") 異構(gòu)計算面臨的挑戰(zhàn)和未來發(fā)展趨勢
異構(gòu)計算面臨的挑戰(zhàn)和未來發(fā)展趨勢
導(dǎo)讀
超異構(gòu)和異構(gòu)的本質(zhì)區(qū)別在哪里?
這篇文章通過對異構(gòu)計算的歷史、發(fā)展、挑戰(zhàn)、以及優(yōu)化和演進等方面的分析,來進一步闡述從異構(gòu)走向異構(gòu)融合(即超異構(gòu))的必然發(fā)展趨勢。
1、異構(gòu)計算的歷史發(fā)展
1.1 并行計算的興起
1971年Intel發(fā)明全球第一款商用的CPU處理器,在之后的上世紀70-90年代,CPU(核)經(jīng)歷了翻天覆地的變化:
- 宏觀架構(gòu)有精簡RISC和復(fù)雜CISC路線之爭;
- 各種各樣的微架構(gòu)創(chuàng)新技術(shù),如處理器流水線、乘法/除法器等復(fù)雜執(zhí)行單元、指令多發(fā)射、亂序執(zhí)行、緩存等等;
- 處理器數(shù)據(jù)位寬從4位到8位到16位到32位,再到目前仍是主流的64位;
- 等等。
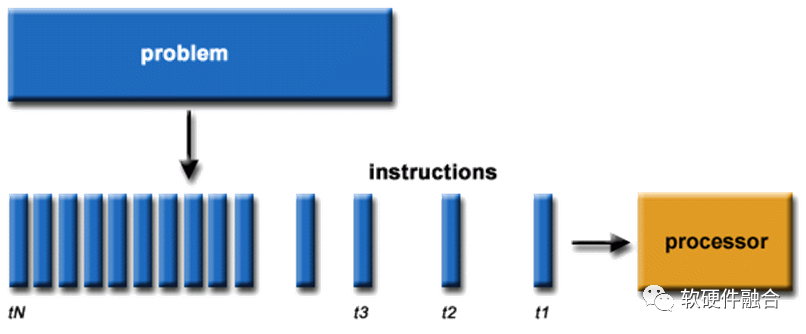
經(jīng)過這些創(chuàng)新之后,逐步的觸達了(架構(gòu)/微架構(gòu)層次的)CPU(核)性能的上限。不考慮工藝升級的影響,單個處理器核的性能幾乎挖掘到極致,持續(xù)增加性能的希望,不得不落在多個處理器核并行的路徑上來。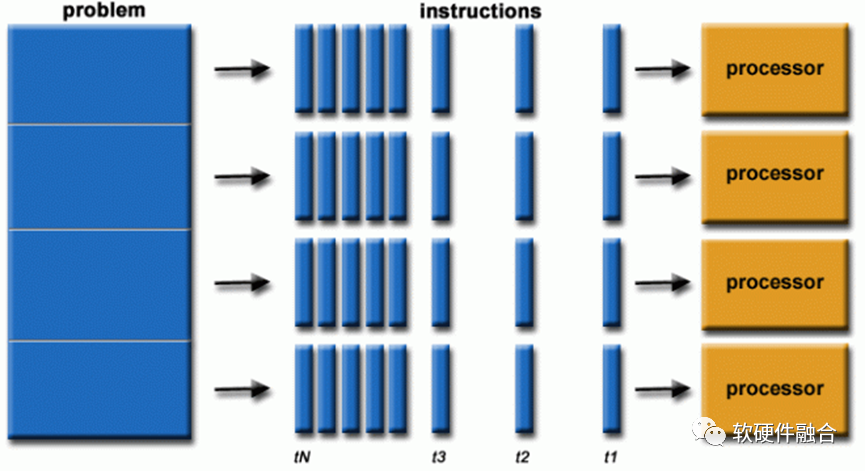 IBM公司于2001年推出IBM Power4雙核處理器,是世界上第一款多核處理器。隨后,AMD和Intel分別推出了各自的雙核處理器。隨著時間推移,更多的CPU核心被集成進了CPU芯片。目前,最新的AMD EPYC 9654 CPU具有96個核心192個硬件線程的超高并行能力。
IBM公司于2001年推出IBM Power4雙核處理器,是世界上第一款多核處理器。隨后,AMD和Intel分別推出了各自的雙核處理器。隨著時間推移,更多的CPU核心被集成進了CPU芯片。目前,最新的AMD EPYC 9654 CPU具有96個核心192個硬件線程的超高并行能力。
1.2 通用GPU本質(zhì)上是眾核并行
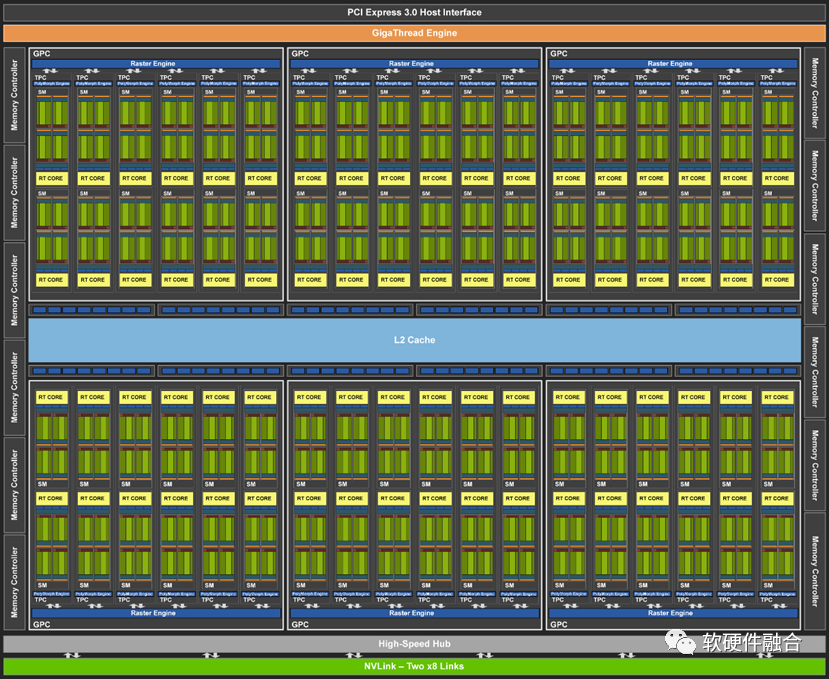
GPGPU本質(zhì)上是數(shù)以百/千計的高效能的小CPU組成的眾核并行計算處理器。如NVIDIA的圖靈架構(gòu)GPGPU,總共72個SM,每個SM由64個CUDA核、8個Tensor核、1個RT核、4個紋理單元,總計有4608個CUDA核、576個Tensor核、72個RT核、288個紋理單元。
