") AMD Versal系列FPGA NoC介紹及實戰(zhàn)
AMD Versal系列FPGA NoC介紹及實戰(zhàn)
一、NoC前世今生
NoC是相對于SoC的新一代片上互連技術,從計算機發(fā)展的歷史可以看到NoC 必將是SoC 之后的下一代主流技術,SoC 通常指在單一芯片上實現的數字計算機系統(tǒng),總線結構是該系統(tǒng)的主要特征,由于其可以提供高性能的互連而被廣泛運用。然而隨著半導體工藝技術的持續(xù)發(fā)展,出現了一些與總線相關的問題:總線地址空間有限,由于使用單一時鐘整個芯片均同步的限制。一個典型的SoC系統(tǒng)主要包含以下結構:
A.至少一個微控制器(MCU)或微處理器(MPU)或數字信號處理器(DSP),但是也可以有多個處理器內核;
B.存儲器可以是RAM、ROM、EEPROM和閃存中的一種或多種;
D.由計數器和計時器、電源電路組成的外設;
E.不同標準的連線接口,如USB、火線、以太網、通用異步收發(fā)和序列周邊接口等;
G.電壓調理電路及穩(wěn)壓器;
目前的SOC架構各個組件之間的通訊還是以AMBA總線為主,AMBA包含AHB/ASB/APB/AXI這四種主要的總線協(xié)議,而這些協(xié)議無一例外的都是基于中斷和仲裁機制的。然而,隨著商業(yè)應用開始不斷追求指令運行并存性和預測性,芯片中集成的核數目將不斷增多,基于總線架構的SoC將逐漸難以滿足不斷增長的計算需求。其主要表現為:
A.可擴展性差:SoC系統(tǒng)設計是從系統(tǒng)需求分析開始,確定硬件系統(tǒng)中的模塊。為了使系統(tǒng)能夠正確工作,SoC中各物理模塊在芯片上的位置是相對固定的;一旦在物理設計完畢后,要進行修改,實際上就有可能是一次重新設計的過程;另一方面,基于總線架構的SoC,由于總線架構固有的仲裁通信機制,即同一時刻只能有一對處理器核心進行通信,限制了可以在其上擴展的處理器核心的數量;
B.平均通信效率低:SoC中采用基于獨占機制的總線架構,其各個功能模塊只有在獲得總線控制權后才能和系統(tǒng)中其他模塊進行通信;從整體來看,一個模塊取得總線仲裁權進行通信時,系統(tǒng)中的其他模塊必須等待,直到總線空閑;
C.單一時鐘同步問題:總線結構要求全局同步,然而隨著工藝特征尺寸越來越小,工作頻率迅速上升,達到10GHz以后,連線延時造成的影響將嚴重到無法設計全局時鐘樹的程度,而且由于時鐘網絡龐大,其功耗將占據芯片總功耗的大部分; 二、AMD Versal器件NoC介紹
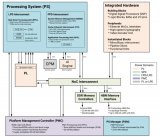
