 AMD最強芯片 全村的希望!
AMD最強芯片 全村的希望!
由于 GPU 嚴重短缺,Nvidia 收取的費用是制造成本的 5 倍左右,業內每個人都迫切希望找到替代方案。雖然谷歌在 AI 工作負載方面具有結構性性能/TCO 優勢,但由于其 TPU具有成熟的硬件和軟件OCS,因此與其他大型科技公司相比,我們認為存在結構性問題會阻止他們成為外部使用的領導者。
1、谷歌 TPU 將只能從 1 個公司在 1 個云中獲得。
2、谷歌Google 在芯片部署很久之后才會公開他們的芯片,因為大買家需要在發布前記錄下來,并在 ramp 之前提供早期訪問系統。
3、多年來,谷歌一直向用戶隱藏多項主要硬件功能,包括內存/計算相關和網絡/部署靈活性。
4、谷歌拒絕為那些想要編寫自定義內核以最大化性能的奇才在外部提供低級別的硬件文檔。
谷歌在 AI 基礎設施方面的最大技術進步的守門人將使他們在結構上與基于 Nvidia 的云產品相比處于落后地位,除非谷歌改變他們的運作方式。來自亞馬遜和微軟等其他云的內部芯片仍然遠遠落后。
在商業芯片的世界里, Cerebras 目前是最接近的競爭對手,在 GPT-3 上表現穩定開源模型令人印象深刻,但硬件可訪問性非常有限,每臺服務器成本高達數百萬美元。在云中訪問 Cerebras 的唯一方法是通過他們自己的產品。缺乏訪問權會損害開發的靈活性。
Nvidia 生態系統的生命線是人們在各種各樣的系統上進行開發,從他們花費數百美元的游戲 GPU 到最終能夠擴展到擁有數萬個本地 GPU 或與所有第 3 方云服務提供商合作. 而Tenstorrent 等其他初創公司則表現出希望我們認為硬件/軟件距離真正大踏步前進還有一段距離。
盡管收購了兩家不同的數據中心 AI 硬件公司 Nervana 和 Habana,但世界上最大的商用芯片供應商英特爾卻不見蹤影。Nervana幾年前就被拋棄了,現在的Habana身上似乎也發生了同樣的事情。英特爾目前正在使用他們的第二代Habana Gaudi 2,除了 AWS 上可用的一些實例外,幾乎沒有采用。
此外,隨著該產品被納入 2025 Falcon Shores GPU,英特爾已經將路線圖宣告失敗。英特爾的 GPU,Ponte Vecchio 也好不到哪兒去。已經很晚了,直到最近才完成對拖延已久的 Aurora 超級計算機的交付,再過 2 年就沒有繼任者了。它的性能通常無法與 Nvidia 的 H100 GPU 競爭。
