 基于通用的模型PADing解決三大分割任務
基于通用的模型PADing解決三大分割任務
1. 研究動機
圖像分割旨在將具有不同語義的像素進行分類進而分組,例如類別或實例,近年來取得飛速的發展。然而,由于深度學習方法是數據驅動的,對大規模標記訓練樣本的強烈需求導致了巨大的挑戰,這些訓練數據需要消耗巨大的時間以及人力成本。為處理上述難題,零樣本學習(Zero-Shot Learning,ZSL)被提出用于分類沒有訓練樣本的新對象,并擴展到分割任務中,例如零樣本語義分割(Zero-Shot Semantic Segmentation, ZSS)和零樣本實例分割(Zero-Shot Instance Segmentation, ZSI)。在此基礎上,本文進一步引入零樣本全景分割(Zero-Shot Panoptic Segmentation, ZSP)并旨在利用語義知識構建一個通用的零樣本全景/語義/實例分割框架,如圖1所示。
本文從為未知類別生成更好的偽特征出發來設計一個通用的模型PADing解決三大分割任務。針對通用分割存在的共性問題:視覺與語言差異以及類別偏見問題,旨在實現對于新類別的全景、實例和語義分割。本文基于零樣本通用分割方法PADing開展定量實驗和定性可視化,研究結果表明,相對于主流方法,該方法在定量實驗結果和定性可視化結果方面表現出色。
本文貢獻主要包括以下四點:
研究了通用的零樣本分割問題,并提出了一種名為基于協作關系對齊和特征解耦學習的基元生成(Primitive generation with collaborative relationship Alignment and feature Disentanglement learning,PADing)的統一框架來處理零樣本語義分割、實例分割和全景分割問題。
提出了一種基元生成器,它使用許多帶有細粒度屬性的學習基元來合成未見過類別的視覺特征,有助于解決偏差問題和域間差距問題。
提出了一種協作關系對齊和特征解耦學習方法,以促進生成器產生更好的合成特征。
提出的方法PADing在零樣本全景分割(ZSP)、零樣本實例分割(ZSI)和零樣本語義分割(ZSS)上取得了新的最先進性能。
2. 方法
2.1 方法概述
本文提出的方法基于協作關系對齊和特征解耦學習的基元生成PADing,其總體架構如圖2所示。首先,Backbone預測了一組與類無關的掩碼及其相應的類向量。接著,基元生成器經過訓練,可以從語義向量中合成類向量。然后,將真實的與合成類向量被分解為與語義相關和與語義無關的特征,并在語義相關的特征上進行關系對齊學習。最后,通過合成未知類別的向量,用實際已知類別的真實向量和未知類別的合成向量進行重新微調訓練分類器。
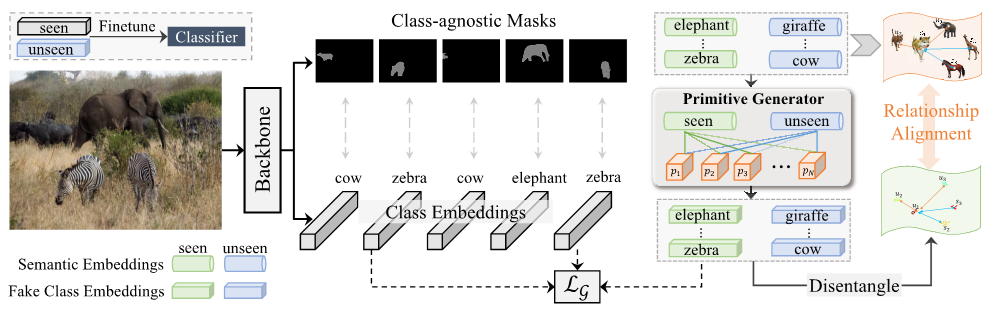
圖2: PADing框架結構圖
2.2 基元跨模態生成
