 為什么 MySQL 單表不能超過 2000 萬行?
為什么 MySQL 單表不能超過 2000 萬行?
最近看到一篇《我說 MySQL 每張表最好不要超過 2000 萬數據,面試官讓我回去等通知》的文章,非常有趣。
文中提到,他朋友在面試的過程中說,自己的工作就是把用戶操作信息存到 MySQL 里,因為數據量超大(5000 萬條左右),需要每天定時生成 3 張表,然后將數據取模分別存到這三張表里。
接下來是兩人的對話:

面試后續暫且不論,不過,互聯網江湖上的確流傳著一個說法:單表數據量超過 500 萬行時就要進行分表分庫,已經超過 2000 萬行時 MySQL 的性能就會急劇下降。
那么,MySQL 一張表最多能存多少數據?
今天我們就從技術層面剖析一下,MySQL 單表數據不能過大的根本原因是什么?
猜想 1,是索引深度嗎?
很多人認為:數據量超過 500 萬行或 2000 萬行時,引起 B+tree 的高度增加,延長了索引的搜索路徑,進而導致了性能下降。事實果真如此嗎?
我們先理一下關系,MySQL 采用了索引組織表的形式組織數據,葉子節點存儲數據,非葉子節點存儲主鍵與頁面號的映射關系。若用戶的主鍵長度是 8 字節時,MySQL 中頁面偏移占 4 個字節,在非葉子節點的時候實際上是 8+4=12 個字節,12 個字節表示一個頁面的映射關系。
MySQL 默認是 16K 的頁面,拋開它的配置 header,大概就是 15K,因此,非葉子節點的索引頁面可放 15*1024/12=1280 條數據,按照每行 1K 計算,每個葉子節點可以存 15 條數據。同理,三層就是 15*1280*1280=24576000 條數據。只有數據量達到 24576000 條時,深度才會增加為 4,所以,索引深度沒有那么容易增加,詳細數據可參考下表:
搜索路徑延長導致性能下降的說法,與當時的機械硬盤和內存條件不無關系。
之前機械硬盤的 IOPS 在 100 左右,而現在普遍使用的 SSD 的 IOPS 已經過萬,之前的內存最大幾十 G,現在服務器內存最大可達到 TB 級。
因此,即使深度增加,以目前的硬件資源,IO 也不會成為限制 MySQL 單表數據量的根本性因素。