AMD 是唯一一家擁有成功交付用于高性能計算的芯片記錄的公司。雖然這主要適用于他們的 CPU 端是一臺運行良好的執行機器,但它還可以進一步擴展。AMD 于 2021 年為全球首臺 ExaFLop 超級計算機 Frontier 交付了 HPC GPU 芯片。雖然為 Frontier 提供動力的 MI250X 足以完成其主要工作,但它未能在云計算和超大規模用戶的大客戶中獲得任何影響力。
現在,每個人都期待著 AMD 的 MI300,它將于今年晚些時候交付給 El Capitan,這是他們的第二個 Exascale 超級計算機獲勝者。出于這個原因,一旦您將目光脫離 Nvidia ,AMD 即將推出的 MI300 GPU 將成為討論最多的芯片之一。我們也一直在密切關注其與Meta 的 PyTorch 2.0 和 OpenAI 的 Triton軟件的適配前景。自 Nvidia 的 Volta GPU 和 AMD 的 Rome CPU 以來,數據中心芯片還沒有引起如此大的轟動。
MI300,代號 Aqua Vanjaram,由多個復雜的硅層組成,坦率地說是工程奇跡。首席執行官 Lisa Su 今年早些時候在 CES 上展示了 MI300 套件,讓我們了解 MI300 的結構。我們看到 4 個硅片被 8 個 HBM 堆棧包圍。這是 HBM3 的最高 5.6 GT/s 速度,八個 16GB 堆棧形成 128GB 統一內存,帶寬高達 5.734 TB/s。
與 3.3 TB/s 的 Nvidia H100 SXM 80GB 相比,其帶寬增加了 72%,容量增加了 60%。
AMD 獲得任何數量的 AI 計算美元的機會最終歸結為成為 hyperscalers 與 Nvidia 的可靠第二來源。假設是漲潮會托起所有船只。
當然,預計在 AI 數據中心基礎設施上的大量支出將以某種方式使 AMD 受益。
AMD 硬件只是 AI 支出熱潮中的一個注腳。事實上,目前 AMD 在生成 AI 基礎設施建設方面相對失敗,因為他們在數據中心 GPU 方面缺乏成功安利,在 HGX H100 系統中缺乏 CPU 勝利,以及 普遍放棄 CPU 支出。因此,MI300 的成功至關重要。
01.基本構建塊 - Elk Range 有源中介層芯片
