") 我們能否擴(kuò)展現(xiàn)有的預(yù)訓(xùn)練 LLM 的上下文窗口
我們能否擴(kuò)展現(xiàn)有的預(yù)訓(xùn)練 LLM 的上下文窗口
在大家不斷升級(jí)迭代自家大模型的時(shí)候,LLM(大語言模型)對(duì)上下文窗口的處理能力,也成為一個(gè)重要評(píng)估指標(biāo)。 比如 OpenAI 的 gpt-3.5-turbo 提供 16k token 的上下文窗口選項(xiàng),AnthropicAI 的更是將 Claude 處理 token 能力提升到 100k。大模型處理上下文窗口是個(gè)什么概念,就拿 GPT-4 支持 32k token 來說,這相當(dāng)于 50 頁的文字,意味著在對(duì)話或生成文本時(shí),GPT-4 最多可以記住 50 頁左右內(nèi)容。 一般來講,大語言模型處理上下文窗口大小的能力是預(yù)定好的。例如,Meta AI 發(fā)布的 LLaMA 模型,其輸入 token 大小必須少于 2048。 然而,在進(jìn)行長(zhǎng)對(duì)話、總結(jié)長(zhǎng)文檔或執(zhí)行長(zhǎng)期計(jì)劃等應(yīng)用程序中,經(jīng)常會(huì)超過預(yù)先設(shè)置的上下文窗口限制,因而,能夠處理更長(zhǎng)上下文窗口的 LLM 更受歡迎。 但這又面臨一個(gè)新的問題,從頭開始訓(xùn)練具有較長(zhǎng)上下文窗口的 LLM 需要很大的投入。這自然引出一個(gè)疑問:我們能否擴(kuò)展現(xiàn)有的預(yù)訓(xùn)練 LLM 的上下文窗口? 一種直接的方法是對(duì)現(xiàn)有的預(yù)訓(xùn)練 Transformer 進(jìn)行微調(diào),以獲得更長(zhǎng)的上下文窗口。然而,實(shí)證結(jié)果表明,使用這種方式訓(xùn)練的模型對(duì)長(zhǎng)上下文窗口的適應(yīng)速度非常慢。經(jīng)過 10000 個(gè)批次的訓(xùn)練后,有效上下文窗口的增加仍然非常小,僅從 2048 增加到 2560(實(shí)驗(yàn)部分的表 4 可以看出)。這表明這種方法在擴(kuò)展到更長(zhǎng)的上下文窗口上效率低下。 本文中,來自 Meta 的研究者引入了位置插值(Position Interpolation,PI)來對(duì)某些現(xiàn)有的預(yù)訓(xùn)練 LLM(包括 LLaMA)的上下文窗口進(jìn)行擴(kuò)展。結(jié)果表明,LLaMA 上下文窗口從 2k 擴(kuò)展到 32k,只需要小于 1000 步的微調(diào)。  ? 論文地址:https://arxiv.org/pdf/2306.15595.pdf ? 該研究的關(guān)鍵思想不是進(jìn)行外推(extrapolation),而是直接縮小位置索引,使得最大位置索引與預(yù)訓(xùn)練階段的上下文窗口限制相匹配。換句話說,為了容納更多的輸入 token,該研究在相鄰的整數(shù)位置上插值位置編碼,利用了位置編碼可以應(yīng)用于非整數(shù)位置的事實(shí),與在訓(xùn)練過的位置之外進(jìn)行外推相比,后者可能導(dǎo)致災(zāi)難性的數(shù)值。 ?
