 2023 DPU廠商大盤點(先鋒版)
2023 DPU廠商大盤點(先鋒版)
去年SDNLAB推出的《史上最全DPU廠商大盤點》系列文章受到了很多的討論與關注,春風吹過,又是一年。國內自研DPU芯片發展突飛猛進,DPU應用也開始逐漸落地。根據賽迪顧問發布的數據,預計到2025年全球DPU產業市場規模將超過245.3億美元(約1771億人民幣),DPU市場有望實現跳躍式增長,迎來黃金發展期。
在DPU全球千億市場面前,廠商們今年又整出了什么花活?
以下排名不分先后,按公司簡稱拼音排序:
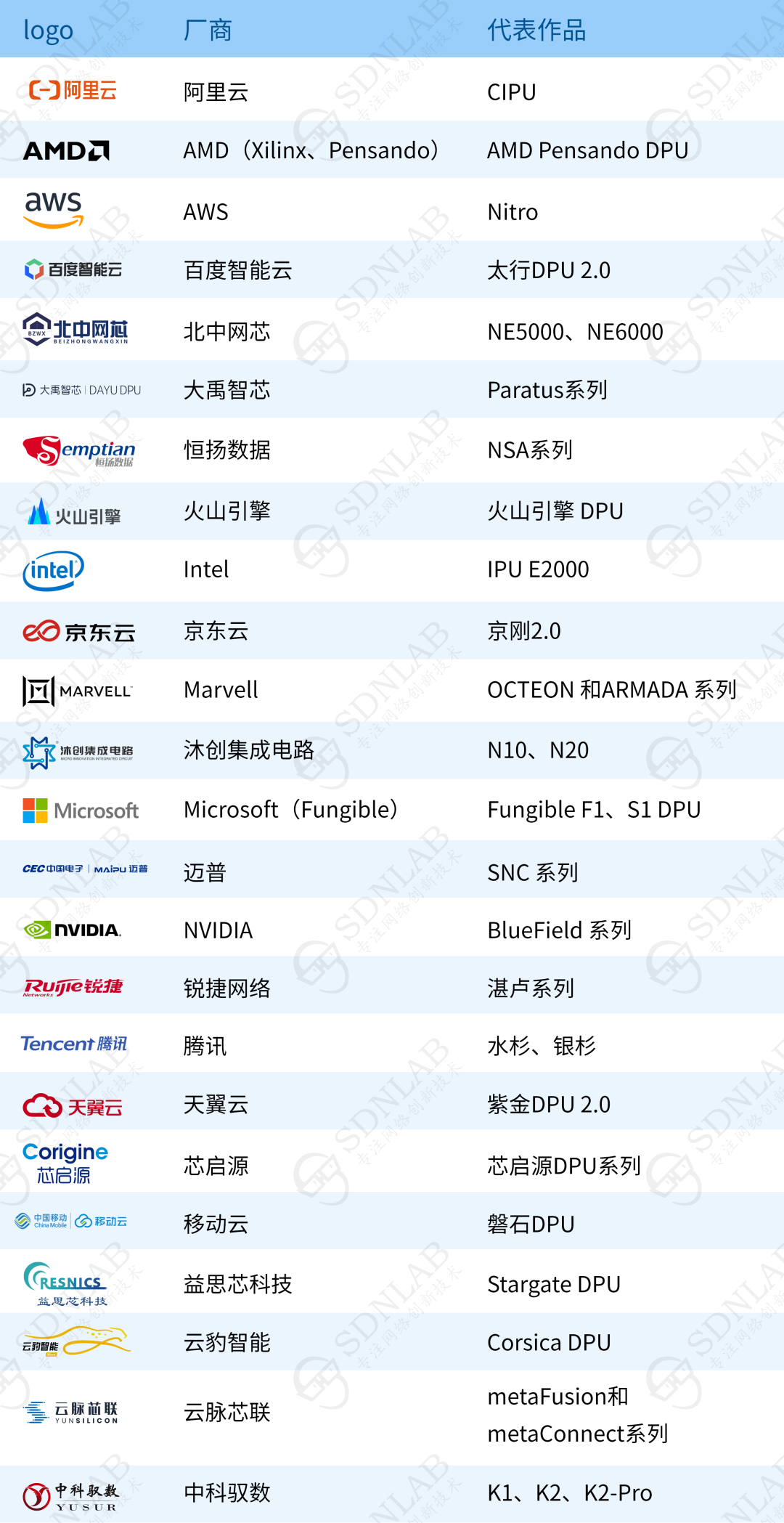
阿里云:CIPU
2017年10月阿里云推出了神龍架構,2022年又發布了一款全新的云數據中心專用處理器——CIPU,不同于傳統的以CPU為中心的架構設計,CIPU被定義為云計算的控制和核心性能加速中心。
CIPU向下云化管理數據中心硬件,加速計算、存儲和網絡資源;向上接入飛天云操作系統,將全球上百萬臺服務器變成一臺“超級計算機”。目前,CIPU已經在阿里云內部有較大規模的應用,為雙11、阿里集團業務等內部客戶和最新實例提供支撐。
總體來說,CIPU有兩大功能:一是具備對底層基礎設施資源的虛擬化管理能力,二是能承載飛天對這些資源的編排和調度需求,并具備存儲、網絡、計算、安全等硬件加速能力。
存儲方面,其對存算分離架構的塊存儲接入進行硬件加速,提供超高性能的云盤。
網絡方面,其對高帶寬物理網絡進行硬件加速,通過建設大規模的彈性RDMA分布式高性能網絡,實現RDMA技術的普惠化,客戶無需修改代碼,即可享受CIPU的加速紅利。
計算方面,CIPU快速接入不同類型資源的神龍服務器,帶來算力的“0”損耗,以及硬件級安全的加固隔離能力(可信根、數據加解密等)。
AMD:AMD Pensando DPU
2022 年,AMD以19億美元收購了Pensando,進入DPU賽道。AMD Pensando 平臺的核心是完全可編程 P4 數據處理單元 (DPU),采用與超大規模服務系統相同的底層技術。經過專門優化,通過軟件堆棧實現以云級別提供云服務、計算、網絡、存儲和安全服務,并盡可能地降低延遲、抖動和能源需求。
AMD Pensando DPU 將強大的軟件堆棧與“零信任安全”和領先的可編程數據包處理器相結合,打造出更為智能、性能更強的 DPU。AMD Pensando DPU 現已在 IBM 云、微軟Azure 和甲骨文云等云合作伙伴中大規模部署。在企業中,它被部署在 HPE Aruba CX 10000 智能交換機中,與領先的 IT 服務公司 DXC 等客戶合作,作為 VMware vSphere Distributed Services Engine 的一部分,為客戶加速應用程序性能。
AMD還公布了代號為“Giglio”的下一代 DPU 路線圖,與當前一代產品相比,該路線圖旨在為客戶帶來更高的性能和能效,預計將于 2023 年底上市。
AWS :Nitro
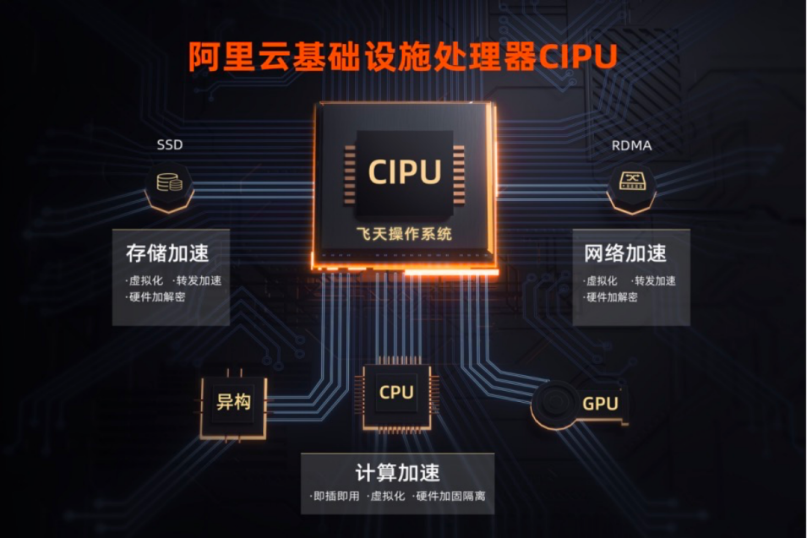
AWS 是早期自研DPU的云廠商之一。2015年,AWS收購了芯片廠商Annapurna Labs,2017年正式推出Nitro芯片。AWS Nitro DPU 系統目前已經成為了AWS 云服務的技術基石。AWS 借助 Nitro DPU 系統把網絡、存儲、安全和監控等功能分解并轉移到專用的硬件和軟件上,將服務器上幾乎所有資源都提供給服務實例,極大地降低了成本。
Nitro DPU 系統主要分為以下幾個部分:
Nitro Hypervisor是一個輕量級虛擬機監控程序只負責管理 CPU 和 Memory 的分配,幾乎不占用 Host 資源,所有的服務器資源都可用來執行客戶的工作負載。
Nitro Cards是一系列用于卸載和加速的協處理外設卡,承載網絡、存儲、安全及管理功能,使得網絡和存儲性能得到了極大提升,并且從硬件層提供天然的安全保障。
Nitro Security Chip提供了面向專用硬件設備及其固件的安全防護能力,包括限制云平臺維護人員對設備的訪問權限,消除人為的錯誤操作和惡意篡改。
Nitro Enclaves基于 Nitro Hypervisor 進一步提供了創建 CPU 和 Memory 完全隔離的計算環境的能力,以保護和安全地處理高度敏感的數據。
Nitro TPM(可信平臺模塊)支持 TPM 2.0 標準,Nitro TPM 允許 EC2 實例生成、存儲和使用密鑰,繼而支持通過 TPM 2.0 認證機制提供實例完整性的加密驗證。
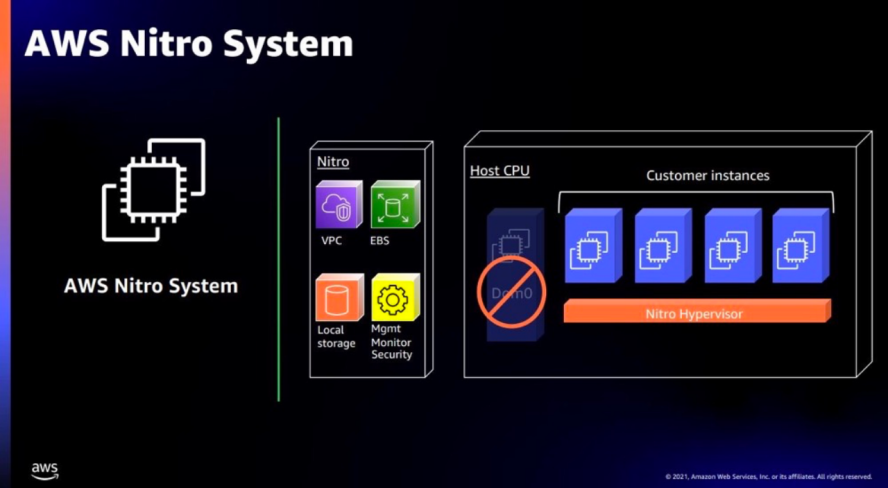
百度智能云:太行DPU 2.0
