") MPU進(jìn)化,多核異構(gòu)處理器有多強(qiáng)?A核與M核通信過(guò)程解析
MPU進(jìn)化,多核異構(gòu)處理器有多強(qiáng)?A核與M核通信過(guò)程解析
隨著市場(chǎng)對(duì)嵌入式設(shè)備功能需求的提高,市面上出現(xiàn)了集成嵌入式處理器和單片機(jī)的主控方案,以兼顧性能和效率。
在實(shí)際應(yīng)用中,嵌入式處理器和單片機(jī)之間需要進(jìn)行大量且頻繁的數(shù)據(jù)交換,如果采用低速串行接口,則數(shù)據(jù)傳輸效率低,這將嚴(yán)重影響產(chǎn)品的性能;而如果采用高速并口,則占用管腳多,硬件成本將會(huì)增加。
為解決這一痛點(diǎn),各大芯片公司陸續(xù)推出了兼具A核和M核的多核異構(gòu)處理器,如NXP的i.MX8系列、瑞薩的RZ/G2L系列以及TI的AM62x系列等等。雖然這些處理器的品牌及性能有所不同,但多核通信原理基本一致,都是基于寄存器和中斷傳遞消息,基于共享內(nèi)存?zhèn)鬏敂?shù)據(jù)。
以配電終端產(chǎn)品為例,A核負(fù)責(zé)通訊和顯示等人機(jī)交互任務(wù),M核負(fù)責(zé)采樣和保護(hù)等對(duì)實(shí)時(shí)性要求較高的任務(wù),雙核間交互模擬量、開(kāi)關(guān)量和錄波文件等多種信息,A核+M核的方案既滿足了傳統(tǒng)采樣保護(hù)功能,又支持多種接口通信及新增容器等功能,符合國(guó)家電網(wǎng)現(xiàn)行配電標(biāo)準(zhǔn)。
 通信過(guò)程整體架構(gòu)說(shuō)明
通信過(guò)程整體架構(gòu)說(shuō)明接下來(lái)小編將以NXP的i.MX8MP為例,借助飛凌OKMX8MP-C開(kāi)發(fā)板分別從硬件層、驅(qū)動(dòng)層、應(yīng)用層介紹大致的通信實(shí)現(xiàn)流程以及實(shí)測(cè)效果。
1. 硬件層通信實(shí)現(xiàn)機(jī)制
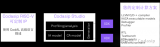
通過(guò)物理內(nèi)存DDR分配,將硬件層分為了兩部分:TXVring Buffer(發(fā)送虛擬環(huán)狀緩沖區(qū))和RXVring Buffer(接收虛擬環(huán)狀緩沖區(qū));其中M核從TXVring區(qū)發(fā)送數(shù)據(jù),從RXVring區(qū)讀取接收數(shù)據(jù),A核反之。
處理器支持消息傳遞單元(MessagingUnit,簡(jiǎn)稱MU)功能模塊,通過(guò)MU傳遞消息進(jìn)行通信和協(xié)調(diào),芯片內(nèi)的M7控制核和A53處理核通過(guò)通過(guò)寄存器中斷的方式傳遞命令,最多支持4組MU雙向傳遞消息,既可通過(guò)中斷告知對(duì)方數(shù)據(jù)傳遞的狀態(tài),也可發(fā)送最多4字節(jié)數(shù)據(jù),還可在低功耗模式下喚醒對(duì)方,是保證雙核通信實(shí)時(shí)性的重要手段。
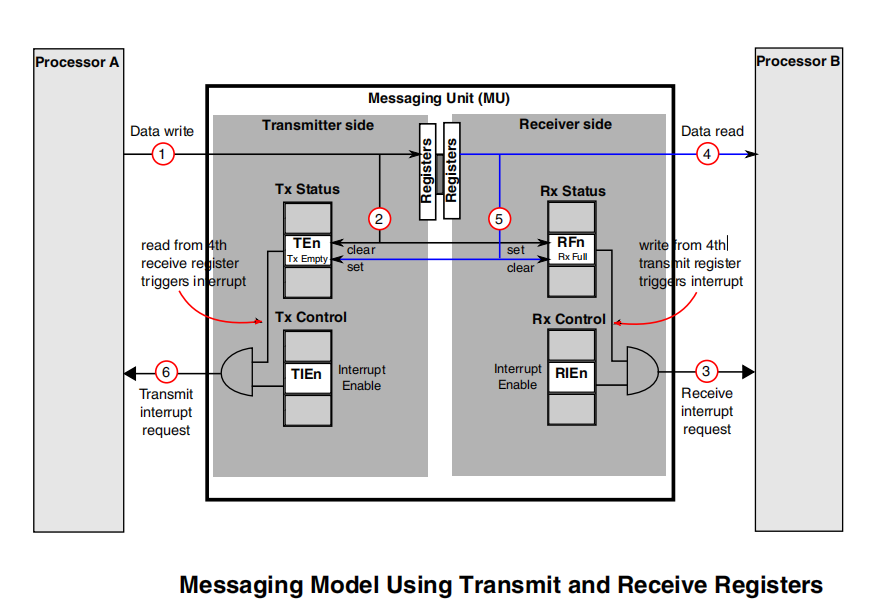 寄存器輸入輸出通信模型
