") SA-1B數(shù)據(jù)集的1/50進行訓(xùn)練現(xiàn)有的實例分割方法
SA-1B數(shù)據(jù)集的1/50進行訓(xùn)練現(xiàn)有的實例分割方法
導(dǎo)讀
SAM已經(jīng)成為許多高級任務(wù)(如圖像分割、圖像描述和圖像編輯)的基礎(chǔ)步驟。然而,其巨大的計算開銷限制了其在工業(yè)場景中的廣泛應(yīng)用。這種計算開銷主要來自于處理高分辨率輸入的Transformer架構(gòu)。因此,本文提出了一種具有可比性能的加速替代方法。通過將該任務(wù)重新定義為分割生成和提示,作者發(fā)現(xiàn)一個常規(guī)的CNN檢測器結(jié)合實例分割分支也可以很好地完成這個任務(wù)。具體而言,本文將該任務(wù)轉(zhuǎn)換為經(jīng)過廣泛研究的實例分割任務(wù),并僅使用SAM作者發(fā)布的SA-1B數(shù)據(jù)集的1/50進行訓(xùn)練現(xiàn)有的實例分割方法。使用這種方法,作者在50倍更快的運行時間速度下實現(xiàn)了與SAM方法相當(dāng)?shù)男阅堋1疚奶峁┝顺浞值膶嶒灲Y(jié)果來證明其有效性。
引言
SAM被認為是里程碑式的視覺基礎(chǔ)模型,它可以通過各種用戶交互提示來引導(dǎo)圖像中的任何對象的分割。SAM利用在廣泛的SA-1B數(shù)據(jù)集上訓(xùn)練的Transformer模型,使其能夠熟練處理各種場景和對象。SAM開創(chuàng)了一個令人興奮的新任務(wù),即Segment Anything。由于其通用性和潛力,這個任務(wù)具備成為未來廣泛視覺任務(wù)基石的所有要素。然而,盡管SAM及其后續(xù)模型在處理segment anything任務(wù)方面展示了令人期待的結(jié)果,但其實際應(yīng)用仍然具有挑戰(zhàn)性。顯而易見的問題是與SAM架構(gòu)的主要部分Transformer(ViT)模型相關(guān)的大量計算資源需求。與卷積模型相比,ViT以其龐大的計算資源需求脫穎而出,這對于其實際部署,特別是在實時應(yīng)用中構(gòu)成了障礙。這個限制因此阻礙了segment anything任務(wù)的進展和潛力。
