 PCIe?結構和RAID如何在GPUDirect存儲中釋放全部潛能
PCIe?結構和RAID如何在GPUDirect存儲中釋放全部潛能
隨著更快的圖形處理單元(GPU)能夠提供明顯更高的計算能力,存儲設備和GPU存儲器之間的數據路徑瓶頸已經無法實現最佳應用程序性能。NVIDIA的Magnum IO GPUDirect存儲解決方案通過在存儲設備和GPU存儲器之間實現直接路徑,可以極大地幫助解決該問題。然而,同等重要的是要使用容錯系統來優化其已經非常出色的能力,從而確保在發生災難性故障時備份關鍵數據。該解決方案通過PCIe?結構連接邏輯RAID卷,在PCIe 4.0規范下,這可以將數據速率提高到26 GB/s。為了解如何實現這些優勢,首先需要檢查該解決方案的關鍵組件及其如何協同工作來提供結果。
Magnum IO GPUDirect存儲
Magnum IO GPUDirect存儲解決方案的關鍵優勢是其能夠消除主要性能瓶頸之一,方法是不使用CPU中的系統存儲器將數據從存儲設備加載到GPU中進行處理。通常將數據移動到主機存儲器并傳送到GPU,這依賴于CPU系統存儲器中的回彈緩沖區,在數據傳送到GPU之前,會在其中創建數據的多個副本。但是,通過這種路徑移動大量數據會產生延遲時間,降低GPU性能,并在主機中占用許多CPU周期。借助Magnum IO GPUDirect存儲解決方案,無需訪問CPU并避免了回彈緩沖區效率低下(圖1)。
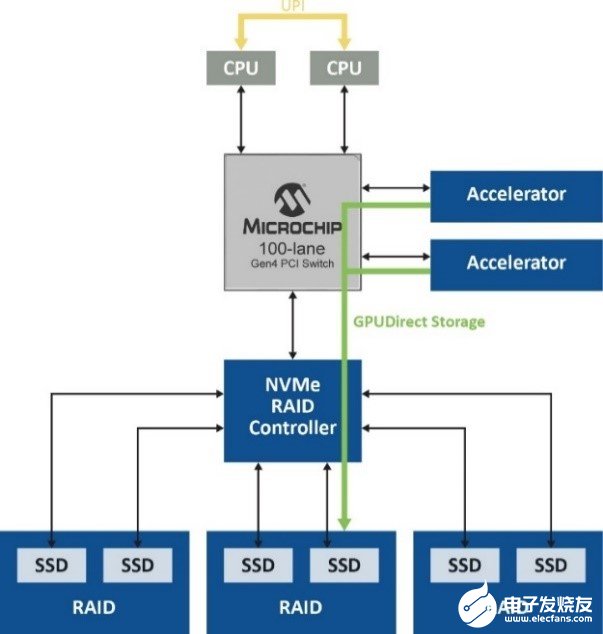
圖1. Magnum IO GPUDirect存儲解決方案無需訪問CPU,避免了從數據路徑回彈緩沖