? 論文地址:https://arxiv.org/pdf/2306.15595.pdf ? 該研究的關(guān)鍵思想不是進(jìn)行外推(extrapolation),而是直接縮小位置索引,使得最大位置索引與預(yù)訓(xùn)練階段的上下文窗口限制相匹配。換句話說,為了容納更多的輸入 token,該研究在相鄰的整數(shù)位置上插值位置編碼,利用了位置編碼可以應(yīng)用于非整數(shù)位置的事實(shí),與在訓(xùn)練過的位置之外進(jìn)行外推相比,后者可能導(dǎo)致災(zāi)難性的數(shù)值。 ? 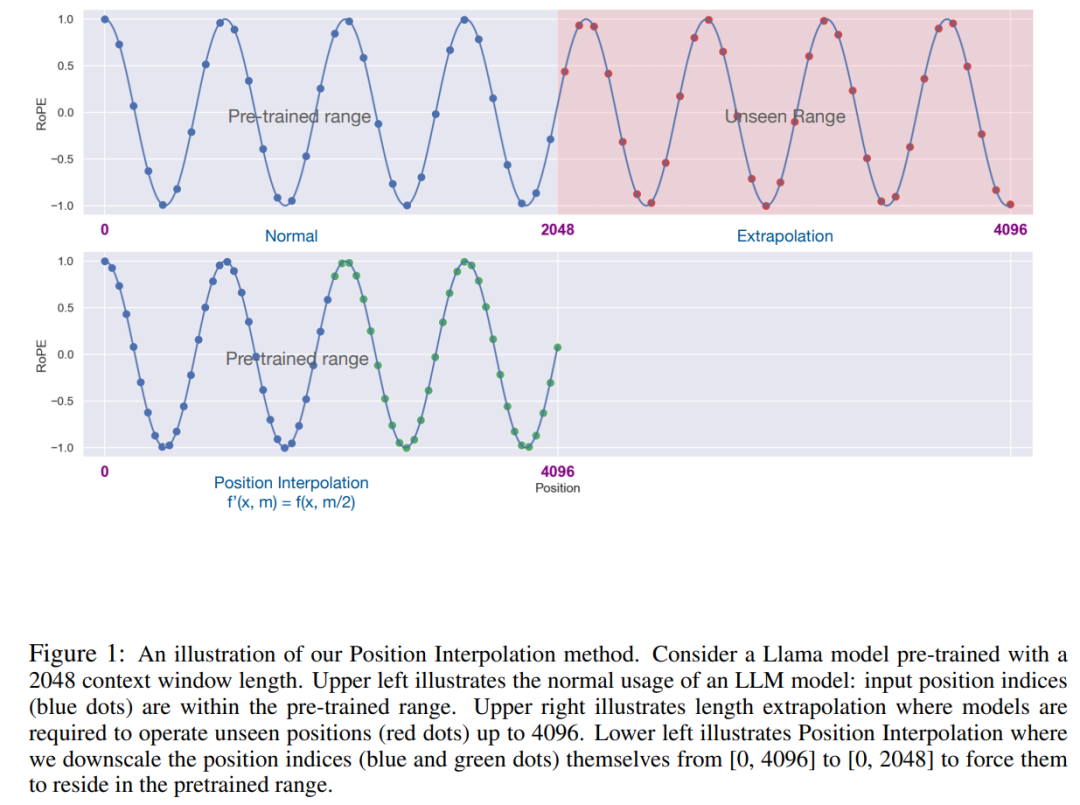 ? PI 方法將基于 RoPE(旋轉(zhuǎn)位置編碼)的預(yù)訓(xùn)練 LLM(如 LLaMA)的上下文窗口大小擴(kuò)展到最多 32768,只需進(jìn)行最小的微調(diào)(在 1000 個(gè)步驟內(nèi)),這一研究在需要長(zhǎng)上下文的各種任務(wù)上性能較好,包括密碼檢索、語言建模以及從 LLaMA 7B 到 65B 的長(zhǎng)文檔摘要。與此同時(shí),通過 PI 擴(kuò)展的模型在其原始上下文窗口內(nèi)相對(duì)保持了較好的質(zhì)量。 ? 方法 在我們比較熟悉的 LLaMA、ChatGLM-6B、PaLM 等大語言模型中,都有 RoPE 身影,該方法由追一科技蘇劍林等人提出,RoPE 通過絕對(duì)編碼的方式實(shí)現(xiàn)了相對(duì)位置編碼。 雖然 RoPE 中的注意力得分只取決于相對(duì)位置,但它的外推性能并不好。