 基于AX650N部署SegFormer
基于AX650N部署SegFormer
一
背景
語義分割(Semantic Segmentation)是計算機視覺中的一項基本任務。與單張圖像分類任務相比,語義分割相當于是像素級別上的分類任務。語義分割為許多下游應用特別是近幾年來的智能駕駛技術的落地提供了可能。
本文將簡單介紹SegFormer的基本原理,同時指導如何導出ONNX模型,并將其部署在優秀的端側AI芯片AX650N上,希望能給行業內對邊緣側/端側部署Transformer模型的愛好者提供新的思路。
二
SegFormer介紹
SegFormer的論文中提出了一個簡單、高效的語義分割方案,它將Transformers與輕量級多層感知(MLPs)解碼器結合起來。SegFormer有兩個吸引人的特點:
1
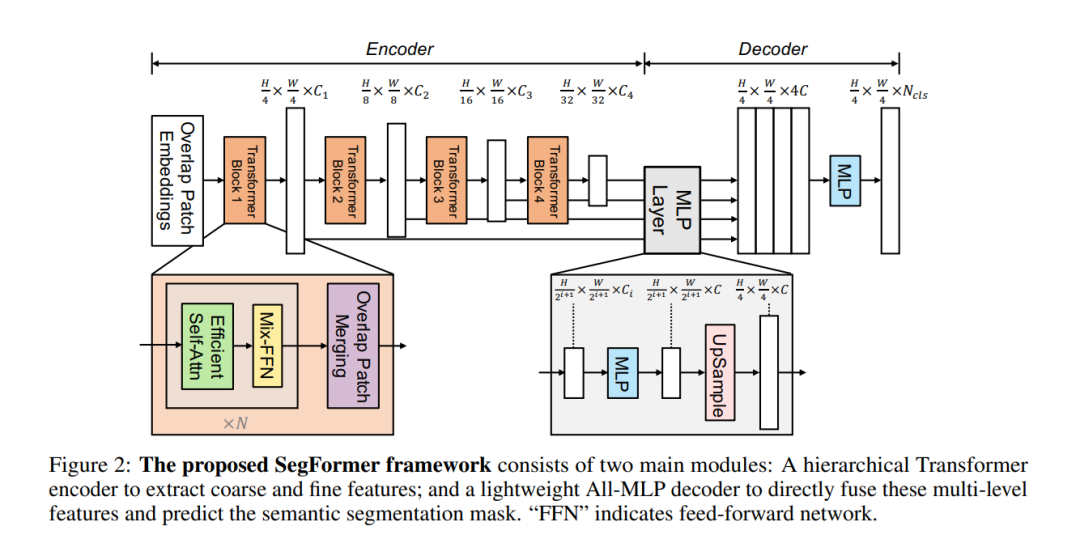
SegFormer包含一個新的層次結構的Transformer編碼器,輸出多尺度特征。它不需要位置編碼,這樣就不用對位置編碼做插值。
2
SegFormer避免了復雜的解碼器。所提出的MLP解碼器從不同的層聚集信息,從而結合Local Attention和Global Attention來呈現強大的表示。這種簡單而輕量級的設計是用Transformer高效地做分割的關鍵。
論文中擴展了上述方案,得到了一系列不同大小型號的模型,從SegFormer-B0到SegFormer-B5,相比之前的分割模型達到了更好的性能和效率。例如,SegFormer-B4在ADE20K上以64M參數實現了50.3%的mIoU,最佳模型SegFormer-B5在Cityscapes驗證集上達到了84.0%的mIoU。
2.1 骨干網絡
backbone
2.2 分級Transformer編碼器
論文中提出了一系列的Mix Transformer編碼器(MiT),MiT-B0到MiT-B5,具有相同的結構,但尺寸不同。MiT-B0是用于快速推理的輕量級模型,而MiT-B5是用于最佳性能的最大模型。設計的MiT部分靈感來自ViT,但針對語義分割進行了定制和優化。
2.3 輕量級All-MLP解碼器
集成了一個僅由MLP層組成的輕量級解碼器,這避免了其他方法中通常用的手工制作和計算要求很高的組件。實現這種簡單解碼器的關鍵是分級Transformer編碼器比傳統的CNN編碼器具有更大的有效感受野(ERF)。
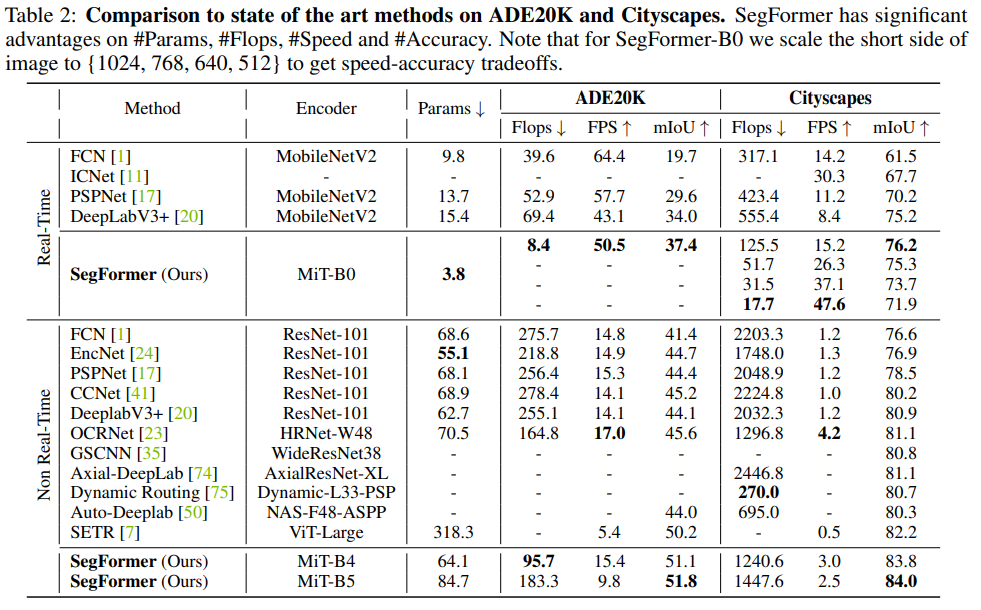
benchmark
三
AX650N
AX650N是一款兼具高算力與高能效比的SoC芯片,集成了八核Cortex-A55 CPU,10.8TOPs@INT8 NPU(針對 Transformer 模型進行了定制優化),支持8K@30fps的ISP,以及H.264、H.265編解碼的VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI輸入,千兆Ethernet、USB、以及HDMI 2.0b輸出,并支持32路1080p@30fps解碼。強大的性能可以讓AX650N幫助用戶在智慧城市、智慧教育、智能制造等領域發揮更大的價值。
四
模型轉換
本文以segformer-b0-cityscapes-640-1280為例。
4.1 模型下載
這次我們推薦從Huggingface的ModelZoo下載模型。
huggingface
● ONNX模型導出的腳本
ONNX模型導出