性能直接隨著傳送數據量的增加而提高,傳送數據量則隨著人工智能(AI)、機器學習(ML)、深度學習(DL)和其他數據密集型應用所需的大型分布式數據集呈指數級增長。當數據在本地存儲或遠程存儲時,可以實現這些優勢,從而允許以比CPU存儲器中的頁面緩存更快的速度訪問數拍字節的遠程存儲。
優化RAID性能
該解決方案中的下一個元素是包括RAID功能,用于保持數據冗余和容錯能力。雖然軟件RAID可以提供數據冗余,但底層軟件RAID引擎仍然使用精簡指令集計算機(RISC)架構進行操作,例如奇偶校驗計算。當比較高級RAID級別(例如RAID 5和RAID 6)的寫I/O延遲時間時,硬件RAID仍然比軟件RAID快得多,因為提供了專用處理器來執行這些操作和回寫高速緩存。在流傳輸應用中,軟件RIAD的長期RIAD響應時間會導致數據堆積在高速緩存中。硬件RAID解決方案不存在緩存數據堆積問題,并且具有專門的備用電池,可以防止出現災難性系統掉電時數據丟失的情況。
標準硬件RAID雖然減輕了主機的奇偶校驗管理負擔,但大量數據仍需經過RAID控制器才能發送到NVMe?驅動器,導致數據路徑更加復雜。針對此問題的解決方案是NVMe優化的硬件RAID,該解決方案提供了簡化的數據路徑,無需經過固件或RAID片上控制器即可傳送數據。它還允許維護基于硬件的保護和加密服務。
混合PCIe結構
PCIe Gen 4現在是存儲子系統內的基本系統互連接口,但標準PCIe交換網具有與前幾代相同的基于樹的基本層級。這意味著,主機間通信需要非透明橋接(NTB)來實現跨分區通信,這使其變得復雜,特別是在多主機多交換網配置中。Microchip的PAX PCIe高級結構交換網等解決方案能夠克服這些限制,因為它們支持冗余路徑和循環,而這是使用傳統PCIe無法實現的。
