 卷積神經網絡結構組成與解釋
卷積神經網絡結構組成與解釋
卷積神經網絡是以卷積層為主的深度網路結構,網絡結構包括有卷積層、激活層、BN層、池化層、FC層、損失層等。卷積操作是對圖像和濾波矩陣做內積(元素相乘再求和)的操作。
1. 卷積層
常見的卷積操作如下:| 卷積操作 | 解釋 | 圖解 |
| 標準卷積 | 一般采用3x3、5x5、7x7的卷積核進行卷積操作。??????? |
|
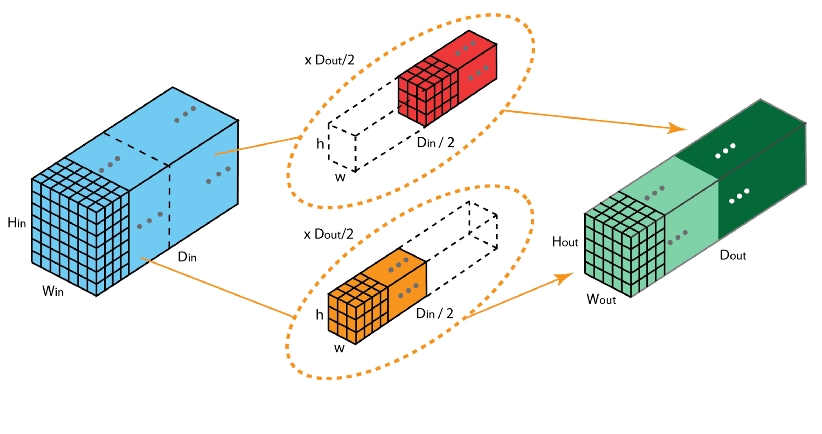
| 分組卷積 | 將輸入特征圖按通道均分為 x 組,然后對每一組進行常規卷積,最后再進行合并。 |
|
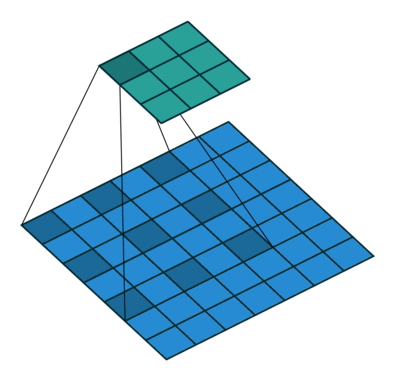