GPU眾核(數(shù)千個)和CPU多核(數(shù)十個)的區(qū)別在于:CPU核是高性能的大核,足夠高性能的同時也足夠復(fù)雜,面積功耗成本等方面的代價也高,單位計算的成本較高;而GPU核是高效能的小核,每個核的性能較低,但數(shù)以千計的小核并行起來的性能足夠高,單位計算的功耗面積等成本較低,但單核的性能不足以滿足通用計算單個線程性能的要求。
1.3 異構(gòu)計算的架構(gòu)模式:CPU+xPU
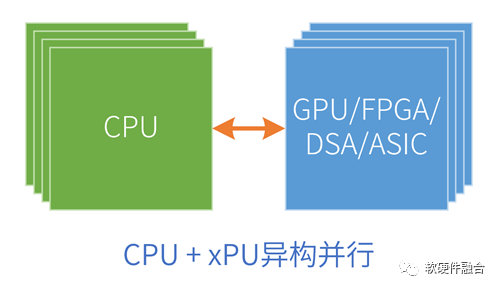 CPU是圖靈完備的(在這里,圖靈完備可以通俗的理解成可以獨立運行的處理器平臺),因此CPU可以單獨的作為軟件系統(tǒng)的運行平臺。而GPU等其他加速處理器則不同,這些平臺是非圖靈完備的,或者說無法獨立運行,只能在CPU的協(xié)助下才可以運行。也因此,我們通常見到的異構(gòu)計算系統(tǒng)都是“CPU+xPU加速處理器”的架構(gòu)(xPU特指其他各類非CPU處理器)。
CPU是圖靈完備的(在這里,圖靈完備可以通俗的理解成可以獨立運行的處理器平臺),因此CPU可以單獨的作為軟件系統(tǒng)的運行平臺。而GPU等其他加速處理器則不同,這些平臺是非圖靈完備的,或者說無法獨立運行,只能在CPU的協(xié)助下才可以運行。也因此,我們通常見到的異構(gòu)計算系統(tǒng)都是“CPU+xPU加速處理器”的架構(gòu)(xPU特指其他各類非CPU處理器)。
2、異構(gòu)成為計算架構(gòu)的主流
2.1 CPU性能瓶頸,但算力需求永無止境
上世紀80-90年代,每18個月,CPU性能提升一倍,這就是著名的摩爾定律。如今,CPU性能提升每年只有3%,要想性能翻倍,需要20年。CPU的性能提升已經(jīng)達到瓶頸,難堪大任。
雖然CPU的性能提升幾乎停滯,但對算力(性能是微觀,算力是宏觀)的需求,是永無止境的:
案例一:2012-2018年共6年時間里,人們對于AI算力的需求增長了超過30萬倍。
案例二:目前L2級別的自動駕駛通常需要數(shù)百TOPS的算力,NVIDIA將于2024年底正式發(fā)布的Thor可以實現(xiàn)2000 TOPS的算力,但要想真正實現(xiàn)L4/L5級別的自動駕駛算力,則需要20000+ TOPS。
案例三:Intel SVP拉加·庫德里表示,要想實現(xiàn)元宇宙級別的用戶體驗,需要當前的算力要再提升1000倍。隨著元宇宙概念的興起,對算力需求猛增,算力成為制約元宇宙發(fā)展的最大問題。
算力需求越來越大,異構(gòu)成為了(架構(gòu)層次)性能提升的主要手段。
2.2 強大的開發(fā)框架和生態(tài),是異構(gòu)計算成功的關(guān)鍵
