") 國(guó)產(chǎn)替代狂奔,中國(guó)版英偉達(dá)何時(shí)現(xiàn)身?
國(guó)產(chǎn)替代狂奔,中國(guó)版英偉達(dá)何時(shí)現(xiàn)身?
導(dǎo)語(yǔ):在國(guó)產(chǎn)GPU突圍的道路上,部分廠商已經(jīng)走出了自己的路。但鑒于硬件、生態(tài)等各方面的差距,這樣必定是一條充滿荊棘的長(zhǎng)路。
最近,風(fēng)頭正盛的英偉達(dá)在算力領(lǐng)域又下一城。
在最新的最新MLPerf訓(xùn)練基準(zhǔn)測(cè)試中,英偉達(dá)的H100僅用11分鐘就訓(xùn)練完了GPT-3。
并且還在所有的八項(xiàng)測(cè)試中都創(chuàng)下了新紀(jì)錄。
可以說(shuō),這是一款專為AI、HPC和數(shù)據(jù)分析而設(shè)計(jì)的“性能怪獸”。
憑借著4nm制程、800億個(gè)晶體管、18432個(gè)CUDA核心,以及專用的Transformer引擎,H100將大模型訓(xùn)練速度提高了6倍。
同時(shí),H100還支持NVLink Switch系統(tǒng),可以實(shí)現(xiàn)單節(jié)點(diǎn)內(nèi)和節(jié)點(diǎn)間的全方位GPU通信,從而支持百億億級(jí)(Exascale)的工作負(fù)載。
這也是其能在MLPerf 8項(xiàng)基準(zhǔn)測(cè)試中橫掃其他競(jìng)爭(zhēng)者的重要原因。

在算力愈發(fā)重要的AIGC時(shí)代,任何能提高模型訓(xùn)練、機(jī)器學(xué)習(xí)的硬件技術(shù),都成了各大AI企業(yè)垂涎欲滴的產(chǎn)物。
然而,目前在GPU領(lǐng)域,大部分國(guó)內(nèi)企業(yè),仍然只能仰賴英偉達(dá)一家的技術(shù)。
在國(guó)內(nèi)算力愈發(fā)捉襟見肘,以及國(guó)際風(fēng)云變幻的敏感時(shí)刻,國(guó)內(nèi)的GPU廠商,能否奮力追趕,解決這一“卡脖子”難題,以至于成為下一個(gè)“英偉達(dá)”呢?
種子選手的秘密
在目前國(guó)內(nèi)一票GPU的“種子選手”中,一家名叫壁仞科技的企業(yè)引起了人們的注意。
原因很簡(jiǎn)單,那就是其產(chǎn)品BR100不僅創(chuàng)下了全球算力紀(jì)錄,并且宣稱其峰值算力達(dá)到了英偉達(dá)A100的3倍,甚至還能對(duì)標(biāo)沒(méi)發(fā)售的H100。
然而,稍微了解過(guò)國(guó)內(nèi)芯片行業(yè)的人都知道,在芯片領(lǐng)域,國(guó)內(nèi)的炒作太多了,徒有其表的例子也太多了。
那么,做出這個(gè)“媲美英偉達(dá)”GPU的企業(yè),究竟是什么來(lái)頭?其自主研發(fā)的BR100,是否真的像其宣傳的那樣出色?