| 空洞卷積 | 為擴大感受野,在卷積核里面的元素之間插入空格來“膨脹”內核,形成“空洞卷積”(或稱膨脹卷積),并用膨脹率參數L表示要擴大內核的范圍,即在內核元素之間插入L-1個空格。當L=1時,則內核元素之間沒有插入空格,變為標準卷積。 |
|
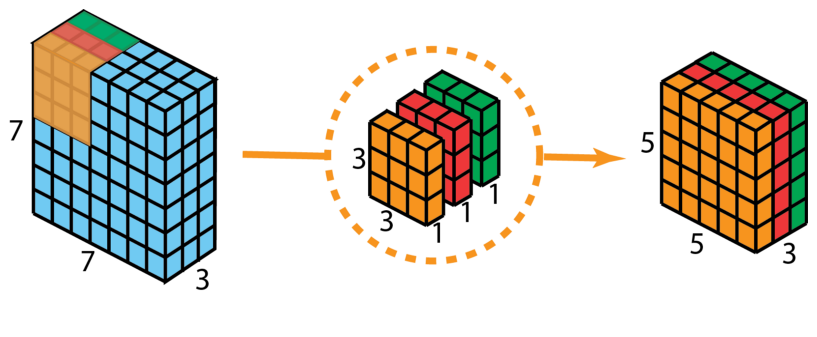
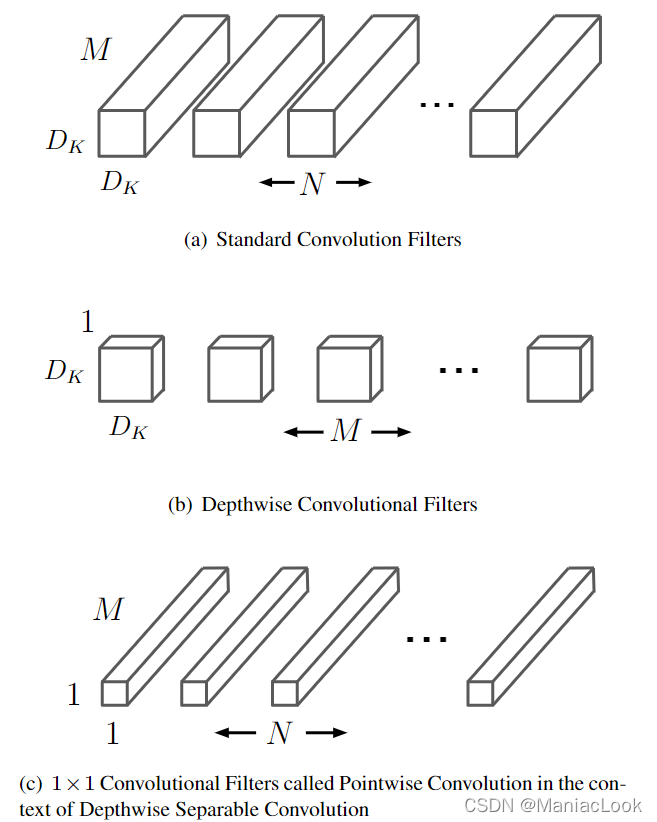
| 深度可分離卷積 | 深度可分離卷積包括為逐通道卷積和逐點卷積兩個過程。???? |
(通道卷積,2D標準卷積)
|
| 反卷積 | 屬于上采樣過程,“反卷積”是將卷積核轉換為稀疏矩陣后進行轉置計算。 |
|
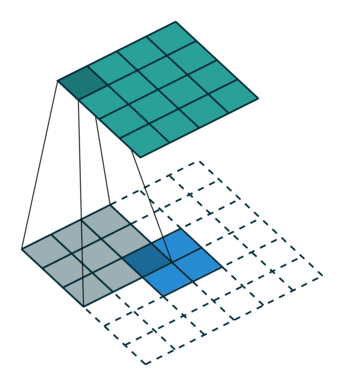
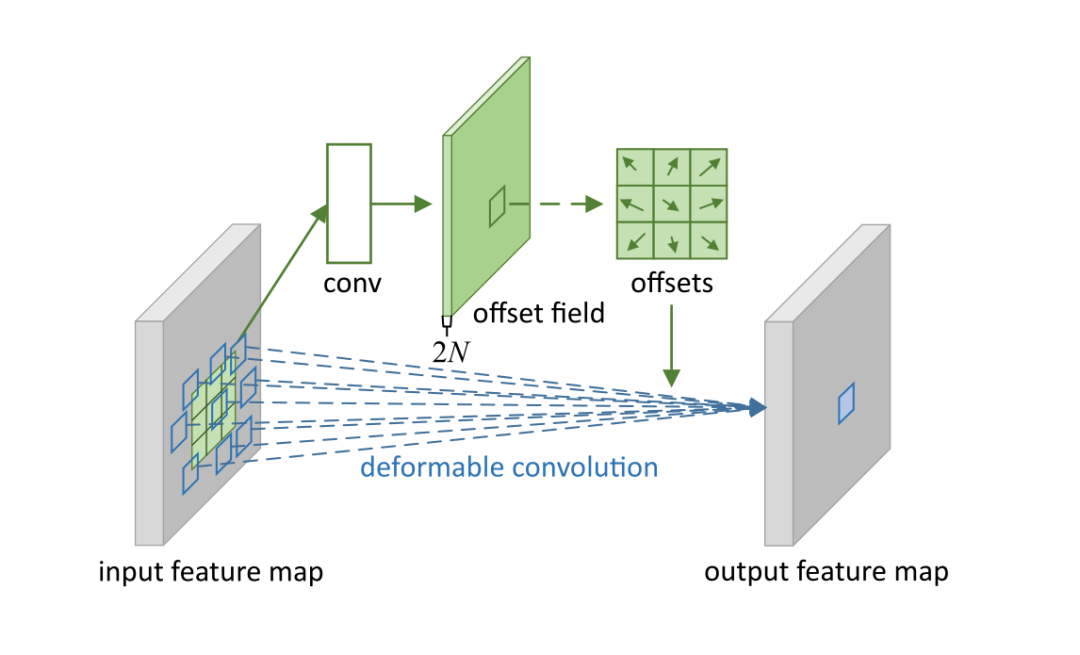
| 可變形卷積 | 指標準卷積操作中采樣位置增加了一個偏移量offset,如此卷積核在訓練過程中能擴展到很大的范圍。 |
