") 旭日X3派BPU部署教程系列之帶你輕松走出模型部署新手村
旭日X3派BPU部署教程系列之帶你輕松走出模型部署新手村
安裝準(zhǔn)備
本部分主要介紹在使用工具鏈前必須的環(huán)境準(zhǔn)備工作,包含開發(fā)機(jī)部署(個人電腦)和開發(fā)板部署(例如旭日開發(fā)板等包含BPU設(shè)備)兩個部分。
開發(fā)機(jī)部署(個人電腦)
官方的示例教程的開發(fā)機(jī)都是Linux系統(tǒng),實際上Windows系統(tǒng)也是可以的。最建議的方式是利用docker,模型轉(zhuǎn)換過程主要還是基于CPU,用不到GPU,所以用docker就夠了。
(1)安裝docker
考慮到用戶多數(shù)是基于個人電腦,所以相關(guān)環(huán)境的配置都是基于Windows的。相關(guān)文檔內(nèi)提供了Docker Desktop Installer.exe安裝文件(見地平線開發(fā)者社區(qū)),安裝之后,用管理員方式啟動得到如下界面。

我們可以從地平線天工開物cpu docker hub獲取部署所需要的CentOS Docker鏡像。使用最新鏡像v1.13.6,以管理員模式運(yùn)行CMD,輸入docker,可以顯示出docker的幫助信息。
選擇最新版本,則在cmd中輸入命令docker pull openexplorer/ai_toolchain_centos_7:v1.13.6,即可自動開始docker的安裝。
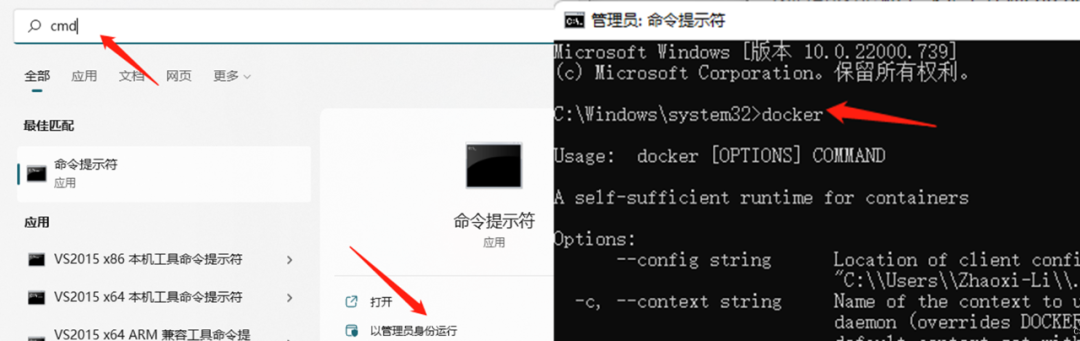
安裝成功之后,即可在docker中查看成功安裝的工具鏈鏡像:
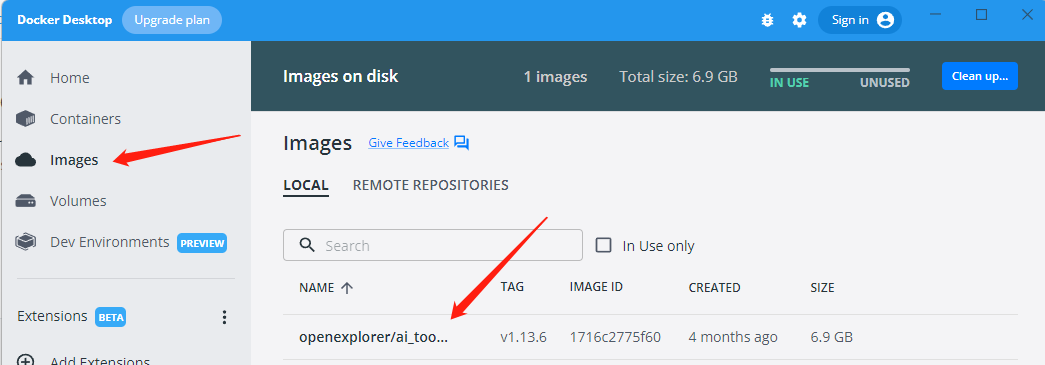
(2)配置天工開物OpenExplorer
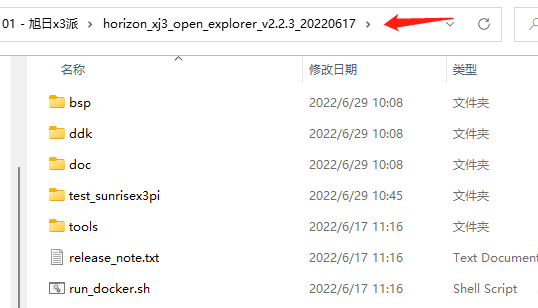
OpenExplorer工具包的下載,需要wget支持,wget的下載鏈接為GNU Wget for Windows,安裝好之后即可在cmd中通過如下命令下載工具包,解壓后,工具包的內(nèi)容如下所示,如果需要其他版本的,可以參考官網(wǎng)信息資料下載專區(qū)。
docker除了要掛載OpenExplorer工具包,還要掛載數(shù)據(jù)集文件夾,通過如下指令可以下載官方提供的數(shù)據(jù)集,或者從相關(guān)文檔中的的OpenExplorer/dataset文件夾中下載,下載之后記得解壓。
# cifar wget -c ftp://vrftp.horizon.ai/Open_Explorer/eval_dataset/cifar-10.tar.gz # cityscapes wget -c ftp://vrftp.horizon.ai/Open_Explorer/eval_dataset/cityscapes.tar.gz # coco wget -c ftp://vrftp.horizon.ai/Open_Explorer/eval_dataset/coco.tar.gz # imagenet wget -c ftp://vrftp.horizon.ai/Open_Explorer/eval_dataset/imagenet.tar.gz # VOC wget -c ftp://vrftp.horizon.ai/Open_Explorer/eval_dataset/VOC.tar.gz
(PS.由于作者在Windows下解壓導(dǎo)致部分軟連接消失,因此補(bǔ)充一些必要的軟連接更新)
# 重新構(gòu)建model_zoo軟連接 rm /open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/model_zoo ln -s /open_explorer/ddk/samples/ai_toolchain/model_zoo /open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/model_zoo
(3) 啟動Docker
按照教程,啟動docker要執(zhí)行run_docker.sh,可直接按照本文教程直接配置好指令即可。在進(jìn)入docker之前,先記錄兩個內(nèi)容:
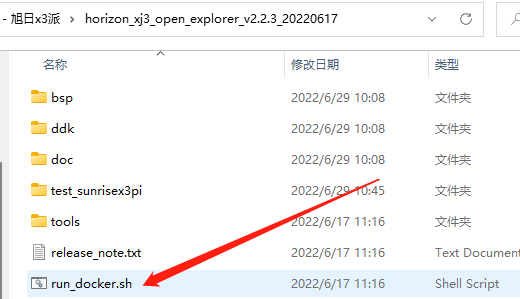
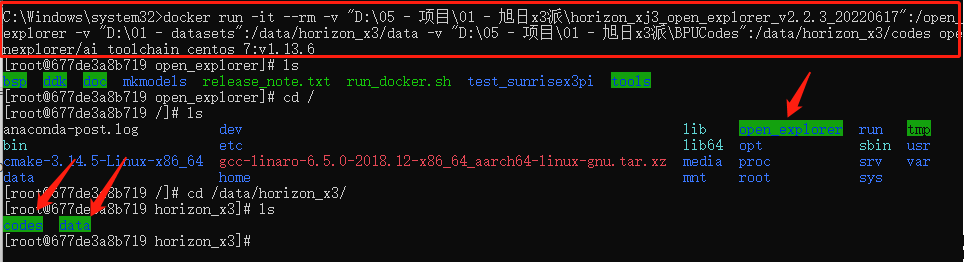
天工開物OpenExplorer根目錄:我的環(huán)境下是"D:\05 - 項目\01 - 旭日x3派\horizon_xj3_open_explorer_v2.2.3_20220617",記得加雙引號防止出現(xiàn)空格,該目錄要掛載在docker中/open_explorer目錄下;
dataset根目錄:我的環(huán)境下是"D:\01 - datasets",記得加雙引號防止出現(xiàn)空格,該目錄需要掛載在docker中的/data/horizon_x3/data目錄下;
*輔助文件夾根目錄:官方教程其實是沒有這個過程的,我把這個掛載在docker里,就是充當(dāng)個類似U盤的介質(zhì)。比如在我的環(huán)境下是"D:\05 - 項目\01 - 旭日x3派\BPUCodes",我可以在windows里面往這個文件夾拷貝數(shù)據(jù),這些數(shù)據(jù)就可以在docker中使用,在docker中的路徑為/data/horizon_x3/codes。
那么,在cmd(管理員)中輸入如下指令即可進(jìn)入docker(切記要確保剛剛安裝的軟件docker desktop是開啟的),值得注意的是CMD不支持換行,記得刪掉后面的\然后整理為一行,這時我們可以看到由命令行掛載的3個目錄。
import cv2 # 打開攝像頭并顯示 docker run -it --rm \ -v "D:\05 - 項目\01 - 旭日x3派\horizon_xj3_open_explorer_v2.2.3_20220617":/open_explorer \ -v "D:\01 - datasets":/data/horizon_x3/data \ -v "D:\05 - 項目\01 - 旭日x3派\BPUCodes":/data/horizon_x3/codes \ openexplorer/ai_toolchain_centos_7:v1.13.6
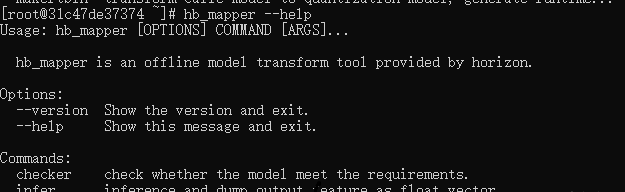
至此,已經(jīng)成功通過Docker鏡像進(jìn)入了完整的工具鏈開發(fā)環(huán)境。可以鍵入 hb_mapper --help 命令驗證下是否可以正常得到幫助信息,hb_mapper 是工具鏈的一個常用工具, 在后文的模型轉(zhuǎn)換部分對其有詳細(xì)介紹。
除了通過掛載個額外的文件夾來實現(xiàn)文件的拷貝,還有一個方法可以直接將文件拷貝到目標(biāo)目錄。
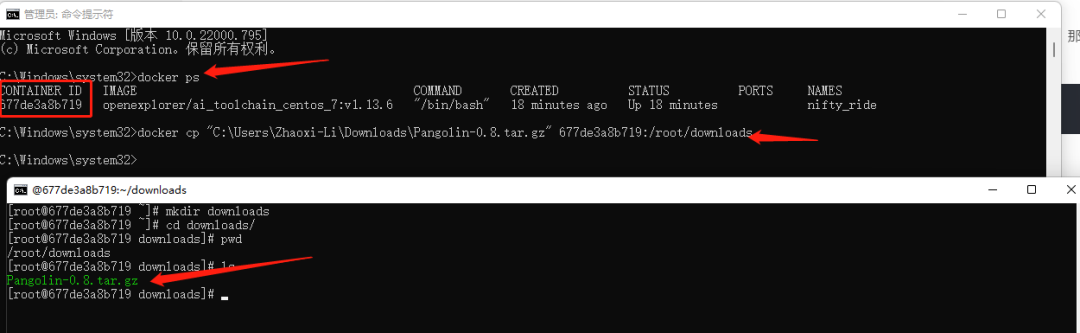
假如我們要拷貝一個文件"C:\Users\Zhaoxi-Li\Downloads\Pangolin-0.8.tar.gz"到docker中的/root/downloads下(目錄要存在),那么用管理員權(quán)限新開一個cmd,輸入docker ps,記錄CONTAINER ID,然后按照docker cp 本地文件的路徑 container_id:的方式輸入docker cp "C:\Users\Zhaoxi-Li\Downloads\Pangolin-0.8.tar.gz" 677de3a8b719:/root/downloads即可完成文件拷貝。
