 使用OpenVINO解鎖AI更輕松部署和加速的潛力
使用OpenVINO解鎖AI更輕松部署和加速的潛力
OpenVINO
2023.0
最新版本來襲
隨著 OpenVINO5周年紀念日的臨近,我們想花點時間對您在過去五年中對OpenVINO的持續使用表示最深切的感謝。到目前為止,這是一段不可思議的旅程,我們很自豪您能成為我們社區中的一員。社區的持續支持使我們的下載量超過了 100 萬次。
在我們紀念這一重要里程碑之際,我們激動地發布我們的最新版本OpenVINO2023.0,它具有一系列新的特性和功能,將使開發人員能夠更輕松地部署和加速人工智能。
2023.0 版本的重點是通過最大限度地減少離線轉換、擴大模型支持和推進硬件優化來改善開發者之旅。完整的發布說明可在此獲得:
亮點包括:
盡量減少 AI 開發者在采用和維護代碼時的代碼修改并更好的與各深度學習框架保持一致
全新的 TensorFlow 體驗:簡化從訓練到部署 TensorFlow 模型的工作流程
現在可用 Conda Forge!對于習慣使用 Conda的 C++ 開發人員來說,更容易安裝 OpenVINO運行時庫
更廣泛的處理器支持:當前 ARM 處理器支持包括 OpenVINOCPU 推理計算,動態輸入,完整的處理器性能和廣泛的示例代碼 Notebook 教程覆蓋
擴展 Python 支持:增加了對 Python 3.11 的支持,以獲得更多潛在的性能改進
在包括 NLP 在內的更多模型上輕松實現優化和部署,并通過新的硬件特性能力獲得更多的 AI 加速
更廣泛的模型支持:支持生成式 AI 模型、文本處理模型、Transformer 模型等
GPU 上支持動態輸入:當使用 GPU 時,不需要將模型輸入改為靜態輸入,這在編寫代碼時提供了更多的靈活性,特別是對于 NLP 模型
NNCF 是首選的量化工具:將訓練后量化(POT)集成到神經網絡壓縮框架(NNCF)中,有了它,通過模型壓縮,更容易獲得巨大的性能提升