import torch from transformers import SegformerForSemanticSegmentation, SegformerFeatureExtractor from pathlib import Path from onnxruntime.quantization import quantize_dynamic, QuantType, preprocess import onnx import onnxruntime import os from PIL import Image from typing import List def export_model(model_name: str, export_dir: str, input_sample: torch.Tensor): model = SegformerForSemanticSegmentation.from_pretrained(model_name) model.eval() export_path = os.path.join(export_dir, model_name) Path(export_path).mkdir(parents=True, exist_ok=True) onnx_path = os.path.join(export_path, "model.onnx") # export the model to ONNX while preserving the first dimension as dynamic torch.onnx.export(model, input_sample, onnx_path, export_params=True, opset_version=11, input_names=["input"], output_names=["output"], ) export_dir = "./hf_export/" model_name = "nvidia/segformer-b0-finetuned-cityscapes-640-1280" export_model(model_name, export_dir, torch.randn([1,3,640,1280])) # model_name = "nvidia/segformer-b1-finetuned-ade-512-512" # export_model(model_name, export_dir, torch.randn([1,3,512,512])) # check_models(model_name, export_dir, image_paths)
● onnxsim優化
$ onnxsim segformer-b0-cityscapes-640-1280.onnx segformer-b0-cityscapes-640-1280-sim.onnx Simplifying... Finish! Here is the difference: ┏━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Original Model ┃ Simplified Model ┃ ┡━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩ │ Add │ 136 │ 136 │ │ Concat │ 21 │ 1 │ │ Constant │ 176 │ 0 │ │ Conv │ 20 │ 20 │ │ Div │ 46 │ 46 │ │ Erf │ 8 │ 8 │ │ MatMul │ 68 │ 68 │ │ Mul │ 46 │ 46 │ │ Pow │ 30 │ 30 │ │ ReduceMean │ 60 │ 60 │ │ Relu │ 1 │ 1 │ │ Reshape │ 76 │ 76 │ │ Resize │ 4 │ 4 │ │ Shape │ 20 │ 0 │ │ Slice │ 20 │ 0 │ │ Softmax │ 8 │ 8 │ │ Sqrt │ 30 │ 30 │ │ Sub │ 30 │ 30 │ │ Transpose │ 76 │ 76 │ │ Model Size │ 14.3MiB │ 14.3MiB │ └────────────┴────────────────┴──────────────────┘
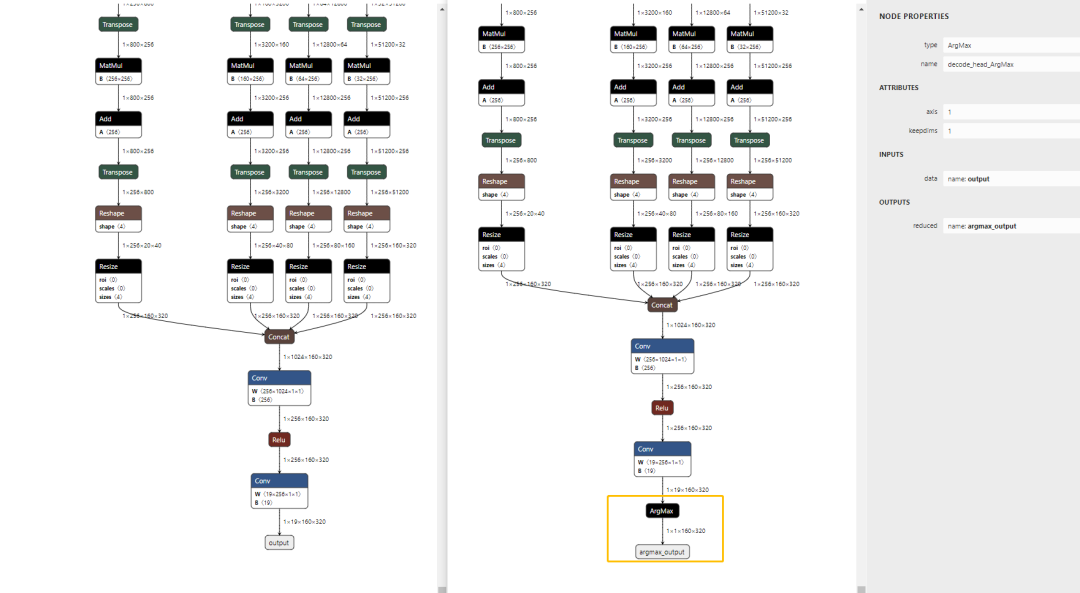