在第五屆Create AI開發者大會上,百度重磅發布了新一代計算架構——百度太行DPU2.0,全新太行DPU2.0具備多平臺、多場景、多協議、多業務四大核心能力,支持Intel、AMD、ARM平臺,同時支持計算、存儲、網絡、虛擬化等功能。
百度智能云對 DPU2.0的核心定位是“Cloud Native IO Engine”。云架構下的核心問題就在于數據中心東西向流量大增,IO 的負擔太大。因此重點需要解決在多租戶、細粒度算力形態、后端解耦的硬件資源池架構下,海量的 IO 數據搬移、通信、處理、安全等等問題。重新定義軟硬件邊界。
百度太行 DPU2.0主要包含5大關鍵技術:
軟件定義虛擬化,支持萬級虛擬設備;
網絡硬件加速,由軟件轉發變成硬件轉發;
高性能的 RDMA 網絡,用自研協議解決流控留空、擁塞等問題;
存算分離硬件加速,通過超大資源池打平本地和遠程的區別;
云管控硬件通道,保證各形態計算實例共池,實現熱遷移、熱升級、熱插拔等特性,支持千億級模型訓練。
百度太行DPU發展路徑如下所示:
北中網芯:NE5000、NE6000
成都北中網芯科技有限公司于2020年4月成立,專注于網絡通信和安全領域的芯片設計和開發。經過研發團隊長期的技術攻堅,公司率先推出基于SOC-NP可編程架構NE6000 DPU芯片、NE5000 DPU芯片,并基于自研芯片推出2*100GbE智能網卡、2*25GbE智能網卡、VPN和DPI等一系列技術研發成果。
北中網芯鯖鯊系列首款網絡數據處理DPU芯片NE6000于2022年11月13日流片成功,這款芯片基于專用的NP可編程芯片架構,采用28nm工藝制程,兼具高性能、可編程、低延時、低功耗等特點,具有雙向200Gbps的處理能力。
NE6000專注于網絡數據處理和安全防護功能,可實現網絡協議處理、交換路由、安全檢測等高性能和高效率的任務,具備25GE和100GE網絡接入能力。NE6000通過微碼編程升級,可根據最終用戶需求靈活進行網絡報文協議解析和編輯,適應任何網絡協議的變化。
NE6000芯片所特有的級聯特性可實現表項擴展和性能擴展,進一步增強系統的靈活性和可擴展性。級聯接口傳輸帶寬可達100Gbps,傳輸延時小于1us。NE6000在靈活性、可編程性、性能、功耗、流片條件等多個維度取得了很好的平衡。
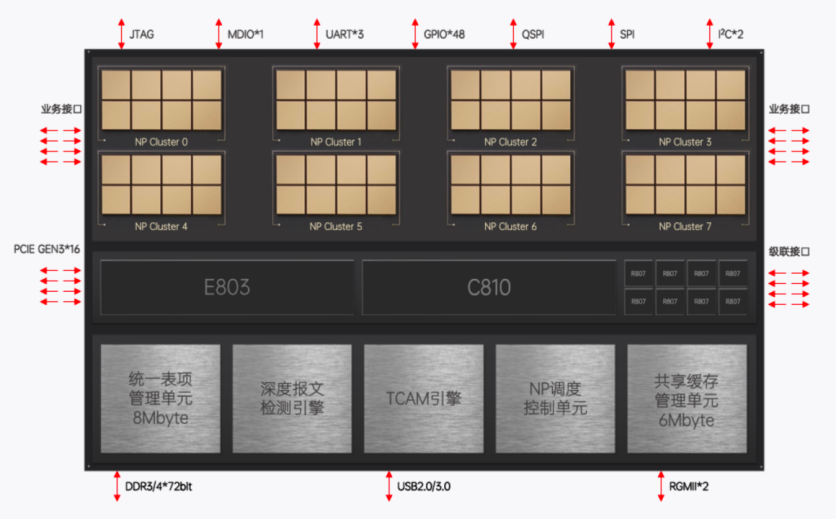
NE6000芯片的應用范圍廣泛,可以滿足云計算、數據通信、網絡安全、5G、邊緣計算、人工智能等領域的需求,適應數據中心、物聯網、車聯網等不同業務場景,以及滿足負載均衡、VPN網關、下一代防火墻、智能網卡等不同產品形態的要求。
大禹智芯:Paratus系列
大禹智芯是一家專注于提供DPU產品設計、研發與服務的國家高新科技企業。為滿足不同客戶及不同場景的DPU使用需求,大禹智芯堅持從貼近用戶需求的場景出發,遵循明確的產品規劃路線,提供Paratus系列DPU產品,目前已推出2個產品序列:

1.0序列產品——Paratus 1.0、Paratus 1.5
Paratus 1.0和Paratus 1.5是大禹智芯的第一款DPU產品。通過運行在ARM SoC上的Linux操作系統及DPDK、SPDK開發套件,用戶可將原先運行在主機側的功能方便的下沉到DPU上運行,實現主機側算力資源的釋放。基于相同的DPU開發運行環境,大禹智芯也提供了虛擬化網絡組件,存儲客戶端組件以及與開源云管平臺Openstack和Kubernetes集成所必要的相關組件。用戶通過Paratus1.0構建高性能的裸金屬云、虛擬機云及容器云等服務。Paratus 1.0可廣泛應用于公有云,邊緣云,企事業內部私有云及其他復雜網絡流量處理等場景。
2.0序列產品——Paratus 2.0
Paratus 2.0是大禹智芯在1.0序列產品基礎上,通過增加FPGA組件而打造的全新DPU產品。采用ARM SoC + FPGA的硬件架構,在保持了與第一款DPU產品相同的軟件開發運行環境的同時,提供了基于FPGA的網絡數據處理通路,大幅提升了網絡流量處理能力。在此基礎上,Paratus 2.0還具有一些獨特的功能:大禹智芯自研高性能網絡協議HPRT的實現可充分釋放RDMA應用的潛力;無感知端到端網絡數據加密功能可最大化保證數據網絡傳輸可靠性,其功能及性能均為業界領先水平;網絡上層應用行為分析功能可為網絡入侵行為判斷提供實時可靠的數據支撐。
恒揚數據:NSA系列
深圳市恒揚數據股份有限公司成立于2003年,通過靈活多變的客制化定制方式,為客戶提供個性化DPU加速產品及異構計算加速方案的設計、研發及生產,滿足用戶在機器學習、視頻轉碼、圖像識別、語音識別、自然語言處理、基因組測序分析等多種應用場景的加速需求,實現高性能、高帶寬、低延遲、低功耗的智能化計算加速。