實際上,硬件實現(xiàn)同構(gòu)或異構(gòu)并行的門檻相對不高。但受限于人類的思維習(xí)慣,駕馭并行硬件平臺,也即并行編程,的難度較大;特別是異構(gòu)并行,編程難度更大。異構(gòu)并行編程不僅僅涉及眾多并行線程的編程,還涉及到加速處理器和Host CPU的交互編程,還包括這兩者的交叉同步。
在并行系統(tǒng)里,通過(手動)編程實現(xiàn)單個軟件內(nèi)部多個不同線程的并行,這種方式編程難度大,系統(tǒng)復(fù)雜,而且對并行資源的利用效率不高,這不是主流的方式。
在CPU同構(gòu)并行的硬件平臺上,更多的是通過操作系統(tǒng)的多線程調(diào)度能力以及虛擬化的多系統(tǒng)隔離的方式,實現(xiàn)宏觀意義上的多個系統(tǒng)或多個軟件的并行,而不是通過(手動)編程實現(xiàn)單個軟件內(nèi)部的線程級并行。
GPU眾核編程則要更加復(fù)雜。為了降低編程門檻,GPU上運行的程序并不是完全“自由”的,而且強加了一些約束或底層細節(jié)屏蔽,以此來降低編程難度。比如SIMD方式的單線程多處理器并行執(zhí)行(多個處理器執(zhí)行的是相同的程序),再比如通過底層的軟件或硬件機制實現(xiàn)統(tǒng)一內(nèi)存,還比如通過框架和開發(fā)庫等方式進一步降低開發(fā)難度,等等。通過這些方式,可以顯著的提高異構(gòu)并行的性能利用效率、提高編程效率、降低編程難度等。
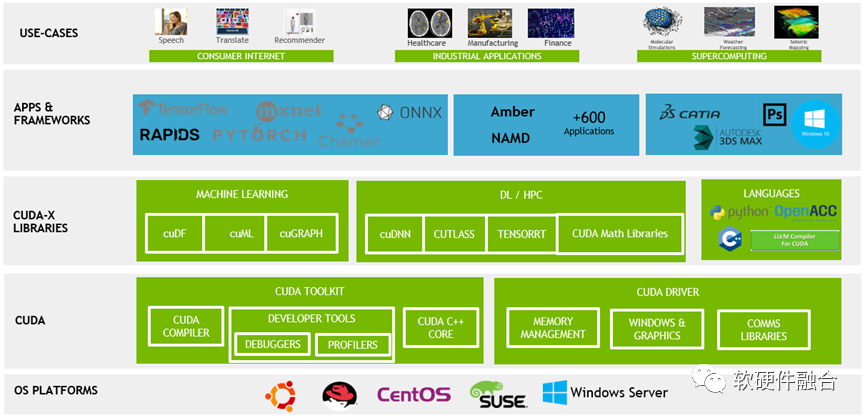
2006 年 11 月,NVIDIA推出了CUDA框架,這是一種通用并行計算平臺和編程模型,它利用NVIDIA GPU中的并行計算引擎以比CPU更有效的方式解決許多復(fù)雜的計算問題。經(jīng)過十多年的發(fā)展,NVIDIA建立了基于其GPGPU的非常強大的CUDA異構(gòu)編程框架和生態(tài)。
隨著AI大潮的到來,對算力的需求不斷快速增長,傳統(tǒng)CPU的算力平臺越來越難以滿足業(yè)務(wù)算力的需要。這進一步推動NVIDIA GPGPU和CUDA成為了炙手可熱的行業(yè)“明星”,使得NVIDIA成為全球市值最高的芯片公司。
對大算力芯片來說,生態(tài)是成功的第一關(guān)鍵。
2.3 DSA,體系結(jié)構(gòu)的黃金年代
DSA是在定制ASIC的基礎(chǔ)上回調(diào),使其具有一定的軟件可編程靈活性。DSA出現(xiàn)的原因主要有:
- CPU單核性能瓶頸,摩爾定律逐漸失效;
- 隨著集成電路工藝逐漸逼近理論極限,晶體管的電流和電壓已經(jīng)不能繼續(xù)下降了,丹納德縮放定律也逐漸失效;