MI300 的所有變體都以稱為 AID(active interposer die) 的相同基本構建塊開始,即是所謂的有源中介層裸片。這是一款名為 Elk Range 的小芯片,尺寸約為 370mm2,采用臺積電的 N6 工藝技術制造。該芯片包含 2 個 HBM 內存控制器、64MB 內存附加末級 (MALL) Infinity Cache、3 個最新一代視頻解碼引擎、36 通道 xGMI/PCIe/CXL,以及 AMD 的片上網絡 (NOC)。在 4 塊配置中,MALL 緩存為 256MB,而 H100 為 50MB。
AID 最重要的部分是它在 CPU 和 GPU 計算方面是模塊化的。AMD 和臺積電使用混合鍵合技術將 AID 連接到其他小芯片。這種通過銅 TSV 的連接允許 AMD 混合和匹配 CPU 與 GPU 的最佳比例。四個 AID 以超過 4.3 TB/s 的對分帶寬相互通信,啟用超短距離 (USR:Ultra Short Reach) 物理層,如 AMD Navi31 游戲 GPU 中的小芯片互連所示,盡管這次同時具有水平和垂直鏈路和具有對稱的讀/寫帶寬。方形拓撲還意味著對角線連接需要 2 跳(hops),而相鄰 AID 需要 1 跳。 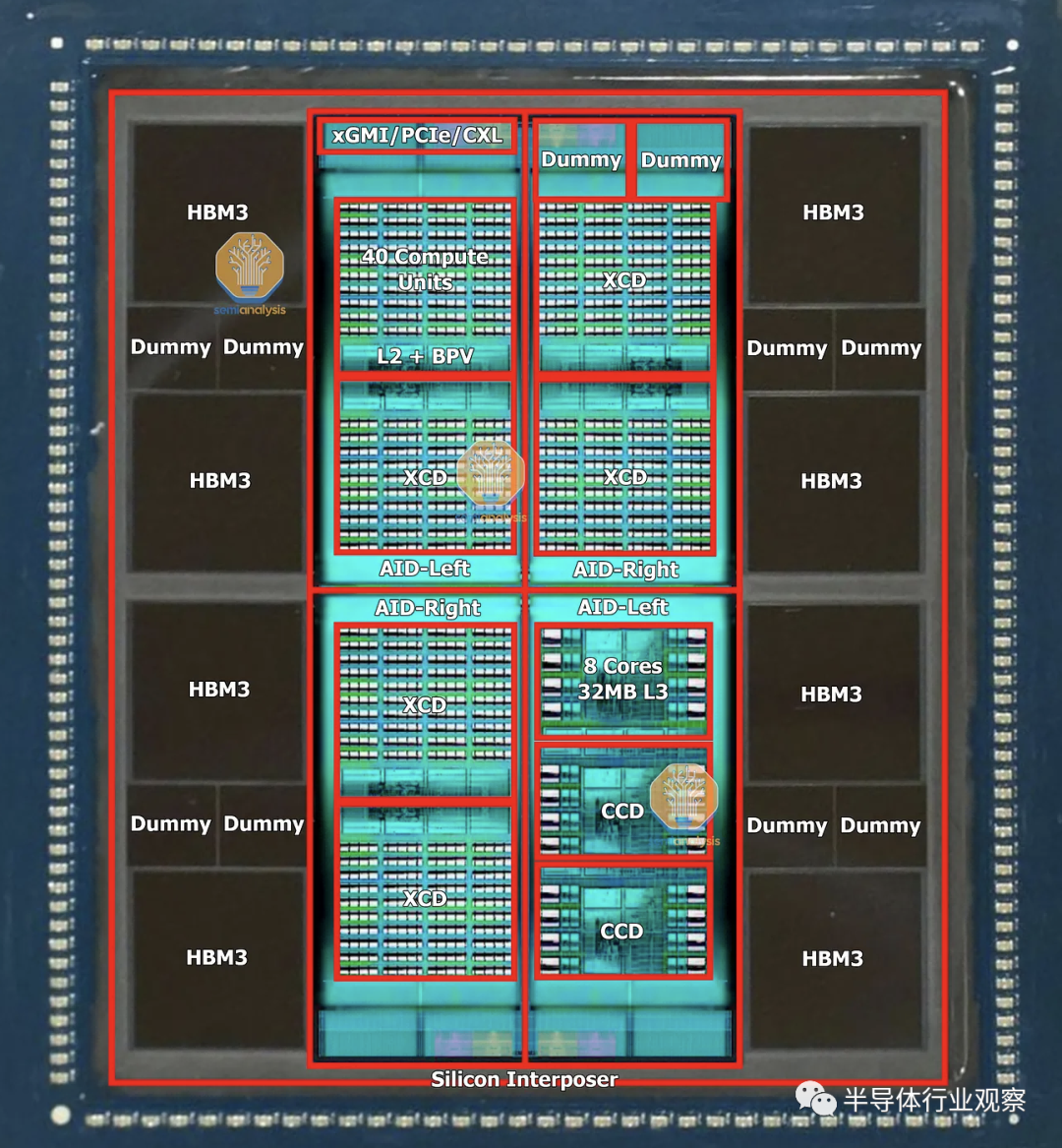 ?
?
這些 AID 中的 2 個或 4 個(根據 MI300 變體具有不同的計算)在CoWoS 硅中介層的頂部組合在一起。AID 有兩種不同的流片,它們的. T鏡像很像英特爾的 Sapphire Rapids。
02.Compute Tiles——Banff XCD 和 DG300 Durango CCD
AID 之上的模塊化計算塊可以是 CPU 或 GPU。
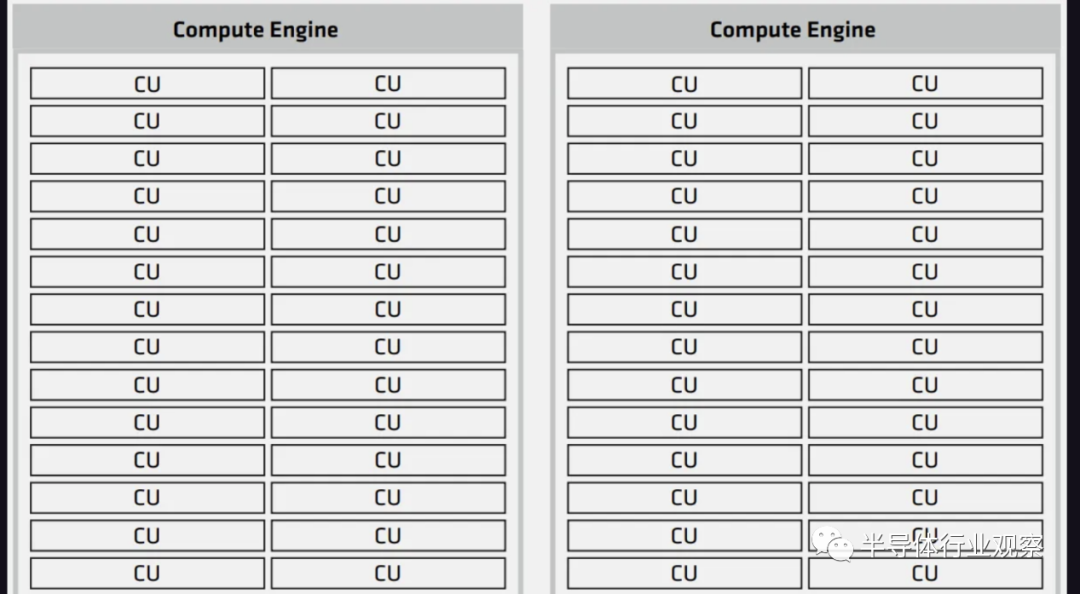
在 GPU 方面,計算小芯片稱為 XCD,代號為 Banff。Banff在 TSMC N5 工藝技術上制造,約為 ~115mm2 。盡管只啟用了 38 個計算單元,但它總共包含 40 個計算單元。
該架構由 AMD 的 MI250X 演變而來,在 GitHub 上,AMD 將其稱為 gfx940,但公開稱其為 CDNA3。它針對計算進行了優化,盡管是“GPU”,但不能真正處理圖形。
這同樣適用于 Nvidia 的 H100,它們的大部分 GPC 都無法處理圖形。
 ?