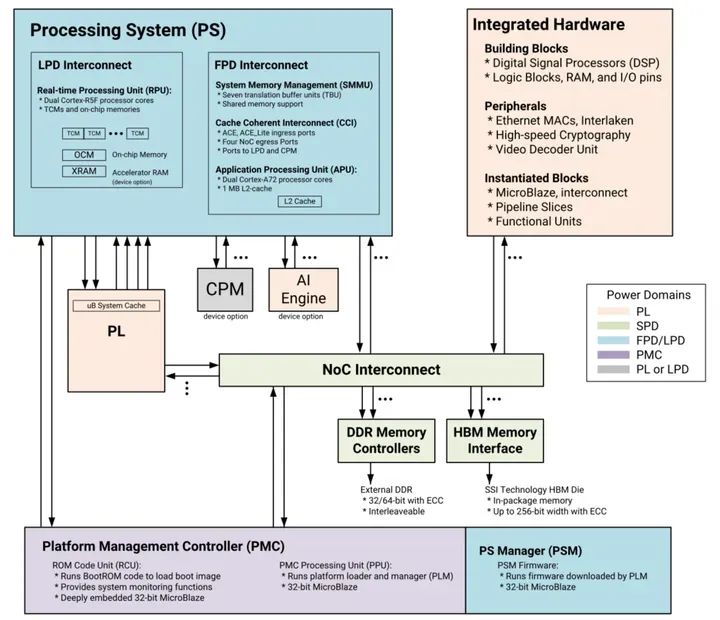
AMD Versal系列器件上的NoC網絡主要架構如下圖所示:
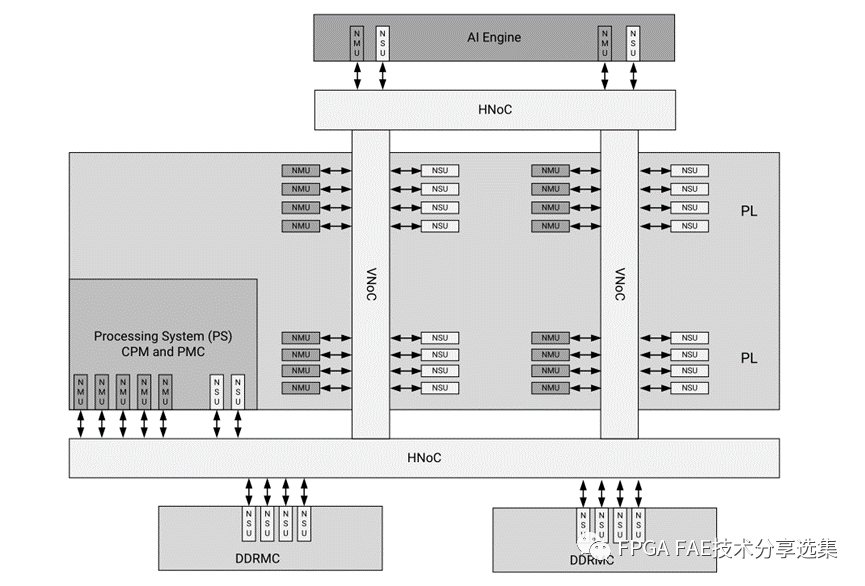
AMD Versal可編程芯片網絡(NoC)是使用的互連網絡,用于在可編程邏輯(PL)、處理系統(tǒng)(PS)中的IP端點之間共享數據。這種設備范圍的基礎設施是高速、集成化并帶有專用開關的數據路徑。可以對NoC進行邏輯配置以表示復雜的拓撲,使用一系列水平和垂直路徑以及一組可定制的體系結構。
NoC是為可擴展性而設計的。它是由一系列相互連接的水平(HNoC)和垂直(VNoC)路徑,由一組可定制的硬件實現支持。可以以不同方式配置的組件,以滿足設計時間,速度和邏輯利用需求。HNoC和VNoC是連接集成塊的專用高帶寬路徑,在處理器系統(tǒng)和可編程邏輯(PL)之間不需要消耗大量可編程邏輯的數量。
NoC支持端到端服務質量(QoS),以有效地管理事務和平衡每個流量流的競爭延遲和帶寬需求。NoC組件包括NoC主單元(NMU)、NoC從單元(NSU)和NoC包交換機(NPS)和NoC模間橋(NIDB)。NMU為交通入口點,而NSU是交通出口點。所有ip都有一定數量的主連接和從連接。NIDB將兩個超級邏輯區(qū)域(slr)連接在一起,提供芯片之間的高帶寬。NPS是橫條交換機,用于完全形成網絡。
AMD Versal系列器件的NoC支持如下特性:
A.PL對PL通信;
B.PL到CIPS的通信;
C.CIPS到PL通信;
D.CIPS到DDR內存通信;
E.CIPS到AI引擎的通信;
F.高帶寬數據傳輸;
G.支持標準的AXI4接口到NoC,支持AXI4-Lite需要軟橋;
H.支持時鐘域交叉;
I.內部寄存器編程互連編程NoC寄存器;
J.多種路由選擇:基于物理地址;根據目的接口設置;虛擬地址支持;
K.通過強化SSIT橋接實現芯片間連接;
L.在SSIT配置中,從源芯片PMC傳輸比特流到目標芯片PMC;
M.可編程路由表的負載平衡和死鎖避免;
N.調試和性能分析功能;
O.端到端數據保護的可靠性,可用性,可服務性(RAS);
P.在整個NoC中有效地支持虛擬通道和服務質量(QoS),管理事務并平衡每個事務的競爭延遲和帶寬需求;
Q.NoC連接硬件(或接入點)使用主從,內存映射配置。NoC上最基本的連接由一個主連接組成到使用單個分組交換機的單個從機。使用這種方法,主機獲得AXI信息并將其打包,以便通過分組交換機在NoC上傳輸到從機的slave將數據包分解為傳遞給連接后的AXI信息。為了實現這一點,一個NoC接入點管理所有的時鐘域交叉、交換和AXI和NoC端之間的數據緩沖,反之亦然;