- 阿姆達爾定律表明:并行性的理論性能提升受任務(wù)順序部分的限制。也因此,通過多核并行來提升綜合性能的收益也在逐漸遞減。
圖靈獎獲得者John Hennessy和David Patterson在其2017年說,未來十年是體系機構(gòu)的黃金年代,在CPU性能達到瓶頸的情況下,要大幅提高性能并且優(yōu)化成本和能耗的唯一途徑是DSA,即針對特定領(lǐng)域的特殊需求定制處理器。
2016年發(fā)布的谷歌TPU是第一款DSA架構(gòu)的處理器,從此之后,各種類型的符合DSA概念的加速處理器如雨后春筍般涌現(xiàn)。
3、異構(gòu)計算存在的主要問題
3.1 DSA的問題
DSA無法包治百病。
所謂“成也蕭何敗也蕭何”,DSA的優(yōu)勢是領(lǐng)域定制,劣勢也是領(lǐng)域定制:
- 優(yōu)勢在于:領(lǐng)域定制具有一定的靈活可編程性,能夠覆蓋比ASIC大得多的場景范圍;并且性能跟ASIC相當,性能效率甚至高于ASIC。
- 劣勢在于:架構(gòu)完全碎片化。不同領(lǐng)域是完全不同的硬件平臺和軟件生態(tài);即使同一領(lǐng)域,不同廠家的架構(gòu)依然不同;甚至,同一廠家不同代產(chǎn)品的架構(gòu)都會不同。
DSA還有一個劣勢的地方在于:定制的架構(gòu),其靈活性不太適合一些應(yīng)用類型的性能加速,比如AI加速。受限于AI算法多種多樣并且許多AI算法仍在快速迭代,DSA性質(zhì)的AI加速器都跟不上軟件的差異性和迭代速度,從而導(dǎo)致AI-DSA芯片的落地困難。
3.2 異構(gòu)xPU無法兼顧性能和靈活性
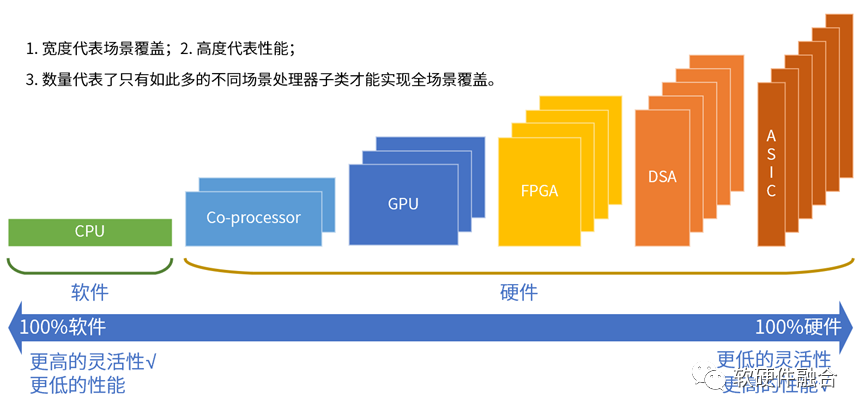
我們依據(jù)指令復(fù)雜度從簡單到復(fù)雜,可以把典型的處理器引擎劃分為CPU、協(xié)處理器、GPU、FPGA、DSA和ASIC。CPU可以理解成純軟件,協(xié)處理器是附屬于CPU,在硬件上跟CPU是一體的。因此,可以作為加速處理器xPU的處理器引擎類型只有后面四個。異構(gòu)計算的核心矛盾在于:系統(tǒng)越復(fù)雜,越需要選擇靈活的處理器;性能挑戰(zhàn)越大,越需要選擇定制的處理器。本質(zhì)原因在于,單一處理器無法兼顧性能和靈活性:
GPGPU,通用眾核并行計算平臺,GPU靈活性較好,適用于性能敏感的業(yè)務(wù)應(yīng)用加速;但性能效率不夠極致。
DSA,接近于ASIC性能,但靈活性差一些。比較適合基礎(chǔ)設(shè)施層的任務(wù)加速,難以適應(yīng)復(fù)雜業(yè)務(wù)計算場景對靈活性的要求。
