


把大模型的訓練門檻打下來!我們在單張消費級顯卡上實現了多模態大模型(LaVIN-7B, LaVIN-13B)的適配和訓練,這篇文章主要介紹一下用到的技術方案和技術細節,供有需要的人參考。這里用到的模型是LaVIN(語言模型是LLaMA,視覺模型是ViT-L)。LaVIN通過參數高效的訓練能將LLaMA拓展到多模態來完成圖文問答、對話以及文本對話等等任務。
目前的結果:7B的多模態大模型訓練(LaVIN-7B)大約需要8~9G的顯存,13B的多模態大模型訓練(LaVIN-13B)大約需要13~14G顯存。目前的模型在單張消費級顯卡上已經完全能夠完成訓練了,性能相較于fp16略有下降,但是仍然極具競爭力!未來預計65B的模型也能在單張A100(40G)上完成訓練,我們后續會公布結果。
技術方案
我們的技術方案結合了LaVIN和qlora,主要分為以下幾點:
參數高效的多模態適配 (大概減少了一大半顯存)
4bit量化訓練 (大概減少了3~8G的固定顯存)
梯度累計+gradient checkpointing (大概減少了一半多的顯存)
Paged Optimizer (作用不是很明顯)
參數高效的多模態適配。
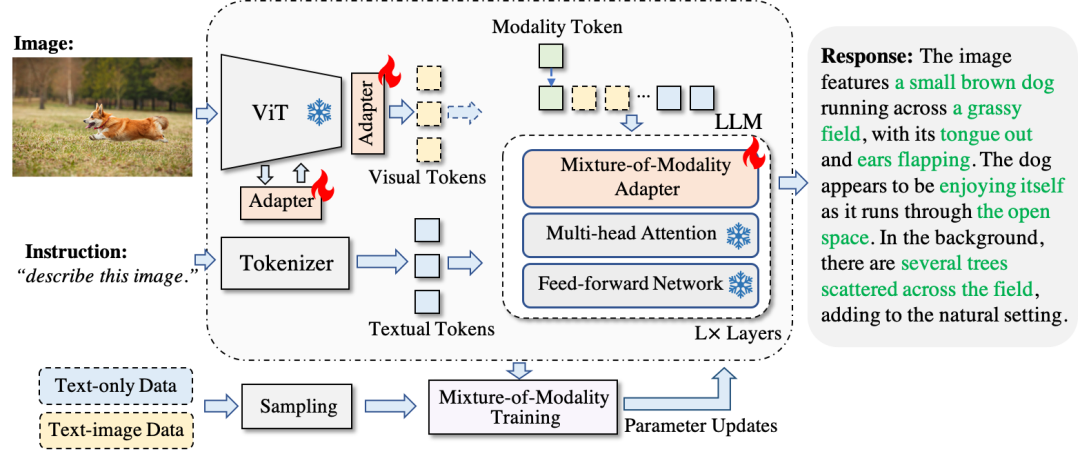
在此之前,我先簡單介紹一下之前的工作《Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models》。我們在這個工作中提出了一種參數高效的適配方法,能夠在將整個LLM參數凍住的情況下實現:
參數高效的多模態大模型適配(僅花費3~6M額外參數)
端到端高效訓練 (減少2/3的訓練時間)
單模態和多模態的自動切換(兼容不同模態)
通過這種方式,我們在ScienceQA上達到了接近SOTA的性能,同時實現了文本模態和圖文模態的同時適配。這種參數高效的訓練方式,實際上節約了大部分的顯存。以LLaVA為比較對象,在完全微調大模型的情況下,LLaVA-13B在A100(80G)上會爆顯存。相比之下,LaVIN-13B僅僅需要大約55G的顯存開銷。考慮到LLaVA還使用了gradient checkpointing,LaVIN-13B至少節省了一半的顯存開銷(估計),同時訓練速度會更快。相比于現有的參數高效的方法,我們的方案在性能和適配性上有顯著優勢,具體參考論文,這里不贅述了。但是由于deepspeed好像不支持參數高效的訓練方式,所以實際中顯存開銷其實和加滿優化的LLaVA差不多,甚至略多一點。
4bit量化訓練
4bit量化訓練主要參考了qlora。簡單來說,qlora把LLM的權重量化成了4bit來存儲,同時在訓練過程中反量化成16bit來保證訓練精度。通過這種方式,能夠大大降低訓練過程中的顯存開銷(訓練速度應該區別不大)。這種方法非常適合和參數高效的方法進行結合。但是原文中針對的是單模態的LLM,同時代碼已經封在了huggingface的庫里。因此,我們把核心代碼從huggingface的庫里抽取出來,同時遷移到了LaVIN的代碼里。主要原理就是將LLM中所有的線性層替換成4bit的量化層,感興趣的可以去參考一下我們的寫法,在quantization.py以及mm_adaptation.py中大概十來行代碼。