開發(fā)板部署(旭日3派為例)
在使用之前,一定要按照教程多方位玩轉(zhuǎn)《地平線新發(fā)布AIoT開發(fā)板——旭日X3派(Sunrise x3 Pi)》(可于「地平線開發(fā)者社區(qū)」-「開發(fā)者論壇」搜索查看)完成系統(tǒng)的啟動。
工具鏈的部分補(bǔ)充工具未包含在系統(tǒng)鏡像中,這些工具已經(jīng)放置在Open Explorer發(fā)布包中。因此在我們剛剛拉取的docker中,輸入cd /open_explorer/ddk/package/board/,執(zhí)行命令bash install.sh 192.168.0.104,其中192.168.0.104為開發(fā)板IP地址,可用ifconfig查看。
這個功能主要就是拷貝hrt_bin_dump和hrt_model_exec到開發(fā)板,并在開發(fā)板的/etc/profile里面添加幾個環(huán)境,添加內(nèi)容如下所示。
#Horizon Open Explorer ENV export PATH=/userdata/.horizon/:/userdata/.horizon/ai_express_webservice_display/sbin/:$PATH export HORIZON_APP_PATH=/userdata/.horizon/:$HORIZON_APP_PATH #Horizon Open Explorer ENV
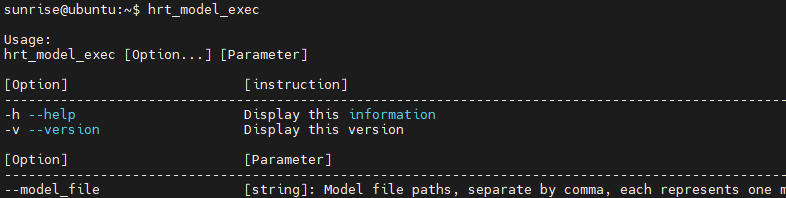
在開發(fā)板里輸入hrt_model_exec,如果有如下輸出,說明開發(fā)板部署完成。
模型部署
BPU的工具鏈?zhǔn)欠浅iL的,在部署之前一定要先理解下每個流程的含義。
模型準(zhǔn)備
支持Caffe模型和ONNX模型,Caffe模型的支持度是最高的。咱們常用的Pytorch模型是可以轉(zhuǎn)為ONNX模型的。實際上,OpenCV內(nèi)部集成的dnn模塊也是以caffe為主的,所以盡管Caffe在學(xué)術(shù)圈不火了,但它在工業(yè)圈一直廣泛使用。
驗證模型
驗證模型中所用的層是否可以在BPU中使用。需要利用hb_mapper checker后面跟一堆參數(shù)來對模型進(jìn)行配置。配置信息如下:
--model-type:輸入的模型類型,onnx或caffe ;
--march:芯片類型,這個板子只能填bernoulli2;
--proto:若模型為caffe,則填入caffe所需的prototxt文件。onnx模型就不用寫這個參數(shù);
--model:模型文件,caffe就是*.caffemodel,onnx模型就是.onnx;
--input-shape:模型數(shù)據(jù)輸入的名稱和維度,比如輸入層名稱叫input1,維度為1x3x128x128,那么該參數(shù)就可以寫為--input-shape input1 1x3x128x128。如果我們的模型有多個輸入,比如第二個輸入層名稱叫input2,維度為1x96x28x28,那么參數(shù)設(shè)置就寫為--input-shape input1 1x3x128x128 --input-shape input2 1x96x28x28(該參數(shù)可選,不寫的話程序會自動識別參數(shù),如果指定以指定為主);
--output:設(shè)置輸出日志文件(已經(jīng)移除,默認(rèn)存在根目錄的hb_mapper_checker.log中);
注意:如果模型檢查不通過,控制臺會有明顯的ERROR信息,一般都會檢查出某些層不支持BPU,這時候可以寫個自定義層來解決,后面會提供個例子來展示不通過情況的處理辦法。
轉(zhuǎn)換模型
模型檢查通過之后,就可以通過配置一個yaml文件來將模型文件轉(zhuǎn)為可以在BPU上運(yùn)行的文件了,后面配置模型時候會進(jìn)行詳細(xì)介紹。
--model-type:根據(jù)模型類型指定caffe或onnx;
--config:模型編譯的配置文件,內(nèi)容采用yaml格式,文件名使用.yaml后綴。
模型性能、精度分析與調(diào)優(yōu)
初時BPU的時候都會疑惑,為什么轉(zhuǎn)換模型后精度會有變化?因為模型轉(zhuǎn)換后是由float轉(zhuǎn)為int8計算的,這個過程必有精度損失。如果精度差異較大,就需要按照官方教程進(jìn)行調(diào)優(yōu)。
Yolov3部署示例
將yolov3放置在docker文件中的/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/04_detection/02_yolov3_darknet53/mapper路徑下,以官方示例,來初步了解下BPU的相關(guān)操作流程。

模型準(zhǔn)備
prototxt和caffemodel文件放置在docker中的/open_explorer/ddk/samples/ai_toolchain/model_zoo/mapper/detection/yolov3_darknet53路徑下。

驗證模型
/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/04_detection/02_yolov3_darknet53/mapper,進(jìn)入該路徑后,輸入 ./01_check.sh,遇到下述這些輸出,就代表轉(zhuǎn)換完成了。
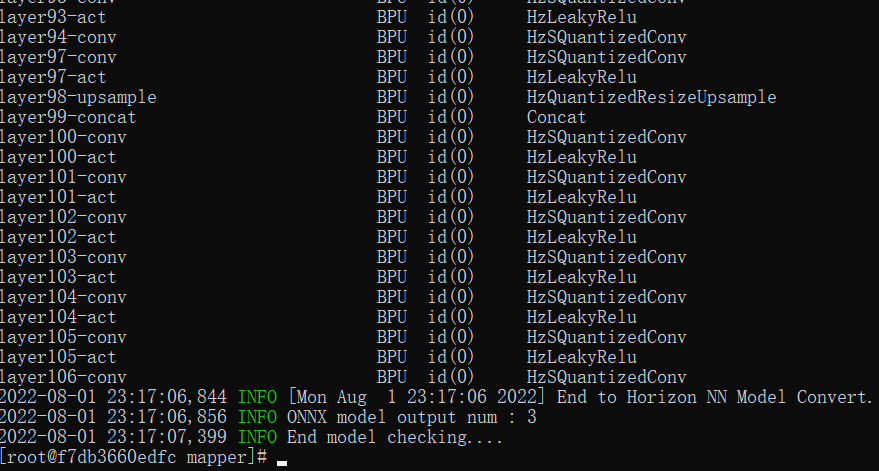
前面已經(jīng)介紹了,模型驗證需要利用hb_mapper checker后面跟一堆參數(shù)來對模型進(jìn)行配置,下面這些就是 ./01_check.sh的主要內(nèi)容。

下面帶各位來理解這些參數(shù):
--model-type:我們這些模型是Caffe,所以填caffe;
--march:旭日X3派只能填bernoulli2;
--proto:填prototxt文件路徑
即../../../01_common/model_zoo/mapper/detection/yolov3_darknet53/yolov3_transposed.prototxt;
--model:填caffemodel文件路徑
即../../../01_common/model_zoo/mapper/detection/yolov3_darknet53/yolov3.caffemodel;
--input-shape:這里沒有指定,代碼可以自動去查找。
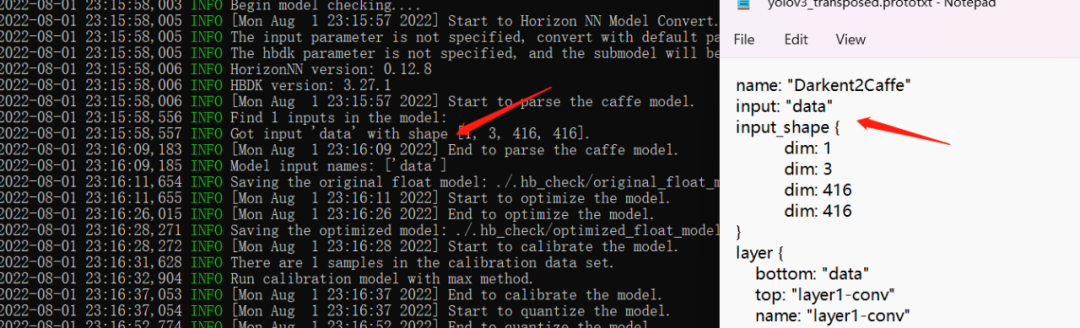
轉(zhuǎn)換模型
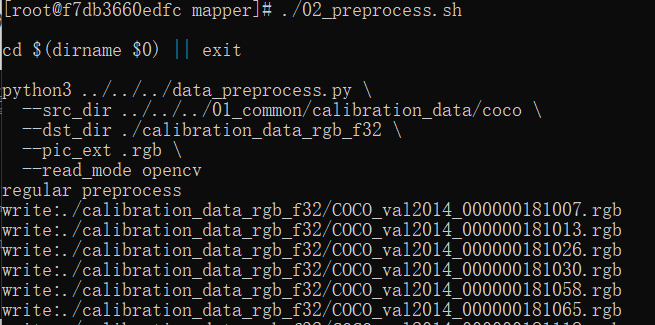
在轉(zhuǎn)換模型之前需要準(zhǔn)備校準(zhǔn)數(shù)據(jù),輸入./02_preprocess.sh會自動從docker的open_explorer包中抽取數(shù)據(jù);再輸入./03_build.sh,輸出一大堆的命令行,等待一段時間之后會輸出。
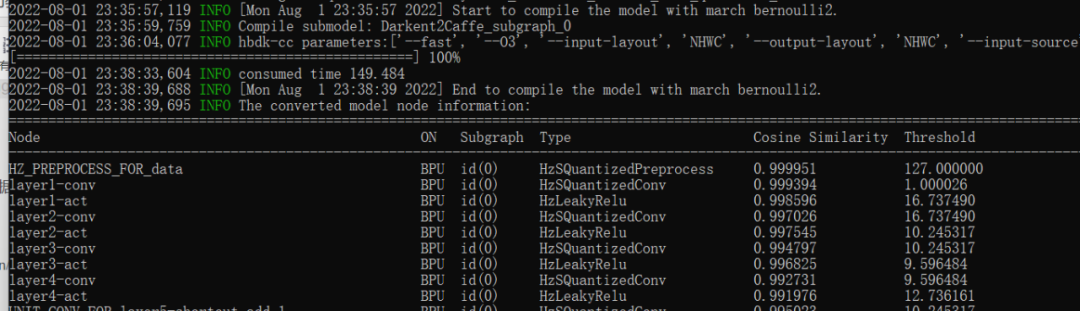
