") 你不了解的國產(chǎn)GPU,都處于什么水平?
你不了解的國產(chǎn)GPU,都處于什么水平?
國內(nèi)GPU廠商有各自的專注領(lǐng)域,其中不乏自主研發(fā)的產(chǎn)品,在IP、微架構(gòu)創(chuàng)新、軟硬件結(jié)合等方面均有建樹。隨著ChatGPT掀起AI熱潮,大模型對算力的要求會越來越高,國內(nèi)GPU廠商以圖形處理、通用GPU(GPGPU)為根基,逐步涉足大模型應(yīng)用,下面列舉幾家具有實力的國內(nèi)GPU廠商。
登臨科技
登臨科技專注于高性能通用計算平臺的芯片研發(fā)與技術(shù)創(chuàng)新,致力于打造云邊端一體、軟硬件協(xié)同、訓(xùn)練推理融合的前沿芯片產(chǎn)品和平臺化基礎(chǔ)系統(tǒng)軟件。
基于GPGPU的軟件定義的片內(nèi)異構(gòu)計算架構(gòu),登臨科技自主研發(fā)了GPU+,在兼容CUDA/OpenCL在內(nèi)的編程模型和軟件生態(tài)的基礎(chǔ)上,通過架構(gòu)創(chuàng)新,完美解決了通用性和高效率的雙重難題。大量客戶產(chǎn)品實測證明,針對AI計算,GPU+相比傳統(tǒng)GPU在性能尤其是能效上有顯著提升。
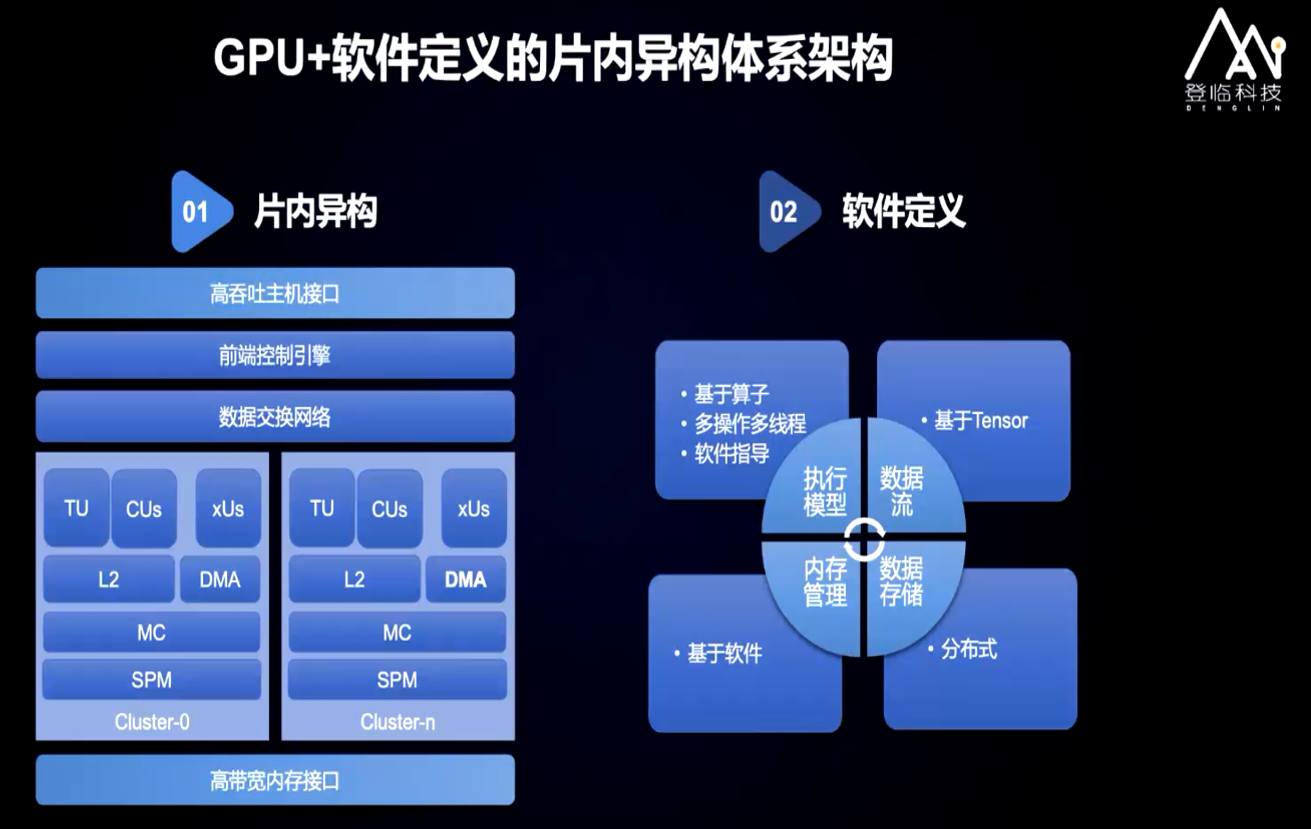
圖片來源:登臨科技
登臨科技GPU+架構(gòu)經(jīng)過優(yōu)化,在基準(zhǔn)測試中使得計算單元、片上內(nèi)存的延遲可以做到30+ cycle,傳統(tǒng)GPU為數(shù)百cycle。
采用“片上內(nèi)存共享”技術(shù),帶寬僅為國際主流方案的五分之一到六分之一,帶寬降低帶來的好處是更高的能效比、更高的并行性。
此外,GPU+架構(gòu)將計算密度和計算效率集中在矩陣單元,綜合上述特性,基于登臨科技GPU+架構(gòu)的產(chǎn)品與國際旗艦產(chǎn)品相比,具有三到四倍單卡能效比優(yōu)勢。

