") 人工智能300年!LSTM之父萬字長文:詳解現(xiàn)代AI和深度學(xué)習(xí)發(fā)展史
人工智能300年!LSTM之父萬字長文:詳解現(xiàn)代AI和深度學(xué)習(xí)發(fā)展史
來源:新智元
編輯:昕朋 好困
導(dǎo)讀
最近,LSTM之父Jürgen Schmidhuber梳理了17世紀以來人工智能的歷史。在這篇萬字長文中,Schmidhuber為讀者提供了一個大事年表,其中包括神經(jīng)網(wǎng)絡(luò)、深度學(xué)習(xí)、人工智能等領(lǐng)域的重要事件,以及那些為AI奠定基礎(chǔ)的科學(xué)家們。
「人工智能」一詞,首次在1956年達特茅斯會議上,由約翰麥卡錫等人正式提出。
實用AI的提出,最早可以追溯到1914年。當時Leonardo Torres y Quevedo構(gòu)建了第一個工作的國際象棋機器終端游戲玩家。當時,國際象棋被認為是一種僅限于智能生物領(lǐng)域的活動。至于人工智能理論,則可以追溯到1931-34年。當時庫爾特·哥德爾(Kurt G?del )確定了任何類型的基于計算的人工智能的基本限制。
時間來到1980年代,此時的AI歷史會強調(diào)定理證明、邏輯編程、專家系統(tǒng)和啟發(fā)式搜索等主題。
2000年代初期的AI歷史會更加強調(diào)支持向量機和內(nèi)核方法等主題。貝葉斯推理(Bayesian reasoning)和其他概率論和統(tǒng)計概念、決策樹、 集成方法、群體智能和進化計算,此類技術(shù)推動了許多成功的AI應(yīng)用。
2020年代的AI研究反而更加「復(fù)古」,比如強調(diào)諸如鏈式法則和通過梯度下降(gradient descent)訓(xùn)練的深度非線性人工神經(jīng)網(wǎng)絡(luò),特別是基于反饋的循環(huán)網(wǎng)絡(luò)等概念。
Schmidhuber表示,這篇文章對之前具有誤導(dǎo)性的「深度學(xué)習(xí)歷史」進行糾正。在他看來,之前的深度學(xué)習(xí)史忽略了文章中提到的大部分開創(chuàng)性工作。
此外,Schmidhuber還駁斥了一個常見的錯誤,即神經(jīng)網(wǎng)絡(luò)「作為幫助計算機識別模式和模擬人類智能的工具是在1980年代引入的」。因為事實上,神經(jīng)網(wǎng)絡(luò)早在80年代前就已出現(xiàn)。
一、1676年:反向信用分配的鏈式法則
1676年,戈特弗里德·威廉·萊布尼茨(Gottfried Wilhelm Leibniz)在回憶錄中發(fā)表了微積分的鏈式法則。如今,這條規(guī)則成為了深度神經(jīng)網(wǎng)絡(luò)中信用分配的核心,是現(xiàn)代深度學(xué)習(xí)的基礎(chǔ)。
神經(jīng)網(wǎng)絡(luò)具有計算來自其他神經(jīng)元的輸入的可微函數(shù)的節(jié)點或神經(jīng)元,這些節(jié)點或神經(jīng)元又計算來自其他神經(jīng)元的輸入的可微函數(shù)。如果想要知道修改早期函數(shù)的參數(shù)或權(quán)值后,最終函數(shù)輸出的變化,就需要用到鏈式法則。這個答案也被用于梯度下降技術(shù)。為了教會神經(jīng)網(wǎng)絡(luò)將來自訓(xùn)練集的輸入模式轉(zhuǎn)換為所需的輸出模式,所有神經(jīng)網(wǎng)絡(luò)權(quán)值都朝著最大局部改進的方向迭代改變一點,以創(chuàng)建稍微更好的神經(jīng)網(wǎng)絡(luò),依此類推,逐漸靠近權(quán)值和偏置的最佳組合,從而最小化損失函數(shù)。值得注意的是,萊布尼茨也是第一個發(fā)現(xiàn)微積分的數(shù)學(xué)家。他和艾薩克·牛頓先后獨立發(fā)現(xiàn)了微積分,而且他所使用的微積分的數(shù)學(xué)符號被更廣泛的使用,萊布尼茨所發(fā)明的符號被普遍認為更綜合,適用范圍更加廣泛。此外,萊布尼茨還是「世界上第一位計算機科學(xué)家」。他于1673年設(shè)計了第一臺可以執(zhí)行所有四種算術(shù)運算的機器,奠定了現(xiàn)代計算機科學(xué)的基礎(chǔ)。
二、19世紀初:神經(jīng)網(wǎng)絡(luò)、線性回歸與淺層學(xué)習(xí)
1805 年,阿德利昂·瑪利·埃·勒讓德(Adrien-Marie Legendre)發(fā)表了現(xiàn)在通常稱為線性神經(jīng)網(wǎng)絡(luò)的內(nèi)容。
