 id的機制不同在mysql的索引結構以及優缺點
id的機制不同在mysql的索引結構以及優缺點
前言
一、mysql和程序實例
1.1.要說明這個問題,我們首先來建立三張表
1.2.光有理論不行,直接上程序,使用spring的jdbcTemplate來實現增查測試:
1.3.程序寫入結果
1.4.效率測試結果
二、使用uuid和自增id的索引結構對比
2.1.使用自增id的內部結構
2.2.使用uuid的索引內部結構
2.3.使用自增id的缺點
三、總結

前言
在mysql中設計表的時候,mysql官方推薦不要使用uuid或者不連續不重復的雪花id(long形且唯一,單機遞增),而是推薦連續自增的主鍵id,官方的推薦是auto_increment,那么為什么不建議采用uuid,使用uuid究竟有什么壞處?
本篇博客我們就來分析這個問題,探討一下內部的原因。
本篇博客的目錄
mysql程序實例 使用uuid和自增id的索引結構對比 總結
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
一、mysql和程序實例
1.1.要說明這個問題,我們首先來建立三張表
分別是user_auto_key,user_uuid,user_random_key,分別表示自動增長的主鍵,uuid作為主鍵,隨機key作為主鍵,其它我們完全保持不變.
根據控制變量法,我們只把每個表的主鍵使用不同的策略生成,而其他的字段完全一樣,然后測試一下表的插入速度和查詢速度:
注:這里的隨機key其實是指用雪花算法算出來的前后不連續不重復無規律的id:一串18位長度的long值
id自動生成表:
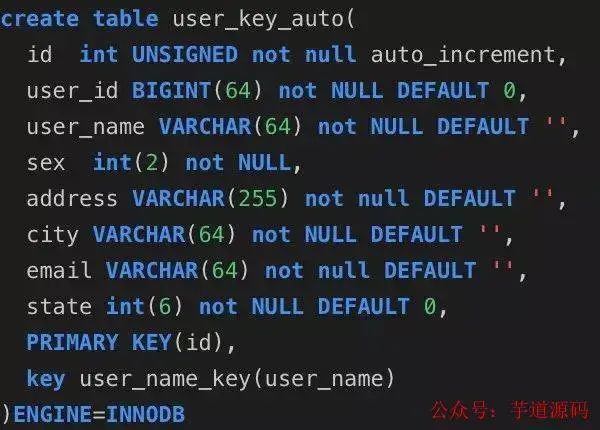
用戶uuid表
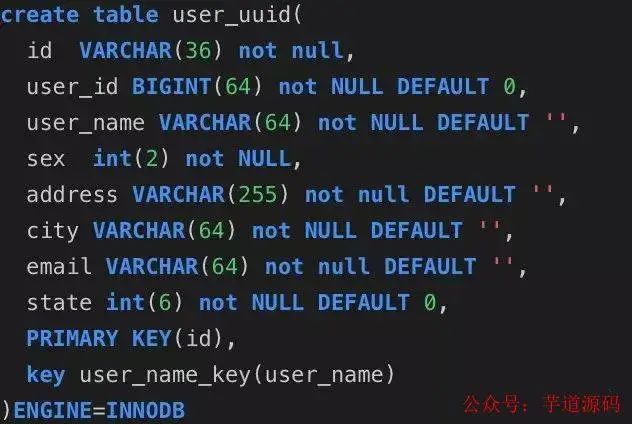
隨機主鍵表:
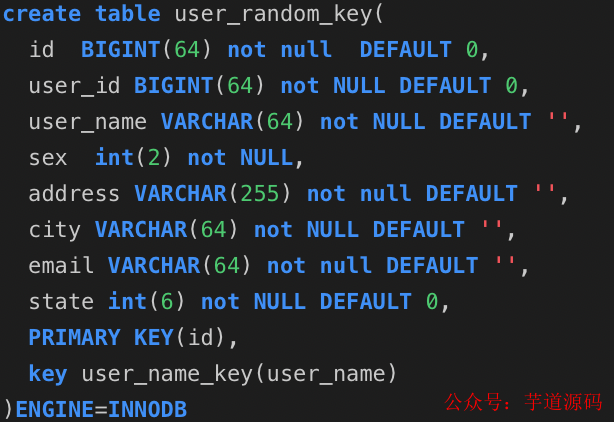
1.2.光有理論不行,直接上程序,使用spring的jdbcTemplate來實現增查測試:
技術框架:springboot+jdbcTemplate+junit+hutool,程序的原理就是連接自己的測試數據庫,然后在相同的環境下寫入同等數量的數據,來分析一下insert插入的時間來進行綜合其效率,為了做到最真實的效果,所有的數據采用隨機生成,比如名字、郵箱、地址都是隨機生成。
packagecom.wyq.mysqldemo; importcn.hutool.core.collection.CollectionUtil; importcom.wyq.mysqldemo.databaseobject.UserKeyAuto; importcom.wyq.mysqldemo.databaseobject.UserKeyRandom; importcom.wyq.mysqldemo.databaseobject.UserKeyUUID; importcom.wyq.mysqldemo.diffkeytest.AutoKeyTableService; importcom.wyq.mysqldemo.diffkeytest.RandomKeyTableService; importcom.wyq.mysqldemo.diffkeytest.UUIDKeyTableService