鑒于工業(yè)應(yīng)用對segment anything模型的高需求,本文設(shè)計了一個實時解決方案,稱為FastSAM,用于segment anything任務(wù)。本文將segment anything任務(wù)分解為兩個連續(xù)的階段,即全實例分割和提示引導(dǎo)選擇。第一階段依賴于基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的檢測器的實現(xiàn)。它生成圖像中所有實例的分割掩碼。然后在第二階段,它輸出與提示相對應(yīng)的感興趣區(qū)域。通過利用CNN的計算效率,本文證明了在不太損失性能質(zhì)量的情況下,可以實現(xiàn)實時的segment anything模型。本文希望所提出的方法能夠促進對segment anything基礎(chǔ)任務(wù)的工業(yè)應(yīng)用。
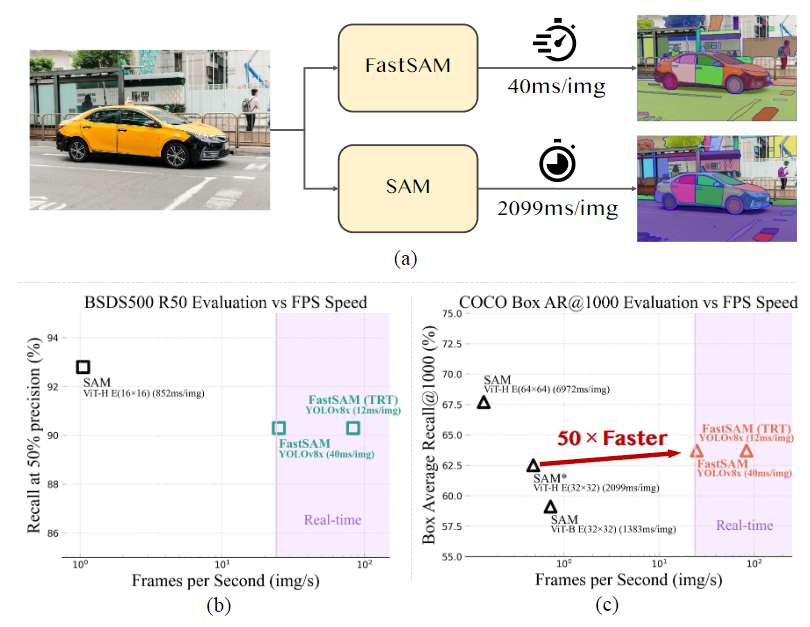
圖1. FastSAM和SAM的性能比較分析
(a) FastSAM和SAM在單個NVIDIA GeForce RTX 3090上的速度比較。(b) 在BSDS500數(shù)據(jù)集[1, 28]上進行邊緣檢測的比較。(c) COCO數(shù)據(jù)集[25]上對象提議的Box AR@1000評估中FastSAM和SAM的比較。SAM和FastSAM都使用PyTorch進行推理,只有FastSAM(TRT)使用TensorRT進行推理。
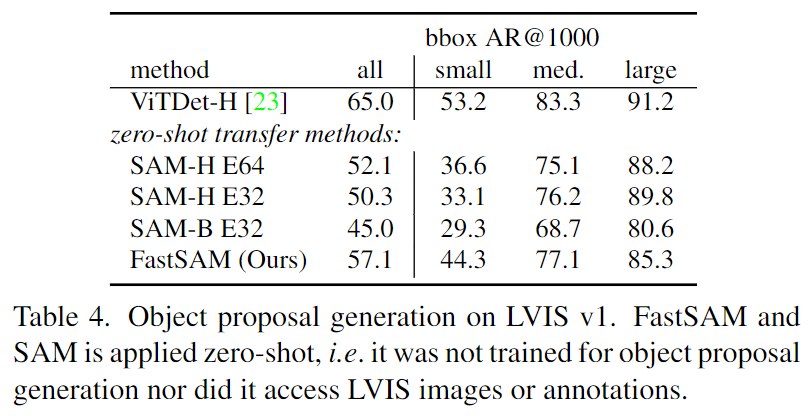
本文提出的FastSAM基于YOLACT方法的實例分割分支的目標(biāo)檢測器YOLOv8-seg。此外,還采用了由SAM發(fā)布的廣泛SA-1B數(shù)據(jù)集,通過僅在SA-1B數(shù)據(jù)集的2%(1/50)上直接訓(xùn)練該CNN檢測器,它實現(xiàn)了與SAM相當(dāng)?shù)男阅埽蟠蠼档土擞嬎愫唾Y源需求,從而實現(xiàn)了實時應(yīng)用。本文還將其應(yīng)用于多個下游分割任務(wù),展示了其泛化性能。在MS COCO 上的對象提議任務(wù)中,該方法在AR1000上達到了63.7,比使用32×32點提示輸入的SAM高1.2點,但在單個NVIDIA RTX 3090上運行速度提高了50倍。