那么,限制 MySQL 單表不能過大的根本性因素是什么?
猜想 2,是 SMO 無法并發嗎?
我們可以嘗試從 MySQL 所采用的存儲引擎 InnoDB 本身來探究一下。
大家知道 InnoDB 引擎使用的是索引組織表,它是通過索引來組織數據的,而它采用 B+tree 作為索引的數據結構。B+Tree 操作非原子,所以當一個線程做結構調整(SMO,Struction-Modification-Operation)時一般會涉及多個節點的改動。
SMO 動作過程中,此時若有另一個線程進來可能會訪問到錯誤的 B+Tree 結構,InnoDB 為了解決這個問題采用了樂觀鎖和悲觀鎖的并發控制協議。
InnoDB 對于葉子節點的修改操作如下:
方法一,先采用樂觀鎖的方式嘗試進行修改。
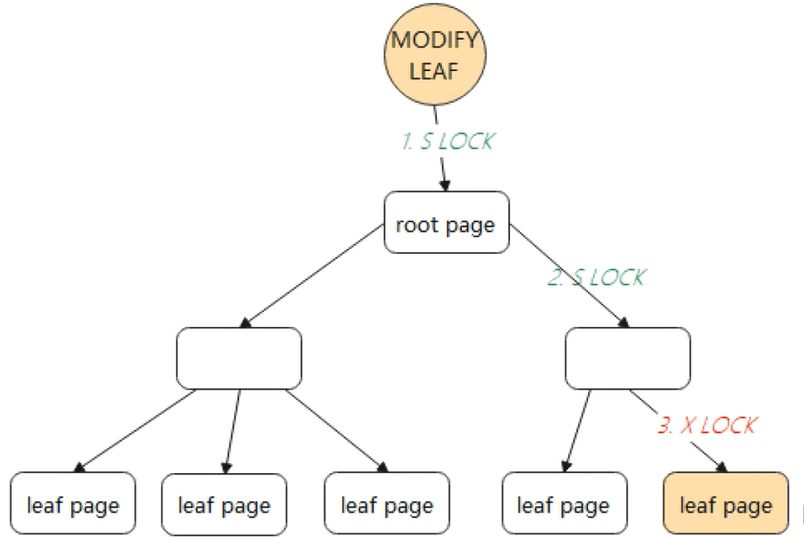
對根節點加 S 鎖(sharedlock,叫共享鎖,也稱讀鎖),依次對非葉子節點加 S 鎖。
如果葉子節點的修改不會引起 B+Tree 結構變動,如分裂、合并等操作,那么只需要對葉子節點進行加 X 鎖(exclusivelock,叫排他鎖,也稱為寫鎖)即可完成修改。如下圖中所示:
方式二,采用悲觀鎖的方式
如果對葉子結點的修改會觸發 SMO,那么會采用悲觀鎖的方式。
采用悲觀鎖,需要重新遍歷 B+Tree,對根節點加全局 SX 鎖(SX 鎖是行鎖),然后從根節點到葉子節點可能修改的節點加 X 鎖)。在整個 SMO 過程中,根節點始終持有 SX 鎖(SX 鎖表示有意向修改這個保護的范圍,SX 鎖與 SX 鎖、X 鎖沖突,與 S 鎖不沖突),此時其他的 SMO,則需要等待。
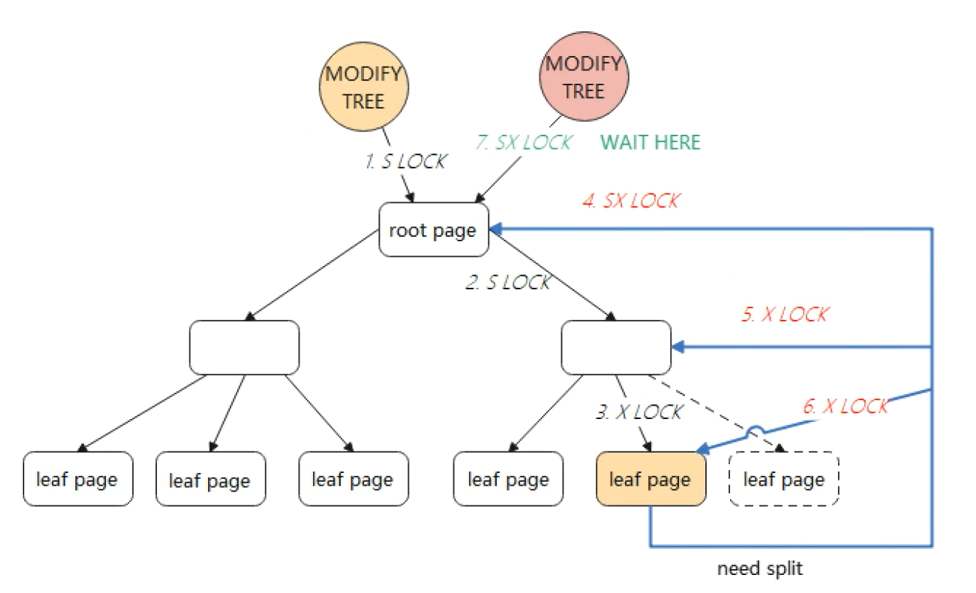
因此,InnoDB 對于簡單的主鍵查詢比較快,因為數據都存儲在葉子節點中,但對于數據量大且改操作比較多的 TP 型業務,并發會有很嚴重的瓶頸問題。
