則我們應該使用非線性模型。
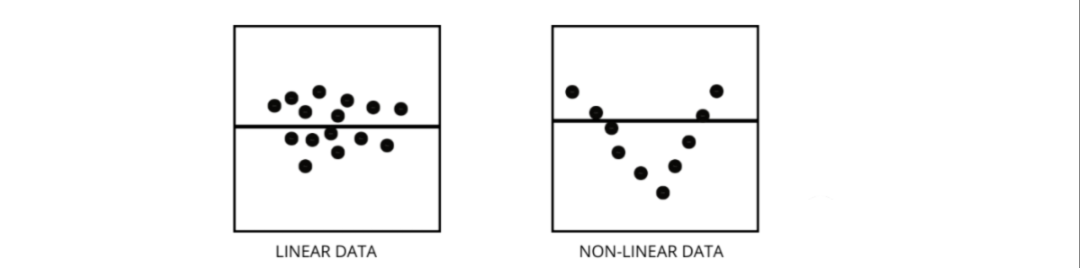
3、如何區分線性回歸模型和非線性回歸模型?
兩者都是回歸問題的類型。兩者的區別在于他們訓練的數據。
線性回歸模型假設特征和標簽之間存在線性關系,這意味著如果我們獲取所有數據點并將它們繪制成線性(直線)線應該適合數據。
非線性回歸模型假設變量之間沒有線性關系。非線性(曲線)線應該能夠正確地分離和擬合數據。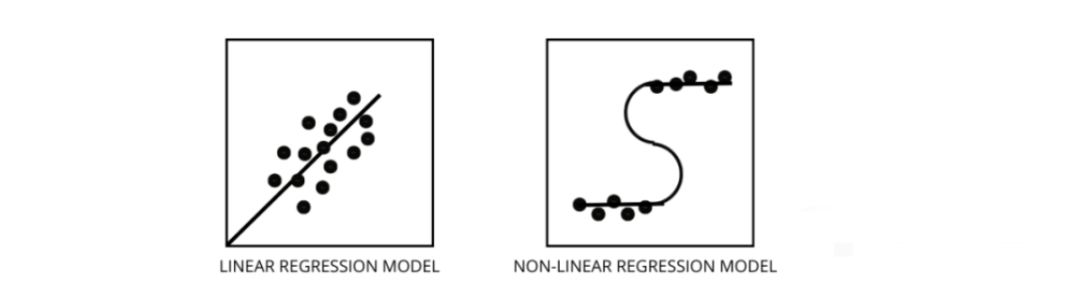 找出數據是線性還是非線性的三種最佳方法 -
找出數據是線性還是非線性的三種最佳方法 -
殘差圖
- 散點圖
- 假設數據是線性的,訓練一個線性模型并通過準確率進行評估。
4、什么是多重共線性,它如何影響模型性能?
當某些特征彼此高度相關時,就會發生多重共線性。相關性是指表示一個變量如何受到另一個變量變化影響的度量。
如果特征 a 的增加導致特征 b 的增加,那么這兩個特征是正相關的。如果 a 的增加導致特征 b 的減少,那么這兩個特征是負相關的。在訓練數據上有兩個高度相關的變量會導致多重共線性,因為它的模型無法在數據中找到模式,從而導致模型性能不佳。所以在訓練模型之前首先要盡量消除多重共線性。
5、異常值如何影響線性回歸模型的性能?
異常值是值與數據點的平均值范圍不同的數據點。換句話說,這些點與數據不同或在第 3 標準之外。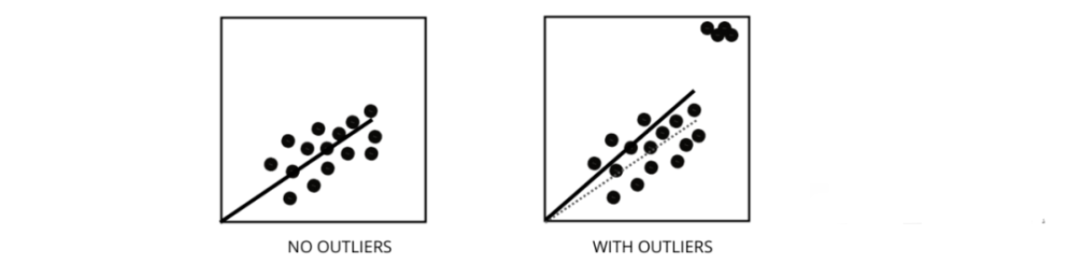 線性回歸模型試圖找到一條可以減少殘差的最佳擬合線。如果數據包含異常值,則最佳擬合線將向異常值移動一點,從而增加錯誤率并得出具有非常高 MSE 的模型。
線性回歸模型試圖找到一條可以減少殘差的最佳擬合線。如果數據包含異常值,則最佳擬合線將向異常值移動一點,從而增加錯誤率并得出具有非常高 MSE 的模型。
6、什么是 MSE 和 MAE 有什么區別?