圖片來源:登臨科技
在生態(tài)上,登臨科技GPU+兼容國內(nèi)外主流CPU、服務(wù)器,以及Network引擎,可有效降低用戶的遷移成本。憑借創(chuàng)新的架構(gòu)、獨有的技術(shù)和完整的生態(tài)支持,面向生成式AI的應(yīng)用和大模型發(fā)展浪潮,登臨科技可提供強有競爭力的算力加速方案,全面助力用戶產(chǎn)品的性能提升以及應(yīng)用落地。
中微電科技
中微電科技專注GPU技術(shù)研發(fā),GPU/顯卡產(chǎn)品主要應(yīng)用于信創(chuàng)市場、消費市場、人工智能、邊緣計算等領(lǐng)域。中微電科技自主研發(fā)的指令集MVP ISA被工信部評定為“完全自主知識產(chǎn)權(quán)指令集”,成功進(jìn)行多次基于MVP核的SoC芯片流片,取得處理器領(lǐng)域核心發(fā)明專利22項。
在“十四五”規(guī)劃期間,中微電科技完成“南風(fēng)”系列GPU芯片MVP核處理器架構(gòu)、GPU核心自主知識產(chǎn)權(quán)IP、MVP指令集、編譯器及軟件棧等創(chuàng)新迭代升級及系統(tǒng)適配對接。完成“南風(fēng)一號”量產(chǎn)、“南風(fēng)二號”量產(chǎn)和“南風(fēng)三號”預(yù)研,打造GPUIP級、芯片級和板塊級產(chǎn)品,形成“自主+安全”的場景解決方案。

圖片來源:中微電科技
中微電科技“南風(fēng)一號”已于2022年完成流片,并于回片當(dāng)天點亮成功。“南風(fēng)一號”顯卡已與長城信創(chuàng)臺式機、麒麟操作系統(tǒng)、飛騰處理器、奇安信可信瀏覽器等完全兼容、運行穩(wěn)定,性能滿足黨政、金融及安防等信創(chuàng)產(chǎn)業(yè)鏈專用整機電腦PC顯卡需求。