這里我們可以發(fā)現(xiàn)每一層網(wǎng)絡(luò)都要評估一個相似度,這也是為什么要準(zhǔn)備校準(zhǔn)數(shù)據(jù),因為BPU是INT8計算,所以注定會有精度損失。而且這些誤差也是可以傳遞的,所以到后面精度是越來越低的。如果網(wǎng)絡(luò)深度過高,也會導(dǎo)致整體精度的下降。
為了更好的理解這些轉(zhuǎn)換流程,將對其中的準(zhǔn)備校準(zhǔn)數(shù)據(jù)、模型轉(zhuǎn)換過程進(jìn)行一個完全解讀。
(1)原理解讀:準(zhǔn)備校準(zhǔn)數(shù)據(jù)
這個過程調(diào)用了腳本./02_preprocess.sh,這個腳本核心調(diào)用的是python文件,data_preprocess.py的源碼可以自行去查看。
python3 ../../../data_preprocess.py \ --src_dir ../../../01_common/calibration_data/coco \ --dst_dir ./calibration_data_rgb_f32 \ --pic_ext .rgb \ --read_mode opencv
然而data_preprocess.py并不適合初學(xué)者進(jìn)行閱讀,因為其兼容了太多東西,很簡單的一些功能硬是寫復(fù)雜了,那么就圍繞這個模型,給各位縷縷校準(zhǔn)數(shù)據(jù)到底要準(zhǔn)備啥。
首先要搞清楚,我們要準(zhǔn)備的校準(zhǔn)數(shù)據(jù)是什么樣的: 校準(zhǔn)數(shù)據(jù)要將圖像數(shù)據(jù)按照目標(biāo)尺寸、目標(biāo)顏色(rgb or bgr等)、目標(biāo)排布(CHW or HWC)進(jìn)行存儲。那么下面,帶著這些問題進(jìn)行處理,先構(gòu)建一個基本處理流程:
①加載一個文件夾下的所有圖像地址信息。圖像目錄為/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/calibration_data/coco;
②對每個圖像按照校準(zhǔn)格式進(jìn)行輸出。從prototxt我們知道圖像的尺寸為416x416,從./03_build.sh調(diào)用的yaml文件可知圖像輸入格式為rgb,數(shù)據(jù)排布為CHW;
③將轉(zhuǎn)換后的圖像利用numpy.tofile函數(shù)存到目標(biāo)文件夾下(你在哪轉(zhuǎn)換的,就要在哪個目錄存校準(zhǔn)數(shù)據(jù)文件夾calibration_data)。
開始寫我們自己的Python代碼,每個步驟都寫了注釋,各位可以直接理解。
# prepare_calibration_data.py import os import cv2 import numpy as np src_root = '/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/calibration_data/coco' cal_img_num = 100 # 想要的圖像個數(shù) dst_root = '/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/04_detection/02_yolov3_darknet53/mapper/calibration_data' ## 1. 從原始圖像文件夾中獲取100個圖像作為校準(zhǔn)數(shù)據(jù) num_count = 0 img_names = [] for src_name in sorted(os.listdir(src_root)): if num_count > cal_img_num: break img_names.append(src_name) num_count += 1 # 檢查目標(biāo)文件夾是否存在,如果不存在就創(chuàng)建 if not os.path.exists(dst_root): os.system('mkdir {0}'.format(dst_root)) ## 2 為每個圖像轉(zhuǎn)換 # 參考了OE中/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/python/data/下的相關(guān)代碼 # 轉(zhuǎn)換代碼寫的很棒,很智能,考慮它并不是官方python包,所以我打算換一種寫法 ## 2.1 定義圖像縮放函數(shù),返回為np.float32 # 圖像縮放為目標(biāo)尺寸(W, H) # 值得注意的是,縮放時候,長寬等比例縮放,空白的區(qū)域填充顏色為pad_value, 默認(rèn)127 def imequalresize(img, target_size, pad_value=127.): target_w, target_h = target_size image_h, image_w = img.shape[:2] img_channel = 3 if len(img.shape) > 2 else 1 # 確定縮放尺度,確定最終目標(biāo)尺寸 scale = min(target_w * 1.0 / image_w, target_h * 1.0 / image_h) new_h, new_w = int(scale * image_h), int(scale * image_w) resize_image = cv2.resize(img, (new_w, new_h)) # 準(zhǔn)備待返回圖像 pad_image = np.full(shape=[target_h, target_w, img_channel], fill_value=pad_value) # 將圖像resize_image放置在pad_image的中間 dw, dh = (target_w - new_w) // 2, (target_h - new_h) // 2 pad_image[dh:new_h + dh, dw:new_w + dw, :] = resize_image return pad_image ## 2.2 開始轉(zhuǎn)換 for each_imgname in img_names: img_path = os.path.join(src_root, each_imgname) img = cv2.imread(img_path) # BRG, HWC img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB, HWC img = imequalresize(img, (416, 416)) img = np.transpose(img, (2, 0, 1)) # RGB, CHW # 將圖像保存到目標(biāo)文件夾下 dst_path = os.path.join(dst_root, each_imgname + '.rgbchw') print("write:%s" % dst_path) # 圖像加載默認(rèn)就是uint8,但是不加這個astype的話轉(zhuǎn)換模型就會出錯 # 轉(zhuǎn)換模型時候,加載進(jìn)來的數(shù)據(jù)竟然是float64,不清楚內(nèi)部是怎么加載的。 img.astype(np.uint8).tofile(dst_path) print('finish')
(2)原理解讀:轉(zhuǎn)換配置