特別是,當(dāng)直接擴(kuò)展到更大的上下文窗口時(shí),困惑度可能會(huì)飆升到非常高的數(shù)字 (即 > 10^3)。 本文采用位置插值的方法,其與外推方法的比較如下。由于基函數(shù) ?_j 的平滑性,插值更加穩(wěn)定,不會(huì)導(dǎo)致野值。
? PI 方法將基于 RoPE(旋轉(zhuǎn)位置編碼)的預(yù)訓(xùn)練 LLM(如 LLaMA)的上下文窗口大小擴(kuò)展到最多 32768,只需進(jìn)行最小的微調(diào)(在 1000 個(gè)步驟內(nèi)),這一研究在需要長(zhǎng)上下文的各種任務(wù)上性能較好,包括密碼檢索、語言建模以及從 LLaMA 7B 到 65B 的長(zhǎng)文檔摘要。與此同時(shí),通過 PI 擴(kuò)展的模型在其原始上下文窗口內(nèi)相對(duì)保持了較好的質(zhì)量。 ? 方法 在我們比較熟悉的 LLaMA、ChatGLM-6B、PaLM 等大語言模型中,都有 RoPE 身影,該方法由追一科技蘇劍林等人提出,RoPE 通過絕對(duì)編碼的方式實(shí)現(xiàn)了相對(duì)位置編碼。 雖然 RoPE 中的注意力得分只取決于相對(duì)位置,但它的外推性能并不好。特別是,當(dāng)直接擴(kuò)展到更大的上下文窗口時(shí),困惑度可能會(huì)飆升到非常高的數(shù)字 (即 > 10^3)。 本文采用位置插值的方法,其與外推方法的比較如下。由于基函數(shù) ?_j 的平滑性,插值更加穩(wěn)定,不會(huì)導(dǎo)致野值。 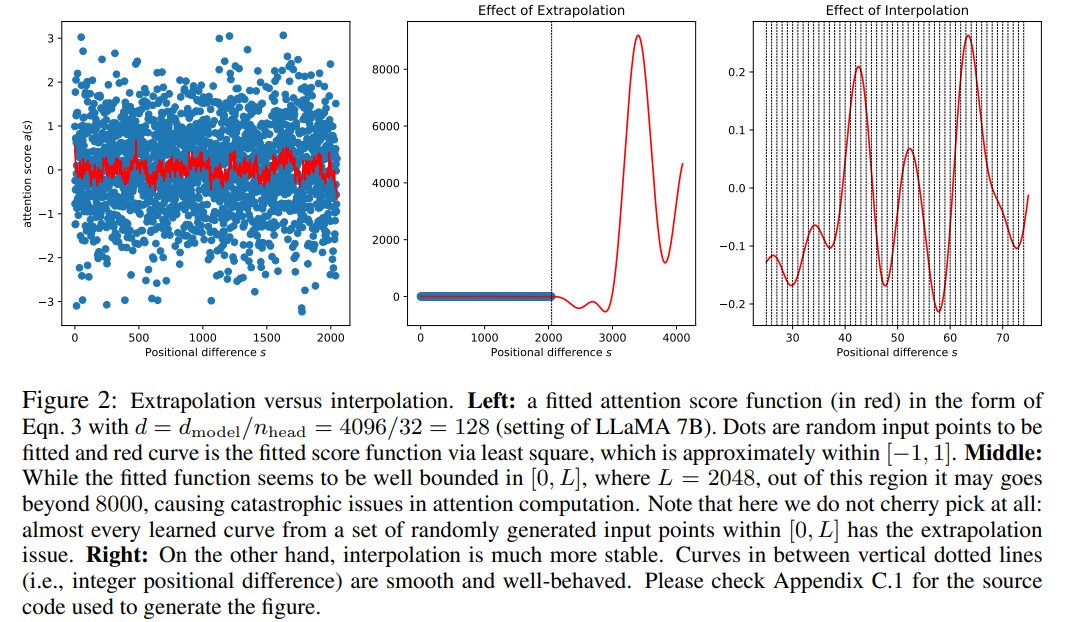 ? ?該研究將 RoPE f 替換為 f ′,得到如下公式 ?