通過自動設備發現,負載平衡和跨 CPU, GPU等的動態推理并行,可以直接看到性能的提升
CPU 插件中的線程調度:通過在第12代英特爾酷睿 處理器及以上版本的 CPU 的能效核、性能核或能效核 + 性能核上運行推理來優化性能或能效。
默認推理精度:默認為不同的格式,以在 CPU 和 GPU 上提供最佳性能。
模型緩存擴展:減少 GPU 和 CPU 的首次推理延遲
現在,讓我們深入研究一下上面介紹的一些新功能。
探索 OpenVINO 2023.0 中的新功能
全新的 TensorFlow 體驗
現在,TensorFlow 開發人員可以更容易地從模型訓練轉移到模型部署。無需離線將 TensorFlow 或 TensorFlow Lite 格式的模型文件轉換為 OpenVINO IR 格式-這會在運行時自動發生。現在,您可以開始試驗 Model Optimizer,以改善有限范圍模型的轉換時間,或者直接在 OpenVINO Runtime 或 OpenVINOModel Server 中加載標準 TensorFlow 或 TensorFlow Lite 模型
下圖顯示了一個簡單的示例:
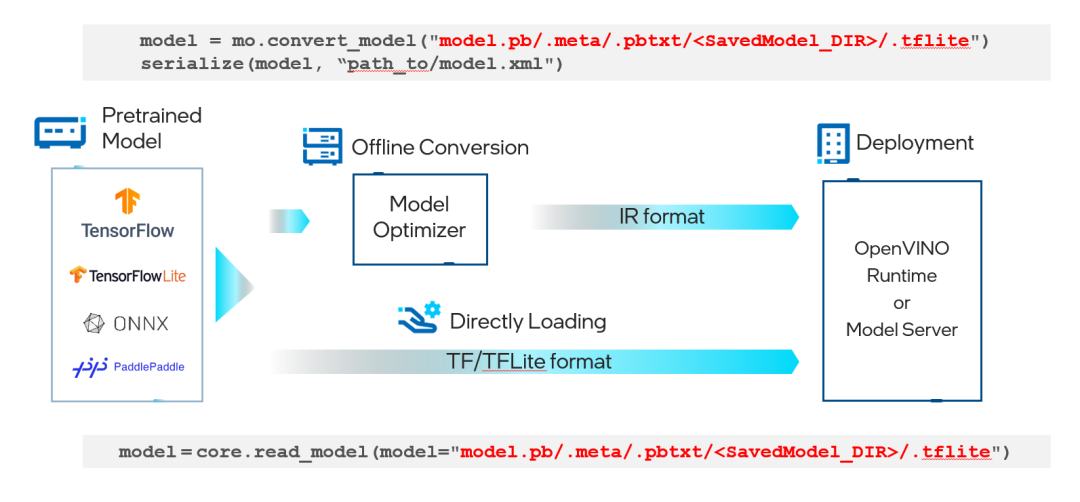
圖 1. 部署 TensorFlow/TensorFlow Lite 模型的通用工作流程
更廣泛的模型支持
AI 開發者可以找到更多的對生成式 AI 模型支持,例如:
CLIP
BLIP
Stable Diffusion 2.0
帶 ControlNet 的 Stable Diffusion
對文本處理模型的支持,對 Transformer 模型的支持,例如,S-BERT,GPT-J 等,對 Detectron2,Paddle Slim,Segment Anything Model(SAM),YOLOv8,RNN-T 等模型的支持。
圖 2. 由 stable-diffusion-2-inpainting 模型生成的無限變焦視頻效果