● 添加argmax輸出頭
由于AX650N的NPU支持argmax算子,因此可以將argmax添加到該模型的輸出頭,直接獲取每個像素點置信度最高的類別ID。
首先安裝onnx_graphsurgeon依賴:
pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.com
運行下面的腳本,添加argmax op:
import numpy as np
import onnx
import onnx_graphsurgeon as gs
model_path = "./segformer-b0-cityscapes-640-1280-sim.onnx"
output_model_path = "./segformer-b0-cityscapes-640-1280-sim-argmax.onnx"
onnx_model = onnx.load(model_path)
onnx_graph = gs.import_onnx(onnx_model)
node_last_conv = onnx_graph.nodes[-1]
# Attrs for ArgMax
axis = 1
keepdims = 1
argmax_out_shape = node_last_conv.outputs[0].shape.copy()
argmax_out_shape[axis] = 1
argmax_out = gs.Variable(
"argmax_output",
dtype=np.int64,
shape=argmax_out_shape,
)
argmax_node = gs.Node(
op="ArgMax",
name="decode_head_ArgMax",
inputs=[node_last_conv.outputs[0]],
outputs=[argmax_out],
attrs={"axis": axis, "keepdims": keepdims},
)
onnx_graph.nodes.append(argmax_node)
onnx_graph.outputs.clear()
onnx_graph.outputs = [argmax_out]
onnx_graph.cleanup().toposort()
onnx_model_with_argmax = gs.export_onnx(onnx_graph)
onnx_model_with_argmax.ir_version = onnx_model.ir_version
onnx.save(onnx_model_with_argmax, output_model_path)
添加argmax前后兩個ONNX模型對比:
add-argmax
4.2 模型編譯
使用AX650N配套的AI工具鏈Pulsar2,一鍵完成圖優化、離線量化、編譯、對分功能。
$ pulsar2 build --input model/segformer-b0-cityscapes-640-1280-sim-argmax.onnx --output_dir segformer/ --config config/seg former_config.json --npu_mode NPU3
Building onnx ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
patool: Extracting ./dataset/coco_4.tar ...
patool: running /usr/bin/tar --extract --file ./dataset/coco_4.tar --directory segformer/quant/dataset/input
patool: ... ./dataset/coco_4.tar extracted to `segformer/quant/dataset/input'.
