") GPU巨頭,拼什么?
GPU巨頭,拼什么?
在 GPU 領(lǐng)域,2022 年無(wú)論好壞都是一個(gè)重要的里程碑。英特爾兌現(xiàn)了重新進(jìn)入獨(dú)立顯卡市場(chǎng)的承諾,Nvidia將顯卡尺寸和價(jià)格推向了頂峰,AMD將 CPU 技術(shù)帶入了顯卡領(lǐng)域。
圍繞 GPU 的熱情彌漫在在線論壇中,讓 PC 愛好者對(duì)顯卡市場(chǎng)的轉(zhuǎn)變感到既敬畏又震驚。在這種喧囂中,人們很容易忘記最新的產(chǎn)品配備了家用電腦中最復(fù)雜、最強(qiáng)大的芯片。
在本文中,我們將深入探討他們的架構(gòu)。讓我們剝開層層,看看有什么新內(nèi)容、它們有什么共同點(diǎn),以及這些對(duì)普通用戶意味著什么。
GPU整體結(jié)構(gòu):從上到下
讓我們從本文的一個(gè)重要方面開始——這不是性能比較。相反,我們正在研究 GPU 內(nèi)部的所有內(nèi)容是如何排列的,檢查規(guī)格和數(shù)據(jù),以了解 AMD、英特爾和 Nvidia 在設(shè)計(jì)圖形處理器時(shí)所采用的方法差異。
我們將首先了解使用我們正在研究的架構(gòu)的最大可用芯片的整體 GPU 組成。需要強(qiáng)調(diào)的是,英特爾的產(chǎn)品并不針對(duì)與 AMD 或 Nvidia 相同的市場(chǎng),因?yàn)樗诤艽蟪潭壬鲜且豢钪袡n圖形處理器。
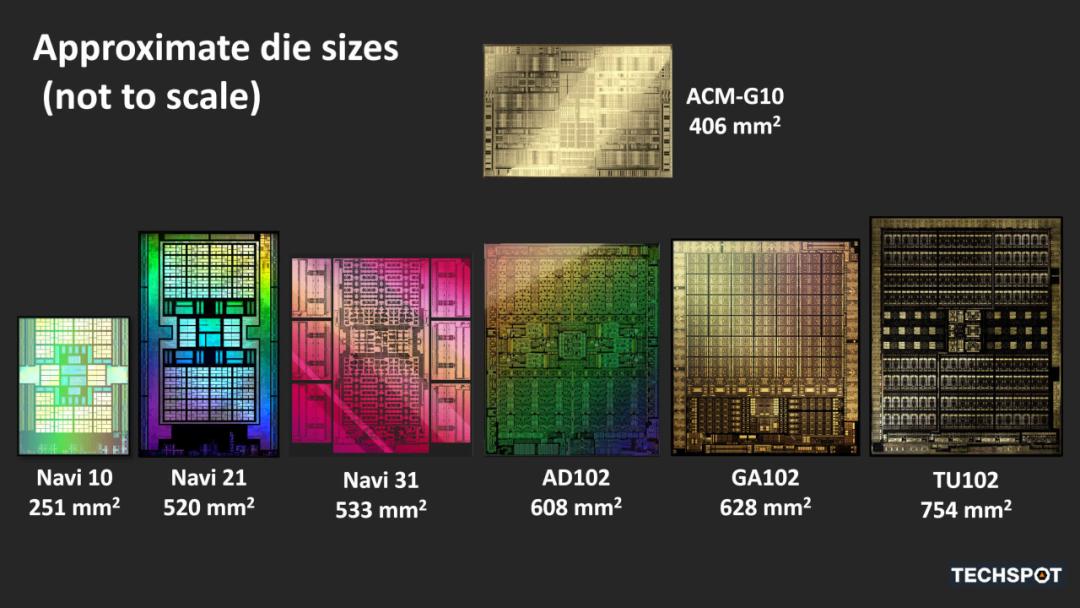
這三者的尺寸不僅彼此不同,而且與使用先前架構(gòu)的類似芯片也有很大不同。所有這些分析純粹是為了了解這三個(gè)處理器的底層到底是什么。在分解每個(gè) GPU 的基本部分(著色器核心、光線追蹤功能、內(nèi)存層次結(jié)構(gòu)以及顯示和媒體引擎)之前,我們將檢查整體結(jié)構(gòu)。
一、AMD Navi 31
按字母順序排列,第一個(gè)出現(xiàn)的是 AMD 的 Navi 31,這是他們迄今為止發(fā)布的最大的 RDNA 3 芯片。與 Navi 21 相比,我們可以看到他們之前的高端 GPU 的組件數(shù)量明顯增長(zhǎng)......
