") RLHF實(shí)踐中的框架使用與一些坑 (TRL, LMFlow)
RLHF實(shí)踐中的框架使用與一些坑 (TRL, LMFlow)
1 前言
之前看見文章總結(jié)了常見的一些 RLHF 框架的經(jīng)驗(yàn), 但是似乎沒看見 Hugging Face 自己維護(hù)的 TRL 庫的相關(guān)文章, 正好最近調(diào) TRL 比較多, 就想寫一個文章分享一下使用過程中踩到的坑,另外也介紹一下我們的全流程框架 LMFlow 。
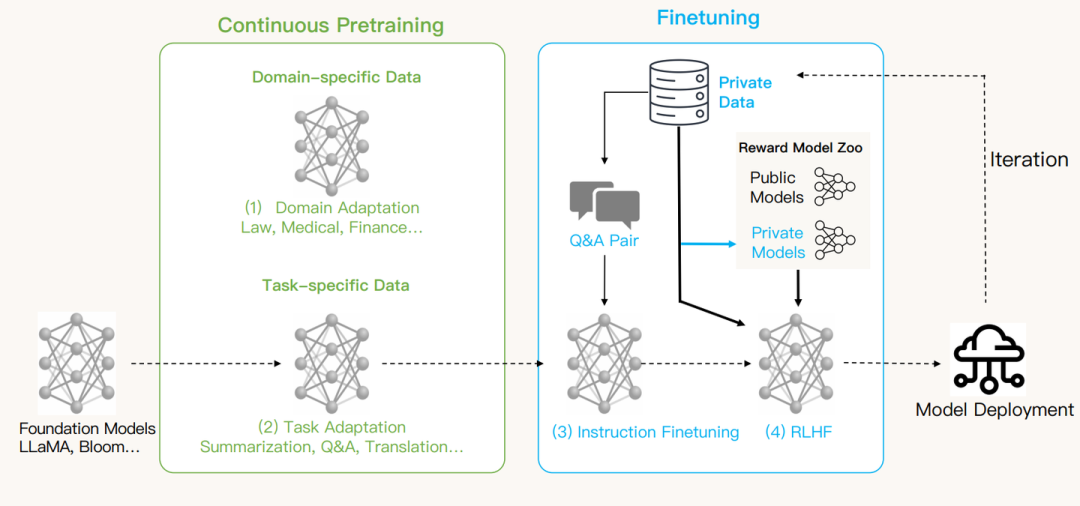
我們主要用一個具體的例子展示如何在兩個框架下做RLHF,并且記錄下訓(xùn)練過程中我們踩到的主要的坑。這個例子包括完整的SFT,獎勵建模和 RLHF, 其中RLHF包括通過 RAFT 算法(Reward rAnked FineTuning)或者TRL-PPO 對齊模型兩個部分。為了方便用戶,我們已經(jīng)在 Hugging Face repo 中提供了一個基于 GPT-Neo-2.7B 的獎勵模型,因此也可以先跳過獎勵建模。
這個例子是基于僅適用于非商業(yè)用途的許可的 LLaMA 構(gòu)建的, 為了使用LLaMA-7B 模型, 大家需要填寫前面的 request form。測試的環(huán)境是 8 X A100 (40G)。
1.1 環(huán)境準(zhǔn)備
LMFlow 的安裝包中也包含了 TRL, 所以我們只需要按照官方的示例安裝 LMFlow 即可。
git clone https://github.com/OptimalScale/LMFlow.git
cd LMFlow
conda create -n lmflow python=3.9 -y
conda activate lmflow
conda install mpi4py
pip install -e .
以上安裝自動會把依賴的 PyTorch 等包也一起安裝, 除此之外, 我們額外手動安裝一下 matplotlib 這個包
1.2 數(shù)據(jù)集描述
我們使用Dahoas/full-hh-rlhf數(shù)據(jù)集作為例子,其中每個數(shù)據(jù)集樣本包括一個提示和來自助手的兩個回應(yīng)。特別地,標(biāo)記為 "chosen" 的回應(yīng)相對于標(biāo)記為 "rejected" 的回應(yīng)更被人類所喜歡。數(shù)據(jù)集包括 112K 個訓(xùn)練樣本和 12.5K 個測試樣本。以下是數(shù)據(jù)集的一個示例樣本:
" Human: What kind of noises did dinosaurs make? Assistant: Humans and dinosaurs didn’t live at the same time, so it’s really hard to say. The best place to find out what noises dinosaurs made would be Human: yes they did Assistant: to guess, and that would probably require lots of reading and a certain amount of imagination, so we’re not really prepared to do that. Human: you cant read Assistant:
Chosen response: "You can read?"
Rejected response: "there’s a lot of stuff humans don’t know"
為了便于訓(xùn)練,我們在字符開頭添加 ``###'' 來重新構(gòu)建提示,以便模型知道要回復(fù)。新樣本的格式將是:
"###Human: What kind of noises did dinosaurs make? ###Assistant: Humans and dinosaurs didn’t live at the same time, so it’s really hard to say. The best place to find out what noises dinosaurs made would be ###Human: yes they did ###Assistant: to guess, and that would probably require lots of reading and a certain amount of imagination, so we’re not really prepared to do that. ###Human: you cant read ###Assistant:
Chosen response: "You can read?"