模型轉(zhuǎn)換的核心在于配置目標(biāo)的yaml文件,官方也提供了一個yolov3_darknet53_config.yaml可供用戶直接試用,每個參數(shù)都給了注釋,我能感受到開發(fā)者的誠意。然而模型轉(zhuǎn)換的配置文件參數(shù)太多,如果想改參數(shù)都不知道如何下手。
本節(jié)目的是引導(dǎo)各位快速上手,因此一些參數(shù)我暫時不解釋意義,用默認(rèn)即可。該模板可將待配置的30多個參數(shù)壓縮到9個參數(shù),方便各位快速的配置簡單模型。本yaml模板適用于的模型具有如下屬性:
- 無自定義層,換句話說,BPU支持該模型的所有層;
- 輸入節(jié)點(diǎn)只有1個,且輸入是圖像。
先復(fù)制這個模板到代碼根目錄,命名為"yolov3_simple.yaml",然后根據(jù)后面的思維導(dǎo)圖進(jìn)行配置具體參數(shù)。
model_parameters: # [待配置參數(shù)],見思維導(dǎo)圖"模型參數(shù)組"部分 prototxt: '***.prototxt' caffe_model: '****.caffemodel' onnx_model: '****.onnx' output_model_file_prefix: 'mobilenetv1' # 默認(rèn)參數(shù),暫不需要理解 march: 'bernoulli2' input_parameters: # [待配置參數(shù)],見思維導(dǎo)圖"輸入信息參數(shù)組/原始模型參數(shù)"部分 input_type_train: 'bgr' input_layout_train: 'NCHW' # [待配置參數(shù)],見思維導(dǎo)圖"輸入信息參數(shù)組/轉(zhuǎn)換后模型參數(shù)"部分 input_type_rt: 'yuv444' # [待配置參數(shù)],見思維導(dǎo)圖"輸入信息參數(shù)組/輸入數(shù)據(jù)預(yù)處理"部分 norm_type: 'data_mean_and_scale' mean_value: '103.94 116.78 123.68' scale_value: '0.017' # 默認(rèn)參數(shù),暫不需要理解 input_layout_rt: 'NHWC' # 校準(zhǔn)參數(shù)組,全部默認(rèn) calibration_parameters: cal_data_dir: './calibration_data' calibration_type: 'max' max_percentile: 0.9999 # 編譯參數(shù)組,全部默認(rèn) compiler_parameters: compile_mode: 'latency' optimize_level: 'O3' debug: False # 別看官網(wǎng)寫的可選,實際上不寫這個出bug
思維導(dǎo)圖如下所示,帶著這個圖,請各位耐心地跟我一步步配置,僅需要配置9個即可。
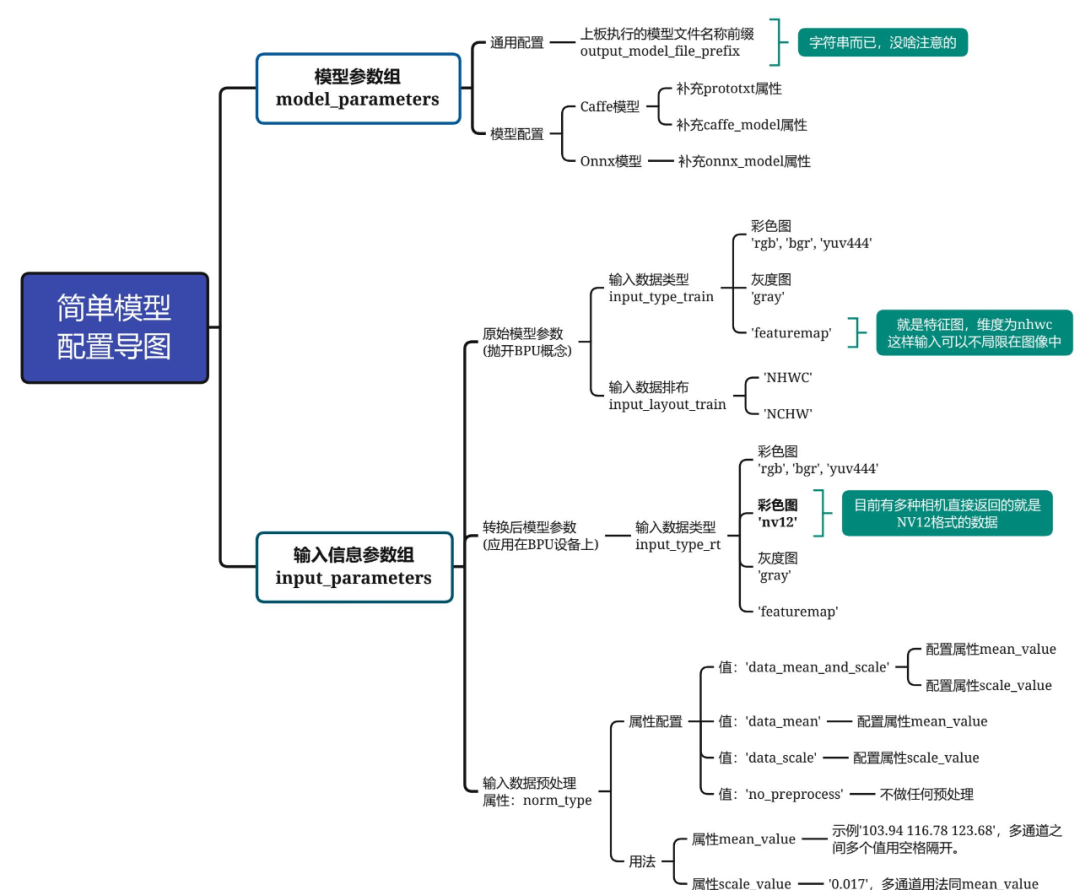
模型參數(shù)組參數(shù)model_parameters配置:
output_model_file_prefix:給轉(zhuǎn)換后的模型起個名,這里叫做'yolov3_selfyaml',注意字符串前后都要有個單引號;
prototxt:caffe的prototxt,這里為'../../../01_common/model_zoo/mapper/detection/yolov3_darknet53/yolov3_transposed.prototxt';
caffe_model:caffe的模型文件,這里為'../../../01_common/model_zoo/mapper/detection/yolov3_darknet53/yolov3.caffemodel';
onnx_model:刪掉。因為我們用的是Caffe。
輸入信息組參數(shù)配置input_parameters:
input_type_train:原始浮點(diǎn)模型的輸入數(shù)據(jù)格式,支持多種圖像格式,這里設(shè)置為'rgb'(這就是前文校準(zhǔn)模型時為什么要將BGR轉(zhuǎn)為RGB); input_layout_train:從前文的prototxt可以看出,數(shù)據(jù)輸入排布為'NCHW'(所以在模型校準(zhǔn)時我們將圖像數(shù)據(jù)由HWC轉(zhuǎn)為CHW) input_type_rt:模型轉(zhuǎn)換后,我們期望輸入的圖像格式。我們在訓(xùn)練模型和部署模型的時候,圖像輸入格式是可以變的,NV12是一些相機(jī)返回的原始數(shù)據(jù)格式,作為嘗試設(shè)置為'nv12'; norm_type:網(wǎng)絡(luò)不可能拿原始圖像數(shù)據(jù)作為輸入的,一般都要進(jìn)行一個歸一化操作。這里用的模型對應(yīng)的歸一化代碼為inpBlob = cv2.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight), (0, 0, 0), swapRB=False, crop=False),無減均值項,只有尺度項。因此,該屬性設(shè)置為'data_scale'; mean_value:刪掉,因為網(wǎng)絡(luò)沒有均值項; scale_value:尺度為1.0 / 255,因此設(shè)置為0.003921568627451。
最終,我們的yaml文件內(nèi)容如下所示:
model_parameters: prototxt: '../../../01_common/model_zoo/mapper/detection/yolov3_darknet53/yolov3_transposed.prototxt' caffe_model: '../../../01_common/model_zoo/mapper/detection/yolov3_darknet53/yolov3.caffemodel' output_model_file_prefix: 'yolov3_selfyaml' march: 'bernoulli2' input_parameters: input_type_train: 'rgb' input_layout_train: 'NCHW' input_type_rt: 'nv12' norm_type: 'data_scale' scale_value: 0.003921568627451 input_layout_rt: 'NHWC' calibration_parameters: cal_data_dir: './calibration_data' calibration_type: 'max' max_percentile: 0.9999 compiler_parameters: compile_mode: 'latency' optimize_level: 'O3' debug: False
之后,用我們親手準(zhǔn)備的校準(zhǔn)數(shù)據(jù)和配置的輕量yaml進(jìn)行模型轉(zhuǎn)換,在控制臺輸入指令hb_mapper makertbin --config yolov3_simple.yaml --model-type caffe。