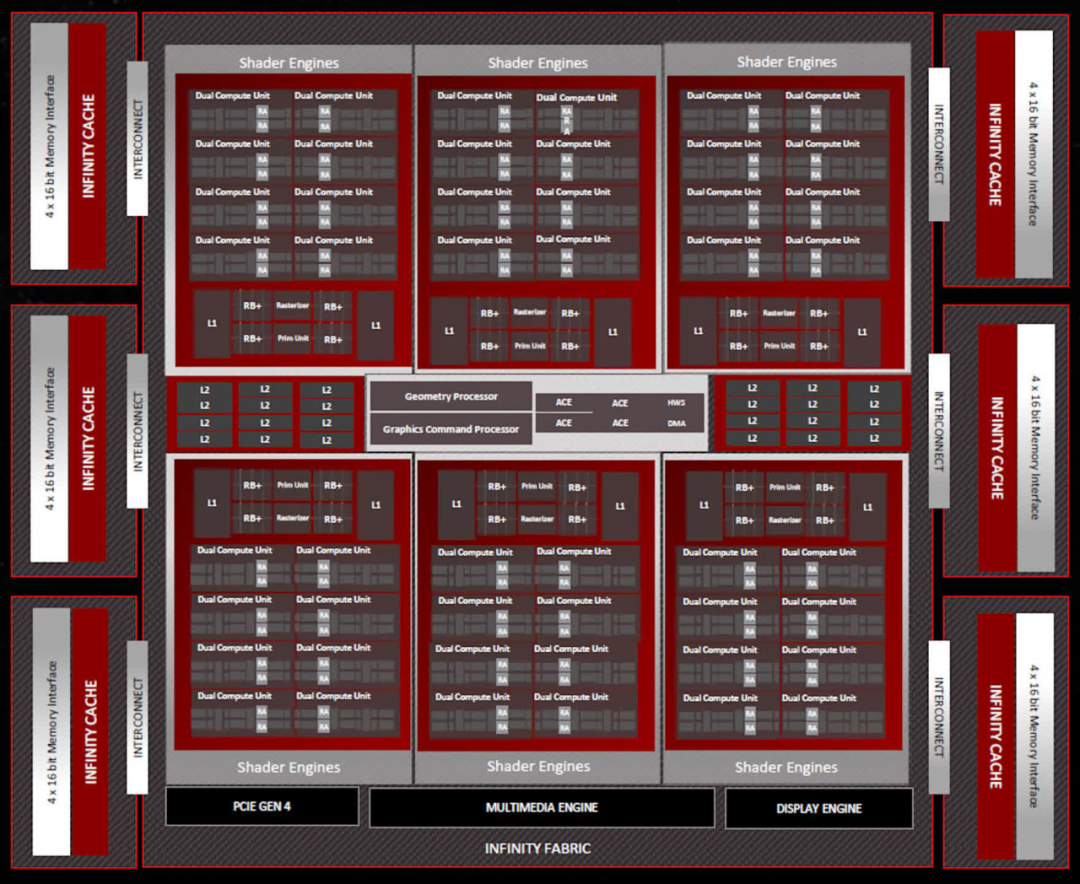
著色器引擎 (SE:Shader Engines) 容納的計(jì)算單元 (CU:Compute Units) 較少,為 16 個(gè),而不是 200 個(gè),但現(xiàn)在總共有 6 個(gè) SE,比以前多了兩個(gè)。這意味著Navi 31擁有多達(dá)96個(gè)CU,總共配備6144個(gè)流處理器(SP:Stream Processors)。AMD 已經(jīng)對(duì) RDNA 3 的 SP 進(jìn)行了全面升級(jí),我們將在后面討論。
每個(gè)著色器引擎還包含一個(gè)處理光柵化( rasterization)的專用單元、一個(gè)用于三角形( triangle )設(shè)置的圖元引擎(primitive engine )、32 個(gè)渲染輸出單元 (ROP:render output units) 和兩個(gè) 256kB L1 緩存。最后一個(gè)方面現(xiàn)在大小增加了一倍,但每個(gè) SE 的 ROP 計(jì)數(shù)仍然相同。
AMD 也沒有對(duì)光柵器( rasterizer )和原始引擎(primitive engines)進(jìn)行太大改變——所稱的 50% 改進(jìn)是針對(duì)整個(gè)芯片進(jìn)行的,因?yàn)樗?SE 比 Navi 21 芯片多了 50%。然而,SE 處理指令的方式發(fā)生了變化,例如更快地處理多個(gè)繪制命令(multiple draw commands)和更好地管理管道階段( pipeline stages),這應(yīng)該會(huì)減少 CU 在繼續(xù)執(zhí)行另一個(gè)任務(wù)之前需要等待的時(shí)間。