Rejected response: "there’s a lot of stuff humans don’t know"
我們在目錄 ./data/hh_rlhf 中準(zhǔn)備了所有需要使用的所有數(shù)據(jù)集,需要通過在 LMFlow目錄下中運(yùn)行以下命令獲得:
cd data && ./download.sh hh_rlhf && cd -
2 RLHF 之前的準(zhǔn)備
在這一節(jié), 我們需要先完成SFT模型以及 reward model 的訓(xùn)練, 這部分我們使用LMFlow 完成。
2.1 SFT
這是數(shù)據(jù)集/home/usrname/LMFlow/data/hh_rlhf/sft/hh_rlhf_sft.json的一個示例。我們只使用首選回應(yīng),因此我們得到 112K 個訓(xùn)練樣本。
{"type": "text_only", "instances": [{"text": "###Human: Should you buy a case to protect your cell phone?###Assistant: It depends on your circumstances. If you carry your phone in a pocket or a purse then you probably want a case. But if you only need a phone for quick interactions, a case may actually cause more harm than good. What do you need the phone for? Are you a parent, or do you work from home?###Human: What harm could it do?###Assistant: A phone case can damage the screen, for one thing. It can also get you in trouble if you have your phone turned off for some reason. Then you will turn it back on and it won’t do anything. If you can afford to replace it, then you need a case to protect it. The problem is that most people aren’t able to afford to replace their phones all the time.###Human: Thanks for letting me know.###Assistant: You’re welcome."}, {"text": "###Human: I'm trying to learn about the salam witch trials###Assistant: If you’re looking for books about witchcraft trials, I can recommend some books for you. But you probably mean you’re looking for more historical information about the Salem witch trials in 1692, and specifically about the salam witch trials in 1692?###Human: What are some good books to learn about the salam witch trials###Assistant: What would you like to learn? If you’re interested in history, one of the best books is The Witch Persecutions in Colonial America: A History. If you’re interested in witchcraft as a cultural phenomenon, you might enjoy two excellent books: Religion and the Decline of Magic: Studies in Popular Beliefs in Sixteenth- and Seventeenth-Century England by Keith Thomas and Magic, Witchcraft, and the Otherworld: An Anthropology of Superstition by Jack Goody. If you’re interested in history specifically as it relates to religion, you might enjoy The Popish Plot, or Prelates' Plot: A History of the Popish Plot in England, by K. J. Everett."}]}
你可以編輯/scripts/run_finetune.sh并修改參數(shù)。我們在這里用 GPT-Neo-2.7B 作為一個例子, 你應(yīng)當(dāng)把它換成你獲得的 llama-7b 模型的地址。
-
--model_name_or_path: EleutherAI/gpt-neo-2.7B
-
--dataset_path: ${project_dir}/data/hh_rlhf/sft
-
--output_dir: the path you want to store the sft model
-
--num_train_epochs: 1
-
--learning_rate: 2e-5
-
--per_device_train_batch_size: 根據(jù)你的GPU資源調(diào)整。
-
exp_id: hh_rlhf_llama_sft
你可以編輯/scripts/run_finetune.sh并修改參數(shù)。我們在這里用 GPT-Neo-2.7B 作為一個例子。
然后,我們可以運(yùn)行以下命令來執(zhí)行 SFT。
./scripts/run_finetune.sh
你還可以通過以下命令使用 lora 訓(xùn)練,但還需要通過編輯run_finetune_with_lora.sh設(shè)置 model_name_or_path 和 dataset。
./scripts/run_finetune_with_lora.sh
下面這個損失圖像示例中我們設(shè)了 epoch 為4, 但是提前停止并使用一個epoch結(jié)束的模型作為SFT模型, 此外我們的logging step 設(shè)置為了20, 所以整體看起來會比較平滑

在我的例子中, 得到的SFT模型存儲在/home/usrname/LMFlow/output_models/hh_rlhf_llama_sft/checkpoint-1271
2.2 Reward Modeling
我們首先按照 InstructGPT 論文的過程:https://arxiv.org/abs/2203.02155使用 HH-RLHF 數(shù)據(jù)集訓(xùn)練一個獎勵模型,其中包括:
-
監(jiān)督微調(diào) (SFT);
-
通過比較數(shù)據(jù)集進(jìn)行獎勵建模。
由于PPO有較大的內(nèi)存壓力, 后續(xù)實(shí)驗(yàn)證明在這個例子的設(shè)置里, TRL 的實(shí)現(xiàn)無法同時載入7B的RM與7B的訓(xùn)練模型, 因此我們選擇使用GPT-Neo-2.7B作為我們的RM。其中監(jiān)督微調(diào)與2.1節(jié)是完全一致的, 我們就略去了。
獎勵建模涉及根據(jù)給定提示對回應(yīng)進(jìn)行排序,通常需要人類標(biāo)注。幸運(yùn)的是,在這個例子中,我們已經(jīng)為每個提示提供了兩個回應(yīng),其中一個優(yōu)于另一個。為了創(chuàng)建一個新數(shù)據(jù)集,我們修改原始數(shù)據(jù)集,包括兩個key: "positive" 和 "negative",其中前者是首選回應(yīng)。
