 AI推理芯片,比你想象難!
AI推理芯片,比你想象難!
來源:內容由半導體行業觀察(ID:icbank)編譯自semianalysis
AI 行業討論最多的部分是追求只能由大型科技公司開發的更大的語言模型。雖然訓練這些模型的成本很高,但在某些方面部署它們更加困難。事實上,OpenAI 的 GPT-4 非常龐大且計算密集,僅運行推理就需要多臺價值約 250,000 美元的服務器,每臺服務器配備 8 個 GPU、大量內存和大量高速網絡。谷歌對其全尺寸PaLM 模型采用了類似的方法,該模型需要 64 個 TPU 和 16 個 CPU 才能運行。Meta 2021 年最大推薦模型需要 128 個 GPU 來服務用戶。越來越強大的模型世界將繼續激增,尤其是在以 AI 為中心的云和 ML Ops 公司(如 MosaicML 協助企業開發和部署 LLM)的情況。
但更大并不總是更好。人工智能行業有一個完全不同的領域,它試圖拒絕大型計算機。圍繞可以在客戶端設備上運行的小型模型展開的開源運動可能是業界討論最多的第二部分。雖然 GPT-4 或完整 PaLM 規模的模型永遠不可能在筆記本電腦和智能手機上運行,但由于內存墻,即使硬件進步了 5 年以上,也有一個面向設備端的模型開發的系統推理。在本文中,我們將在筆記本電腦和手機等客戶端設備上討論這些較小的模型。本次討論將重點關注推理性能的門控因素、模型大小的基本限制,以及未來的硬件開發將如何在此建立開發邊界。為什么需要本地模型
設備上人工智能的潛在用例廣泛多樣。人們希望擺脫擁有所有數據的科技巨頭。Google、Meta、百度和字節跳動,AI 5 大領導者中的 4 家,其目前的全部盈利能力基本上都基于使用用戶數據來定向廣告。只要看看整個 IDFA 混戰,就可以看出缺乏隱私對這些公司來說有多重要。設備上的 AI 可以幫助解決這個問題,同時還可以通過針對每個用戶的獨特對齊和調整來增強功能。
為較小的語言模型提供上 一代大型模型的性能th是 AI 在過去幾個月中最重要的發展之一。
一個簡單、容易解決的例子是設備上的語音到文本。這是相當糟糕的,即使是目前一流的谷歌 Pixel 智能手機也是如此。轉到基于云的模型的延遲對于自然使用來說也非常刺耳,并且在很大程度上取決于良好的互聯網連接。隨著OpenAI Whisper等模型在移動設備上運行,設備上語音轉文本的世界正在迅速變化。(谷歌 IO 還表明這些功能可能很快就會得到大規模升級。)
一個更大的例子是 Siri、Alexa 等,作為個人助理非常糟糕。在自然語音合成 AI 的幫助下,大型語言模型可以解鎖更多可以為您的生活提供幫助的人類和智能 AI 助手。從創建日歷事件到總結對話再到搜索,每臺設備上都會有一個基于多模態語言模型的個人助理。這些模型已經比 Siri、Google Assistant、Alexa、Bixby 等功能強大得多,但我們仍處于早期階段。
在某些方面,生成式人工智能正迅速成為一種雙峰分布,具有大量的基礎模型和可以在客戶端設備上運行的小得多的模型,獲得了大部分投資,并且兩者之間存在巨大鴻溝。設備上推理的基本限制