R.支持內存映射事務的糾錯碼(ECC),不支持流;
NoC功能模塊如下:
A.NoC Master Unit (NMU):用于連接主控節(jié)點和NoC;
B.NoC Slave Unit (NSU):用于連接從設備到NoC;
C.NoC分組交換機(NPS):用于沿NoC和執(zhí)行傳輸和分組交換設置和使用虛擬通道NMU和NSU組件通過標準從可編程邏輯端訪問;
NoC的AXI4使用以下基本的AXI特性:
A.支持AXI4和AXI4- stream;
B.可配置AXI接口寬度:32、64、128、256或512位接口;
C.64位尋址;
D.AXI排他訪問的處理;
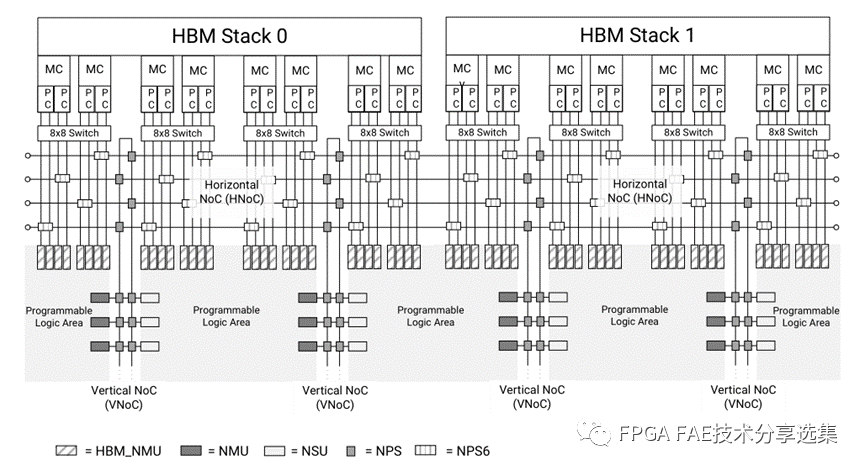
在AMD Versal系列器件中將NoC整合到了專用的硬化DDR/HBM控制器中,可以更為方便的對存儲器數據流進行分配。其中HBM NoC結構可以參見下圖:
三、AMD Versal NoC IP功能介紹
AMD Versal NoC IP主要包括AXI/DDR Memory Controller/HBM Memory Controller/AXI Stream幾種基礎模式,可以根據速率/帶寬的需求進行自由組合和選擇。本文主要基于AXI接口的NoC IP進行簡要介紹,基本界面如下圖所示:
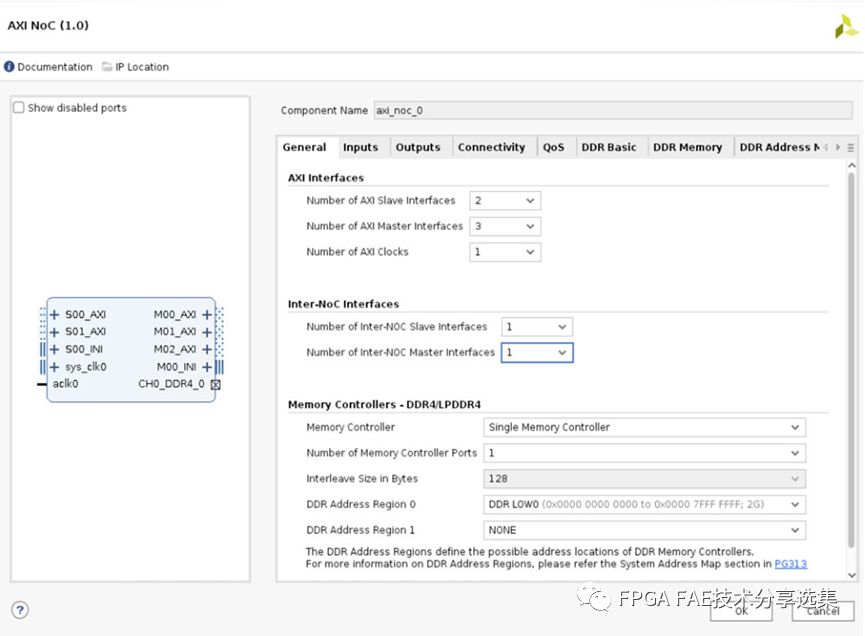
對界面上幾個主要選項做如下說明:
AXI接口:
A. AXI Slave接口數量:NMU (NoCingress)接口的數; B. AXI Master Interface數量:NSU (NoC出口)端口數量; C. AXI時鐘的數量:這是將被跨使用的獨立AXI時鐘的數量,NMU和NSU端口的集合,基于接口輸入相關時鐘的工具將推斷每個接口的時鐘關聯(lián);
Inter-NoC接口:
A. Inter-NoC SlaveInterface的數量:表示Inter-NoC Interface ingress (INI)的數量;
B. Inter-NoC MasterInterface數量:Inter-NoC Interface出接口數量(INI)端口;
內存控制器-DDR4/LPDDR4:
A. 內存控制器數量:已連接的集成內存控制器數量這個axi_noc實例,必須為0、1、2或4,2或4表示內存控制器交錯;