FPGA不僅功耗和成本高,而且需要經(jīng)過硬件編程之后才能確定其真正的架構(gòu)類型。FPGA的靈活性來源于硬件可編程性,也意味著架構(gòu)是變化的,不利于軟件生態(tài)的形成。FPGA實際落地案例不多。
- ASIC,受限于其完全固化的業(yè)務(wù)邏輯,在靈活多變的復(fù)雜計算場景幾乎難以應(yīng)用。
3.3 異構(gòu)計算的孤島問題
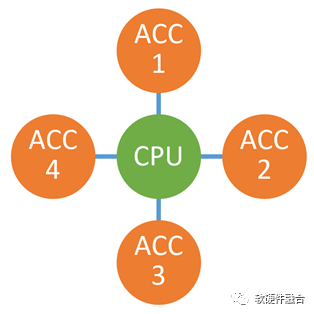 隨著異構(gòu)計算成為計算的主流架構(gòu),也隨著異構(gòu)的處理器越來越多,最終的系統(tǒng)一定不是Host+某個唯一的xPU加速處理器,而是Host+很多個xPU加速處理器的模式。這樣,多個異構(gòu)協(xié)同計算的問題就出現(xiàn)了:
隨著異構(gòu)計算成為計算的主流架構(gòu),也隨著異構(gòu)的處理器越來越多,最終的系統(tǒng)一定不是Host+某個唯一的xPU加速處理器,而是Host+很多個xPU加速處理器的模式。這樣,多個異構(gòu)協(xié)同計算的問題就出現(xiàn)了:
最核心的是,每個加速處理器都只考慮特定的場景或領(lǐng)域;反過來說,就是較少考慮與其他加速處理器的協(xié)同。如同瞎子摸象,每個人看到扇子、繩子、柱子、墻壁的時候,最終,能組織成“大象”嗎?
加速處理器之間的交互困難。所有加速器的交互需要經(jīng)過CPU,而CPU已經(jīng)性能瓶頸,還要給它壓更重的“擔(dān)子”,那就是“頸上加頸”。
服務(wù)器等計算機設(shè)備的物理空間和擴展總線/卡槽有限,很難支持太多的物理加速卡,異構(gòu)加速處理器需要整合。
4、異構(gòu)計算的架構(gòu)優(yōu)化
4.1 異構(gòu)計算的優(yōu)化權(quán)衡
維度一:處理器引擎的類型。靈活性和性能是系統(tǒng)架構(gòu)的核心矛盾,更多的靈活性,也意味著更加易于編程,系統(tǒng)更好駕馭,與此同時卻意味著更低的性能。許多設(shè)計權(quán)衡其實都在根據(jù)業(yè)務(wù)場景的特點,在靈活性和性能的天平上左右搖擺:到底是應(yīng)該偏向靈活性的CPU多一些,還是偏向極致性能的ASIC多一些。維度二,處理器引擎類型的數(shù)量。系統(tǒng)的駕馭難度,也跟處理器類型的數(shù)量有關(guān):
同構(gòu)并行只有一種類型的處理器引擎(CPU),編程要相對簡單。
異構(gòu)的CPU+xPU加速處理器是兩種類型的處理器引擎,編程要更復(fù)雜一些。
既然異構(gòu)有兩個類型,未來是否還可以有三個、四個,甚至更多的處理器類型組成更復(fù)雜的多異構(gòu)系統(tǒng)?