最明顯的變化是在 11 月發(fā)布之前引起最多謠言和八卦的變化——GPU 封裝的小芯片方法。憑借在該領(lǐng)域多年的經(jīng)驗(yàn),AMD 選擇這樣做在某種程度上是合乎邏輯的,但這完全是出于成本/制造原因,而不是性能。
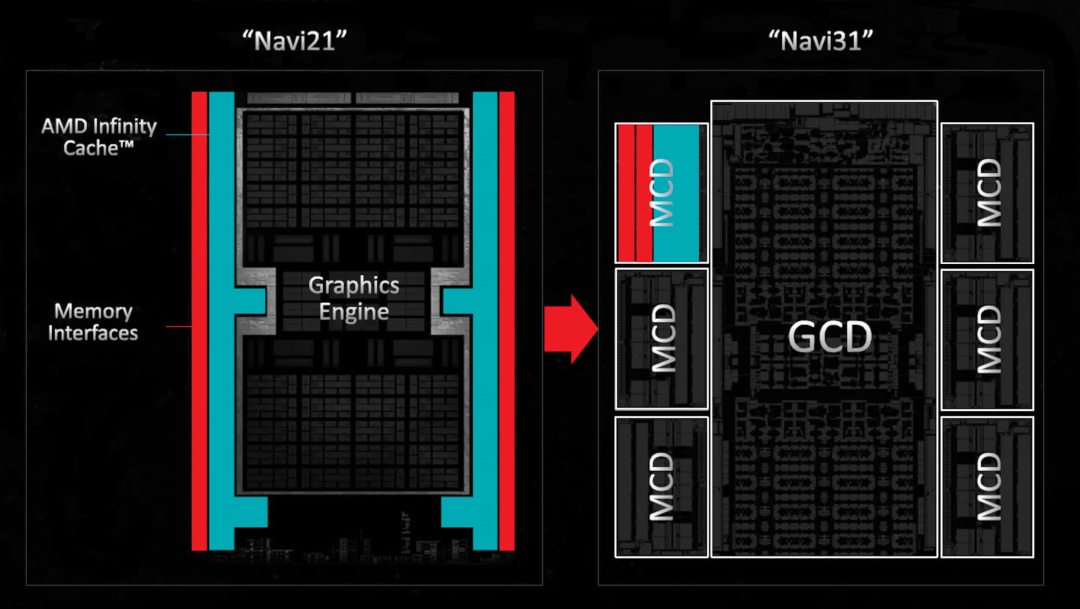
我們將在本文后面更詳細(xì)地討論這一點(diǎn),所以現(xiàn)在我們只關(guān)注哪些部分在哪里。在 Navi 31 中,最終層緩存的內(nèi)存控制器及其相關(guān)分區(qū)位于主處理器(GCD,Graphics Compute Die)周圍的單獨(dú)小芯片(稱為 MCD 或Memory Cache Dies)中。
由于需要提供更多數(shù)量的 SE,AMD 也將 MC 數(shù)量增加了 50%,因此 GDDR6 全局內(nèi)存的總總線寬度現(xiàn)在為 384 位。這次 Infinity Cache 總量減少了(96MB vs 128MB),但更大的內(nèi)存帶寬抵消了這一點(diǎn)。
二、英特爾ACM-G10
接下來(lái)是 Intel 和 ACM-G10 芯片(以前稱為 DG2-512)。雖然這不是英特爾生產(chǎn)的最大的 GPU,但它是他們最大的消費(fèi)類圖形芯片。
該框圖是相當(dāng)標(biāo)準(zhǔn)的排列,盡管看起來(lái)更類似于 Nvidia 的而不是 AMD 的。共有 8 個(gè)渲染切片(Render Slices),每個(gè)渲染切片包含 4 個(gè) Xe 核心,總共 512 個(gè)矢量引擎(Vector Engines:相當(dāng)于 AMD 的流處理器和 Nvidia 的 CUDA 核心 )。