; importcom.wyq.mysqldemo.util.JdbcTemplateService; importorg.junit.jupiter.api.Test; importorg.springframework.beans.factory.annotation.Autowired; importorg.springframework.boot.test.context.SpringBootTest; importorg.springframework.util.StopWatch; importjava.util.List; @SpringBootTest classMysqlDemoApplicationTests{ @Autowired privateJdbcTemplateServicejdbcTemplateService; @Autowired privateAutoKeyTableServiceautoKeyTableService; @Autowired privateUUIDKeyTableServiceuuidKeyTableService; @Autowired privateRandomKeyTableServicerandomKeyTableService; @Test voidtestDBTime(){ StopWatchstopwatch=newStopWatch("執行sql時間消耗"); /** *auto_incrementkey任務 */ finalStringinsertSql="INSERTINTOuser_key_auto(user_id,user_name,sex,address,city,email,state)VALUES(?,?,?,?,?,?,?)"; ListinsertData=autoKeyTableService.getInsertData(); stopwatch.start("自動生成key表任務開始"); longstart1=System.currentTimeMillis(); if(CollectionUtil.isNotEmpty(insertData)){ booleaninsertResult=jdbcTemplateService.insert(insertSql,insertData,false); System.out.println(insertResult); } longend1=System.currentTimeMillis(); System.out.println("autokey消耗的時間:"+(end1-start1)); stopwatch.stop(); /** *uudID的key */ finalStringinsertSql2="INSERTINTOuser_uuid(id,user_id,user_name,sex,address,city,email,state)VALUES(?,?,?,?,?,?,?,?)"; List insertData2=uuidKeyTableService.getInsertData(); stopwatch.start("UUID的key表任務開始"); longbegin=System.currentTimeMillis(); if(CollectionUtil.isNotEmpty(insertData)){ booleaninsertResult=jdbcTemplateService.insert(insertSql2,insertData2,true); System.out.println(insertResult); } longover=System.currentTimeMillis(); System.out.println("UUIDkey消耗的時間:"+(over-begin)); stopwatch.stop(); /** *隨機的long值key */ finalStringinsertSql3="INSERTINTOuser_random_key(id,user_id,user_name,sex,address,city,email,state)VALUES(?,?,?,?,?,?,?,?)"; List insertData3=randomKeyTableService.getInsertData(); stopwatch.start("隨機的long值key表任務開始"); Longstart=System.currentTimeMillis(); if(CollectionUtil.isNotEmpty(insertData)){ booleaninsertResult=jdbcTemplateService.insert(insertSql3,insertData3,true); System.out.println(insertResult); } Longend=System.currentTimeMillis(); System.out.println("隨機key任務消耗時間:"+(end-start)); stopwatch.stop(); Stringresult=stopwatch.prettyPrint(); System.out.println(result); }
1.3.程序寫入結果
user_key_auto寫入結果:
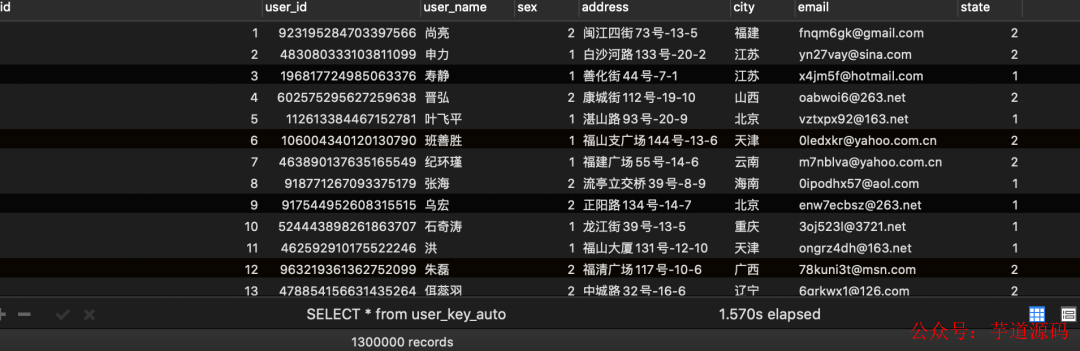
user_random_key寫入結果:
user_uuid表寫入結果:
1.4.效率測試結果
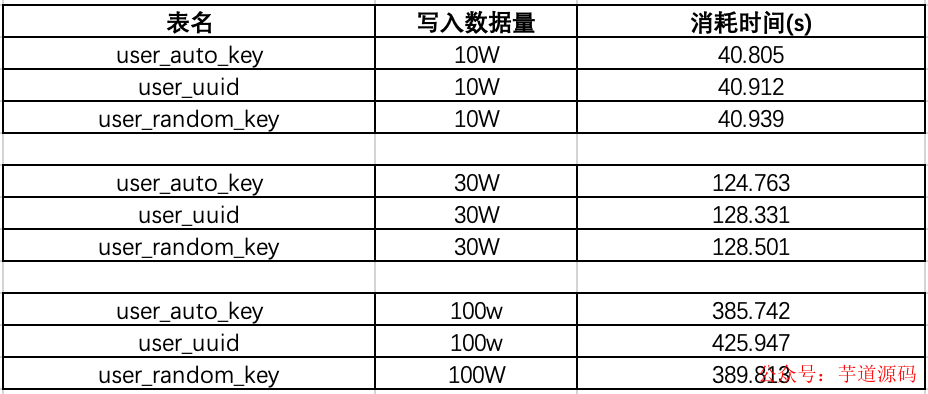
在已有數據量為130W的時候:我們再來測試一下插入10w數據,看看會有什么結果:

可以看出在數據量100W左右的時候,uuid的插入效率墊底,并且在后序增加了130W的數據,uudi的時間又直線下降。
時間占用量總體可以打出的效率排名為:auto_key>random_key>uuid,uuid的效率最低,在數據量較大的情況下,效率直線下滑。那么為什么會出現這樣的現象呢?帶著疑問,我們來探討一下這個問題:
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
二、使用uuid和自增id的索引結構對比
2.1.使用自增id的內部結構
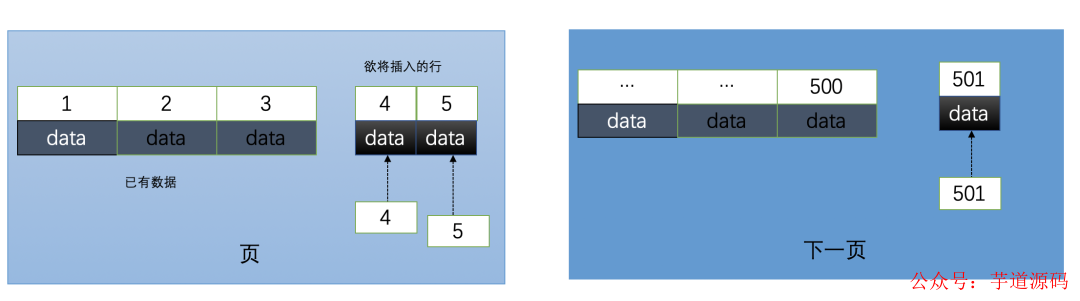
自增的主鍵的值是順序的,所以Innodb把每一條記錄都存儲在一條記錄的后面。當達到頁面的最大填充因子時候(innodb默認的最大填充因子是頁大小的15/16,會留出1/16的空間留作以后的 修改):