圖 3. 基于兩個條件生成的圖像,用 OpenPose 從輸入圖像提取關鍵點的 ControlNet 工作流程,然后作為額外條件與文本提示詞一起輸入到 Stable Diffusion 模型
圖 4. 用 Segment Anything Model (SAM) 模型分割給定圖片的一切
默認推理精度
最新的更新包括在各種設備上的推理性能的顯著提高,這些設備現在默認以高性能模式運行。這意味著對于 GPU 設備,使用 FP16 推理,而 CPU 設備使用 BF16 推理(如果可用)。
關于 BF16 推理請訪問:
以前,用戶必須自己將 IR 轉換為 FP16,才能使 GPU 在 FP16 模式下執行。現在,所有設備都可以自動選擇默認推理精度,并且此選擇與 IR 精度沒有關系。在極少數情況下,使用默認模式可能會影響推理準確性,此時用戶也可以通過接口手動調整推理精度。
此外,開發者可以單獨控制 IR 精度。默認情況下,我們建議將其設置為 FP16,以便為浮點模型減少 2 倍的模型大小。值得注意的是,IR 精度并不影響設備執行模型的方式,而是通過降低權重精度來壓縮模型。

圖 5. 自動轉換 IR 模型為默認推理精度
NNCF 作為首選的量化工具
NNCF 為 OpenVINO 中的神經網絡推理優化提供了一套先進的算法,并具有最小的精度損失。它支持對 PyTorch,TensorFlow,ONNX 和 OpenVINO 模型對象進行量化 。
在這之前,OpenVINO有單獨的工具用于訓練后優化(POT)和量化感知訓練。我們將這兩種方法合并到 NNCF 中,其中提供的壓縮算法如下所示,見圖 6。這有助于減少模型大小、內存占用和延遲,并提高計算效率。
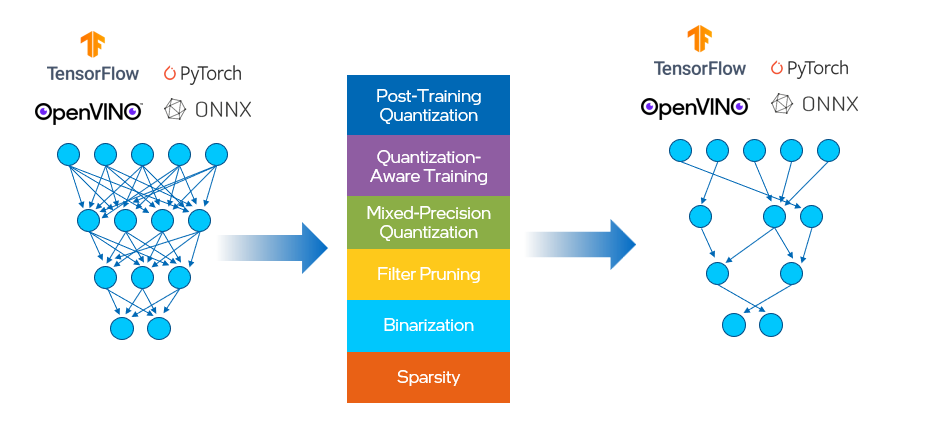
圖 6. NNCF 提供的壓縮算算法
訓練后量化算法從代表性數據集中獲取樣本,并將其輸入到網絡中,然后根據所得的權重和激活值對網絡進行校準。一旦校準完成,網絡中的值就被轉換為 8 位整型格式。NNCF 的基本訓練后量化流程是將 8 位量化應用于模型的最簡單方法:
設置環境并安裝依賴項
pip install nncf
準備校準數據集
import nncf calibration_loader = torch.utils.data.DataLoader(...) def transform_fn(data_item): images, _ = data_item return images calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
向右滑動查看完整代碼
運行以獲取量化模型
model = ... #OpenVINO/ONNX/PyTorch/TF object quantized_model = nncf.quantize(model, calibration_dataset)
向右滑動查看完整代碼
關于如何使用 NNCF 進行模型量化和壓縮的教程可以在這里找到,其中我們驗證了將訓練后量化應用于 YOLOv5 模型,精度幾乎沒有下降(圖7):
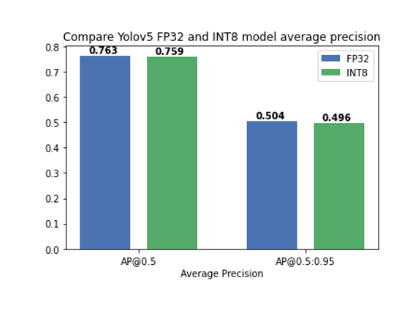
圖 7. 將訓練后量化應用于 YOLOv5 模型,精度幾乎沒有下降
CPU 插件中的線程調度
提升英特爾 平臺的多線程調度。
有了新的 ov::scheduling_core_type屬性,可以通過選擇在 {ov::ANY_CORE, ov::PCORE_ONLY, ov::ECORE_ONLY}上運行推理來配置性能優先或能效優先,用于第12代英特爾酷睿及以上的 CPU,HYBRID 平臺。
通過將ov::enable_hyper_threading屬性設置為 "True",物理核和邏輯核都可以在英特爾平臺的性能核上啟用,因此通過這種配置帶來性能提升。
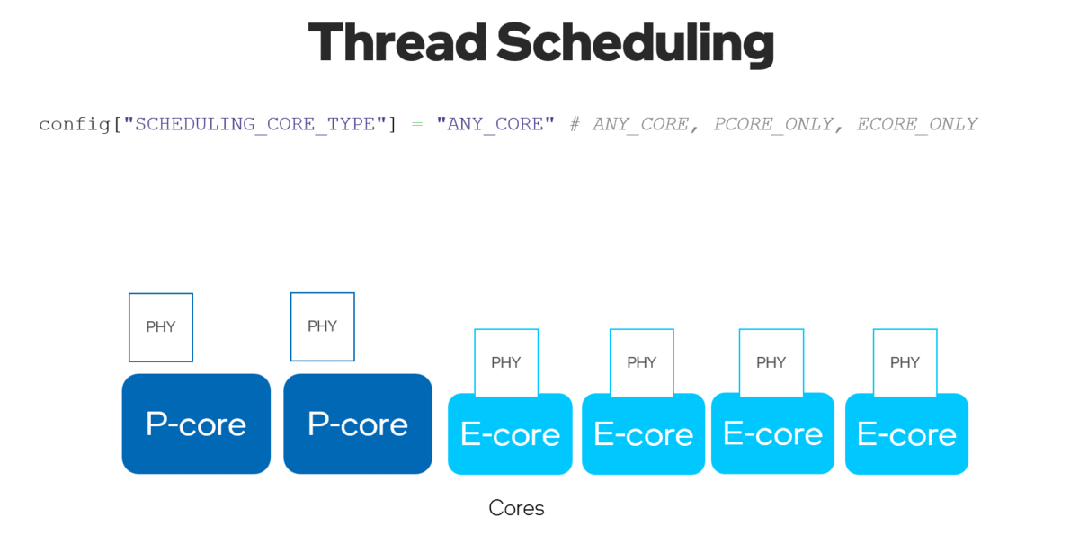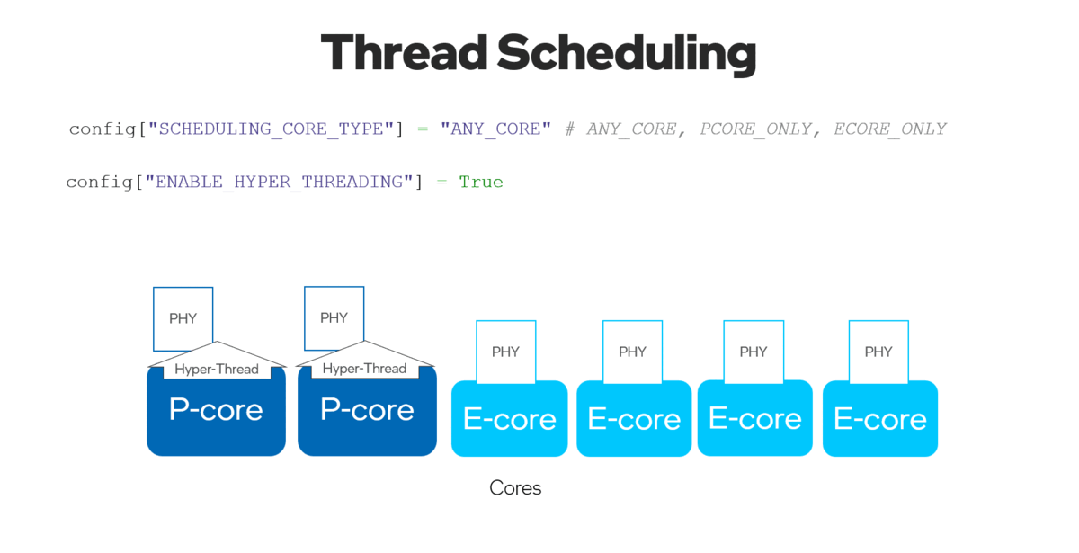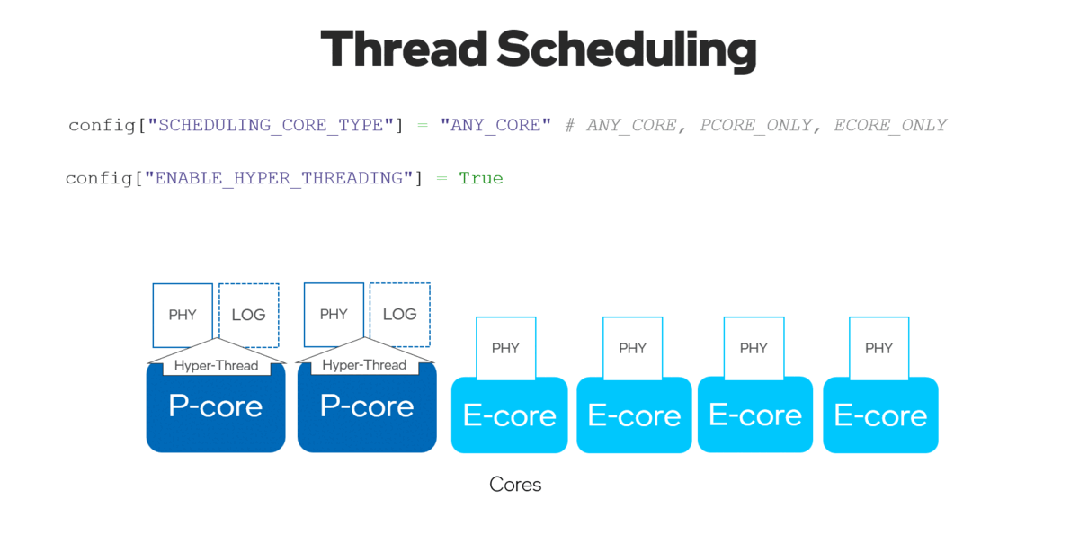
