

來源:DeepHub IMBA
強(qiáng)化學(xué)習(xí)的基礎(chǔ)知識和概念簡介(無模型、在線學(xué)習(xí)、離線強(qiáng)化學(xué)習(xí)等)
機(jī)器學(xué)習(xí)(ML)分為三個(gè)分支:監(jiān)督學(xué)習(xí)、無監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)。
- 監(jiān)督學(xué)習(xí)(SL):關(guān)注在給定標(biāo)記訓(xùn)練數(shù)據(jù)的情況下獲得正確的輸出
- 無監(jiān)督學(xué)習(xí)(UL):關(guān)注在沒有預(yù)先存在的標(biāo)簽的情況下發(fā)現(xiàn)數(shù)據(jù)中的模式
- 強(qiáng)化學(xué)習(xí)(RL):關(guān)注智能體在環(huán)境中如何采取行動(dòng)以最大化累積獎(jiǎng)勵(lì)
通俗地說,強(qiáng)化學(xué)習(xí)類似于嬰兒學(xué)習(xí)和發(fā)現(xiàn)世界,如果有獎(jiǎng)勵(lì)(正強(qiáng)化),嬰兒可能會(huì)執(zhí)行一個(gè)行動(dòng),如果有懲罰(負(fù)強(qiáng)化),嬰兒就不太可能執(zhí)行這個(gè)行動(dòng)。這也是來自監(jiān)督學(xué)習(xí)和非監(jiān)督學(xué)習(xí)的強(qiáng)化學(xué)習(xí)之間的主要區(qū)別,后者從靜態(tài)數(shù)據(jù)集學(xué)習(xí),而前者從探索中學(xué)習(xí)。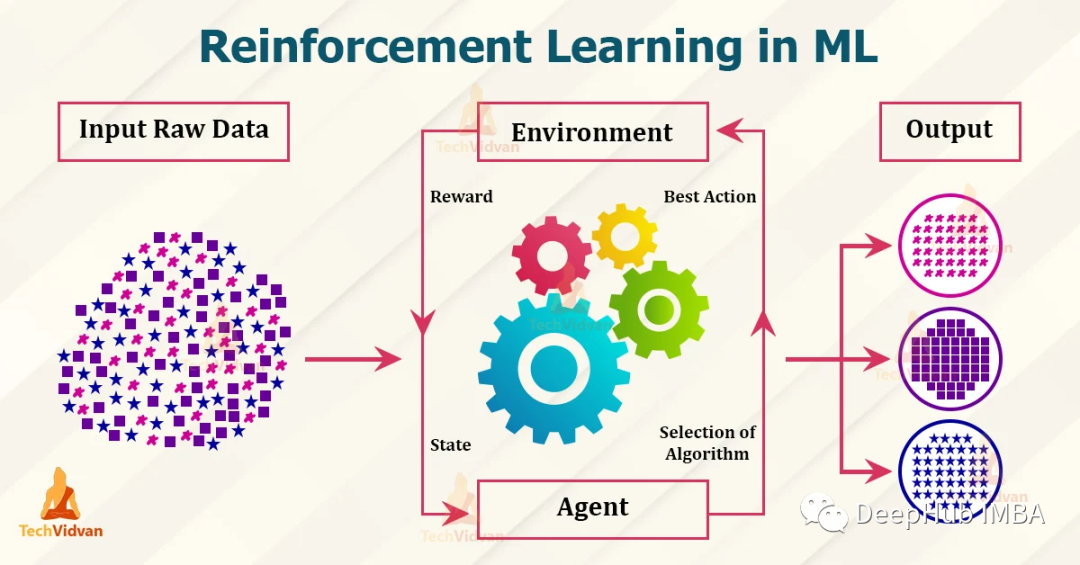 本文將涉及強(qiáng)化學(xué)習(xí)的術(shù)語和基本組成部分,以及不同類型的強(qiáng)化學(xué)習(xí)(無模型、基于模型、在線學(xué)習(xí)和離線學(xué)習(xí))。本文最后用算法來說明不同類型的強(qiáng)化學(xué)習(xí)。
本文將涉及強(qiáng)化學(xué)習(xí)的術(shù)語和基本組成部分,以及不同類型的強(qiáng)化學(xué)習(xí)(無模型、基于模型、在線學(xué)習(xí)和離線學(xué)習(xí))。本文最后用算法來說明不同類型的強(qiáng)化學(xué)習(xí)。
本文的公式基于Stuart J. Russell和Peter Norvig的教科書《Artificial Intelligence: A Modern Approach》(第四版),為了保持?jǐn)?shù)學(xué)方程格式的一致性所以略有改動(dòng)。
強(qiáng)化學(xué)習(xí)
在深入研究不同類型的強(qiáng)化學(xué)習(xí)和算法之前,我們應(yīng)該熟悉強(qiáng)化學(xué)習(xí)的組成部分。
- Agent:從環(huán)境中接收感知并執(zhí)行操作的程序,被翻譯成為智能體,但是我個(gè)人感覺代理更加恰當(dāng),因?yàn)樗褪亲鳛槲覀內(nèi)嗽趶?qiáng)化學(xué)習(xí)環(huán)境下的操作者,所以稱為代理或者代理人更恰當(dāng)
- Environment:代理所在的真實(shí)或虛擬環(huán)境
- State (S):代理當(dāng)前在環(huán)境中所處的狀態(tài)
- Action (A):代理在給定狀態(tài)下可以采取的動(dòng)作