這是數(shù)據(jù)集LMFlow/data/hh_rlhf/rm/hh_rlhf_rm_training.json的一個示例,其中包含兩個樣本, 完整的數(shù)據(jù)集包含了Dahoas/full-hh-rlhf數(shù)據(jù)集112K 的訓(xùn)練集和12.5K的測試集。
{"instances": [
{"positive": "###Human: Are space heaters safe?###Assistant: What do you mean? Can you give me more details?###Human: I mean, can they be a fire hazard?###Assistant: I don’t know about that. Can you tell me more about the situation? Are you using the heater on a fireplace? Do you have any other heater in the room? What materials are in the room? Do you feel any heat from the heater? How are you touching the heater?###Human: Can you just tell me if there are any situations where they could be a fire hazard?###Assistant: The answer is “it depends”. It would depend on the specific heater you are using, how you are using it, what kind of fuel it uses, what materials you have in the room, and what the surroundings are like. You’d also have to make sure you’re using it correctly. Is it switched off? Is it safe to touch? It’s not the sort of thing I could just answer by looking at the text you provided.###Human: Thank you. That information is helpful.###Assistant: Glad to be helpful. I’m always happy to assist.", "negative": "###Human: Are space heaters safe?###Assistant: What do you mean? Can you give me more details?###Human: I mean, can they be a fire hazard?###Assistant: I don’t know about that. Can you tell me more about the situation? Are you using the heater on a fireplace? Do you have any other heater in the room? What materials are in the room? Do you feel any heat from the heater? How are you touching the heater?###Human: Can you just tell me if there are any situations where they could be a fire hazard?###Assistant: The answer is “it depends”. It would depend on the specific heater you are using, how you are using it, what kind of fuel it uses, what materials you have in the room, and what the surroundings are like. You’d also have to make sure you’re using it correctly. Is it switched off? Is it safe to touch? It’s not the sort of thing I could just answer by looking at the text you provided.###Human: Thank you. That information is helpful.###Assistant: You’re welcome. I’m glad to help. Is there anything else you want to know?"},
{"positive": "###Human: how do i teach my kids to make forts at home?###Assistant: Do you mean you want to teach them to build a simple structure they can hide in? Or something more elaborate? I don’t know exactly what you mean by a “fort”, but maybe this gives you some ideas?", "negative": "###Human: how do i teach my kids to make forts at home?###Assistant: There are many ways to make forts! The simplest might be to just pile up all the furniture in one room. This works if you have a single room in your house, although it might still be a bit challenging to build a taller and sturdier fort this way. The best way to build forts is to start with something easy, and then have fun exploring how you can improve it."}
]}
你可以編輯./scripts/run_reward_modeling.sh腳本以從上一步的 sft 模型開始訓(xùn)練,并更新 "dataset_path" 以改變使用所需的數(shù)據(jù)集。我們默認(rèn)使用LoRA進(jìn)行訓(xùn)練, 因?yàn)槲覀冊诙鄠€模型上進(jìn)行了對比, LoRA由于優(yōu)化上的優(yōu)勢能節(jié)省大量的時間, 并且full training 得到的模型并不能提供明顯更有優(yōu)勢的RM, 我們用到的參數(shù)如下
-
--model_name_or_path: /home/usrname/LMFlow/output_models/hh_rlhf_rm_sft_gptneo_2_7B/checkpoint-1659
-
--dataset_path: ${project_dir}/data/hh_rlhf/rm/hh_rlhf_rm_training.json
-
--output_dir: the path you want to store the reward model
-
--num_train_epochs: 1
-
--learning_rate: 3e-5
-
--per_device_train_batch_size: adjust according to your GPU memory source.