模型推理
在官方給的demo中,04_inference.sh可以直接調(diào)用執(zhí)行好的模型進(jìn)行推理,但是為了我覺得這種方案對于未來要如何部署自己的模型是無意義的。因此我閱讀了官方推理的demo之后,自己寫個完整的推理過程。模型推理流程主要可以分為以下三個步驟:
①數(shù)據(jù)預(yù)處理,生成推理所需數(shù)據(jù);
②利用處理好的數(shù)據(jù)進(jìn)行模型推理,得到輸出;
③將輸出轉(zhuǎn)換成最終數(shù)據(jù),也就是后處理過程。
(PS.使用的測試圖像路徑為/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/test_data/det_images/kite.jpg)
在上一節(jié)中,模型轉(zhuǎn)換后有三個關(guān)鍵文件:
yolov3_selfyaml_original_float_model.onnx:圖像量化前的模型; yolov3_selfyaml_quantized_model.onnx:圖像量化后的模型; yolov3_selfyaml.bin:在BPU上用于推理的模型文件,輸出結(jié)果與yolov3_selfyaml_quantized_model.onnx一致。
下面將給出推理一張圖像的相關(guān)代碼,其中我把圖像格式轉(zhuǎn)換,以及yolo后處理的細(xì)節(jié)封裝在一個包里,相關(guān)的代碼已經(jīng)放在社區(qū)里供大家參考。
以下是inference_model.py的代碼細(xì)節(jié),在每個關(guān)鍵過程中都給出了相關(guān)的注釋:
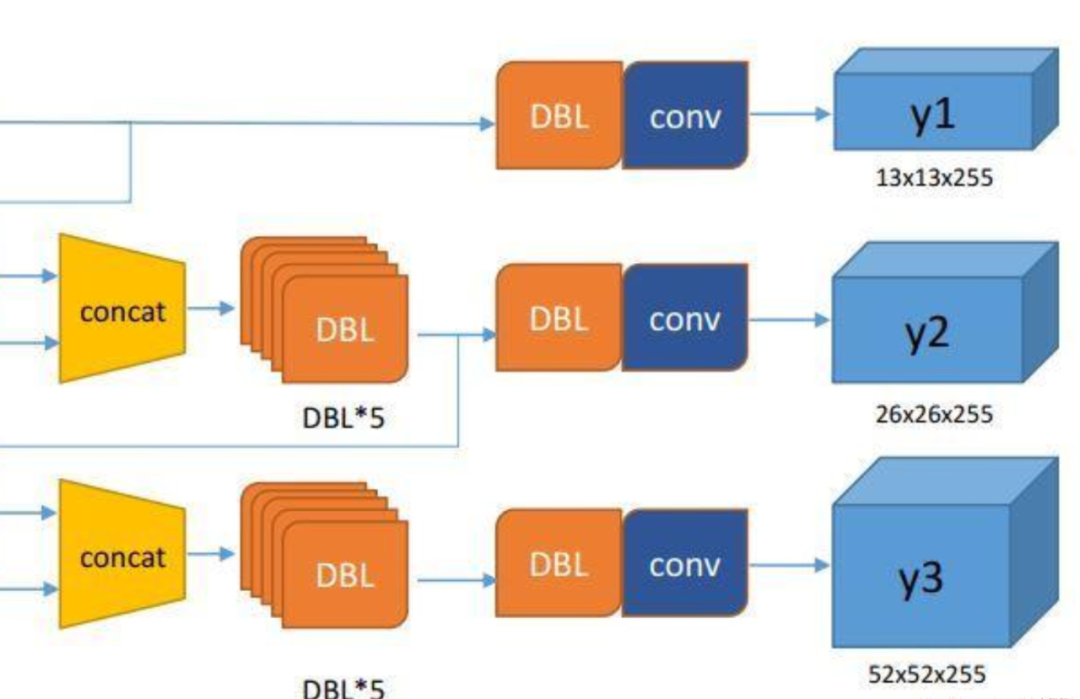
從代碼可以獲知模型會輸出三層,每層的維度為(1, 13, 13, 255) (1, 26, 26, 255) (1, 52, 52, 255),對著下圖,可以很容易對應(yīng)的是網(wǎng)絡(luò)的哪一層。
import numpy as np import cv2 import os from horizon_tc_ui import HB_ONNXRuntime from bputools.format_convert import imequalresize, bgr2nv12_opencv, nv122yuv444 from bputools.yolo_postproc import modelout2predbbox, recover_boxes, nms, draw_bboxs modelpath_prefix = '/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample' # img_path 圖像完整路徑 img_path = os.path.join(modelpath_prefix, '01_common/test_data/det_images/kite.jpg') # model_path 量化模型完整路徑 model_root = os.path.join(modelpath_prefix, '04_detection/02_yolov3_darknet53/mapper/model_output') model_path = os.path.join(model_root, 'yolov3_selfyaml_quantized_model.onnx') # 1. 加載模型,獲取所需輸出HW sess = HB_ONNXRuntime(model_file=model_path) sess.set_dim_param(0, 0, '?') model_h, model_w = sess.get_hw() # 2 加載圖像,根據(jù)前面模型,轉(zhuǎn)換后的模型是以NV12作為輸入的 # 但在OE驗證的時候,需要將圖像再由NV12轉(zhuǎn)為YUV444 imgOri = cv2.imread(img_path) img = imequalresize(imgOri, (model_w, model_h)) nv12 = bgr2nv12_opencv(img) yuv444 = nv122yuv444(nv12, [model_w, model_h]) # 3 模型推理 input_name = sess.input_names[0] output_name = sess.output_names output = sess.run(output_name, {input_name: np.array([yuv444])}, input_offset=128) print(output_name) print(output[0].shape, output[1].shape, output[2].shape) # ['layer82-conv-transposed', 'layer94-conv-transposed', 'layer106-conv-transposed'] # (1, 13, 13, 255) (1, 26, 26, 255) (1, 52, 52, 255) # 4 檢測結(jié)果后處理 # 由output恢復(fù)416*416模式下的目標(biāo)框 pred_bbox = modelout2predbbox(output) # 將目標(biāo)框恢復(fù)到原始分辨率 bboxes = recover_boxes(pred_bbox, (imgOri.shape[0], imgOri.shape[1]), input_shape=(model_h, model_w), score_threshold=0.3) # 對檢測出的框進(jìn)行非極大值抑制,抑制后得到的框就是最終檢測框 nms_bboxes = nms(bboxes, 0.45) print("detected item num: {0}".format(len(nms_bboxes))) # 繪制檢測框 draw_bboxs(imgOri, nms_bboxes) cv2.imwrite('detected.png', imgOri)
上板運(yùn)行
我們將下圖所示的一些文件拖到旭日X3派開發(fā)板中,注意inference_model_bpu.py跟docker中是有微小的改動的。
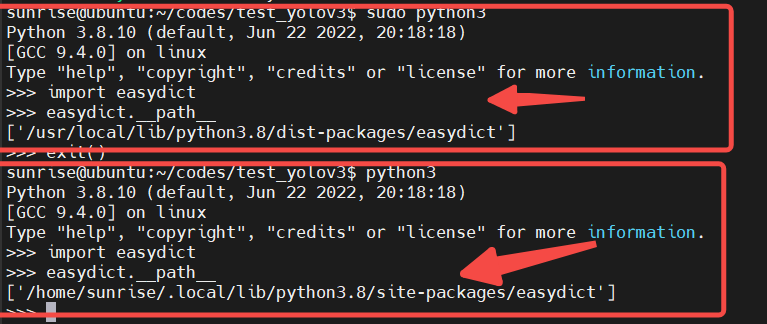
注意,在執(zhí)行前要安裝一些包sudo pip3 install EasyDict pycocotools,切記要加sudo,這樣安裝的路徑不是用戶目錄,在運(yùn)行BPU模型時候,也是必須要加sudo的。
inference_model_bpu.py的源碼如下所示,與在docker中不同,nv12不需要再轉(zhuǎn)為yuv444了,模型的運(yùn)行也有一些差別,而后處理幾乎沒有變化。
