") 基于一個完整的 LLM 訓(xùn)練流程
基于一個完整的 LLM 訓(xùn)練流程
在這篇文章中,我們將盡可能詳細(xì)地梳理一個完整的 LLM 訓(xùn)練流程。包括模型預(yù)訓(xùn)練(Pretrain)、Tokenizer 訓(xùn)練、指令微調(diào)(Instruction Tuning)等環(huán)節(jié)。
文末進(jìn)群,作者答疑、不錯過直播
1.預(yù)訓(xùn)練階段(Pretraining Stage)
工欲善其事,必先利其器。
當(dāng)前,不少工作選擇在一個較強(qiáng)的基座模型上進(jìn)行微調(diào),且通常效果不錯(如:[alpaca]、[vicuna] 等)。
這種成功的前提在于:預(yù)訓(xùn)練模型和下游任務(wù)的差距不大,預(yù)訓(xùn)練模型中通常已經(jīng)包含微調(diào)任務(wù)中所需要的知識。
但在實際情況中,我們通常會遇到一些問題,使得我們無法直接使用一些開源 backbone:
語言不匹配:大多數(shù)開源基座對中文的支持都不太友好,例如:[Llama]、[mpt]、[falcon] 等,這些模型在英文上效果都很優(yōu)秀,但在中文上卻差強(qiáng)人意。
專業(yè)知識不足:當(dāng)我們需要一個專業(yè)領(lǐng)域的 LLM 時,預(yù)訓(xùn)練模型中的知識就尤為重要。由于大多數(shù)預(yù)訓(xùn)練模型都是在通用訓(xùn)練語料上進(jìn)行學(xué)習(xí),對于一些特殊領(lǐng)域(金融、法律等)中的概念和名詞無法具備很好的理解。我們通常需要在訓(xùn)練語料中加入一些領(lǐng)域數(shù)據(jù)(如:[xuanyuan 2.0]),以幫助模型在指定領(lǐng)域內(nèi)獲得更好的效果。
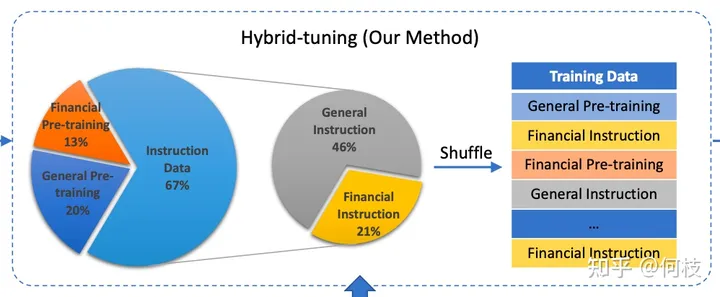 軒轅 2.0(金融對話模型)論文中所提及的訓(xùn)練語料分布,其中 Financial Pretraining 為金融語料
軒轅 2.0(金融對話模型)論文中所提及的訓(xùn)練語料分布,其中 Financial Pretraining 為金融語料
基于上述原因,我們在進(jìn)行 SFT 步驟之前,先來看看預(yù)訓(xùn)練任務(wù)是如何做的。
1.1 Tokenizer Training
在進(jìn)行預(yù)訓(xùn)練之前,我們需要先選擇一個預(yù)訓(xùn)練的模型基座。
一個較為普遍的問題是:大部分優(yōu)秀的語言模型都沒有進(jìn)行充分的中文預(yù)訓(xùn)練,
因此,許多工作都嘗試將在英語上表現(xiàn)比較優(yōu)秀的模型用中文語料進(jìn)行二次預(yù)訓(xùn)練,期望其能夠?qū)⒂⒄Z上的優(yōu)秀能力遷移到中文任務(wù)中來。
已經(jīng)有許多優(yōu)秀的倉庫做過這件事情,比如:[Chinese-LLaMA-Alpaca]。
但在進(jìn)行正式的訓(xùn)練之前,我們還有一步很重要的事情去做:詞表擴(kuò)充。
通俗來講,tokenizer 的目的就是將一句話進(jìn)行切詞,并將切好詞的列表喂給模型進(jìn)行訓(xùn)練。
例如:
輸入句子>>>你好世界 切詞結(jié)果>>>['你','好','世','界']
通常,tokenizer 有 2 種常用形式:WordPiece 和 BPE。
WordPiece
WordPiece 很好理解,就是將所有的「常用字」和「常用詞」都存到詞表中,
當(dāng)需要切詞的時候就從詞表里面查找即可。
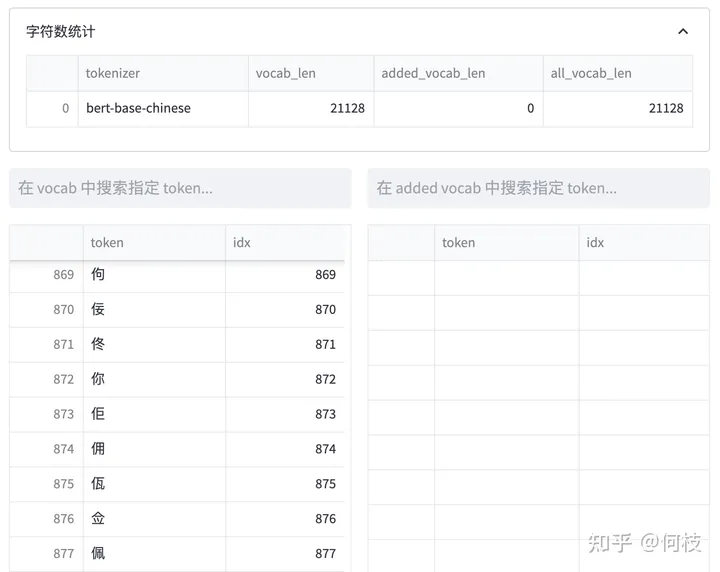 bert-base-chinese tokenizer 可視化
bert-base-chinese tokenizer 可視化
上述圖片來自可視化工具 [tokenizer_viewer]。
如上圖所示,大名鼎鼎的 BERT 就使用的這種切詞法。
當(dāng)我們輸入句子:你好世界,
BERT 就會依次查找詞表中對應(yīng)的字,并將句子切成詞的組合。
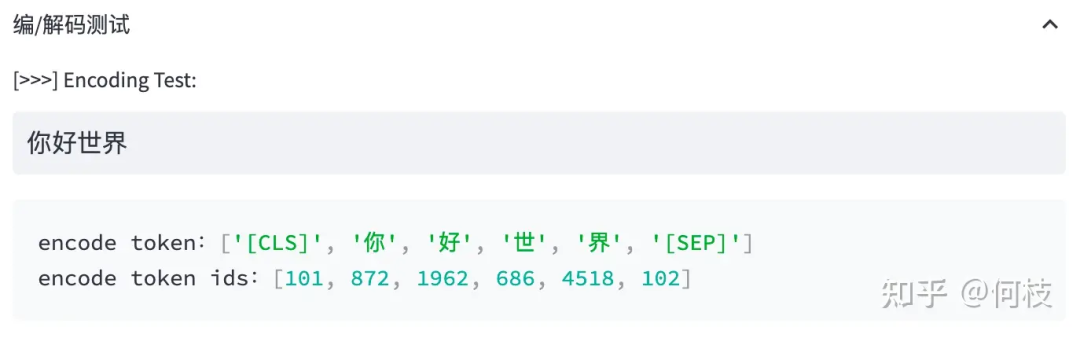 BERT 切詞測試圖
BERT 切詞測試圖
當(dāng)遇到詞表中不存在的字詞時,tokenizer 會將其標(biāo)記為特殊的字符 [UNK]:
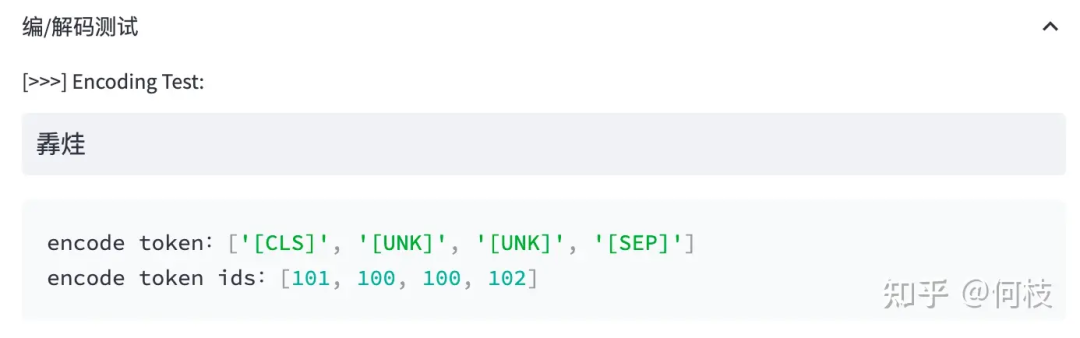 Out of Vocabulary(OOV)情況
Out of Vocabulary(OOV)情況
Byte Pair Encoder(BPE)
WordPiece 的方式很有效,但當(dāng)字詞數(shù)目過于龐大時這個方式就有點難以實現(xiàn)了。
對于一些多語言模型來講,要想窮舉所有語言中的常用詞(窮舉不全會造成 OOV),
既費人力又費詞表大小,為此,人們引入另一種方法:BPE。
BPE 不是按照中文字詞為最小單位,而是按照 unicode 編碼 作為最小粒度。
對于中文來講,一個漢字是由 3 個 unicode 編碼組成的,
因為平時我們不會拆開來看(畢竟中文漢字是不可拆分的),所以我一開始對這個概念也不太熟悉。
我們來看看 LLaMA 的 tokenizer(BPE)對中文是如何進(jìn)行 encode 的:
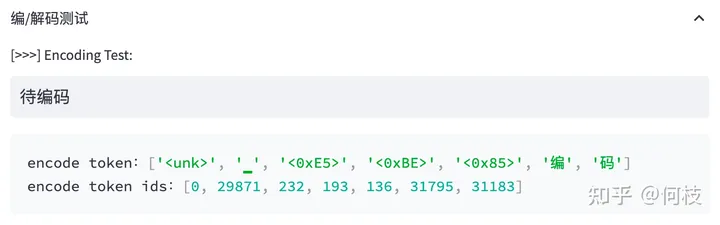
上述圖片來自可視化工具 [tokenizer_viewer]。
可以看到,「編碼」兩個字能夠被正常切成 2 個字,
但「待」卻被切成了 3 個 token,這里的每個 token 就是 1 個 unicode 編碼。
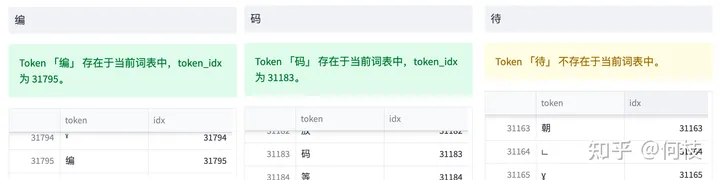 LLaMA tokenizer 查找結(jié)果,「待」不在詞表中,「編」「碼」在詞表中
LLaMA tokenizer 查找結(jié)果,「待」不在詞表中,「編」「碼」在詞表中
通過 token 查找功能,我們可以發(fā)現(xiàn)「編」「碼」在詞表中,但「待」不在詞表中。
但任何 1 個漢字都是可以由 unicode 表示(只是組合順序不同),因此「待」就被切成了 3 個 token。
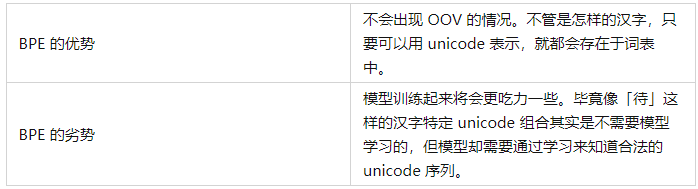
通常在模型訓(xùn)練不夠充足的時候,模型會輸出一些亂碼(不合法的 unicode 序列):
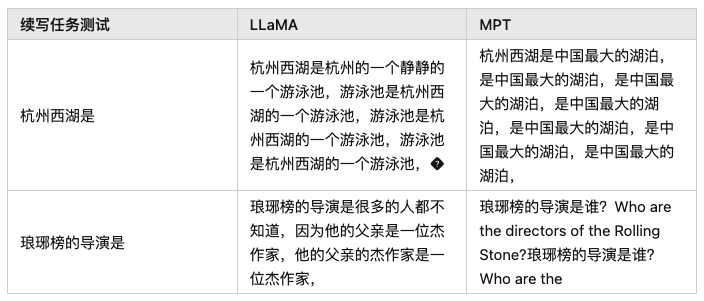
游泳池是杭州西湖的一個游泳池,???