|
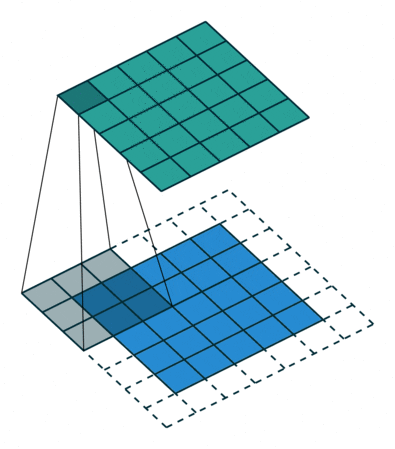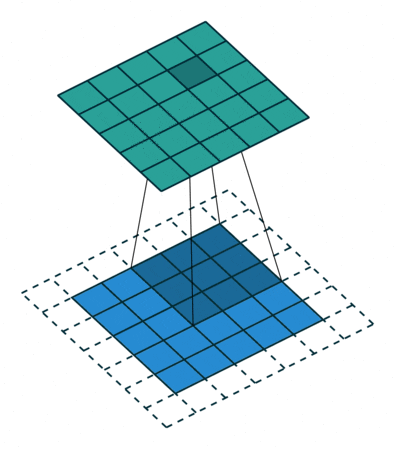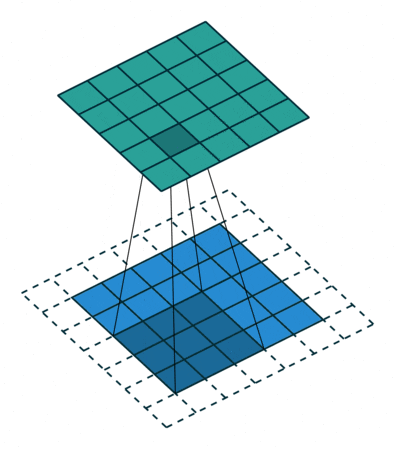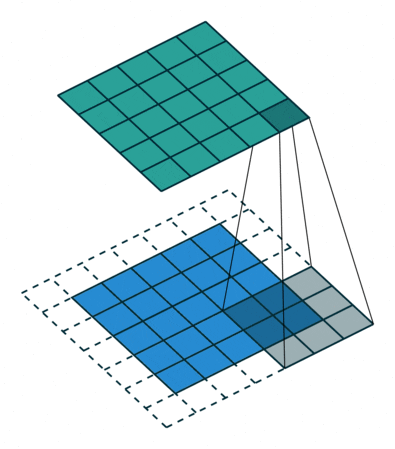
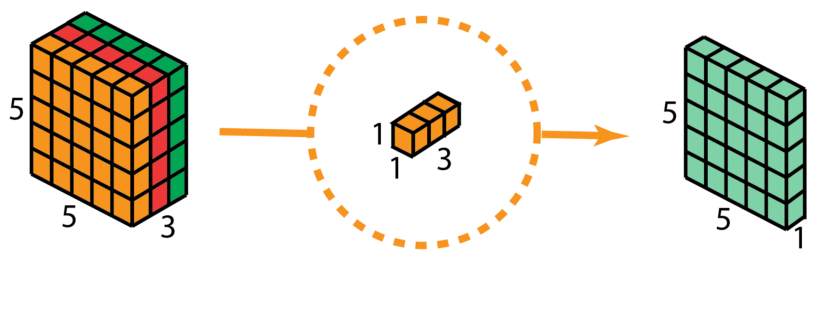
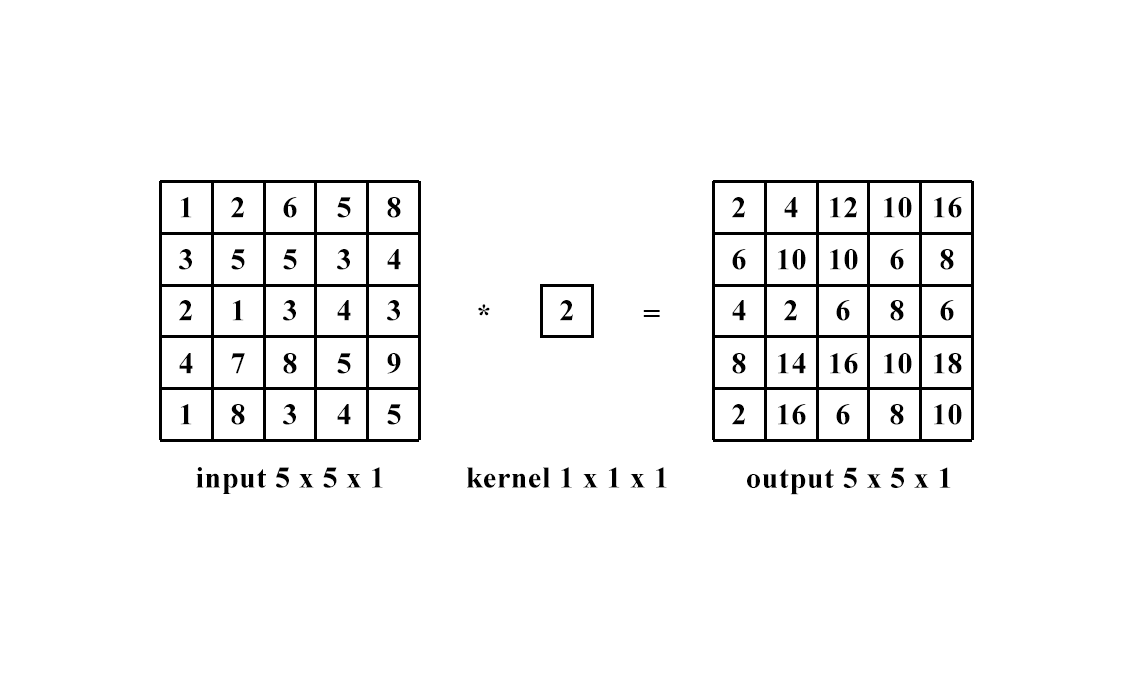
1 x 1卷積即用1 x 1的卷積核進行卷積操作,其作用在于升維與降維。升維操作常用于chennel為1(即是通道數為1)的情況下,降維操作常用于chennel為n(即是通道數為n)的情況下。??????????????