要回答這個(gè)問(wèn)題,我們不妨先看看壁仞科技的創(chuàng)始班底,技術(shù)背景究竟如何。
作為一家通用智能芯片設(shè)計(jì)研發(fā)商的壁仞科技,成立于2019年,團(tuán)隊(duì)由國(guó)內(nèi)外芯片和云計(jì)算領(lǐng)域的專家和研發(fā)人員組成。
其創(chuàng)始人張旭博士,不僅擁有清華大學(xué)和斯坦福大學(xué)的博士學(xué)位,還曾是英偉達(dá)的高級(jí)架構(gòu)師,負(fù)責(zé)Volta架構(gòu)的設(shè)計(jì)和開發(fā)。
除此之外, 團(tuán)隊(duì)其他成員的技術(shù)身份,也頗為亮眼。
李新榮,聯(lián)席CEO,曾任AMD全球副總裁、中國(guó)研發(fā)中心總經(jīng)理,負(fù)責(zé)AMD大中華區(qū)的研發(fā)建設(shè)和管理工作。
洪洲,CTO,曾在NVIDIA、S3、華為等工作操刀GPU工程項(xiàng)目,擁有超過(guò)30年的GPU領(lǐng)域經(jīng)驗(yàn)。
焦國(guó)方,軟件生態(tài)環(huán)境主要負(fù)責(zé)人,曾在高通領(lǐng)導(dǎo)和產(chǎn)品研發(fā)了5代Adreno移動(dòng)GPU系統(tǒng)架構(gòu)。
這樣的團(tuán)隊(duì)背景,決定了壁仞科技的技術(shù)底色。
依據(jù)之前在英偉達(dá)、AMD、高通、商湯科技等知名企業(yè)的研發(fā)經(jīng)驗(yàn)和技術(shù)積累,壁仞科技研發(fā)了自主原創(chuàng)的芯片架構(gòu)——壁立仞。
壁立仞架構(gòu)基于SIMT(單指令多線程)模型,針對(duì)AI場(chǎng)景進(jìn)行了專用的優(yōu)化和定制。
其最大的特點(diǎn),就是可以將多個(gè)小芯片拼成一個(gè)大芯片,每個(gè)小芯片只做一部分功能,然后通過(guò)高速互連組合成一個(gè)大芯片。
這樣可以提高芯片的良率和可靠性,同時(shí)降低成本和功耗,實(shí)現(xiàn)更強(qiáng)大的算力和擴(kuò)展性。
這就是壁仞科技所謂的Chiplet的設(shè)計(jì)理念。
這種技術(shù)的難點(diǎn)在于如何保證芯片之間的高速通信和協(xié)作,同時(shí)避免信號(hào)干擾和功耗過(guò)高。
因此,如何設(shè)計(jì)合適的芯片分割和組合方案,使得每個(gè)芯片都能發(fā)揮最大的效能,同時(shí)減少電磁干擾和熱耗散,就成了Chiplet能否成功的關(guān)鍵。
對(duì)此,壁仞科技使用了兩種關(guān)鍵的技術(shù)2.5DCoWoS和BLink,來(lái)攻克這一難關(guān)。
簡(jiǎn)單地說(shuō),2.5D CoWoS技術(shù)是一種把多個(gè)芯片堆疊在一起的技術(shù),它利用了一個(gè)硅基板作為中介層,縮短了芯片之間的距離,從而提高了信號(hào)的傳輸速度和質(zhì)量。
而BLink則在中介層上,建立了一個(gè)專用的接口,它可以讓多個(gè)芯片之間直接傳輸數(shù)據(jù),而不需要經(jīng)過(guò)其他的電路或芯片,從而減少了延遲和功耗。
然而,盡管2.5D CoWoS、BLink這些技術(shù),讓壁仞科技打造出了算力更強(qiáng)的BR100,但這些技術(shù),目前在國(guó)際上并不罕見,其他GPU廠商也有過(guò)類似的設(shè)計(jì)。
例如,Nvidia的A100和H100 GPU都采用了CoWoS技術(shù),把GPU芯片和HBM內(nèi)存堆疊在一起,提高了內(nèi)存帶寬和計(jì)算性能。而Nvidia還開發(fā)了自己的NVLink接口,類似于BLink接口,可以讓多個(gè)GPU之間高速互聯(lián)。
此外,AMD也有自己的Infinity Fabric接口,可以實(shí)現(xiàn)類似的功能。
那既然這是一種“大家都能用”的技術(shù),那壁仞科技怎么就做到讓BR100算力達(dá)到A100三倍的呢?而英偉達(dá)真就會(huì)坐視著自己被超越了?