實時的segment anything模型對于工業(yè)應(yīng)用非常有價值。它可以應(yīng)用于許多場景。所提出的方法不僅為大量視覺任務(wù)提供了新的實用解決方案,而且速度非常快,比當(dāng)前方法快幾十倍或幾百倍。此外,它還為通用視覺任務(wù)的大型模型架構(gòu)提供了新的視角。對于特定任務(wù)來說,特定的模型仍然可以利用優(yōu)勢來獲得更好的效率-準(zhǔn)確性平衡。
在模型壓縮的角度上,本文方法通過引入人工先驗結(jié)構(gòu),展示了顯著減少計算量的可行路徑。本文貢獻可總結(jié)如下:
引入了一種新穎的實時基于CNN的Segment Anything任務(wù)解決方案,顯著降低了計算需求同時保持競爭性能。
本研究首次提出了將CNN檢測器應(yīng)用于segment anything任務(wù),并提供了在復(fù)雜視覺任務(wù)中輕量級CNN模型潛力的見解。
通過在多個基準(zhǔn)測試上對所提出的方法和SAM進行比較評估,揭示了該方法在segment anything領(lǐng)域的優(yōu)勢和劣勢。
方法
下圖2展示了FastSAM網(wǎng)絡(luò)架構(gòu)圖。該方法包括兩個階段,即全實例分割和提示引導(dǎo)選擇。前一個階段是基礎(chǔ)階段,第二個階段本質(zhì)上是面向任務(wù)的后處理。與端到端的Transformer方法不同,整體方法引入了許多與視覺分割任務(wù)相匹配的人類先驗知識,例如卷積的局部連接和感受野相關(guān)的對象分配策略。這使得它針對視覺分割任務(wù)進行了定制,并且可以在較少的參數(shù)數(shù)量下更快地收斂。
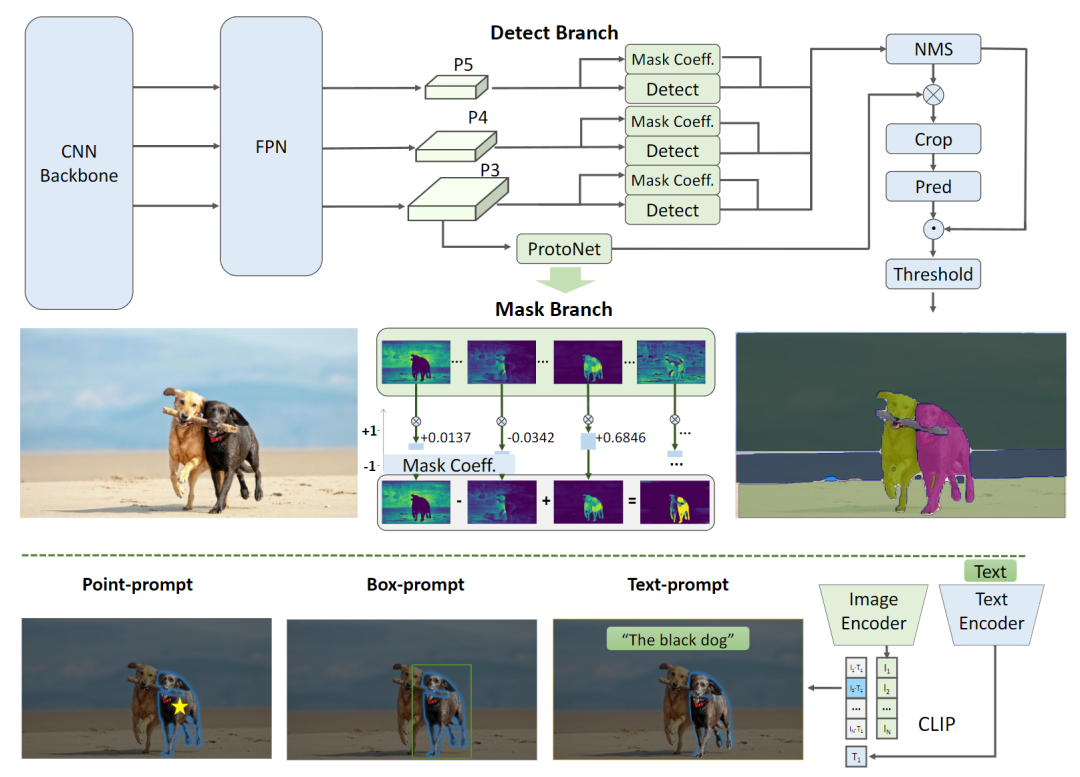
圖2. FastSAM網(wǎng)絡(luò)架構(gòu)圖
FastSAM包含兩個階段:全實例分割(AIS)和提示引導(dǎo)選擇(PGS)。先使用YOLOv8-seg 對圖像中的所有對象或區(qū)域進行分割。然后使用各種提示來識別感興趣的特定對象。主要涉及點提示、框提示和文本提示的利用。
實例分割