降維:通道數不變,數值改變。
 升維:通道數改變為kernel的數量(即為filters),運算本質可以看為全連接。
升維:通道數改變為kernel的數量(即為filters),運算本質可以看為全連接。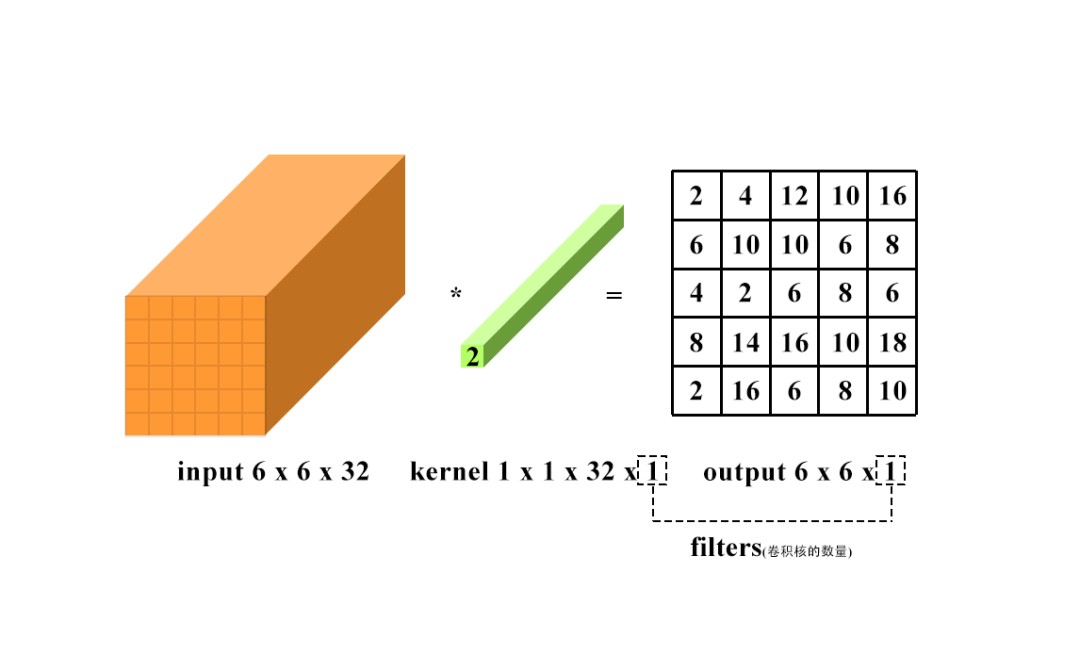 卷積計算在深度神經網絡中的量是極大的,壓縮卷積計算量的主要方法如下:
卷積計算在深度神經網絡中的量是極大的,壓縮卷積計算量的主要方法如下:| 序號 | 方法 |
| 1 | 采用多個3x3卷積核代替大卷積核(如用兩個3 x 3的卷積核代替5 x 5的卷積核) |
| 2 | 采用深度可分離卷積(分組卷積) |
| 3 | 通道Shuffle |
| 4 | Pooling層 |
| 5 | Stride = 2 |
| 6 | 等等 |
2. 激活層
介紹:為了提升網絡的非線性能力,以提高網絡的表達能力。每個卷積層后都會跟一個激活層。激活函數主要分為飽和激活函數(sigmoid、tanh)與非飽和激活函數(ReLU、Leakly ReLU、ELU、PReLU、RReLU)。非飽和激活函數能夠解決梯度消失的問題,能夠加快收斂速度。??????????????常用函數:ReLU函數、Leakly ReLU函數、ELU函數等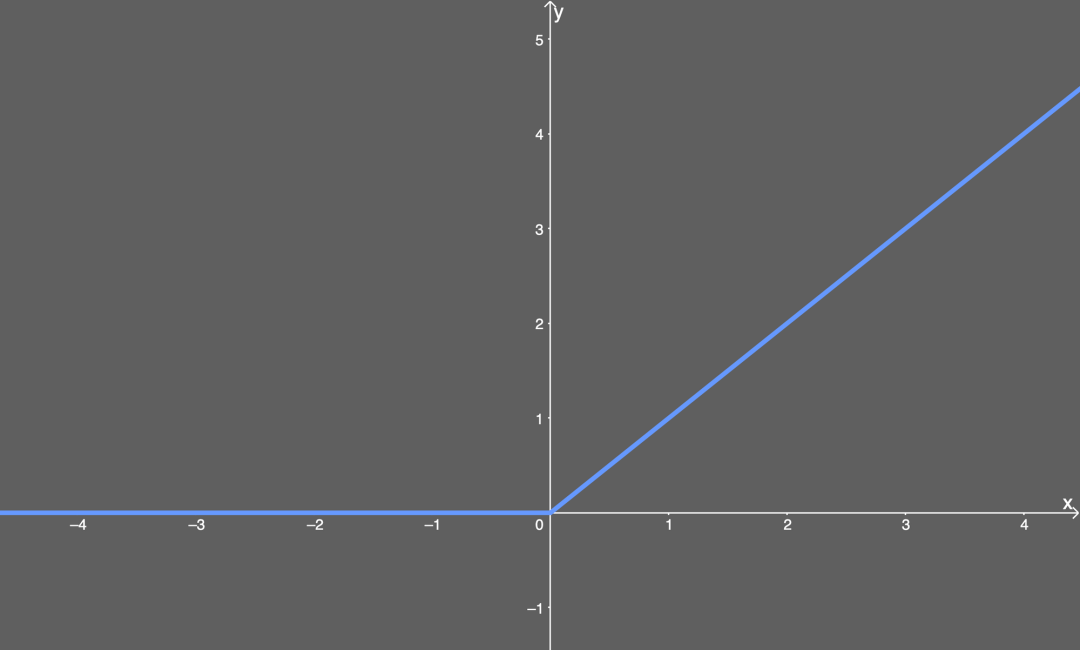 ReLU函數
ReLU函數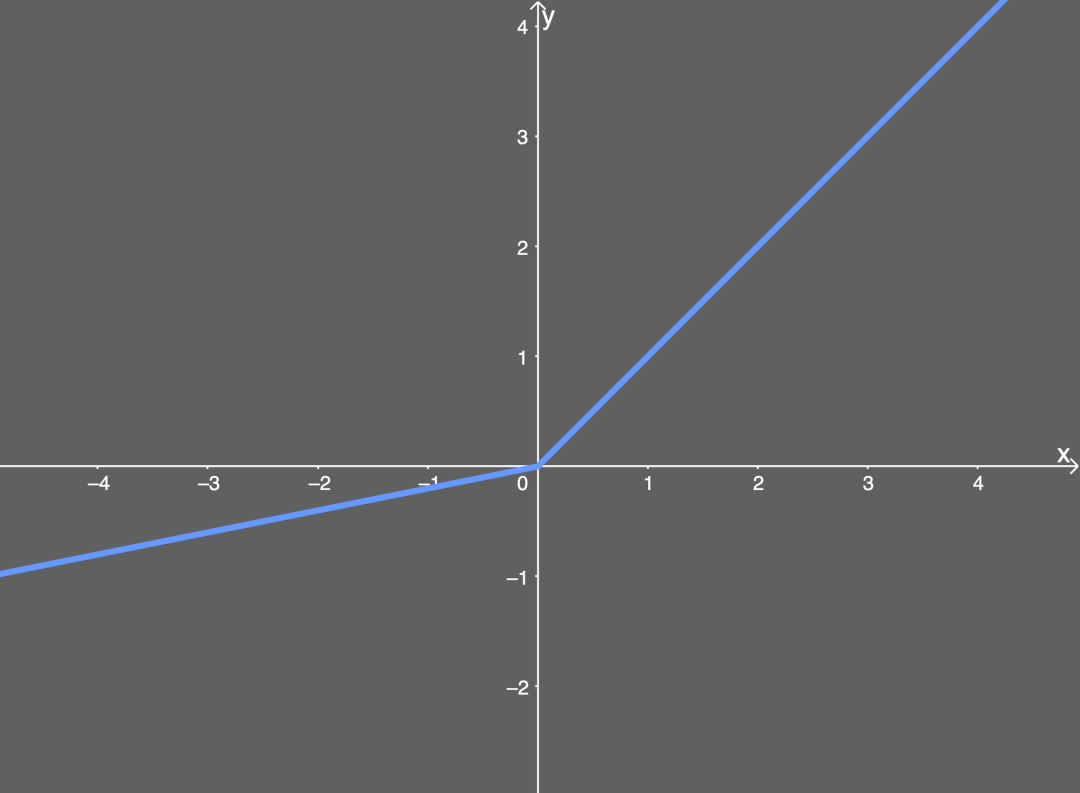 Leakly ReLU函數
Leakly ReLU函數
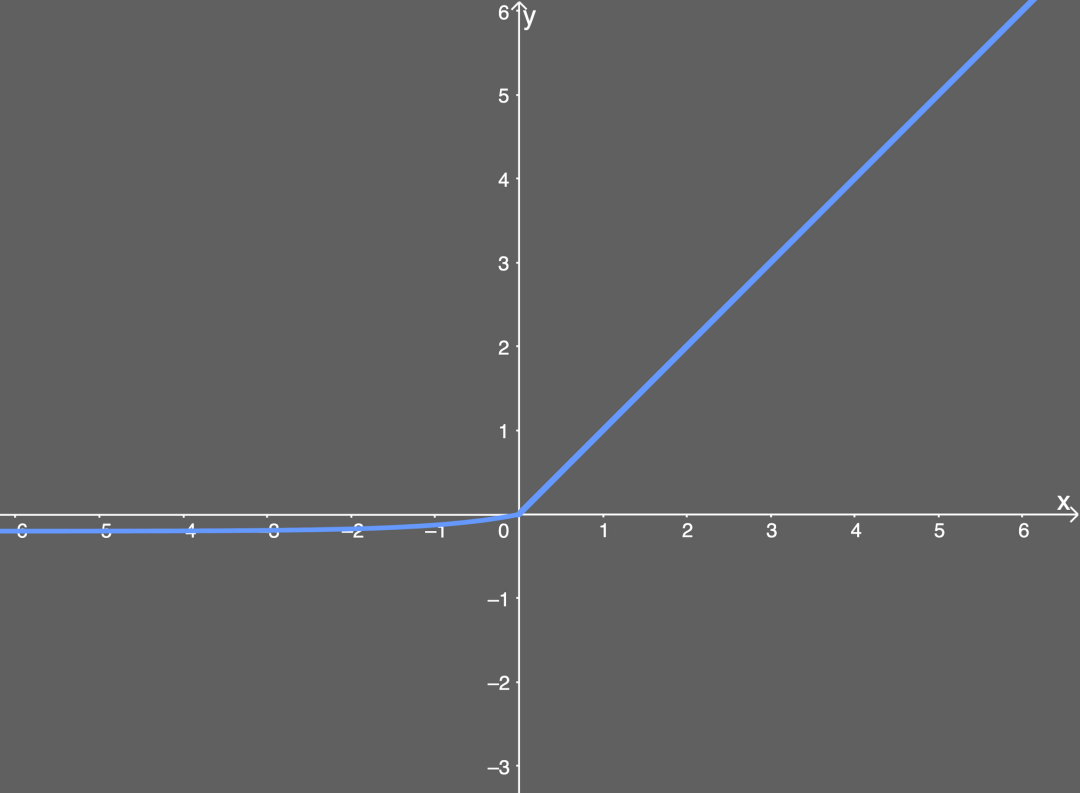
ELU函數
3. BN層(BatchNorm)介紹:通過一定的規范化手段,把每層神經網絡任意神經元的輸入值的分布強行拉回到均值為0,方差為1的標準正態分布。BatchNorm是歸一化的一種手段,會減小圖像之間的絕對差異,突出相對差異,加快訓練速度。但不適用于image-to-image以及對噪聲明感的任務中。