詞表擴(kuò)充
為了降低模型的訓(xùn)練難度,人們通常會考慮在原來的詞表上進(jìn)行「詞表擴(kuò)充」,
也就是將一些常見的漢字 token 手動添加到原來的 tokenizer 中,從而降低模型的訓(xùn)練難度。
我們對比 [Chinese-LLaMA] 和 [LLaMA] 之間的 tokenizer 的區(qū)別:
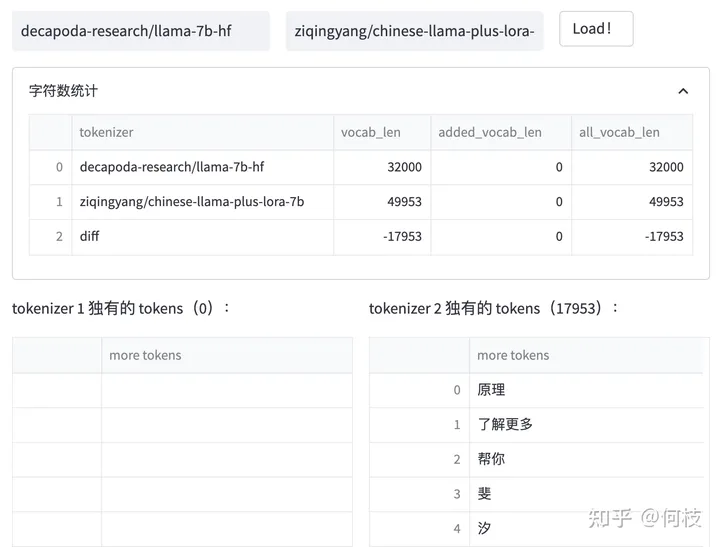 Chinese LLaMA 和 原始LLaMA 之間 tokenizer 的區(qū)別
Chinese LLaMA 和 原始LLaMA 之間 tokenizer 的區(qū)別
我們可以發(fā)現(xiàn):Chinese LLaMA 在原始 tokenizer 上新增了17953 個 tokens,且加入 token 的大部分為漢字。
而在 [BELLE] 中也有同樣的做法:
在 120w 行中文文本上訓(xùn)練出一個 5w 規(guī)模的 token 集合,
并將這部分 token 集合與原來的 LLaMA 詞表做合并,
最后再在 3.2B 的中文語料上對這部分新擴(kuò)展的 token embedding 做二次預(yù)訓(xùn)練。
 《Towards Better Instruction Following Language Models for Chinese》 Page-4
《Towards Better Instruction Following Language Models for Chinese》 Page-4
1.2 Language Model PreTraining
在擴(kuò)充完 tokenizer 后,我們就可以開始正式進(jìn)行模型的預(yù)訓(xùn)練步驟了。
Pretraining 的思路很簡單,就是輸入一堆文本,讓模型做 Next Token Prediction 的任務(wù),這個很好理解。
我們主要來討論幾種預(yù)訓(xùn)練過程中所用到的方法:數(shù)據(jù)源采樣、數(shù)據(jù)預(yù)處理、模型結(jié)構(gòu)。
數(shù)據(jù)源采樣
在 [gpt3] 的訓(xùn)練過程中,存在多個訓(xùn)練數(shù)據(jù)源,論文中提到:對不同的數(shù)據(jù)源會選擇不同采樣比例:
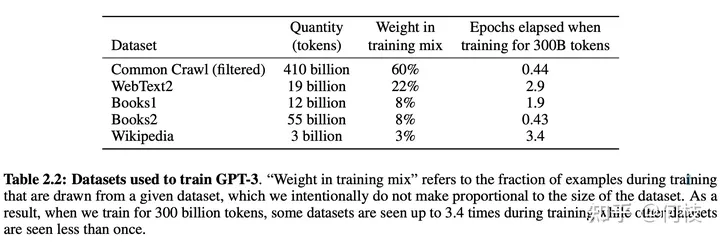 GPT3 Paper Page-9
GPT3 Paper Page-9
通過「數(shù)據(jù)源」采樣的方式,能夠緩解模型在訓(xùn)練的時候受到「數(shù)據(jù)集規(guī)模大小」的影響。
從上圖中可以看到,相對較大的數(shù)據(jù)集(Common Crawl)會使用相對較大的采樣比例(60%),
這個比例遠(yuǎn)遠(yuǎn)小于該數(shù)據(jù)集在整體數(shù)據(jù)集中所占的規(guī)模(410 / 499 = 82.1%),
因此,CC 數(shù)據(jù)集最終實際上只被訓(xùn)練了 0.44(0.6 / 0.82 * (300 / 499))個 epoch。
而對于規(guī)模比較小的數(shù)據(jù)集(Wikipedia),則將多被訓(xùn)練幾次(3.4 個 epoch)。
這樣一來就能使得模型不會太偏向于規(guī)模較大的數(shù)據(jù)集,從而失去對規(guī)模小但作用大的數(shù)據(jù)集上的學(xué)習(xí)信息。
數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理主要指如何將「文檔」進(jìn)行向量化。
通常來講,在 Finetune 任務(wù)中,我們通常會直接使用 truncation 將超過閾值(2048)的文本給截斷,
但在 Pretrain 任務(wù)中,這種方式顯得有些浪費。
以書籍?dāng)?shù)據(jù)為例,一本書的內(nèi)容肯定遠(yuǎn)遠(yuǎn)多余 2048 個 token,但如果采用頭部截斷的方式,
則每本書永遠(yuǎn)只能夠?qū)W習(xí)到開頭的 2048 tokens 的內(nèi)容(連序章都不一定能看完)。
因此,最好的方式是將長文章按照 seq_len(2048)作分割,將切割后的向量喂給模型做訓(xùn)練。
模型結(jié)構(gòu)
為了加快模型的訓(xùn)練速度,通常會在 decoder 模型中加入一些 tricks 來縮短模型訓(xùn)練周期。
目前大部分加速 tricks 都集中在 Attention 計算上(如:MQA 和 Flash Attention [falcon] 等);