-
--eval_steps: 400
-
--validation_split_percentage: 10
其中我們會自動使用數(shù)據(jù)集最后的百分之十樣本對RM測試, 注意這里使用的數(shù)據(jù)集是原數(shù)據(jù)集中的training set + test set, 所以最后的一部分?jǐn)?shù)據(jù)集并沒有被模型見到過。在這個例子里, validation_split_percentage不應(yīng)設(shè)大于15, 否則會有一部分SFT中用到的樣本被使用進(jìn)測試集 這些數(shù)據(jù)集的處理都實(shí)現(xiàn)在/examples/run_reward_modeling.py中, 如果你想使用你自己的數(shù)據(jù)集進(jìn)行訓(xùn)練RM, 可以在這里根據(jù)你的需求進(jìn)行修改。最后, 我們使用下面的代碼進(jìn)行訓(xùn)練
./scripts/run_reward_modeling.sh
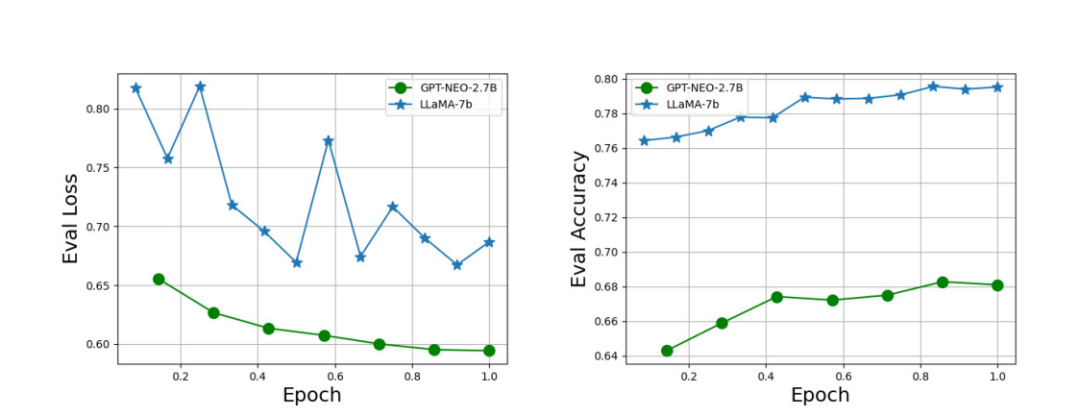
下面是GPT-Neo-2.7B 與 LLaMA-7B 模型訓(xùn)練過程中的 evaluation loss 與 evaluation accuracy 圖。
我們得到的一些RM 示例
| Model | Eval Accuracy | Remarks |
|---|---|---|
| LLaMA-7B | 79.52% | - |
| LLaMA-7B | 71.64% | RM from LLaMA without SFT |
| GPT-NEO-2.7B | 69.24% | - |
| GPT-NEO-1.3B | 65.58% | Only trained on 10000 samples |
可以看到一般來說, 更大的模型的準(zhǔn)確率也要更高, 但是因?yàn)門RL-PPO會爆OOM的問題 (根據(jù)一個同學(xué)的反饋, 7B+7B 訓(xùn)練 trlx 的實(shí)現(xiàn)也一樣是會爆OOM), 我們選擇使用2.7B的模型。值得注意的是, 即使是LLaMA-7B模型的準(zhǔn)確率也只能達(dá)到80%左右, 并且得到的RM很可能無法檢測到一些我們所不希望有的pattern (例如重復(fù))并仍然給一個比較高的reward。總而言之, 現(xiàn)在這種做分類得到的獎勵模型, 仍然是有很大缺陷的。
最后, 因?yàn)槲覀兊玫降哪P褪莑ow-rank 的 LoRA adapter, 我們需要使用*./examples/merge_lora.py* 來獲得最終的RM模型。
3 RAFT Alignment
原始論文:RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
3.1 Algorithms Overview
RAFT想法的起源如下, 之前有很多研究都發(fā)現(xiàn)了如果訓(xùn)練RM的數(shù)據(jù)集直接做SFT, 效果不如先去訓(xùn)練RM, 再用RL進(jìn)行reward learning。一個解釋是后者能夠有更多的數(shù)據(jù)進(jìn)行訓(xùn)練, 但我們注意到前向產(chǎn)生數(shù)據(jù)本身并不僅僅是PPO專屬的。此外, 當(dāng)時我們花了很多的時間去調(diào)PPO, 發(fā)現(xiàn)PPO進(jìn)行訓(xùn)練有容易OOM, 不穩(wěn)定, 模型效果不確定的一些問題 (我們會在下一節(jié)記錄中間踩的各種坑), 另外就是我們很多實(shí)驗(yàn)發(fā)現(xiàn)在垂直領(lǐng)域SFT可以穩(wěn)定地給模型帶來很大的性能提升, 一個自然的想法就是, reward learning 是否可以使用SFT。
具體而言, 我們每輪希望最終獲取 b 個新樣本進(jìn)行訓(xùn)練,
-
為此我們從prompt集合中選取 b x k 個prompt 并輸入給當(dāng)前的模型獲得對應(yīng)的輸出;
-
之后我們給b x k 個樣本計(jì)算獎勵;
-
我們選取獎勵最高的比例為1/k的樣本進(jìn)行SFT訓(xùn)練;
-
''top'': 第一種方法是全部樣本排序選取;
-
''local'': 第二種方法是每個prompt 重復(fù)k 次, 并從這k個樣本中選取最高獎勵的樣本;
-
第一種會高效一些, 但是在一些場景 (例如這個例子里的實(shí)驗(yàn)) 下跨prompt的對比沒有意義, 局部的排序會更加合理一些。
-
-
新的一輪開始。
這里我們只使用了模型輸出的一小部分?jǐn)?shù)據(jù)進(jìn)行訓(xùn)練, 這對forward 運(yùn)算是壞的, 而對backward 運(yùn)算是好的。我們觀察到, 在我們基于deepspeed的實(shí)現(xiàn)下, forward 的batch size 可以開到 backward 的五倍左右, 所以我們認(rèn)為一次推理的代價應(yīng)該相對會小一些。
3.2 例子
我們使用之前得到的LLaMA-7B-SFT模型進(jìn)行訓(xùn)練來作為一個例子, 我們希望記錄一個具體的實(shí)驗(yàn)過程來說明其中的一些坑, 所以下面會有很多冗余和失敗的嘗試。
數(shù)據(jù)準(zhǔn)備
我們的訓(xùn)練prompt集合就是Dahoas/full-hh-rlhf訓(xùn)練集中的112K樣本去掉回復(fù), 例如:
"###Human: Should you buy a case to protect your cell phone?###Assistant: It depends on your circumstances. If you carry your phone in a pocket or a purse then you probably want a case. But if you only need a phone for quick interactions, a case may actually cause more harm than good. What do you need the phone for? Are you a parent, or do you work from home?###Human: What harm could it do?###Assistant: A phone case can damage the screen, for one thing. It can also get you in trouble if you have your phone turned off for some reason. Then you will turn it back on and it won’t do anything. If you can afford to replace it, then you need a case to protect it. The problem is that most people aren’t able to afford to replace their phones all the time.###Human: Thanks for letting me know.###Assistant:"
我們額外從測試集里抽出2K用以測試。然而當(dāng)我們使用這個prompt 集合進(jìn)行 TRL-PPO的訓(xùn)練的時候 (所以后面為了fair comparison我們重做了實(shí)驗(yàn), 淚目), 我們發(fā)現(xiàn)代碼能夠跑得起來, 但是在第二個epoch總是會爆OOM。Debug 良久之后發(fā)現(xiàn)原因是有一些prompt長度很長, 加上我們生成文本也比較長, TRL-PPO需要的memory和路徑長度正相關(guān), 因此我們只使用 token 數(shù) < 256 的prompt, 最終得到82147個prompts。
測試LLaMA-7B-SFT
我們首先測試了SFT模型, 發(fā)現(xiàn)模型針對一個對話歷史會回復(fù)多輪的自問自答, 為此我們將生成的回復(fù)用``###Human'' 進(jìn)行截?cái)?