? ?該研究將 RoPE f 替換為 f ′,得到如下公式 ?  ? 該研究將在位置編碼上的轉(zhuǎn)換稱為位置插值。這一步將位置索引從 [0, L′ ) 縮減到 [0, L) ,以匹配計(jì)算 RoPE 前的原始索引范圍。因此,作為 RoPE 的輸入,任意兩個(gè) token 之間的最大相對(duì)距離已從 L ′ 縮減到 L。通過在擴(kuò)展前后對(duì)位置索引和相對(duì)距離的范圍進(jìn)行對(duì)齊,減輕了由于上下文窗口擴(kuò)展而對(duì)注意力分?jǐn)?shù)計(jì)算產(chǎn)生的影響,這使得模型更容易適應(yīng)。 ? 值得注意的是,重新縮放位置索引方法不會(huì)引入額外的權(quán)重,也不會(huì)以任何方式修改模型架構(gòu)。 ? 實(shí)驗(yàn) 該研究展示了位置插值可以有效地將上下文窗口擴(kuò)展到原始大小的 32 倍,并且這種擴(kuò)展只需進(jìn)行幾百個(gè)訓(xùn)練步驟即可完成。 表 1 和表 2 報(bào)告了 PI 模型和基線模型在 PG-19 、 Arxiv Math Proof-pile 數(shù)據(jù)集上的困惑度。結(jié)果表明使用 PI 方法擴(kuò)展的模型在較長(zhǎng)的上下文窗口大小下顯著改善了困惑度。
? 該研究將在位置編碼上的轉(zhuǎn)換稱為位置插值。這一步將位置索引從 [0, L′ ) 縮減到 [0, L) ,以匹配計(jì)算 RoPE 前的原始索引范圍。因此,作為 RoPE 的輸入,任意兩個(gè) token 之間的最大相對(duì)距離已從 L ′ 縮減到 L。