通過“南風(fēng)一號”成功點亮可以充分驗證自研GPU IP滿足桌面電腦顯示的基本功能和性能要求。相對于授權(quán)IP受制于人,功能性能受限及產(chǎn)品同質(zhì)化競爭的問題,自研IP不受任何第三方控制,可自主迭代發(fā)展,有望徹底解決卡脖子問題,打造自主GPU產(chǎn)業(yè)生態(tài)。只有堅持自主IP路線,深度的自研才能在產(chǎn)品和價格上形成競爭力,成為獨特的IP護(hù)城河。
沐曦集成電路
沐曦集成電路(下文簡稱沐曦)專注于設(shè)計具有完全自主知識產(chǎn)權(quán),針對異構(gòu)計算等各類應(yīng)用的高性能通用GPU芯片。首款異構(gòu)GPU產(chǎn)品MXN100采用7nm制程,已于2022年8月回片點亮,主要應(yīng)用于推理側(cè);應(yīng)用于AI訓(xùn)練及通用計算的產(chǎn)品MXC500已于2022年12月交付流片,公司計劃2024年全面量產(chǎn)。
沐曦?fù)碛型耆灾餮邪l(fā)的GPU IP、指令集和架構(gòu),以及兼容主流GPU生態(tài)的完整軟件棧(MXMACA),產(chǎn)品具備高能效、高通用性。目前已推出MXN系列GPU(曦思)用于AI推理,MXC系列GPU(曦云)用于AI訓(xùn)練及通用計算,以及MXG系列GPU(曦彩)用于圖形渲染,可滿足數(shù)據(jù)中心對高能效和高通用性的算力需求。

圖注:沐曦產(chǎn)品系列。來源:沐曦、財通證券研究所
景嘉微
景嘉微研發(fā)了JM5400、JM7200、JM9為代表的系列圖形處理芯片,目前正籌集資金用于“高性能通用GPU芯片研發(fā)及產(chǎn)業(yè)化項目”、“通用GPU先進(jìn)架構(gòu)研發(fā)中心建設(shè)項目”。