雖然設備上人工智能的前景無疑是誘人的,但有一些基本的限制使得本地推理比大多數人預期的更具挑戰性。絕大多數客戶端設備沒有也永遠不會有專用 GPU,因此所有這些挑戰都必須在 SoC 上解決。主要問題之一是 GPT 樣式模型所需的大量內存占用和計算能力。計算要求雖然很高,但在未來 5 年內將通過更專業的架構、摩爾定律擴展到 3nm/2nm 以及芯片的 3D 堆疊來迅速解決。
由于英特爾、AMD、蘋果、谷歌、三星、高通和聯發科等公司正在進行的架構創新,最高端的客戶端移動設備將配備約 500 億個晶體管和超過足夠的 TFLOP/s 用于設備上的人工智能,需要明確的是,他們現有的客戶端 AI 加速器中沒有一個非常適合 Transformer,但這將在幾年內改變。芯片數字邏輯方面的這些進步將解決計算問題,但它們無法解決內存墻和數據重用的真正根本問題。
GPT 風格的模型被訓練為在給定先前標記的情況下預測下一個標記(~= 單詞)。要用它們生成文本,你需要給它提示,然后讓它預測下一個標記,然后將生成的標記附加到提示中,然后讓它預測下一個標記,然后繼續。為此,您必須在每次預測下一個標記時將所有參數從 RAM 發送到處理器。第一個問題是您必須將所有這些參數存儲在盡可能靠近計算的地方。另一個問題是您必須能夠在需要時準確地將這些參數從計算加載到芯片上。
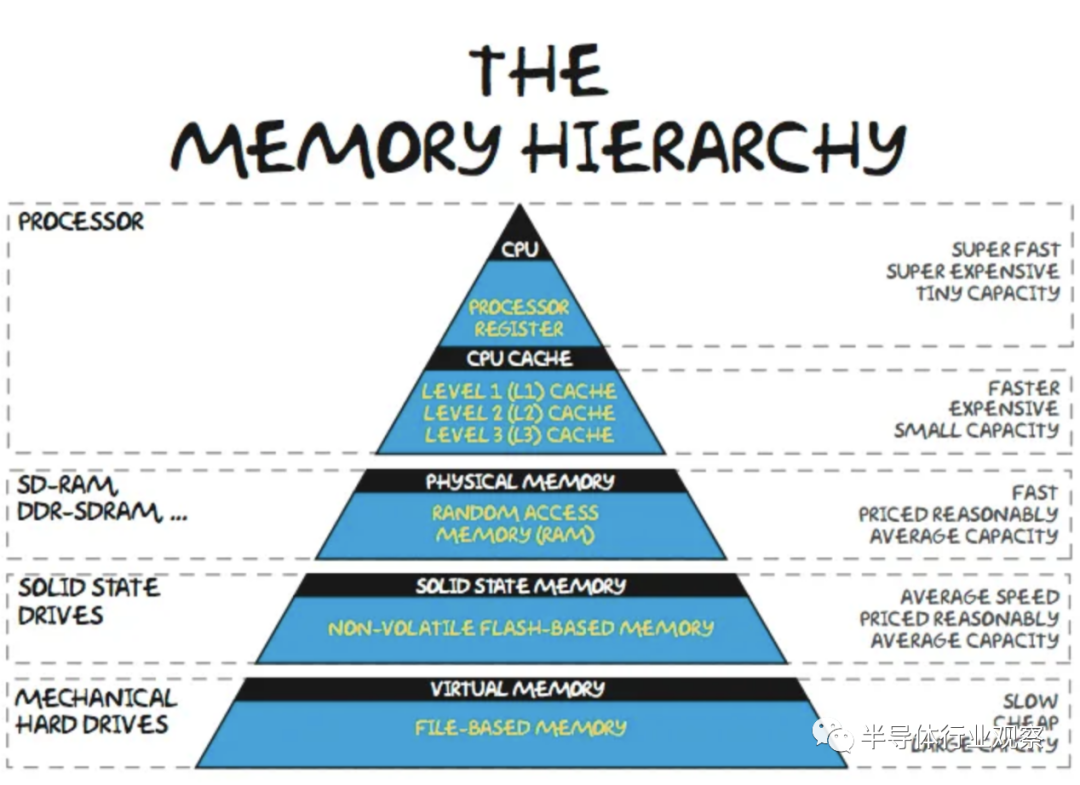
在內存層次結構中,在芯片上緩存頻繁訪問的數據在大多數工作負載中很常見。對于設備上的 LLM,這種方法的問題在于參數占用的內存空間太大而無法緩存。以 FP16 或 BF16 等 16 位數字格式存儲的參數為 2 個字節。即使是最小的“體面”通用大型語言模型也是 LLAMA,至少有 70 億個參數。較大的版本質量明顯更高。要簡單地運行此模型,需要至少 14GB 的內存(16 位精度)。雖然有多種技術可以減少內存容量,例如遷移學習、稀疏化和量化,但這些技術并不是免費的,而且會影響模型的準確性。
此外,這 14GB 忽略了其他應用程序、操作系統以及與激活/kv 緩存相關的其他開銷。這直接限制了開發人員可以用來部署設備上 AI 的模型大小,即使他們可以假設客戶端端點具有所需的計算能力。在客戶端處理器上存儲 14GB 的參數在物理上是不可能的。最常見的片上存儲器類型是 SRAM,即使在 TSMC 3nm 上,每 100mm^2 也只有約 0.6GB.
作為參考,這與即將推出的 iPhone 15 Pro 的 A17 芯片尺寸大致相同,比即將推出的 M3 小約 25%。此外,該圖沒有來自輔助電路、陣列低效、NOC 等的開銷。大量本地 SRAM 將無法用于客戶端推理。諸如 FeRAM 和 MRAM 之類的新興存儲器確實為隧道盡頭的曙光帶來了一些希望,但它們距離千兆字節規模的產品化還有很長的路要走。
層次結構的下一層是 DRAM。最高端的 iPhone 14 Pro Max 有 6GB 內存,但常用 iPhone 有 3GB 內存。雖然高端 PC 將擁有 16GB+,但大多數新銷售的 RAM 為 8GB。典型的客戶端設備無法運行量化為 FP16 的 70 億參數模型!