更多類型的處理器引擎,又是一個艱難的抉擇:一方面意味著性能的進一步提升,另一方面意味著更高的編程難度。
4.2 各類型處理器都在拓展自己的能力邊界
越來越“卷”,隨著處理器引擎越來越多,每個處理器引擎其實都突破了我們通常意義上的各自邊界,侵入到其他處理器引擎的領(lǐng)地。例如:
- CPU集成協(xié)處理器。CPU不斷擴展硬件加速指令集,這些加速指令集的執(zhí)行單元就是協(xié)處理器。例如Intel Xeon支持AVX和AMX。
- GPU集成CUDA核,還集成DSA性質(zhì)的Tensor核,使得單個GPU引擎具有了DSA性質(zhì)的能力。
- FPGA集成CPU以及ASIC,例如AMD Xilinx Zynq。
- ASIC不斷回調(diào),變成部分可編程的DSA,可以當作是ASIC+DSA。
處理器引擎不斷擴展,在引擎內(nèi)部形成了某種程度上的“異構(gòu)”能力,這可以看做是異構(gòu)計算優(yōu)化權(quán)衡的第三個維度。
4.3 異構(gòu)計算的未來,從單異構(gòu)走向多異構(gòu)融合
前面我們從三個維度介紹了異構(gòu)計算的優(yōu)(左)化(右)權(quán)(搖)衡(擺):要想獲得靈活性,勢必會降低性能(效率);而要想獲得性能,勢必會降低系統(tǒng)的靈活性,增加系統(tǒng)的復(fù)雜度,使得系統(tǒng)難以駕馭。但考慮到業(yè)務(wù)應(yīng)用對算力的渴求,我們不得不“迎難而上”,不斷的提升硬件平臺的性能。這樣勢必會增加整個系統(tǒng)的復(fù)雜度,也進一步提高了編程的難度。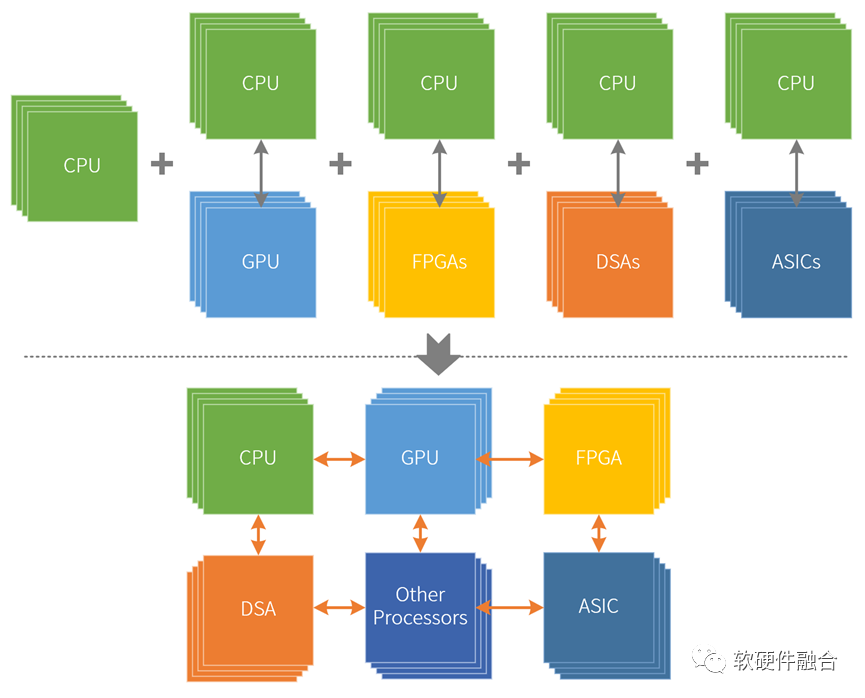 受限于前面提到的異構(gòu)計算孤島問題,把多個異構(gòu)計算系統(tǒng)合并到一起的時候,不能簡單的拼湊,而是要重新構(gòu)建一個新的超異構(gòu)計算系統(tǒng)。
受限于前面提到的異構(gòu)計算孤島問題,把多個異構(gòu)計算系統(tǒng)合并到一起的時候,不能簡單的拼湊,而是要重新構(gòu)建一個新的超異構(gòu)計算系統(tǒng)。
接下來,更重要的問題來了:如何駕馭比異構(gòu)并行更復(fù)雜的超異構(gòu)融合計算?