常用函數:BatchNorm2dpytorch用法:nn.BatchNorm2d(num_features, eps, momentum, affine)num_features:一般輸入參數為batch_sizenum_featuresheight*width,即為其中特征的數量。eps:分母中添加的一個值,目的是為了計算的穩定性,默認為:1e-5。momentum:一個用于運行過程中均值和方差的一個估計參數(我的理解是一個穩定系數,類似于SGD中的momentum的系數)。
affine:當設為true時,會給定可以學習的系數矩陣gamma和beta。
4. 池化層(pooling)介紹:pooling一方面使特征圖變小,簡化網絡計算復雜度。一方面通過多次池化壓縮特征,提取主要特征。屬于下采樣過程。常用函數:Max Pooling(最大池化)、Average Pooling(平均池化)等。MaxPooling 與 AvgPooling用法:1. 當需綜合特征圖上的所有信息做相應決策時,通常使用AvgPooling,例如在圖像分割領域中用Global AvgPooling來獲取全局上下文信息;在圖像分類中在最后幾層中會使用AvgPooling。2. 在圖像分割/目標檢測/圖像分類前面幾層,由于圖像包含較多的噪聲和目標處理無關的信息,因此在前幾層會使用MaxPooling去除無效信息。
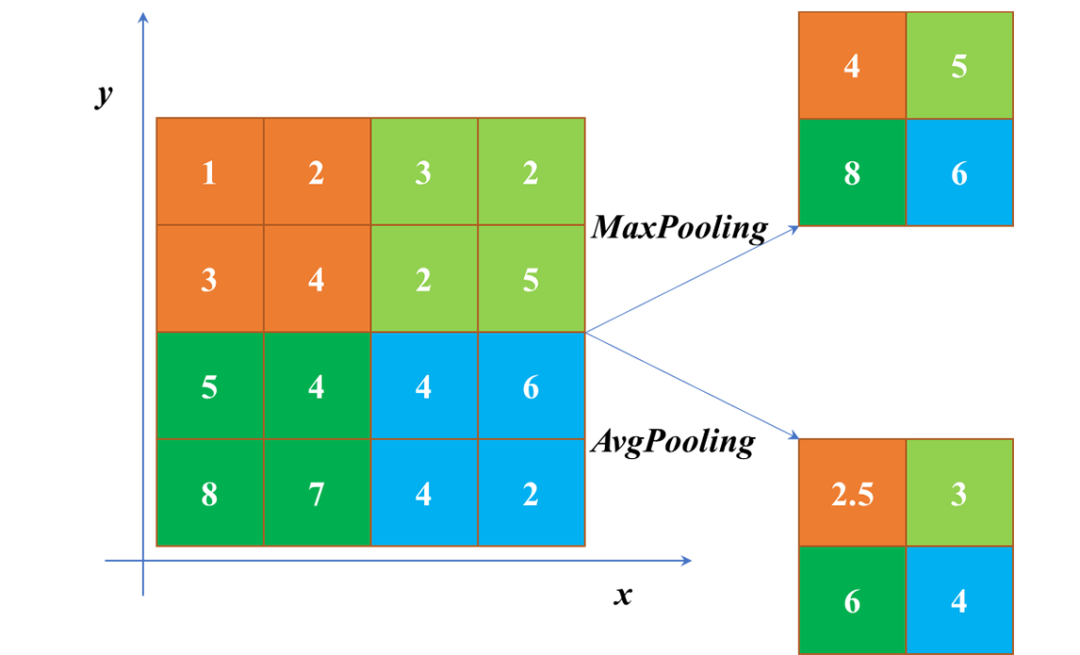
補充:上采樣層重置圖像大小為上采樣過程,如Resize,雙線性插值直接縮放,類似于圖像縮放,概念可見最鄰近插值算法和雙線性插值算法。實現函數有nn.functional.interpolate(input, size = None, scale_factor = None, mode = 'nearest', align_corners = None)和nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, output_padding = 0, bias = True)