寄存器輸入輸出通信模型(1)CoreA寫入數(shù)據(jù);
(2)MU將Tx 空位清0,Rx滿位置1;
(3)產(chǎn)生接收中斷請(qǐng)求,通知CoreB接收狀態(tài)寄存器中的接收器滿,可以讀取數(shù)據(jù);
(4)CoreB響應(yīng)中斷,讀取數(shù)據(jù);
(5)CoreB讀完數(shù)據(jù)后,MU將Rx滿位清0,Tx空位置1;
(6)狀態(tài)寄存器向CoreA生成發(fā)送中斷請(qǐng)求,告知CoreB讀完數(shù)據(jù),發(fā)送寄存器空。
通過(guò)以上步驟,就完成了1次從CoreA向CoreB 傳遞消息的過(guò)程,反之亦然。
2. 驅(qū)動(dòng)層Virtio下RPMsg通信實(shí)現(xiàn)
Virtio是通用的IO虛擬化模型,位于設(shè)備之上的抽象層,負(fù)責(zé)前后端之間的通知機(jī)制和控制流程,為異構(gòu)多核間數(shù)據(jù)通信提供了層的實(shí)現(xiàn)。
RPMsg消息框架是Linux系統(tǒng)基于Virtio緩存隊(duì)列實(shí)現(xiàn)的主處理核和協(xié)處理核間進(jìn)行消息通信的框架,當(dāng)客戶端驅(qū)動(dòng)需要發(fā)送消息時(shí),RPMsg會(huì)把消息封裝成Virtio緩存并添加到緩存隊(duì)列中以完成消息的發(fā)送,當(dāng)消息總線接收到協(xié)處理器送到的消息時(shí)也會(huì)合理地派送給客戶驅(qū)動(dòng)程序進(jìn)行處理。
在驅(qū)動(dòng)層,對(duì)A核,Linux采用RPMsg框架+Virtio驅(qū)動(dòng)模型,將RPMsg封裝為了tty文件供應(yīng)用層調(diào)用;在M核,將Virtio移植,并使用簡(jiǎn)化版的RPMsg,因?yàn)樯婕暗交コ怄i和信號(hào)量,最終使用FreeRTOS完成過(guò)程的封裝,流程框圖如下方所示。
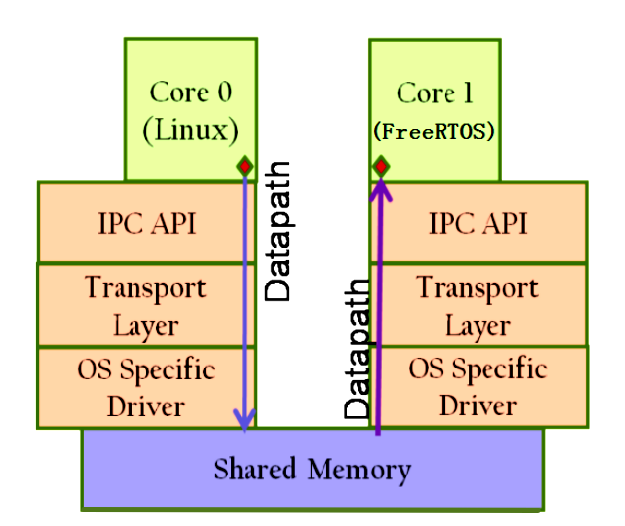 主處理核與協(xié)處理核數(shù)據(jù)傳遞流程圖
主處理核與協(xié)處理核數(shù)據(jù)傳遞流程圖(1)Core0向Core1發(fā)送數(shù)據(jù),通過(guò)rpmsg_send函數(shù)將數(shù)據(jù)打包至Virtioavail鏈表區(qū);
(2)在avail鏈表尋找共享內(nèi)存中空閑緩存,將數(shù)據(jù)置于共享內(nèi)存中;
(3)通過(guò)中斷通知Core1數(shù)據(jù)到來(lái),共享內(nèi)存由avail鏈表區(qū)變至used區(qū);
(4)Core1收到中斷,觸發(fā)rpmsg的接收回調(diào)函數(shù),從used區(qū)獲取數(shù)據(jù)所在的共享內(nèi)存的物理地址,完成數(shù)據(jù)接收;
(5)通過(guò)中斷通知Core0數(shù)據(jù)接收完成,共享內(nèi)存緩存由used區(qū)變?yōu)閍vail區(qū),供下次傳輸使用。
3. 應(yīng)用層雙核通信實(shí)現(xiàn)方式