阿德利昂·瑪利·埃·勒讓德后來,約翰·卡爾·弗里德里希·高斯(Johann Carl Friedrich Gauss)也因類似的研究而受到贊譽。這個來自2個多世紀前的神經(jīng)網(wǎng)絡(luò)有兩層:一個具有多個輸入單元的輸入層和一個輸出層。每個輸入單元都可以保存一個實數(shù)值,并通過具有實數(shù)值權(quán)值的連接連接到輸出。神經(jīng)網(wǎng)絡(luò)的輸出是輸入與其權(quán)值的乘積之和。給定輸入向量的訓(xùn)練集和每個向量的期望目標值,調(diào)整 權(quán)值,使神經(jīng)網(wǎng)絡(luò)輸出與相應(yīng)目標之間的平方誤差之和最小化。當然,那時候這還不叫神經(jīng)網(wǎng)絡(luò)。它被稱為最小二乘法(least squares),也被廣泛稱為線性回歸。但它在數(shù)學(xué)上與今天的線性神經(jīng)網(wǎng)絡(luò)相同:相同的基本算法、相同的誤差函數(shù)、相同的自適應(yīng)參數(shù)/權(quán)值。
這種簡單的神經(jīng)網(wǎng)絡(luò)執(zhí)行「淺層學(xué)習(xí)」,與具有許多非線性層的「深度學(xué)習(xí)」相反。事實上,許多神經(jīng)網(wǎng)絡(luò)課程都是從介紹這種方法開始的,然后轉(zhuǎn)向更復(fù)雜、更深入的神經(jīng)網(wǎng)絡(luò)。當今,所有技術(shù)學(xué)科的學(xué)生都必須上數(shù)學(xué)課,尤其是分析、線性代數(shù)和統(tǒng)計學(xué)。在所有這些領(lǐng)域中,許多重要的結(jié)果和方法都要歸功于高斯:代數(shù)基本定理、高斯消元法、統(tǒng)計的高斯分布等。這位號稱「自古以來最偉大的數(shù)學(xué)家」的人也開創(chuàng)了微分幾何、數(shù)論(他最喜歡的科目)和非歐幾何。如果沒有他的成果,包括AI在內(nèi)的現(xiàn)代工程將不可想象。
三、1920-1925年:第一個循環(huán)神經(jīng)網(wǎng)絡(luò)
與人腦相似,循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)具有反饋連接,因此可以遵循從某些內(nèi)部節(jié)點到其他節(jié)點的定向連接,并最終在起點處結(jié)束。這對于在序列處理期間實現(xiàn)對過去事件的記憶至關(guān)重要。
物理學(xué)家恩斯特·伊辛(Ernst Ising)和威廉·楞次(Wilhelm Lenz)在 1920 年代引入并分析了第一個非學(xué)習(xí)RNN架構(gòu):伊辛模型(Ising model)。它根據(jù)輸入條件進入平衡狀態(tài),是第一個RNN學(xué)習(xí)模型的基礎(chǔ)。1972 年,甘利俊一(Shun-Ichi Amari)使伊辛模型循環(huán)架構(gòu)具有自適應(yīng)性,可以通過改變其連接權(quán)值來學(xué)習(xí)將輸入模式與輸出模式相關(guān)聯(lián)。這是世界上第一個學(xué)習(xí)型RNN。
目前,最流行的RNN就是Schmidhuber提出的長短期記憶網(wǎng)絡(luò)LSTM。它已經(jīng)成為20世紀被引用最多的神經(jīng)網(wǎng)絡(luò)。
四、1958年:多層前饋神經(jīng)網(wǎng)絡(luò)
1958年,弗蘭克·羅森布拉特(Frank Rosenblatt)結(jié)合了線性神經(jīng)網(wǎng)絡(luò)和閾值函數(shù),設(shè)計出了更深層次的多層感知器 (MLP)。
多層感知器遵循人類神經(jīng)系統(tǒng)原理,學(xué)習(xí)并進行數(shù)據(jù)預(yù)測。它首先學(xué)習(xí),然后使用權(quán)值存儲數(shù)據(jù),并使用算法來調(diào)整權(quán)值并減少訓(xùn)練過程中的偏差,即實際值和預(yù)測值之間的誤差。由于多層前饋網(wǎng)絡(luò)的訓(xùn)練經(jīng)常采用誤差反向傳播算法,在模式識別的領(lǐng)域中算是標準監(jiān)督學(xué)習(xí)算法,并在計算神經(jīng)學(xué)及并行分布式處理領(lǐng)域中,持續(xù)成為被研究的課題。
五、1965年:第一個深度學(xué)習(xí)
深度前饋網(wǎng)絡(luò)架構(gòu)的成功學(xué)習(xí)始于1965年的烏克蘭,當時Alexey Ivakhnenko和Valentin Lapa為具有任意多個隱藏層的深度MLP引入了第一個通用的工作學(xué)習(xí)算法。