MSE 代表均方誤差,它是實際值和預測值之間的平方差。而 MAE 是目標值和預測值之間的絕對差。
MSE 會懲罰大錯誤,而 MAE 不會。隨著 MSE 和 MAE 的值都降低,模型趨向于一條更好的擬合線。
7、L1 和 L2 正則化是什么,應該在什么時候使用?
在機器學習中,我們的主要目標是創建一個可以在訓練和測試數據上表現更好的通用模型,但是在數據非常少的情況下,基本的線性回歸模型往往會過度擬合,因此我們會使用 l1 和l2 正則化。L1 正則化或 lasso 回歸通過在成本函數內添加添加斜率的絕對值作為懲罰項。有助于通過刪除斜率值小于閾值的所有數據點來去除異常值。
L2 正則化或ridge 回歸增加了相當于系數大小平方的懲罰項。它會懲罰具有較高斜率值的特征。
l1 和 l2 在訓練數據較少、方差高、預測特征大于觀察值以及數據存在多重共線性的情況下都很有用。
8、異方差是什么意思?
它是指最佳擬合線周圍的數據點的方差在一個范圍內不一樣的情況。它導致殘差的不均勻分散。如果它存在于數據中,那么模型傾向于預測無效輸出。檢驗異方差的最好方法之一是繪制殘差圖。
數據內部異方差的最大原因之一是范圍特征之間的巨大差異。例如,如果我們有一個從 1 到 100000 的列,那么將值增加 10% 不會改變較低的值,但在較高的值時則會產生非常大的差異,從而產生很大的方差差異的數據點。
9、方差膨脹因子的作用是什么的作用是什么?
方差膨脹因子(vif)用于找出使用其他自變量可預測自變量的程度。
讓我們以具有 v1、v2、v3、v4、v5 和 v6 特征的示例數據為例。現在,為了計算 v1 的 vif,將其視為一個預測變量,并嘗試使用所有其他預測變量對其進行預測。如果 VIF 的值很小,那么最好從數據中刪除該變量。因為較小的值表示變量之間的高相關性。
10、逐步回歸(stepwise regression)如何工作?
逐步回歸是在假設檢驗的幫助下,通過移除或添加預測變量來創建回歸模型的一種方法。它通過迭代檢驗每個自變量的顯著性來預測因變量,并在每次迭代之后刪除或添加一些特征。它運行n次,并試圖找到最佳的參數組合,以預測因變量的觀測值和預測值之間的誤差最小。
它可以非常高效地管理大量數據,并解決高維問題。
11、除了MSE 和 MAE 外回歸還有什么重要的指標嗎?
