") 現(xiàn)代異步存儲訪問API探索:libaio、io_uring和SPDK
現(xiàn)代異步存儲訪問API探索:libaio、io_uring和SPDK
【摘要】
最近的高性能存儲設(shè)備暴露了現(xiàn)有軟件棧的低效,因而催生了對I/O棧的改進(jìn)。Linux內(nèi)核的最新API是io_uring。作者提供了第一個針對io_uring的深度研究,并且和libaio、SPDK比較,探討它的下性能和優(yōu)缺點。根據(jù)作者的發(fā)現(xiàn),(1)輪詢能極大影響性能(2)只要CPU核足夠多,io_uring可以提供和SPKD接近的性能(3)在多核CPU和多設(shè)備場景下擴(kuò)展需要仔細(xì)的考慮并且需要一個混合方案。最后,作者為存儲密集的應(yīng)用開發(fā)者提供了設(shè)計指導(dǎo)。
【三種API簡介】
1、libaio
傳統(tǒng)的同步I/O接口包括read()、write()、pread()、pwrite()等,線程開始I/O操作后立刻進(jìn)入阻塞狀態(tài),直到I/O請求完成。而使用異步I/O接口,如aio,線程把I/O請求發(fā)送給內(nèi)核后可以繼續(xù)做其他工作,直到內(nèi)核把I/O請求完成的信號發(fā)送給線程。通常,異步I/O接口效率更高,其中的核心系統(tǒng)調(diào)用是io_submit(用于提交I/O請求)和io_getevents(用于獲得完成的I/O請求)。然而,在每個I/O操作中,libaio要依賴兩個系統(tǒng)調(diào)用,而且使用中斷的方式通知I/O請求的完成,這導(dǎo)致libaio的單個I/O性能并不好,如下圖。

2、SPDK
SPDK是Linux的高性能API。它在用戶空間映射了PCIe寄存器以配置CQ和SQ,用戶通過輪詢CQ來捕獲I/O請求的完成,而不需要中斷和系統(tǒng)調(diào)用。SPDK的缺點是它很復(fù)雜,而且相對于libaio適用范圍很窄。SPDK不支持文件系統(tǒng),也無法利用內(nèi)核存儲服務(wù),如訪問控制、調(diào)度、QoS和配額管理。
3、io_uring
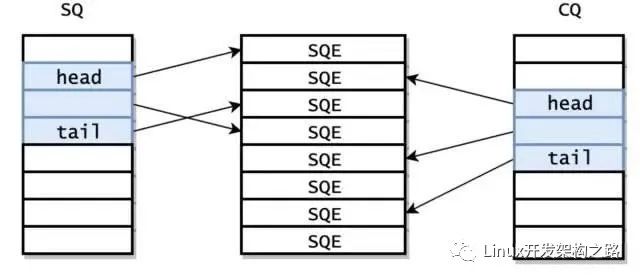
io_uring中和了上述兩類API的優(yōu)缺點。它在用戶空間實現(xiàn)了兩個環(huán)形數(shù)據(jù)結(jié)構(gòu),同時內(nèi)核可以訪問它們,類似于NVMe的CQ和SQ,submission ring存儲了用戶提交的I/O請求,completion存儲了I/O請求的完成結(jié)果。用戶可以不通過系統(tǒng)調(diào)用插入和檢索兩個環(huán)。
io_uring提供的I/O機制有三種,如下圖:
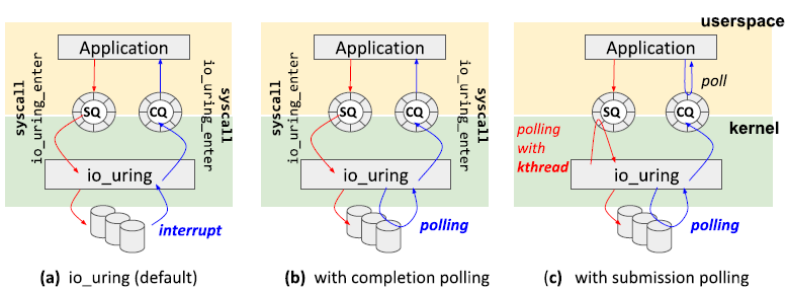
默認(rèn)模式下,用戶可以通過io_uring_enter系統(tǒng)調(diào)用通知內(nèi)核新請求已經(jīng)提交到SQ中。用戶使用同一個io_uring_enter系統(tǒng)調(diào)用等待I/O請求完成。io_uring_enter支持中斷模式(a)和輪詢模式(b)。當(dāng)然,因為用戶也可以訪問CQ,所以用戶可以自己輪詢CQ等待I/O請求完成,而不使用任何系統(tǒng)調(diào)用。并且,io_uring也可以使用一個內(nèi)核線程輪詢SQ,這樣在整個I/O操作中不會使用任何系統(tǒng)調(diào)用(c)。