YOLOv8 的架構(gòu)是基于其前身YOLOv5 發(fā)展而來的,融合了最近算法(如YOLOX 、YOLOv6 和YOLOv7 )的關(guān)鍵設(shè)計。YOLOv8的主干網(wǎng)絡(luò)和特征融合模塊(neck module)將YOLOv5的C3模塊替換為C2f模塊。更新后的頭部模塊采用解耦結(jié)構(gòu),將分類和檢測分開,并從基于Anchor的方法轉(zhuǎn)向了基于Anchor-Free的方法。
YOLOv8-seg應(yīng)用了YOLACT的實例分割原理。它通過主干網(wǎng)絡(luò)和特征金字塔網(wǎng)絡(luò)(Feature Pyramid Network, FPN)從圖像中提取特征,集成了不同尺度的特征。輸出包括檢測分支和分割分支。檢測分支輸出目標(biāo)的類別和邊界框,而分割分支輸出k個原型(在FastSAM中默認為32個)以及k個掩碼系數(shù)。分割和檢測任務(wù)并行計算。分割分支輸入高分辨率特征圖,保留空間細節(jié),并包含語義信息。該特征圖經(jīng)過卷積層處理,上采樣,然后通過另外兩個卷積層輸出掩碼。與檢測頭部的分類分支類似,掩碼系數(shù)的范圍在-1到1之間。通過將掩碼系數(shù)與原型相乘并求和,得到實例分割結(jié)果。
YOLOv8可以用于各種目標(biāo)檢測任務(wù)。而通過實例分割分支,YOLOv8-Seg非常適用于segment anything任務(wù),該任務(wù)旨在準(zhǔn)確檢測和分割圖像中的每個對象或區(qū)域,而不考慮對象的類別。原型和掩碼系數(shù)為提示引導(dǎo)提供了很多可擴展性。例如,可以額外訓(xùn)練一個簡單的提示編碼器和解碼器結(jié)構(gòu),以各種提示和圖像特征嵌入作為輸入,掩碼系數(shù)作為輸出。在FastSAM中,本文直接使用YOLOv8-seg方法進行全實例分割階段。
提示引導(dǎo)選擇
在使用YOLOv8成功地對圖像中的所有對象或區(qū)域進行分割后,segment anything 任務(wù)的第二階段是利用各種提示來識別感興趣的特定對象。這主要涉及到點提示、框提示和文本提示的利用。
點提示
