") 大模型如何快速構(gòu)建指令遵循數(shù)據(jù)集
大模型如何快速構(gòu)建指令遵循數(shù)據(jù)集
一、概述
1 Motivation
構(gòu)造instruction data非常耗時耗力,常受限于質(zhì)量,多樣性,創(chuàng)造性,阻礙了instruction-tuned模型的發(fā)展。
背景:instruction-tuned方法是指利用非常多的指令數(shù)據(jù)【人類instructions指令和respond回答數(shù)據(jù)】去finetuned LLM模型,讓模型能夠理解人類指令,訓(xùn)練后使其對新的任務(wù)有非常強的zero-shot能力。
2 Methods
方法概述:本文提出self-instruct框架,通過bootstrapping off方法讓原始的LM模型直接生成instruction數(shù)據(jù),通過過濾和篩選后,產(chǎn)生大量的insturction指令數(shù)據(jù)(多樣性和效果都不錯),進而可以極大降低instruction數(shù)據(jù)的構(gòu)建成本。
方法步驟總結(jié):通過少量種子數(shù)據(jù) + LM模型本身(未經(jīng)過tuned模型)=> 生成instruction(指令)+ input(指令提到的輸入,可以為空)+ output(響應(yīng)輸出)=> 然后filters過濾無效和相似的樣本 => 來構(gòu)造非常多的instruction指令遵循數(shù)據(jù),詳細(xì)步驟如下:
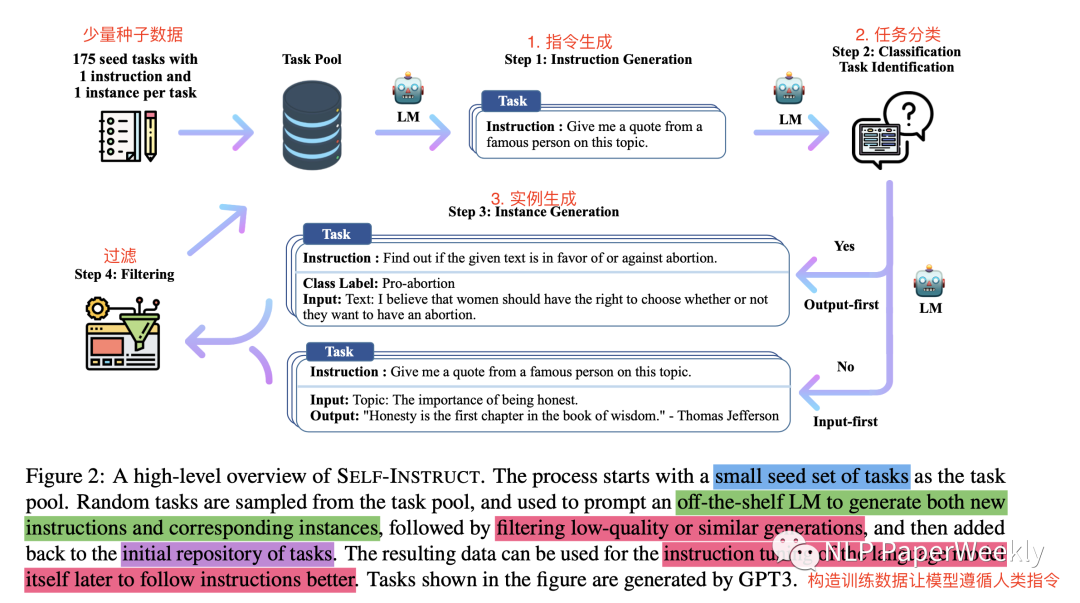