import numpy as np import cv2 import os from hobot_dnn import pyeasy_dnn as dnn from bputools.format_convert import imequalresize, bgr2nv12_opencv, nv122yuv444 from bputools.yolo_postproc import modelout2predbbox, recover_boxes, nms, draw_bboxs def get_hw(pro): if pro.layout == "NCHW": return pro.shape[2], pro.shape[3] else: return pro.shape[1], pro.shape[2] modelpath_prefix = '' # img_path 圖像完整路徑 img_path = 'COCO_val2014_000000181265.jpg' # model_path 量化模型完整路徑 model_path = 'yolov3_selfyaml.bin' # 1. 加載模型,獲取所需輸出HW models = dnn.load(model_path) model_h, model_w = get_hw(models[0].inputs[0].properties) # 2 加載圖像,根據(jù)前面模型,轉(zhuǎn)換后的模型是以NV12作為輸入的 # 但在OE驗證的時候,需要將圖像再由NV12轉(zhuǎn)為YUV444 imgOri = cv2.imread(img_path) img = imequalresize(imgOri, (model_w, model_h)) nv12 = bgr2nv12_opencv(img) # 3 模型推理 t1 = cv2.getTickCount() outputs = models[0].forward(nv12) t2 = cv2.getTickCount() outputs = (outputs[0].buffer, outputs[1].buffer, outputs[2].buffer) print(outputs[0].shape, outputs[1].shape, outputs[2].shape) # (1, 13, 13, 255) (1, 26, 26, 255) (1, 52, 52, 255) print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency())) # 4 檢測結(jié)果后處理 # 由output恢復(fù)416*416模式下的目標(biāo)框 pred_bbox = modelout2predbbox(outputs) # 將目標(biāo)框恢復(fù)到原始分辨率 bboxes = recover_boxes(pred_bbox, (imgOri.shape[0], imgOri.shape[1]), input_shape=(model_h, model_w), score_threshold=0.3) # 對檢測出的框進(jìn)行非極大值抑制,抑制后得到的框就是最終檢測框 nms_bboxes = nms(bboxes, 0.45) print("detected item num: {0}".format(len(nms_bboxes))) # 繪制檢測框 draw_bboxs(imgOri, nms_bboxes) cv2.imwrite('detected.png', imgOri)
手部關(guān)鍵點(diǎn)檢測網(wǎng)絡(luò)
手部關(guān)鍵點(diǎn)檢測是做手勢識別的一個關(guān)鍵過程,該代碼基于Caffe,而且無自定義層,因此作為個引子,帶領(lǐng)各位先初步使用BPU。
模型準(zhǔn)備
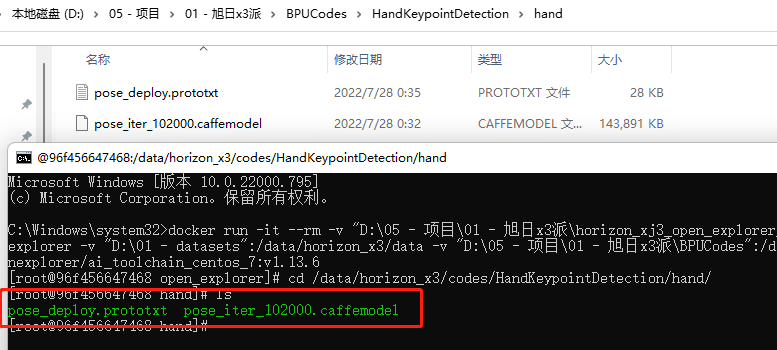
在前期安裝準(zhǔn)備中,我們掛載了一個目錄-v "D:\05 - 項目\01 - 旭日x3派\BPUCodes":/data/horizon_x3/codes,下載好代碼后,按照如下方式放置相關(guān)文件,此時可以發(fā)現(xiàn)docker中也有這些文件。
驗證模型
驗證前,先將docker根目錄切換到模型根目錄下cd /data/horizon_x3/codes/HandKeypointDetection/hand/。模型驗證需要利用hb_mapper checker后面跟一堆參數(shù)來對模型進(jìn)行配置。下面帶各位來配置這些參數(shù):
--model-type:我們這些模型是Caffe,所以填caffe
--march:旭日3派只能填bernoulli2
--proto:填prototxt文件名,即pose_deploy.prototxt
--model:填caffemodel文件名,即pose_iter_102000.caffemodel
--input-shape:打開prototxt文件,查找input屬性,可以發(fā)現(xiàn)模型只有一個輸入,輸入層的名稱為image,輸入圖像的維度大小為1x3x368x368,那么這個參數(shù)設(shè)置就寫為image 1x3x368x368。

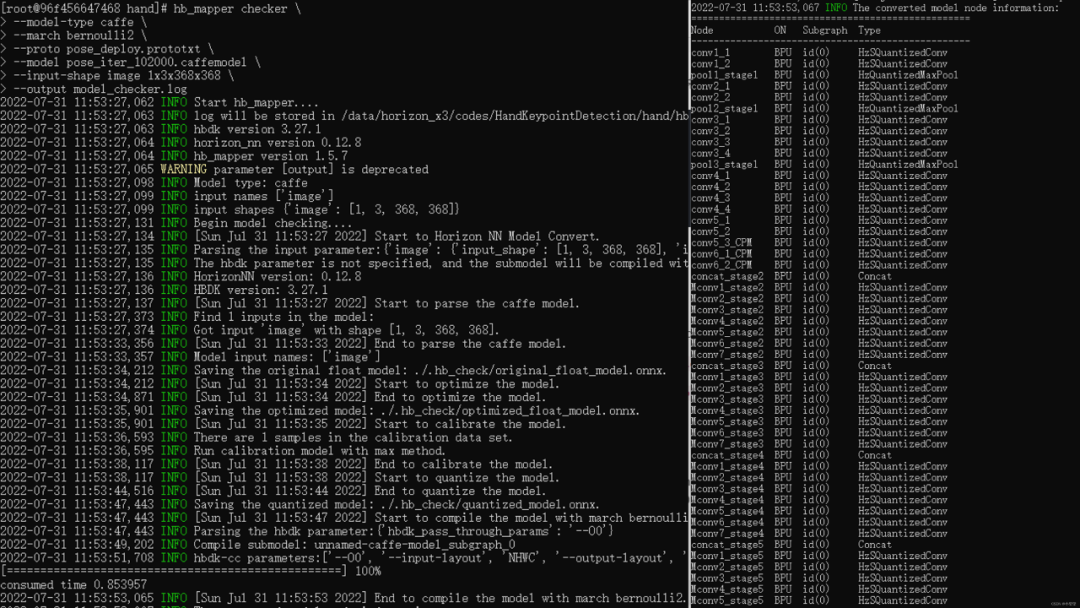
綜上所述,在docker中需要輸入如下指令來完成模型驗證過程:
hb_mapper checker \ --model-type caffe \ --march bernoulli2 \ --proto pose_deploy.prototxt \ --model pose_iter_102000.caffemodel \ --input-shape image 1x3x368x368
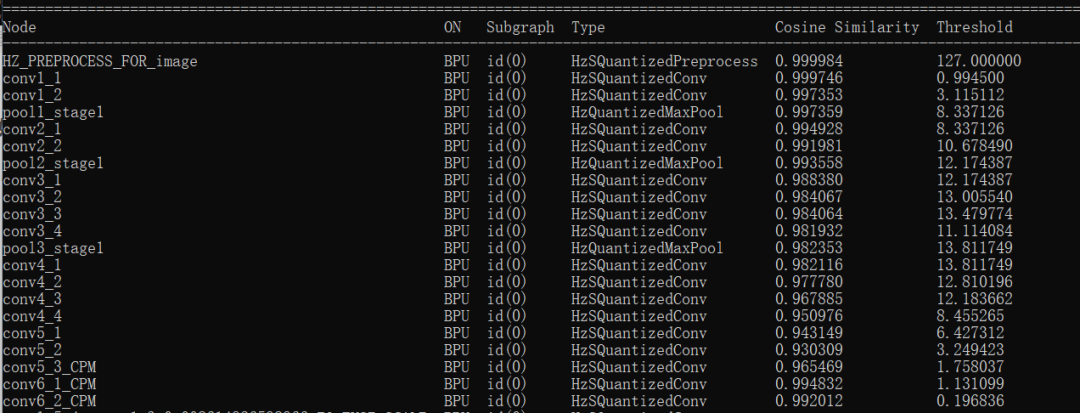
輸出結(jié)果如下所示,可以看到整個流程的轉(zhuǎn)換狀態(tài)以及每個節(jié)點(diǎn)是在BPU還是CPU上運(yùn)行的。整個控制臺的運(yùn)行結(jié)果默認(rèn)存在根目錄的hb_mapper_checker.log中。
轉(zhuǎn)換模型
與前面流程不同,這里先配置yaml文件,再準(zhǔn)備校準(zhǔn)數(shù)據(jù)。
(1)配置yaml文件
模型參數(shù)組參數(shù)model_parameters配置:
output_model_file_prefix:給轉(zhuǎn)換后的模型起個名,這里叫做'handkpdet'(hand keypoint detection);
prototxt:caffe的prototxt,這里為'pose_deploy.prototxt';
caffe_model:caffe的模型文件,這里為'pose_iter_102000.caffemodel'
onnx_model:刪掉。因為我們用的是Caffe。
輸入信息組參數(shù)配置input_parameters:
input_type_train:原始浮點(diǎn)模型的輸入數(shù)據(jù)格式,支持多種圖像格式。我們這個模型,輸入的是彩色圖,考慮到opencv加載圖像默認(rèn)是BGR通道,因此這里設(shè)置為'bgr';
input_layout_train:從前文的prototxt可以看出,數(shù)據(jù)輸入排布為'NCHW';
input_type_rt:模型轉(zhuǎn)換后,我們期望輸入的圖像格式。我們在訓(xùn)練模型和部署模型的時候,圖像輸入格式是可以變的,NV12是一些相機(jī)返回的原始數(shù)據(jù)格式,考慮到我們測試仍然基于本地圖像,因此這里仍然設(shè)置為'bgr';