給定一組具有相應(yīng)目標輸出向量的輸入向量訓(xùn)練集,層逐漸增長并通過回歸分析進行訓(xùn)練,然后借助單獨的驗證集進行修剪,其中正則化用于清除多余的單元。層數(shù)和每層單元以問題相關(guān)的方式學(xué)習(xí)。與后來的深度神經(jīng)網(wǎng)絡(luò)一樣,Ivakhnenko的網(wǎng)絡(luò)學(xué)會了為傳入數(shù)據(jù)創(chuàng)建分層的、分布式的、內(nèi)部表示。他沒有稱它們?yōu)樯疃葘W(xué)習(xí)神經(jīng)網(wǎng)絡(luò),但它們就是這樣。事實上,「深度學(xué)習(xí)」這個術(shù)語最早是由Dechter于1986年引入機器學(xué)習(xí)的,而Aizenberg等人在2000則引入了「神經(jīng)網(wǎng)絡(luò)」的概念。
六、1967-68年:隨機梯度下降
1967年,甘利俊一首次提出通過隨機梯度下降 (SGD)訓(xùn)練神經(jīng)網(wǎng)絡(luò)。甘利俊一與他的學(xué)生Saito在具有兩個可修改層的五層MLP中學(xué)習(xí)了內(nèi)部表示,該層被訓(xùn)練用于對非線性可分離模式類進行分類。Rumelhart和Hinton等人在1986年做出了類似的工作,并將其命名為反向傳播算法。
七、1970年:反向傳播算法
1970 年,Seppo Linnainmaa率先發(fā)表了反向傳播的算法,這是一種著名的可微節(jié)點網(wǎng)絡(luò)信用分配算法,也稱為「自動微分的反向模式」。
首次描述了在任意、離散的稀疏連接情況下的類神經(jīng)網(wǎng)絡(luò)的高效誤差反向傳播方式。它現(xiàn)在是廣泛使用的神經(jīng)網(wǎng)絡(luò)軟件包的基礎(chǔ),例如PyTorch和谷歌的Tensorflow。反向傳播本質(zhì)上是為深度網(wǎng)絡(luò)實施萊布尼茨鏈式法則的有效方式。柯西(Cauchy)提出的梯度下降在許多試驗過程中使用它逐漸削弱某些神經(jīng)網(wǎng)絡(luò)連接并加強其他連接。1985年,計算成本已比1970年減少約1,000倍,當臺式計算機剛剛在富裕的學(xué)術(shù)實驗室中普及時,David Rumelhart等人對已知方法進行實驗分析。
通過實驗,魯姆哈特等人證明反向傳播可以在神經(jīng)網(wǎng)絡(luò)的隱藏層中產(chǎn)生有用的內(nèi)部表示。至少對于監(jiān)督學(xué)習(xí),反向傳播通常比甘利俊一通過SGD方法進行的上述深度學(xué)習(xí)更有效。2010年之前,許多人認為訓(xùn)練多層神經(jīng)網(wǎng)絡(luò)需要無監(jiān)督預(yù)訓(xùn)練。2010年,Schmidhuber的團隊與Dan Ciresan表明深度FNN可以通過簡單的反向傳播進行訓(xùn)練,并且根本不需要對重要應(yīng)用進行無監(jiān)督預(yù)訓(xùn)練。
八、1979年:首個卷積神經(jīng)網(wǎng)絡(luò)
1979年,福島邦彥(Kunihiko Fukushima)在STRL開發(fā)了一種用于模式識別的神經(jīng)網(wǎng)絡(luò)模型:Neocognitron。
但這個Neocognitron用今天的話來說,叫卷積神經(jīng)網(wǎng)絡(luò)(CNN),是深度神經(jīng)網(wǎng)絡(luò)基本結(jié)構(gòu)的最偉大發(fā)明之一,也是當前人工智能的核心技術(shù)。福島博士引入的Neocognitron,是第一個使用卷積和下采樣的神經(jīng)網(wǎng)絡(luò),也是卷積神經(jīng)網(wǎng)絡(luò)的雛形。福島邦彥設(shè)計的具有學(xué)習(xí)能力的人工多層神經(jīng)網(wǎng)絡(luò),可以模仿大腦的視覺網(wǎng)絡(luò),這種「洞察力」成為現(xiàn)代人工智能技術(shù)的基礎(chǔ)。福島博士的工作帶來了一系列實際應(yīng)用,從自動駕駛汽車到面部識別,從癌癥檢測到洪水預(yù)測,還會有越來越多的應(yīng)用。1987年,Alex Waibel將具有卷積的神經(jīng)網(wǎng)絡(luò)與權(quán)值共享和反向傳播相結(jié)合,提出了延時神經(jīng)網(wǎng)絡(luò)(TDNN)的概念。1989年以來,Yann LeCun的團隊為CNN的改進做出了貢獻,尤其是在圖像方面。
2011年末,Schmidhuber的團隊大大加快了深度CNN的訓(xùn)練速度,使其在機器學(xué)習(xí)社區(qū)中變得更加流行。團隊推出基于GPU的CNN:DanNet,比早期的CNN更深入、運算更快。同年,DanNet成為第一個贏得計算機視覺競賽的純深度CNN。由Microsoft Research的4位學(xué)者提出的殘差神經(jīng)網(wǎng)絡(luò)(ResNet),在2015年的ImageNet大規(guī)模視覺識別競賽拔得頭籌。Schmidhuber 表示,ResNet是其團隊研發(fā)的高速神經(jīng)網(wǎng)絡(luò)(Highway Net)的一個早期版本。相較于以前的神經(jīng)網(wǎng)絡(luò)最多只有幾十層,這是第一個真正有效的、具有數(shù)百層的深度前饋神經(jīng)網(wǎng)絡(luò)。