【性能測試分析】
實驗使用fio生成4KB隨機讀負(fù)載,不使用page cache。純讀負(fù)載能達(dá)到更高的IOPS,而高IOPS有助于分析不同API的可擴(kuò)展性趨勢和每個I/O操作的開銷。除了io_uring外,其他API均使用默認(rèn)配置。io_uring的配置如下:
(1)iou:上圖(a)的配置(默認(rèn)的fio參數(shù))
(2)iou+p:上圖(b)的配置(fio參數(shù)是hipri)
(3)iou+k:不使用系統(tǒng)調(diào)用,即使用內(nèi)核線程輪詢I/O的提交,同時應(yīng)用輪詢I/O的完成(fio的參數(shù)是sqthread_poll)
環(huán)境配置如下表:

P.S. 雖然io_uring里提供了io_uring_enter作為提交I/O請求和捕獲完成的I/O請求的統(tǒng)一接口,但FIO里面還是分開使用了(即調(diào)用了兩次io_uring_enter)。
1、理解輪詢
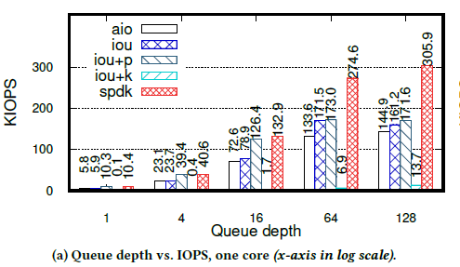
作者使用單個fio job、單個NVMe驅(qū)動和單個CPU,在不同隊列深度下,測試三種API(libaio、io_uring和SPDK)的KIOPS,如下圖:
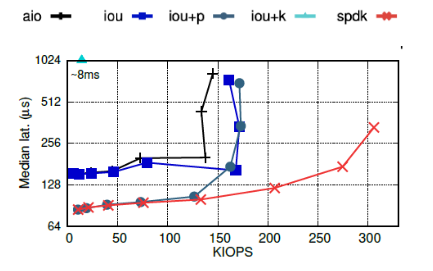
每個IOPS下對應(yīng)的延遲中位數(shù)如下圖:
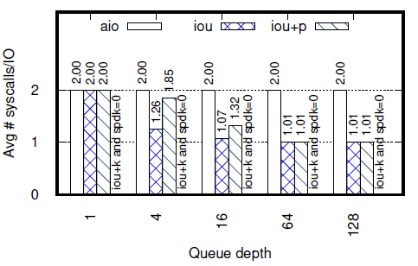
平均每個I/O操作進(jìn)行的系統(tǒng)調(diào)用個數(shù)如下圖:
① 可知,iou+k的KIOPS僅僅13,比其他API少一個數(shù)量級。因為此時fio線程和內(nèi)核輪詢線程共享一個CPU,減少了FIO每秒處理的I/O請求的數(shù)量。同時,iou+k的延遲是8ms,比其他API慢1~2個數(shù)量級。iou+k的延遲不隨KIOPS的變化而變化,因為此時的延遲取決于CPU資源的競爭,而非排隊等待。
當(dāng)CPU數(shù)量增加到2時,iou+k的性能完全恢復(fù)了,如下圖:
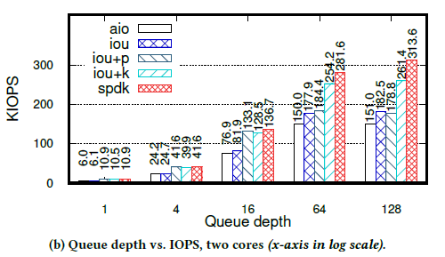
每個KIOPS對應(yīng)的延遲中位數(shù)為:
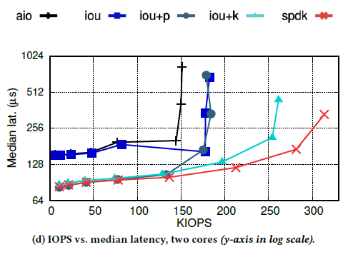
此時,iou+k的性能僅次于SPDK:最大帶寬比SPDK小18%,延遲和SPDK相當(dāng)。
②SPDK在所有場景下性能最好,也是唯一達(dá)到驅(qū)動帶寬上限的API。SPDK和iou+k的區(qū)別在于,iou+k使用兩個線程訪問同一個變量,會產(chǎn)生原子訪問和緩存失效的開銷,而SPDK使用一個線程,能更加充分的利用資源。