- Reward (R):采取行動(dòng)的獎(jiǎng)勵(lì)(依賴于行動(dòng)),處于狀態(tài)的獎(jiǎng)勵(lì)(依賴于狀態(tài)),或在給定狀態(tài)下采取行動(dòng)的獎(jiǎng)勵(lì)(依賴于行動(dòng)和狀態(tài))
在一個(gè)嬰兒探索世界的例子中,嬰兒(代理)在現(xiàn)實(shí)世界(環(huán)境)中,能夠感到高興或饑餓(狀態(tài))。因此,寶寶可以選擇哭泣,吃或睡(動(dòng)作),如果寶寶餓的時(shí)候吃了東西(獎(jiǎng)勵(lì)),寶寶就滿足了(正獎(jiǎng)勵(lì))。強(qiáng)化學(xué)習(xí)涉及探索,強(qiáng)化學(xué)習(xí)的輸出是一個(gè)最優(yōu)策略。策略描述了在每個(gè)狀態(tài)下要采取的行動(dòng);類似于說明書。比如,政策可以是寶寶餓了就吃,否則,寶寶就該睡覺。這也與監(jiān)督學(xué)習(xí)形成了對比,監(jiān)督學(xué)習(xí)的輸出只是一個(gè)單一的決策或預(yù)測,比策略更簡單。
強(qiáng)化學(xué)習(xí)的目標(biāo)是通過優(yōu)化所采取的行動(dòng)來最大化總累積獎(jiǎng)勵(lì)。和嬰兒一樣,我們不都想從生活中獲得最大的累積利益嗎?
馬爾可夫決策過程(MDP)
由于強(qiáng)化學(xué)習(xí)涉及一系列最優(yōu)行為,因此它被認(rèn)為是一個(gè)連續(xù)的決策問題,可以使用馬爾可夫決策過程建模。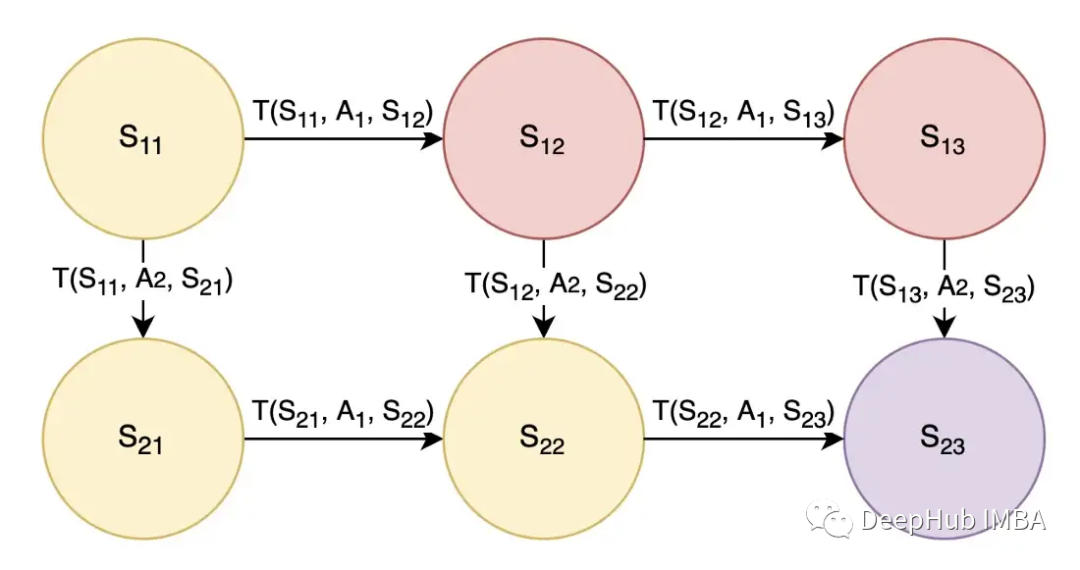 這里的狀態(tài)(用S表示)被建模為圓圈,動(dòng)作(用A表示)允許代理在狀態(tài)之間轉(zhuǎn)換。在上圖2中,還有一個(gè)轉(zhuǎn)換概率(用T表示),T(S11, A1, S12)是在狀態(tài)S11采取A1動(dòng)作后轉(zhuǎn)換到狀態(tài)S12的概率。我們可以認(rèn)為動(dòng)作A1是向右的動(dòng)作A2是向下的。為了簡單起見,我們假設(shè)轉(zhuǎn)移概率為1,這樣采取行動(dòng)A1將確保向右移動(dòng),而采取行動(dòng)A2將確保向下移動(dòng)。參照圖2,設(shè)目標(biāo)為從狀態(tài)S11開始,結(jié)束于狀態(tài)S23,黃色狀態(tài)為好(獎(jiǎng)勵(lì)+1),紅色狀態(tài)為壞(獎(jiǎng)勵(lì)-1),紫色為目標(biāo)狀態(tài)(獎(jiǎng)勵(lì)+100)。我們希望智能體了解到最佳的行動(dòng)或路線是通過采取行動(dòng)A2-A1-A1來走向下-右-右,并獲得+1+1+1+100的總獎(jiǎng)勵(lì)。再進(jìn)一步,利用金錢的時(shí)間價(jià)值,我們在獎(jiǎng)勵(lì)上應(yīng)用折扣因子gamma,因?yàn)楝F(xiàn)在的獎(jiǎng)勵(lì)比以后的獎(jiǎng)勵(lì)更好。綜上所述,從狀態(tài)S11開始執(zhí)行動(dòng)作A2-A1-A1,預(yù)期效用的數(shù)學(xué)公式如下:
這里的狀態(tài)(用S表示)被建模為圓圈,動(dòng)作(用A表示)允許代理在狀態(tài)之間轉(zhuǎn)換。在上圖2中,還有一個(gè)轉(zhuǎn)換概率(用T表示),T(S11, A1, S12)是在狀態(tài)S11采取A1動(dòng)作后轉(zhuǎn)換到狀態(tài)S12的概率。我們可以認(rèn)為動(dòng)作A1是向右的動(dòng)作A2是向下的。為了簡單起見,我們假設(shè)轉(zhuǎn)移概率為1,這樣采取行動(dòng)A1將確保向右移動(dòng),而采取行動(dòng)A2將確保向下移動(dòng)。