在技術(shù)儲備方面,截至2022年12月31日,景嘉微共申請238項專利(193項國家發(fā)明專利、31項實用新型專利、10項國際專利、4項外觀專利),較2021年同比增長16.10%,其中87項發(fā)明專利、29項實用新型專利、4項外觀專利均已授權(quán),登記了119項軟件著作權(quán),登記了2項集成電路布圖。
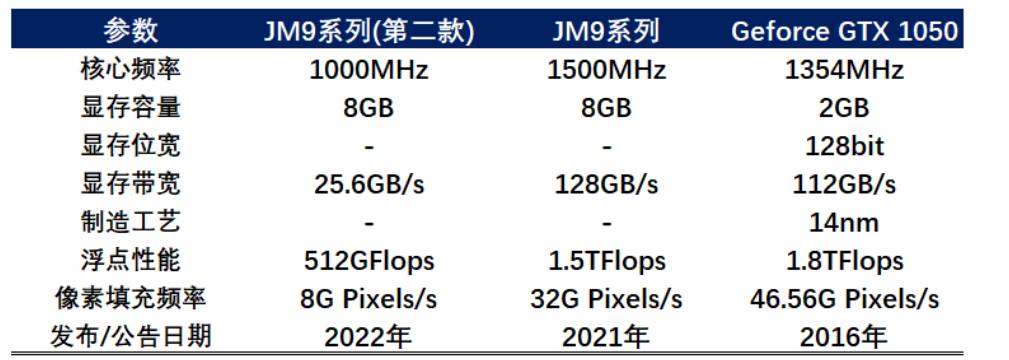
圖注:景嘉微GPU產(chǎn)品JM9規(guī)格
2022年公司圍繞核心產(chǎn)品保持高研發(fā)投入,成功研發(fā)JM9系列第二款GPU芯片,并完成適配測試工作。2022年和1Q23受政策波動影響,市場需求萎縮,景嘉微產(chǎn)品銷量減少。
景嘉微成長動力主要為算力需求有望拉動圖形渲染GPU市場,進(jìn)一步打開信創(chuàng)需求,對辦公PC的GPU性能提出更高要求,推動獨立顯卡成為主流配置,信創(chuàng)GPU市場有望迎來擴容。同時隨著數(shù)字化的發(fā)展,云游戲、數(shù)字孿生、元宇宙、工業(yè)數(shù)字化等產(chǎn)業(yè)成為高性能渲染GPU新的增長點。
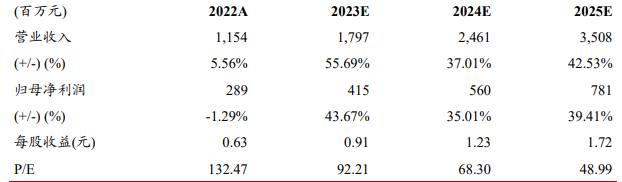
圖注:景嘉微業(yè)績預(yù)測(來源:浙商證券研究所)
龍芯中科
龍芯中科掌握了處理器核及相關(guān)IP核設(shè)計的核心技術(shù),是國內(nèi)極少數(shù)使用自主架構(gòu)研制通用處理器的企業(yè)。龍芯中科掌握指令系統(tǒng)、處理器核微結(jié)構(gòu)、GPU以及各種接口IP等芯片核心技術(shù),在關(guān)鍵技術(shù)上進(jìn)行自主研發(fā),擁有大量的自主知識產(chǎn)權(quán),已取得專利400余項。龍芯指令系統(tǒng)和處理器IP核的關(guān)鍵技術(shù)已申請相關(guān)專利,相關(guān)處理器芯片也申請了集成電路布圖設(shè)計版權(quán)。