2.1 Defining Instruction Data
Instruction:指令
X:根據(jù)instruction,X可能為空或者不為空。例如:輸入X為空的Instruction:write an essay about school safety,輸入不為空的Instruction:write an essay about the following topic
Y:答案,只根據(jù)X或者Instruction理想的response回答
2.2 Automatic Instruction Data Generation
Instruction Generation:使用175個種子數(shù)據(jù)來生成新的Instruction,每一步采用8-few-shot的策略,其中6個是人類寫的,2個是機器生成的。

Classification Task Identification:利用LM采用few-shot的方式來預(yù)測1中生成的instructions是否為分類任務(wù),采用12個分類任務(wù),19個非分類任務(wù)作為few-shot的例子。

2.3 Instance Generation:采用兩種方法來生成實例X和Y
輸入優(yōu)先方法(Input-first Approach),首先根據(jù)說明提出輸入字段X,然后產(chǎn)生相應(yīng)的輸出Y,這里task就是input X,output就是輸出Y,也是通過in-context learning來做的,主要處理非分類的實例生成。

分類任務(wù)的輸出優(yōu)先方法(Output-first Approach),先生成可能的類標(biāo)簽,然后生成對應(yīng)句子【這么做是為了控制正負(fù)樣本比例】

2.4Filtering and Postprocessing
過濾相似度比較高的,和已有的樣本ROUGE-L小于0.7的才要
過濾image,picture,graph通常LLM無法處理的詞
過濾instruction相同但是answer不同的
過濾太長或者太短
2.5FineTuning
采用多個templates模版,來encode instruction和instance進行訓(xùn)練,提升不同格式的魯棒性。
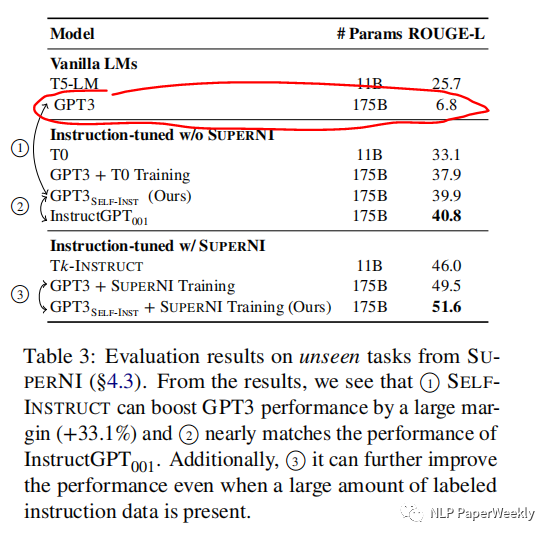
3 Conclusion
比原始的GPT-3模型,絕對提升了33%,并且達到了差不多追上InstructGPT001的效果。就算利用公開的instruct數(shù)據(jù),也有不錯的提升。
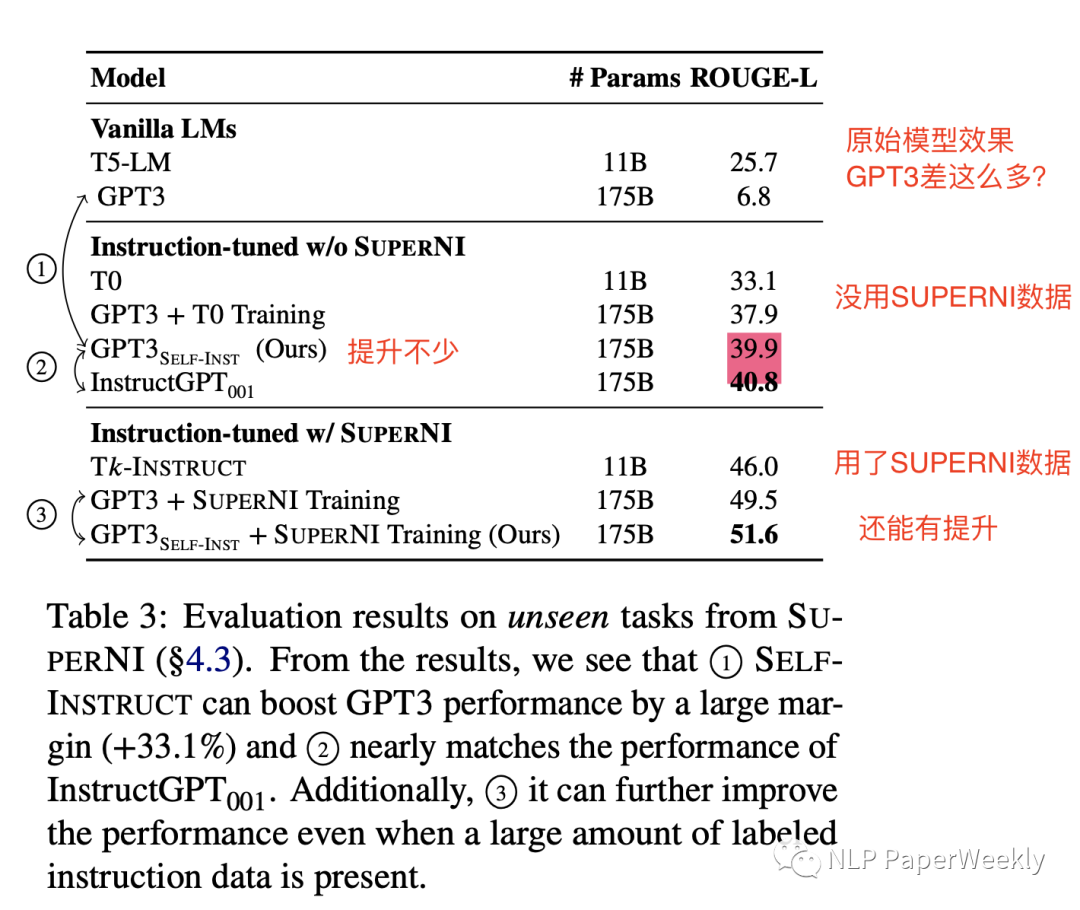
總結(jié):
就用了175個原始種子數(shù)據(jù),利用GPT3接口finetuned模型,比原始的GPT3高了33個點,并且居然和InstructGPT001效果差不太多了。
有了充分的訓(xùn)練數(shù)據(jù),在SUPERNI數(shù)據(jù)集(其更偏向于研究領(lǐng)域任務(wù),與人類的Instruction的分布還是有差異,后續(xù)也針對真實的人類Instruction分布做了實驗)上訓(xùn)練,用了本文提出的self-instruct還是有2個點的提升。
self-instruct提供了一個不用大量標(biāo)注就能讓原始的LM(未經(jīng)過指令學(xué)習(xí)的模型)學(xué)習(xí)理解人類指令的解決方案,極大地降低指令數(shù)據(jù)的生成和標(biāo)注成本。