Quant Config Table
┏━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Input ┃ Shape ┃ Dataset Directory ┃ Data Format ┃ Tensor Format ┃ Mean ┃ Std ┃
┡━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ input │ [1, 3, 640, 1280] │ input │ Image │ RGB │ [123.67500305175781, 116.27999877929688, │ [58.39500045776367, 57.119998931884766, │
│ │ │ │ │ │ 103.52999877929688] │ 57.356998443603516] │
└───────┴───────────────────┴───────────────────┴─────────────┴───────────────┴───────────────────────────────────────────────┴──────────────────────────────────────────────┘
4 File(s) Loaded.
[14:17:44] AX LSTM Operation Format Pass Running ... Finished.
[14:17:44] AX Refine Operation Config Pass Running ... Finished.
[14:17:44] AX Transformer Optimize Pass Running ... Finished.
[14:17:45] AX Reset Mul Config Pass Running ... Finished.
[14:17:45] AX Tanh Operation Format Pass Running ... Finished.
[14:17:45] AX Quantization Config Refine Pass Running ... Finished.
[14:17:45] AX Quantization Fusion Pass Running ... Finished.
[14:17:45] AX Quantization Simplify Pass Running ... Finished.
[14:17:45] AX Parameter Quantization Pass Running ... Finished.
Calibration Progress(Phase 1): 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:23<00:00, ?5.86s/it]
Finished.
[1411] AX Passive Parameter Quantization Running ... ?Finished.
[1411] AX Parameter Baking Pass Running ... ? ? ? ? ? Finished.
[1412] AX Refine Int Parameter Pass Running ... ? ? ? Finished.
Network Quantization Finished.
quant.axmodel export success: segformer/quant/quant_axmodel.onnx
Building native ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 000
......
2023-05-30 1418.661 | INFO ? ? | yasched.test_onepass1615 - max_cycle = 37883954
2023-05-30 14:35:04.545 | INFO ? ? | yamain.command.build904 - fuse 1 subgraph(s)
五
上板部署
5.1 AX-Samples
開源項目AX-Samples實現了常見的深度學習開源算法在愛芯元智的AI SoC上的示例代碼,方便社區開發者進行快速評估和適配。最新版本已開始提供AX650系列的NPU示例,其中也包含了本文介紹的SegFormer參考代碼。
https://github.com/AXERA-TECH/ax-samples/blob/main/examples/ax650/ax_segformer_steps.cc
5.2 運行
# ./ax_segformer -m segformer-b0-cityscapes-640-1280-argmax.axmodel -i segformer_test.png -------------------------------------- model file : segformer-b0-cityscapes-640-1280-argmax.axmodel image file : segformer_test.png img_h, img_w : 640 1280 -------------------------------------- post process cost time:7.07 ms -------------------------------------- Repeat 1 times, avg time 48.15 ms, max_time 48.15 ms, min_time 48.15 ms -------------------------------------- --------------------------------------
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1143瀏覽量
40720 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980 -
AI芯片
+關注
關注
17文章
1880瀏覽量
34994 -
MLP
+關注
關注
0文章
57瀏覽量
4241
原文標題:愛芯分享 | 基于AX650N部署SegFormer
文章出處:【微信號:愛芯元智AXERA,微信公眾號:愛芯元智AXERA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于AX650N/AX620Q部署YOLO-World
基于AX650N/AX630C部署端側大語言模型Qwen2
愛芯元智發布第三代智能視覺芯片AX650N,為智慧生活賦能

【愛芯派 Pro 開發板試用體驗】在愛芯派 Pro上部署坐姿檢測
【愛芯派 Pro 開發板試用體驗】篇一:開箱篇
【愛芯派 Pro 開發板試用體驗】愛芯元智AX650N部署yolov5s 自定義模型
【愛芯派 Pro 開發板試用體驗】愛芯元智AX650N部署yolov8s 自定義模型
【愛芯派 Pro 開發板試用體驗】ax650使用ax-pipeline進行推理
愛芯元智第三代智能視覺芯片AX650N高能效比SoC芯片
如何優雅地將Swin Transformer模型部署到AX650N Demo板上?
基于AX650N部署DETR
基于AX650N部署EfficientViT
基于AX650N部署SegFormer
基于AX650N部署視覺大模型DINOv2
愛芯元智AX620E和AX650系列芯片正式通過PSA Certified安全認證






 工商網監
工商網監
評論