 如何使用NVIDIA DALI實現和使用GPU加速自動增強來訓練
如何使用NVIDIA DALI實現和使用GPU加速自動增強來訓練
深度學習模型需要數百 GB 的數據才能在看不見的樣本上很好地泛化。數據擴充有助于增加數據集中示例的可變性。
傳統的數據擴充方法可以追溯到統計學習,當時擴充的選擇依賴于建立模型訓練的工程師的領域知識、技能和直覺。
自動增強出現了減少對手動數據預處理的依賴。它結合了應用自動調整和根據概率分布隨機選擇增強的思想。
事實證明,使用 AutoAugment 和 RandAugment 等自動數據增強方法可以通過使模型在訓練中看到的樣本多樣化來提高模型的準確性。自動擴充使數據預處理更加復雜,因為一批中的每個樣本都可以用不同的隨機擴充進行處理。
在這篇文章中,我們介紹了如何使用 NVIDIA DALI 實現和使用 GPU 加速自動增強來訓練,然后使用條件執行。
自動數據擴充方法
自動增強是基于標準的圖像變換,如旋轉、剪切、模糊或亮度調整。大多數操作都接受一個稱為幅值的控制參數。幅度越大,操作對圖像的影響就越大。
傳統上,擴充策略是由工程師手工編寫的固定操作序列。自動增強策略與傳統策略的區別在于,增強和參數的選擇不是固定的,而是概率的。
AutoAugment采用強化學習從數據中學習最佳概率增強策略,將目標模型的泛化視為獎勵信號。使用 AutoAugment ,我們發現了圖像數據集的新策略,例如ImageNet,CIFAR-10和SVHN,超過了最先進的精度。
AutoAugment 策略是一組增強對。每個增強都用應用或跳過操作的幅度和概率進行參數化。運行策略時,隨機選擇并應用其中一對,獨立于每個樣本。
學習策略意味著搜索最佳的增強對、它們的大小和概率。在策略搜索過程中,必須對目標模型進行多次再培訓。這使得策略搜索的計算成本巨大。
為了避免計算成本高昂的搜索步驟,您可以重用在類似任務中找到的現有策略。或者,您可以使用其他自動數據擴充方法,這些方法旨在將搜索步驟保持在最低限度。
RandAugment將策略搜索步驟減少到只調整兩個數字:N和M.N是要在序列中應用的隨機選擇的操作數,以及M是所有操作共享的大小。盡管 RandAugment 很簡單,但我們發現,當與相同的增強集一起使用時,這種數據增強方法優于 AutoAugment 的策略。
TrivialAgument通過移除這兩個超參數來構建 RandAugment 。我們建議對每個樣本隨機選擇一個增量。 TrivialAugment 和 RandAugment 之間的區別在于,幅度不是固定的,而是隨機均勻采樣的。
結果表明,在訓練過程中隨機采樣增強對于模型泛化可能比廣泛搜索仔細調整的策略更重要。
從開始1.24 版本發布, DALI 提供了AutoAugment,RandAugment和TrivialAugment在這篇文章中,我們向您展示了如何使用所有這些最先進的實現,并討論了 DALI 中新的條件執行功能,這是它們實現的支柱。
DALI 和有條件執行
現代 GPU 架構顯著加快了深度學習模型訓練。然而,為了實現最大的端到端性能,必須快速預處理模型消耗的數據批次,以避免 CPU 出現瓶頸。
NVIDIA DALI 通過異步執行、預取、專用加載程序、一組豐富的面向批處理的擴充以及與流行的 DL 框架(如PyTorch,TensorFlow,PaddlePaddle和MXNet.