在對葉子節點的修改操作中,InnoDB 可以實現較好的 1 與 1、1 與 2 的并發,但是無法解決 2 的并發。因為在方式 2 中,根節點始終持有 SX 鎖,必須串行執行,等待上一個 SMO 操作完成。這樣在具有大量的 SMO 操作時,InnoDB 的 B+Tree 實現就會出現很嚴重的性能瓶頸。
解決方案
目前業界有一個更好的方案 B-LinkTree,與 B+Tree 相比,B-LinkTree 優化了 B+Tree 結構調整時的鎖粒度,只需要逐層加鎖,無需對 root 節點加全局鎖,因此,可以做到在 SMO 過程中寫操作的并發執行,保持高并發下性能的穩定。
主要改進點有 2 個:
1.中間節點增加 link 指針,指向右兄弟節點;
2.每個節點內增加字段 highkey,存儲該節點中最大的 key 值。
新增的 link 指針便是為了解決 SMO 過程中并發寫的問題,在 SMO 過程中,B-LinkTree 對修改節點逐層加鎖,修改完一層即可放鎖,然后去加上一層節點的鎖繼續修改。這樣在 InnoDB 引擎中被 SMO 阻塞的寫操作可以有機會再 SMO 操作過程中并發進行。
如下圖所示,在節點 2 分裂為節點 2 和 4 的過程中,只需要在最后一步將父節點 1 指向新節點 4 時,對父節點 1 加鎖,其他操作均無需對父節點加鎖,更無需對 root 節點加鎖,因此,大大提升了 SMO 過程中寫操作的并發度。
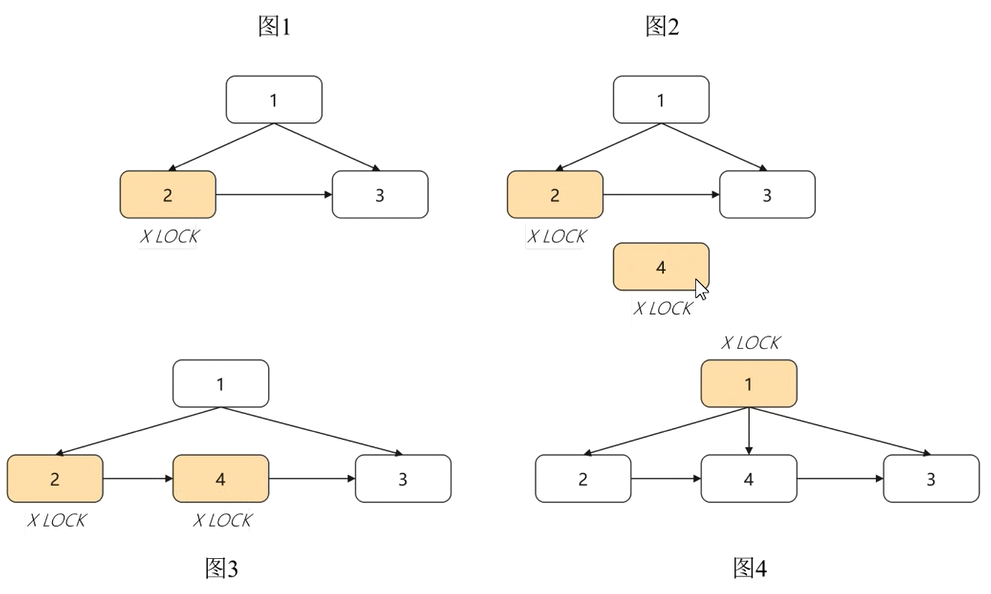
由此可見,和 B+Tree 全局加鎖對比起來,B-LinkTree 在高并發操作下的性能是顯著優于 B+Tree 的。華為云 GaussDB 當前采用的就是 B-LinkTree 索引數據結構。
InnoDB 的索引組織表更容易觸發 SMO
索引組織表的葉子節點,存儲主鍵以及應對行的數據,InnoDB 默認頁面為 16K,若每行數據的大小為 1000 字節,每個葉子節點僅能存儲 16 行數據。
在索引組織表中,當葉子節點的扇出值過低時,SMO 的觸發將更加頻繁,進而放大了 SMO 無法并發寫的缺陷。
目前業界有一個堆組織表的數據組織方案,也是華為云數據庫 GaussDB 采用的方案。它的葉子節點存儲索引鍵以及對應的行指針(所在的頁面編號及頁內偏移),堆組織表葉子節點可以存更多的數據,分析可得在同樣的數據量與業務并發量下,堆組織表會比索引組織表發生 SMO 概率低許多。