點提示的目標(biāo)是將所選點與第一階段獲得的各種掩碼進行匹配,以確定點所在的掩碼。類似于SAM在方法中采用前景/背景點作為提示。在前景點位于多個掩碼中的情況下,可以利用背景點來篩選出與當(dāng)前任務(wù)無關(guān)的掩碼。通過使用一組前景/背景點,我們能夠選擇感興趣區(qū)域內(nèi)的多個掩碼。這些掩碼將被合并為一個單獨的掩碼,完整標(biāo)記出感興趣的對象。此外,還可以利用形態(tài)學(xué)操作來提高掩碼合并的性能。
框提示
框提示涉及將所選框與第一階段中對應(yīng)的邊界框進行IoU(交并比)匹配。目標(biāo)是識別與所選框具有最高IoU得分的掩碼,從而選擇感興趣的對象。
文本提示
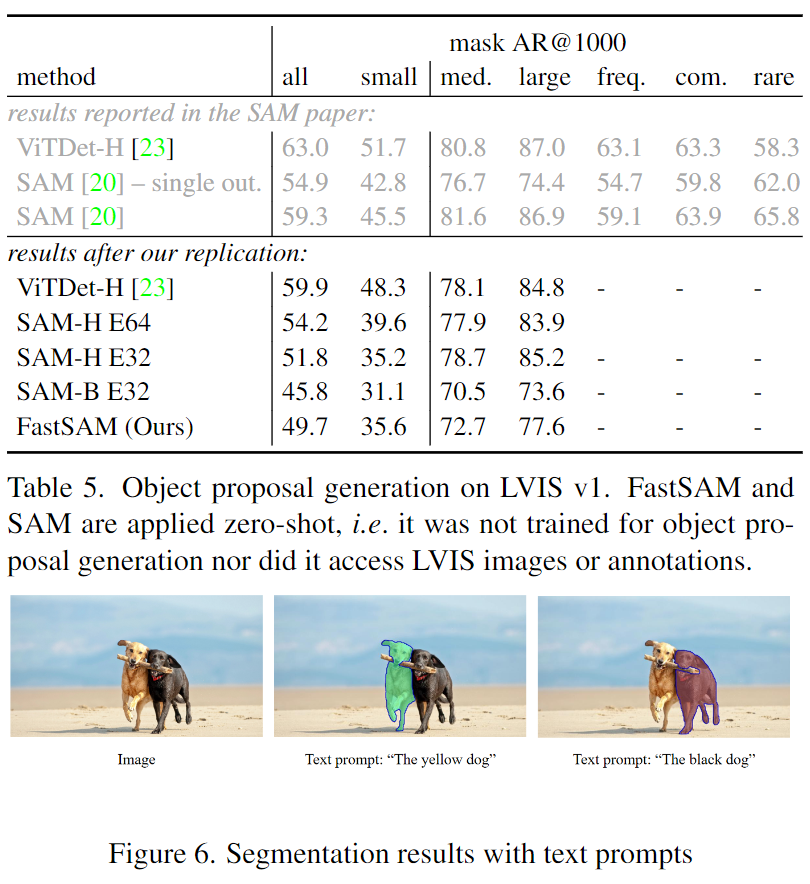
在文本提示的情況下,我們使用CLIP模型提取文本的相應(yīng)嵌入。然后,確定與每個掩碼的固有特征進行匹配的圖像嵌入,并使用相似度度量方法進行匹配。選擇與文本提示的圖像嵌入具有最高相似度得分的掩碼。
通過精心實施這些基于提示的選擇技術(shù),F(xiàn)astSAM可以可靠地從分割圖像中選擇特定的感興趣對象。上述方法為在實時情況下完成segment anything任務(wù)提供了高效的方式,從而極大地增強了YOLOv8模型在復(fù)雜圖像分割任務(wù)中的實用性。對于更有效的基于提示的選擇技術(shù),將留待未來探索。
實驗結(jié)果

SAM和FastSAM在單個NVIDIA GeForce RTX 3090 GPU上的運行速度對比。可以看出,F(xiàn)astSAM在所有提示數(shù)量上超過了SAM。此外,F(xiàn)astSAM的運行速度與提示數(shù)量無關(guān),使其成為"Everything mode"的更好選擇。

FastSAM分割結(jié)果
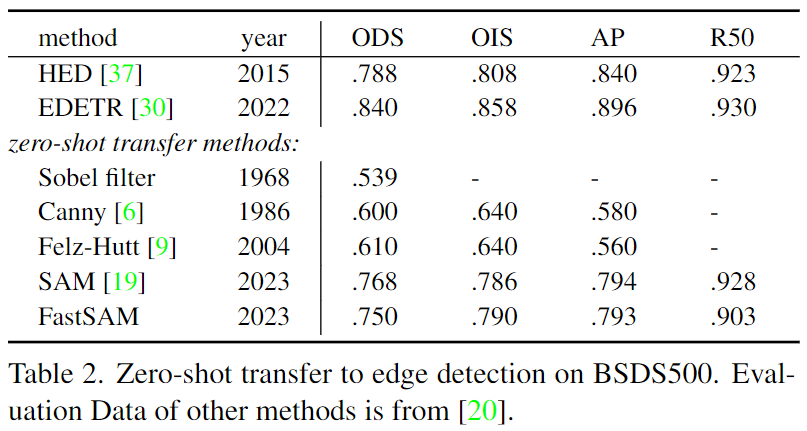
邊緣檢測zero-shot能力評估-量化指標(biāo)評估
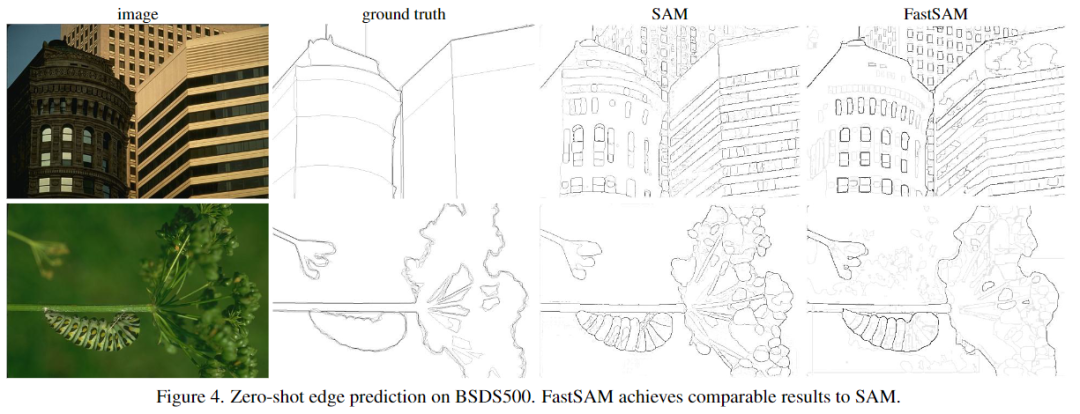
邊緣檢測zero-shot能力評估-可視化結(jié)果評估
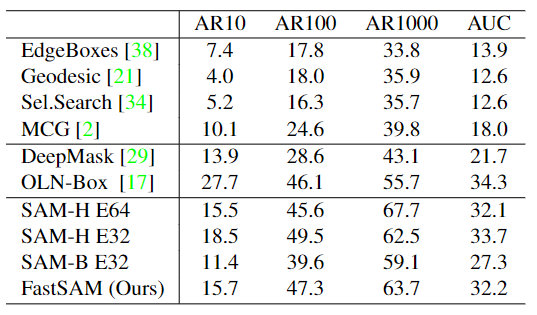