通過在擴(kuò)展前后對(duì)位置索引和相對(duì)距離的范圍進(jìn)行對(duì)齊,減輕了由于上下文窗口擴(kuò)展而對(duì)注意力分?jǐn)?shù)計(jì)算產(chǎn)生的影響,這使得模型更容易適應(yīng)。 ? 值得注意的是,重新縮放位置索引方法不會(huì)引入額外的權(quán)重,也不會(huì)以任何方式修改模型架構(gòu)。 ? 實(shí)驗(yàn) 該研究展示了位置插值可以有效地將上下文窗口擴(kuò)展到原始大小的 32 倍,并且這種擴(kuò)展只需進(jìn)行幾百個(gè)訓(xùn)練步驟即可完成。 表 1 和表 2 報(bào)告了 PI 模型和基線模型在 PG-19 、 Arxiv Math Proof-pile 數(shù)據(jù)集上的困惑度。結(jié)果表明使用 PI 方法擴(kuò)展的模型在較長(zhǎng)的上下文窗口大小下顯著改善了困惑度。 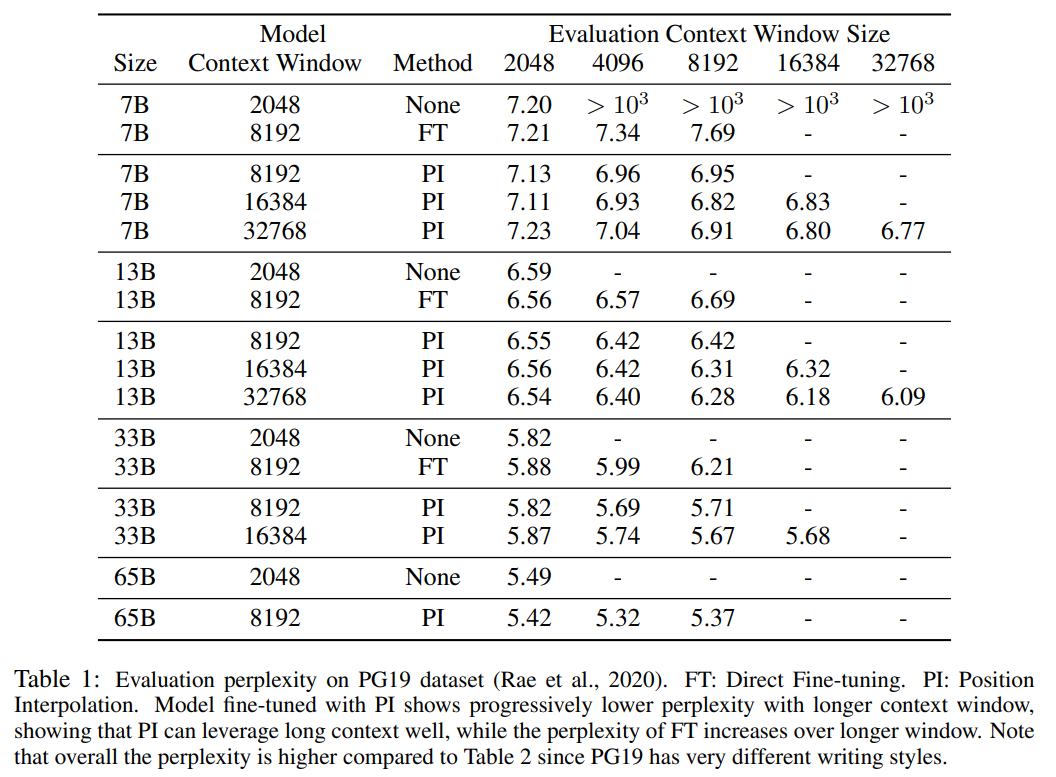 ?
? 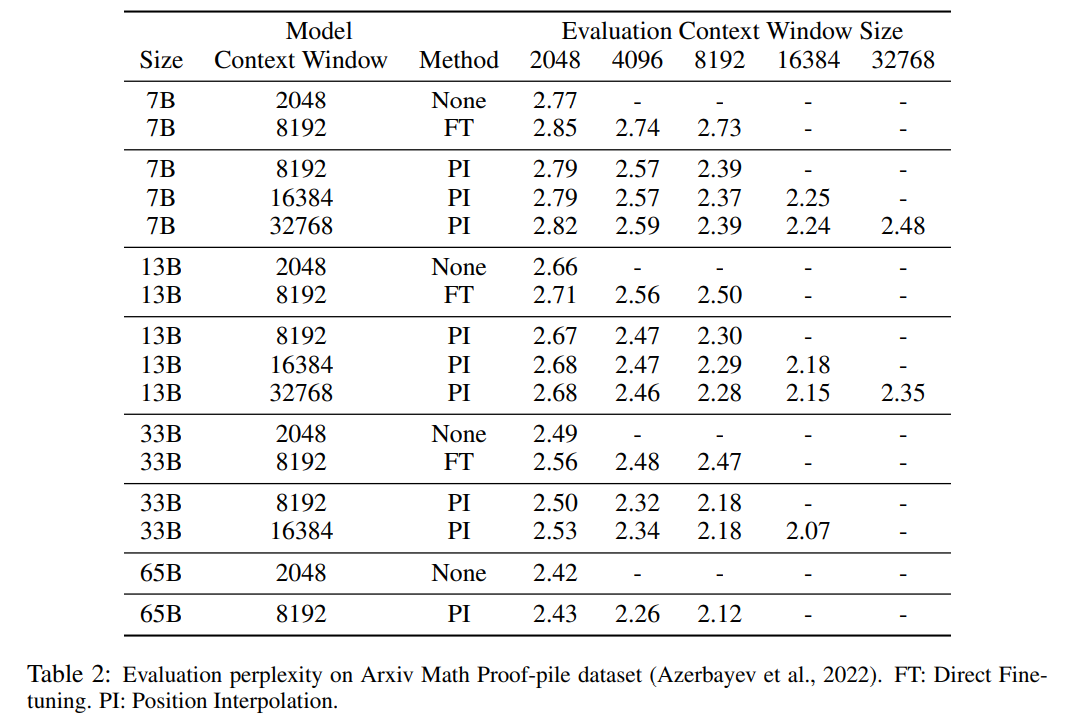 ? ? 表 3 報(bào)告了在 PG19 數(shù)據(jù)集上使用 PI 方法,將 LLaMA 7B 模型擴(kuò)展到 8192 和 16384 上下文窗口大小時(shí)的困惑度與微調(diào)步數(shù)之間的關(guān)系。 ? 由結(jié)果可得,在沒有微調(diào)的情況下(步數(shù)為 0),模型可以展現(xiàn)出一定的語言建模能力,如將上下文窗口擴(kuò)展到 8192 時(shí)的困惑度小于 20(相比之下,直接外推方法的困惑度大于 10^3)。在 200 個(gè)步驟時(shí),模型的困惑度超過了 2048 上下文窗口大小下原始模型的困惑度,表明模型能夠有效利用比預(yù)訓(xùn)練設(shè)置更長(zhǎng)的序列進(jìn)行語言建模。在 1000 個(gè)步驟時(shí)可以看到模型穩(wěn)步改進(jìn),并取得了更好的困惑度。 ?