由于缺乏未知類別的樣本,分類器不能使用未知類別的特征進行優化。因此,僅使用已知類別的特征進行訓練的分類器往往會將所有對象標記為已知類別,這稱為偏置問題。先前的方法提出利用生成模型來為未知類別合成假的視覺特征。雖然達到了良好的性能,但并未考慮特征粒度的視覺-語義差異。眾所周知,圖像通常包含比語言更豐富的信息。視覺信息提供了對象的非常精細的屬性,而文本信息通常提供抽象和高級別的屬性。這種差異導致了視覺特征和語義特征之間的不一致。為了解決這一挑戰,本文提出了一個基于基元的跨模態生成器,利用大量學習到的屬性基元來構建視覺表示。
先初始化一堆可學習的基元,希望它能學習到細粒度的信息,具體的方法是利用Transformer將語義向量和基元組都輸入到網絡中,首先語義向量先與基元組計算相似度,選擇其與語義向量最為相關型的基元后并加入高斯噪聲。這樣就得到由基元組成的特征,當輸入一個語義向量,能輸出生成相應的視覺向量。最后用MMD損失來拉近這兩個生成與真實的視覺向量特征。基元就像是語言與視覺之間的橋梁,消除兩者之間的域內差異。
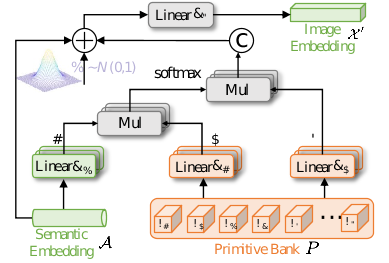
圖3: 基元跨模態生成的結構示意圖
2.3 語義-視覺關系對齊
眾所周知,類別之間的關系自然上是不同的。例如,有三個對象:蘋果、橙子和奶牛。顯然,蘋果和橙子之間的關系比蘋果和奶牛之間的關系更緊密。語義空間中的類別關系是強大的先驗知識,而類別特定的特征生成并沒有明確利用這種關系。也就是語義空間中關系相近的物體,在視覺空間也應該相近,具有相似的分布。但通常的方法一般直接將語義空間的關系暴力地遷移到視覺空間中。這樣并不能有效的利用語義關系,因為語義和視覺本來就不是相互對齊的空間,視覺特征包含更多信息,而語義特征可以看作是信息的濃縮。也就是視覺特征中多了多余的信息。所以本文考慮到了將視覺特征進行解耦之后再進行關系對齊。解耦的方法也就是分成了語義相關特征與語義無關特征,然后將視覺的語義相關特征再與語義特征對齊。語義無關特征希望其符合正態分布刻畫著沒有具體語義信息的特征。而語義相關特征需要其能通過特征將其分到指定語義信息中。
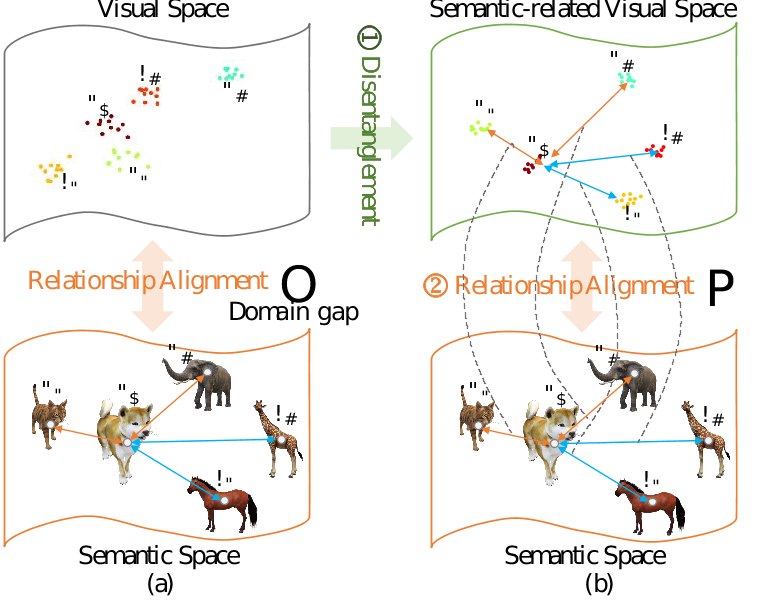
圖4: 語義-視覺關系對齊示意圖
3. 實驗
3.1 定量結果實驗
為了驗證本文方法的有效性,在COCO數據上針對全景分割、實例分割、語義分割上進行了對比實驗,見表1、2、3。實驗結果表明,本文方法PADing取得先進的性能。
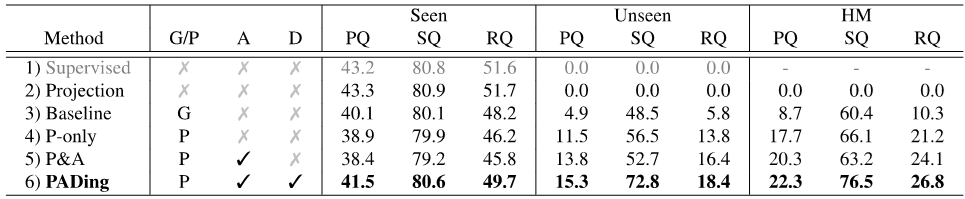
表1: 零樣本全景分割結果
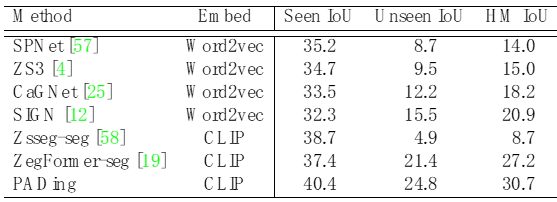
表2: 零樣本語義分割結果
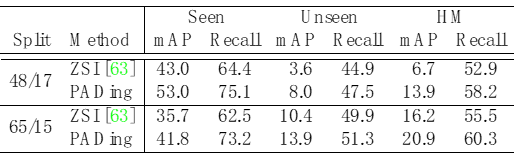
表1: 零樣本實例分割結果
3.2 定性結果實驗