圖 8. 啟用 "SCHEDULING_CORE_TYPE "和 "ENABLE_HYPER_THREADING",在CPU插件中提升了多線程。
另一個新屬性是 ov::enable_cpu_pinning。默認情況下,ov::enable_cpu_pinning 被設置為 “True”, 這意味著用于運行多個深度學習模型的推理請求的多個線程將由 OpenVINO運行時(TBB)調度。在這種模式下,具有多個線程的一個深度學習模型的推理將被視為一個整體圖,其中每個線程將綁定到 CPU 處理器,而不會引起緩存丟失和額外的開銷。但是,在同時運行兩個神經網絡的推理的情況下,可能在相同的 CPU 處理器上調度不同深度學習模型推理請求的多個線程,從而導致對相同處理器資源上的競爭(如圖 9 所示)。
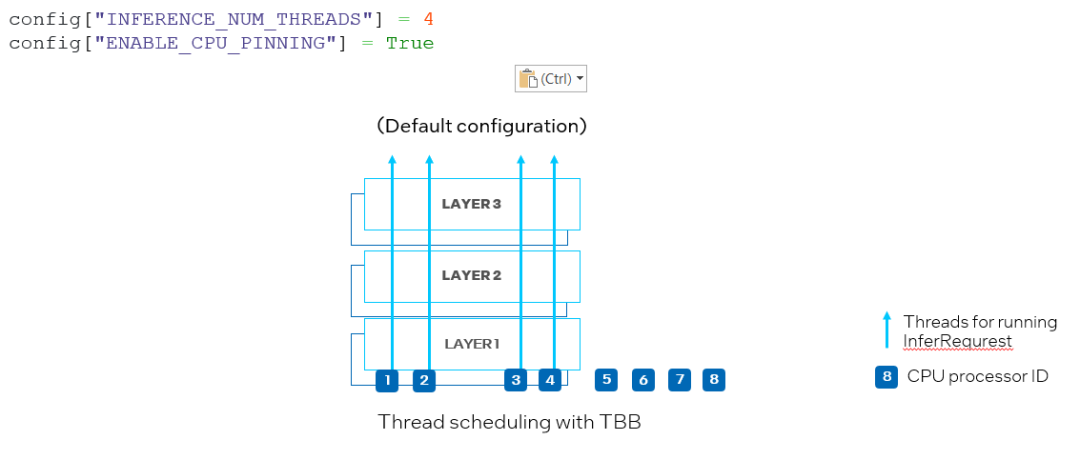
圖 9. 在 CPU 插件中設置 "ENABLE_CPU_PINNING "為 "True",為多線程啟用 TBB 調度
為了避免 CPU 處理器資源競爭,我們可以通過將 ov::enable_cpu_pinning 設置為 “False”來禁用處理器綁定屬性,并讓操作系統為神經網絡的每個線程調度處理器資源。在這種模式下,同一深度學習模型不同層上的推理可能會在不同的處理器之間切換,從而導致緩存丟失和額外的開銷(如圖 10 所示),此時開發者可以根據實際的測試結果,選擇最合適的方案進行部署。
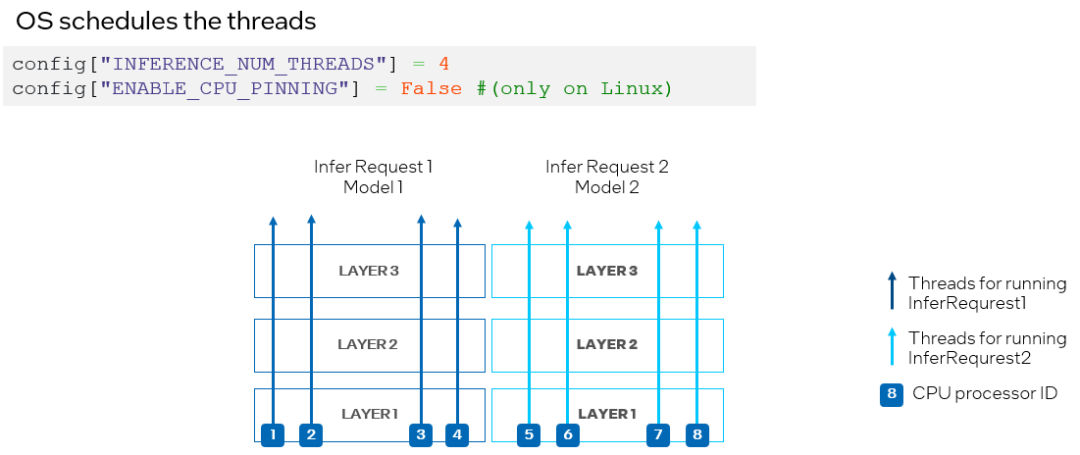
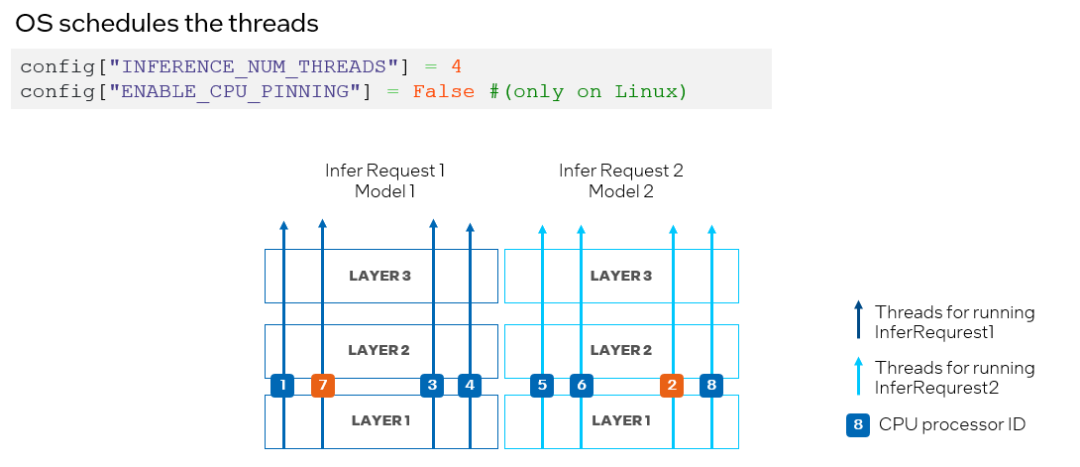
圖 10. 在 CPU 插件中設置 "ENABLE_CPU_PINNING "為 "False",由操作系統調度多線程
升級到 OpenVINO 2023.0