九、1987-1990年代:圖神經(jīng)網(wǎng)絡(luò)與隨機Delta法則
可以操縱結(jié)構(gòu)化數(shù)據(jù)(例如圖形)的深度學(xué)習(xí)架構(gòu)于1987年由Pollack提出,并在20世紀90年代初由 Sperduti、Goller和Küchler進行擴展和改進。如今,圖神經(jīng)網(wǎng)絡(luò)被用于許多應(yīng)用程序中。
Paul Werbos和R. J. Williams等人分析了在RNN中實現(xiàn)梯度下降的方法。Teuvo Kohonen的自組織映射(Self-Organizing Map)也流行起來。
1990年,Stephen Hanson引入了隨機Delta法則,這是一種通過反向傳播訓(xùn)練神經(jīng)網(wǎng)絡(luò)的隨機方法。幾十年后,這個方法在「dropout」的綽號下流行起來。
十、1990年2月:生成式對抗網(wǎng)絡(luò)/好奇心
生成對抗網(wǎng)絡(luò)(GAN)最早于1990年在以「人工智能好奇心」為名發(fā)表。
兩個對抗的NN(一個概率生成器和一個預(yù)測器)試圖在一個最小極限游戲中使對方的損失最大化。其中:
生成器(稱為控制器)生成概率輸出(使用隨機單元,如后來的StyleGAN)。
預(yù)測器(稱為世界模型)看到控制器的輸出并預(yù)測環(huán)境對它們的反應(yīng)。使用梯度下降法,預(yù)測器NN將其誤差最小化,而生成器NN試圖這個誤差最大化——一個網(wǎng)的損失就是另一個網(wǎng)絡(luò)的收益。
之前4年,Schmidhuber就在著名的2010年調(diào)查中,將1990年的生成式對抗NN總結(jié)如下:「作為預(yù)測世界模型的神經(jīng)網(wǎng)絡(luò)被用來最大化控制器的內(nèi)在獎勵,它與模型的預(yù)測誤差成正比」。而之后發(fā)布的GAN,只是一個實例。其中,試驗非常短,環(huán)境只是根據(jù)控制器(或生成器)的輸出是否在一個給定的集合中而返回1或0。
1990年的原理被廣泛用于強化學(xué)習(xí)的探索和現(xiàn)實圖像的合成,盡管后者的領(lǐng)域最近被Rombach等人的Latent Diffusion接替。1991年,Schmidhuber發(fā)表了另一個基于兩個對抗性NN的ML方法,稱為可預(yù)測性最小化,用于創(chuàng)建部分冗余數(shù)據(jù)的分離表征,1996年應(yīng)用于圖像。
十一、1990年4月:生成子目標/按指令工作
近幾個世紀以來,大多數(shù)NN都致力于簡單的模式識別,而不是高級推理。
然而,在20世紀90年代初,首次出現(xiàn)了例外。這項工作將傳統(tǒng)的「符號」層次式人工智能的概念注入到端到端的可區(qū)分的「次符號」(sub-symbolic)NN中。1990年,Schmidhuber團隊的NN學(xué)會了用端到端可微分NN的子目標生成器來生成層次化的行動計劃,用于層次化強化學(xué)習(xí)(HRL)。
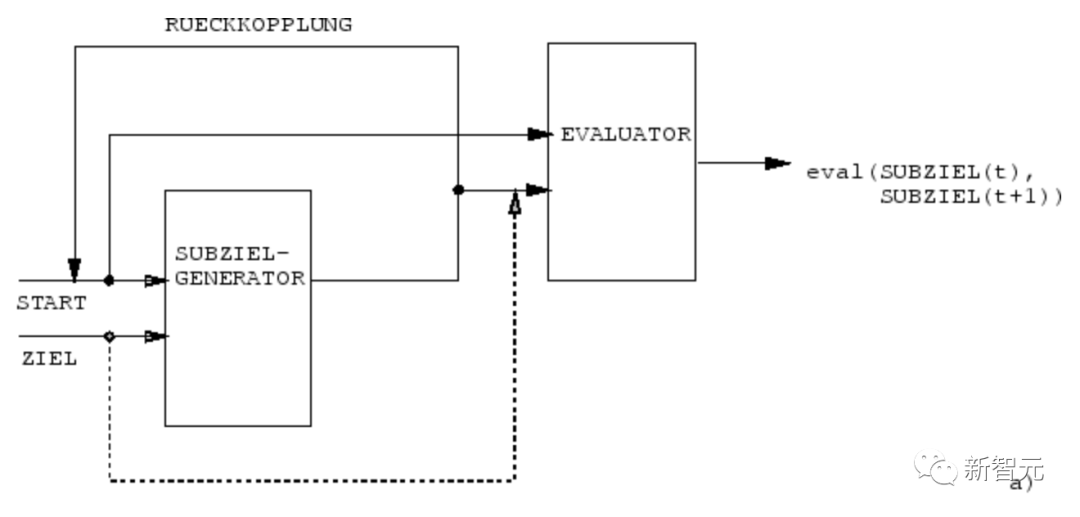
一個RL機器得到額外的命令輸入,其形式為(開始,目標)。一個評估器NN學(xué)習(xí)預(yù)測從開始到目標的當前獎勵/成本。一個基于(R)NN的子目標生成器也看到了(開始,目標),并使用評估器NN的(副本)通過梯度下降學(xué)習(xí)一連串成本最低的中間子目標。RL機器試圖使用這種子目標序列來實現(xiàn)最終目標。該系統(tǒng)在多個抽象層次和多個時間尺度上學(xué)習(xí)行動計劃,并在原則上解決了最近被稱為「開放性問題」的問題。
十二、1991年3月:具有線性自注意力的Transformer
具有「線性自注意力」的Transformer首次發(fā)表于1991年3月。
這些所謂的「快速權(quán)重程序員」(Fast Weight Programmers)或「快速權(quán)重控制器」(Fast Weight Controllers)就像傳統(tǒng)計算機一樣分離了存儲和控制,但以一種端到端差異化、自適應(yīng),以及神經(jīng)網(wǎng)絡(luò)的方式。
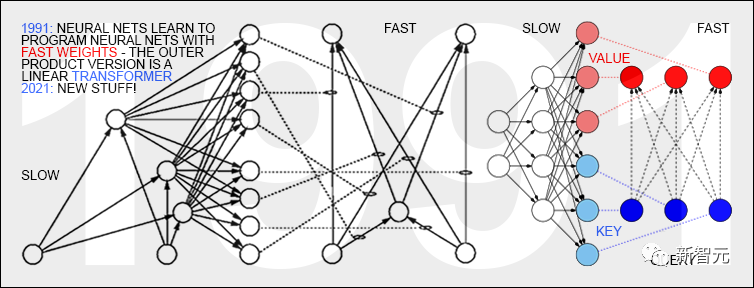 此外,今天的Transformer大量使用無監(jiān)督預(yù)訓(xùn)練,這是Schmidhuber在1990-1991年首次發(fā)表的一種深度學(xué)習(xí)方法。