在應(yīng)用層,對(duì)A核可使用open、write和read函數(shù)對(duì) /dev下設(shè)備文件進(jìn)行調(diào)用;對(duì)M核,可使用rpmsg_lite_remote_init、rpmsg_lite_send和rpmsg_queue_recv函數(shù)進(jìn)行調(diào)用,不做重點(diǎn)闡述。
4. 實(shí)際使用效果
通過(guò)程序?qū)崪y(cè),M核和A核可以批量傳輸大數(shù)據(jù)。同樣以配電產(chǎn)品為例——128點(diǎn)采樣的錄波文件大約為43K,若通過(guò)傳統(tǒng)的串行總線傳輸方式,需要數(shù)秒才可完成傳輸。
而使用i.MX8MP的雙核異構(gòu)通信方案,只需要不到0.5秒即可傳輸完成,數(shù)據(jù)傳輸效率提升數(shù)十倍!同時(shí)還避免了串行總線易受EMC干擾的問(wèn)題,提高了數(shù)據(jù)傳輸穩(wěn)定性,簡(jiǎn)化了應(yīng)用編程,可滿足用戶快速開(kāi)發(fā)的需求。
以上就是多核異構(gòu)處理器中A核與M核通信過(guò)程的解析,想要了解具體詳細(xì)程序?qū)嵗傻健?a target="_blank">飛凌嵌入式官方微信公眾號(hào)】回復(fù)關(guān)鍵詞“程序?qū)嵗辈榭?/strong>。
-
處理器
+關(guān)注
關(guān)注
68文章
19317瀏覽量
230103
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于IMX8MM處理器Cortex-A核和Cortex-M核的RPMsg通信方案

全志T113雙核異構(gòu)處理器的使用基于Tina Linux5.0——異構(gòu)雙核通信驗(yàn)證
基于全志T113-i多核異構(gòu)處理器的全國(guó)產(chǎn)嵌入式核心板簡(jiǎn)介
MicroBlaze V軟核處理器的功能特性
【米爾NXP i.MX 93開(kāi)發(fā)板試用評(píng)測(cè)】1、異構(gòu)核心通信的技術(shù)內(nèi)容
基于國(guó)產(chǎn)異構(gòu)雙核(RISC-V+FPGA)處理器,AG32開(kāi)發(fā)板開(kāi)發(fā)資料
淺談國(guó)產(chǎn)異構(gòu)雙核RISC-V+FPGA處理器AG32VF407的優(yōu)勢(shì)和應(yīng)用場(chǎng)景
關(guān)于2K1000LA的核間中斷
復(fù)旦微PS+PL異構(gòu)多核開(kāi)發(fā)案例分享,基于FMQL20SM國(guó)產(chǎn)處理器平臺(tái)
君正X2600在3D打印機(jī)上的優(yōu)勢(shì):多核異構(gòu),遠(yuǎn)程控制與實(shí)時(shí)控制
瑞薩電子RZ/V2H MPU提升機(jī)器人與自主應(yīng)用中的AI性能和實(shí)時(shí)控制
多核異構(gòu)通信框架(RPMsg-Lite)

基于嵌入式RISC-V處理器核輕松實(shí)現(xiàn)DSP擴(kuò)展設(shè)計(jì)
如何提高處理器的性能
瑞薩RZ/G2L MPU的多核異構(gòu)設(shè)計(jì)及通信方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論