?
總的來說,每個 AID 可以有 2 個 Banff die,總共有 76 個 CU。MI300 的最大 XCD/GPU 配置將提供 304 個 CU。作為對比,AMD MI250X 具有 220 個 CU。 MI300 的另一個模塊化計算方面是 CPU 方面。AMD 部分重用了他們的 Zen 4 CCD 小芯片,盡管進行了一些修改。
他們改變了一些金屬層掩模,為 SoIC 和 AID 創建焊盤,需要重新設計一些金屬掩模的新流片。這個修改過的 Zen 4 CCD,GD300 Durango 禁用了 GMI3 PHY。AID 的帶寬明顯高于 GMI3。此 CCD 采用 TSMC 的 5nm 工藝技術,并保留與臺式機和服務器上的 Zen 4 CCD相同的 ~70.4mm 2芯片尺寸。
每個 AID 可以有 3 個 Zen 4 小芯片,總共 24 個內核。MI300的最大CCD/CPU配置可以提供多達96個核心。
03.先進封裝——品味未來
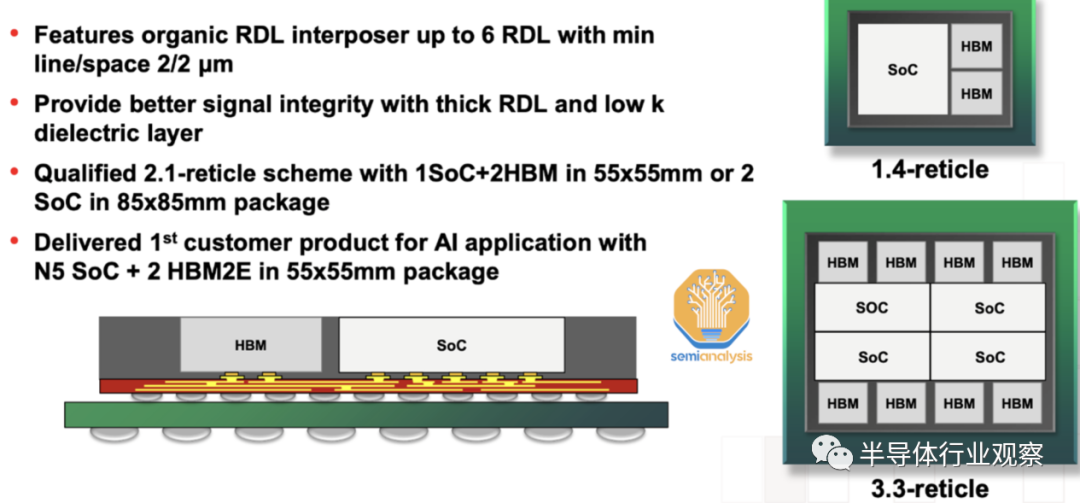
AMD 的MI300 是世界上最令人難以置信的先進封裝形式。有超過 100 塊硅粘在一起,全部位于使用 TSMC 的 CoWoS-S 技術的破紀錄的 3.5x 光罩硅中介層之上。
這種硅的范圍從 HBM 存儲層到有源中介層以進行計算,再到用于結構支持的空白硅。這個巨大的中介層幾乎是 NVIDIA H100 上中介層的兩倍。MI300 的封裝工藝流程非常復雜,是行業的未來。
 ?
?