 我們用一個回歸問題來介紹這些指標,我們的其中輸入是工作經驗,輸出是薪水。下圖顯示了為預測薪水而繪制的線性回歸線。
我們用一個回歸問題來介紹這些指標,我們的其中輸入是工作經驗,輸出是薪水。下圖顯示了為預測薪水而繪制的線性回歸線。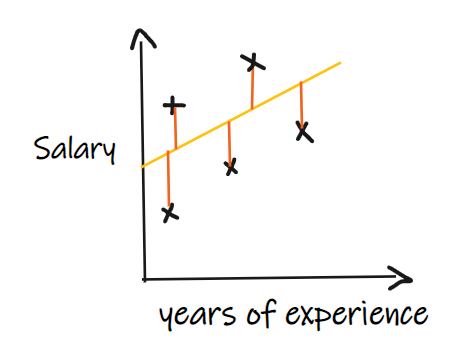
1、平均絕對誤差(MAE):
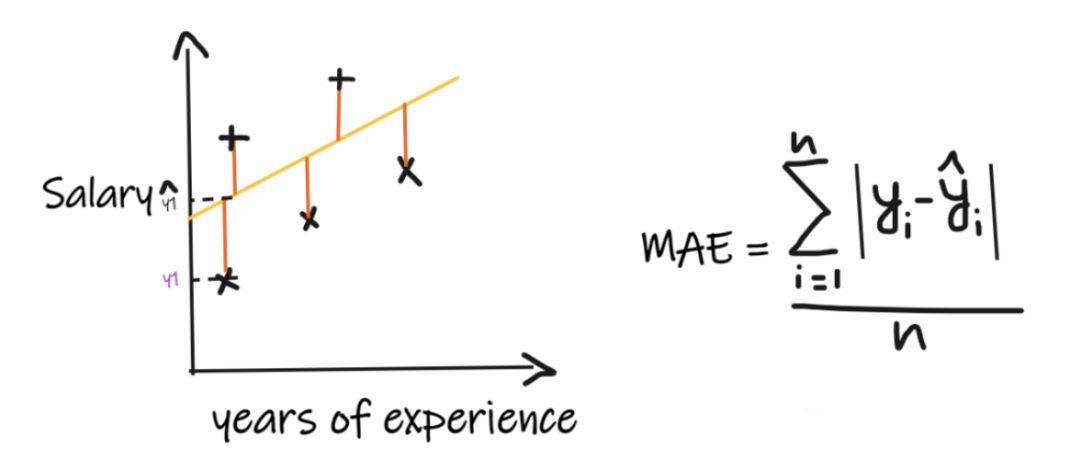 平均絕對誤差 (MAE) 是最簡單的回歸度量。它將每個實際值和預測值的差值相加,最后除以觀察次數。為了使回歸模型被認為是一個好的模型,MAE 應該盡可能小。MAE的優點是:簡單易懂。結果將具有與輸出相同的單位。例如:如果輸出列的單位是 LPA,那么如果 MAE 為 1.2,那么我們可以解釋結果是 +1.2LPA 或 -1.2LPA,MAE 對異常值相對穩定(與其他一些回歸指標相比,MAE 受異常值的影響較小)。MAE的缺點是:MAE使用的是模函數,但模函數不是在所有點處都可微的,所以很多情況下不能作為損失函數。
平均絕對誤差 (MAE) 是最簡單的回歸度量。它將每個實際值和預測值的差值相加,最后除以觀察次數。為了使回歸模型被認為是一個好的模型,MAE 應該盡可能小。MAE的優點是:簡單易懂。結果將具有與輸出相同的單位。例如:如果輸出列的單位是 LPA,那么如果 MAE 為 1.2,那么我們可以解釋結果是 +1.2LPA 或 -1.2LPA,MAE 對異常值相對穩定(與其他一些回歸指標相比,MAE 受異常值的影響較小)。MAE的缺點是:MAE使用的是模函數,但模函數不是在所有點處都可微的,所以很多情況下不能作為損失函數。
2、均方誤差(MSE):
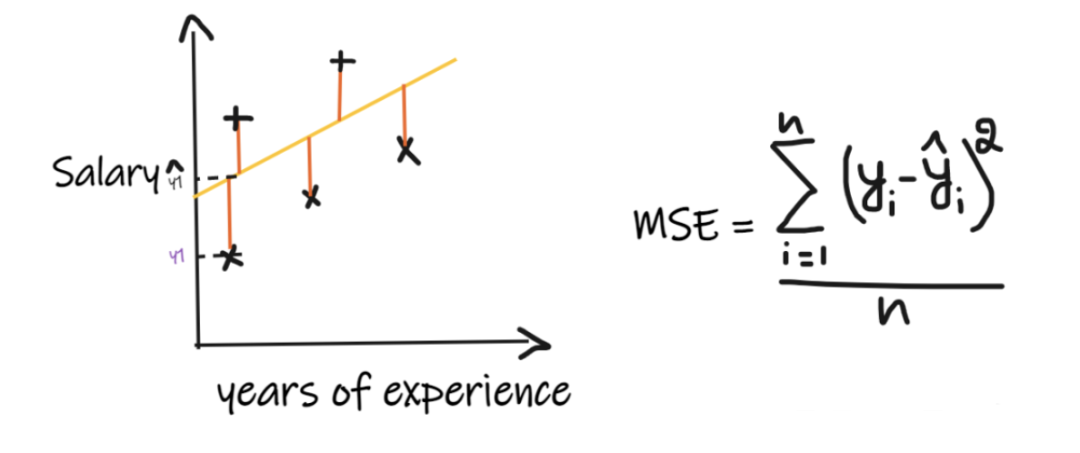 MSE取每個實際值和預測值之間的差值,然后將差值平方并將它們相加,最后除以觀測數量。為了使回歸模型被認為是一個好的模型,MSE 應該盡可能小。MSE的優點:平方函數在所有點上都是可微的,因此它可以用作損失函數。MSE的缺點:由于 MSE 使用平方函數,結果的單位是輸出的平方。因此很難解釋結果。由于它使用平方函數,如果數據中有異常值,則差值也會被平方,因此,MSE 對異常值不穩定。