參照圖2,設(shè)目標(biāo)為從狀態(tài)S11開始,結(jié)束于狀態(tài)S23,黃色狀態(tài)為好(獎(jiǎng)勵(lì)+1),紅色狀態(tài)為壞(獎(jiǎng)勵(lì)-1),紫色為目標(biāo)狀態(tài)(獎(jiǎng)勵(lì)+100)。我們希望智能體了解到最佳的行動(dòng)或路線是通過采取行動(dòng)A2-A1-A1來走向下-右-右,并獲得+1+1+1+100的總獎(jiǎng)勵(lì)。再進(jìn)一步,利用金錢的時(shí)間價(jià)值,我們在獎(jiǎng)勵(lì)上應(yīng)用折扣因子gamma,因?yàn)楝F(xiàn)在的獎(jiǎng)勵(lì)比以后的獎(jiǎng)勵(lì)更好。綜上所述,從狀態(tài)S11開始執(zhí)行動(dòng)作A2-A1-A1,預(yù)期效用的數(shù)學(xué)公式如下:
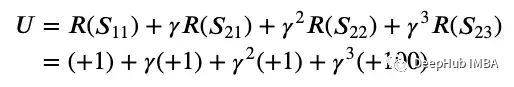
上面的例子是一個(gè)簡單的例子,一般情況下都會(huì)有一些變化,比如,
- 轉(zhuǎn)移概率不可能是1,因?yàn)樾枰谛袆?dòng)中考慮不確定性因素,例如采取某些行動(dòng)可能并不總是保證成功地向右或向下移動(dòng)。因此,我們需要在這個(gè)不確定性上取一個(gè)期望值
- 最優(yōu)動(dòng)作可能還不知道,因此一般的表示方式是將動(dòng)作表示為來自狀態(tài)的策略,用π(S)表示。
- 獎(jiǎng)勵(lì)可能不是基于黃色/紅色/紫色狀態(tài),而是基于前一個(gè)狀態(tài)、行動(dòng)和下一個(gè)狀態(tài)的組合,用R(S1, π(S1), S2)表示。
- 問題可能不需要4步就能解決,它可能需要無限多的步驟才能達(dá)到目標(biāo)狀態(tài)
考慮到這些變化,確定給定狀態(tài)下策略π的期望效用U(s)的更一般的方程是這樣的:
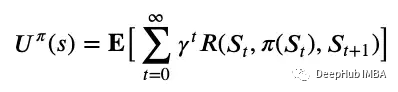
用上圖4的話來說,狀態(tài)的預(yù)期效用是折現(xiàn)獎(jiǎng)勵(lì)的預(yù)期總和。所以一個(gè)狀態(tài)的效用與其相鄰狀態(tài)的效用相關(guān);假設(shè)選擇了最優(yōu)行動(dòng),狀態(tài)的效用是轉(zhuǎn)移的預(yù)期獎(jiǎng)勵(lì)加上下一個(gè)狀態(tài)的折扣效用。這就是遞歸。在數(shù)學(xué)上使用下面的方程表示
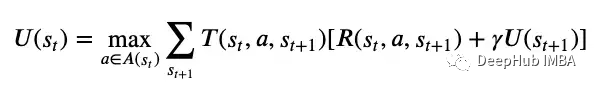
上圖5是著名的Bellman方程,它求解最大效用并推導(dǎo)出最優(yōu)策略。最優(yōu)策略是在考慮轉(zhuǎn)移概率的情況下,對所有可能的下一個(gè)狀態(tài)進(jìn)行求和,使當(dāng)前狀態(tài)的最大效用加上下一個(gè)狀態(tài)的折現(xiàn)效用。回到MDP問題中,圖2的最優(yōu)策略是,如果代理處于狀態(tài)S11, S12或S13,代理應(yīng)該通過采取動(dòng)作A2向下移動(dòng),如果代理處于狀態(tài)S21或S22,則代理應(yīng)該通過采取動(dòng)作A1向右移動(dòng)。這里的最優(yōu)策略是通過求解Bellman方程來執(zhí)行獲得最大當(dāng)前和折現(xiàn)未來獎(jiǎng)勵(lì)的行動(dòng)。