其實(shí),這樣的結(jié)果,是二者在不同數(shù)據(jù)格式下的表現(xiàn)所致。
具體來(lái)說(shuō),BR100的巨大算力,更多是在矩陣FP32數(shù)據(jù)格式下的表現(xiàn)。
一般來(lái)說(shuō),數(shù)據(jù)格式占用的位數(shù)越多,它的范圍和精度就越高,但是也會(huì)消耗更多的空間和電力。
而矩陣FP32其實(shí)就是一種特殊的FP32數(shù)據(jù)格式,它只用了19位來(lái)存儲(chǔ)一個(gè)浮點(diǎn)數(shù),這樣做的目的是為了讓矩陣FP32能夠兼容Tensor Core這種專門用于加速矩陣乘法的硬件單元。
矩陣乘法是深度學(xué)習(xí)中最常見和最重要的計(jì)算操作之一,所以使用矩陣FP32可以大幅提升深度學(xué)習(xí)的性能。
但是,矩陣FP32也有一個(gè)缺點(diǎn),就是它的精度比向量FP32低,也就是說(shuō)它能表示的浮點(diǎn)數(shù)的范圍和細(xì)節(jié)程度比向量FP32小。
這樣就會(huì)導(dǎo)致一些誤差和損失,在某些情況下可能會(huì)影響模型的質(zhì)量和效果。
因此,矩陣FP32和英偉達(dá)A100的向量FP32并不等價(jià),因?yàn)榫仃嘑P32只適用于矩陣乘法這種特定的計(jì)算操作,并不能代表GPU的整體性能。
生態(tài)之痛
除了技術(shù)方面的較量外,軟件生態(tài)上的壁壘,也是國(guó)產(chǎn)GPU無(wú)法忽視的一道屏障。
從某種程度上說(shuō),這樣的壁壘比某些具體技術(shù)的難點(diǎn),更難以攻克。
在GPU領(lǐng)域,業(yè)界流傳著一種說(shuō)法:“CUDA是Nvidia最深的護(hù)城河”。
這是因?yàn)椋缭谑畮啄昵埃跇I(yè)內(nèi)大部分人都認(rèn)為GPU只能處理圖形相關(guān)的計(jì)算時(shí),英偉達(dá)就已經(jīng)意識(shí)到了GPU在AI領(lǐng)域的潛力和價(jià)值,并開始了相應(yīng)的布局,在2006年推出了通用并行計(jì)算架構(gòu)CUDA。
在CUDA問(wèn)世前,人們?cè)谶M(jìn)行各種計(jì)算任務(wù)時(shí),用的都是CPU,而非GPU。
然而,CPU雖然具有很強(qiáng)的“通用性”,可以處理各種計(jì)算,但是它的速度不夠快,而且核心數(shù)量有限。
而相較之下,只能處理圖形計(jì)算的GPU,不僅速度很快快,而且有很多很多的核心。
通過(guò)CUDA,在進(jìn)行AI計(jì)算時(shí),人們可以將神經(jīng)元之間的計(jì)算分配到GPU的不同核心上,并行地進(jìn)行運(yùn)算。這樣就大大提高了神經(jīng)網(wǎng)絡(luò)的訓(xùn)練和推理的速度、效果。
英偉達(dá)看到了CUDA的巨大潛力,于是不斷地完善和優(yōu)化CUDA的技術(shù)和生態(tài)。
例如讓CUDA支持C、C++、Fortran、Python等多種編程語(yǔ)言,或是提供了針對(duì)不同領(lǐng)域和應(yīng)用優(yōu)化的庫(kù)和工具,比如圖像處理庫(kù)、深度學(xué)習(xí)庫(kù)、自動(dòng)駕駛庫(kù)等等。