此外,為了讓模型能夠在不同長度的樣本上都具備較好的推理能力,
通常也會在 Position Embedding 上進(jìn)行些處理,選用 ALiBi([Bloom])或 RoPE([GLM-130B])等。
具體內(nèi)容可以參考下面這篇文章[1]
1.3 數(shù)據(jù)集清理
中文預(yù)訓(xùn)練數(shù)據(jù)集可以使用 [悟道],數(shù)據(jù)集分布如下(主要以百科、博客為主):
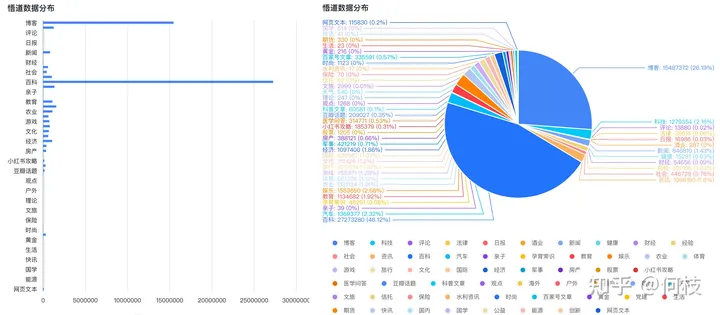 悟道-數(shù)據(jù)分布圖
悟道-數(shù)據(jù)分布圖
但開源數(shù)據(jù)集可以用于實驗,如果想突破性能,則需要我們自己進(jìn)行數(shù)據(jù)集構(gòu)建。
在 [falcon paper] 中提到,
僅使用「清洗后的互聯(lián)網(wǎng)數(shù)據(jù)」就能夠讓模型比在「精心構(gòu)建的數(shù)據(jù)集」上有更好的效果,
一些已有的數(shù)據(jù)集和它們的處理方法如下:
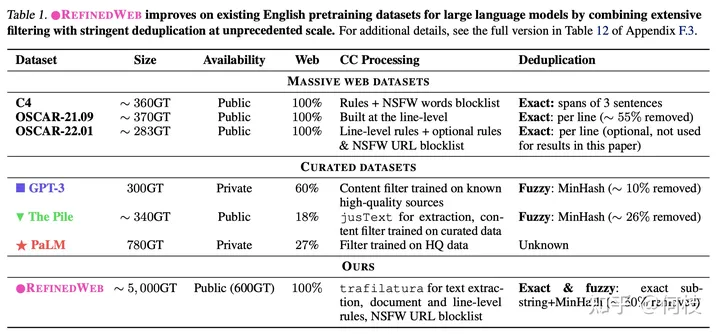 各種數(shù)據(jù)源 & 數(shù)據(jù)清理方法
各種數(shù)據(jù)源 & 數(shù)據(jù)清理方法
有關(guān) Falcon 更多的細(xì)節(jié)可以看這里[2]
1.4 模型效果評測
關(guān)于 Language Modeling 的量化指標(biāo),較為普遍的有 [PPL],[BPC] 等,
可以簡單理解為在生成結(jié)果和目標(biāo)文本之間的 Cross Entropy Loss 上做了一些處理。
這種方式可以用來評估模型對「語言模板」的擬合程度,
即給定一段話,預(yù)測后面可能出現(xiàn)哪些合法的、通順的字詞。
但僅僅是「生成通順句子」的能力現(xiàn)在已經(jīng)很難滿足現(xiàn)在人們的需求,
大部分 LLM 都具備生成流暢和通順語句能力,很難比較哪個好,哪個更好。
為此,我們需要能夠評估另外一個大模型的重要能力 —— 知識蘊含能力。
C-Eval
一個很好的中文知識能力測試數(shù)據(jù)集是 [C-Eval],涵蓋1.4w 道選擇題,共 52 個學(xué)科。
覆蓋學(xué)科如下:
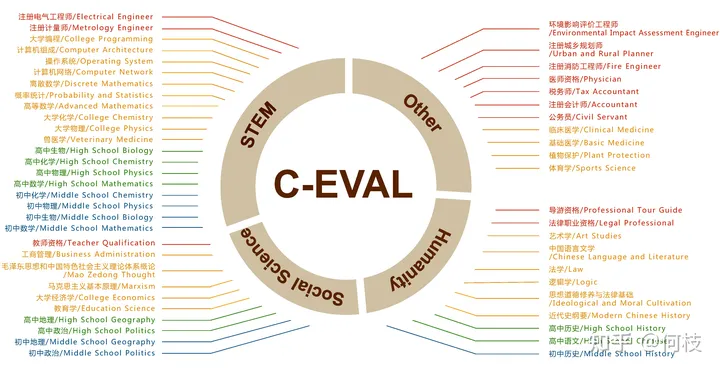 c-eval 數(shù)據(jù)集覆蓋學(xué)科圖
c-eval 數(shù)據(jù)集覆蓋學(xué)科圖
由于是選擇題的形式,我們可以通過將題目寫進(jìn) prompt 中,
并讓模型續(xù)寫 1 個 token,判斷這個續(xù)寫 token 的答案是不是正確答案即可。
但大部分沒有精調(diào)過的預(yù)訓(xùn)練模型可能無法續(xù)寫出「A B C D」這樣的選項答案,
因此,官方推薦使用 5-shot 的方式來讓模型知道如何輸出答案:
以下是中國關(guān)于會計考試的單項選擇題,請選出其中的正確答案。
下列關(guān)于稅法基本原則的表述中,不正確的是____。
A. 稅收法定原則包括稅收要件法定原則和稅務(wù)合法性原則
B. 稅收公平原則源于法律上的平等性原則
C. 稅收效率原則包含經(jīng)濟(jì)效率和行政效率兩個方面
D. 稅務(wù)機(jī)關(guān)按法定程序依法征稅,可以自由做出減征、停征或免征稅款的決定
答案:D
甲公司是國內(nèi)一家領(lǐng)先的新媒體、通信及移動增值服務(wù)公司,由于遭受世界金融危機(jī),甲公司經(jīng)濟(jì)利潤嚴(yán)重下滑,經(jīng)營面臨困境,但為了穩(wěn)定職工隊伍,公司并未進(jìn)行裁員,而是實行高層管理人員減薪措施。甲公司此舉采用的收縮戰(zhàn)略方式是____。
A. 轉(zhuǎn)向戰(zhàn)略
B. 放棄戰(zhàn)略
C. 緊縮與集中戰(zhàn)略
D. 穩(wěn)定戰(zhàn)略
答案:C
... # 第 3, 4, 5 道樣例題
下列各項中,不能增加企業(yè)核心競爭力的是____。
A. 產(chǎn)品差異化
B. 購買生產(chǎn)專利權(quán)
C. 創(chuàng)新生產(chǎn)技術(shù)
D. 聘用生產(chǎn)外包商
答案:
通過前面的樣例后,模型能夠知道在「答案:」后面應(yīng)該輸出選項字母。
于是,我們獲得模型續(xù)寫后的第一個 token 的概率分布(logits),
并取出「A B C D」這 4 個字母的概率,通過 softmax 進(jìn)行歸一化:
probs=( torch.nn.functional.softmax( torch.tensor( [ logits[self.tokenizer.encode( "A",bos=False,eos=False)[0]], logits[self.tokenizer.encode( "B",bos=False,eos=False)[0]], logits[self.tokenizer.encode( "C",bos=False,eos=False)[0]], logits[self.tokenizer.encode( "D",bos=False,eos=False)[0]], ] ), dim=0, ).detach().cpu().numpy() ) pred={0:"A",1:"B",2:"C",3:"D"}[np.argmax(probs)]#將概率最大的選項作為模型輸出的答案
C-Eval 通過這種方式測出了許多模型在中文知識上的效果,
由于是 4 選項問題,所以基線(隨機(jī)選擇)的正確率是 25%。
C-Eval 也再一次證明了 GPT-4 是個多么強(qiáng)大的知識模型:
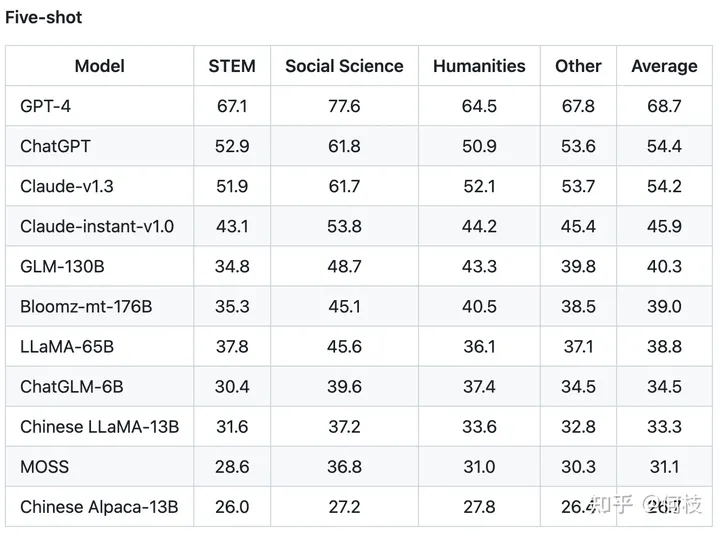 各模型在 5-shot 下的得分排名
各模型在 5-shot 下的得分排名
2. 指令微調(diào)階段(Instruction Tuning Stage)
在完成第一階段的預(yù)訓(xùn)練后,就可以開始進(jìn)到指令微調(diào)階段了。
由于預(yù)訓(xùn)練任務(wù)的本質(zhì)在于「續(xù)寫」,而「續(xù)寫」的方式并一定能夠很好的回答用戶的問題。
例如:

因為訓(xùn)練大多來自互聯(lián)網(wǎng)中的數(shù)據(jù),我們無法保證數(shù)據(jù)中只存在存在規(guī)范的「一問一答」格式,
這就會造成預(yù)訓(xùn)練模型通常無法直接給出人們想要的答案。
但是,這并不代表預(yù)訓(xùn)練模型「無知」,只是需要我們用一些巧妙的「技巧」來引導(dǎo)出答案:

不過,這種需要用戶精心設(shè)計從而去「套」答案的方式,顯然沒有那么優(yōu)雅。
既然模型知道這些知識,只是不符合我們?nèi)祟惖膶υ捔?xí)慣,那么我們只要再去教會模型「如何對話」就好了。
這就是 Instruction Tuning 要做的事情,即指令對齊。
OpenAI 在 [instruction-following] 中展示了 GPT-3 和經(jīng)過指令微調(diào)前后模型的區(qū)別:
 GPT-3 只是在做續(xù)寫任務(wù),InstructGPT 則能夠回答正確內(nèi)容
GPT-3 只是在做續(xù)寫任務(wù),InstructGPT 則能夠回答正確內(nèi)容
2.1 Self Instruction
既然我們需要去「教會模型說人話」,
那么我們就需要去精心編寫各式各樣人們在對話中可能詢問的問題,以及問題的答案。
在 [InstructGPT Paper] 中,使用了 1.3w 的數(shù)據(jù)來對 GPT-3.5 進(jìn)行監(jiān)督學(xué)習(xí)(下圖中左 SFT Data):
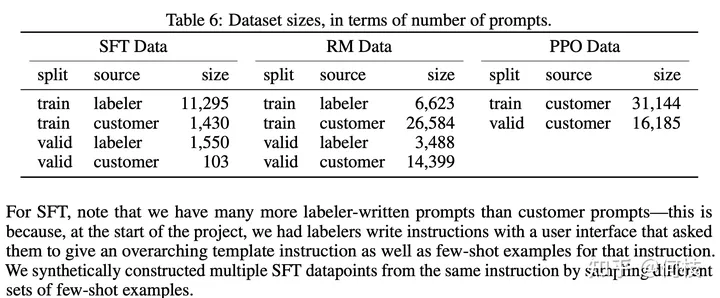 InstructGPT Paper 訓(xùn)練數(shù)據(jù)集預(yù)覽
InstructGPT Paper 訓(xùn)練數(shù)據(jù)集預(yù)覽
可以觀察到,數(shù)據(jù)集中人工標(biāo)注(labeler)占大頭,
這還僅僅只是 InstructGPT,和 ChatGPT 遠(yuǎn)遠(yuǎn)不是一個量級。
非官方消息:ChatGPT 使用了百萬量級的數(shù)據(jù)進(jìn)行指令微調(diào)。
可見,使用人工標(biāo)注是一件成本巨大的事情,只是找到人不夠,需要找到「專業(yè)」且「認(rèn)知一致」的標(biāo)注團(tuán)隊。
如果這件事從頭開始做自然很難(OpenAI 確實厲害),但今天我們已經(jīng)有了 ChatGPT 了,
我們讓 ChatGPT 來教我們自己的模型不就好了嗎?
這就是 Self Instruction 的思路,即通過 ChatGPT 的輸入輸出來蒸餾自己的模型。
一個非常出名的項目是 [stanford_alpaca]。
如果從 ChatGPT 「套」數(shù)據(jù),那么我們至少需要「套」哪些數(shù)據(jù)。
Instruction Tuning 中的「輸入」(問題)和「輸出」(答案)是訓(xùn)練模型的關(guān)鍵,
答案很好得到,喂給 ChatGPT 問題根據(jù)返回結(jié)果就能獲得,
但「問題」從哪里獲得呢?