恒揚數據DPU產品面向數據中心設計,為服務器提供高帶寬IO,為數據中心算力提供高性能卸載,產品在網絡、存儲、安全、計算領域得到廣泛批量應用。基于FPGA的設計方式,可極大地利用FPGA自身豐富的邏輯單元,實現對數據的快速并行處理,通過較小的能耗開銷,實現數據中心性能的大幅躍遷。
恒揚數據NSA系列DPU產品及解決方案依托FPGA、FPGA+CX、FPGA+CPU等多種架構設計,其中FPGA單元主要基于Xilinx Zynq系列、KU系列、VU系列、VP系列,CX系列(包括CX5、CX6)芯片研制開發,產品可廣泛應用于互聯網數據中心的網絡、存儲、安全、計算等加速場景,是集高速IO帶寬和高性能計算處理為一體的異構數據處理加速單元。
產品方案可廣泛應用于云數據中心網絡、存儲加速,網絡虛擬化卸載、RDMA網絡加速及資源池化等多種場景,助力客戶在云數據中心的算力加速,包括圖片/視頻的處理分析、目標識別與追蹤、基因測序、版權保護、傳播影響力監測、素材管理等領域的算法加速。
火山引擎:火山引擎 DPU
火山引擎是字節跳動于2021年6月推出的云服務業務板塊,至今逐漸完善了IaaS+PaaS+SaaS云服務體系。在2023火山引擎原動力大會上,火山引擎全棧自研核心組件——火山引擎DPU重磅登場。
火山引擎基于自研DPU推出了新一代服務器實例,整體性能大幅提升。在Intel全新一代SPR CPU平臺上,通過引入火山引擎DPU,整機性能最高提升93%,單核性能最高提升13%。≤16c小規格實例性能最高提升6倍以上。

在AMD全新一代Genoa CPU平臺上,通過引入火山引擎DPU,整機性能最高提升138%,單核性能最高提升39%。≤16c小規格實例性能最高提升10倍以上。而在Nvidia A800 裸金屬上,擁有火山引擎DPU的加持,跨節點提供800Gbps RDMA網絡帶寬,更加適用于大規模集群分布式訓練場景,提高集群并行效率,相較于上一代實例集群性能最高提升3倍以上。
據悉,火山引擎 DPU 整體網絡性能升級到 5000 萬 pps 轉發能力,20us 延遲。目前,字節內部已經實現上萬臺 DPU 的部署,并且將持續提升滲透率。基于自研 DPU 的各類計算實例性能也有顯著提升,例如適用于大模型分布式并行訓練場景的 GPU 實例,相較上一代實例集群性能最高提升 3 倍以上。
Intel:IPU E2000
Intel在 2021 年 6 月正式提出了IPU,目的是改善資料中心效率與管理簡便度,并強調這是唯一與超大型云端客戶合作構建的加速與卸載解決方案。
E2000是Intel和谷歌共同設計的新型定制IPU芯片,代號為“Mount Evans”,以降低數據中心主 CPU 負載,并更有效和安全地處理數據密集型云工作負載。特性如下:
2 個 100 GbE 或 1 個 200 GbE 連接
多達 16 個 Arm Neoverse N1 核心
PCIe 4.0 x16
支持高達 48 GB DRAM

Oak Springs Canyon是Intel第二代基于 FPGA 的 IPU 平臺,該平臺采用Intel Xeon-D和Agilex FPGA 構建。
在 2022 年的 Vision 全球用戶大會期間,公布了其最新的IPU路線圖,展示了從2022年至2026年IPU的整體規劃。英特爾將繼續 ASIC + FPGA IPU 設計,其IPU路線圖如下:
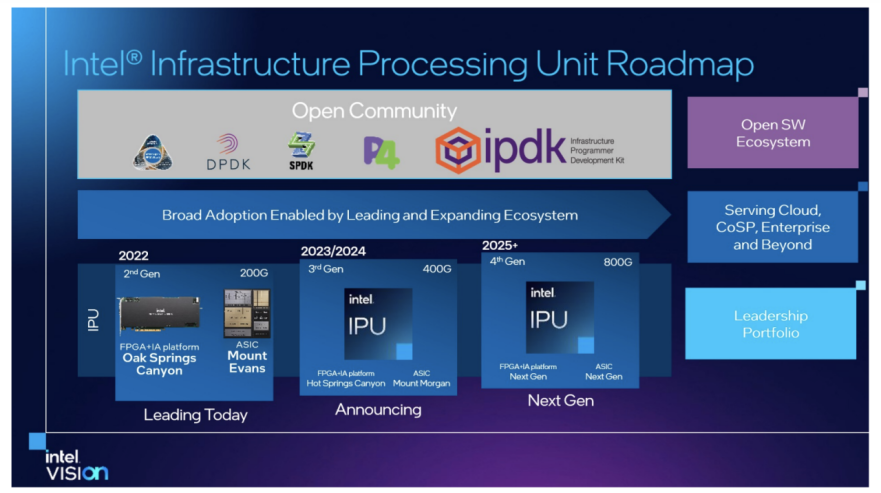
2022年:推出了200 Gbps IPU,代號為Mount Evans和Oak Springs Canyon。
2023/2024年:推出 400 Gbps IPU,代號為Mount Morgan和Hot Springs Canyon。
2025/2026 : 推出800 Gbps IPU。
京東云:京剛2.0
京剛是京東云自主研發的行業領先的全業務軟硬一體虛擬化引擎,包括京剛智能網卡和完整的計算、存儲、網絡虛擬化協議棧和管理軟件。在2022京東云峰會上,京東云正式發布了京剛2.0。
作為數據中心級DPU引擎,京剛2.0存儲IOPS、網絡轉發性能均提升50%,效能提升立竿見影。基于存算分離技術自主研發的統一存儲平臺云海,打破了存算一體限制,使計算資源利用率提升30%。京剛2.0+云海軟硬融合,存儲性能提升10倍,極大提升了資源利用率,目前已經全面應用于京東618、京東11.11等大規模復雜場景。
京剛智能網卡的核心為基于FPGA的京剛DPU芯片,使用硬件替代軟件完成虛擬化工作,極大提升了資源利用率。京剛智能芯片卸載網絡轉發和存儲IO功能,讓硬件性能不受損,支持了業界標準的SRIOV虛擬化技術,保證設備虛擬化無開銷;同時,芯片級的硬件隔離技術,實現了用戶負載和云管理負載的完全隔離,大幅提升了云計算平臺的安全級別。