MDP一般用(S, A, T, R)表示,它們分別表示一組狀態(tài),動(dòng)作,轉(zhuǎn)移函數(shù)和獎(jiǎng)勵(lì)函數(shù)。MDP假設(shè)環(huán)境是完全可觀察的,如果代理不知道它當(dāng)前處于什么狀態(tài),我們將使用部分可觀察的MDP (POMDP) 圖5中的Bellman方程,可以使用值迭代或策略迭代來求解最優(yōu)策略,這是一種將效用值從未來狀態(tài)傳遞到當(dāng)前狀態(tài)的迭代方法。
強(qiáng)化學(xué)習(xí)類似于求解MDP,但現(xiàn)在轉(zhuǎn)移概率和獎(jiǎng)勵(lì)函數(shù)是未知的,代理必須在訓(xùn)練期間執(zhí)行動(dòng)作來學(xué)習(xí)
無模型與基于模型的強(qiáng)化學(xué)習(xí)
上面提到的MDP示例是基于模型的強(qiáng)化學(xué)習(xí)。基于模型的強(qiáng)化學(xué)習(xí)具有轉(zhuǎn)移概率T(s1, a, s2)和獎(jiǎng)勵(lì)函數(shù)R(s1, a, s2),它們是未知的,他們表示要解決的問題。基于模型的方法對仿真很有用。基于模型的強(qiáng)化學(xué)習(xí)的例子包括值迭代和策略迭代,因?yàn)樗褂镁哂修D(zhuǎn)移概率和獎(jiǎng)勵(lì)函數(shù)的MDP。無模型方法不需要知道或?qū)W習(xí)轉(zhuǎn)移概率來解決問題。我們的代理直接學(xué)習(xí)策略。
無模型方法對于解決現(xiàn)實(shí)問題很有用。無模型強(qiáng)化學(xué)習(xí)的例子包括Q-learning 和策略搜索,因?yàn)樗苯訉W(xué)習(xí)策略。
離線學(xué)習(xí)vs.在線學(xué)習(xí)
離線學(xué)習(xí)和在線學(xué)習(xí)又稱為被動(dòng)學(xué)習(xí)和主動(dòng)學(xué)習(xí)。離線學(xué)習(xí)在離線(被動(dòng))學(xué)習(xí)中,通過學(xué)習(xí)效用函數(shù)來解決該問題。給定一個(gè)具有未知轉(zhuǎn)移和獎(jiǎng)勵(lì)函數(shù)的固定策略,代理試圖通過使用該策略執(zhí)行一系列試驗(yàn)來學(xué)習(xí)效用函數(shù)。例如,在一輛自動(dòng)駕駛汽車中,給定一張地圖和一個(gè)要遵循的大致方向(固定策略),但控制出錯(cuò)(未知的轉(zhuǎn)移概率-向前移動(dòng)可能導(dǎo)致汽車稍微左轉(zhuǎn)或右轉(zhuǎn))和未知的行駛時(shí)間(獎(jiǎng)勵(lì)函數(shù)未知-假設(shè)更快到達(dá)目的地會(huì)帶來更多獎(jiǎng)勵(lì)),汽車可以重復(fù)運(yùn)行以了解平均總行駛時(shí)間是多少(效用函數(shù))。離線強(qiáng)化學(xué)習(xí)的例子包括值迭代和策略迭代,因?yàn)樗褂檬褂眯в煤瘮?shù)的Bellman方程(圖5)。其他的一些例子包括直接效用估計(jì)、自適應(yīng)動(dòng)態(tài)規(guī)劃(Adaptive Dynamic Programming, ADP)和時(shí)間差分學(xué)習(xí)(Temporal-Difference Learning, TD),這些將在后面詳細(xì)闡述。在線學(xué)習(xí)在線(主動(dòng))學(xué)習(xí)中,通過學(xué)習(xí)規(guī)劃或決策來解決問題。對于基于模型的在線強(qiáng)化學(xué)習(xí),有探索和使用的階段。在使用階段,代理的行為類似于離線學(xué)習(xí),采用固定的策略并學(xué)習(xí)效用函數(shù)。在探索階段,代理執(zhí)行值迭代或策略迭代以更新策略。