這樣的優(yōu)化,為開發(fā)者提供了極大的便利,使其不用再學(xué)習(xí)新的編程語(yǔ)言,或是從頭開始編寫代碼。
于是,越來(lái)越多的人用慣了,用舒服了,CUDA的生態(tài)就這么被搭建起來(lái)了。
誠(chéng)然,在CUDA構(gòu)建自身生態(tài)壁壘的過(guò)程中,也不是沒(méi)有遇到過(guò)競(jìng)爭(zhēng)者,但最后這些對(duì)手都一一成為了“陪跑者”。
例如,蘋果公司和Khronos Group在2009年推出的OpenCL,也有過(guò)想成為行業(yè)標(biāo)準(zhǔn)的想法,讓人們可以用不同廠商的CPU、GPU、來(lái)做異構(gòu)計(jì)算。
然而,OpenCL沒(méi)有CUDA那么高效和靈活,需要更多的編程技巧和優(yōu)化工作,這就加大了開發(fā)者的負(fù)擔(dān)。
而英偉達(dá)的老對(duì)手AMD,也想要提供一個(gè)通用并行計(jì)算平臺(tái),并推出了相應(yīng)的產(chǎn)品ROCm,它跟CUDA的架構(gòu)非常類似,甚至有一個(gè)工具叫hipify,可以把CUDA代碼轉(zhuǎn)換成ROCm代碼。
但是ROCm只能用在AMD的GPU上,而且只支持幾款顯卡。
于是,綜合對(duì)比下來(lái),更多的開發(fā)者還是選擇了“通用性”、“易用性”都更勝一籌的CUDA。
如今,在軟件生態(tài)方面,壁仞科技也推出了自主研發(fā)的BIRENSUPA軟件平臺(tái),試圖通過(guò)“無(wú)縫運(yùn)行”的方式,讓開發(fā)者無(wú)需修改代碼,就可以在BR100系列產(chǎn)品上運(yùn)行原本基于CUDA的應(yīng)用。
這樣,習(xí)慣了使用CUDA的用戶,如果轉(zhuǎn)而使用BR100系列產(chǎn)品,可以獲得更高的計(jì)算性能和更低的功耗成本。
然而,這樣的思路,卻面臨著幾大挑戰(zhàn),而其中之一,就是BR100系列產(chǎn)品在通用計(jì)算生態(tài)上的支持。
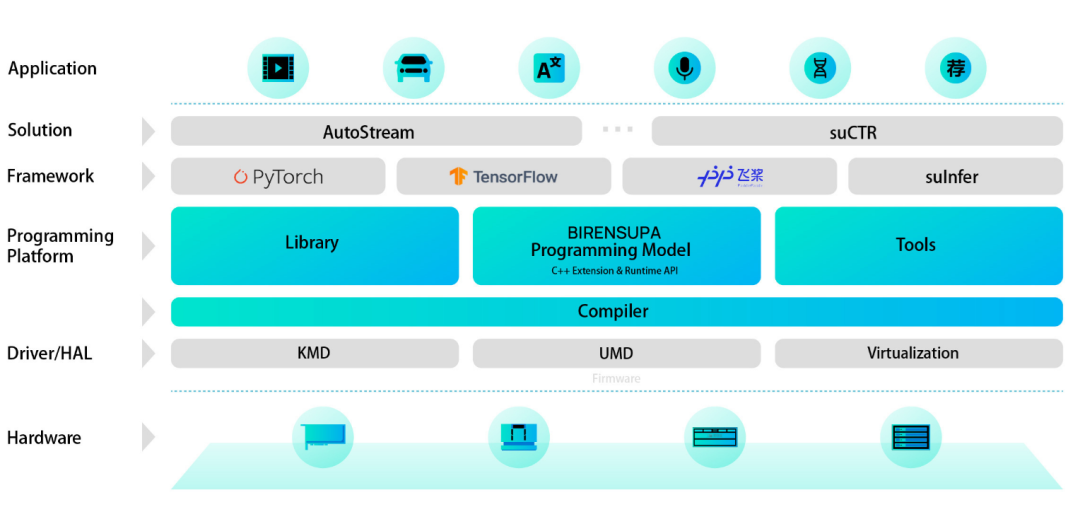
BIRENSUPA軟件平臺(tái)
因?yàn)椋谪鹂萍紴榱颂岣連R100系列產(chǎn)品在AI計(jì)算方面的性能和能效,也對(duì)流處理器進(jìn)行了一些優(yōu)化和定制,比如說(shuō)使用BF16替代FP16作為主要的數(shù)據(jù)格式,以及增加了一些針對(duì)AI的硬件指令和功能。
這樣,BR100就可能犧牲了部分通用計(jì)算能力,導(dǎo)致其在一些非AI的應(yīng)用場(chǎng)景和領(lǐng)域上表現(xiàn)不佳或者不兼容。
而這也是為什么,BR100的主要應(yīng)用場(chǎng)景,大多是復(fù)旦大學(xué)、清華大學(xué)這類高校的人工智能計(jì)算和高性能計(jì)算項(xiàng)目。
除此之外,BR100系列產(chǎn)品,在算力利用率上也存在著風(fēng)險(xiǎn)。