norm_type:網(wǎng)絡(luò)不可能拿原始圖像數(shù)據(jù)作為輸入的,一般都要進(jìn)行一個歸一化操作。這里用的模型對應(yīng)的歸一化代碼為inpBlob = cv2.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight), (0, 0, 0), swapRB=False, crop=False),無減均值項,只有尺度項。因此,該屬性設(shè)置為'data_scale';
mean_value:刪掉,因為網(wǎng)絡(luò)沒有均值項;
scale_value:尺度為1.0 / 255,因此設(shè)置為'0.0039'。
最終,我們的yaml文件handpoint.yaml內(nèi)容為:
model_parameters: prototxt: 'pose_deploy.prototxt' caffe_model: 'pose_iter_102000.caffemodel' output_model_file_prefix: 'handkpdet' march: 'bernoulli2' input_parameters: input_type_train: 'bgr' input_layout_train: 'NCHW' input_type_rt: 'bgr' norm_type: 'data_scale' scale_value: '0.0039' input_layout_rt: 'NHWC' calibration_parameters: cal_data_dir: './calibration_data' calibration_type: 'max' max_percentile: 0.9999 compiler_parameters: compile_mode: 'latency' optimize_level: 'O3' debug: False
(2)準(zhǔn)備校準(zhǔn)數(shù)據(jù)
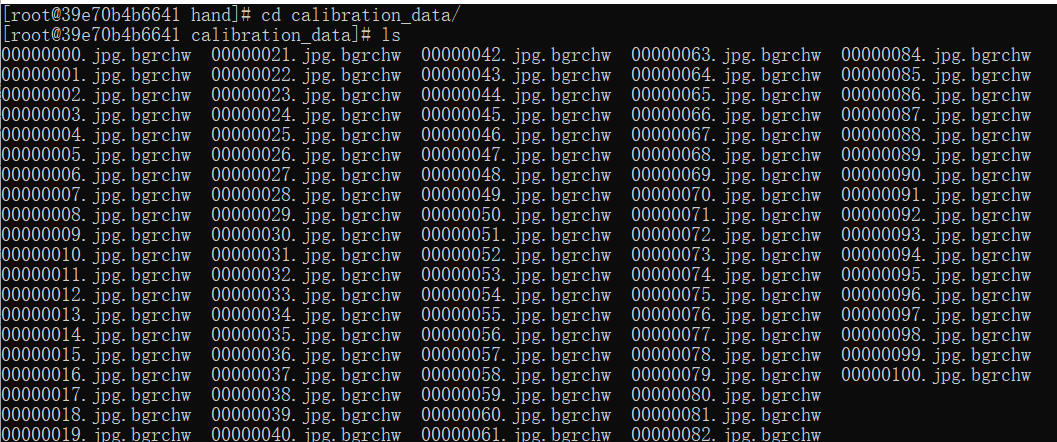
考慮到這個模型的輸入只有一個,因此,準(zhǔn)備校準(zhǔn)數(shù)據(jù)部分的代碼可以參考上一節(jié)的內(nèi)容,需要修改的只有兩個地方,原始數(shù)據(jù)地址,和顏色轉(zhuǎn)換部分(取消了BGR轉(zhuǎn)RGB的過程),數(shù)據(jù)集用的是FreiHAND_pub_v2_eval.zip。

docker中,校準(zhǔn)數(shù)據(jù)形式如下圖所示,共計100張。
(3)開始轉(zhuǎn)換
數(shù)據(jù)準(zhǔn)備就緒,輸入命令hb_mapper makertbin --config handpoint.yaml --model-type caffe開始轉(zhuǎn)換我們的模型!等待一段時間之后,模型轉(zhuǎn)換成功,從結(jié)果可以看出來,模型的損失并不是很高!!感覺有戲,(☆▽☆)。
模型推理
由于該模型與前面的模型相似,都是以一張圖像作為輸入的,因此自己要補(bǔ)充的工作主要有兩點(diǎn):
- 完成圖像預(yù)處理部分。前面的yaml文件指明了,量化后的模型是以BGR、NHWC格式作為輸入的。因此,只需要調(diào)用resize成目標(biāo)模型大小就行,opencv加載圖像時候默認(rèn)是HWC格式。
- 完成圖像后處理部分。圖像后處理一般與推理平臺沒有太大的關(guān)系,完整的流程都會有這個過程。
在docker中推理的完整代碼如下所示:
import numpy as np import cv2 import os from horizon_tc_ui import HB_ONNXRuntime import copy # img_path 圖像完整路徑 img_path = '/data/horizon_x3/codes/HandKeypointDetection/hand/FreiHAND_pub_v2_eval/evaluation/rgb/00000253.jpg' # model_path 量化模型完整路徑 model_path = '/data/horizon_x3/codes/HandKeypointDetection/hand/model_output/handkpdet_quantized_model.onnx' # 1. 加載模型,獲取所需輸出HW sess = HB_ONNXRuntime(model_file=model_path) sess.set_dim_param(0, 0, '?') model_h, model_w = sess.get_hw() # 2 加載圖像,根據(jù)前面yaml,量化后的模型以BGR NHWC形式輸入 imgOri = cv2.imread(img_path) img = cv2.resize(imgOri, (model_w, model_h)) # 3 模型推理 input_name = sess.input_names[0] output_name = sess.output_names output = sess.run(output_name, {input_name: np.array([img])}, input_offset=128) print(output_name) print(output[0].shape) # ['net_output'] # (1, 22, 46, 46) # 4 檢測結(jié)果后處理 # 繪制關(guān)鍵點(diǎn) nPoints = 22 threshold = 0.1 POSE_PAIRS = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], [10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]] imgh, imgw = imgOri.shape[:2] points = [] imgkp = copy.deepcopy(imgOri) for i in range(nPoints): probMap = output[0][0, i, :, :] probMap = cv2.resize(probMap, (imgw, imgh)) minVal, prob, minLoc, point = cv2.minMaxLoc(probMap) if prob > threshold: cv2.circle(imgkp, (int(point[0]), int(point[1])), 8, (0, 255, 255), thickness=-1, lineType=cv2.FILLED) cv2.putText(imgkp, "{}".format(i), (int(point[0]), int(point[1])), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, lineType=cv2.LINE_AA) points.append((int(point[0]), int(point[1]))) else: points.append(None) # 繪制骨架 imgskeleton = copy.deepcopy(imgOri) for pair in POSE_PAIRS: partA = pair[0] partB = pair[1] if points[partA] and points[partB]: cv2.line(imgskeleton, points[partA], points[partB], (0, 255, 255), 2) cv2.circle(imgskeleton, points[partA], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED) cv2.circle(imgskeleton, points[partB], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED) # 保存關(guān)鍵點(diǎn)和骨架圖 cv2.imwrite('handkeypoint.png', imgkp) cv2.imwrite('imgskeleton.png', imgskeleton)