5. FC層(全連接層)介紹:連接所有的特征,將輸出值送給分類器。主要是對前層的特征進行一個加權和(卷積層是將數據輸入映射到隱層特征空間),將特征空間通過線性變換映射到樣本標記空間(label)。全連接層可以通過1 x 1卷機+global average pooling代替。可以通過全連接層參數冗余,全連接層參數和尺寸相關。常用函數:nn.Linear(in_features, out_features, bias)
 補充:分類器包括線性分類器與非線性分類器。
補充:分類器包括線性分類器與非線性分類器。| 分類器 | 介紹?? | 常見種類 | 優缺點 |
| 線性分類器 | 線性分類器就是用一個“超平面”將正、負樣本隔離開 | LR、Softmax、貝葉斯分類、單層感知機、線性回歸、SVM(線性核)等 | 線性分類器速度快、編程方便且便于理解,但是擬合能力低 |
| 非線性分類器 | 非線性分類器就是用一個“超曲面”或者多個超平(曲)面的組合將正、負樣本隔離開(即,不屬于線性的分類器) | 決策樹、RF、GBDT、多層感知機、SVM(高斯核)等 | 非線性分類器擬合能力強但是編程實現較復雜,理解難度大 |
6. 損失層介紹:設置一個損失函數用來比較網絡的輸出和目標值,通過最小化損失來驅動網絡的訓練。網絡的損失通過前向操作計算,網絡參數相對于損失函數的梯度則通過反向操作計算。
常用函數:分類問題損失(離散值:分類問題、分割問題):nn.BCELoss、nn.CrossEntropyLoss等。回歸問題損失(連續值:推測問題、回歸分類問題):nn.L1Loss、nn.MSELoss、nn.SmoothL1Loss等。
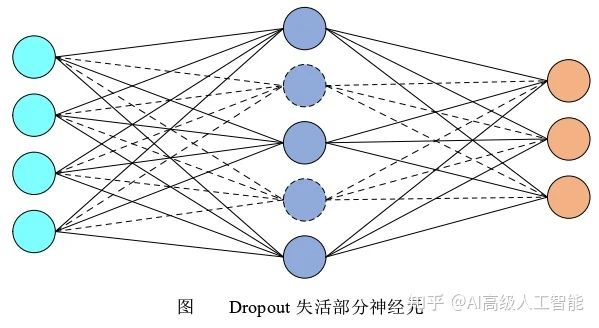
7. Dropout層
介紹:在不同的訓練過程中隨機扔掉一部分神經元,以防止過擬合,一般用在全連接層。在測試過程中不使用隨機失活,所有的神經元都激活。?????????????????????