性能對比
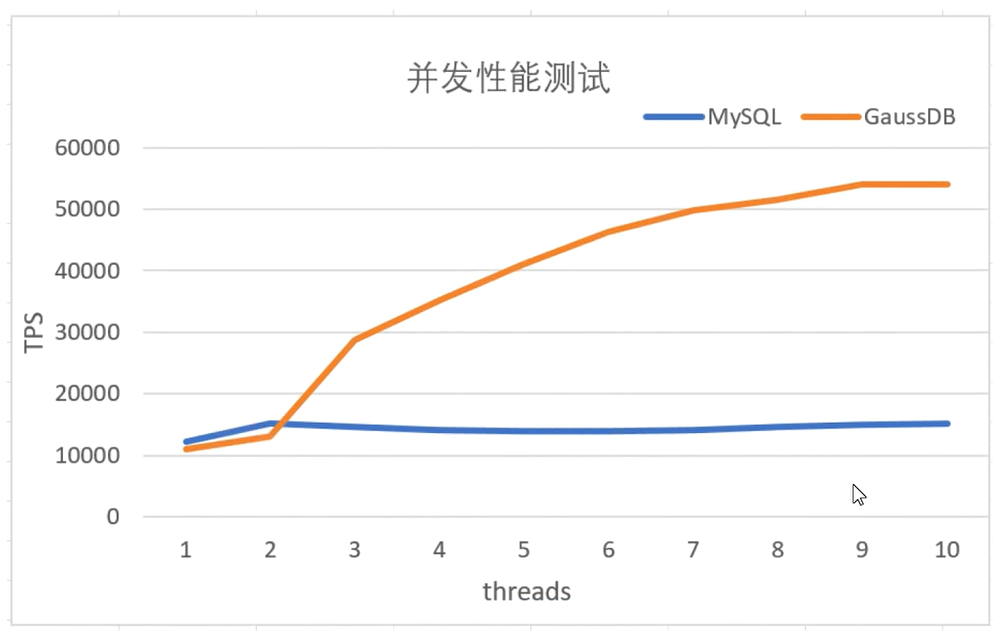
在 8U32G 的兩臺服務器分別搭建了 MySQL(B+Tree 和索引組織表)與 GaussDB(B-LinkTree 和堆組織表)的環境,進行了如下性能驗證:
實驗場景:在基礎表的場景上,測試增量隨機插入性能。
1.基礎表總大小 10G,包含主鍵隨機分布的 1000w 行數據,每行數據 1k;
2.插入主鍵隨機分布的 1000w 行數據,每行數據大小 1k,測試并發插入性能。
結論:隨著并發數的上升,GaussDB 能穩步提升系統的 TPS,而 MySQL 并發數的提高并不能帶來 TPS 的顯著提升。
總結
MySQL 無法支持大數據量下并發修改的根本原因,是因為其索引并發控制協議的缺陷造成的,而 MySQL 選擇索引組織表,又放大了這一缺陷。所以,開源 MySQL 數據庫更適用于主鍵查詢為主的簡單業務場景,如互聯網類應用,對于復雜的商業場景限制比較明顯。
相比之下,采用 B-LinkTree 和堆組織表的 GaussDB 數據庫在性能和場景應用方面更勝一籌。
審核編輯黃宇
-
MySQL
+關注
關注
1文章
804瀏覽量
26533 -
華為云
+關注
關注
3文章
2445瀏覽量
17410
發布評論請先 登錄
相關推薦
誰說MySQL單表行數不要超過2000W?
PoE交換機供電的功率為什么不能超過30瓦?
請問TAS5717的MCLK是12.288MHZ那頻率的上下誤差最大不能超過多少?
800萬行代碼的鴻蒙系統,在世界上處于什么水平?
【HarmonyOS】800萬行代碼的鴻蒙系統,在世界上處于什么水平?
濤思數據開源TDengine,10多萬行C代碼,登頂GitHub!

再創新高!深開鴻OpenHarmony社區代碼貢獻量超過200萬行!

社區代碼貢獻企業啟新篇,深開鴻代碼貢獻量超過200萬行
MySQL單表數據量限制:為何2000萬行成為瓶頸?






 工商網監
工商網監
評論