③ 當(dāng)IOPS較小時,iou+p的性能和SPDK接近,因為隊列深度較小時,系統(tǒng)調(diào)用的開銷還不足以成為性能瓶頸,此時系統(tǒng)態(tài)輪詢和用戶態(tài)輪詢的性能接近。類似的還有iou和libaio,當(dāng)隊列深度小于16時,二者KIOPS和延遲都很接近,當(dāng)隊列深度大于16后,iou的KIOPS和延遲比libaio要好——因為iou使用的系統(tǒng)調(diào)用比libaio少,所以可以更加充分的利用CPU資源。
當(dāng)隊列深度小于16時,iou的系統(tǒng)調(diào)用比iou+p少,但延遲比iou+p高。原因是,隊列較淺時,fio的隊列很快會被填滿,而當(dāng)隊列滿時,fio會等待至少一個請求完成再進(jìn)行下一步動作。此時,雖然中斷比較慢,但iou可能會一次處理較多完成的請求,而輪詢則是檢測到一個請求完成就退出,從而錯失了批量處理多個完成的請求的機會。當(dāng)隊列深度增加時,兩個API最后都趨向于每個I/O請求只使用1個系統(tǒng)調(diào)用。
iou和libaio的最大區(qū)別是,iou多了一個提交隊列(SQ),這就是它具有批處理能力的原因。
2、不同的CPU-設(shè)備比
作者進(jìn)一步分析了對于iou+k,每個驅(qū)動需要多少個CPU以獲得最佳性能。此時,作者使用了J=5個FIO job測試,每個job運行在不同的驅(qū)動上,隊列深度為128,C代表CPU的數(shù)目,本次實驗中,分別測試了C=J,C=J+1,C=J+2和C=J*2的情況。
注意,在iou+k中,內(nèi)核會為每個job產(chǎn)生一個內(nèi)核線程以輪詢SQ獲得提交的請求。
實驗結(jié)果如下圖:
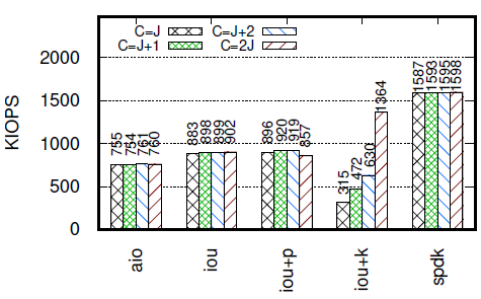
可見,除了iou+k,其他API的帶寬表現(xiàn)和CPU-設(shè)備比無關(guān)。而iou+k需要兩倍于驅(qū)動數(shù)的CPU才能達(dá)到最好的性能——即每個線程需要一個單獨的CPU來輪詢。糟糕的是,當(dāng)CPU數(shù)不是最佳時,iou+k的KIOPS是最低的。這一實驗結(jié)果揭示了iou+k要實現(xiàn)高性能的隱藏開銷,而其他測試忽略了這一點。
3、可擴(kuò)展性
作者控制job從1到20,以測試不同API的可擴(kuò)展性。每個job訪問不同的驅(qū)動,設(shè)置CPU數(shù)C=2*J(由于硬件限制,C最大可以取到20),隊列深度為128。下圖是測試結(jié)果:
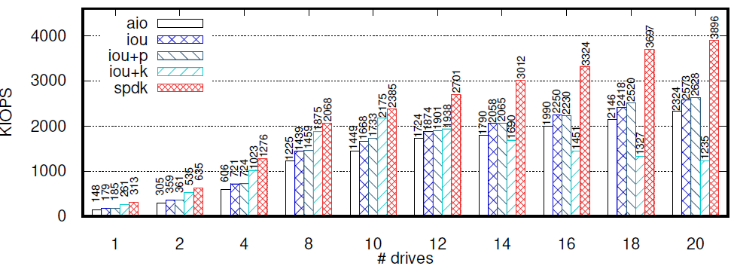
SPDK的性能總是最好的,而性能第二好的API取決于job的數(shù)量和CPU核的數(shù)量。當(dāng)J不大于10時,iou+k可以給每個內(nèi)核線程分配一個CPU,性能最好。此后隨著J的增大,內(nèi)核線程和應(yīng)用線程開始搶奪CPU資源,KIOPS開始下滑。在J=12時,iou+k和iou、iou+p的KIOPS交匯,在J=14時,iou+k成為性能最差的API。其他的API隨著job的增長,KIOPS也基本上穩(wěn)定增長。
iou和iou+p的性能很接近,libaio的帶寬也僅僅比iou、iou+p少10%。