如果使用值迭代更新策略,則使用最大化效用/值的一步前瞻提取最佳行動(dòng)。如果使用策略迭代更新策略,則可獲得最優(yōu)策略,并可按照建議執(zhí)行操作。以自動(dòng)駕駛汽車為例,在探索階段,汽車可能會(huì)了解到在高速公路上行駛所花費(fèi)的總時(shí)間更快,并選擇向高速公路行駛,而不是簡單地沿著大方向行駛(策略迭代)。在使用階段,汽車按照更新的策略以更少的平均總時(shí)間(更高的效用)行駛。在線強(qiáng)化學(xué)習(xí)的例子包括Exploration、Q-Learning和SARSA,這些將在后面幾節(jié)中詳細(xì)闡述。當(dāng)狀態(tài)和動(dòng)作太多以至于轉(zhuǎn)換概率太多時(shí),在線學(xué)習(xí)是首選。在線學(xué)習(xí)中探索和“邊學(xué)邊用”比在離線學(xué)習(xí)中一次學(xué)習(xí)所有內(nèi)容更容易。但是由于探索中的試錯(cuò)法,在線學(xué)習(xí)也可能很耗時(shí)。需要說明的是:在線學(xué)習(xí)和基于策略的學(xué)習(xí)(以及基于策略的離線學(xué)習(xí))是有區(qū)別的,前者指的是學(xué)習(xí)(策略可以更改或固定),后者指的是策略(一系列試驗(yàn)來自一個(gè)策略還是多個(gè)策略)。在本文的最后兩部分中,我們將使用算法來解釋策略啟動(dòng)和策略關(guān)閉。
在理解了不同類型的強(qiáng)化學(xué)習(xí)之后,讓我們深入研究一下算法!
1、直接效用估計(jì) Direct Utility Estimation
無模型的離線學(xué)習(xí)在直接效用估計(jì)中,代理使用固定策略執(zhí)行一系列試驗(yàn),并且狀態(tài)的效用是從該狀態(tài)開始的預(yù)期總獎(jiǎng)勵(lì)或預(yù)期獎(jiǎng)勵(lì)。以一輛自動(dòng)駕駛汽車為例,如果汽車在一次試驗(yàn)中從網(wǎng)格 (1, 1) 開始時(shí),未來的總獎(jiǎng)勵(lì)為 +100。在同一次試驗(yàn)中,汽車重新訪問該網(wǎng)格,從該點(diǎn)開始的未來總獎(jiǎng)勵(lì)是+300。在另一項(xiàng)試驗(yàn)中,汽車從該網(wǎng)格開始,未來的總獎(jiǎng)勵(lì)為 +200。該網(wǎng)格的預(yù)期獎(jiǎng)勵(lì)將是所有試驗(yàn)和對該網(wǎng)格的所有訪問的平均獎(jiǎng)勵(lì),在本例中為 (100 + 300 + 200) / 3。優(yōu)點(diǎn):給定無限次試驗(yàn),獎(jiǎng)勵(lì)的樣本平均值將收斂到真實(shí)的預(yù)期獎(jiǎng)勵(lì)。
缺點(diǎn):預(yù)期的獎(jiǎng)勵(lì)在每次試驗(yàn)結(jié)束時(shí)更新,這意味著代理在試驗(yàn)結(jié)束前什么都沒有學(xué)到,導(dǎo)致直接效用估計(jì)收斂非常慢。
2、自適應(yīng)動(dòng)態(tài)規(guī)劃 (ADP)