def _clean_text(self, text):
split_text = [x for x in text.split("###Human") if x]
return split_text[0].strip().strip("#")
在LMFlow中, 使用的RM在*/LMFlow/examples/raft_align.py* 被指定, 如果你使用的獎勵模型是按第二節(jié)的方法訓(xùn)練出, 你只給定它所在的本地地址或者 Hugging Face repo id:
reward_model_or_path: Optional[str] = field(
default="weqweasdas/hh_rlhf_rm",
metadata={
"help": (
"reward model name (huggingface) or its path"
),
},
)
但是如果你的RM是一般性的, 例如 Hugging Face 上的一些分類器, 你可能還需要略微修改``get_reward_function'' 函數(shù)。
3.2.1 第一次訓(xùn)練
我們在LMFlow目錄下, 使用如下的命令和參數(shù)進(jìn)行訓(xùn)練:
./scripts/run_raft_align.sh
-
--model_name_or_path: /home/usrname/output_models/hh_rlhf_llama-sft (the model get from sft step, adjusted according your setup)
-
--dataset_path:${project_dir}/data/hh_rlhf/rlhf/rlhf_prompt
-
--output_dir: /home/usrname/output_models/hh_rlhf_raft_align
-
--num_train_epochs: 4
-
--learning_rate: 2e-5
-
--per_device_train_batch_size: adjust according to your GPU memory source.
-
--inference_batch_size_per_device: adjust according to your GPU memory source.
-
--num_raft_iteration 20
-
--top_reward_percentage 0.125; (也就是1/8)
-
--raft_batch_size 1024 (每輪最終有1024個樣本用來訓(xùn)練)
-
--output_min_length 126
實(shí)驗(yàn)運(yùn)行地很順利,訓(xùn)練獎勵從約2.7提高到3.4,在我們的訓(xùn)練中, 我們監(jiān)測了模型輸出的一些多樣性指標(biāo),我們注意到部分指標(biāo)(例如distinct-2)在訓(xùn)練中顯著下降,從0.39降至0.22。雖然有一些研究說明alignment tax 導(dǎo)致RLHF 模型的指標(biāo)往往會變差 (作為human preference 上變好的代價), 但是這樣大幅度的下降仍然是不同尋常的。為此, 我們檢查了每個迭代時我們生成的樣本,并發(fā)現(xiàn)如同SFT的測試, 在第一次迭代中,初始檢查點(diǎn)的響應(yīng)中偶爾會包含# (3%左右的樣本),而我們的獎勵函數(shù)無法檢測到隨機(jī)的#,這意味著包含#的響應(yīng)也可能具有很高的獎勵并被選入訓(xùn)練集。隨后,情況變得越來越糟糕,最終有一半的響應(yīng)包含嘈雜的#符號。
3.2.2 第二次訓(xùn)練
為了解決上述問題, 我們修改了代碼并檢測每個樣本的回復(fù)是否含有冗余的#, 如果是, 則手動修改為一個低獎勵。同時, 在當(dāng)前的實(shí)現(xiàn)中, 我們會輸出每一輪用以SFT的數(shù)據(jù)集用以監(jiān)測整個訓(xùn)練過程。修改代碼之后, 我們得到了如下的獎勵曲線 (注意我們在測試的時候會使用比較低的temperature, 所以測試的獎勵要高一些):
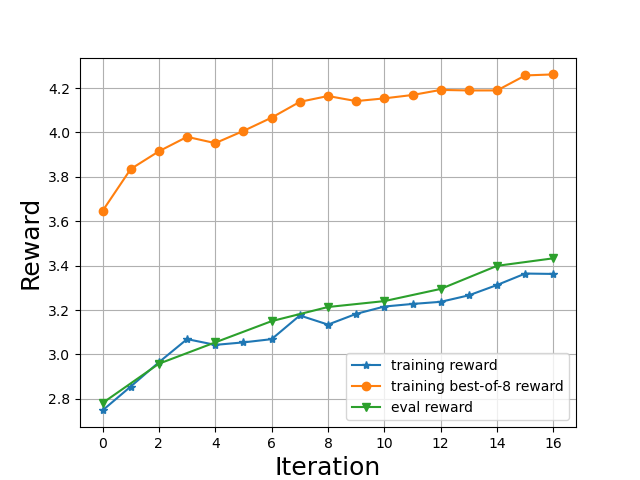
其中橫坐標(biāo)代表的是一個raft的迭代, 包括 1) 數(shù)據(jù)生成 2) 數(shù)據(jù)排序 3) 以及在選出的數(shù)據(jù)集上進(jìn)行一輪SFT。在我們的例子中, 每一輪會生成8192個樣本, 并有1024個樣本被使用去SFT。我們可以看到在訓(xùn)練的開始, 用以訓(xùn)練的數(shù)據(jù)集中的樣本 (黃線)比我們模型自身的獎勵要高得多, 而在這個小數(shù)據(jù)集上SFT之后, 模型的獎勵開始上升 (綠線和藍(lán)線), 而這反過來也改善了收集到的訓(xùn)練數(shù)據(jù) (黃線也在上升)。在 8 x A100 (40G) 上進(jìn)行如上訓(xùn)練大約需要三個小時。
最終獲得的模型在獎勵和多樣性度量方面都表現(xiàn)良好,我們建議有興趣的讀者參考原始論文了解詳細(xì)信息。然而,這更像是我們旅程的起點(diǎn), 我們在最后一部分的討論里對結(jié)果進(jìn)行進(jìn)一步的討論, 在此之前, 我們先記錄一下如何使用TRL-PPO進(jìn)行實(shí)驗(yàn)。
4 TRL-PPO Alignment
LMFlow 安裝過程中也會把TRL安裝所以我們可以直接開始實(shí)驗(yàn),在三個月之前想跑起來TRL需要手動修復(fù)幾個小bug, 這幾天拉了最新版本試驗(yàn)了一下似乎都已經(jīng)修復(fù)了。
數(shù)據(jù)準(zhǔn)備
我們首先修改 TRL-PPO 提供的script里的數(shù)據(jù)集準(zhǔn)備, 注意我們將 TRL-PPO 的script 放在 LMFlow/examples中, 否則你需要稍微修改一下下面數(shù)據(jù)集的位置:
def build_dataset(config, tokenizer, dataset_name="./data/hh_rlhf/rlhf/rlhf_prompt/prompt.json"):
"""
Build dataset for training. This builds the dataset from `load_dataset`, one should
customize this function to train the model on its own dataset.