為了創建一個數據處理管道,我們在 Python 函數中組合了所需的操作,并用@pipeline_def出于性能原因,該函數只定義 DALI 的執行計劃,然后由 DALI 執行器異步運行。
下面的代碼示例顯示了一個管道定義,該定義加載、解碼并將隨機噪聲增強應用于圖像。
from nvidia.dali import pipeline_def, fn, types @pipeline_def(batch_size=8, num_threads=4, device_id=0) def pipeline(): encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True) image = fn.decoders.image(encoded, device="mixed") prob = fn.random.uniform(range=[0, 0.15]) distorted = fn.noise.salt_and_pepper(image, prob=prob) return distorted
管道的代碼是面向樣本的,而輸出是一批圖像。在指定運算符時不需要處理批處理,因為 DALI 在內部進行管理。
然而,到目前為止,還不可能表達對一批樣本子集進行操作的操作。這阻止了使用 DALI 實現自動擴增,因為它為每個樣本隨機選擇不同的操作。
DALI 中引入的條件執行使您能夠使用正則 Python 語義為批處理中的每個樣本選擇單獨的操作: if 語句。下面的代碼示例隨機應用兩個增強中的一個。
@pipeline_def(batch_size=4, num_threads=4, device_id=0,
enable_conditionals=True)
def pipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
image = fn.decoders.image(encoded, device="mixed")
change_stauration = fn.random.coin_flip(dtype=types.BOOL)
if change_stauration:
distorted = fn.saturation(image, saturation=2)
else:
edges = fn.laplacian(image, window_size=5)
distorted = fn.cast_like(0.5 * image + 0.5 * edges, image)
return distorted
我們增加了一些樣本的飽和度,并在其他樣本中使用拉普拉斯算子檢測邊緣,基于fn.random.coin_flip后果 DALI 翻譯if-else語句轉換為執行計劃,該執行計劃根據 if 條件將批處理拆分為兩個批處理。通過這種方式,部分批次分別并行處理,而樣本則屬于同一批次if-else分支仍然受益于批處理的 CUDA 內核。
您可以很容易地擴展該示例,以使用從任意集合中隨機選擇的擴充。在下面的代碼示例中,我們定義了三個擴充,并實現了一個選擇運算符,該運算符根據隨機選擇的整數選擇正確的一個。
def edges(image):
edges = fn.laplacian(image, window_size=5)
return fn.cast_like(0.5 * image + 0.5 * edges, image)
def rotation(image):
angle = fn.random.uniform(range=[-45, 45])
return fn.rotate(image, angle=angle, fill_value=0)
def salt_and_pepper(image):
return fn.noise.salt_and_pepper(image, prob=0.15)
def select(image, operation_idx, operations, i=0):
if i >= len(operations):
return image
if operation_idx == i:
return operations[i](image)
return select(image, operation_idx, operations, i + 1)
在下面的代碼示例中,我們選擇了一個隨機整數,并在 DALI 管道內使用 select 運算符運行相應的操作。
@pipeline_def(batch_size=6, num_threads=4, device_id=0,
enable_conditionals=True)
def pipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
image = fn.decoders.image(encoded, device="mixed")
operations = [edges, rotation, salt_and_pepper]
operation_idx = fn.random.uniform(values=list(range(len(operations))))
distorted = select(image, operation_idx, operations)
return distorted
因此,我們得到了一批圖像,其中每個圖像都通過一個隨機選擇的操作進行變換:邊緣檢測、旋轉和椒鹽噪聲失真。
DALI 自動增強
通過按樣本選擇運算符,您可以實現自動擴充。為了便于使用, NVIDIA 推出了auto_augDALI 中的模塊,具有流行的自動增強的現成實現:auto_aug.auto_augment,auto_aug.rand_augment和auto_aug.trivial_augment它們可以開箱即用,也可以通過調整增強幅度或構建 DALI 基元的用戶定義的增強來定制。
這個auto_aug.augmentationsDALI 中的模塊提供由自動增強程序共享的默認操作集:
auto_contrast
brightness
color
contrast
equalize
invert
posterize
rotate
sharpness
shear_x
shear_y
solarize
solarize_add
translate_x
translate_y
下面的代碼示例顯示了如何運行 RandAugment 。
import nvidia.dali.auto_aug.rand_augment as ra