本文發(fā)布了大規(guī)模的synthetic數(shù)據(jù)集,方便后續(xù)大家進行instruction tuning的研究。
4 limitation
長尾效應(yīng)還比較嚴(yán)重:self-instruct依賴于LMs生成數(shù)據(jù),會繼承LM的缺陷,偏向于出現(xiàn)頻率高的詞。在常見的指令上效果可能不錯,在長尾樣本上可能效果比較差。
依賴大模型:依賴大模型的歸納偏差(inductive biases),可能只在大模型上效果比較好,由于大模型資源要求比較大,這也限制了小模型的使用。
可能會增強LM的偏見:可能會放大social bias,例如模型可能無法產(chǎn)生比較balanced的label。
二、詳細(xì)內(nèi)容
1 評估本文self-instruct在用戶實際需求的Instructions上是否有效果

背景:SUPERNI數(shù)據(jù)更偏向于研究任務(wù),這里通過頭腦風(fēng)暴構(gòu)造了一些更偏向用戶實際需求的Instructions,來檢驗self-instruct的效果,還是和InstructGPT系列來比較
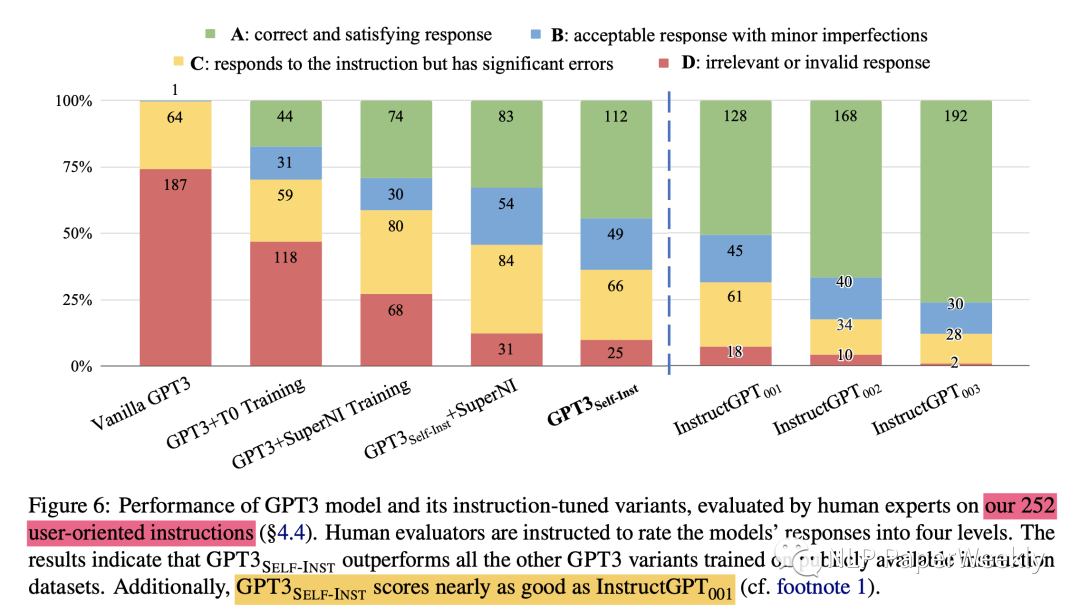
結(jié)論:效果也基本接近InstructGPT001,說明了其有效性,這里只使用了252個種子數(shù)據(jù),也可以極大地降低Instruction構(gòu)建的成本。
2 評估使用本文self-instruct方法擴充的Instruction是否真的有用