B. Memory ControllerPorts數量:內存控制器中可連接的MC端口數量連接選項卡,必須是0-4,這對應于已啟用的NSU連接數;
C.交錯大小:當內存控制器交錯時,設置每個字節(jié)的數量交錯,必須是{128,256,512,1024,2048,4096}中的一個;
D. DDR地址區(qū)域0/1:將DDRMC地址與統(tǒng)一的系統(tǒng)地址進行映射通用設備的地圖,有關更多信息,請參閱系統(tǒng)地址映射;
對于input和output頁面的功能主要是配置NoC的互聯(lián)信息,整體界面如下圖所示:
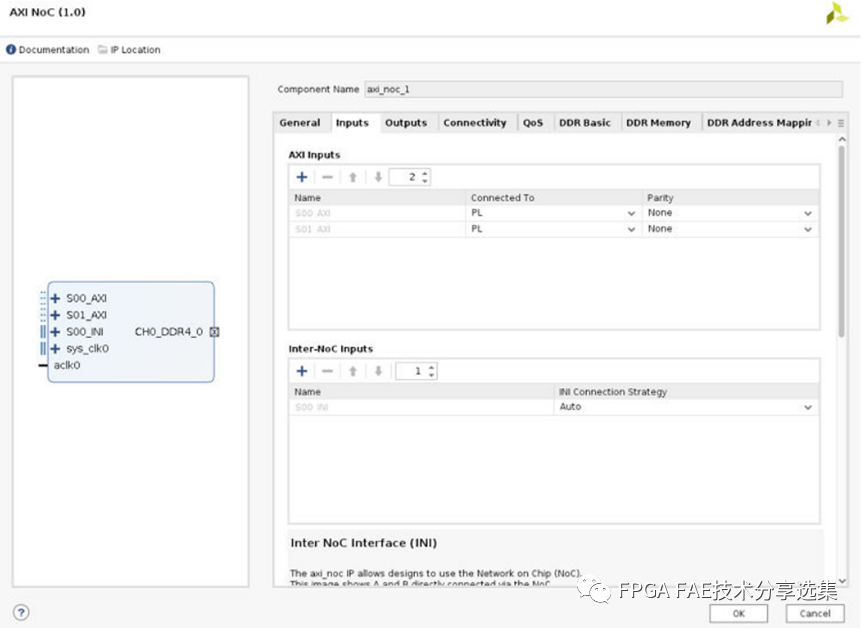
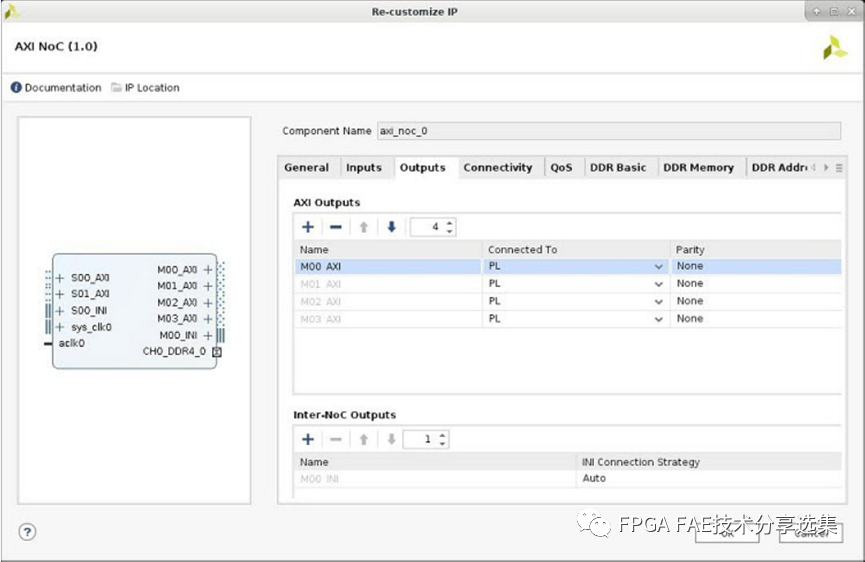
A. AXI輸入:設置該實例的AXI輸入的數量,并配置每個輸入的配置選項有如下連接對象:
? AIE:來自AI引擎陣列;
? PS非相干:來自PS的非相干接口之一;
? PS PMC:來自PS的平臺管理控制器;
? PS LPD:來自低功耗域;
? PL:來自可編程邏輯結構;
? PS Cache Coherent:從PS的一個Cache Coherent接口;
? PS PCIe:從PS的PCIe接口;
B. 奇偶校驗:啟用從AXI主機到NMU的連接的奇偶校驗,可用的奇偶校驗選項有:
? None:不校驗;
? 地址:AXI地址奇偶校驗啟用;
? 數據:AXI數據奇偶校驗啟用;
? 地址和數據:啟用了AXI地址和數據檢查;
奇偶校驗位的對應關系如下表所示:
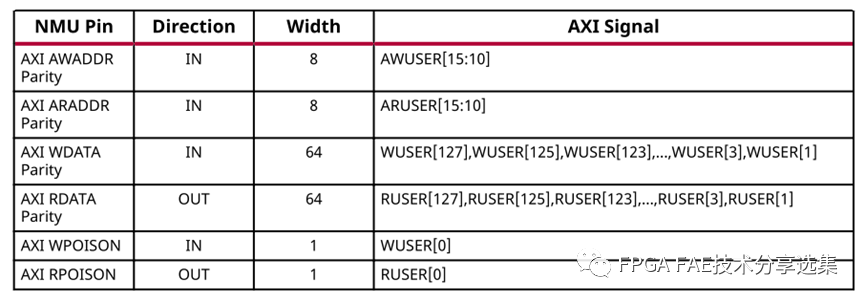
注意:奇偶校驗只對連接到PL的輸入有效,從PS或AI引擎不支持奇偶校驗。
C. Inter-NoC輸入:使用Inter-NoC接口指定來自其他axi_noc實例的輸入(INI);
您可以選擇設置INI連接策略如下:
? 自動:IP集成商決定正確的策略。這是默認設置;
? 單驅動:只有一個驅動,可能有多個負載;
? 單負載:有一個負載和可能的多個驅動程序;
D. AXI輸出:設置該實例的AXI輸出數量并配置每個輸出,配置選項有:
? 連接對象;
? PL:到可編程邏輯結構;
? AIE:連接到AI引擎陣列;
? PS Cache CoherentVirtual:到PS的一個Cache Coherent接口,路由到此NSU端主機使用固定目的地地址路由所有從NMU到NSU的事務,此設置適用于使用功能在SMMU-400和/或CCI-500;