①下一條記錄就會寫入新的頁中,一旦數據按照這種順序的方式加載,主鍵頁就會近乎于順序的記錄填滿,提升了頁面的最大填充率,不會有頁的浪費
②新插入的行一定會在原有的最大數據行下一行,mysql定位和尋址很快,不會為計算新行的位置而做出額外的消耗
③減少了頁分裂和碎片的產生
2.2.使用uuid的索引內部結構
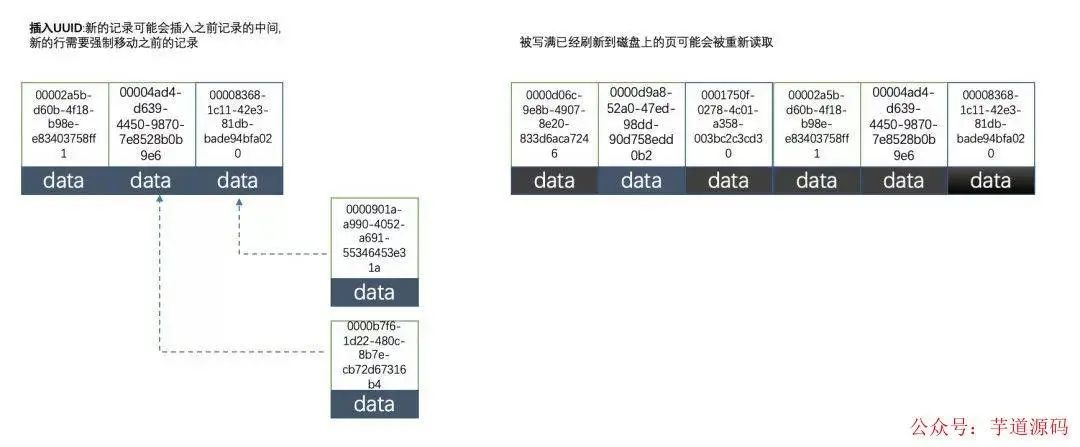
因為uuid相對順序的自增id來說是毫無規律可言的,新行的值不一定要比之前的主鍵的值要大,所以innodb無法做到總是把新行插入到索引的最后,而是需要為新行尋找新的合適的位置從而來分配新的空間。
這個過程需要做很多額外的操作,數據的毫無順序會導致數據分布散亂,將會導致以下的問題:
①寫入的目標頁很可能已經刷新到磁盤上并且從緩存上移除,或者還沒有被加載到緩存中,innodb在插入之前不得不先找到并從磁盤讀取目標頁到內存中,這將導致大量的隨機IO
②因為寫入是亂序的,innodb不得不頻繁的做頁分裂操作,以便為新的行分配空間,頁分裂導致移動大量的數據,一次插入最少需要修改三個頁以上
③由于頻繁的頁分裂,頁會變得稀疏并被不規則的填充,最終會導致數據會有碎片
在把隨機值(uuid和雪花id)載入到聚簇索引(innodb默認的索引類型)以后,有時候會需要做一次OPTIMEIZE TABLE來重建表并優化頁的填充,這將又需要一定的時間消耗。
結論:使用innodb應該盡可能的按主鍵的自增順序插入,并且盡可能使用單調的增加的聚簇鍵的值來插入新行
2.3.使用自增id的缺點
那么使用自增的id就完全沒有壞處了嗎?并不是,自增id也會存在以下幾點問題:
①別人一旦爬取你的數據庫,就可以根據數據庫的自增id獲取到你的業務增長信息,很容易分析出你的經營情況
②對于高并發的負載,innodb在按主鍵進行插入的時候會造成明顯的鎖爭用,主鍵的上界會成為爭搶的熱點,因為所有的插入都發生在這里,并發插入會導致間隙鎖競爭
③Auto_Increment鎖機制會造成自增鎖的搶奪,有一定的性能損失
附:Auto_increment的鎖爭搶問題,如果要改善需要調優innodb_autoinc_lock_mode的配置
三、總結
本篇博客首先從開篇的提出問題,建表到使用jdbcTemplate去測試不同id的生成策略在大數據量的數據插入表現,然后分析了id的機制不同在mysql的索引結構以及優缺點,深入的解釋了為何uuid和隨機不重復id在數據插入中的性能損耗,詳細的解釋了這個問題。
在實際的開發中還是根據mysql的官方推薦最好使用自增id,mysql博大精深,內部還有很多值得優化的點需要我們學習。
-
磁盤
+關注
關注
1文章
375瀏覽量
25201 -
數據庫
+關注
關注
7文章
3794瀏覽量
64362 -
MySQL
+關注
關注
1文章
804瀏覽量
26531
原文標題:用雪花 id 和 uuid 做 MySQL 主鍵,被領導懟了
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
闡述FreeRTOS系統中的機制及在應用中的優缺點
DMA的傳輸過程與優缺點
MySQL索引使用原則
MySQL索引的使用問題
MySQL為什么選擇B+樹作為索引結構?
索引是什么意思 優缺點有哪些
一文了解MySQL索引機制






 工商網監
工商網監
評論