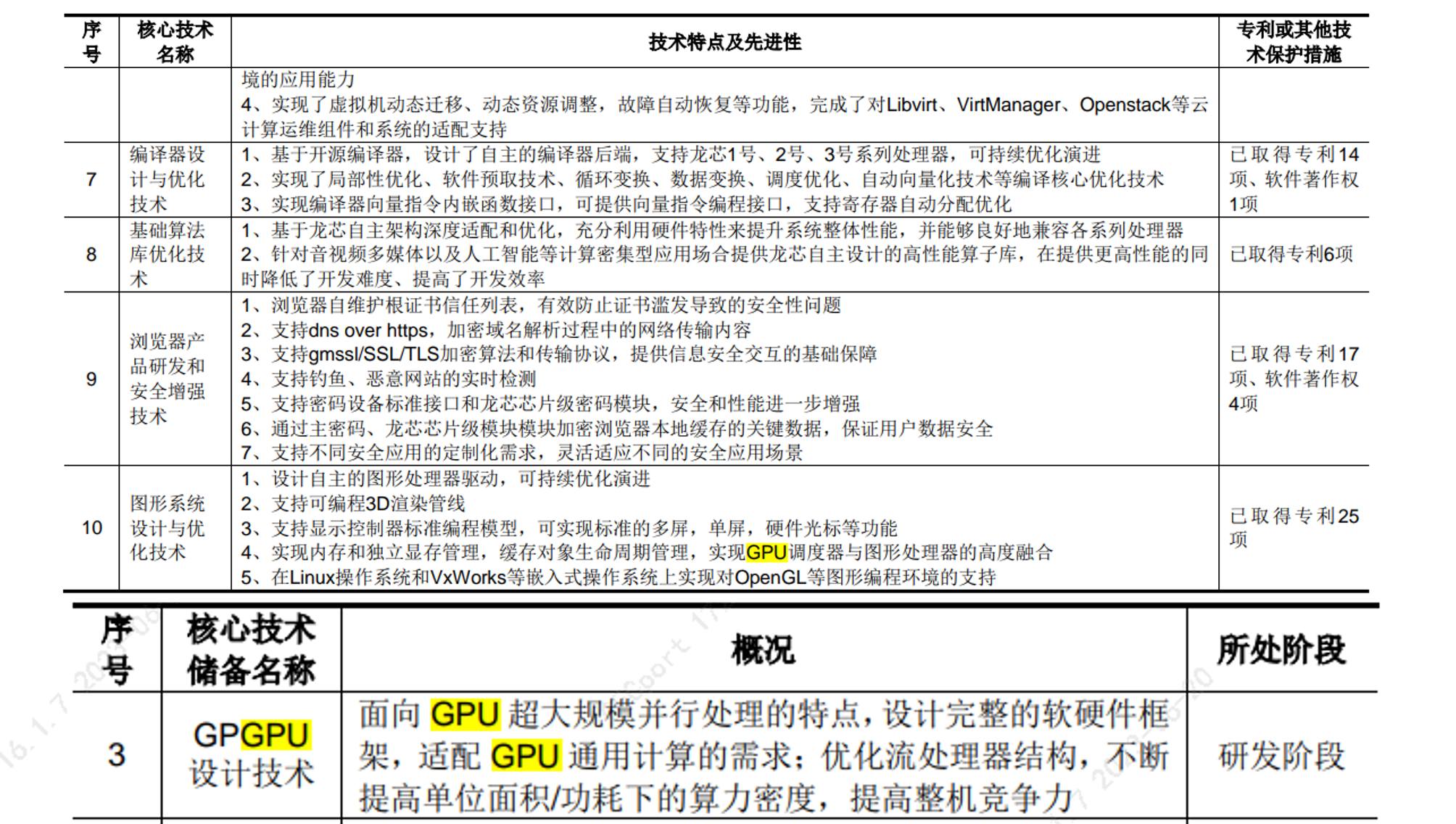
圖注:龍芯中科的核心技術(shù)(來源:龍芯中科招股書)
在顯卡GPU驅(qū)動層面,根據(jù)龍芯系統(tǒng)架構(gòu)的特點和優(yōu)勢,通過數(shù)據(jù)布局、傳輸通路、協(xié)作機制等優(yōu)化手段,圖形系統(tǒng)可充分釋放GPU的性能潛力。在渲染庫、解碼庫等基礎(chǔ)圖形庫層面,結(jié)合龍芯CPU微結(jié)構(gòu)和指令集的特點進(jìn)行算法優(yōu)化,從而推動整體系統(tǒng)性能的改善。
海光信息
海光信息同時具備CPU和DCU研發(fā)能力,在電信、金融、能源等重要行業(yè)領(lǐng)域?qū)崿F(xiàn)訂單放量。當(dāng)前海光四號、海光五號CPU產(chǎn)品,以及深算二號、深算三號DCU(深度計算單元)產(chǎn)品研發(fā)進(jìn)展順利。
海光DCU系列產(chǎn)品以GPGPU架構(gòu)為基礎(chǔ),兼容“類CUDA”環(huán)境,具備豐富軟硬件生態(tài),全面覆蓋支持深度學(xué)習(xí)訓(xùn)練場景,滿足AI、大數(shù)據(jù)處理、商業(yè)計算等高性能需求。深海一號DCU產(chǎn)品在典型應(yīng)用場景下性能已達(dá)國際同類型產(chǎn)品同期水平,已經(jīng)在北京大學(xué)高性能計算系統(tǒng)及百度飛槳AI大框架中應(yīng)用落地,未來有望持續(xù)受益于AIGC時代算力需求爆發(fā)以及國產(chǎn)替代下的龐大市場。
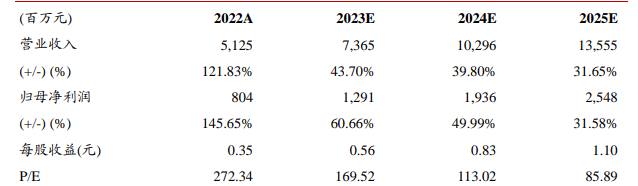
圖注:海光信息業(yè)績預(yù)估
從消費應(yīng)用到大模型,國內(nèi)GPU如何突破?