? PS Cache CoherentPhysical:到PS的Cache Coherent接口之一,All PL路由到該NSU端口的主機使用地址解碼尋址來路由事務,此設置適用于以PS中的端點從機為目標的端點主機并不適用于使用CCI-500中的特性的端點主機;
? PS Non-CoherentVirtual:指向PS上的一個非相干接口路由到此NSU端口的主機使用固定目的地地址路由所有從NMU到NSU的事務;
? PS Non-CoherentPhysical:到PS的一個非相干接口路由到該NSU端口的主機使用地址解碼尋址來路由事務,此設置適用于以PS中的端點從服務器為目標的端點主服務器;
? PS PCIe:連接到PS的PCIe接口;
? PS PMC:到PS的平臺管理控制器;
? 奇偶校驗:啟用從NSU到AXI slave的連接的奇偶校驗使用奇偶校驗,奇偶校驗選項與輸入選項卡中描述的選項相同;
奇偶校驗位的映射說明如下表所示:
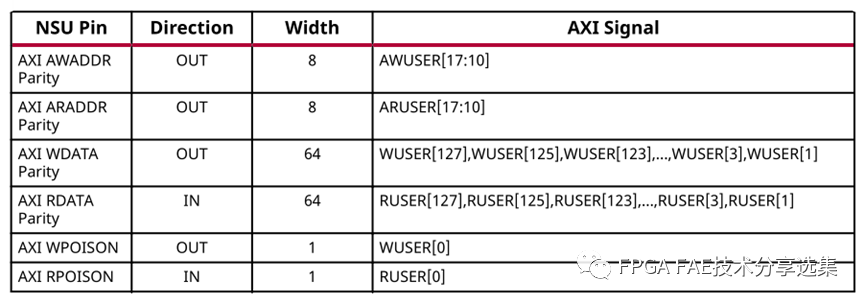
注意:奇偶校驗只對連接到PL的輸出有效,對于PS或AI引擎無效;
E. Inter-NoC輸出:使用Inter-NoC接口指定輸出到其他axi_noc實例(INI);
您可以選擇設置INI連接策略如下:
? 自動:允許IP集成商確定正確的策略;
? 單驅動(NMU):負載(NSU/MC)擁有PR路徑并具有QoS;
? 單負載(NSU/MC):NMU (Driver)擁有PR路徑和QoS;
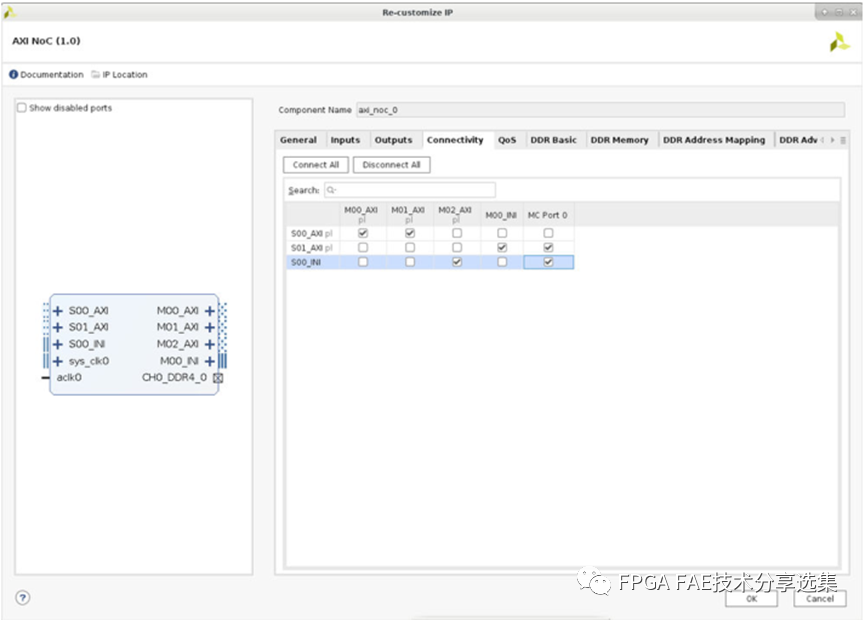
對于Connectivity頁面來說主要是用于配置AXI接口的Slave和Master的連接關系,就不再詳述了,頁面布局如下圖所示:
對于QoS頁面來說主要是配置NoC的QoS特性,分為基礎QOS和高級QOS配置兩種,整體界面如下圖所示:
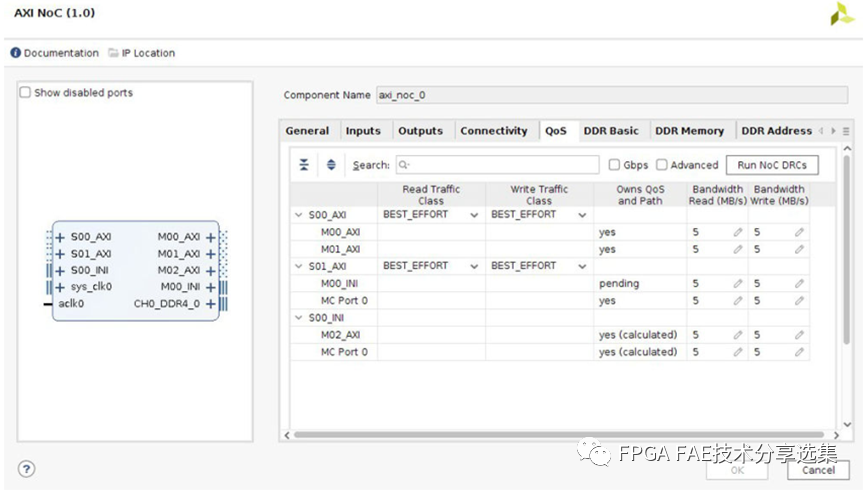
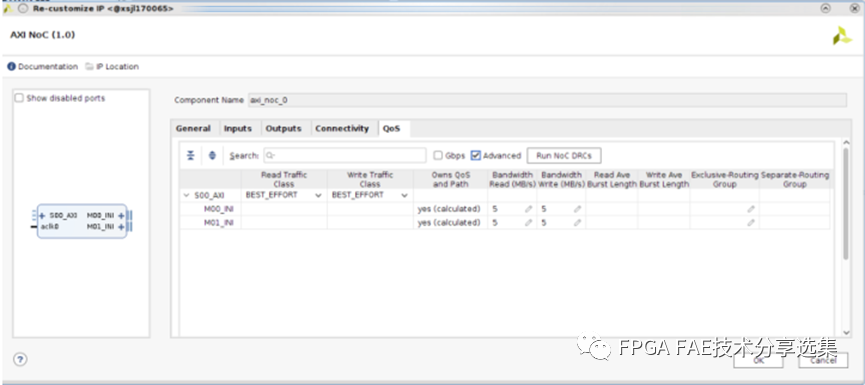
A. QoS選項卡的第一列顯示了定義的連接的樹形結構連接選項卡;每個樹的頂部(左對齊的端口名稱)是NoC入口端口;每個入口端口下面顯示的是相關行對于每個連接的出口端口。
B. 第二列定義讀流量的分類:取值為LOW_LATENCY和BEST_EFFORT(默認),流量類適用于所有連接源自給定的入口端口;
C. 第三列定義寫流量類別,取值包括ISOCHRONOUS和BEST_EFFORT,寫流量不支持LOW_LATENCY,寫流量類適用于從給定入口端口發(fā)起的所有連接;