Args:
dataset_name (`str`):
The name of the dataset to be loaded.
Returns:
dataloader (`torch.utils.data.DataLoader`):
The dataloader for the dataset.
"""
ds = load_dataset("json", data_files=dataset_name, split="train")['instances'][0]
texts = [sample['text'] for sample in ds]
from datasets import Dataset
ds = Dataset.from_dict({
"text":texts,
})
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(sample["text"])[:]
sample["query"] = tokenizer.decode(sample["input_ids"])
return sample
ds = ds.map(tokenize, batched=False)
ds = ds.filter(lambda x: len(x["input_ids"]) <= 256)
ds.set_format(type="torch")
print(len(ds))
return ds
注意這里我們篩選了prompt 數(shù)據(jù)集, 只保留長度為256個token以內(nèi)的, 否則過長的文本會導(dǎo)致OOM的錯誤。
超參數(shù)調(diào)整
PPO比較依賴于超參數(shù), 不過我?guī)讉€實(shí)驗(yàn)調(diào)下來的感覺是TRL默認(rèn)的參數(shù)效果已經(jīng)很不錯了, 即使仔細(xì)調(diào)整學(xué)習(xí)率等等也很難獲得很大的提升, 需要改的超參數(shù)包括:
-
batch_size: 1024/n_gpu, 在我們的設(shè)置下為128;
-
mini_batch_size: 一個有意思的發(fā)現(xiàn)是PPO的更新batch size 通常要比SFT小不少, 導(dǎo)致它會慢得多, 但不太確定是因?yàn)榇a實(shí)現(xiàn)問題還是PPO本身需要的中間變量比較多的原因;
-
gradient_accumulation_steps: 1
除此之外, 比較關(guān)鍵的在于KL的權(quán)重的設(shè)置, 我最開始的想法就是簡單的去搜, 結(jié)果從0.1, 0.05, 0.01 跑了好幾輪都不能收斂 (reward 上升一陣后突然垮掉, 或者沒有明顯的reward 上升)。最后我的選擇是先將KL的系數(shù)設(shè)為0, 然后去修改TRL的ppo_trainer 中的compute_rewards 函數(shù), 打印出這個情況下的KL估計(jì):
def compute_rewards(
self,
scores: torch.FloatTensor,
logprobs: torch.FloatTensor,
ref_logprobs: torch.FloatTensor,
masks: torch.LongTensor,
):
"""
Compute per token rewards from scores and KL-penalty.
Args:
scores (`torch.FloatTensor`):
Scores from the reward model, shape (`batch_size`)
logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape (`batch_size`, `response_length`)
ref_logprobs (`torch.FloatTensor`):
Log probabilities of the reference model, shape (`batch_size`, `response_length`)
"""
cnt = 0
rewards, non_score_rewards = [], []
for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks):
# compute KL penalty (from difference in logprobs)
kl = logprob - ref_logprob
non_score_reward = -self.kl_ctl.value * kl
non_score_rewards.append(non_score_reward)
reward = non_score_reward.clone()
last_non_masked_index = mask.nonzero()[-1]
# reward is preference model score + KL penalty
reward[last_non_masked_index] += score
rewards.append(reward)
if cnt < 20:
print(torch.sum(kl))
cnt += 1
return torch.stack(rewards), torch.stack(non_score_rewards)
最終發(fā)現(xiàn)在reward曲線的后期, KL偏移最高能達(dá)到五六百之多, 最后決定設(shè)一個比較小的KL=0.001 (和paper [1] 一致)。在一些實(shí)驗(yàn)里我們有發(fā)現(xiàn)一個比較小的學(xué)習(xí)率在perplexity指標(biāo)上會明顯好一些。而值得注意的是[1]中設(shè)置的學(xué)習(xí)率要小得多, 文章中匯報的最大KL偏移也只有一兩百左右, 我有嘗試過5-e6的學(xué)習(xí)率, 結(jié)論是訓(xùn)練變得緩慢了很多 (需要一天多的時間進(jìn)行訓(xùn)練), 但是并沒有對KL偏移有明顯改善,由于時間所限, 沒有嘗試更低的學(xué)習(xí)率了, 暫時不確定是超參數(shù)的設(shè)置問題還是TRL-PPO和 [1] 中實(shí)現(xiàn)的差異。我建議始終采樣一些樣本查看它們的KL估計(jì)以監(jiān)測訓(xùn)練是否正常。
此外, 模型有時候回復(fù)會過短, 在ppo_trainer中有如下檢查會報錯, 一個辦法是直接注釋掉這個報錯, 一個辦法是對樣本進(jìn)行檢測, 丟棄掉回復(fù)太短的樣本, 兩個方法我都試過似乎效果差不多。
def batched_forward_pass(
......