@pipeline_def(batch_size=6, num_threads=4, device_id=0,
enable_conditionals=True)
def pipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
shape = fn.peek_image_shape(encoded)
image = fn.decoders.image(encoded, device="mixed")
distorted = ra.rand_augment(image, n=3, m=15, shape=shape, fill_value=0)
return distorted
這個rand_augment操作員接受解碼后的圖像、圖像的形狀、要在序列中應用的隨機增強的數量 (n=3) 以及這些行動應該具有的規模 (m=15,在可定制的0, 30范圍)。
在某些應用程序中,您可能必須限制已使用的擴充集。例如,如果數據集由數字圖片組成,則將數字“ 9 ”旋轉 180 度將使相關標簽無效。運行以下代碼示例rand_augment具有有限的增強集。
from nvidia.dali.auto_aug import augmentations as a
augmentations = [
a.shear_x.augmentation((0, 0.3), randomly_negate=True),
a.shear_y.augmentation((0, 0.3), randomly_negate=True),
a.translate_x.augmentation((0, 0.45), randomly_negate=True),
a.translate_y.augmentation((0, 0.45), randomly_negate=True),
a.rotate.augmentation((0, 30), randomly_negate=True),
]
每個增強都可以通過幅度如何映射到變換強度來參數化。例如a.rotate.augmentation((0, 30))指定要將圖像旋轉不大于 30 度的角度。randomly_negate=True指定角度應隨機取反,以便隨機順時針或逆時針旋轉圖像。
下面的代碼示例以類似 RandAugment 的方式應用增強。
@pipeline_def(batch_size=8, num_threads=4, device_id=0,
enable_conditionals=True)
def pipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
shape = fn.peek_image_shape(encoded)
image = fn.decoders.image(encoded, device="mixed")
distorted = ra.apply_rand_augment(augmentations, image, n=3, m=15, shape=shape, fill_value=0)
return distorted
前兩個管道定義之間的唯一區別是使用了更通用的apply_rand_augment接受附加參數的運算符,即擴充列表。
接下來,將自定義擴充添加到集合中。使用cutout作為一個例子。它使用 DALI 用一個歸零的矩形隨機覆蓋圖像的一部分fn.erase作用包fn.erase與@augmentation描述如何將幅度映射到cutout矩形。cutout_size是從 0 . 01 到 0 . 4 范圍的大小的元組,而不是普通大小。
from nvidia.dali.auto_aug.core import augmentation
def cutout_shape(size):
# returns the shape of the rectangle
return [size, size]
@augmentation(mag_range=(0.01, 0.4), mag_to_param=cutout_shape)
def cutout(image, cutout_size, fill_value=None):
anchor = fn.random.uniform(range=[0, 1], shape=(2,))
return fn.erase(image, anchor=anchor, shape=cutout_size, normalized=True, centered_anchor=True, fill_value=fill_value)
augmentations += [cutout]
對于更改,運行一組自定義的幾何增強,如TrivialAugment,即具有隨機幅度。對代碼的更改是最小的;您導入并調用trivial_augment而不是rand_augment來自aut_aug單元
import nvidia.dali.auto_aug.trivial_augment as ta
@pipeline_def(batch_size=8, num_threads=4, device_id=0,
enable_conditionals=True)
def pipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
shape = fn.peek_image_shape(encoded)
image = fn.decoders.image(encoded, device="mixed")
distorted = ta.apply_trivial_augment(augmentations, image, shape=shape, fill_value=0)
return distorted
DALI 的自動增強性能
現在,插上 DALI 和AutoAugment進入模型訓練并比較吞吐量,使用EfficientNet-b0例如,改編自NIVDIA Deep Learning Examples.AutoAugment是 EfficientNet 系列模型預處理階段的標準部分。
在鏈接的示例中AutoAugment策略使用 PyTorch 數據加載器實現,并在 CPU 上運行,而模型訓練在 GPU 上進行。當 DALI 管道替換在 CPU 上運行的數據加載器時,吞吐量會增加。 EfficientNet 加 DALI 的源代碼可在DALI examples.