每個(gè)渲染切片中還包含一個(gè)基元單元、光柵器、深度緩沖處理器、32 個(gè)紋理單元和 16 個(gè) ROP。乍一看,這款 GPU 似乎相當(dāng)大,因?yàn)?256 個(gè) TMU 和 128 個(gè) ROP 比 Radeon RX 6800 或 GeForce RTX 2080 中的數(shù)量還要多。
然而,AMD 的 RNDA 3 芯片擁有 96 個(gè)計(jì)算單元,每個(gè)計(jì)算單元有 128 個(gè) ALU,而 ACM-G10 總共有 32 個(gè) Xe 核心,每個(gè)核心有 128 個(gè) ALU。因此,僅就 ALU 數(shù)量而言,英特爾 Alchemist 驅(qū)動(dòng)的 GPU 的大小是 AMD 的三分之一。但正如我們稍后將看到的,ACM-G10 的大部分芯片都交給了不同的數(shù)字處理單元。
與英特爾通過(guò) OEM 供應(yīng)商發(fā)布的首款 Alchemist GPU相比,該芯片在組件數(shù)量和結(jié)構(gòu)排列方面具備成熟架構(gòu)的所有特征。
我們完成了對(duì) Nvidia AD102 不同布局的開場(chǎng)概述,這是他們第一個(gè)使用 Ada Lovelace 架構(gòu)的 GPU。與它的前身Ampere GA102相比,它看起來(lái)并沒有什么不同,只是大了很多。就所有意圖和目的而言,確實(shí)如此。
Nvidia 使用圖形處理集群 (GPU:Graphics Processing Cluster) 的組件層次結(jié)構(gòu),其中包含 6 個(gè)紋理處理集群 (TPC:Texture Processing Clusters),每個(gè)集群包含 2 個(gè)流式多處理器 (SM)。這種安排對(duì)于Ada來(lái)說(shuō)并沒有改變,但總數(shù)肯定已經(jīng)改變了……