此外,京剛2.0還做到了更廣泛的適配,同時支持x86架構下Intel、AMD處理器,及ARM架構下安培、飛騰等處理器,應用場景進一步擴大。
Marvell:OCTEON 和 ARMADA 系列
Marvell 的 OCTEON 和 ARMADA 系列設備用于 5G 無線基礎設施和網絡設備,包括交換機、路由器、安全網關、防火墻、網絡監控和 SmartNIC(智能網絡接口卡)。
OCTEON 10 DPU 針對具有挑戰性的超大規模云工作負載、5G 傳輸處理、5G RAN 智能控制器 (RIC) 和邊緣推理、運營商和企業數據中心應用以及無風扇網絡邊緣盒進行了優化。OCTEON 10 DPU采用 Arm Neoverse N2 內核,5nm 工藝,與前幾代 OCTEON 相比計算性能提高 3 倍,功耗降低 50%。
OCTEON TX2 是 64 位 ARM SoC 處理器,將多達 36 個內核與可配置和可編程硬件加速器模塊相結合,支持高達 200G 的數據路徑。
OCTEON MIPS64 多核DPU是唯一采用定制設計的 64 位 cnMIPS 內核并可擴展至 48 個內核的 DPU 系列。它結合了網絡 I/O 以及先進的安全性、存儲和應用程序硬件加速,提供高吞吐量和可編程性。
ARMADA DPU經過定制設計,可提供最佳性能、低功耗和高集成度。ARMADA DPU 系列針對計算、網絡和存儲平臺中的成本優化應用進行了優化。
Marvell 為所有 OCTEON 和 ARMADA 系列提供統一軟件開發套件 (SDK)。DPU系列設備的功能通過開源數據包和安全應用加速 API 得到增強。Marvell還提供行業標準控制、管理和數據平面軟件堆棧,針對最新一代基于 ARM 的 OCTEON 處理器進行了優化。
沐創集成電路:N10、N20
無錫沐創集成電路設計有限公司成立于2018年12月,專注于可重構可編程系統芯片的研發和銷售,主要產品包括密碼安全芯片和智能網絡控制器芯片。
2021年,沐創首款純國產化智能網絡控制器芯片N10順利推出。N10系列智能網絡控制器芯片是基于清華大學可重構技術開發出來的網卡芯片,擁有完全自主知識產權;支持八口10G,雙口25G,雙口40G 以太網接口,內置可重構處理器內核,支持網絡協議卸載處理,同時還支持高效的密碼算法加速,通過可重構實現40Gbps 的密碼算法處理,支持國際密碼(AES/SHA/RSA)和國內商用密碼(SM2/3/4)等數十種算法,實現高效的IPSec/TLS 加速。RNP N10智能網絡控制器芯片具有高安全、高性能、可編程等特點。截至當前,N10系列芯片已與百余家客戶完成適配,并在眾多客戶的不同應用場景中落地生根。
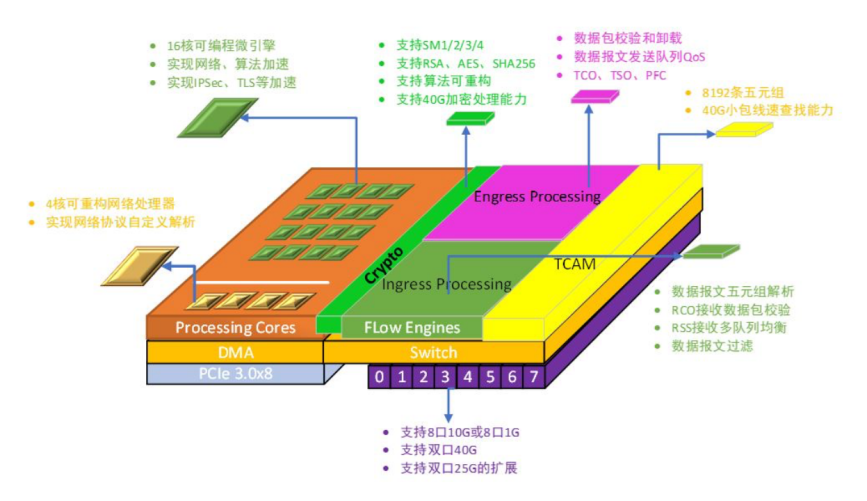
N10架構圖
N20是沐創在研的第二代智能網絡控制器芯片,是一款25G/100G的智能網卡芯片,具備高速網絡協議卸載,RDMA,網絡可編程,虛擬化等能力。主要面向國產服務器、網絡安全設備、云廠等廠家,為其提供100G網卡芯片產品。
沐創公司的產品路線圖如下:
N10:2021年,第一代智能網絡控制器,10G/40G,支持基礎的網絡協議卸載能、安全卸載和可編程能力;
N20:2023年,第二代智能網絡控制器,25G/100G,支持RDMA、OVS,更高性能的網絡協議卸載、安全卸載、可編程能力;
N30:2025年,第三代智能網絡控制器,100G,多核ARM架構,數據平面和控制平面的全面卸載。
Microsoft(Fungible):
F1、S1
2023 年1 月,微軟宣布收購 DPU 技術提供商 Fungible。Fungible 曾經是最熱門的半導體初創公司之一,自 2015 年以來已籌集了超過 3.7 億美元的資金。Fungible 是第一家針對云級 DPU 的商業芯片公司,先于Intel、Nvidia、Pensando (AMD) 和 Marvell。
Fungible DPU 平臺包括硬件和軟件,按需拆分或組合計算和存儲資源。它包括兩個核心部分:一是可編程數據路徑引擎,它可以高速執行以數據為中心的計算,并提供比通用 CPU 更大的靈活性。二是實現 Fungible 專有 TrueFabric 端點的網絡引擎。可提供確定性的低延遲、高帶寬、擁塞和錯誤控制以及從數百到數十萬個節點的高安全性。
Fungible 有兩款DPU芯片。Fungible F1 DPU 是一款 800 Gb/s 芯片,專為高性能存儲、分析和安全平臺而設計。Fungible S1 DPU 是一款 200 Gb/s 芯片,針對主機端用例進行了優化,包括裸機虛擬化、存儲啟動器、NFV 基礎設施/虛擬網絡功能 (VNF) 應用程序和分布式節點安全性。