MSE取每個實際值和預測值之間的差值,然后將差值平方并將它們相加,最后除以觀測數量。為了使回歸模型被認為是一個好的模型,MSE 應該盡可能小。MSE的優點:平方函數在所有點上都是可微的,因此它可以用作損失函數。MSE的缺點:由于 MSE 使用平方函數,結果的單位是輸出的平方。因此很難解釋結果。由于它使用平方函數,如果數據中有異常值,則差值也會被平方,因此,MSE 對異常值不穩定。
3、均方根誤差 (RMSE):
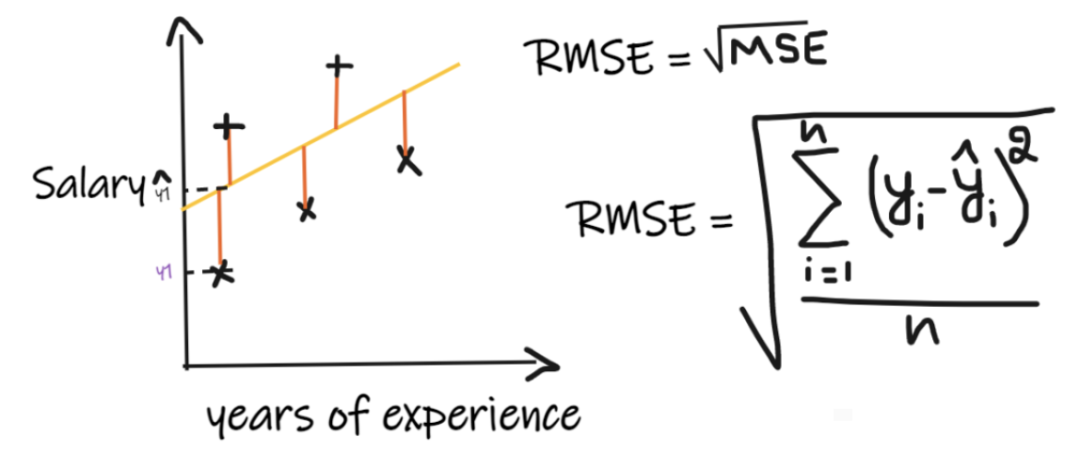 均方根誤差(RMSE)取每個實際值和預測值之間的差值,然后將差值平方并將它們相加,最后除以觀測數量。然后取結果的平方根。因此,RMSE 是 MSE 的平方根。為了使回歸模型被認為是一個好的模型,RMSE 應該盡可能小。RMSE 解決了 MSE 的問題,單位將與輸出的單位相同,因為它取平方根,但仍然對異常值不那么穩定。
均方根誤差(RMSE)取每個實際值和預測值之間的差值,然后將差值平方并將它們相加,最后除以觀測數量。然后取結果的平方根。因此,RMSE 是 MSE 的平方根。為了使回歸模型被認為是一個好的模型,RMSE 應該盡可能小。RMSE 解決了 MSE 的問題,單位將與輸出的單位相同,因為它取平方根,但仍然對異常值不那么穩定。
上述指標取決于我們正在解決的問題的上下文, 我們不能在不了解實際問題的情況下,只看 MAE、MSE 和 RMSE 的值來判斷模型的好壞。
4、R2 score:
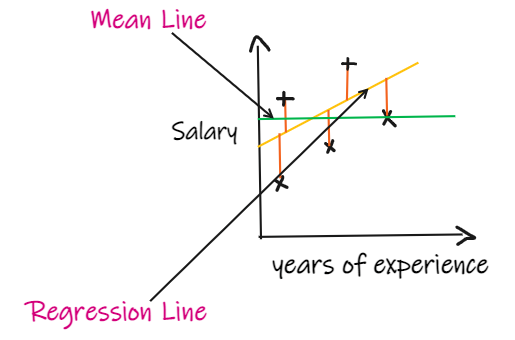 如果我們沒有任何輸入數據,但是想知道他在這家公司能拿到多少薪水,那么我們能做的最好的事情就是給他們所有員工薪水的平均值。
如果我們沒有任何輸入數據,但是想知道他在這家公司能拿到多少薪水,那么我們能做的最好的事情就是給他們所有員工薪水的平均值。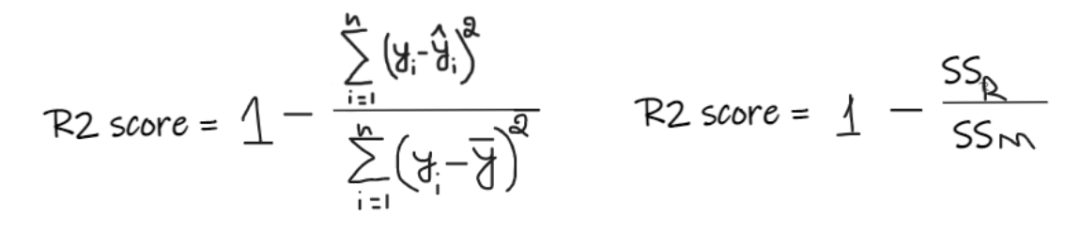 R2 score 給出的值介于 0 到 1 之間,可以針對任何上下文進行解釋。它可以理解為是擬合度的好壞。SSR 是回歸線的誤差平方和,SSM 是均線誤差的平方和。我們將回歸線與平均線進行比較。