方法:從Instruction數(shù)量、回復(fù)response質(zhì)量兩個角度來進行試驗,其中response質(zhì)量對比是通過蒸餾更好模型的response來做的實驗。
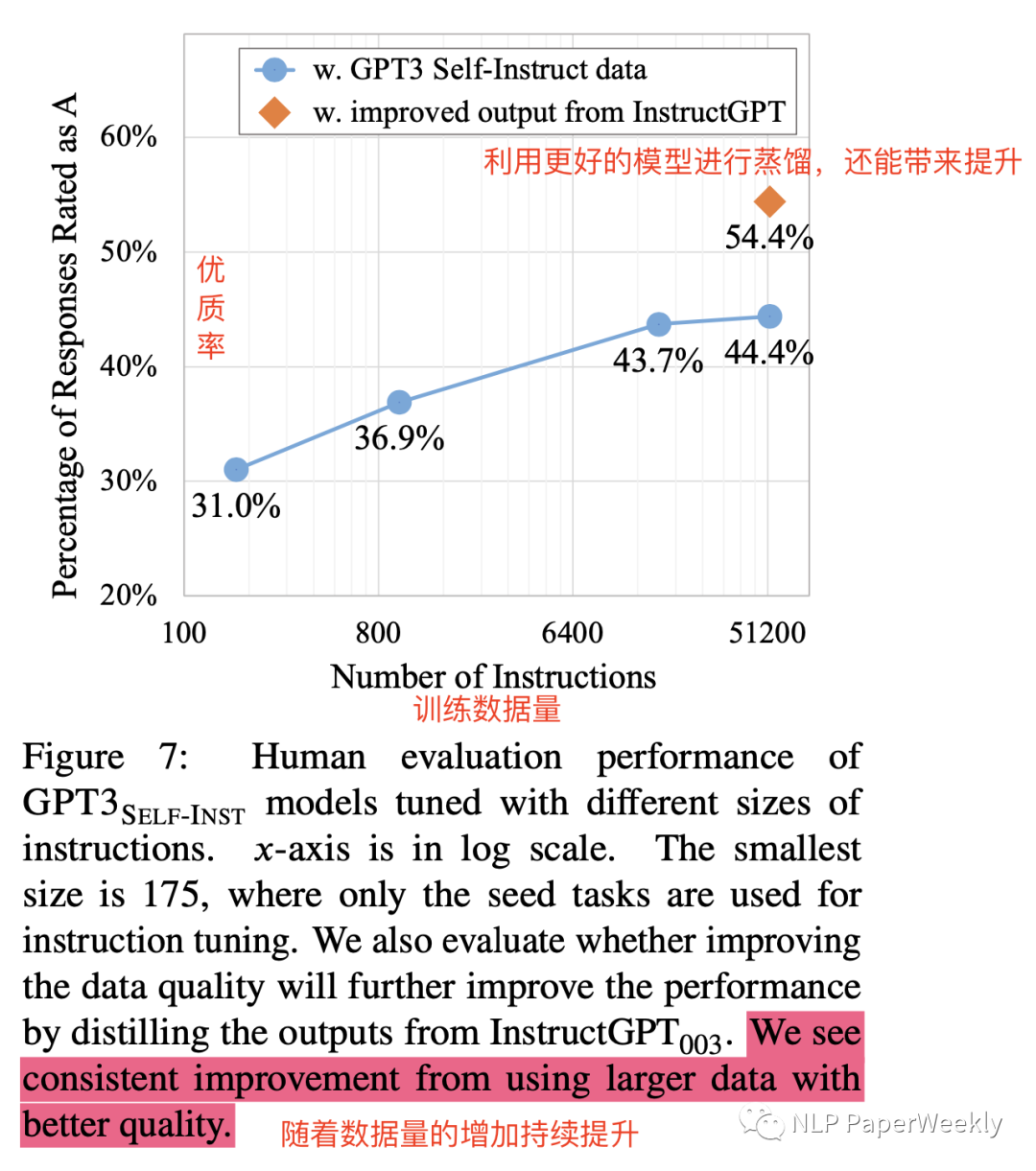
實驗1:評估擴充的訓(xùn)練數(shù)據(jù)量級對效果的影響
方法:從最開始的175個種子數(shù)據(jù),逐步增加數(shù)據(jù)量,評估效果。
結(jié)論:大概訓(xùn)練數(shù)據(jù)在16K左右,效果就比較平了,帶來的提升沒那么大了。
實驗2:評估生成的response的質(zhì)量對效果的影響(從更好的模型InstructGPT蒸餾得到更好的response)
結(jié)論:44.4%提升到54.4%,說明更好的回復(fù)質(zhì)量對模型的提升也是巨大的。
3 生成的數(shù)據(jù)量級
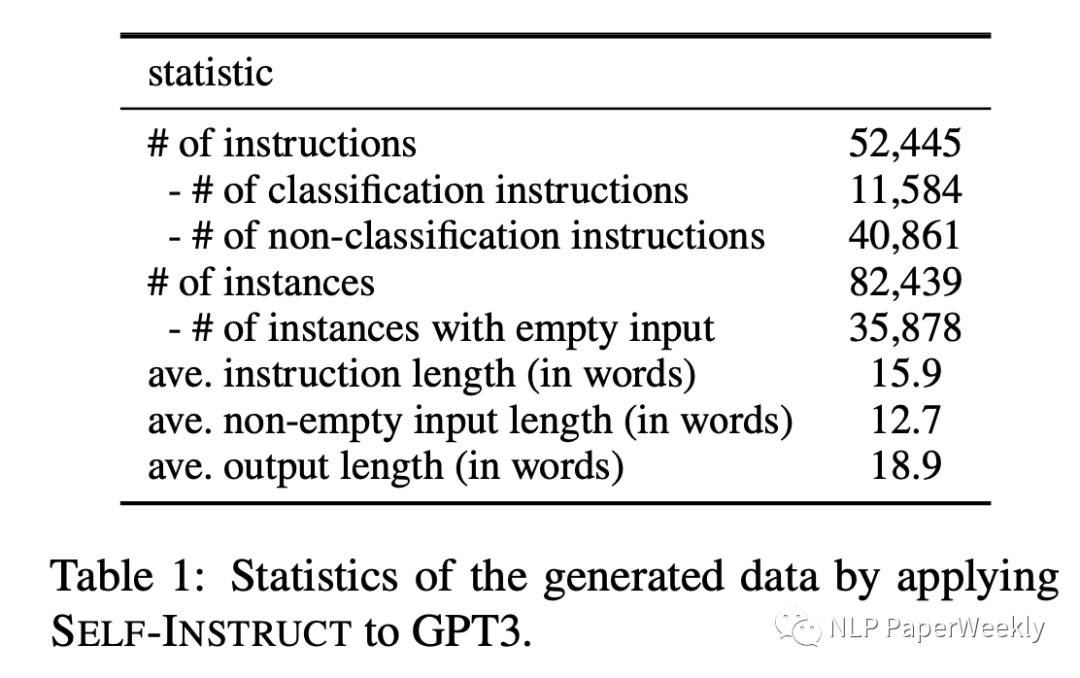
訓(xùn)練GPT3的數(shù)據(jù)量級:52k個Instruction數(shù)據(jù),82k個實例。
4 生成的數(shù)據(jù)的多樣性

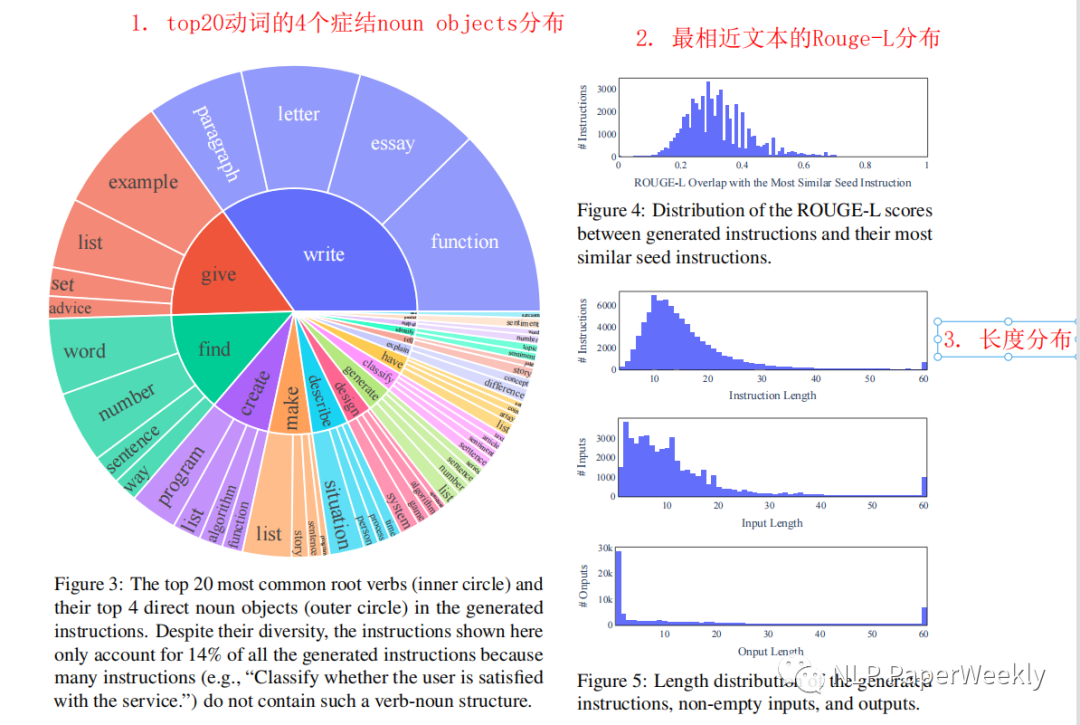
評估方法1:挑選top20最常見的動詞,然后畫出其top4的直接noun object分布,衡量整體的數(shù)據(jù)分布。
評估方法2:畫出與種子數(shù)據(jù)中,最相近文本的Rouge-L的分布,衡量與種子數(shù)據(jù)的分布差異。
結(jié)論:發(fā)現(xiàn)多樣性還不錯,這也是生成的數(shù)據(jù)能讓模型學(xué)會通用的指令遵循的原因之一。