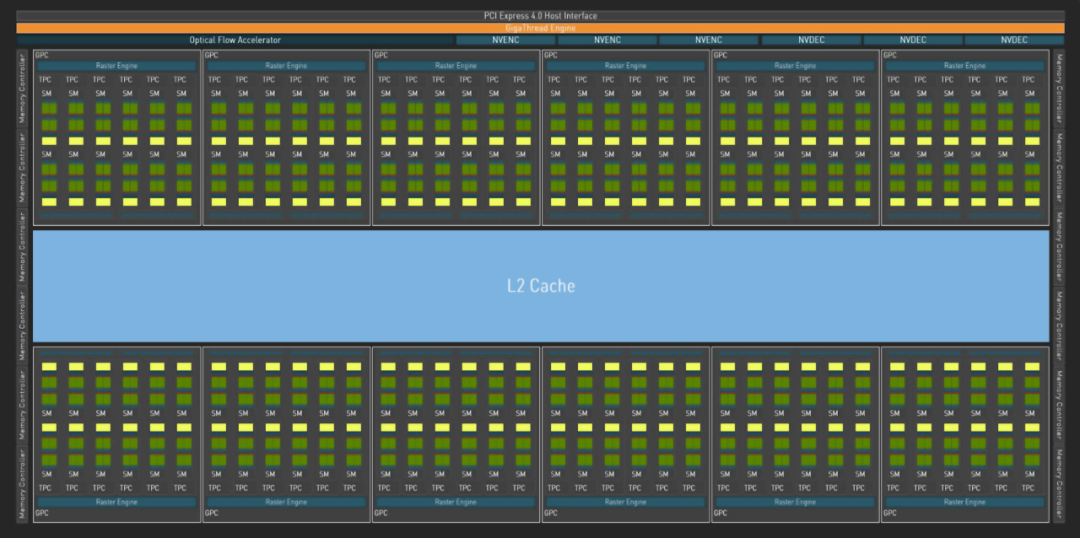
在完整的 AD102 芯片中,GPC 數(shù)量從 7 個(gè)增加到 12 個(gè),因此現(xiàn)在總共有 144 個(gè) SM,總共有 18432 個(gè) CUDA 核心。與 Navi 31 中的 6144 個(gè) SP 相比,這個(gè)數(shù)字似乎高得離譜,但 AMD 和 Nvidia 對(duì)其組件的計(jì)數(shù)方式不同。
雖然這大大簡(jiǎn)化了問(wèn)題,但 1 個(gè) Nvidia SM 相當(dāng)于 1 個(gè) AMD CU——兩者都包含 128 個(gè) ALU。因此,Navi 31 的尺寸是英特爾 ACM-G10 的兩倍(僅 ALU 數(shù)量),而 AD102 的尺寸是英特爾 ACM-G10 的 3.5 倍。
這就是為什么當(dāng)芯片在規(guī)模上有如此明顯的差異時(shí),對(duì)它們進(jìn)行任何直接的性能比較是不公平的。然而,一旦它們進(jìn)入顯卡、定價(jià)并上市,那么情況就不同了。
但我們可以比較的是三個(gè)處理器中最小的重復(fù)部分。
著色器核心(Shader Cores):
走進(jìn) GPU 的大腦
從整個(gè)處理器的概述開始,現(xiàn)在讓我們深入了解芯片的核心,看看處理器的基本數(shù)字處理部分:著色器核心。