結構交換網具有兩個獨立的域,主機虛擬域(專用于每個物理主機)和結構域(包含所有端點和結構鏈路)。來自主機域的事務會在結構域中轉換為ID和地址,反之,結構域中通信的非分層路由也是如此。這樣,系統中的所有主機便可共享連接到交換網和端點的結構鏈路。
在嵌入式CPU上運行的結構固件通過可配置的下行端口數虛擬化符合PCIe標準的交換網。因此,交換網將始終顯示為具有直連端點的標準單層PCIe設備,而與這些端點在結構中的位置無關。由于結構交換網會攔截來自主機的所有配置平面通信(包括PCIe枚舉過程)并選擇最佳路徑,因此它可以實現這一點。這樣,GPU等端點便可綁定到域中的任何主機(圖2)。
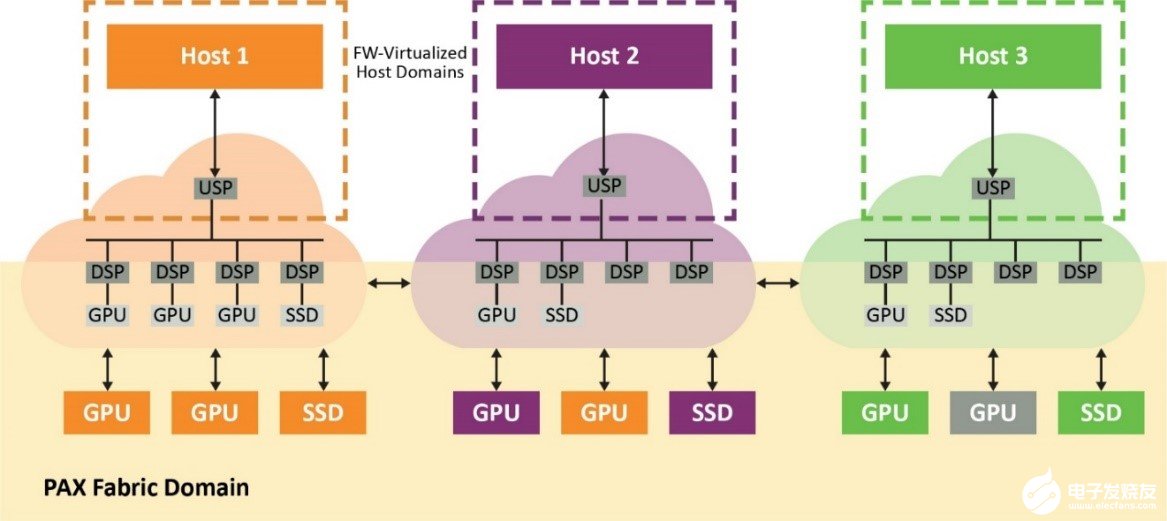
圖2. 交換網固件虛擬化的主機域顯示為每個主機符合PCIe標準的單層交換網
在以下示例(圖3)中,我們給出了雙主機PCIe結構引擎設置。此處,我們可以看到,結構虛擬化允許每個主機看到一個透明PCIe拓撲,其中包含一個上行端口、三個下行端口和三個連接到它們的端點,并且主機可以正確枚舉它們。圖3中的有趣之處是具有一個包含兩個虛擬功能的SR-IOV SSD,通過Microchip的PCIe高級結構交換網,同一驅動器的虛擬功能可以共享給不同的主機。
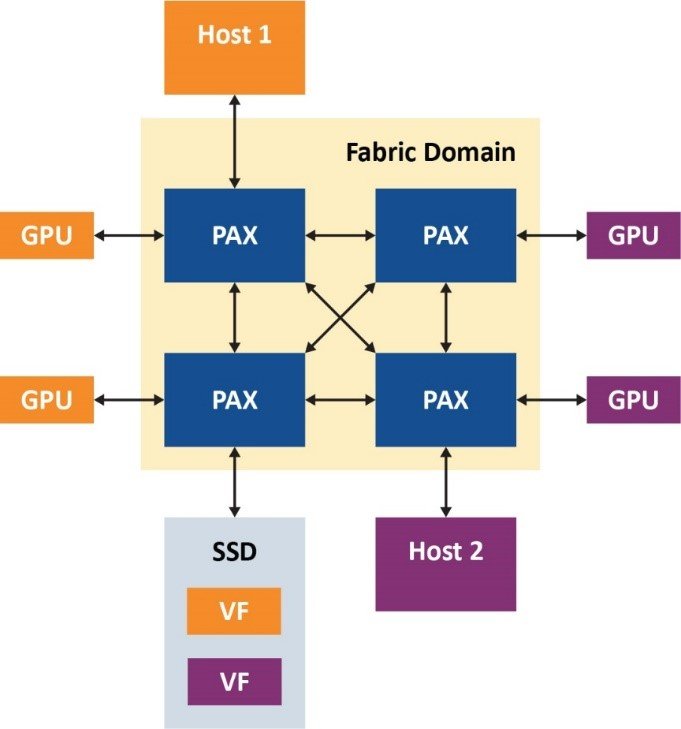
圖3. 雙主機PCIe?結構引擎
這種PAX結構交換網解決方案還支持在各結構之間直接跨域點對點傳輸,因此可減少根端口阻塞并進一步緩解CPU性能瓶頸,如圖4所示。
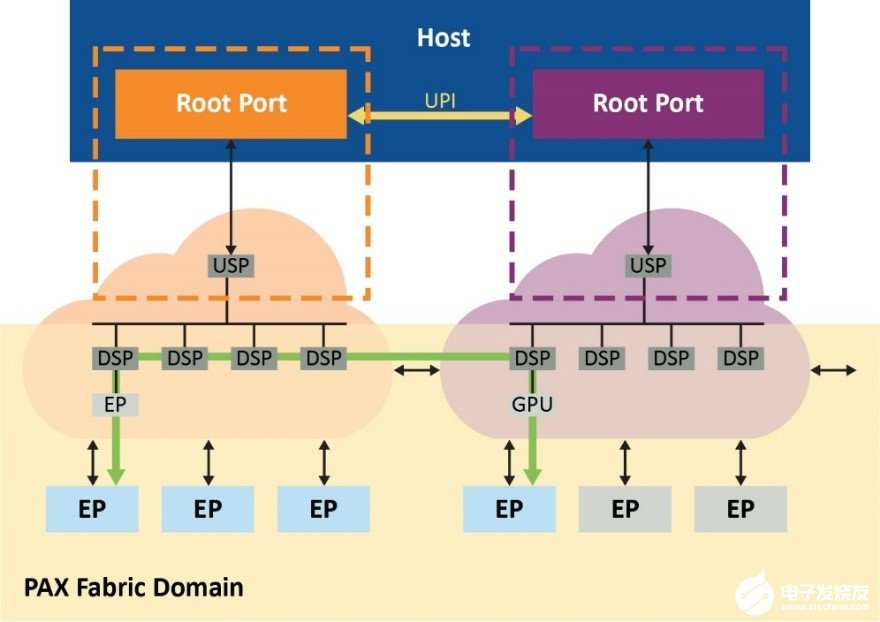
圖4. 通過結構路由通信,可減少根端口阻塞