(靠人想太累了,屏幕前的你不妨試試,看看短時間內(nèi)能想出多少有價值的問題)
Alpaca 則是使用「種子指令(seed)」,使得 ChatGPT 既生成「問題」又生成「答案」。
由于 Alpaca 是英文項目,為了便于理解,我們使用相同思路的中文項目 [BELLE] 作為例子。
通俗來講,就是人為的先給一些「訓(xùn)練數(shù)據(jù)樣例」讓 ChatGPT 看,
緊接著利用 ChatGPT 的續(xù)寫功能,讓其不斷地舉一反三出新的訓(xùn)練數(shù)據(jù)集:
你被要求提供10個多樣化的任務(wù)指令。這些任務(wù)指令將被提供給GPT模型,我們將評估GPT模型完成指令的能力。
以下是你提供指令需要滿足的要求:
1.盡量不要在每個指令中重復(fù)動詞,要最大化指令的多樣性。
2.使用指令的語氣也應(yīng)該多樣化。例如,將問題與祈使句結(jié)合起來。
3.指令類型應(yīng)該是多樣化的,包括各種類型的任務(wù),類別種類例如:brainstorming,open QA,closed QA,rewrite,extract,generation,classification,chat,summarization。
4.GPT語言模型應(yīng)該能夠完成這些指令。例如,不要要求助手創(chuàng)建任何視覺或音頻輸出。例如,不要要求助手在下午5點叫醒你或設(shè)置提醒,因為它無法執(zhí)行任何操作。例如,指令不應(yīng)該和音頻、視頻、圖片、鏈接相關(guān),因為GPT模型無法執(zhí)行這個操作。
5.指令用中文書寫,指令應(yīng)該是1到2個句子,允許使用祈使句或問句。
6.你應(yīng)該給指令生成適當(dāng)?shù)妮斎耄斎胱侄螒?yīng)包含為指令提供的具體示例,它應(yīng)該涉及現(xiàn)實數(shù)據(jù),不應(yīng)包含簡單的占位符。輸入應(yīng)提供充實的內(nèi)容,使指令具有挑戰(zhàn)性。
7.并非所有指令都需要輸入。例如,當(dāng)指令詢問一些常識信息,比如“世界上最高的山峰是什么”,不需要提供具體的上下文。在這種情況下,我們只需在輸入字段中放置“<無輸入>”。當(dāng)輸入需要提供一些文本素材(例如文章,文章鏈接)時,就在輸入部分直接提供一些樣例。當(dāng)輸入需要提供音頻、圖片、視頻或者鏈接時,則不是滿足要求的指令。
8.輸出應(yīng)該是針對指令和輸入的恰當(dāng)回答。
下面是10個任務(wù)指令的列表:
###
1.指令: 在面試中如何回答這個問題?
1.輸入:當(dāng)你在車?yán)铼毺帟r,你會想些什么?
1.輸出:如果是在晚上,我通常會考慮我今天所取得的進(jìn)步,如果是在早上,我會思考如何做到最好。我也會嘗試練習(xí)感恩和活在當(dāng)下的狀態(tài),以避免分心駕駛。
###
2.指令: 按人口對這些國家進(jìn)行排名。
2.輸入:巴西,中國,美國,日本,加拿大,澳大利亞
2.輸出:中國,美國,巴西,日本,加拿大,澳大利亞
###
3.指令:
如上述例子所示,我們先給出 2 個樣例,并讓 ChatGPT 進(jìn)行續(xù)寫:
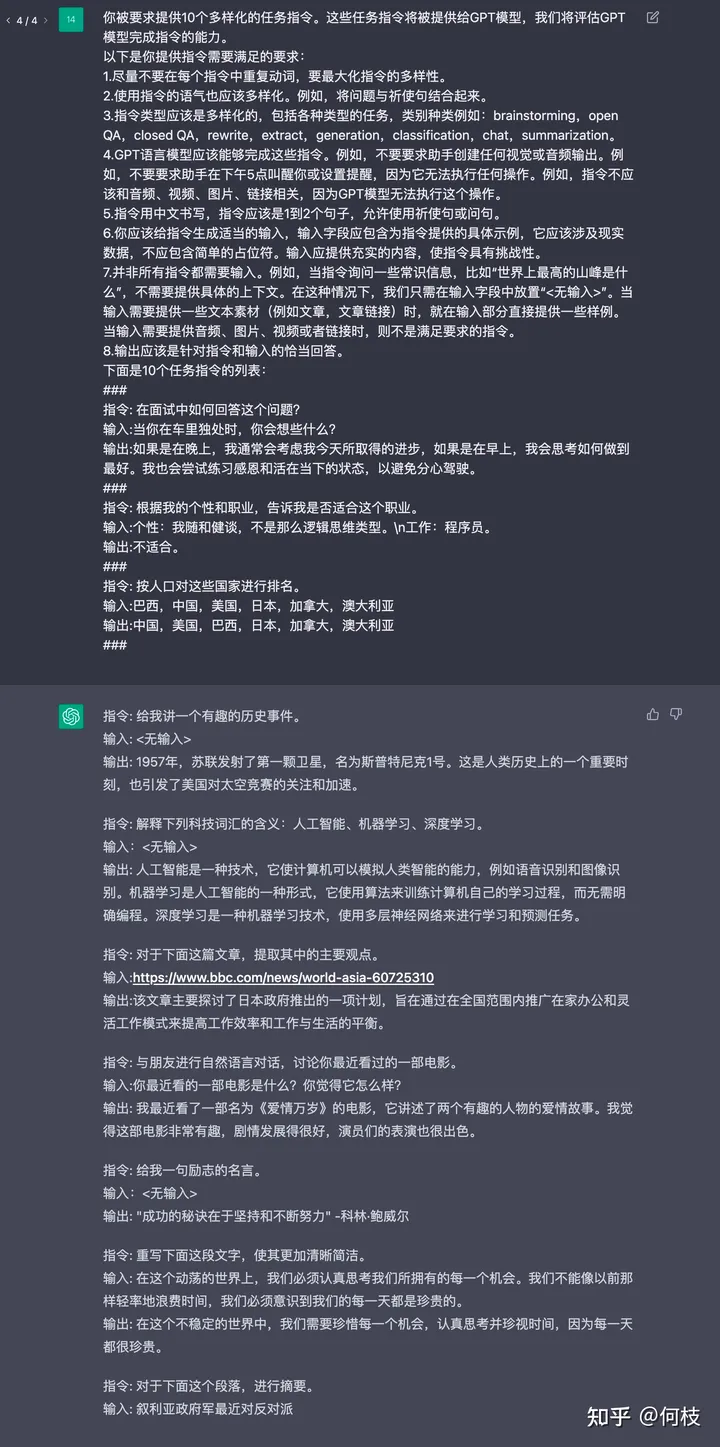 ChatGPT 續(xù)寫結(jié)果
ChatGPT 續(xù)寫結(jié)果
關(guān)于 BELLE 的更多細(xì)節(jié)可以參考這篇文章[3]
2.2 開源數(shù)據(jù)集整理
在這一章中,我們將梳理一些開源的 Instruction Tuning 的數(shù)據(jù)集,
除了直接拿來用以外,我們期望通過分析這些已有數(shù)據(jù)集,從而學(xué)習(xí)如何構(gòu)建一個指令數(shù)據(jù)集。
Alpaca
[stanford_alpaca] 采用上述的 self instruction 的方式采集了 5200 條指令訓(xùn)練數(shù)據(jù)集。
數(shù)據(jù)樣例如下:
{
"instruction":"Arrangethewordsinthegivensentencetoformagrammaticallycorrectsentence.",
"input":"quicklythebrownfoxjumped",
"output":"Thequickbrownfoxjumpedquickly."