5、駕馭超異構(gòu)
串行計算符合人類思維,編程相對最簡單;同構(gòu)并行的編程,就要復(fù)雜很多;異構(gòu)并行,則更是難上加難;那么超異構(gòu)并行呢?那就是難上加難再加難。要想駕馭超異構(gòu),核心的思路跟駕馭異構(gòu)計算的思路一致,就是要降低軟硬件系統(tǒng)的復(fù)雜度。接下來,我們詳細介紹一些主要的降低復(fù)雜度的方法。
5.1 復(fù)雜大系統(tǒng)分解成簡單小系統(tǒng)
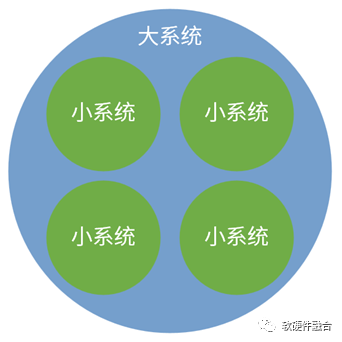 從系統(tǒng)的角度,多個小系統(tǒng)組成一個大系統(tǒng),多個大系統(tǒng)組成一個宏系統(tǒng)。反過來,復(fù)雜大系統(tǒng)可以分解成若干個簡單的小的系統(tǒng),大系統(tǒng)由多個小系統(tǒng)和小系統(tǒng)間的交互組成。
從系統(tǒng)的角度,多個小系統(tǒng)組成一個大系統(tǒng),多個大系統(tǒng)組成一個宏系統(tǒng)。反過來,復(fù)雜大系統(tǒng)可以分解成若干個簡單的小的系統(tǒng),大系統(tǒng)由多個小系統(tǒng)和小系統(tǒng)間的交互組成。
相比大系統(tǒng),小系統(tǒng)必然更加簡單;針對分解后的小系統(tǒng),則可以更加容易的駕馭。
5.2 依據(jù)系統(tǒng)的性能/靈活性特征進行分層
 應(yīng)用,是完全不可確定的,針對應(yīng)用,只能采用CPU處理器。如果完全“躺平”(不加約束),并不考慮平臺上面運行什么軟件任務(wù),那么極端保守的做法就是選用CPU平臺。CPU平臺什么任務(wù)都能支持,但劣勢是性能是最差的,成本代價是最高的。一個系統(tǒng)并不都是應(yīng)用類型的任務(wù)。系統(tǒng)可以看作是很多工作任務(wù)的組合,這些工作任務(wù)都各有特點,我們可以針對任務(wù)的特點,把任務(wù)進行分類:
應(yīng)用,是完全不可確定的,針對應(yīng)用,只能采用CPU處理器。如果完全“躺平”(不加約束),并不考慮平臺上面運行什么軟件任務(wù),那么極端保守的做法就是選用CPU平臺。CPU平臺什么任務(wù)都能支持,但劣勢是性能是最差的,成本代價是最高的。一個系統(tǒng)并不都是應(yīng)用類型的任務(wù)。系統(tǒng)可以看作是很多工作任務(wù)的組合,這些工作任務(wù)都各有特點,我們可以針對任務(wù)的特點,把任務(wù)進行分類:
一個極端。在系統(tǒng)中,有很多非常確定性的任務(wù),比如虛擬化、網(wǎng)絡(luò)、存儲等,這些可以稱為基礎(chǔ)設(shè)施型任務(wù)。這類任務(wù)因為其確定性的特點,特別適合DSA和ASIC級別的加速處理器處理。
另一個極端,即不太好加速的應(yīng)用部分。在硬件平臺上到底會運行什么樣的應(yīng)用,通常是不可預(yù)知的,或者說應(yīng)用是非常不確定的。因此,針對應(yīng)用,最好是用CPU(+協(xié)處理器)平臺。CPU平臺還有另外一個價值,兜底,凡是無法加速或者不存在合適加速處理器的工作任務(wù)都可以放在CPU平臺處理。
處于兩個極端之間的部分任務(wù),則通常是性能敏感的應(yīng)用任務(wù),比如AI訓(xùn)練、視頻圖形處理、語音處理等。這類任務(wù)具有一定的確定性,但通常還是需要平臺的一些彈性的能力,其性能/靈活性特征處于前面兩個極端的中間。因此比較適合GPU、FPGA這樣的處理器平臺。