OpenVINO從頭到尾都能讓您的 AI 應用發揮最大的作用。有了您的持續支持,我們可以為各地的開發人員提供有價值的升級。憑借其智能和全面的功能,OpenVINO就像在您身邊有自己的性能工程師。
您可以使用以下命令升級到 OpenVINO2023.0:
但是請確保檢查所有的依賴項,因為升級可能會更新 OpenVINO之外的其他包。如果您希望安裝 C/ C++ API,拉取預構建的 Docker 鏡像或從其他存儲庫下載,請訪問下載頁面以找到適合您的需求的包。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19293瀏覽量
229941 -
英特爾
+關注
關注
61文章
9974瀏覽量
171818 -
AI
+關注
關注
87文章
30946瀏覽量
269196 -
模型
+關注
關注
1文章
3248瀏覽量
48860 -
python
+關注
關注
56文章
4797瀏覽量
84721
原文標題:使用OpenVINO?解鎖 AI 更輕松部署和加速的潛力
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用OpenVINO C++ API部署FastSAM模型
為什么無法通過Heroku部署OpenVINO?工具套件?
OpenVINO加速多領域AI產業創新發展
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
OpenVINO賦能BLIP實現視覺語言AI邊緣部署
OpenVINO? 賦能 BLIP 實現視覺語言 AI 邊緣部署

基于OpenVINO Python API部署RT-DETR模型
簡單三步使用OpenVINO?搞定ChatGLM3的本地部署

簡單兩步使用OpenVINO?搞定Qwen2的量化與部署任務

解鎖LLM新高度—OpenVINO? 2024.1賦能生成式AI高效運行
使用OpenVINO Model Server在哪吒開發板上部署模型





 工商網監
工商網監
評論