這三個(gè)制造商在描述他們的芯片時(shí)使用不同的術(shù)語(yǔ)和短語(yǔ),特別是在概述圖時(shí)。因此,在本文中,我們將使用我們自己的圖像,具有常見的顏色和結(jié)構(gòu),以便更容易看出相同和不同之處。
一、AMD RDNA 3
AMD GPU 著色部分內(nèi)最小的統(tǒng)一結(jié)構(gòu)稱為雙計(jì)算單元(DCU:Double Compute Unit)。在某些文檔中,它仍然稱為工作組處理器 (WGP:Workgroup Processor),而其他文檔則將其稱為計(jì)算單元對(duì)(CUP:Compute Unit Pair)。
請(qǐng)注意,如果這些圖中未顯示某些內(nèi)容(例如常量緩存、雙精度單元),并不意味著它們不存在于體系結(jié)構(gòu)中。
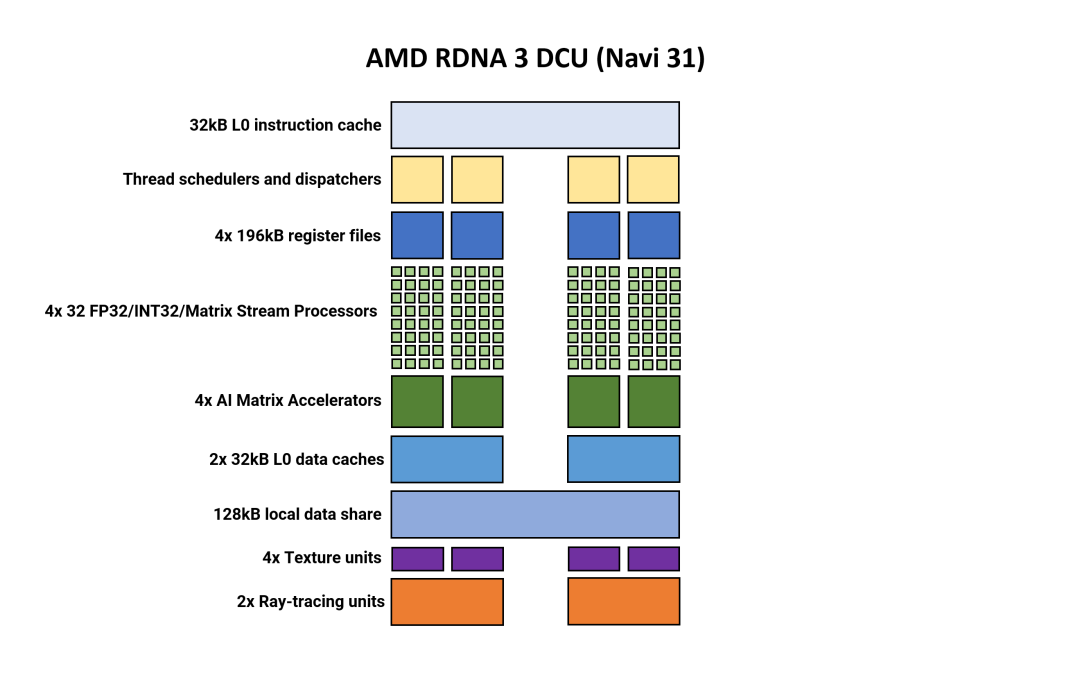
在很多方面,整體布局和結(jié)構(gòu)元素與 RDNA 2 相比并沒有太大變化。兩個(gè)計(jì)算單元共享一些緩存和內(nèi)存,每個(gè)計(jì)算單元包含兩組 32 個(gè)流處理器 (SP)。
第 3 版的新增功能是,每個(gè) SP 現(xiàn)在容納的算術(shù)邏輯單元 (ALU:arithmetic logic units ) 數(shù)量是以前的兩倍。現(xiàn)在,每個(gè) CU 有兩組 SIMD64 單元,每個(gè)組有兩個(gè)數(shù)據(jù)端口——一個(gè)用于浮點(diǎn)、整數(shù)和矩陣運(yùn)算,另一個(gè)僅用于浮點(diǎn)和矩陣運(yùn)算。
AMD 確實(shí)針對(duì)不同的數(shù)據(jù)格式使用單獨(dú)的 SP, RDNA 3 中的計(jì)算單元支持使用 FP16、BF16、FP32、FP64、INT4、INT8、INT16 和 INT32 值進(jìn)行操作。