此外,今天的Transformer大量使用無監(jiān)督預(yù)訓(xùn)練,這是Schmidhuber在1990-1991年首次發(fā)表的一種深度學(xué)習(xí)方法。
十三、1991年4月:通過自監(jiān)督的預(yù)訓(xùn)練進行深度學(xué)習(xí)
今天最強大的NN往往是非常深的,也就是說,它們有很多層的神經(jīng)元或很多后續(xù)的計算階段。
然而,在20世紀90年代之前,基于梯度的訓(xùn)練對深度NN并不奏效(只對淺層NN有效)。與前饋NN(FNN)不同的是,RNN有反饋連接。這使得RNN成為強大的、通用的、平行序列的計算機,可以處理任意長度的輸入序列(比如語音或者視頻)。然而,在20世紀90年代之前,RNN在實踐中未能學(xué)習(xí)深層次的問題。為此,Schmidhuber建立了一個自監(jiān)督的RNN層次結(jié)構(gòu),來嘗試實現(xiàn)「通用深度學(xué)習(xí)」。
1991年4月:將一個NN蒸餾成另一個NN
通過使用Schmidhuber在1991年提出的NN蒸餾程序,上述神經(jīng)歷史壓縮機的分層內(nèi)部表征可以被壓縮成一個單一的遞歸NN(RNN)。在這里,教師NN的知識被「蒸餾」到學(xué)生NN中,方法是訓(xùn)練學(xué)生NN模仿教師NN的行為(同時也重新訓(xùn)練學(xué)生NN,從而保證之前學(xué)到的技能不會被忘記)。NN蒸餾法也在許多年后被重新發(fā)表,并在今天被廣泛使用。
十四、1991年6月:基本問題——梯度消失
Schmidhuber的第一個學(xué)生Sepp Hochreiter在1991年的畢業(yè)論文中發(fā)現(xiàn)并分析了基本的深度學(xué)習(xí)問題。
深度NN受到現(xiàn)在著名的梯度消失問題的困擾:在典型的深度或遞歸網(wǎng)絡(luò)中,反向傳播的錯誤信號要么迅速縮小,要么超出界限增長。在這兩種情況下,學(xué)習(xí)都會失敗。
十五、1991年6月:LSTM/Highway Net/ResNet的基礎(chǔ)
長短期記憶(LSTM)遞歸神經(jīng)網(wǎng)絡(luò)克服了Sepp Hochreiter在上述1991年的畢業(yè)論文中指出的基本深度學(xué)習(xí)問題。
在1997年發(fā)表了經(jīng)同行評審的論文之后(現(xiàn)在是20世紀被引用最多的NN文章),Schmidhuber的學(xué)生Felix Gers和Alex Graves等人,進一步改進了LSTM及其訓(xùn)練程序。1999-2000年發(fā)表的LSTM變體——帶有遺忘門的「vanilla LSTM架構(gòu)」,在如今谷歌的Tensorflow中依然還在應(yīng)用。2005年,Schmidhuber首次發(fā)表了LSTM在時間上完全反向傳播和雙向傳播的文章(同樣也被廣泛使用)。
2006年一個里程碑式的訓(xùn)練方法是「聯(lián)結(jié)主義時間分類」(CTC),用于同時對齊和識別序列。Schmidhuber的團隊在2007年成功地將CTC訓(xùn)練的LSTM應(yīng)用于語音(也有分層的LSTM堆棧),第一次實現(xiàn)了卓越的端到端神經(jīng)語音識別效果。2009年,通過Alex的努力,由CTC訓(xùn)練的LSTM成為第一個贏得國際比賽的RNN,即三個ICDAR 2009手寫比賽(法語、波斯語、阿拉伯語)。這引起了業(yè)界的極大興趣。LSTM很快被用于所有涉及序列數(shù)據(jù)的場合,比如語音和視頻。2015年,CTC-LSTM的組合極大地改善了谷歌在安卓智能手機上的語音識別性能。直到2019年,谷歌在移動端搭載的語音識別仍然是基于LSTM。
1995年:神經(jīng)概率語言模型
1995年,Schmidhuber提出了一個優(yōu)秀的神經(jīng)概率文本模型,其基本概念在2003年被重新使用。2001年,Schmidhuber表明LSTM可以學(xué)習(xí)HMM等傳統(tǒng)模型無法學(xué)習(xí)的語言。2016年的谷歌翻譯,則是基于兩個連接的LSTM(白皮書提到LSTM超過50次),一個用于傳入文本,一個用于傳出翻譯。同年,谷歌數(shù)據(jù)中心用于推理的超強計算能力中,有超過四分之一用于LSTM(還有5%用于另一種流行的深度學(xué)習(xí)技術(shù),即CNN)。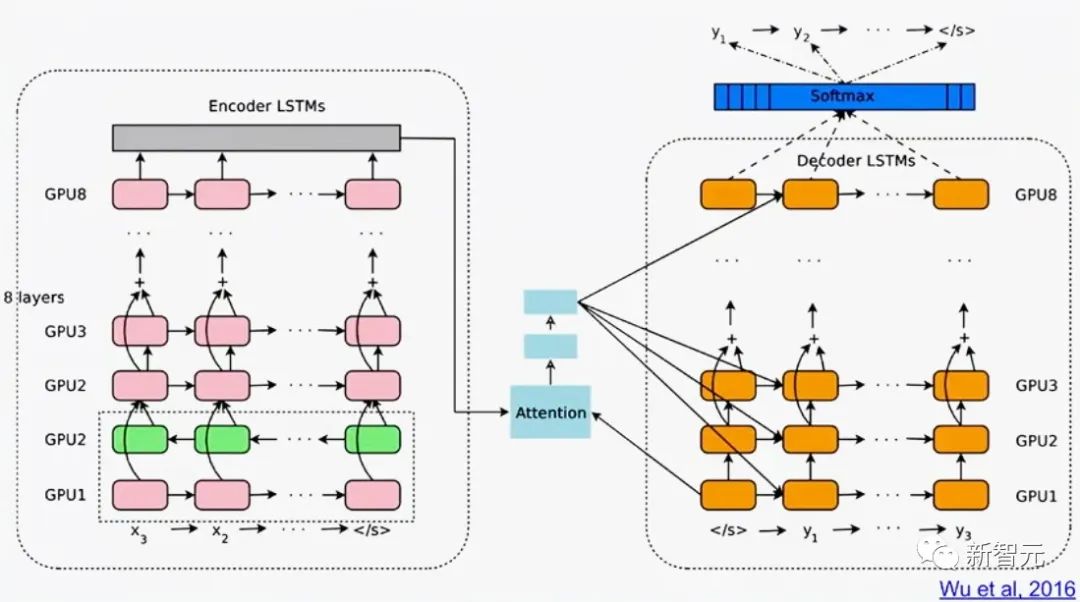 到了2017年,LSTM還為Facebook的機器翻譯(每周超過300億次翻譯)、蘋果在大約10億部iPhone上的Quicktype、亞馬遜的Alexa的語音、谷歌的圖像標題生成和自動電子郵件回答等提供支持。當然,Schmidhuber的LSTM也被大量用于醫(yī)療保健和醫(yī)療診斷——簡單的谷歌學(xué)術(shù)搜索就能找到無數(shù)標題中帶有「LSTM」的醫(yī)學(xué)文章。