性能優化
在探索了NVMe驅動器和GPU之間數據傳輸的性能優化過程中涉及的所有組件之后,現在可以結合使用這些組件來實現預期的結果。說明這一點的最佳方式是利用圖示演示各個步驟,圖5顯示了主機CPU及其根端口以及可實現最佳結果的各種配置。
如圖5左側所示,盡管使用的是高性能NVMe控制器,但由于根端口的開銷,PCI Gen 4 x 4(4.5 GB/s)的最大數據速率也限制為3.5 GB/s。不過,通過RAID(邏輯卷)同時聚合多個驅動器(如右側所示),SmartRAID控制器可為四個NVMe驅動器各創建兩個RAID卷,并通過根端口創建傳統PCIe點對點路由。這會將數據速率提高到9.5 GB/s。
但是,利用跨域點對點傳輸(底部的圖),可以通過結構鏈路而不是根端口來路由通信,從而實現26 GB/s的速率,這是使用SmartROC 3200 RAID控制器可達到的最高速率。在最后一個場景中,交換網提供不受固件影響的直接數據路徑,并且仍然保持基于硬件的RAID保護和加密服務,同時充分利用GPUDirect存儲的全部潛能。
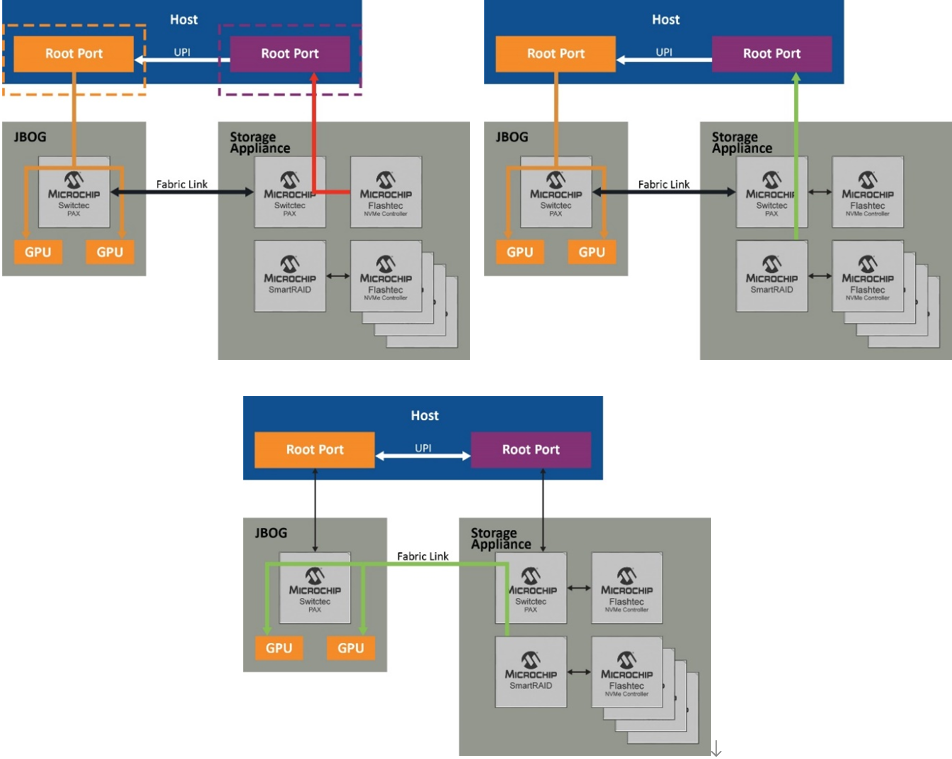
圖5. 實現26 GB/s的路徑
總結
高性能PCIe結構交換網(例如Microchip的PAX)允許多主機共享支持單根I/O虛擬化(SR-IOV)的驅動器,以及動態劃分可在多個主機之間共享的GPU和NVMe SSD池。Microchip的PAX結構交換網可以將端點資源動態重新分配給需要這些資源的任何主機。