在COCO的所有類別上與無需學(xué)習(xí)的方法進行比較。此處報告了無需學(xué)習(xí)的方法、基于深度學(xué)習(xí)的方法(在VOC上進行訓(xùn)練)以及本文方法與SAM方法在所有泛化上的平均召回率(AR)和AUC對比結(jié)果。
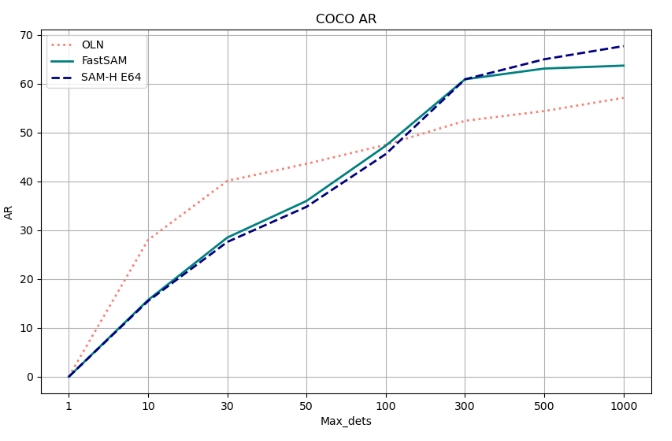
與OLN和SAM-H的比較
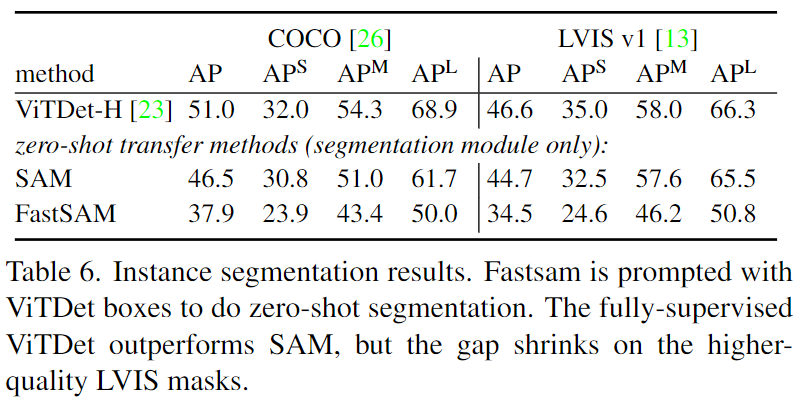

在異常檢測中的應(yīng)用,其中SAM-point/box/everything分別表示使用點提示、框提示和全部模式。

在顯著性分割中的應(yīng)用,其中SAM-point/box/everything分別表示使用點提示、框提示和全部模式。

在建筑物提取中的應(yīng)用,其中SAM-point/box/everything分別表示使用點提示、框提示和全部模式。

相比SAM,F(xiàn)astSAM在大對象的狹窄區(qū)域上可以生成更精細的分割掩碼。
Limitations
總體而言,F(xiàn)astSAM在性能上與SAM相當(dāng),并且比SAM (32×32) 快50倍,比SAM (64×64) 快170倍。其運行速度使其成為工業(yè)應(yīng)用的良好選擇,如道路障礙檢測、視頻實例跟蹤和圖像處理。在一些圖像上,F(xiàn)astSAM甚至能夠為大尺寸對象生成更好的掩碼。

圖11
然而,正如實驗中所展示的,F(xiàn)astSAM在生成框上具有明顯的優(yōu)勢,但其掩碼生成性能低于SAM,如上圖11所示。FastSAM具有以下特點:
低質(zhì)量的小尺寸分割掩碼具有較高的置信度分數(shù)。作者認為這是因為置信度分數(shù)被定義為YOLOv8的邊界框分數(shù),與掩碼質(zhì)量關(guān)系不大。改變網(wǎng)絡(luò)以預(yù)測掩碼的IoU或其它質(zhì)量指標(biāo)是改進的一種方式。
一些微小尺寸對象的掩碼傾向于接近正方形。此外,大尺寸對象的掩碼可能在邊界框的邊緣出現(xiàn)一些偽影,這是YOLACT方法的弱點。通過增強掩碼原型的能力或重新設(shè)計掩碼生成器,可以預(yù)期解決這個問題。
結(jié)論