到了2017年,LSTM還為Facebook的機器翻譯(每周超過300億次翻譯)、蘋果在大約10億部iPhone上的Quicktype、亞馬遜的Alexa的語音、谷歌的圖像標題生成和自動電子郵件回答等提供支持。當然,Schmidhuber的LSTM也被大量用于醫(yī)療保健和醫(yī)療診斷——簡單的谷歌學(xué)術(shù)搜索就能找到無數(shù)標題中帶有「LSTM」的醫(yī)學(xué)文章。
2015年5月,Schmidhuber團隊基于LSTM原理提出了Highway Network,第一個具有數(shù)百層的非常深的FNN(以前的NN最多只有幾十層)。微軟的ResNet(贏得了ImageNet 2015比賽)便是它的一個版本。早期Highway Net在ImageNet上的表現(xiàn)與ResNet大致相同。Highway Net的變體也被用于某些算法任務(wù),在這些任務(wù)中,純殘差層的效果并不理想 。
LSTM/Highway Net原理是現(xiàn)代深度學(xué)習(xí)的核心
深度學(xué)習(xí)的核心是NN深度。在20世紀90年代,LSTM為有監(jiān)督的遞歸NN帶來了基本無限的深度;在2000年,受LSTM啟發(fā)的Highway Net為前饋NN帶來了深度。
現(xiàn)在,LSTM已經(jīng)成為20世紀被引用最多的NN,而Highway Net的其中一個版本ResNet,則是21世紀被引用最多的NN。
十六、1980至今:在沒有老師的情況下學(xué)習(xí)行動的NNN
此外,NN也與強化學(xué)習(xí)(RL)有關(guān)。
雖然部分問題可以通過早在20世紀80年代之前發(fā)明的非神經(jīng)技術(shù)來解決。比如,蒙特卡洛樹搜索(MC)、動態(tài)規(guī)劃(DP)、人工進化、α-β-剪枝、控制理論和系統(tǒng)識別、隨機梯度下降,以及通用搜索技術(shù)。但深度FNN和RNN可以為某些類型的RL任務(wù)帶來更好的效果。一般來說,強化學(xué)習(xí)智能體必須學(xué)會如何在沒有老師的幫助下,與一個動態(tài)的、最初未知的、部分可觀察的環(huán)境互動,從而使預(yù)期的累積獎勵信號最大化。在行動和可感知的結(jié)果之間可能存在任意的、先驗的未知延遲。當環(huán)境有一個馬爾可夫接口,使RL智能體的輸入可以傳達確定下一個最佳行動所需的所有信息時,基于動態(tài)規(guī)劃(DP)/時序差分(TD)/蒙特卡洛樹搜索(MC)的RL會非常成功。對于沒有馬爾可夫接口的更復(fù)雜的情況,智能體不僅要考慮現(xiàn)在的輸入,還要考慮以前輸入的歷史。對此,由RL算法和LSTM形成的組合已經(jīng)成為了一種標準方案,特別是通過策略梯度訓(xùn)練的LSTM。
例如,在2018年,一個經(jīng)過PG訓(xùn)練的LSTM是OpenAI著名的Dactyl的核心,它在沒有老師的情況下學(xué)會了控制一只靈巧的機器人手。視頻游戲也是如此。2019年,DeepMind(由Schmidhuber實驗室的一名學(xué)生共同創(chuàng)立)在《星際爭霸》游戲中擊敗了職業(yè)選手,其中用到的Alphastar,就是有一個由PG訓(xùn)練的深度LSTM核心。
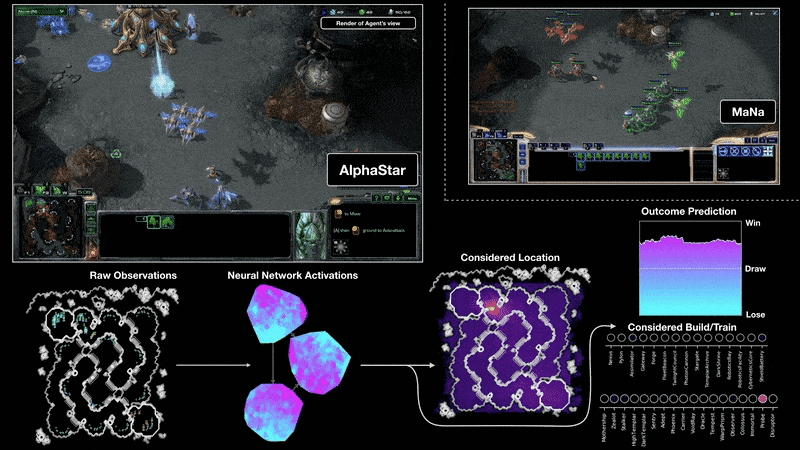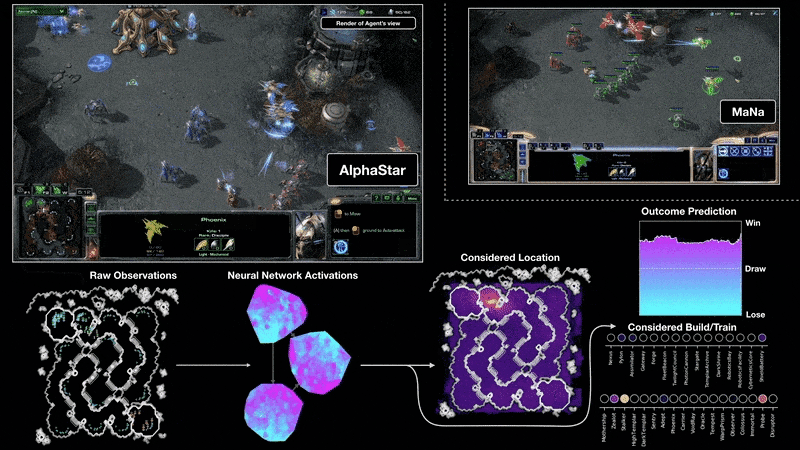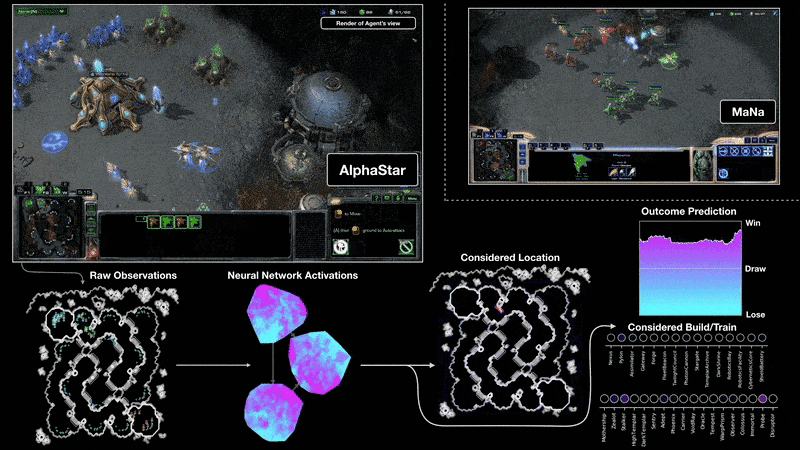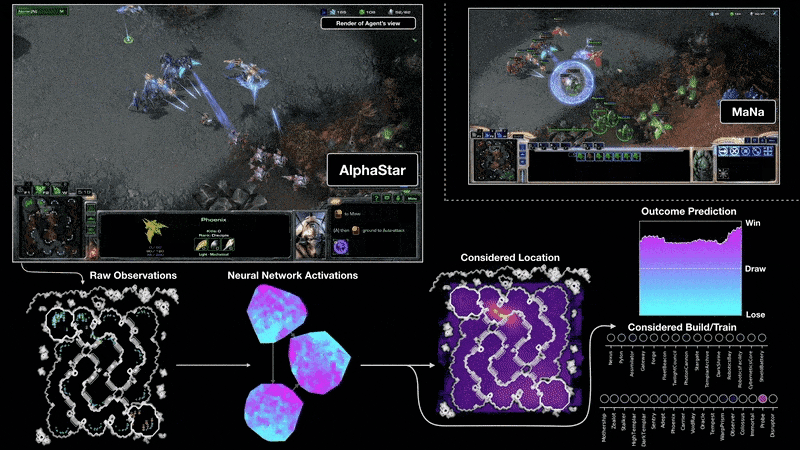
與此同時,RL LSTM(占模型總參數(shù)數(shù)的84%)也是著名的OpenAI Five的核心,它在Dota 2中擊敗了專業(yè)的人類玩家。RL的未來將是用復(fù)雜輸入流的緊湊時空抽象來學(xué)習(xí)/組合/規(guī)劃,也就是關(guān)于常識推理和學(xué)習(xí)思考。Schmidhuber在1990-91年發(fā)表的論文中提出,自監(jiān)督的神經(jīng)歷史壓縮器,可以學(xué)習(xí)多層次的抽象和多時間尺度上的表征概念;而基于端到端的可區(qū)分NN的子目標生成器,則可以通過梯度下降學(xué)習(xí)分層的行動計劃。在隨后的1997年和2015-18年,更復(fù)雜的學(xué)習(xí)抽象思維的方法被發(fā)表。
十七、是硬件問題,呆子!