這就提出了問題。為什么我們不能在層次結構中再往下一層?我們能否在基于 NAND 的 SSD 而不是 RAM 上運行這些模型?
不幸的是,這太慢了。FP16 的 70 億參數模型需要 14GB/s 的 IO 才能將權重流式傳輸以生成 1 個token(~4 個字符)!最快的 PC 存儲驅動器最多為 6GB/s,但大多數手機和 PC 都低于 1GB/s。在 1GB/s 的情況下,在 4 位量化下,可以運行的最大模型仍將僅在約 20 億個參數的范圍內,這是在不考慮任何其他用途的情況下將 SSD 固定在最大值上僅用于 1 個應用案例。
除非你想在普通設備上等待 7 秒才能吐出半個字,否則將參數存儲在存儲器中不是一種選擇。它們必須在 RAM 中。
模型尺寸限制
一般人每分鐘閱讀約 250 個單詞。作為良好用戶體驗的下限,設備上的 AI 必須每秒生成 8.33 個tokens,或每 120 毫秒生成一次。熟練的速度讀者可以達到每分鐘 1,000 個單詞,因此對于上限,設備上的 AI 必須能夠每秒生成 33.3 個tokens,或每 30 毫秒一次。下表假定平均閱讀速度的下限,而不是速讀。
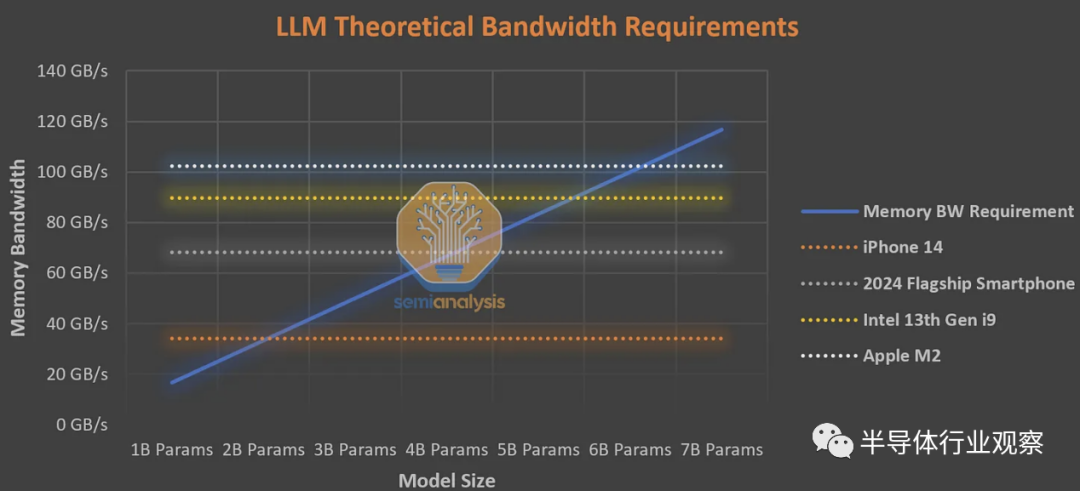
如果我們保守地假設正常的非 AI 應用程序以及激活/kv 緩存消耗所有帶寬的一半,那么 iPhone 14 上最大的可行模型大小是約 10 億個 FP16 參數,或約 40 億個 int4 參數。這是基于智能手機的 LLM 的基本限制。任何更大的產品都會排除很大一部分安裝基礎,以至于無法采用。
這是對本地 AI 可以變得多大和強大的基本限制。或許像蘋果這樣的公司可以利用它來追加銷售更新、更昂貴、配備更先進人工智能的手機,但這還有一段時間。根據與上述相同的假設,在 PC 上,英特爾的頂級第 13 代CPU 和蘋果的 M2 的上限約為 30 到 40 億個參數。
一般來說,這些只是消費設備的下限。重復一遍,我們忽略了多個因素,包括使用理論 IO 速度(這是從未達到過的)或為簡單起見激活/kv 緩存。這些只會進一步提高帶寬要求,并進一步限制模型尺寸。我們將在下面詳細討論明年將出現的創新硬件平臺,這些平臺可以幫助重塑格局,但內存墻限制了大多數當前和未來的設備。為什么服務器端 AI 獲勝