【總結(jié)與討論】
1、不同的輪詢方式各有特點
lSPDK的優(yōu)勢不僅僅體現(xiàn)在用戶態(tài)輪詢、無系統(tǒng)調(diào)用開銷,還體現(xiàn)在使用單個線程進(jìn)行輪詢。
liou+k的優(yōu)勢在CPU不夠時不明顯。
liou+p使用系統(tǒng)級輪詢,在隊列深度較小時可以和SPDK相當(dāng)。
2、io_uring在特定配置下的性能接近SPDK
3、性能的可擴(kuò)展性需要仔細(xì)考慮
雖然SPDK的性能最好,但需要放棄Linux文件的支持。如果需要使用文件系統(tǒng),且CPU足夠多,iou+k是不錯的選擇(可以達(dá)到90% SPDK的性能),而若CPU資源不足,可以使用iou+p,當(dāng)隊列深度不深時和SPDK的性能接近。
未來可以在更在實際的I/O密集型應(yīng)用上測試,如數(shù)據(jù)庫。它們都需要文件系統(tǒng)的支持,可能會帶來額外的同步開銷,可能會覆蓋I/O路徑上的bottleneck。此外還可以研究更高效的iou+k設(shè)計,如不同的應(yīng)用線程共享一個內(nèi)核輪詢線程,或者二者更好的使用CPU資源等。最后,io_uring支持socket I/O,所以它的性能也可以測試以評估網(wǎng)絡(luò)應(yīng)用的表現(xiàn)。
審核編輯:湯梓紅
-
cpu
+關(guān)注
關(guān)注
68文章
10854瀏覽量
211587 -
接口
+關(guān)注
關(guān)注
33文章
8575瀏覽量
151021 -
存儲
+關(guān)注
關(guān)注
13文章
4296瀏覽量
85801 -
API
+關(guān)注
關(guān)注
2文章
1499瀏覽量
61965 -
線程
+關(guān)注
關(guān)注
0文章
504瀏覽量
19675
原文標(biāo)題:現(xiàn)代異步存儲訪問API探索:libaio、io_uring和SPDK
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
請教關(guān)于c6747的EMIFA訪問外部16位異步存儲設(shè)備的地址總線問題
異步IO是什么
《Linux設(shè)備驅(qū)動開發(fā)詳解》第9章、Linux設(shè)備驅(qū)動中的異步通知與異步IO
超全的SPDK性能評估指南
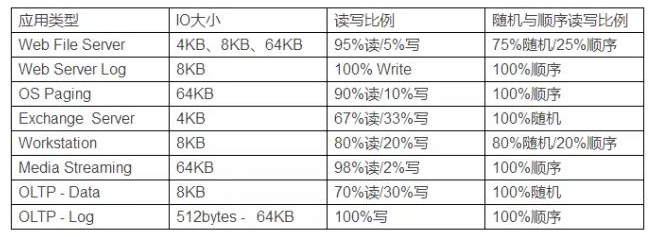
不同應(yīng)用程序的存儲IO類型解析
io_uring 優(yōu)化 nginx,基于通用應(yīng)用 nginx 的實戰(zhàn)
SPDK Thread模型設(shè)計與實現(xiàn) NVMe-oF的使用案例
Linux 6.0生命周期結(jié)束介紹
信號驅(qū)動IO與異步IO的區(qū)別
linux異步io框架iouring應(yīng)用
異步IO框架iouring介紹
SPDK在虛擬化場景下的使用方法
io_uring內(nèi)核各個組件的性能
λ-IO:存儲計算下的IO棧設(shè)計






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論