4bit量化訓練之后,顯存在bs>1的時候下降的不是特別明顯。LaVIN-7B大概下降了4~6G的樣子,但是這部分的顯存下降是固定的,其實非常有價值。到這里我也很好奇qlora怎么把模型塞到單卡里的,這個時候LaVIN-7B的顯存開銷大概還在36+G的水平。后面check了一下他們的代碼發現了接下來的關鍵設置。
梯度累計+gradient checkpointing
這里的關鍵就在于時間換空間。通過batch size (bs)=1+梯度累計以及gradient checkpointing的方式能夠大大降低顯存開銷。這也是qlora訓練時的一大核心(其實光靠量化訓練很難做到顯存的極致壓縮)。我們的實驗結果大概是這樣:LaVIN-7B在bs=4改成batch size (bs)=1+梯度累計之后顯存降低到了25G左右。經過gradient checkpointing,顯存降低到9~10G左右。到這里,顯存從原來的上百G壓縮到了10G左右,已經非常可觀了。但是這一步的代價是訓練速度明顯變慢了,但其實和qlora原文中的速度下降比例差不多。相比于原來完全訓不了的情況來說,這些額外的時間開銷顯得非常微不足道。
Paged Optimizer
Paged Optimizer的作用是在快爆顯存的時候,會將optimizer中的一部分權重遷移到cpu上,從而保證訓練的正常進行。實際使用中,沒有感覺到太大的區別。我猜測是在顯存開銷和顯卡顯存非常接近的時候,這個設置能救下急。正常情況下,好像沒有什么太大的幫助。感興趣的可以試一下8 bit的optimizer,或許幫助更明顯。
性能比較
ScienceQA(多模態科學問答數據集):在ScienceQA上,我們單卡的情況下完成了4bit訓練并和16bit的方法進行了比較,結果如下:
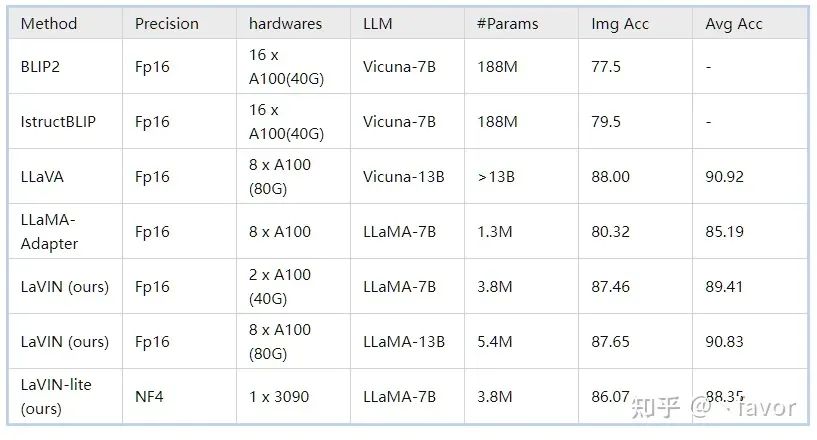
可以看到LaVIN-lite性能仍然遠超參數高效的方法LLaMA-Adapter,但是相比較16bit訓練的LaVIN,性能出現了略微的下降。我們猜測原因是4bit訓練的時候可能需要插入更多的adapter來進行適配,也歡迎大家基于這個基線來進行進一步探索和比較。
最后,在解決訓練的問題之后,我們會持續推進模型能力的提升以及應用場景的創新。另外,多模態對話模型我們也在持續迭代中,未來也會以技術報告的形式來進行分享。
審核編輯:劉清
-
適配器
+關注
關注
9文章
2058瀏覽量
69822
原文標題:LaVIN-lite:單張消費級顯卡微調多模態大模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀

更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

中科大&字節提出UniDoc:統一的面向文字場景的多模態大模型
多模態大模型企業,智子引擎全國總部落戶南京江北
北大&華為提出:多模態基礎大模型的高效微調

大模型+多模態的3種實現方法

從Google多模態大模型看后續大模型應該具備哪些能力
機器人基于開源的多模態語言視覺大模型






 工商網監
工商網監

評論