目前實現(xiàn)商業(yè)化的國內(nèi)GPU產(chǎn)品以消費應(yīng)用居多,據(jù)Imagination中國區(qū)技術(shù)總監(jiān)艾克介紹,消費應(yīng)用的GPU和大模型中的GPU有所不同,國內(nèi)GPU廠商要將技術(shù)和產(chǎn)品擴展到大模型應(yīng)用,需要關(guān)注幾點:
(1)技術(shù)研發(fā):大規(guī)模GPU模型需要高性能的計算能力和大規(guī)模的數(shù)據(jù)存儲能力,需要加強對GPU技術(shù)的研發(fā)力量,提升核心技術(shù)水平。包括研發(fā)GPU架構(gòu)、設(shè)計和制造工藝的能力,提高芯片性能和功耗比,推動技術(shù)創(chuàng)新。
(2)創(chuàng)新應(yīng)用:需要在新的應(yīng)用領(lǐng)域進(jìn)行創(chuàng)新,如人工智能、云計算、大數(shù)據(jù),自動駕駛等。這些領(lǐng)域?qū)τ嬎隳芰Φ囊蠓浅8撸珿PU可以提供并行計算能力,因此加強與這些領(lǐng)域的合作,推動GPU技術(shù)的應(yīng)用。
(3)產(chǎn)業(yè)環(huán)境:需要打造良好的產(chǎn)業(yè)環(huán)境,吸引和培育GPU相關(guān)企業(yè)和人才。加大對GPU產(chǎn)業(yè)鏈關(guān)鍵環(huán)節(jié)的支持力度。同時,建立起完善的知識產(chǎn)權(quán)保護(hù)體系,保護(hù)自主研發(fā)成果。
(4)先進(jìn)制造工藝:當(dāng)前最先進(jìn)制程和高GPU算力的設(shè)計,或受到美國出口技術(shù)的限制。如果國內(nèi)先進(jìn)制程技術(shù)能夠獲得突破,那么將十分利于國產(chǎn)GPU的發(fā)展。

圖注:消費級GPU與大模型GPU的區(qū)別(來源:Imagination)
小結(jié)
海外廠商的發(fā)展過程有幾個特點值得觀察。首先,選擇技術(shù)方向或許比快速展開業(yè)務(wù)更加重要。NVIDIA很早就意識到GPU在科學(xué)計算領(lǐng)域的潛力,并將其應(yīng)用于人工智能、深度學(xué)習(xí)等領(lǐng)域。提前布局為未來趨勢做好準(zhǔn)備。
其次,持續(xù)進(jìn)行微架構(gòu)創(chuàng)新。NVIDIA始終保持著創(chuàng)新和領(lǐng)導(dǎo)地位,與不斷研發(fā)新的GPU微架構(gòu)和技術(shù)、提升性能和能效有較大關(guān)系。NVIDIA在GPU微架構(gòu)上不斷演進(jìn),推出了包括Tesla、Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere在內(nèi)的架構(gòu),每一次微架構(gòu)的創(chuàng)新涵蓋了許多關(guān)鍵技術(shù)的引入和改進(jìn),推動了游戲圖形性能的提升,也使得GPU在科學(xué)計算、人工智能等領(lǐng)域發(fā)揮了重要作用。
此外,國產(chǎn)GPU發(fā)展初期可以通過兼容CUDA的部分功能,快速拓展市場,降低開發(fā)難度和用戶移植成本,但是長期來看,國內(nèi)GPU廠商還是要不斷提升自身的軟硬件實力,打造一個自己的、獨具特色的軟硬件生態(tài)系統(tǒng)。
審核編輯黃宇
-
芯片
+關(guān)注
關(guān)注
455文章
50725瀏覽量
423173 -
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128897 -
AI
+關(guān)注
關(guān)注
87文章
30749瀏覽量
268901
發(fā)布評論請先 登錄
相關(guān)推薦

你不了解的示波器前面板
java開發(fā)人員不了解jvm調(diào)優(yōu)對工作有影響嗎
鏈接腳本對一些命令不了解
總結(jié)使用 Vim 的過程中不得不了解的一些指令和注意事項
你所不了解的自動焊錫機
你到底了不了解物聯(lián)網(wǎng)
談?wù)?b class='flag-5'>你所不了解的PCB
不了解中斷,還怎么玩單片機?資料下載






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論