}
其中,instruction 代表要求模型做的任務(wù),input 代表用戶輸入, output 代表喂給模型的 label。
Alpaca 覆蓋了多種類型的指令,其數(shù)據(jù)分布如下:
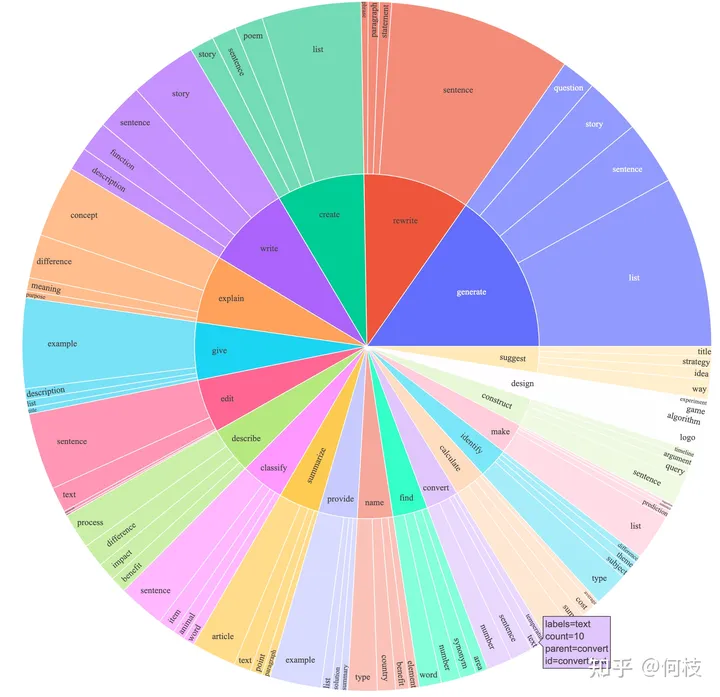 Alpaca 數(shù)據(jù)分布圖
Alpaca 數(shù)據(jù)分布圖
包含寫作、描述、分類、摘要等多種類型的任務(wù)集合。
BELLE
BELLE 開放了好幾種規(guī)模的數(shù)據(jù)集,[100萬]、[200萬]、[350萬] 等。
訓(xùn)練數(shù)據(jù)集樣例如下:
{
"instruction":"判斷給定的文章是否符合語法規(guī)則。如果不符合,請?zhí)峁┬薷慕ㄗh。下面是一篇文章的開頭:‘為了探討這個主題,本文將提供一系列數(shù)據(jù)和實例,以證明這一觀點。’",
"input":"",
"output":"這個開頭符合語法規(guī)則。"
}
由于數(shù)據(jù)量很大,我們無法統(tǒng)計出訓(xùn)練數(shù)據(jù)集中各任務(wù)的真實占比,
但從 [1000條評測集] 數(shù)據(jù)分布可以推測出,訓(xùn)練數(shù)據(jù)集中同樣包含:摘要、問答、分類等任務(wù)。
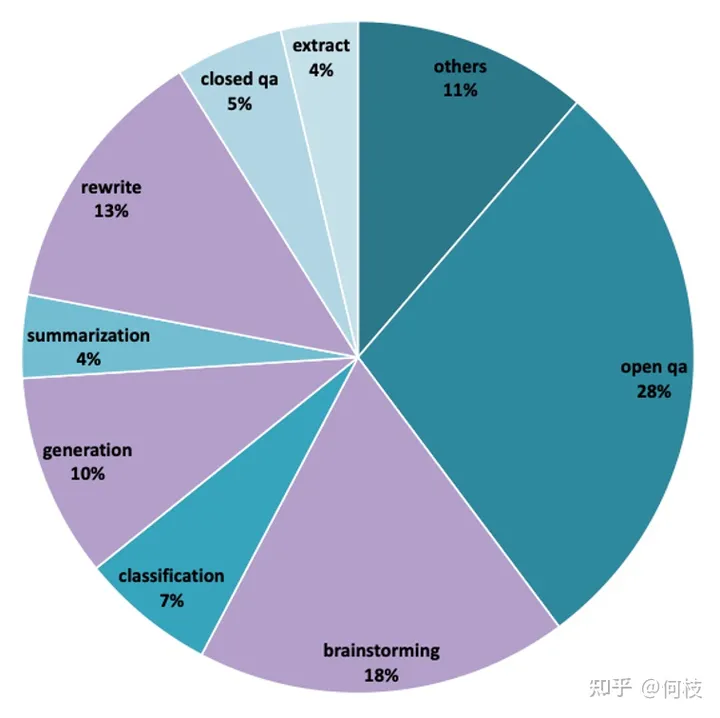 BELLE - 評測集分布
BELLE - 評測集分布
我們按照類別對評測數(shù)據(jù)進(jìn)行采樣,結(jié)果如下:
2.3 模型的評測方法
比起預(yù)訓(xùn)練(Pretrain)環(huán)節(jié)里相對明確的評價指標(biāo)(如PPL、NLL等),
Instruction 環(huán)節(jié)中的評價指標(biāo)比較令人頭疼。
鑒于語言生成模型的發(fā)展速度,BLEU 和 ROUGH 這樣的指標(biāo)已經(jīng)不再客觀。
一種比較流行的方式是像 [FastChat] 中一樣,利用 GPT-4 為模型的生成結(jié)果打分,
我們也嘗試使用同樣的 Prompt 對 3 種開源模型:OpenLlama、ChatGLM、BELLE 進(jìn)行測試。
注意:下面的測試結(jié)果僅源自我們自己的實驗,不具備任何權(quán)威性。
對于每一個問題,我們先獲得 ChatGPT 的回復(fù),以及另外 3 種模型的回復(fù),
接著我們將 「ChatGPT 答案 - 候選模型答案」這樣的 pair 喂給 GPT-4 打分(滿分為 10 分)。
得到的結(jié)果如下:
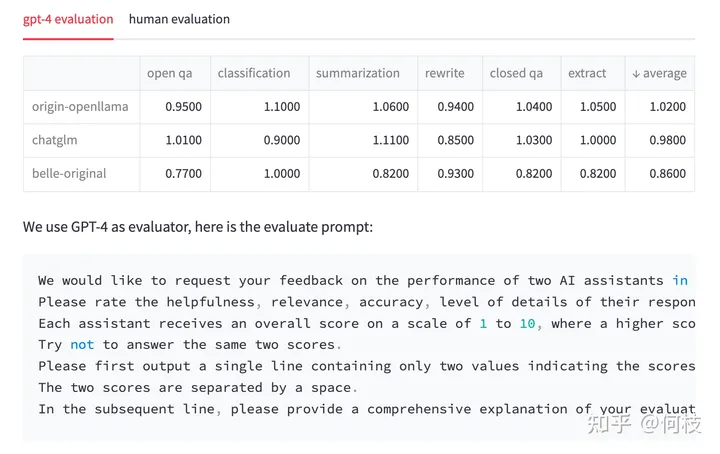 測試結(jié)果 & 測試 prompt
測試結(jié)果 & 測試 prompt
我們對每個任務(wù)單獨進(jìn)行了統(tǒng)計,并在最后一列求得平均值。
GPT-4 會對每一條測試樣本的 2 個答案分別進(jìn)行打分,并給出打分理由:
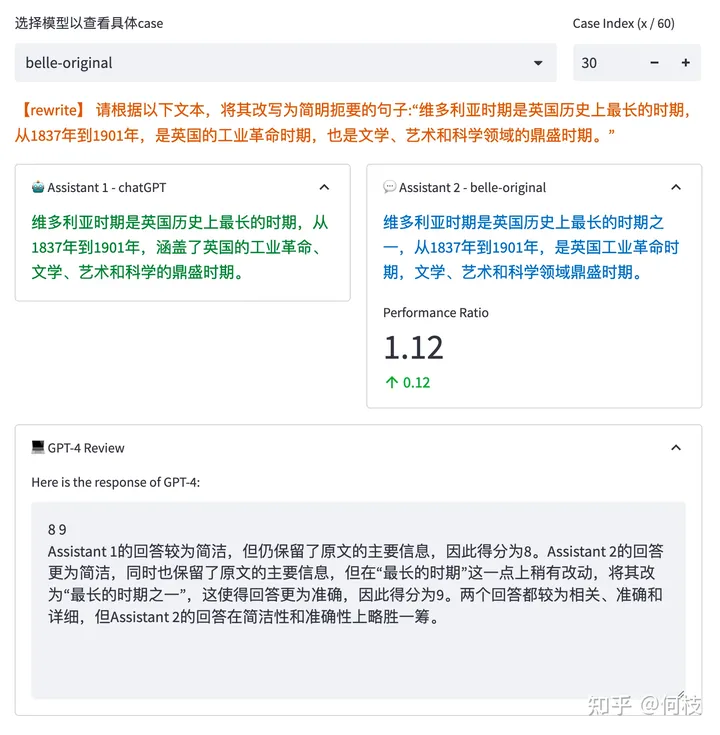 GPT-Review 的結(jié)果
GPT-Review 的結(jié)果