由于極端的內存容量和帶寬要求,生成式 AI比之前的任何其他應用程序更受內存墻的影響。在客戶端推理中,對于生成文本模型,批量大小(batch size)幾乎始終為 1。每個后續標記都需要輸入先前的標記/提示,這意味著每次從內存中將參數加載到芯片上時,您只需攤銷成本僅為 1 個生成的token加載參數。沒有其他用戶可以傳播這個瓶頸。內存墻也存在于服務器端計算中,但每次加載參數時,它都可以分攤到為多個用戶生成的多個tokens(批量大小:batch size)。
我們的數據顯示,HBM 內存的制造成本幾乎是服務器級 AI 芯片(如 H100 或 TPUv5)的一半。雖然客戶端計算確實可以使用便宜得多的 DDR 和 LPDDR 內存(每 GB 約 4 倍),但內存成本無法通過多個并發推理進行分攤。批量大小不能無限大,因為這會引入另一個難題,即任何單個token都必須等待所有其他token處理完畢,然后才能附加其結果并開始生成新token。
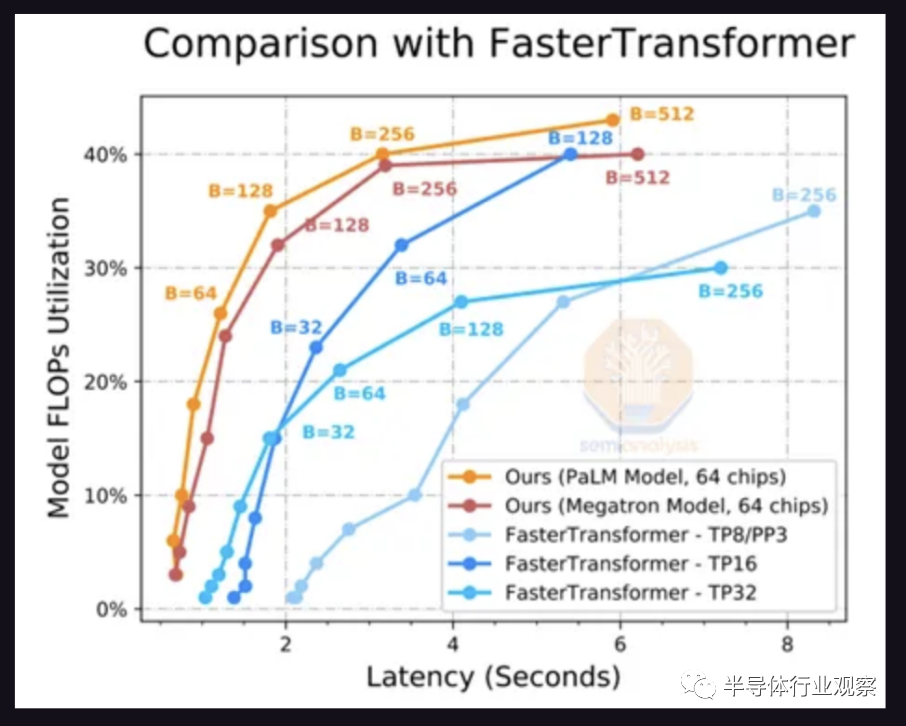
這是通過將模型拆分到多個芯片來解決的。上圖是生成 20 個token的延遲。方便的是,PaLM 模型達到每秒 6.67 個標記,或每分鐘約 200 個單詞的最小可行目標,其中 64 個芯片以 256 的批大小運行推理。這意味著每次加載參數時,它會用于 256 個不同的推論。
FLOPS 利用率隨著批處理大小的增加而提高,因為FLOPS ,內存墻正在得到緩解。只有將工作分配到更多芯片上,才能將延遲降低到一個合理的水平。即便如此,也只有 40% 的 FLOPS 被使用。谷歌展示了 76% 的 FLOPS 利用率,PaLM 推理的延遲為 85.2 秒,因此 so 內存墻顯然仍然是一個重要因素。
所以服務器端的效率要高得多,但是本地模型可以擴展到什么程度呢?
-
芯片
+關注
關注
455文章
50714瀏覽量
423131 -
AI
+關注
關注
87文章
30728瀏覽量
268880
發布評論請先 登錄
相關推薦
AI推理CPU當道,Arm驅動高效引擎

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

李開復:中國擅長打造經濟實惠的AI推理引擎
AMD助力HyperAccel開發全新AI推理服務器

如何基于OrangePi?AIpro開發AI推理應用


奕斯偉展示全球首款RISC-V邊緣計算芯片EIC7700X與高算力AI PC芯片
邊緣側AI芯片提供商超星未來完成數億元 Pre-B輪融資
AI推理,和訓練有什么不同?






 工商網監
工商網監
評論