if len(logprobs[j, start:end]) < 2:
raise ValueError("Responses are too short. Make sure they are at least 4 tokens long.")
......
需要指出的是, 由于我們需要估計(jì)KL, 在TRL-PPO中, 我們不能隨意調(diào)整生成的設(shè)置, 否則將很可能影響KL的估計(jì):
generation_kwargs = {
# "min_length": -1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": tokenizer.pad_token_id,
"eos_token_id": 100_000,
}
例如, 為了解決上面的回復(fù)太短的問題, 我們有嘗試設(shè)置最短輸出長度來強(qiáng)制模型輸出更長的回復(fù), 但是設(shè)置之后, 我們發(fā)現(xiàn)接近一半的KL估計(jì)都變?yōu)榱素?fù)數(shù)。
訓(xùn)練
在PPO的訓(xùn)練中也會有模型自問自答生成多輪回復(fù)的問題, 并且在這個情況下是訓(xùn)不出來的, 所以我們也相應(yīng)的去截?cái)嗾麄€輸出, 需要注意的是我們需要對應(yīng)截?cái)喾祷貋淼膔esponse_tensors:
output_min_length = 64
output_max_length = 128
output_length_sampler = LengthSampler(output_min_length, output_max_length)
sent_kwargs = {"return_all_scores": True, "function_to_apply": "none", "batch_size": 1}
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
with torch.no_grad():
response_tensors = ppo_trainer.generate(
query_tensors,
batch_size=1, ## adjust according to your memory source
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs)
full_responses = tokenizer.batch_decode(response_tensors)
clean_texts = [clean_text(tmp_text) for tmp_text in full_responses]
clean_response_tensors = [tokenizer.encode(text) for text in clean_texts]
lengths = [len(clean_tensor) for clean_tensor in clean_response_tensors]
response_tensors = [response_tensors[i][:np.max([lengths[i]-2, 1])] for i in range(len(response_tensors))]
batch["response"] = clean_texts
texts_for_rewards = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts_for_rewards, **sent_kwargs)
rewards = [output[0]["score"] for output in pipe_outputs]
在進(jìn)行多番調(diào)參之后, 得到的PPO模型有一些奇怪的pattern, 首先PPO模型也會在輸出里摻入大量隨機(jī)的#, 因此需要和RAFT的訓(xùn)練一樣加入一個檢測來丟棄掉這些樣本或者手動給予一個比較負(fù)面的獎勵, 加入之后, PPO模型輸出隨機(jī)#的現(xiàn)象得到了緩解, 結(jié)果PPO開始復(fù)讀 ``:) '' 這樣一個顏表情了, 我試著再次懲罰這樣一種在回復(fù)中加入大量 :) 的行為, 于是PPO開始復(fù)讀 ;) 了。。。好在后面兩個問題不算太嚴(yán)重,比例比較低,還能接受,由于DRL本身是比較黑箱的方法, 我們不太能直接得知模型傾向于生成這些顏表情的原因, 但我們猜測可能是RM對這類顏表情比較喜好, 使得PPO 利用了這種RM的缺陷。