R2 score 給出的值介于 0 到 1 之間,可以針對任何上下文進行解釋。它可以理解為是擬合度的好壞。SSR 是回歸線的誤差平方和,SSM 是均線誤差的平方和。我們將回歸線與平均線進行比較。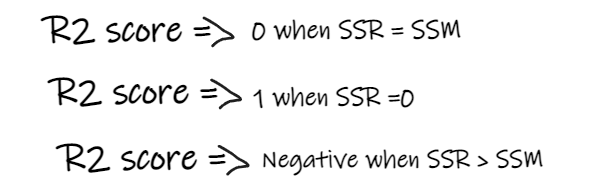
- 如果 R2 得分為 0,則意味著我們的模型與平均線的結果是相同的,因此需要改進我們的模型。
- 如果 R2 得分為 1,則等式的右側部分變為 0,這只有在我們的模型適合每個數據點并且沒有出現誤差時才會發生。
- 如果 R2 得分為負,則表示等式右側大于 1,這可能發生在 SSR > SSM 時。這意味著我們的模型比平均線最差,也就是說我們的模型還不如取平均數進行預測
如果我們模型的 R2 得分為 0.8,這意味著可以說模型能夠解釋 80% 的輸出方差。也就是說,80%的工資變化可以用輸入(工作年限)來解釋,但剩下的20%是未知的。如果我們的模型有2個特征,工作年限和面試分數,那么我們的模型能夠使用這兩個輸入特征解釋80%的工資變化。R2的缺點:隨著輸入特征數量的增加,R2會趨于相應的增加或者保持不變,但永遠不會下降,即使輸入特征對我們的模型不重要(例如,將面試當天的氣溫添加到我們的示例中,R2是不會下降的即使溫度對輸出不重要)。
5、Adjusted R2 score:
上式中R2為R2,n為觀測數(行),p為獨立特征數。Adjusted R2解決了R2的問題。當我們添加對我們的模型不那么重要的特性時,比如添加溫度來預測工資..... 當添加對模型很重要的特性時,比如添加面試分數來預測工資……
當添加對模型很重要的特性時,比如添加面試分數來預測工資……
以上就是回歸問題的重要知識點和解決回歸問題使用的各種重要指標的介紹及其優缺點,希望對你有所幫助。
-
機器學習
+關注
關注
66文章
8407瀏覽量
132567
發布評論請先 登錄
相關推薦
接口測試理論、疑問收錄與擴展相關知識點
【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
名單公布!【書籍評測活動NO.35】如何用「時間序列與機器學習」解鎖未來?

一篇搞定DCS系統相關知識點
【量子計算機重構未來 | 閱讀體驗】第二章關鍵知識點

機器學習、深度學習面試知識點匯總






 工商網監
工商網監
評論