雖然,BR100的架構(gòu)是通用的,如果如果壁仞科技愿意,也同樣可以將其用于通用類的計(jì)算。
但因?yàn)锽R100的內(nèi)部算力帶寬已經(jīng)明顯超過(guò)PCIe和HBM2e的帶寬,所以絕大部分?jǐn)?shù)據(jù)可能都要在GPU內(nèi)流轉(zhuǎn)。
這就意味著,雖然BR100的算力很強(qiáng)大,它的數(shù)據(jù)來(lái)源和輸出通道,都不夠快,不能及時(shí)地給它送來(lái)或者拿走數(shù)據(jù)。
而如果一個(gè)軟件生態(tài)主要支持通用處理, 它的GPU芯片往往就需要有足夠高的外部帶寬,來(lái)獲取各種類型的數(shù)據(jù)。
這是因?yàn)椋煌愋偷膽?yīng)用,往往對(duì)帶寬的需求和敏感度都不同。一些大型的應(yīng)用,可能需要更高的帶寬,才能更好地計(jì)算。
最后,也是最具風(fēng)險(xiǎn)的一點(diǎn),就是雖然壁仞科技宣稱,BR100要無(wú)縫地支持CUDA生態(tài),但CUDA不是一個(gè)開源生態(tài),英偉達(dá)在其中埋下了大量專利壁壘。
如果壁仞科技真的打算撬動(dòng)這塊壁壘,則很可能受到英偉達(dá)的在專利上的反擊。
綜上所述,雖然目前在國(guó)產(chǎn)GPU突圍的道路上,部分廠商已經(jīng)走出了自己的路,但鑒于硬件、生態(tài)等各方面的差距,這樣的道路,必定是一條充滿荊棘的長(zhǎng)路。
審核編輯:劉清
-
gpu
+關(guān)注
關(guān)注
28文章
4743瀏覽量
129009 -
芯片設(shè)計(jì)
+關(guān)注
關(guān)注
15文章
1021瀏覽量
54922 -
晶體管
+關(guān)注
關(guān)注
77文章
9701瀏覽量
138382 -
HPC
+關(guān)注
關(guān)注
0文章
316瀏覽量
23807 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3780瀏覽量
91219
原文標(biāo)題:國(guó)產(chǎn)替代狂奔,中國(guó)版英偉達(dá)何時(shí)現(xiàn)身?
文章出處:【微信號(hào):alpworks,微信公眾號(hào):阿爾法工場(chǎng)研究院】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
英偉達(dá)辟謠中國(guó)市場(chǎng)斷供消息

加速拋棄英偉達(dá),微軟又發(fā)布一顆芯片 #微軟 #英偉達(dá) #半導(dǎo)體 #芯片 #電路知識(shí)
英偉達(dá)超越蘋果成為市值最高 英偉達(dá)取代英特爾加入道指
英偉達(dá)投資日本AI公司Sakana AI

英偉達(dá)Blackwell架構(gòu)揭秘:下一個(gè)AI計(jì)算里程碑?# 英偉達(dá)# 英偉達(dá)Blackwell
成都匯陽(yáng)投資關(guān)于華為新版芯片或挑戰(zhàn)英偉達(dá),國(guó)產(chǎn)算力值得關(guān)注?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論