5 生成數(shù)據(jù)的質(zhì)量
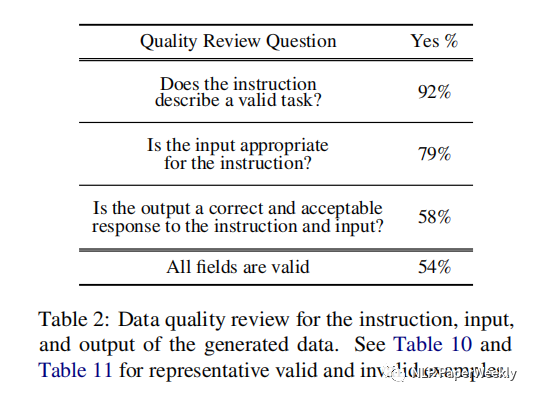
統(tǒng)計指標(biāo):隨機挑選200個指令,每個指令隨機挑選一個實例來標(biāo)注
指令有效率:92%
input與指令一致:79%
output正確(能很好地響應(yīng)Instruction和input的要求):58%
各個場景都有效:54%
總結(jié):盡管生成的數(shù)據(jù)還是包含誤差,但是大多數(shù)還是正確的,可以提供有用的指導(dǎo),讓模型能學(xué)會遵循人類指令。
三、個人總結(jié)
相當(dāng)于驗證了少量種子數(shù)據(jù) + 原始預(yù)訓(xùn)練模型 => 生成大批量 多樣性 + 質(zhì)量還不錯的 指令數(shù)據(jù)的可行性 => 好處是可以極大降低指令遵循數(shù)據(jù)集構(gòu)建的成本。
這篇文章解釋了為什么大模型能聽懂人類指令的困惑,可以看出,原始的GPT-3模型學(xué)習(xí)了非常多的知識,但是人類指令遵循的能力非常非常差,通過self-instruct構(gòu)造大量的多樣、高質(zhì)量的指令數(shù)據(jù)和答案,模型就開始能聽懂指令,理解這個指令的具體含義,并給出人類期望的respond響應(yīng)。其中指令的【多樣性】和回復(fù)的【質(zhì)量】是非常關(guān)鍵的兩個因素。