D. 第四列表示該NoC實例是否擁有給定路徑的QoS設置:NoC路徑可以使用INI遍歷多個NoC實例,QoS設置取自擁有QoS和路徑的NoC實例,當NoC實例不擁有QoS時,QoS將被忽略的路徑,所有權正處于從NMU或strategy=Driver者到NSU, MC,或strategy=Load,如果值為“pending”,則表示在此期間將計算所有權驗證,或單擊上面的Run NoC drc按鈕,對于值“error”,請驗證或單擊單擊上面的Run NoC drc按鈕,在Tcl控制臺和消息窗口中查看錯誤詳細信息;
E. 第五列為讀帶寬,單位為MB/s,允許取值范圍為0 (不接受讀流量)到NoC物理通道的最大數據帶寬;
F. 第六列為寫帶寬,單位為MB/s,允許的值范圍從0(不接受寫流量)到NoC物理通道的最大數據帶寬;
擁有QoS和路徑:
NoC路徑可以使用INI遍歷多個NoC實例,QoS設置取自擁有QoS和Path的NoC實例,當NoC不擁有QoS時,將忽略QoS路徑;所有權處于從NMU或strategy=Driver程序到NSU, MC或的過渡階段strategy=Load,值“pending”意味著所有權將在驗證期間計算,或者通過單擊運行上面的NoC DRCs按鈕,若值為“error”,請驗證或單擊“Run NoC drc”按鈕在Tcl控制臺和消息窗口中查看錯誤詳細信息。
注意:如果“擁有QoS”和“路徑”為“否”,則所有設置BW和流量分類將被忽略。
運行NoC drc:
在整個設計中運行NoC drc,錯誤會在Tcl控制臺和消息窗口中列出,通過計算所有權來更新'Owns QoS'列中的'pending'條目設計,NoC路徑可以使用INI遍歷多個NoC實例,采取QoS設置從擁有QoS和Path的NoC實例獲取,當NoC沒有忽略QoS時,QoS將被忽略擁有這條路徑;所有權正處于從NMU或strategy=Driver者到NSU, MC,或strategy=Load。
對于Address Remap頁面來說主要是配置輸入輸出的地址映射關系,有一些地址規(guī)則會詳細說明,Address Remap頁面如下圖所示:
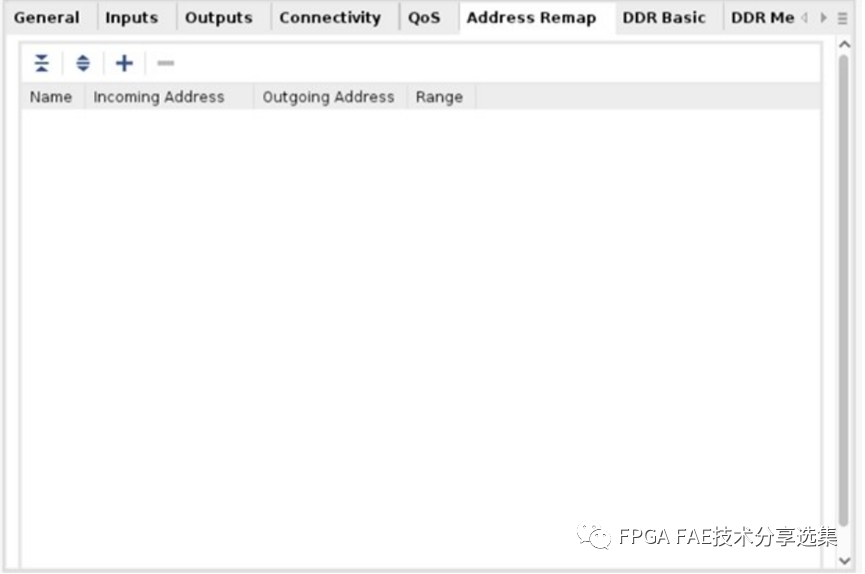
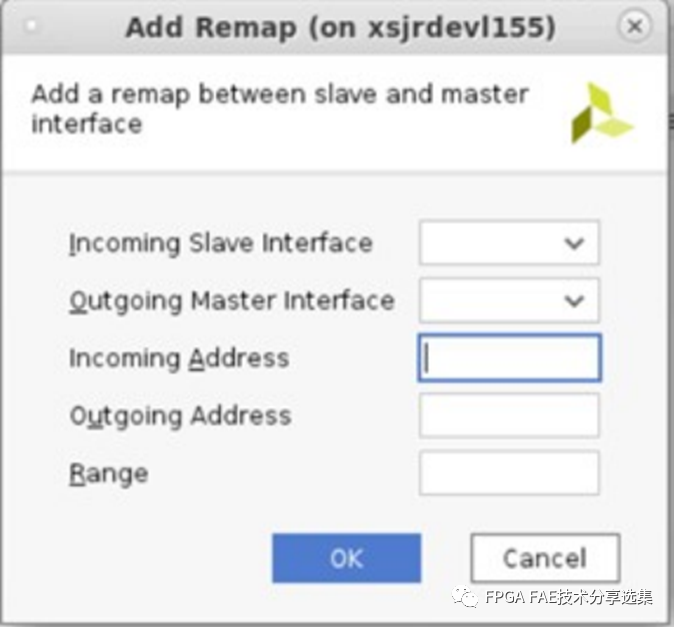
A. IncomingSlave Interface:從下拉菜單中選擇從端口(NMU)存在需要重新映射的傳入地址;
B. 出主接口:從下拉菜單中選擇主接口(NSU)輸出重新映射的地址;
C. 入站地址:從站發(fā)送的起始地址,需要重新映射;