Fungible S1 DPU 經過優化,可在服務器節點內組合以數據為中心的計算并在節點間高效移動數據。以數據為中心的計算的特點是高速數據流的有狀態處理,通常是通過網絡、安全和存儲堆棧。S1 DPU 通過其 TrueFabric技術促進服務器節點之間的數據交換。
邁普:SNC 系列
邁普通信 SNC 系列智能網卡是邁普公司面向新一代云數據中心推出的智能化網絡接口控制器。該系列智能網卡為公有云/專為云、高性能計算、人工智能和超大規模計算等應用而設計,提供強大的網絡和應用平臺能力,用于應對現代云和數據中心在網絡性能、軟件定義網絡(SDN)、業務卸載、計算加速以及定制化解決方案等方面的挑戰。
該產品型號為 SNC4000-2S,該系列產品在滿足傳統的彈性裸金屬及虛擬化場景下,追求高性價比以及提供強大的場景化定制能力,可靈活適應于客戶特定的應用場景和服務器類型,可按需打造滿足客戶特定要求的高價值解決方案。
該產品型號為 SNC5000-2S,該系列產品技術架構先進,根據不同的業務應用場景,提供基于 CPU+FPGA 芯片的智能網卡解決方案,國內技術領先。可針對數據中心計算/網絡/存儲等基礎設施,提供區別于傳統網卡的強大優化能力,如網絡加速、OVS 卸載、存儲標準化、加解密、安全卸載、裸金屬管理、可編程能力等。從芯片到硬件到軟件的全方位提供安全可控、穩定、可靠、開放的高性能智能網卡軟硬件平臺。
該產品型號為 SNC5000-2H,具備 100G 的接口能力以及標準的 BMC 管理能力,致力于 打造高吞吐轉發性能以及高 IOPS 存儲性能的產品。除傳統裸金屬和虛擬化場景智能網卡的 能力外,還提供適用于容器等場景對 SRIOV 有極致虛擬化要求的能力,以及提供硬件國密加解密算法能力。
NVIDIA:BlueField 系列
NVIDIA是一家以設計顯示芯片和主板芯片組為主的半導體公司,總部位于美國加利福尼亞州圣克拉拉市。2020 年 4 月,Nvidia 以 69 億美元的價格收購了網絡芯片和設備公司 Mellanox,隨后陸續推出 BlueField 系列 DPU。
NVIDIA BlueField-3 DPU 延續了 BlueField-2 DPU 的特性,是首款為 AI 和加速計算而設計的 DPU。BlueField-3 DPU 提供了最高 400Gbps 網絡連接,可以卸載、加速和隔離軟件定義網絡、存儲、安全和管控功能,從而提高數據中心性能、效率和安全性。
BlueField-3 DPU 能夠滿足苛刻的應用基礎設施需求,在I/O路徑中提供強大的計算能力和廣泛的可編程加速引擎,同時通過NVIDIA DOCA軟件框架提供完整的軟件向后兼容性。
BlueField-3 DPU 將傳統的計算環境轉變為高性能、高效和可持續的數據中心,使組織能夠在安全的多租戶環境中運行應用程序工作負載。BlueField-3 DPU 將數據中心基礎設施與業務應用分離,增強了數據中心的安全性,簡化了操作并降低了總擁有成本。
銳捷網絡:湛盧系列
銳捷網絡結合對云數據中心方案和運營商數據中心業務的理解,推出了智能網卡產品,面向裸金屬、虛擬化和存儲卸載三大場景,整合運營商大云方案開發智能網卡解決方案,在提升服務器內網絡性能同時,實現網絡Overlay、混合Overlay過渡到統一的主機Overlay架構,簡化了運營商云數據中心的邏輯組網模式,支持裸金屬、虛擬化環境,實現統一的網絡架構,并且具有更強的轉發性能和可編程特性,可靈活擴展有狀態安全組、QoS流控和SDN網絡功能,同時Underlay層面的物理交換機不再與SDN方案綁定,增加了運營商云數據中心網絡設備選擇的靈活性。
銳捷網絡支持 2x100G和2x25G智能網卡:

RG-SMARTNIC-2000 雙口100G智能網卡(左)、RG-SMARTNIC-1810雙口25G智能網卡(右)
銳捷網絡湛盧系列智能網卡基于FPGA+SOC增強架構,支持裸金屬和虛擬化兩種模式,通過FPGA實現OVS快路徑的轉發功能卸載,通過SOC實現OVS DPDK慢路徑轉發和存儲SPDK控制功能卸載,因此支持轉發和控制功能的網絡全卸載。
銳捷智能網卡基于FPGA+SOC架構,可以根據用戶將來需求不斷迭代新功能。支持裸金屬、虛擬化和存儲卸載三大場景功能,支持OVS 轉發和控制功能全卸載。銳捷智能網卡方案可以實現與運營商云平臺全面對接,可在 SOC 上部署裸金屬插件、存儲插件、虛擬火墻等應用。
騰訊:水杉、銀杉
2020年9月,騰訊第一代基于FPGA的自研智能網卡正式上線,命名為“水杉”。水杉投入應用后,“銀杉”的研發工作也緊鑼密鼓地啟動,并于2021年10月正式上線。