針對不同任務(wù)的靈活性/性能特征,把任務(wù)劃分到這三個層次,然后采取各自特征能力相符的處理器平臺,可以做到滿足整個系統(tǒng)最極致靈活性的同時,實現(xiàn)整個系統(tǒng)最極致的性能。
5.3 開放:讓處理器架構(gòu)和生態(tài)收斂,防止碎片化
 架構(gòu)(硬件的具體實現(xiàn)是微架構(gòu),而架構(gòu)指的是軟件看到的硬件架構(gòu)),也可以稱為軟硬件接口,是系統(tǒng)架構(gòu)中最核心的概念。
架構(gòu)(硬件的具體實現(xiàn)是微架構(gòu),而架構(gòu)指的是軟件看到的硬件架構(gòu)),也可以稱為軟硬件接口,是系統(tǒng)架構(gòu)中最核心的概念。
CPU目前有非常流行的RISC-v架構(gòu),RISC-v開放架構(gòu)的價值大家都能夠理解。從CPU到ASIC,越往右,處理器的子類型越多,架構(gòu)的數(shù)量也越多。不同類型、不同領(lǐng)域、不同場景、不同廠家、不同架構(gòu)的處理器,如果不加以約束的話,會導(dǎo)致處理器架構(gòu)的完全碎片化。越是處理器類型眾多,越需要全行業(yè)形成共識的開放架構(gòu)。
5.4 軟硬件深度融合,讓硬件具有更多軟件的能力
軟件越來越復(fù)雜,業(yè)務(wù)邏輯變化越來越快,具體的表現(xiàn)就是軟件開發(fā)者越來越崇尚敏捷開發(fā),兩個月一個小迭代,半年一個大迭代。同樣由于系統(tǒng)的復(fù)雜度提升,硬件卻與軟件相反,其開發(fā)難度越來越大,開發(fā)周期1-3年,生命周期5-8年。硬件的迭代周期完全跟不上軟件的更新節(jié)奏。因此,需要更進一步的系統(tǒng)架構(gòu)創(chuàng)新,把傳統(tǒng)的軟件層次的能力融入到硬件中去。這些能力包括功能的擴展性、資源的彈性和近乎無限的資源擴展、完全的硬件虛擬化、硬件高可用等等,通過這些能力來整體的提升硬件的靈活性。
超異構(gòu)計算,需要“軟硬件融合”來駕馭。
-
cpu
+關(guān)注
關(guān)注
68文章
10947瀏覽量
213895 -
異構(gòu)計算
+關(guān)注
關(guān)注
2文章
104瀏覽量
16403
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
淺析半導(dǎo)體激光器的發(fā)展趨勢
異構(gòu)計算的概念、核心、優(yōu)勢、挑戰(zhàn)及考慮因素
【一文看懂】什么是異構(gòu)計算?

未來物流發(fā)展趨勢與TMS的關(guān)系
邊緣計算的未來發(fā)展趨勢
云計算技術(shù)的未來發(fā)展趨勢
未來AI大模型的發(fā)展趨勢
變阻器的未來發(fā)展趨勢和前景如何?是否有替代品出現(xiàn)?
國產(chǎn)8位單片機在國內(nèi)的應(yīng)用情況及發(fā)展趨勢!
偉創(chuàng)力談制造業(yè)面臨的挑戰(zhàn)和發(fā)展趨勢
打造異構(gòu)計算新標桿!國數(shù)集聯(lián)發(fā)布首款CXL混合資源池參考設(shè)計

異構(gòu)計算:解鎖算力潛能的新途徑
工業(yè)物聯(lián)網(wǎng)之電梯物聯(lián)網(wǎng)行業(yè)發(fā)展趨勢及發(fā)展機遇風(fēng)險特征分析|梯云物聯(lián)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論