基于模型的離線學(xué)習(xí)在自適應(yīng)動(dòng)態(tài)規(guī)劃 (ADP) 中,代理嘗試通過經(jīng)驗(yàn)學(xué)習(xí)轉(zhuǎn)換和獎(jiǎng)勵(lì)函數(shù)。轉(zhuǎn)換函數(shù)是通過計(jì)算從當(dāng)前狀態(tài)轉(zhuǎn)換到下一個(gè)狀態(tài)的次數(shù)來學(xué)習(xí)的,而獎(jiǎng)勵(lì)函數(shù)是在進(jìn)入該狀態(tài)時(shí)學(xué)習(xí)的。給定學(xué)習(xí)到的轉(zhuǎn)換和獎(jiǎng)勵(lì)函數(shù),我們可以解決MDP。以自動(dòng)駕駛汽車為例,在給定狀態(tài)下嘗試向前移動(dòng) 10 次,如果汽車最終向前移動(dòng) 8 次并向左移動(dòng) 2 次,我們了解到轉(zhuǎn)換概率為 T(當(dāng)前狀態(tài), 向前,前狀態(tài))= 0.8 和 T(當(dāng)前狀態(tài),向前,左狀態(tài))= 0.2。優(yōu)點(diǎn):由于環(huán)境是完全可觀察的,因此很容易通過簡單的計(jì)數(shù)來學(xué)習(xí)轉(zhuǎn)換模型。
缺點(diǎn):性能受到代理學(xué)習(xí)轉(zhuǎn)換模型的能力的限制。這將導(dǎo)致這個(gè)問題對于大狀態(tài)空間來說是很麻煩的,因?yàn)閷W(xué)習(xí)轉(zhuǎn)換模型需要太多的試驗(yàn),并且在 MDP 中有太多的方程和未知數(shù)需要求解。
3、時(shí)間差分學(xué)習(xí)(TD Learning)
無模型的離線學(xué)習(xí)在時(shí)間差分學(xué)習(xí)中,代理學(xué)習(xí)效用函數(shù)并在每次轉(zhuǎn)換后以學(xué)習(xí)率更新該函數(shù)。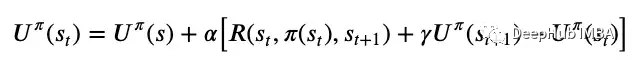 這里的時(shí)間差分(temporal difference)是指連續(xù)狀態(tài)之間的效用差異,并根據(jù)此誤差信號更新效用函數(shù),由學(xué)習(xí)率縮放,如上圖6所示。學(xué)習(xí)率可以是一個(gè)固定的參數(shù),也可以是對一個(gè)狀態(tài)訪問量增加的遞減函數(shù),這有助于效用函數(shù)的收斂。與直接效用估計(jì)在每次嘗試后進(jìn)行學(xué)習(xí)相比,TD學(xué)習(xí)在每次轉(zhuǎn)換后進(jìn)行學(xué)習(xí),具有更高的效率。與ADP相比,TD學(xué)習(xí)不需要學(xué)習(xí)轉(zhuǎn)換函數(shù)和獎(jiǎng)勵(lì)函數(shù),使其計(jì)算效率更高,但也需要更長的收斂時(shí)間。ADP和TD學(xué)習(xí)是離線強(qiáng)化學(xué)習(xí)算法,但在線強(qiáng)化學(xué)習(xí)算法中也存在主動(dòng)ADP和主動(dòng)TD學(xué)習(xí)!
這里的時(shí)間差分(temporal difference)是指連續(xù)狀態(tài)之間的效用差異,并根據(jù)此誤差信號更新效用函數(shù),由學(xué)習(xí)率縮放,如上圖6所示。學(xué)習(xí)率可以是一個(gè)固定的參數(shù),也可以是對一個(gè)狀態(tài)訪問量增加的遞減函數(shù),這有助于效用函數(shù)的收斂。與直接效用估計(jì)在每次嘗試后進(jìn)行學(xué)習(xí)相比,TD學(xué)習(xí)在每次轉(zhuǎn)換后進(jìn)行學(xué)習(xí),具有更高的效率。與ADP相比,TD學(xué)習(xí)不需要學(xué)習(xí)轉(zhuǎn)換函數(shù)和獎(jiǎng)勵(lì)函數(shù),使其計(jì)算效率更高,但也需要更長的收斂時(shí)間。ADP和TD學(xué)習(xí)是離線強(qiáng)化學(xué)習(xí)算法,但在線強(qiáng)化學(xué)習(xí)算法中也存在主動(dòng)ADP和主動(dòng)TD學(xué)習(xí)!