在本文中,我們重新思考了Segment Anything的任務(wù)和模型架構(gòu)選擇,并提出了一種替代方案,其運行速度比SAM-ViT-H (32×32)快50倍。實驗證明,F(xiàn)astSAM可以很好地解決多個下游任務(wù)。然而,F(xiàn)astSAM還存在一些可以改進的弱點,例如評分機制和實例掩碼生成范式。這些問題將留待未來的研究解決。
-
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809 -
SAM
+關(guān)注
關(guān)注
0文章
112瀏覽量
33519 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24689
原文標(biāo)題:中科院自動化所發(fā)布FastSAM | 精度相當(dāng),速度提升50倍!!!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一個全新的無監(jiān)督不需要明確物體種類的實例分割算法
數(shù)據(jù)高效缺陷檢測技術(shù)有哪些
一種先分割后分類的兩階段同步端到端缺陷檢測方法
幾大主流公開遙感數(shù)據(jù)集
YOLOv6中的用Channel-wise Distillation進行的量化感知訓(xùn)練
圖像分割基礎(chǔ)算法及實現(xiàn)實例

索尼發(fā)布新的方法,在ImageNet數(shù)據(jù)集上224秒內(nèi)成功訓(xùn)練了ResNet-50
算法 | 超Mask RCNN速度4倍,僅在單個GPU訓(xùn)練的實時實例分割算法
在一個很小的Pascal VOC數(shù)據(jù)集上訓(xùn)練一個實例分割模型
分析總結(jié)基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

基于X光圖片的實例分割垃圾數(shù)據(jù)集WIXRay (Waste Item X- Ray)
語義分割數(shù)據(jù)集:從理論到實踐
基于通用的模型PADing解決三大分割任務(wù)

復(fù)旦開源LVOS:面向真實場景的長時視頻目標(biāo)分割數(shù)據(jù)集

機器視覺圖像分割的方法有哪些?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論