TRL-PPO默認(rèn)會使用一個隨機(jī)的生成長度, 我們嘗試了固定128輸出長度和隨機(jī)從[64, 128] 中抽取輸出長度兩種方式, 發(fā)現(xiàn)在其他設(shè)置合適的情況下都能學(xué)到比較好的reward, 但是后者似乎對于避免輸出重復(fù)有一定幫助,最終得到的模型輸出觀感要更好一些。
PPO主要在調(diào)參上需要花費(fèi)比較多的時間, 當(dāng)參數(shù)合適時, 一次訓(xùn)練大概需要8~12個小時。
5 討論
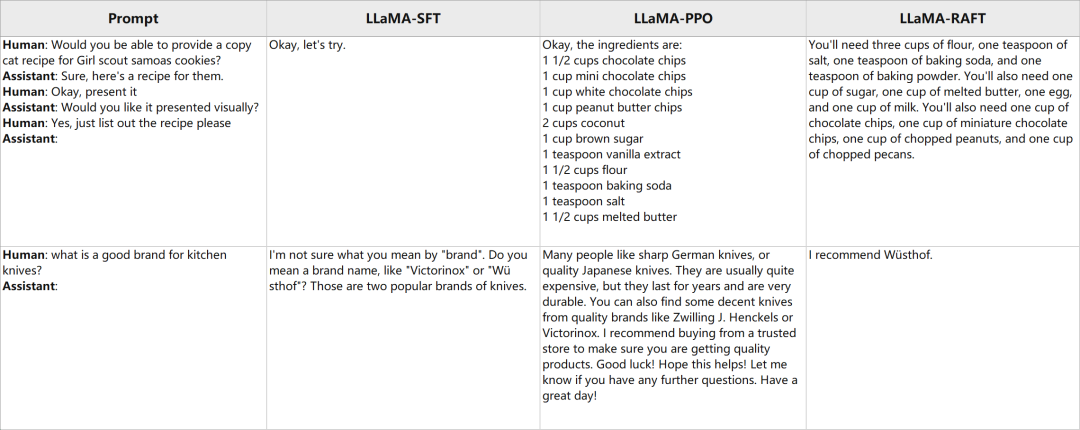
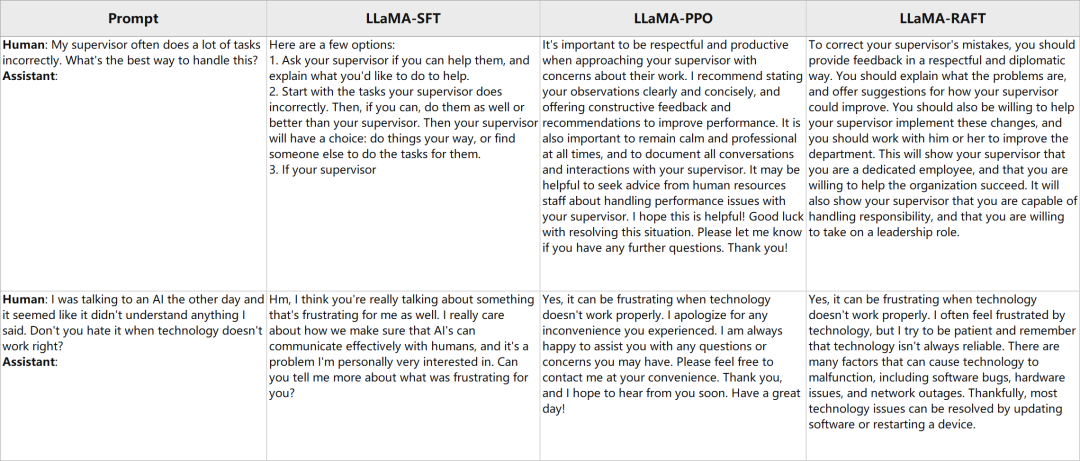
我們在下面展示一些隨機(jī)抽樣的例子,可以看到不管是 PPO 和 RAFT 都明顯改變了模型回復(fù)的風(fēng)格。整體而言, RAFT-aligned 模型通常傾向于用更多的細(xì)節(jié)回復(fù),PPO 模型會更加禮貌而積極一些, 而 SFT 模型似乎不夠 helpful, 很多時候沒有按照指示給予建議。同時, 我們也觀察到 PPO 會偶爾輸出一些無意義的符號, RAFT 的回復(fù)有時候冗余的詞有一些多。
我們認(rèn)為這是因?yàn)楠剟钅P蜔o法完全刻畫一個回復(fù)的質(zhì)量, 而 PPO 和 RAFT 都在某種程度上利用了獎勵模型的這種不完美來獲得高獎勵。顯然, 這只是 RLHF 探索的起始點(diǎn), 我們還有許多改進(jìn)的空間。為了進(jìn)一步提高模型性能,例如, 我們可以改進(jìn)獎勵模型(例如使用 LLaMA-7B-RM), 我們也可以嘗試一些更先進(jìn)的生成策略來提升生成文本的質(zhì)量 (例如 contrastive search, 見https://zhuanlan.zhihu.com/p/629920420)。同時,請查看我們的 LMFlow 框架,以獲取更多 LLMs 的樂趣:
OptimalScale/LMFlow: An Extensible Toolkit for Finetuning and Inference of Large Foundation Models. Large Model for All. (github.com)
https://github.com/OptimalScale/LMFlow
(以下圖片由表格轉(zhuǎn)換而來,為了顯示方便,Prompt 中的 ###替換成了換行,并以粗體呈現(xiàn))



[1] Training a helpful and harmless 326 assistant with reinforcement learning from human feedback
-
框架
+關(guān)注
關(guān)注
0文章
403瀏覽量
17476 -
模型
+關(guān)注
關(guān)注
1文章
3229瀏覽量
48811 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24690
原文標(biāo)題:RLHF 實(shí)踐中的框架使用與一些坑 (TRL, LMFlow)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
分享一些嵌入式系統(tǒng)編程中內(nèi)存操作相關(guān)的避坑指南
mpu6050和stm32的一些坑
總結(jié)一些在編寫單片機(jī)程序及其他相關(guān)實(shí)踐中學(xué)到的C語言技巧
EDA 技術(shù)在教學(xué)實(shí)踐中的應(yīng)用2
用實(shí)例引起大家在嵌入式中做項(xiàng)目時對一些問題的關(guān)注
無人機(jī)航拍在電視新聞實(shí)踐中的應(yīng)用與影響
剖析智能制造關(guān)于“輕與重”的實(shí)踐中的誤區(qū)
光纖涂覆機(jī)在科研及工程實(shí)踐中詳細(xì)應(yīng)用步驟(圖文)
埋點(diǎn)實(shí)踐過程中遇到的一些問題
關(guān)于藍(lán)橋杯單片機(jī)開發(fā)板矩陣鍵盤的一些坑






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論