復雜的封裝需要 AMD 的重大靈活性和修改才能按時獲得 MI300。最初的設計是使用采用臺積電CoWoS-R技術的有機再分布層 (RDL) 中介層。事實上,臺積電去年確實推出了CoWoS-R測試封裝,其結構與小米300有著驚人的相似之處。可能由于具有如此大尺寸的有機中介層的翹曲和熱穩定性問題而改變了中介層材料。
AID 以 9um 間距與 SoIC gen 1 混合鍵合到 XCD 和 CCD。由于工藝不成熟,AMD 不得不放棄轉向TSMC 的 SoIC gen 2 的計劃,該 SoIC 的間距為 6um 。
然后將它們封裝在 CoW 無源中介層之上。通過這個過程有十幾塊支撐硅片。最終的 MI300 包含傳統的倒裝芯片質量回流和 TCB 以及晶圓上的芯片、晶圓上的晶圓和晶圓上的重構晶圓混合鍵合。
04.MI300 配置
AMD MI300 有 4 種不同的配置,但我們不確定是否所有 4 種都會真正發布。 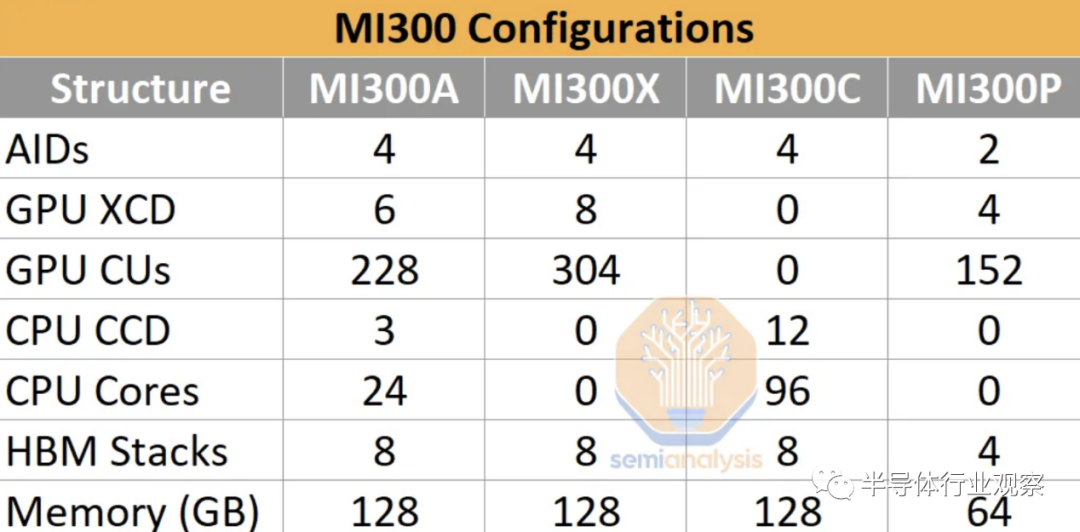 ?
?
MI300A 憑借異構 CPU+GPU 計算成為頭條新聞,El Capitan Exascale 超級計算機正在使用該版本。MI300A 在 72 x 75.4mm 基板上采用集成散熱器封裝,適合插槽 SH5 LGA 主板,每塊板有 4 個處理器。它有效地支付了開發成本。它已經出貨,但真正在第三季度出現增長。標準服務器/節點將是 4 個 MI300A。
不需要主機 CPU,因為它是內置的。這是迄今為止市場上最好的 HPC 芯片,并將保持一段時間。
MI300X 是 AI hyperscaler 變體,如果成功,將成為真正的容量推動者。全是 GPU,以實現 AI 的最佳性能。AMD這里推的服務器級配置是8顆MI300X+2顆Genoa CPU。
MI300C 將走相反的方向,成為僅具有 96 核 Zen4 + HBM 的 CPU,以響應英特爾的 Sapphire Rapids HBM。然而,這個市場可能太小而且產品太貴,以至于 AMD 無法生產這個變體。
MI300P 就像一半大小的 MI300X。它是一種可以以較低功率進入 PCIe 卡的產品。這又需要主機 CPU。這將是最容易開始開發的版本,盡管我們認為它更像是 2024 年的版本。
審核編輯:劉清
-
TSMC
+關注
關注
3文章
177瀏覽量
84529 -
TPU
+關注
關注
0文章
141瀏覽量
20741 -
USR
+關注
關注
1文章
49瀏覽量
11058 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5835
原文標題:AMD最強芯片,全村的希望!
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AMD最強AI芯片,性能強過英偉達H200,但市場仍不買賬,生態是最大短板?

Lunar Lake大戰Strix Point!AMD、英特爾掀起新一輪AI PC芯片“大躍進”
AMD MI300X AI芯片面臨挑戰
AMD或涉足手機芯片市場
AMD發布新一代AI芯片MI325X

AMD穩固合作,贏得索尼PS6處理器芯片設計合同
AMD AI芯片需求井噴,業績預估再獲提升
使用STM32F407ZGT6的設備無法連接到AMD處理器的電腦上,怎么處理?
英特爾、AMD等聯手推出UALink,希望用它取代Nvidia NVLink接口






 工商網監
工商網監
評論