上板運(yùn)行
在開發(fā)板運(yùn)行的程序與上述推理代碼差異不大,注意好模型的輸入數(shù)據(jù)格式即可,這里要注意,輸出的outputs與docker中有差異,要做output = (outputs[0].buffer,)轉(zhuǎn)換,這樣可以直接兼容后面的后處理部分,進(jìn)而生成結(jié)果圖。
import numpy as np import cv2 import os from hobot_dnn import pyeasy_dnn as dnn import copy def get_hw(pro): if pro.layout == "NCHW": return pro.shape[2], pro.shape[3] else: return pro.shape[1], pro.shape[2] # img_path 圖像完整路徑 img_path = '20220806023323.jpg' # model_path 量化模型完整路徑 model_path = 'handkpdet.bin' # 1. 加載模型,獲取所需輸出HW models = dnn.load(model_path) model_h, model_w = get_hw(models[0].inputs[0].properties) # 2 加載圖像,根據(jù)前面yaml,量化后的模型以BGR NHWC形式輸入 imgOri = cv2.imread(img_path) img = cv2.resize(imgOri, (model_w, model_h)) # 3 模型推理 t1 = cv2.getTickCount() outputs = models[0].forward(img) t2 = cv2.getTickCount() output = (outputs[0].buffer,) print(outputs[0].buffer.shape) # (1, 22, 46, 46) print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency())) # 4 檢測結(jié)果后處理 # 繪制關(guān)鍵點(diǎn) nPoints = 22 threshold = 0.1 POSE_PAIRS = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], [10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]] imgh, imgw = imgOri.shape[:2] points = [] imgkp = copy.deepcopy(imgOri) for i in range(nPoints): probMap = output[0][0, i, :, :] probMap = cv2.resize(probMap, (imgw, imgh)) minVal, prob, minLoc, point = cv2.minMaxLoc(probMap) if prob > threshold: cv2.circle(imgkp, (int(point[0]), int(point[1])), 8, (0, 255, 255), thickness=-1, lineType=cv2.FILLED) cv2.putText(imgkp, "{}".format(i), (int(point[0]), int(point[1])), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, lineType=cv2.LINE_AA) points.append((int(point[0]), int(point[1]))) else: points.append(None) # 繪制骨架 imgskeleton = copy.deepcopy(imgOri) for pair in POSE_PAIRS: partA = pair[0] partB = pair[1] if points[partA] and points[partB]: cv2.line(imgskeleton, points[partA], points[partB], (0, 255, 255), 2) cv2.circle(imgskeleton, points[partA], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED) cv2.circle(imgskeleton, points[partB], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED) # 保存關(guān)鍵點(diǎn)和骨架圖 cv2.imwrite('handkeypoint.png', imgkp) cv2.imwrite('imgskeleton.png', imgskeleton)
我自己拍了兩張圖進(jìn)行測試,第一排是晚上拍的,手指頭有點(diǎn)串味哈哈,整體檢測耗時在480ms左右,網(wǎng)絡(luò)深度沒有yolo高,也許是橫向的特征比較多。

原作者:小璽璽
原鏈接:本文轉(zhuǎn)自地平線開發(fā)者社區(qū)
-
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48807 -
BPU
+關(guān)注
關(guān)注
0文章
4瀏覽量
1951
發(fā)布評論請先 登錄
相關(guān)推薦
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型

用Ollama輕松搞定Llama 3.2 Vision模型本地部署

AI模型部署和管理的關(guān)系
企業(yè)AI模型部署怎么做
使用TVM量化部署模型報錯NameError: name \'GenerateESPConstants\' is not defined如何解決?
【AIBOX上手指南】快速部署Llama3

大模型端側(cè)部署加速,都有哪些芯片可支持?
基于stm32h743IIK在cubeai上部署keras模型,模型輸出結(jié)果都是同一組概率數(shù)組,為什么?
使用CUBEAI部署tflite模型到STM32F0中,模型創(chuàng)建失敗怎么解決?
源2.0適配FastChat框架,企業(yè)快速本地化部署大模型對話平臺

使用愛芯派Pro開發(fā)板部署人體姿態(tài)估計模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論