4、Exploration
基于模型的在線學(xué)習(xí),主動(dòng)ADPExploration 算法是一種主動(dòng)ADP算法。與被動(dòng)ADP算法類似,代理試圖通過經(jīng)驗(yàn)學(xué)習(xí)轉(zhuǎn)換和獎(jiǎng)勵(lì)函數(shù),但主動(dòng)ADP算法將學(xué)習(xí)所有動(dòng)作的結(jié)果,而不僅僅是固定的策略。它還有一個(gè)額外的函數(shù),確定代理在現(xiàn)有策略之外采取行動(dòng)的“好奇程度”。這個(gè)函數(shù)隨著效用的增加而增加,隨著經(jīng)驗(yàn)的減少而減少。如果狀態(tài)具有高效用,則探索函數(shù)傾向于更頻繁地訪問該狀態(tài)。探索功能隨著效用的增加而增加。如果狀態(tài)之前沒有被訪問過或訪問過足夠多次,探索函數(shù)傾向于選擇現(xiàn)有策略之外的動(dòng)作。如果多次訪問狀態(tài),則探索函數(shù)就不那么“好奇”了。由于好奇程度的降低,探索功能隨著經(jīng)驗(yàn)的增加而降低。優(yōu)點(diǎn):探索策略會(huì)快速收斂到零策略損失(最優(yōu)策略)。
缺點(diǎn):效用估計(jì)的收斂速度不如策略估計(jì)的快,因?yàn)榇聿粫?huì)頻繁地出現(xiàn)低效用狀態(tài),因此不知道這些狀態(tài)的確切效用。
5、Q-Learning
無模型的在線學(xué)習(xí),主動(dòng)TD學(xué)習(xí)Q-Learning 是一種主動(dòng)的 TD 學(xué)習(xí)算法。圖 6 中的更新規(guī)則保持不變,但現(xiàn)在狀態(tài)的效用表示為使用 Q 函數(shù)的狀態(tài)-動(dòng)作對的效用,因此得名 Q-Learning。被動(dòng) TD 學(xué)習(xí)與主動(dòng) TD 學(xué)習(xí)的更新規(guī)則差異如下圖 7 所示。
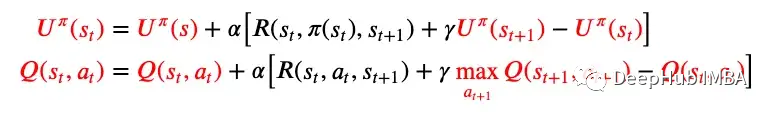
這種差異是由于被動(dòng)RL都是用固定的策略,因此每個(gè)狀態(tài)只會(huì)執(zhí)行固定的操作,效用僅取決于狀態(tài)。而在主動(dòng)RL 中,策略會(huì)被更新并且效用現(xiàn)在取決于狀態(tài)-動(dòng)作對,因?yàn)槊總€(gè)狀態(tài)可能會(huì)根據(jù)不同的策略執(zhí)行不同的動(dòng)作。Q-Learning 是 Off-Policy(無既定策略),這意味著目標(biāo)或下一個(gè)狀態(tài)的效用是使Q函數(shù)最大化(而不是下一個(gè)狀態(tài)中可能的操作),我們就不需要下一個(gè)狀態(tài)下的實(shí)際動(dòng)作。優(yōu)點(diǎn):可以應(yīng)用于復(fù)雜領(lǐng)域,因?yàn)樗菬o模型的,代理不需要學(xué)習(xí)或應(yīng)用轉(zhuǎn)換模型。
缺點(diǎn):它不看到未來的情況,所以當(dāng)獎(jiǎng)勵(lì)稀少時(shí)可能會(huì)遇到困難。與 ADP 相比,它學(xué)習(xí)策略的速度較慢,因?yàn)楸镜馗虏荒艽_保 Q 值的一致性。
6、SARSA
無模型的在線學(xué)習(xí),主動(dòng)TD學(xué)習(xí)SARSA是一種主動(dòng)TD學(xué)習(xí)算法。算法名稱SARSA源自算法的組件,即狀態(tài)S、動(dòng)作A、獎(jiǎng)勵(lì)R、(下一個(gè))狀態(tài)S和(下一個(gè))動(dòng)作A。這意味著SARSA算法在更新Q函數(shù)之前,要等待下一個(gè)狀態(tài)下執(zhí)行下一個(gè)動(dòng)作。相比之下,Q-Learning是一種“SARS”算法,因?yàn)樗豢紤]下一個(gè)狀態(tài)的動(dòng)作。SARSA 算法知道在下一個(gè)狀態(tài)下采取的動(dòng)作,并且不需要在下一個(gè)狀態(tài)下的所有可能動(dòng)作上最大化 Q 函數(shù)。Q-Learning與SARSA的更新規(guī)則差異顯示在下面的圖8中。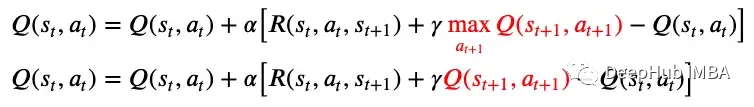 SARSA 以“策略”或者當(dāng)前正在運(yùn)行的策略的下一個(gè)狀態(tài)的效用的q函數(shù)為目標(biāo),這樣就能夠獲得下一個(gè)狀態(tài)下的實(shí)際動(dòng)作。也就是說如果Q-Learning不探索其他操作并在下一個(gè)狀態(tài)下遵循當(dāng)前策略,則它與SARSA相同。優(yōu)點(diǎn):如果整個(gè)策略由另一個(gè)代理或程序控制,則適合使用策略,這樣代理就不會(huì)脫離策略并嘗試其他操作。
