 DragGAN開源效果如何
DragGAN開源效果如何
動動鼠標,讓圖片變「活」,成為你想要的模樣。
在 AIGC 的神奇世界里,我們可以在圖像上通過「拖曳」的方式,改變并合成自己想要的圖像。比如讓一頭獅子轉頭并張嘴:
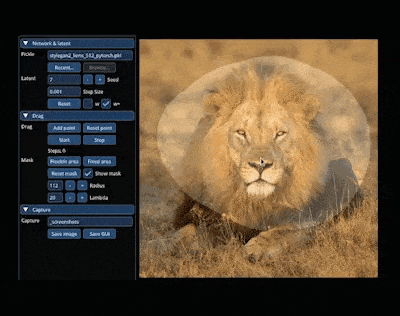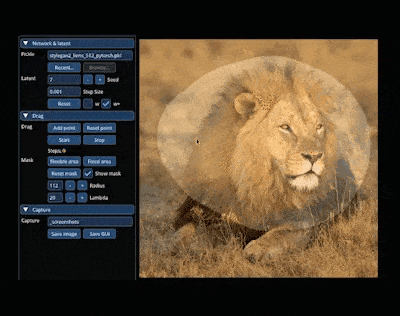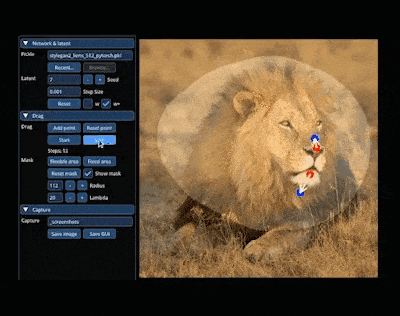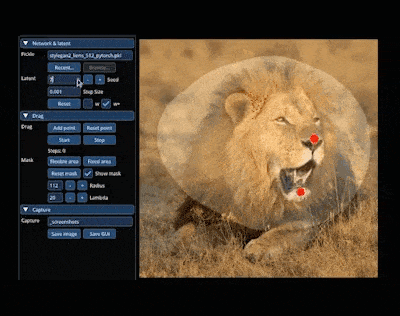
實現這一效果的研究出自華人一作領銜的「Drag Your GAN」論文,于上個月放出并已被 SIGGRAPH 2023 會議接收。 一個多月過去了,該研究團隊于近日放出了官方代碼。短短三天時間,Star 量便已突破了 23k,足可見其火爆程度。  GitHub 地址:https://github.com/XingangPan/DragGAN 無獨有偶,今日又一項類似的研究 —— DragDiffusion 進入了人們的視線。此前的 DragGAN 實現了基于點的交互式圖像編輯,并取得像素級精度的編輯效果。但是也有不足,DragGAN 是基于生成對抗網絡(GAN),通用性會受到預訓練 GAN 模型容量的限制。 在新研究中,新加坡國立大學和字節跳動的幾位研究者將這類編輯框架擴展到了擴散模型,提出了 DragDiffusion。他們利用大規模預訓練擴散模型,極大提升了基于點的交互式編輯在現實世界場景中的適用性。 雖然現在大多數基于擴散的圖像編輯方法都適用于文本嵌入,但 DragDiffusion 優化了擴散潛在表示,實現了精確的空間控制。
GitHub 地址:https://github.com/XingangPan/DragGAN 無獨有偶,今日又一項類似的研究 —— DragDiffusion 進入了人們的視線。此前的 DragGAN 實現了基于點的交互式圖像編輯,并取得像素級精度的編輯效果。但是也有不足,DragGAN 是基于生成對抗網絡(GAN),通用性會受到預訓練 GAN 模型容量的限制。 在新研究中,新加坡國立大學和字節跳動的幾位研究者將這類編輯框架擴展到了擴散模型,提出了 DragDiffusion。他們利用大規模預訓練擴散模型,極大提升了基于點的交互式編輯在現實世界場景中的適用性。 雖然現在大多數基于擴散的圖像編輯方法都適用于文本嵌入,但 DragDiffusion 優化了擴散潛在表示,實現了精確的空間控制。 
論文地址:https://arxiv.org/abs/2306.14435
項目地址:https://yujun-shi.github.io/projects/dragdiffusion.html
研究者表示,擴散模型以迭代方式生成圖像,而「一步」優化擴散潛在表示足以生成連貫結果,使 DragDiffusion 高效完成了高質量編輯。 他們在各種具有挑戰性的場景(如多對象、不同對象類別)下進行了廣泛實驗,驗證了 DragDiffusion 的可塑性和通用性。相關代碼也將很快放出、 下面我們看看 DragDiffusion 效果如何。 首先,我們想讓下圖中的小貓咪的頭再抬高一點,用戶只需將紅色的點拖拽至藍色的點就可以了:
接下來,我們想讓山峰變得再高一點,也沒有問題,拖拽紅色關鍵點就可以了:

還想讓雕塑的頭像轉個頭,拖拽一下就能辦到:

讓岸邊的花,開的范圍更廣一點:
方法介紹 本文提出的 DRAGDIFFUSION 旨在優化特定的擴散潛變量,以實現可交互的、基于點的圖像編輯。 為了實現這一目標,該研究首先在擴散模型的基礎上微調 LoRA,以重建用戶輸入圖像。這樣做可以保證輸入、輸出圖像的風格保持一致。 接下來,研究者對輸入圖像采用 DDIM inversion(這是一種探索擴散模型的逆變換和潛在空間操作的方法),以獲得特定步驟的擴散潛變量。 在編輯過程中,研究者反復運用動作監督和點跟蹤,以優化先前獲得的第 t 步擴散潛變量,從而將處理點的內容「拖拽(drag)」到目標位置。編輯過程還應用了正則化項,以確保圖像的未掩碼區域保持不變。 最后,通過 DDIM 對優化后的第 t 步潛變量進行去噪,得到編輯后的結果。總體概覽圖如下所示: 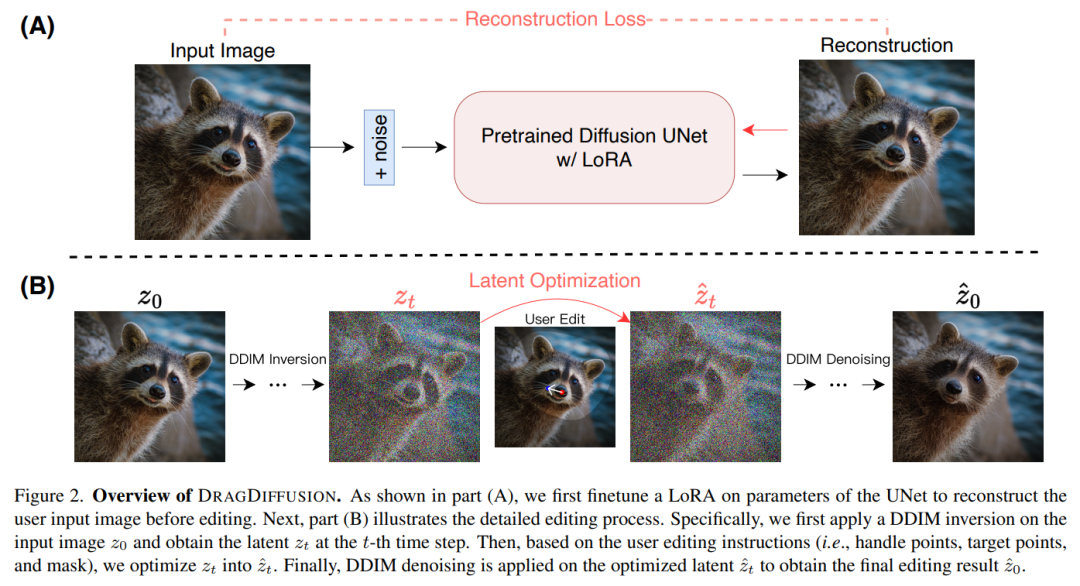 實驗結果 給定一張輸入圖像,DRAGDIFFUSION 將關鍵點(紅色)的內容「拖拽」到相應的目標點(藍色)。例如在圖(1)中,將小狗的頭轉過來,圖(7)將老虎的嘴巴合上等等。 ? 下面是更多示例演示。如圖(4)將山峰變高,圖(7)將筆頭變大等等。
實驗結果 給定一張輸入圖像,DRAGDIFFUSION 將關鍵點(紅色)的內容「拖拽」到相應的目標點(藍色)。例如在圖(1)中,將小狗的頭轉過來,圖(7)將老虎的嘴巴合上等等。 ? 下面是更多示例演示。如圖(4)將山峰變高,圖(7)將筆頭變大等等。
-
開源
+關注
關注
3文章
3309瀏覽量
42473 -
模型
+關注
關注
1文章
3226瀏覽量
48809
原文標題:DragGAN重磅開源!擴散模型版的DragDiffusion也來了!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
adxl加速度mems測量低頻振動的效果如何?
VL53L1水下使用效果如何?
空調制熱效果如何?空調制熱多少度最合適?
電銷機器人的使用效果如何?
i9-9900K開蓋 使用了釬焊散熱后實際效果如何
EE-26:AD184x Sigma Delta轉換器:它們使用直流輸入的效果如何?

Go項目中引入中間件的目的和效果如何
Catalinbread Formula No 5效果器開源





 工商網監
工商網監
評論