? ? 表 3 報(bào)告了在 PG19 數(shù)據(jù)集上使用 PI 方法,將 LLaMA 7B 模型擴(kuò)展到 8192 和 16384 上下文窗口大小時(shí)的困惑度與微調(diào)步數(shù)之間的關(guān)系。 ? 由結(jié)果可得,在沒有微調(diào)的情況下(步數(shù)為 0),模型可以展現(xiàn)出一定的語言建模能力,如將上下文窗口擴(kuò)展到 8192 時(shí)的困惑度小于 20(相比之下,直接外推方法的困惑度大于 10^3)。在 200 個(gè)步驟時(shí),模型的困惑度超過了 2048 上下文窗口大小下原始模型的困惑度,表明模型能夠有效利用比預(yù)訓(xùn)練設(shè)置更長(zhǎng)的序列進(jìn)行語言建模。在 1000 個(gè)步驟時(shí)可以看到模型穩(wěn)步改進(jìn),并取得了更好的困惑度。 ? 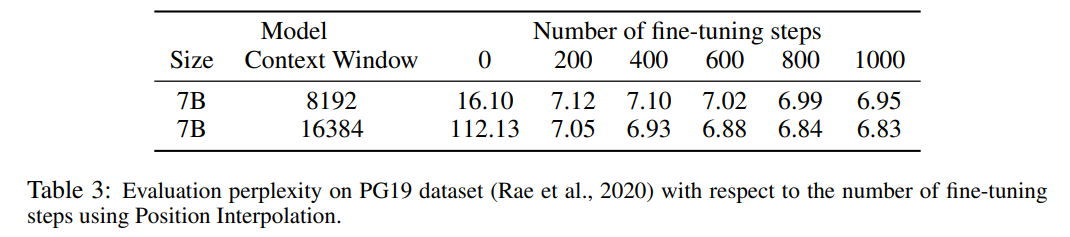 ? ? 下表表明,通過 PI 擴(kuò)展的模型在有效上下文窗口大小方面都成功地實(shí)現(xiàn)了擴(kuò)展目標(biāo),即僅通過微調(diào) 200 個(gè)步驟后,有效上下文窗口大小達(dá)到最大值,在 7B 和 33B 模型大小以及最高 32768 上下文窗口的情況下保持一致。相比之下,僅通過直接微調(diào)擴(kuò)展的 LLaMA 模型的有效上下文窗口大小僅從 2048 增加到 2560,即使經(jīng)過 10000 多個(gè)步驟的微調(diào),也沒有明顯加速窗口大小增加的跡象。 ?