在過去的一千年里,如果沒有不斷改進和加速升級的計算機硬件,深度學(xué)習(xí)算法不可能迎來重大突破。
我們第一個已知的齒輪計算設(shè)備是2000多年前古希臘的安提基特拉機械(Antikythera mechanism)。這是現(xiàn)今所知的最古老的復(fù)雜科學(xué)計算機,同時也是世界上第一臺模擬計算機。
安而世界上第一臺實用的可編程機器,是古希臘機械學(xué)家海倫于公元1世紀發(fā)明的。17世紀的機器變得更為靈活,可以根據(jù)輸入數(shù)據(jù)計算答案。第一臺用于簡單算術(shù)的機械計算器由威廉·契克卡德(Wilhelm Schickard)于1623年發(fā)明制造。1673年,萊布尼茨設(shè)計了第一臺可以執(zhí)行所有四種算術(shù)運算,并帶有內(nèi)存的機器。他還描述了由穿孔卡控制的二進制計算機的原理并提出鏈式法則,構(gòu)成了深度學(xué)習(xí)和現(xiàn)代人工智能的重要組成部分。
800年左右,約瑟夫·瑪麗·雅卡爾 (Joseph Marie Jacquard) 等人在法國制造了第一臺首臺可設(shè)計織布機——雅卡爾織布機(Jacquard machine)。該發(fā)明對將來發(fā)展出其他可編程機器(例如計算機)起了重要作用。
他們啟發(fā)了阿達·洛芙萊斯(Ada Lovelace)和她的導(dǎo)師查爾斯·巴貝奇(Charles Babbage)發(fā)明了一臺現(xiàn)代電子計算機的前身:巴貝奇差分機。在隨后的1843年,洛芙萊斯公布了世界上第一套計算機算法。
巴貝奇差分機1914年,西班牙人Leonardo Torres y Quevedo成為20世紀第一位人工智能先驅(qū),他創(chuàng)造了第一個國際象棋終端機器玩家。1935年至1941年間,康拉德·楚澤(Konrad Zuse)發(fā)明了世界上第一臺可運行的可編程通用計算機:Z3。
與巴貝奇分析機不同,楚澤使用萊布尼茨的二進制計算原理,而不是傳統(tǒng)的十進制計算。這大大簡化了硬件的負荷。1944年,霍華德·艾肯(Howard Aiken)帶領(lǐng)團隊,發(fā)明世界上第一臺大型自動數(shù)字計算機Mark Ⅰ(馬克一號)。1948年,弗雷德里克·威廉姆斯(Frederic Williams)、湯姆·基爾伯恩(Tom Kilburn)和杰夫·托蒂(Geoff Tootill)發(fā)明了世界第一臺電子存儲程序計算機:小型實驗機 (SSEM),又被稱為「曼徹斯特寶貝」(Manchester Baby)。
從那時起,計算機的運算在集成電路(IC)的幫助下變得更快。1949年,西門子的維爾納·雅各比(Werner Jacobi)申請了一項集成電路半導(dǎo)體專利,使一個公共基板可以有多個晶體管。1958年,Jack Kilby展示了帶有外部導(dǎo)線的集成電路。1959年,羅伯特·諾伊斯 (Robert Noyce) 提出了單片集成電路。自上世紀70年代以來,圖形處理單元 (GPU) 已被用于通過并行處理來加速計算。現(xiàn)在,計算機的GPU包含數(shù)十億個晶體管。物理極限在哪里?根據(jù)漢斯·約阿希姆·布雷默曼(Hans Joachim Bremermann)提出的布雷默曼極限,一臺質(zhì)量為1千克、體積為1升的計算機最多可以在最多10的32次方位上每秒執(zhí)行最多10的51次方操作。
然而,太陽系的質(zhì)量只有2x10^30千克,這一趨勢勢必會在幾個世紀內(nèi)打破,因為光速會嚴重限制以其他太陽系的形式獲取額外質(zhì)量。因此,物理學(xué)的限制要求未來高效的計算硬件必須像大腦一樣,在三維空間中有許多緊湊放置的處理器以最小化總連接成本,其基本架構(gòu)本質(zhì)上是一種深度的、稀疏連接的三維RNN。Schmidhuber推測,此類RNN的深度學(xué)習(xí)方法將變得更加重要。
十八、1931年以來的人工智能理論
現(xiàn)代人工智能和深度學(xué)習(xí)的核心主要是基于近幾個世紀的數(shù)學(xué):微積分、線性代數(shù)和統(tǒng)計學(xué)。