D. 發(fā)送地址:發(fā)送地址為映射后的地址,這是第一個地址在重新映射開始的地方;
E. 范圍:要訪問的地址空間的總范圍;
F. 重新映射規(guī)則:
? 范圍必須最小為64K,必須為2的整數次方;
? 范圍內的入地址位必須為零:incoming_address& (range-1)== 0;
? 示例:對于由主控機尋址的32位4G范圍;
? 輸出地址范圍內的位必須為零:output_address& (range-1) == 0;
四、DDR4/LPDDR4 NoC IP實戰(zhàn)
在 Versal新一代ACAP器件上,除了延續(xù)之前Ultrascale/Ultrascale+系列器件上已有的DDR4IP之外,還配置了最新的DDR4/LPDDR4 硬核控制器(NoC IP)。它的性能更高,并且不額外占用其他的可編程邏輯資源(PL),使用它的時候,在硬件設計方面和設計流程上,和之前的軟核控制器(DDR4 IP)也有著很大的不同。今天我們來介紹一下I/O planning方面的設計考慮和實現流程。
我們首先要新建一個工程并添加CISP IP core,這樣我們才能順利的開始block design的設計工作。
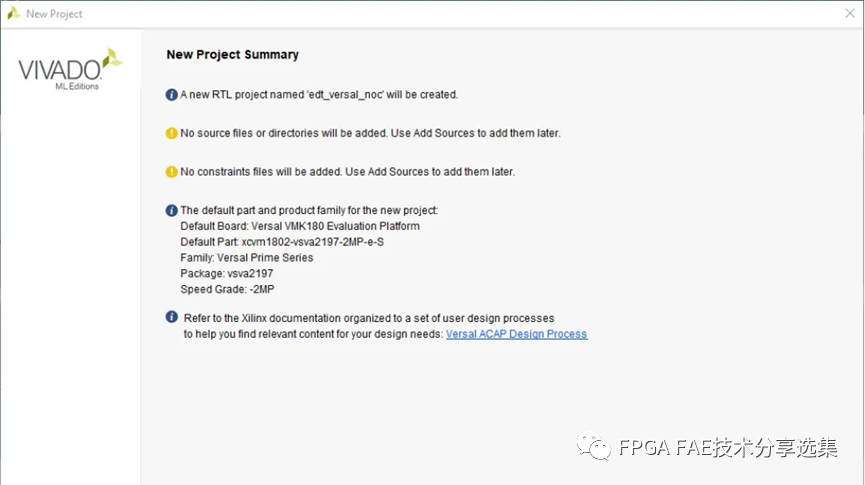
新建如圖基于VMK180的vivado工程'edt_versal_noc':
新建一個BlockDesign,這里我們添加CISP ip core (系統(tǒng)默認為versal_cips_0),并且run design automation讓vivado對ip核做自動初始化。這里我們使用CISP IP的默認配置,不進行更改。
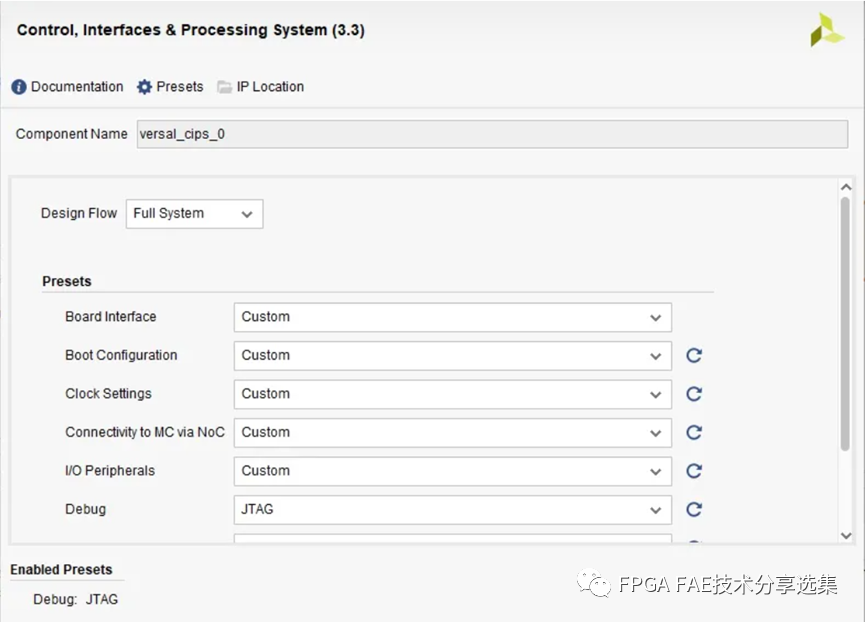
自動化后雙擊versal_cips_0框圖,進入Re-customize IP向導,將Board Interface設置成Custom, 如圖所示:
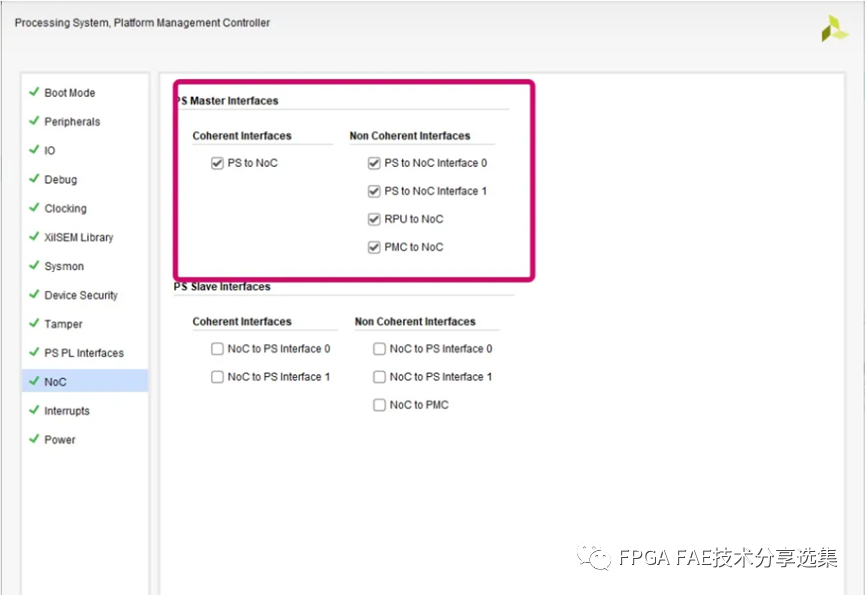
雙擊CIPS打開配置向導找到PS PMC配置NoC頁, 啟動PS Master Interfaces如圖所示:
最后點擊Finish更新CIPS的配置。
接著添加另外一個IP核 AXI NoC,RunBlock Automation, 配置如下:
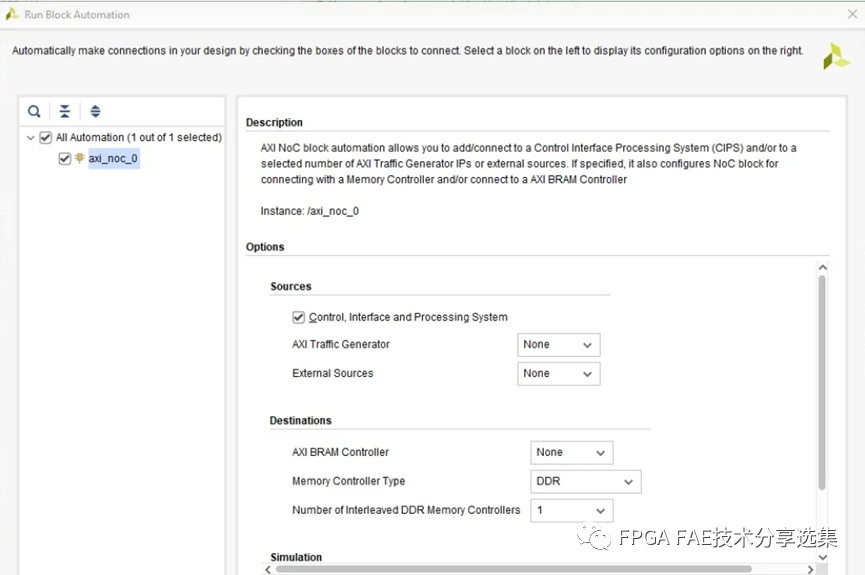
在block design中添加NoC IP。
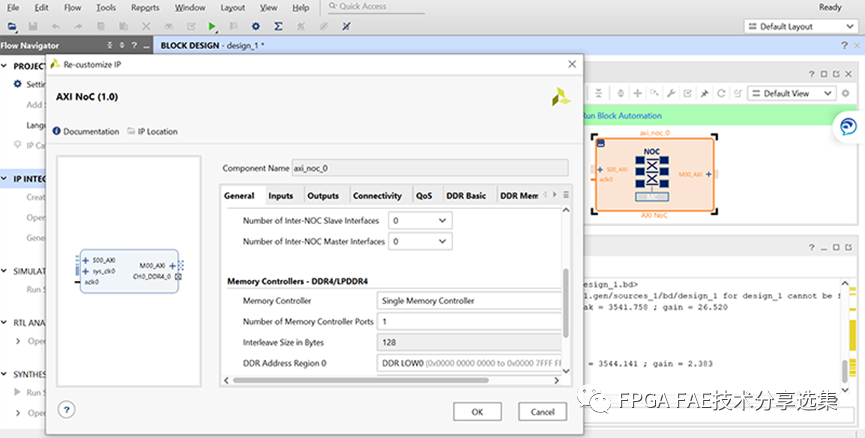