為了探究基元是否可以代表細微的細節元素,圖5可視化不同基元在圖片上的注意力響應。結果表明基元可以代表不同細粒度的屬性,例如在圖中的貓作為例子:關注到了耳朵、尾巴以及輪廓。
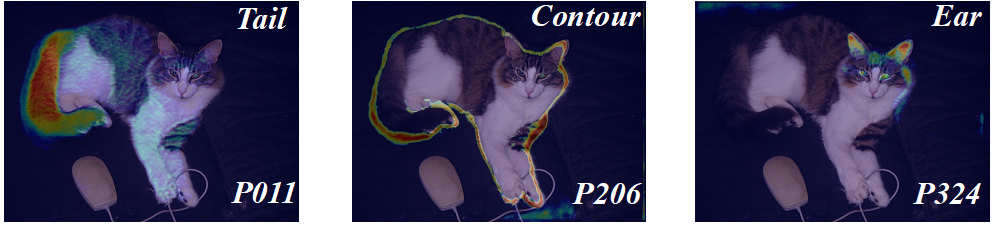
圖5: 基元注意力響應圖
為了研究本文合成的未見特征的屬性,并展示本章提出的方法的有效性,圖6使用 t-SNE來展示合成的未知特征的分布情況。(a)由 GMMN 生成器生成的合成特征由于語義-視覺差異而雜亂無序。(b)引入了本文的基元生成器,同一類別的特征變得更加緊密,不同類別的特征則高度可分。此外,在語義相關特征上應用關系對齊約束后,(c),不同類別的特征相距更遠,分布結構更好,這表明結構關系已經嵌入到合成的特征中,合成的未見特征大大增強了較好的區分性。
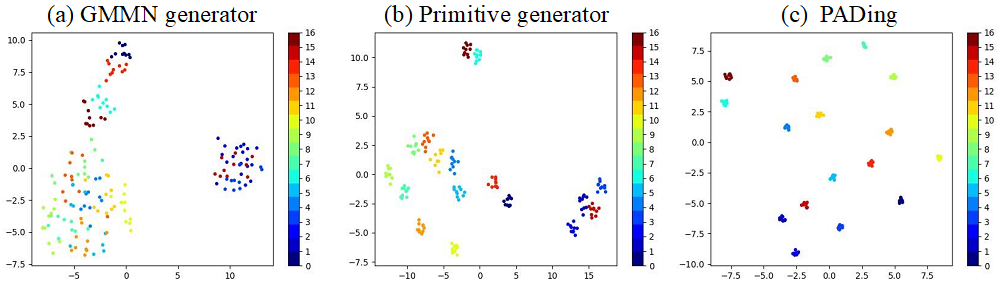
圖6: 不同生成器生成未知類別特征分布圖
圖7定性可視化了零樣本通用分割結果的例子,結果表明我們的方法可以取得很好的效果。

圖7: 零樣本通用分割(全景、實例、語義分割)可視化結果
4. 總結
本文針對零樣本通用分割中存在的視覺與語言差異以及類別偏見問題,提出了基元生成、協作關系對齊與特征解耦學習的統一框架(PADing),以實現高效、實用的零樣本通用分割。首先,提出了基元生成器,用于合成未知類別的偽訓練特征。接著,提出了協作的特征解耦和關系對齊學習策略,幫助生成器產生更好的偽未知特征,前者將視覺特征解耦為語義相關部分和語義不相關部分,后者將跨類知識從語義空間傳輸到視覺空間。PADing在三個零樣本分割任務,包括語義、實例和全景分割上進行的廣泛實驗,都取得了最先進的結果。
責任編輯:彭菁
-
模型
+關注
關注
1文章
3226瀏覽量
48809 -
生成器
+關注
關注
7文章
315瀏覽量
21003 -
分割
+關注
關注
0文章
17瀏覽量
11895
原文標題:CVPR 2023 | 浙大&南洋理工提出PADing:零樣本通用分割框架
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
通過任務分割提高嵌入式系統的實時性
基于多級混合模型的圖像分割方法
基于三維模型球型分割的信息隱藏算法
聚焦語義分割任務,如何用卷積神經網絡處理語義圖像分割?
基于預測算法實現模型的最優在線任務分配
通用航空器運行排班及維修任務的優化模型
在NGC上玩轉圖像分割!NeurIPS頂會模型、智能標注10倍速神器、人像分割SOTA方案、3D醫療影像分割利器應有盡有
通用視覺GPT時刻來臨?智源推出通用分割模型SegGPT
近期分割大模型發展情況

中科院提出FastSAM快速分割一切模型!比Meta原版提速50倍!
三項SOTA!MasQCLIP:開放詞匯通用圖像分割新網絡





 工商網監
工商網監
評論