20世紀30年代初,哥德爾創(chuàng)立了現(xiàn)代理論計算機科學(xué)。他引入了一種以整數(shù)為基礎(chǔ)的通用編碼語言,允許以公理形式將任何數(shù)字計算機的操作正規(guī)化。同時,哥德爾還構(gòu)建了著名的形式化語句,通過給定一個計算性的定理檢驗器,從可列舉的公理集合中系統(tǒng)地列舉所有可能的定理。因此,他確定了算法定理證明、計算以及任何類型的基于計算的人工智能的基本限制。此外,哥德爾在寫給約翰·馮·諾伊曼的著名信件中,確定了計算機科學(xué)中最著名的開放問題「P=NP?」。

1935年,Alonzo Church通過證明Hilbert和Ackermann的決策問題沒有一般的解決方案,得出了哥德爾結(jié)果的一個推論。為了做到這一點,他使用了他的另一種通用編碼語言,稱為Untyped Lambda Calculus,它構(gòu)成了極具影響力的編程語言LISP的基礎(chǔ)。1936年,阿蘭·圖靈引入了另一個通用模型:圖靈機,重新得出了上述結(jié)果。同年,Emil Post發(fā)表了另一個獨立的計算通用模型。康拉德·楚澤不僅創(chuàng)造了世界上第一臺可用的可編程通用計算機,并且還設(shè)計了第一種高級編程語言——Plankalkül。他在1945年將其應(yīng)用于國際象棋,在1948年應(yīng)用于定理證明。
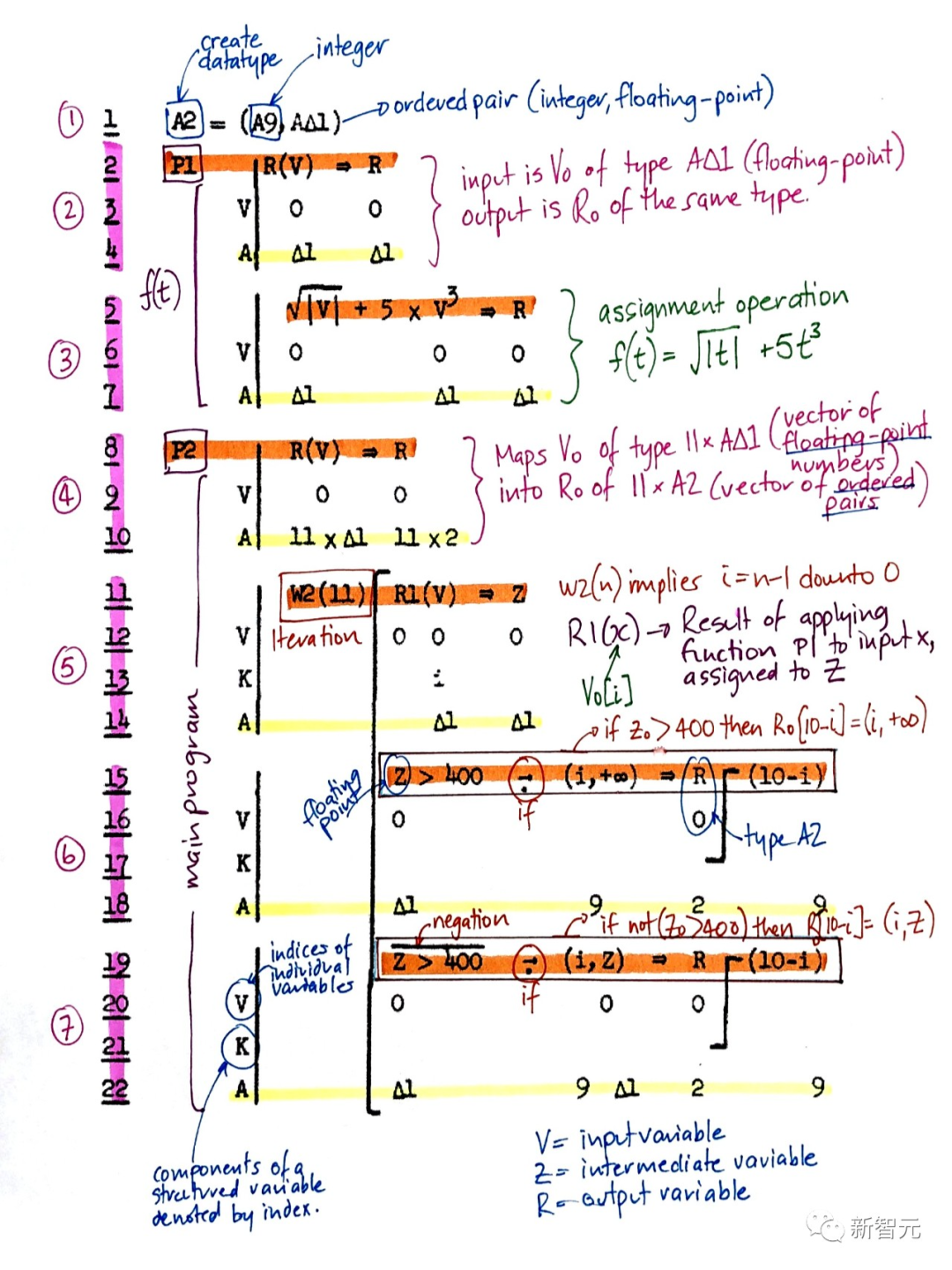
Plankalkül20世紀40-70年代的大部分早期人工智能實際上是關(guān)于定理證明和通過專家系統(tǒng)和邏輯編程進行哥德爾式的推導(dǎo)。1964年,Ray Solomonoff將貝葉斯(實際上是拉普拉斯)概率推理和理論計算機科學(xué)結(jié)合起來,得出一種數(shù)學(xué)上最優(yōu)(但計算上不可行)的學(xué)習(xí)方式,從過去的觀察中預(yù)測未來數(shù)據(jù)。他與Andrej Kolmogorov一起創(chuàng)立了柯氏復(fù)雜性或算法信息論(AIT)的理論,通過計算數(shù)據(jù)的最短程序的概念,將奧卡姆剃刀的概念正式化,從而超越了傳統(tǒng)的信息論。
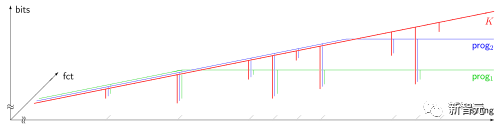
柯氏復(fù)雜性自指哥德爾機更通用的最優(yōu)性并不局限于漸進式最優(yōu)。盡管如此,由于各種原因,這種數(shù)學(xué)上的最優(yōu)人工智能在實踐上還不可行。相反,實用的現(xiàn)代人工智能是基于次優(yōu)的、有限的、但并不被極度理解的技術(shù),如NN和深度學(xué)習(xí)則是重點。但誰知道20年后的人工智能歷史會是什么樣的呢?
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238265 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113
發(fā)布評論請先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第4章-AI與生命科學(xué)讀后感
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第一章人工智能驅(qū)動的科學(xué)創(chuàng)新學(xué)習(xí)心得
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新
FPGA在人工智能中的應(yīng)用有哪些?
人工智能、機器學(xué)習(xí)和深度學(xué)習(xí)是什么
人工智能深度學(xué)習(xí)的五大模型及其應(yīng)用領(lǐng)域
阿里通義千問重磅升級,免費開放1000萬字長文檔處理功能
嵌入式人工智能的就業(yè)方向有哪些?
“單純靠大模型無法實現(xiàn) AGI”!萬字長文看人工智能演進






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論