SARSA 以“策略”或者當(dāng)前正在運(yùn)行的策略的下一個(gè)狀態(tài)的效用的q函數(shù)為目標(biāo),這樣就能夠獲得下一個(gè)狀態(tài)下的實(shí)際動(dòng)作。也就是說如果Q-Learning不探索其他操作并在下一個(gè)狀態(tài)下遵循當(dāng)前策略,則它與SARSA相同。優(yōu)點(diǎn):如果整個(gè)策略由另一個(gè)代理或程序控制,則適合使用策略,這樣代理就不會(huì)脫離策略并嘗試其他操作。
缺點(diǎn):SARSA不如Q-Learning靈活,因?yàn)樗粫?huì)脫離策略來進(jìn)行探索。與 ADP 相比,它學(xué)習(xí)策略的速度較慢,因?yàn)楸镜馗聼o法確保與 Q 值的一致性。
總結(jié)
在本文中我們介紹了強(qiáng)化學(xué)習(xí)的基本概念,并且討論了6種算法,并將其分為不同類型的強(qiáng)化學(xué)習(xí)。 這6種算法是幫助形成對強(qiáng)化學(xué)習(xí)的基本理解的基本算法。還有更有效的強(qiáng)化學(xué)習(xí)算法,如深度Q網(wǎng)絡(luò)(Deep Q Network, DQN)、深度確定性策略梯度(Deep Deterministic Policy Gradient, DDPG)等算法,具有更實(shí)際的應(yīng)用。
這6種算法是幫助形成對強(qiáng)化學(xué)習(xí)的基本理解的基本算法。還有更有效的強(qiáng)化學(xué)習(xí)算法,如深度Q網(wǎng)絡(luò)(Deep Q Network, DQN)、深度確定性策略梯度(Deep Deterministic Policy Gradient, DDPG)等算法,具有更實(shí)際的應(yīng)用。
我一直覺得強(qiáng)化學(xué)習(xí)很有趣,因?yàn)樗U明了人類如何學(xué)習(xí)以及我們?nèi)绾螌⑦@些知識傳授給機(jī)器人(當(dāng)然也包括其他應(yīng)用,如自動(dòng)駕駛汽車、國際象棋和Alpha Go等)。希望本文能夠讓你對強(qiáng)化學(xué)習(xí)有了更多的了解,并且知道了強(qiáng)化學(xué)習(xí)的不同類型,以及說明每種類型的強(qiáng)化學(xué)習(xí)的算法。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134156
發(fā)布評論請先 登錄
18個(gè)常用的強(qiáng)化學(xué)習(xí)算法整理:從基礎(chǔ)方法到高級模型的理論技術(shù)與代碼實(shí)現(xiàn)

詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式

螞蟻集團(tuán)收購邊塞科技,吳翼出任強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)室首席科學(xué)家
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)

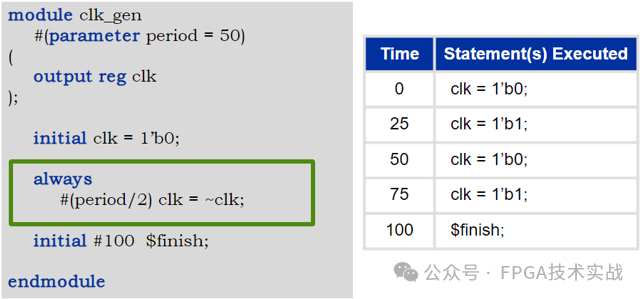
Verilog HDL的基礎(chǔ)知識
負(fù)載開關(guān)基礎(chǔ)知識

谷歌AlphaChip強(qiáng)化學(xué)習(xí)工具發(fā)布,聯(lián)發(fā)科天璣芯片率先采用
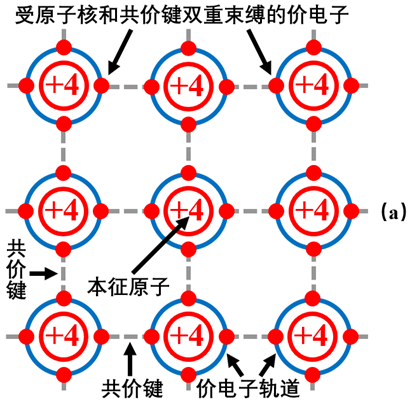
全新的半導(dǎo)體基礎(chǔ)知識
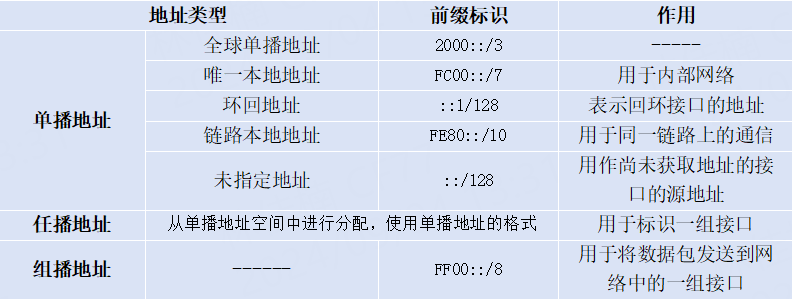
IPV6基礎(chǔ)知識詳解





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論