? ? 下表表明,通過 PI 擴(kuò)展的模型在有效上下文窗口大小方面都成功地實(shí)現(xiàn)了擴(kuò)展目標(biāo),即僅通過微調(diào) 200 個(gè)步驟后,有效上下文窗口大小達(dá)到最大值,在 7B 和 33B 模型大小以及最高 32768 上下文窗口的情況下保持一致。相比之下,僅通過直接微調(diào)擴(kuò)展的 LLaMA 模型的有效上下文窗口大小僅從 2048 增加到 2560,即使經(jīng)過 10000 多個(gè)步驟的微調(diào),也沒有明顯加速窗口大小增加的跡象。 ? 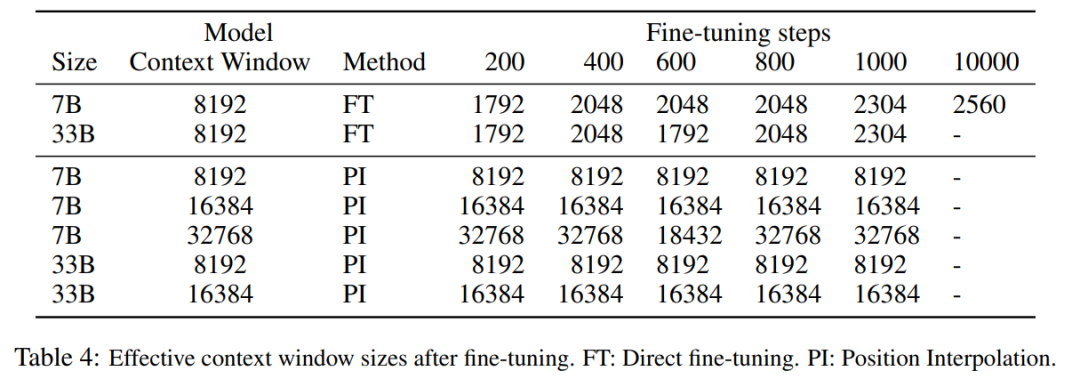 ? ? 表 5 顯示擴(kuò)展到 8192 的模型在原始基準(zhǔn)任務(wù)上產(chǎn)生了可比較的結(jié)果,而該基準(zhǔn)任務(wù)是針對(duì)更小的上下文窗口設(shè)計(jì)的,對(duì)于 7B 和 33B 模型大小,在基準(zhǔn)任務(wù)中的退化最多達(dá)到 2%。 ?