在網絡方面,銀杉提供2*100G網絡帶寬、高達5000萬PPS的超高網絡性能;存儲方面,提供高達100萬IOPS,存儲延遲低于40微秒;同時,銀杉具備彈性RMDA支持,可為業務提供Bypass kernel和零拷貝的網絡傳輸能力,網絡延遲低于5微秒,滿足企業高性能計算和集群訓練場景的高性能需求。
目前,騰訊自研DPU已經支撐公有云外部客戶,以及微信、QQ、騰訊會議等自研業務上云。
2021 年 11 月,騰訊發布了玄靈智能網卡芯片,騰訊表示其定位于云主機的性能加速,結合CVM/BM/容器等場景優化芯片架構,將原來運行在主CPU上的虛擬化、網絡/存儲IO等功能下移到芯片,實現了主CPU的零占用,相比業界產品性能提升了4倍。這一芯片的目標或許和云計算有關,更進一步或許和云游戲相關,游戲業務對騰訊至關重要,而云游戲則面向未來,通過玄靈智能網卡芯片,騰訊或將進一步完成其在云游戲領域的深入布局。
天翼云:紫金DPU 2.0
天翼云紫金DPU 2.0采用FPGA+SoC架構,依托于FPGA超高的性能和靈活的可編程特性,將數據面全卸載到FPGA,實現業務的直接硬件卸載加速,支持網絡虛擬化、存儲虛擬化、IO虛擬化、RDMA、高可用等關鍵技術。相較于傳統數據中心,搭配紫金DPU的新一代數據中心,具有多個方面的領先優勢。
軟硬協同卸載加速。充分發揮軟件“功能全”,硬件“速度快”的優勢。讓硬件專注解決主要矛盾,發揮極致性能;軟件則提供完整功能,負責整個系統的兜底。整個系統軟硬協同,通力合作,從而達到1+1>2的協同效果。網絡轉發性能超過5000萬PPS,存儲讀寫性能超過200萬IOPS。
SF-STACK超融合協議棧。打造內核態TCP/用戶態TCP/RDMA三棧合一的傳輸層。內核態TCP主打高可用,用于故障切換。用戶態TCP和RDMA主打高性能,分別用于跨AZ和AZ內的數據傳輸。傳輸層對上提供統一接口,動態選擇傳輸協議,真正做到簡單易用,高可靠,高性能,可大規模部署。
一云多芯、即插即用。紫金DPU實現了主機CPU環境與虛擬化環境的物理隔離,主機不同CPU芯片架構的服務器實現了“即插即用”。紫金架構更加開放、靈活、兼容,提升了算力資源使用效率和國產化平臺性能,架構適配上做到了又快又穩。
天翼云紫金DPU主要為天翼云自身產品提供底層和技術支撐,通過彈性裸金屬、云主機、容器等產品進行整體售賣。紫金DPU支持彈性裸金屬、云主機、容器等場景,目前已經在天翼云部分資源池推廣部署2000+臺服務器,后續將在整個云數據中心全面推廣部署。
天翼云將堅持DPU核心技術自主研發,持續演進,產品路線圖如下:
2022年:DPU1.0。
2023年:DPU2.0,支持25G網絡,支持SF-STACK超融合協議棧等核心技術。
2024年:DPU3.0,支持100G網絡,并適配更多的業務場景。
芯啟源:芯啟源DPU系列
芯啟源智能網卡是基于SoC架構的成熟DPU解決方案,具備完全的自主知識產權并已成熟量產,可以提供從芯片、板卡、驅動軟件和全套云網解決方案產品,同時具有可編程、高性能、低功耗、低成本、節能減排等獨特優勢,可以為5G通訊、云數據中心、大數據、人工智能等應用提供極有競爭力的解決方案,滿足當前快速迭代的新技術、新應用不斷對基礎設施提出的新需求。
芯啟源下一代DPU架構基于Chiplet技術,極大地提升了自有網卡產品的性能;同時通過支持與第三方芯片的Die-To-Die互聯,還可以集成更多的特定專業領域芯片。除了在性能和功能豐富度有飛躍式提升外,基于下一代DPU芯片的網卡產品將為客戶提供更多業務場景的支持能力。
芯啟源下一代DPU智能網卡是基于DPU芯片的新一代智能網卡,采用NP-SoC模式進行芯片設計、多線程的處理模式,使其可以達到ASIC固化芯片的數據處理能力。在高性能數據處理的同時,芯啟源DPU智能網卡還具備靈活高效的可編程能力,支持P4/C語言等高級編程語言的混合編程能力,支持基于XDP的eBPF卸載,幫助客戶實現貼合自身業務的定制化功能。兼具了FPGA高效、靈活可編程和專用處理器芯片(ASIC)低成本、低功耗的優勢,致力于為客戶提供高性能、低成本、產業化、生態化的解決方案。
芯啟源DPU產品路線圖如下:
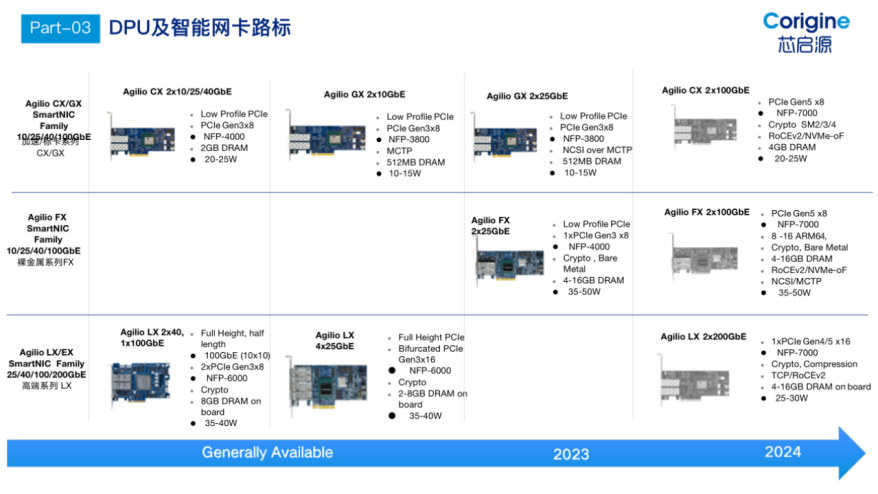
移動云:磐石DPU
磐石DPU由移動云計算團隊自主設計和研發,是中國移動強化芯片自主可控、布局算力網絡的重要載體。基于移動云算力迭代需求,結合業界首推的COCA(Compute on Chip Architecture)開放生態,實現“算力+連接”的高性能、高效率、集群化算力架構。

磐石DPU
磐石DPU聚焦算力服務,以100%自研安全、穩定、可靠、高性能硬件為措施,力圖在算力、連接、效率等關鍵領域取得核心突破,主要創新點包括:
基于磐石DPU “PCIe Switch+PF/VF”動態封裝算力服務接口,實現一套硬件滿足移動云裸金屬、云主機、容器等多種算力載體的業務需求,突破性能瓶頸,降低算力損耗的同時提升算力編排效率。
自研彈性裸金屬虛擬化技術棧,以自主設計的可編程芯片磐石DPU和全新打造的輕量級Hypervisor為核心,突破傳統技術架構極限,實現真正意義上的I/O虛擬化零損耗。
提出硬件多級流控QoS引擎,實現整機QoS、隊列QoS、流級QoS的雙向三級QoS精細調度,在高優先級業務帶寬保證的同時具備更低時延、更小抖動。
自研RNIC算法,將RDMA路徑管控邏輯全面開放,實現網絡數據路徑透明、智能、實時管控,場景化降低RDMA網絡通信時延,減少連接路徑上的網絡抖動,以實現大規模場景下高效率、大容量吞吐和時延低至5微秒的網絡數據傳輸。
存儲卸載引擎通過全方位深度開發的虛擬化卸載技術NVMe-oF、RDMA等,結合用戶態存儲后端轉發能力,實現云存儲IO全鏈路零拷貝。
當前,磐石DPU已應用到移動云全系列計算產品中,并支持以容器為接口實現硬件級云原生的能力拓展,滿足HPC、AI等高性能業務上云訴求。下一階段,磐石DPU將通過COCA聯動GPU、RDMA等技術體系,面向AI/HPC場景構建以AI大模型應用場景為代表的端到端技術能力支撐體系,構建AI抽象、AI池化、AI加速三大模塊和自主可控的高性能算力連接核心技術,解決國產GPU生態“碎片化”和算力集群大規模擴展瓶頸問題。
益思芯科技:Stargate DPU
益思芯科技(上海)有限公司成立于2020年7月,團隊由國內外網絡、交換、存儲領域的核心專業人員組成,在網絡、交換、存儲及高性能CPU等領域具有深厚的技術實力。公司致力于為通信、互聯網行業提供領先的存儲與網絡芯片解決方案。
Stargate DPU智能網卡是一款具有自主知識產權的P4可編程云原生智能網卡。益思芯科技的P4網絡加速引擎是針對vSwitch加速而設計的VLIW ISA P4可編程處理器,不依賴于FPGA的可編程性,支持千萬級流表的同時性能可以做到數據包線速轉發。NVMe-oF引擎基于全硬件邏輯實現,具有高性能、低延遲等特點,是對高速共享存儲有較高要求的云計算、HPC、數據庫等應用領域的最佳選擇。
益思芯科技DPU智能網卡技術與產品創新點如下:
1.P4網絡可編程:具有自主知識產權的DSA P4引擎,滿足靈活的定制需求;具有高性能、低延遲、高靈活性、低功耗等特點。
2.NVMe-oF高速共享存儲:NVMe-oF把NVMe協議在單系統中的高性能、低延遲和低協議負擔的優勢發揮到了基于高速網絡的NVMe共享存儲架構中。益思芯NVMe-oF技術采用全硬件加速的端到端解決方案,是數據中心下一代共享存儲的最佳解決方案。
3.豐富的安全特性:支持完善的網絡安全、存儲數據安全處理;支持國密SM2/SM3/SM4加解密算法。
4.云原生軟件開發平臺:支持使用Host側的云原生驅動。與開源DPDK、SPDK庫無縫對接。
益思芯科技后續產品規劃如下:
云豹智能:Corsica DPU
云豹智能是一家專注于云計算和數據中心DPU和解決方案的領先半導體公司。云豹智能自主設計研發的Corsica DPU芯片是云計算數據中心高性能軟件定義數據處理器芯片,具備豐富的可編程性和完備的DPU功能,支持不同云計算場景和資源統一管理,優化數據中心計算資源利用率。
云豹Corsica DPU具有性能強大的“CPU+可編程硬件”,不僅能夠保證硬件計算的高能效,還能提供靈活的軟件定義的可編程能力,助力數據中心提供租戶自定義高能效云計算基礎設施服務。
云豹Corsica DPU具備層級化可編程、低時延網絡、統一運維管控和適應云計算業務持續發展的加速卸載等特性,主要聚焦解決當前數據中心應用中消耗CPU、GPU算力資源的網絡、存儲、安全以及應用相關問題,諸如AI、數據庫等性能要求敏感的數據處理任務。
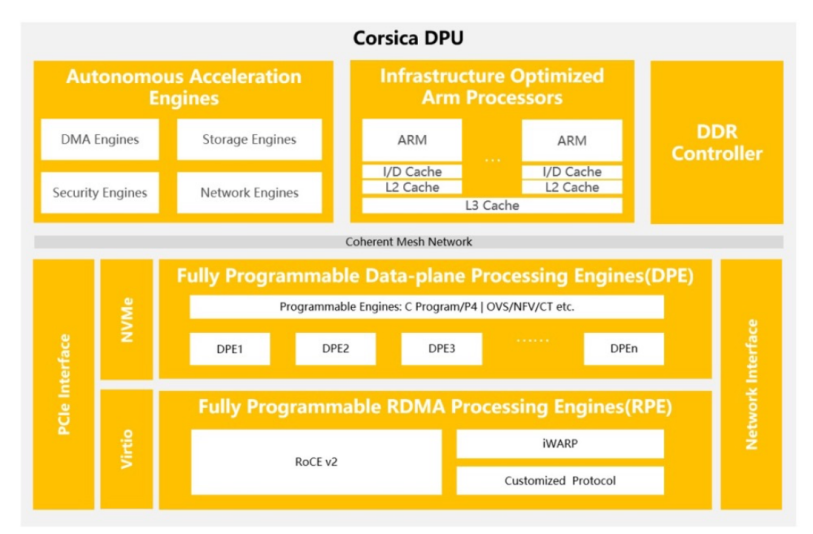
云豹Corsica DPU提供最高2*200G網絡連接,搭載性能強勁ARMv9架構的通用處理單元,滿足數據中心云計算基礎設施層業務的卸載需求。云豹智能Corsica DPU還配備眾多自主研發設計的可編程硬件加速處理引擎,實現網絡、存儲和安全的全面加速,具體情況如下:
數據面處理引擎提供高性能數據處理,具備靈活的軟硬件多層級可編程能力。
RDMA處理引擎支持RoCE和iWARP等主流協議和可編程擁塞控制算法。
安全處理引擎提供SM2/SM3/SM4等國密和其他主流加密算法。
支持安全啟動、機密計算、加解密的零信任安全解決方案,保護系統、數據、應用的安全。
支持DDP(Data Direct Path)數據直通技術,加速數據處理,提高 AI 訓練效率。