常用函數:nn.dropout8. 優化器介紹:為了更高效的優化網絡結構(損失函數最小),即是網絡的優化策略,主要方法如下:
| 解釋?? | 優化器種類? | 特點 |
| 基于梯度下降原則(均使用梯度下降算法對網絡權重進行更新,區別在于使用的樣本數量不同)?????? | GD(梯度下降); SGD(隨機梯度下降,面向一個樣本); BGD(批量梯度下降,面向全部樣本); MBGD(小批量梯度下降,面向小批量樣本)????? | 引入隨機性和噪聲 |
| 基于動量原則(根據局部歷史梯度對當前梯度進行平滑) |
Momentum(動量法); NAG(Nesterov Accelerated Gradient) ??? |
加入動量原則,具有加速梯度下降的作用???? |
| 自適應學習率(對于不同參數使用不同的自適應學習率;Adagrad使用梯度平方和、Adadelta和RMSprop使用梯度一階指數平滑,RMSprop是Adadelta的一種特殊形式、Adam吸收了Momentum和RMSprop的優點改進了梯度計算方式和學習率)??? | Adagrad; Adadelta; RMSprop; Adam????? | 自適應學習 |
補充:卷積神經網絡正則化是為減小方差,減輕過擬合的策略,方法有:L1正則(參數絕對值的和); L2正則(參數的平方和,weight_decay:權重衰退)。
9. 學習率?介紹:學習率作為監督學習以及深度學習中重要的超參,其決定著目標函數能否收斂到局部最小值以及合適收斂到最小值。合適的學習率能夠使目標函數在合適的時間內收斂到局部最小值。????
常用函數:torch.optim.lr_scheduler; ExponentialLR; ReduceLROnplateau; CyclicLR等。???????
卷積神經網絡的常見結構
常見結構有:跳連結構(ResNet)、并行結構(Inception V1-V4即GoogLeNet)、輕量型結構(MobileNetV1)、多分支結構(SiameseNet; TripletNet; QuadrupletNet; 多任務網絡等)、Attention結構(ResNet+Attention)
| 結構???????????? | 介紹與特點 | 圖示 |
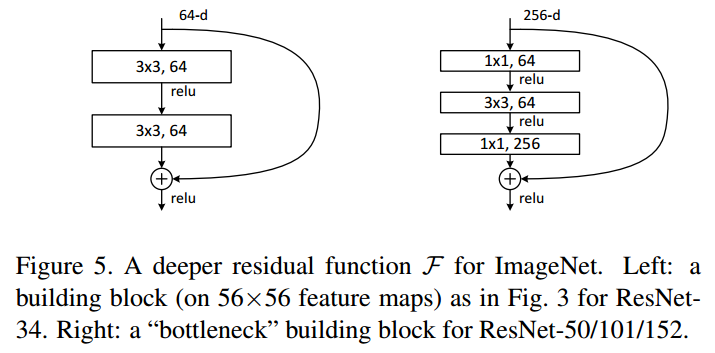
| 跳連結構(代表:ResNet) | 2015年何愷明團隊提出。引入跳連的結構來防止梯度消失問題,今兒可以進一步加大網絡深度。擴展結構有:ResNeXt、DenseNet、WideResNet、ResNet In ResNet、Inception-ResNet等??????????????? |
|
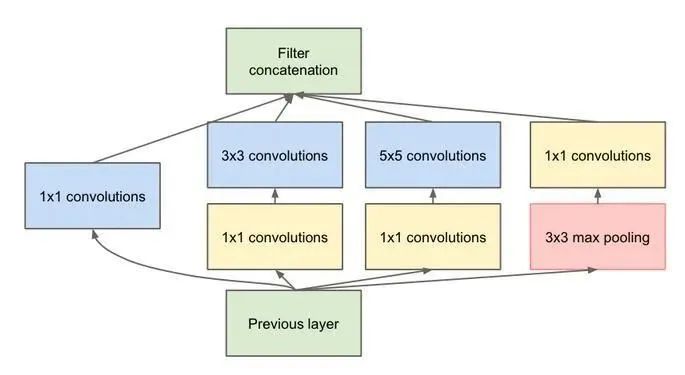