但是,我們發(fā)現(xiàn),GPT-4 打出的分?jǐn)?shù)和給出理由并不一定正確。
如上圖所示,GPT-4 為右邊模型的答案打出了更高的分?jǐn)?shù),給出的理由是:
將「最長時期」改為了「最長時期之一」會更準(zhǔn)確。
但事實上,Instruction 中明確設(shè)定就是「最長時期」,
這種「給高分」的理由其實是不正確的。
此外,我們還發(fā)現(xiàn),僅僅調(diào)換句子順序也會對最后打分結(jié)果產(chǎn)生影響,
針對這個問題,我們考慮「調(diào)換句子順序并求和平均」來緩解。
但不管怎么樣,GPT-4 給出的分?jǐn)?shù)或許并沒有我們想象中的那么靠譜,
為此,我們通過人工的 Review 的方式對每個答案進(jìn)行了一次回掃,得到的結(jié)果和標(biāo)準(zhǔn)如下:
再次重申:我們只是期望指出 GPT-4 打分可能會和實際產(chǎn)生偏差的問題,這里排名不具備任何權(quán)威性。
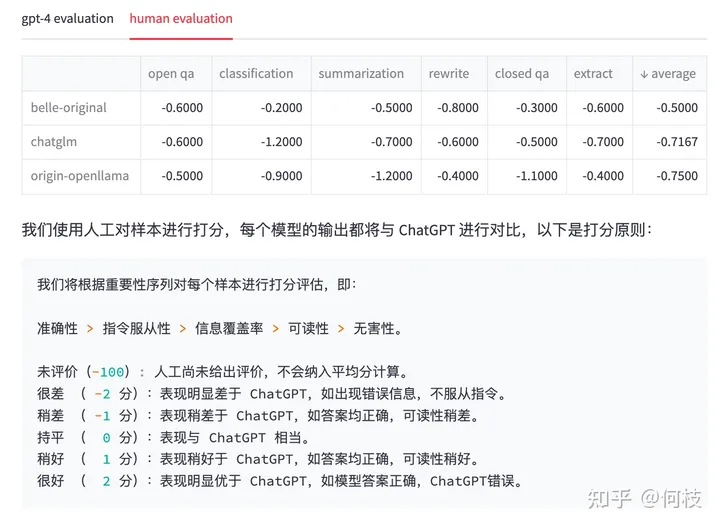 人工 Review 結(jié)果 & 打分原則
人工 Review 結(jié)果 & 打分原則
我們可以看到,
在 GPT-4 打分的結(jié)果中,已經(jīng)有模型的效果甚至超過了 ChatGPT(分?jǐn)?shù)為 1.02),
但再經(jīng)過人工 Review 后,ChatGPT 的答案是我們認(rèn)為更合理一些的。
當(dāng)然,最近陸陸續(xù)續(xù)的推出了許多新的評測方法,如:[PandaLM],
以及許多比較有影響力的評測集,如:[C-Eval]、[open_llm_leaderboard] 等,
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7002瀏覽量
88941 -
編碼
+關(guān)注
關(guān)注
6文章
940瀏覽量
54814 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48807 -
LLM
+關(guān)注
關(guān)注
0文章
286瀏覽量
327
原文標(biāo)題:從零詳細(xì)地梳理一個完整的 LLM 訓(xùn)練流程
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
大型語言模型(LLM)的自定義訓(xùn)練:包含代碼示例的詳細(xì)指南
MLC-LLM的編譯部署流程

大語言模型(LLM)預(yù)訓(xùn)練數(shù)據(jù)集調(diào)研分析

mlc-llm對大模型推理的流程及優(yōu)化方案
基于NVIDIA Megatron Core的MOE LLM實現(xiàn)和訓(xùn)練優(yōu)化

人臉識別模型訓(xùn)練流程
llm模型和chatGPT的區(qū)別
llm模型有哪些格式
llm模型訓(xùn)練一般用什么系統(tǒng)
LLM預(yù)訓(xùn)練的基本概念、基本原理和主要優(yōu)勢
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論