云脈芯聯:metaFusion和metaConnect系列
云脈芯聯自2021年成立以來已經先后發布了面向云計算場景的metaFusion系列DPU產品和主打RDMA高性能網絡的metaConnect系列智能網卡產品,能夠提升用戶計算集群整體的運算效率,釋放更多CPU資源支持上層應用,滿足數據中心云計算、智能計算、云存儲等核心場景集群高性能互聯和算力擴展的業務訴求。
云脈芯聯第一款高性能DPU產品metaFusion-50基于自主知識產權硬核業務邏輯研發設計,重點針對當前云計算數據中心發展的新需求,解決云計算產品形態支持能力的問題,實現統一計算、網絡、存儲的管理方式,簡化云計算平臺的管理運維成本,提升新基建的綜合業務能力。metaFusion-200高性能DPU為云計算基礎設施提供了豐富的虛擬化能力、高性能的開放網絡、靈活的存儲解決方案,同時在RoCEv2網絡還提供了自主創新的HyperDirect能力和可編程擁塞控制算法平臺,實現高性能網絡能力。

metaFusion-50(左)和metaFusion-200(右)
云脈芯聯推出的高性能智能網卡產品metaConnect-200,提供了高性能RDMA網絡能力,支持自主創新的HyperDirect技術,可以有效加速GPU和AI芯片的計算效率,可編程擁塞控制算法平臺可以幫助用戶根據不同的業務類型設計和應用適合的擁塞控制算法,提升端到端的網絡性能和可靠性,主要應用于AI/ML、HPC和高性能存儲場景。
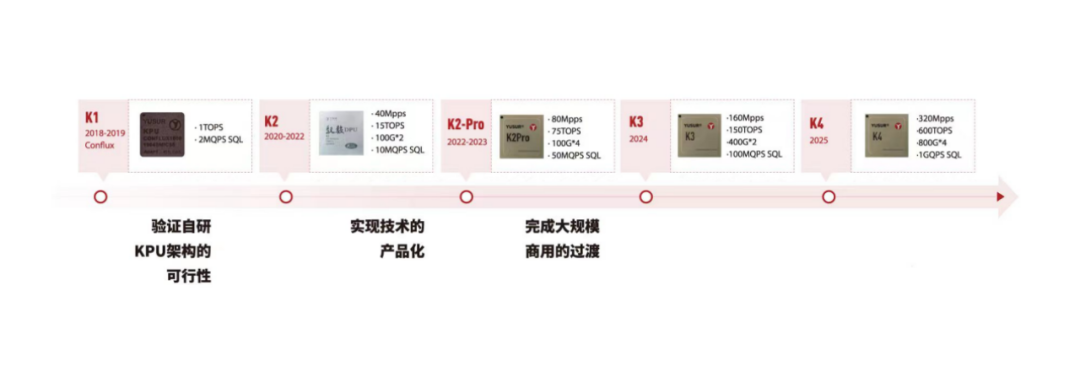
中科馭數:K1、K2、K2-Pro
中科馭數在網絡、存儲、計算等領域積累了TOE、RDMA、NVMe-oF、大數據處理等功能核,已開展三代DPU系列芯片的研發迭代工作。其自主研發的DPU產品可應用于超低延遲網絡、大數據處理、5G邊緣計算、高速存儲等場景,助力算力成為數字時代的新生產力。
中科馭數自研的第二代DPU芯片K2采用28nm成熟工藝制程,可以支持網絡、存儲、虛擬化等功能卸載,具有成本低、性能優、功耗小等優勢。尤其在性能上,其具有極其出色的時延性能,可以達到1.2微秒超低時延,支持最高200G網絡帶寬。在應用場景上可以廣泛適用于金融計算、高性能計算、數據中心、云原生、5G邊緣計算等場景。

K1(左)和K2(右)
在核心技術上,公司提出了創新性的軟件定義加速器技術(Software Defined Accelerator),自主研發了面向領域專用計算(DSA)的芯片架構KPU(Kernel Processing Unit)和敏捷異構軟件棧(HADOS)。基于中科馭數DPU芯片底層,搭載敏捷異構開發軟件HADOS,公司面向高吞吐、低時延場景,打造了三大體系“思威(SWIFT)系列、功夫(CONFLUX)系列、福來(FLEXFLOW)系列”,性能表現優越。
此外,中科馭數還積極布局DPU產品矩陣,打造軟硬一體化的高吞吐、低時延的產品生態,其中基于DPU研發的超低時延智能網卡、數據計算加速卡、以及面向金融計算領域的解決方案已經實現成熟規模化商用。
中科馭數DPU發展路線圖如下:
2023 DPU廠商大盤點(先鋒版)就先到這里啦,目前SDNLAB正在籌備2023 DPU廠商大盤點(終極版),歡迎符合條件的廠商與我們聯系,一起將生態做大、做強!
-
處理器
+關注
關注
68文章
19265瀏覽量
229671 -
DPU
+關注
關注
0文章
357瀏覽量
24169 -
RDMA
+關注
關注
0文章
77瀏覽量
8945
原文標題:2023 DPU廠商大盤點(先鋒版)
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
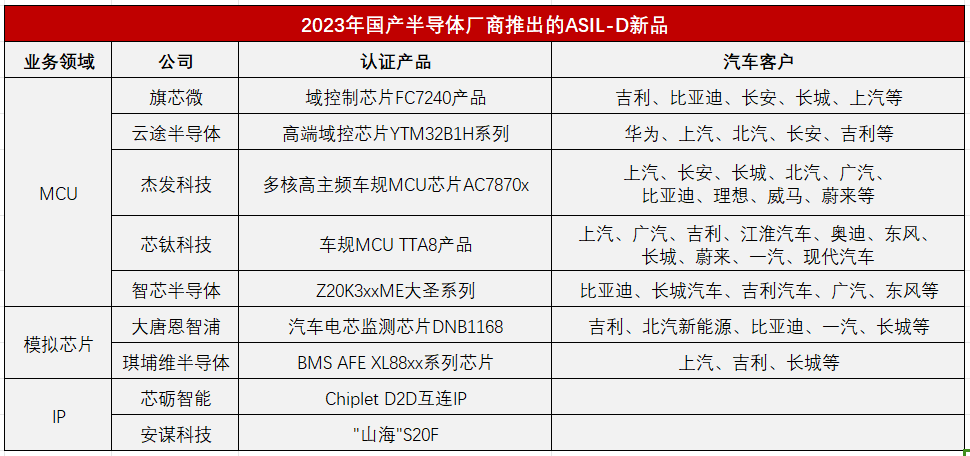
盤點2023年國產廠商推出ASIL-D芯片新品
盤點那些常見音視頻接口
中科馭數分析DPU在云原生網絡與智算網絡中的實際應用
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
杭州羅萊迪思創新研發中心榮獲杭州市“工人先鋒號”

明天線上見!DPU構建高性能云算力底座——DPU技術開放日最新議程公布!
國星光電成功斬獲“2023年度科技先鋒獎(科技進步獎)”

FPGA-Based DPU網卡的發展和應用
2023年五大無線通信模組廠商:整體虧損減少,車載市場表現強勁
國內SAP實施公司大盤點
中科馭數自研第二代DPU芯片K2獲得行業認可
英飛凌零碳之路——2023年度盤點(1)

“碳”路可持續發展|華潤微獲評2023可持續發展“創新先鋒企業”






 工商網監
工商網監
評論