在IP wizard中,根據memory 容量,位寬,帶寬等要求完成相關配置。
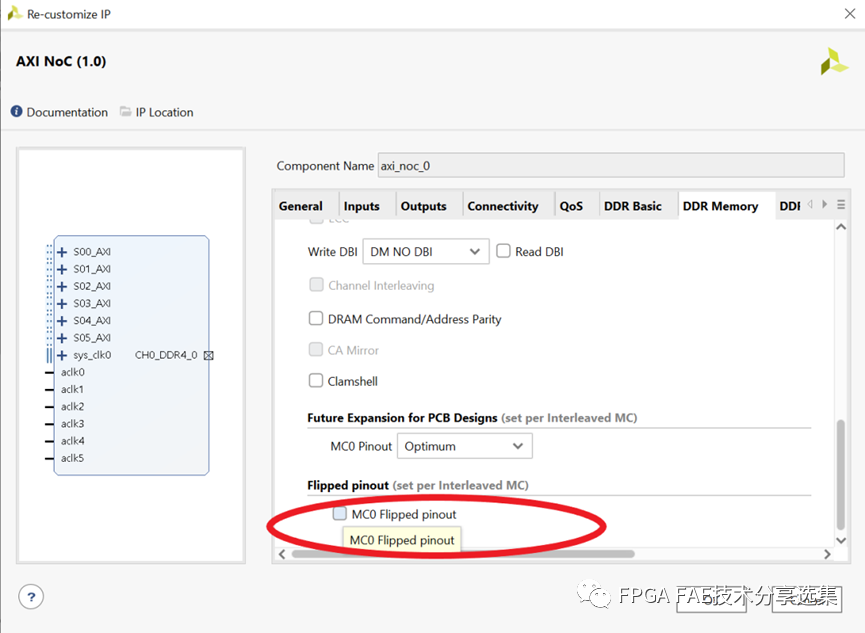
總體上來講,DDR4/LPDDR4的管腳有2種分配模式—Flipped和Non-flipped,模式的選擇可以通過使能或者關閉NoC IP中 “Flipped pinout”的選項來實現。
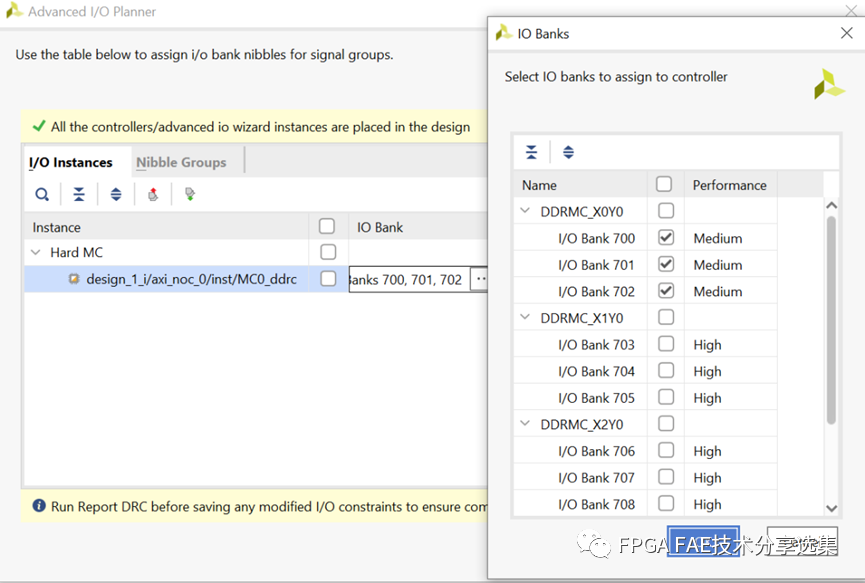
Versal器件上每個NoC IP對應3個IO bank的管腳,它們都位于同一個triplet之中。一個NoC IP對應的所有DDR4/LPDDR4接口管腳都必須放置在這3個IO bank之中。在對block design進行綜合之后,打開synthesized design,在I/O ports窗口中點擊 “Open advanced I/O planner” ,按照bank或者nibble為單位指定所有管腳的位置。
在此之后,地址、控制和時鐘管腳的位置就被固定了下來。數據管腳在Byte以內和Byte之間可以進行微調,這樣一個NoC的block design實例工程就搭建完成了。
審核編輯:湯梓紅
-
FPGA
+關注
關注
1629文章
21729瀏覽量
602993 -
amd
+關注
關注
25文章
5466瀏覽量
134089 -
計算機
+關注
關注
19文章
7488瀏覽量
87849 -
NoC
+關注
關注
0文章
38瀏覽量
11734 -
Versal
+關注
關注
1文章
158瀏覽量
7658
發(fā)布評論請先 登錄
相關推薦
AMD Versal系列CIPS IP核建立示例工程
AMD Versal AI Edge自適應計算加速平臺之Versal介紹(2)
【ALINX 技術分享】AMD Versal AI Edge 自適應計算加速平臺之 Versal 介紹(2)
AMD Versal AI Edge自適應計算加速平臺之PL通過NoC讀寫DDR4實驗(4)

技術文章:如何利用NoC來進行FPGA內部邏輯的互連
怎么構建一種基于FPGA的NoC驗證平臺?
基于FPGA的NoC多核處理器的設計
采用FPGA的NoC驗證平臺實現方案
Versal系列芯片三個產品的基礎知識
在Versal中通過NoC從PS-APU對AXI BRAM執(zhí)行基本讀寫操作
如何通過NoC 從 Versal應用處理單元訪問AXI BRAM
AMD Versal系列FPGA NoC介紹及實戰(zhàn)






 工商網監(jiān)
工商網監(jiān)
評論