這種解決方案還使用了SmartROC 3200 RAID控制器系列支持的SmartPQI驅動程序,因此無需自定義驅動程序。Microchip的SmartROC 3200 RAID控制器是目前惟一能夠提供最高傳輸速率(即26 GB/s)的設備。它具有極低的延遲時間,可向主機提供最多16個PCIe Gen 4通道,并向后兼容PCIe Gen 2。與Microchip基于Flashtec?系列的NVMe SSD結合使用時,可在多主機系統中發揮PCIe和Magnum IO GPUDirect存儲的全部潛能。總體而言,上述所有特性使其能夠構建一種強大的系統,該系統可以滿足AI、ML、DL以及其他高性能計算應用的實時需求。
-
存儲
+關注
關注
13文章
4296瀏覽量
85800 -
PCIe
+關注
關注
15文章
1234瀏覽量
82583
發布評論請先 登錄
相關推薦
服務器數據恢復—華為OceanStor存儲中RAID5陣列數據恢復案例

raid 在大數據分析中的應用
raid 存儲方案適合哪些場景
raid 和備份的區別是什么
PCIe與NVMe存儲的關系
服務器數據恢復—用5盤RAID5陣列中的4塊盤重建RAID5陣列后如何恢復原始數據?
總線類型raid是什么意思
服務器數據恢復—LeftHand存儲結構介紹和數據恢復案例
服務器數據恢復—raid5陣列熱備盤未全部成功啟用的數據恢復案例
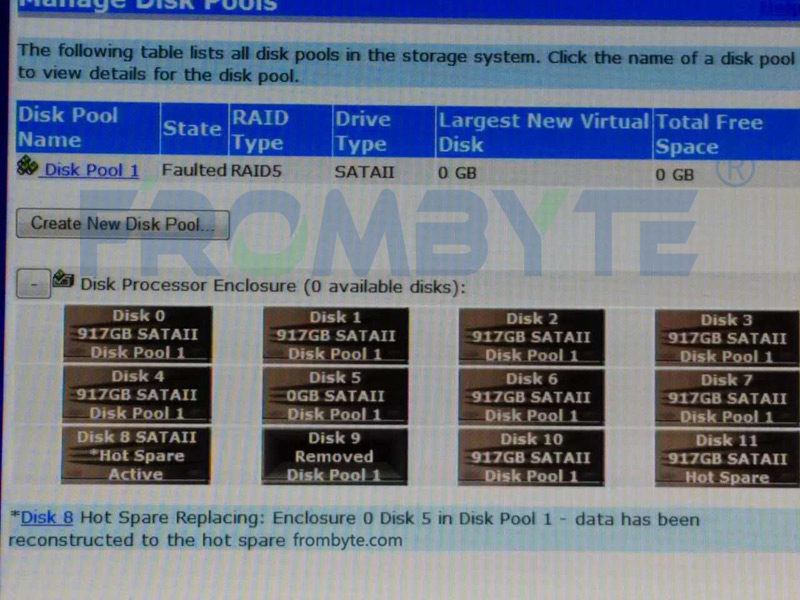
服務器數據恢復—LeftHand存儲結構&raid故障的數據恢復案例
服務器數據恢復—EMC存儲中raid5陣列多塊硬盤離線的數據恢復案例
浪潮信息引領數據編排新紀元,加速釋放數據潛能
佰維存儲RAID固件優化,助力數據中心強化效能與安全

服務器數據恢復—華為OceanStor存儲raid5數據恢復案例





 工商網監
工商網監
評論