| 并行結構(代表:Inception V1-V4) | 2014年Google團隊提出。不僅強調網絡的深度,還考慮網絡的寬度。其使用1×1的卷積來進行升降維,在多個尺寸上同時進行卷積再聚合。其次利用稀疏矩陣分解成密集矩陣計算的原理加快收斂速度。?? |
|
| 輕量型結構(代表:MobileNetV1) | 2017年Google團隊提出。為了設計能夠用于移動端的網絡結構,使用Depth-wise Separable Convolution的卷積方式代替傳統卷積方式,以達到減少網絡權值參數的目的。擴展結構有:MobileNetV2、MobileNetV3、SqueezeNet、ShuffleNet V1、ShuffleNet V2等???????? |
|
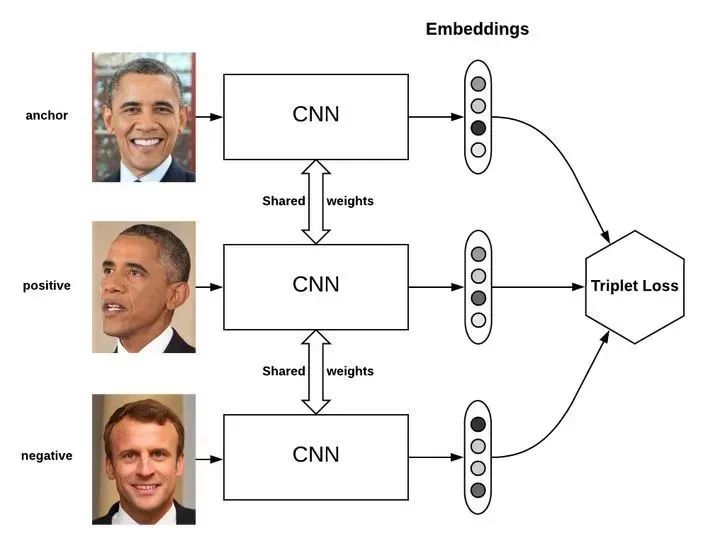
| 多分支結構(代表:TripletNet)? | 基于多個特征提取方法提出,通過比較距離來學習有用的變量。該網絡由3個具有相同前饋網絡(共享參數)組成的,需要輸入是3個樣本,一個正樣本和兩個負樣本,或者一個負樣本和兩個正樣本。訓練的目標是讓相同類別之間的距離竟可能的小,讓不同的類別之間距離竟可能的大。常用于人臉識別。 |
|
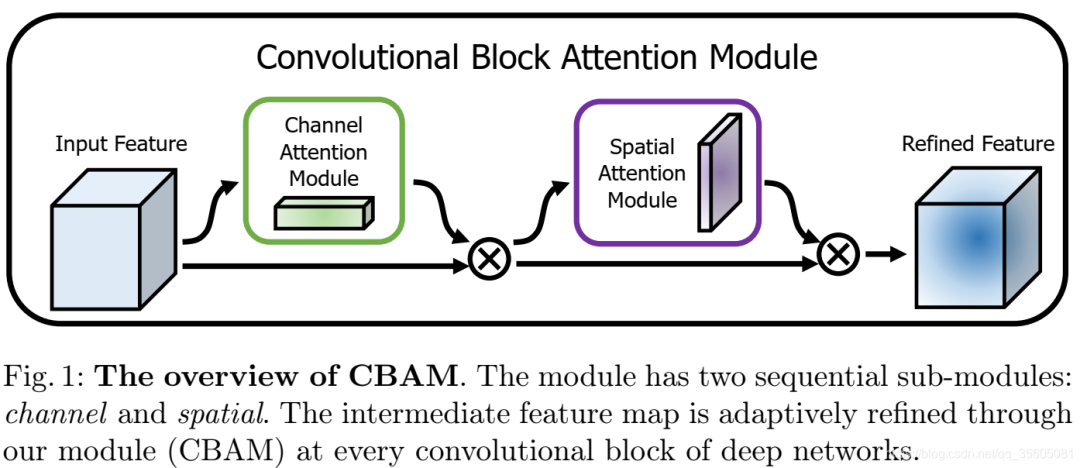
| Attention結構(代表:ResNet+Attention) | 對于全局信息,注意力機制會重點關注一些特殊的目標區域,也就是注意力焦點,進而利用有限的注意力資源對信息進行篩選,提高信息處理的準確性和效率。注意力機制有Soft-Attention和Hard-Attention區分,可以作用在特征圖上、尺度空間上、channel尺度上和不同時刻歷史特征上等。?????????????? |
|
END
歡迎加入Imagination GPU與人工智能交流2群

(添加請備注公司名和職稱)
推薦閱讀 對話Imagination中國區董事長:以GPU為支點加強軟硬件協同,助力數字化轉型Imagination Technologies是一家總部位于英國的公司,致力于研發芯片和軟件知識產權(IP),基于Imagination IP的產品已在全球數十億人的電話、汽車、家庭和工作 場所中使用。獲取更多物聯網、智能穿戴、通信、汽車電子、圖形圖像開發等前沿技術信息,歡迎關注 Imagination Tech!
原文標題:卷積神經網絡結構組成與解釋
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
-
imagination
+關注
關注
1文章
573瀏覽量
61316
原文標題:卷積神經網絡結構組成與解釋
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論