對于如何對齊人類的價值觀:可以參考復(fù)旦moss模型【參考資源1】,也是構(gòu)造了非常多的對人類無害的種子數(shù)據(jù),然后利用模型生成非常多的指令遵循數(shù)據(jù),讓模型盡可能的生成無害的結(jié)果,從另一個角度看,如果不法分子誘導(dǎo)模型去生成暴力傾向等不符合人類期望的答案,那么可能會訓(xùn)練出毒性非常大的模型,這也是非常恐怖的,難怪微軟的文章說原始的gpt-3.5系列可能具備更強的能力,說明OpenAI在這方面做了非常強的約束。也難怪OpenAI強烈建議對大模型進行監(jiān)管。
-
機器
+關(guān)注
關(guān)注
0文章
780瀏覽量
40711 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24689
原文標(biāo)題:ACL2023 | 大模型如何快速構(gòu)建指令遵循數(shù)據(jù)集?Self-Instruct:只需175條種子數(shù)據(jù)追上InstructGPT
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
請問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
高階API構(gòu)建模型和數(shù)據(jù)集使用

sse指令集
Thumb指令集之Thumb編程模型

thumb指令集是什么_thumb指令集與arm指令集的區(qū)別

mips指令集指的是什么
大模型如何快速構(gòu)建指令遵循數(shù)據(jù)集?

如何構(gòu)建高質(zhì)量的大語言模型數(shù)據(jù)集
如何解決LLMs的規(guī)則遵循問題呢?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論