? ? 表 5 顯示擴(kuò)展到 8192 的模型在原始基準(zhǔn)任務(wù)上產(chǎn)生了可比較的結(jié)果,而該基準(zhǔn)任務(wù)是針對(duì)更小的上下文窗口設(shè)計(jì)的,對(duì)于 7B 和 33B 模型大小,在基準(zhǔn)任務(wù)中的退化最多達(dá)到 2%。 ? 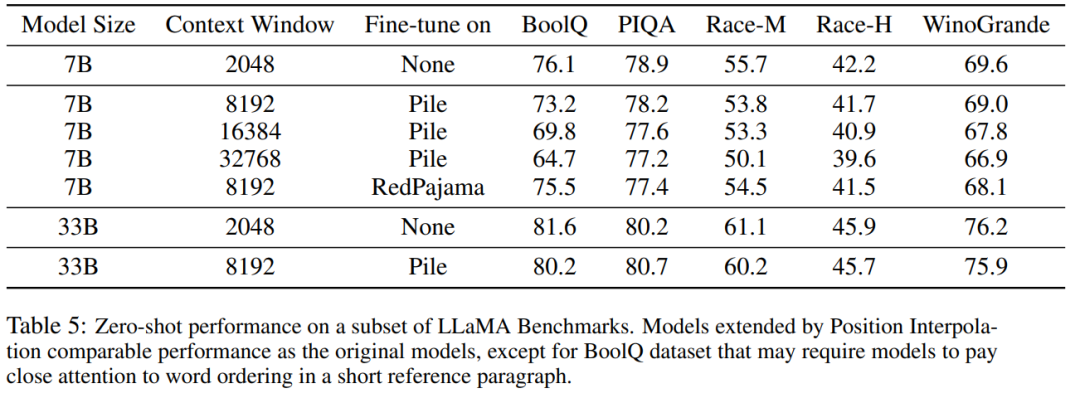 ? 表 6 表明,具有 16384 上下文窗口的 PI 模型,可以有效地處理長(zhǎng)文本摘要任務(wù)。 ?
? 表 6 表明,具有 16384 上下文窗口的 PI 模型,可以有效地處理長(zhǎng)文本摘要任務(wù)。 ? 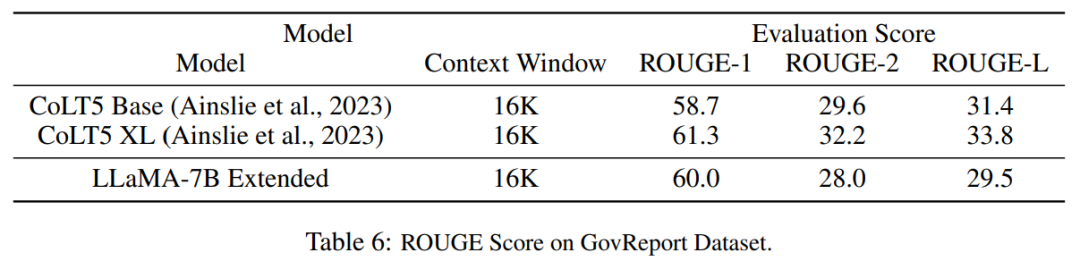
-
編碼
+關(guān)注
關(guān)注
6文章
940瀏覽量
54814 -
窗口
+關(guān)注
關(guān)注
0文章
66瀏覽量
10856 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809 -
LLM
+關(guān)注
關(guān)注
0文章
286瀏覽量
327
原文標(biāo)題:不到1000步微調(diào),將LLaMA上下文擴(kuò)展到32K,田淵棟團(tuán)隊(duì)最新研究
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
關(guān)于進(jìn)程上下文、中斷上下文及原子上下文的一些概念理解
進(jìn)程上下文與中斷上下文的理解
基于多Agent的用戶上下文自適應(yīng)站點(diǎn)構(gòu)架
基于交互上下文的預(yù)測(cè)方法
終端業(yè)務(wù)上下文的定義方法及業(yè)務(wù)模型
基于Pocket PC的上下文菜單實(shí)現(xiàn)
基于Pocket PC的上下文菜單實(shí)現(xiàn)
基于上下文相似度的分解推薦算法
初學(xué)OpenGL:什么是繪制上下文
如何分析Linux CPU上下文切換問題
谷歌新作SPAE:GPT等大語言模型可以通過上下文學(xué)習(xí)解決視覺任務(wù)

Linux技術(shù):什么是cpu上下文切換






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論