該模型在自動混合精度模式( AMP )下運行,批量大小: DGX-1 V100 為 128 , DGX A100 為 256 。
我們用兩種硬件設置進行了實驗: DGX-1 V100 16 GB 和 DGX A100 。我們測量了每秒處理的圖像數量(越多越好)。在這兩種情況下,速度都有所提高: DGX-1 V100 的速度提高了 33% , DGX A100 的速度增加了 12% 。
圖中虛線所示的理論吞吐量是通過單獨改進數據預處理可以預期的訓練速度的上限。為了測量理論極限,我們使用在每次迭代中重復的一批合成數據而不是真實數據進行訓練。這讓我們看到了在不需要預處理的情況下,模型處理批次的速度有多快。
合成情況和 CPU 數據加載器情況之間的顯著性能差距表明存在預處理瓶頸。為了驗證這一假設,請查看訓練期間 GPU 的使用情況。
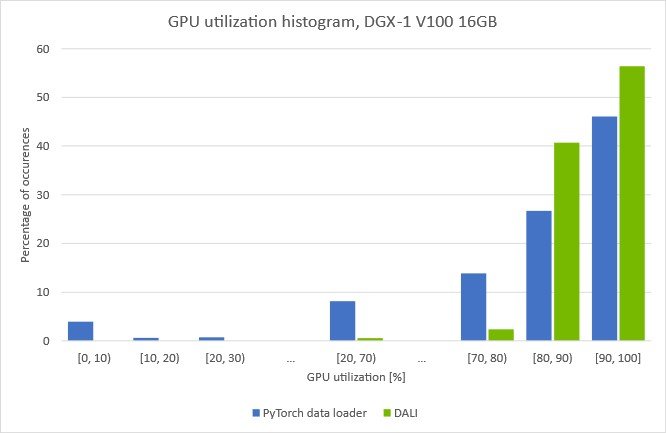 圖 7 。在 EfficientNet-b0 培訓期間, DGX-1V 16GB 的 GPU 利用率增加
圖 7 。在 EfficientNet-b0 培訓期間, DGX-1V 16GB 的 GPU 利用率增加
(批量大小 128 ,具有 DALI 數據預處理的自動混合精度模式)
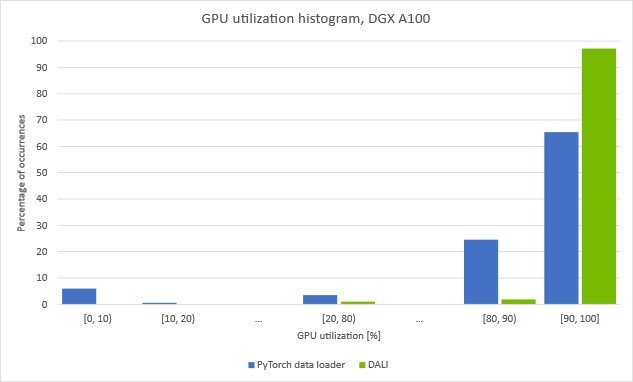 圖 8 。在 EfficientNet-b0 培訓期間, DGX-A100 的 GPU 利用率增加
圖 8 。在 EfficientNet-b0 培訓期間, DGX-A100 的 GPU 利用率增加
(批量大小 256 ,自動混合精度模式,帶 DALI 數據預處理)
這些圖顯示了在給定的 GPU 利用率下我們花費了多少時間。您可以看到,當使用在 CPU 上運行的數據加載器對數據進行預處理時, GPU 的利用率會反復下降。值得注意的是,在大約 5% 的時間里,利用率下降到 10% 以下。這表明訓練定期停滯,等待下一批數據從數據加載程序到達。
如果您將加載和自動增強步驟移動到帶有 DALI 的 GPU0, 10條消失,并且整體 GPU 利用率增加。圖 6 中顯示的使用 DALI 的訓練吞吐量的增加證實了我們成功地克服了之前的預處理瓶頸。
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102990 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238265 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
發布評論請先 登錄
相關推薦
《CST Studio Suite 2024 GPU加速計算指南》
NVIDIA火熱招聘GPU高性能計算架構師
NVIDIA-SMI:監控GPU的絕佳起點
購買哪款Nvidia GPU
Nvidia GPU風扇和電源顯示ERR怎么解決
在Ubuntu上使用Nvidia GPU訓練模型
MathWorks 增加對 NVIDIA GPU Cloud (NGC) 和 DGX 系統的支持
混合精度訓練的優勢!將自動混合精度用于主流深度學習框架
NVIDIA GPU加速計算之路
Nvidia GPU風扇和電源顯示ERR!

NVIDIA GPU加快深度神經網絡訓練和推斷
NVIDIA DALI概述及主要特性
NVIDIA GPU加速潞晨科技Colossal-AI大模型開發進程
Oracle 云基礎設施提供新的 NVIDIA GPU 加速計算實例






 工商網監
工商網監
評論