使用 SIMD64 意味著每個(gè)線程調(diào)度程序可以在每個(gè)時(shí)鐘周期發(fā)出一組 64 個(gè)線程(稱為wavefront),或者可以共同發(fā)出兩個(gè) 32 個(gè)線程的波前。AMD 保留了與以前的 RDNA 架構(gòu)相同的指令規(guī)則,因此這是由 GPU/驅(qū)動(dòng)程序處理的。
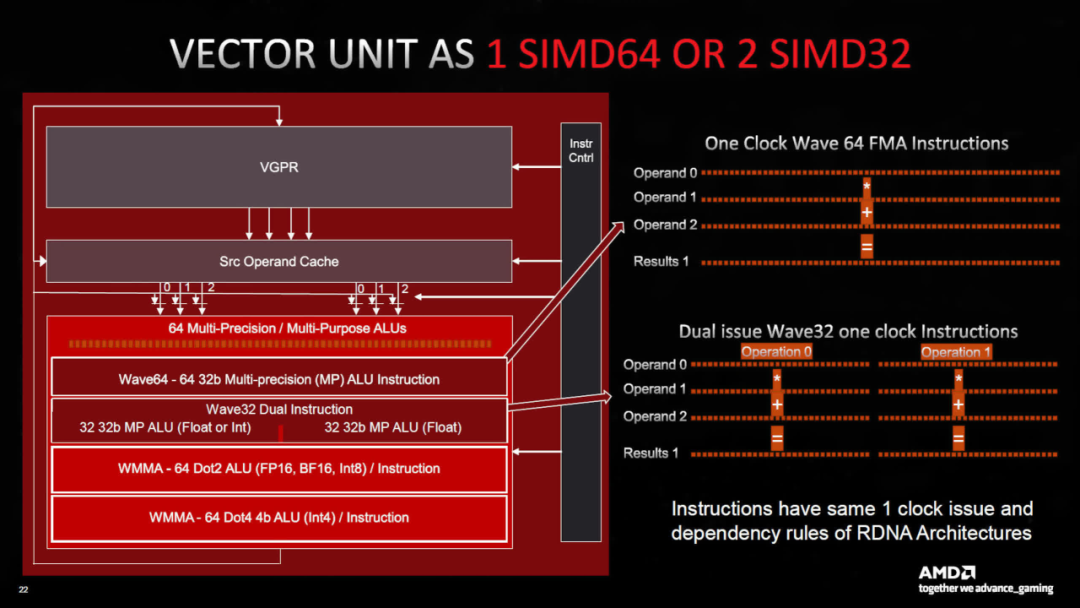
另一個(gè)重要的新功能是 AMD 所謂的 AI 矩陣加速器的出現(xiàn)。
與我們很快就會(huì)看到的 Intel 和 Nvidia 的架構(gòu)不同,它們并不充當(dāng)單獨(dú)的單元——所有矩陣運(yùn)算都利用 SIMD 單元,并且任何此類計(jì)算(稱為波矩陣乘法累加,WMMA:Wave Matrix Multiply Accumulate)都將使用完整的 64 個(gè) ALU 組。
在撰寫本文時(shí),人工智能加速器的確切性質(zhì)尚不清楚,但它可能只是與處理指令和涉及的大量數(shù)據(jù)相關(guān)的電路,以確保最大吞吐量。它很可能與 Nvidia 的Hopper 架構(gòu)中的張量?jī)?nèi)存加速器具有類似的功能。
與 RDNA 2 相比,變化相對(duì)較小——較舊的架構(gòu)還可以處理 64 個(gè)線程波前(又名 Wave64),但這些是在兩個(gè)周期內(nèi)發(fā)布的,并且在每個(gè)計(jì)算單元中使用兩個(gè) SIMD32 塊。現(xiàn)在,這一切都可以在一個(gè)周期內(nèi)完成,并且僅使用一個(gè) SIMD 塊。
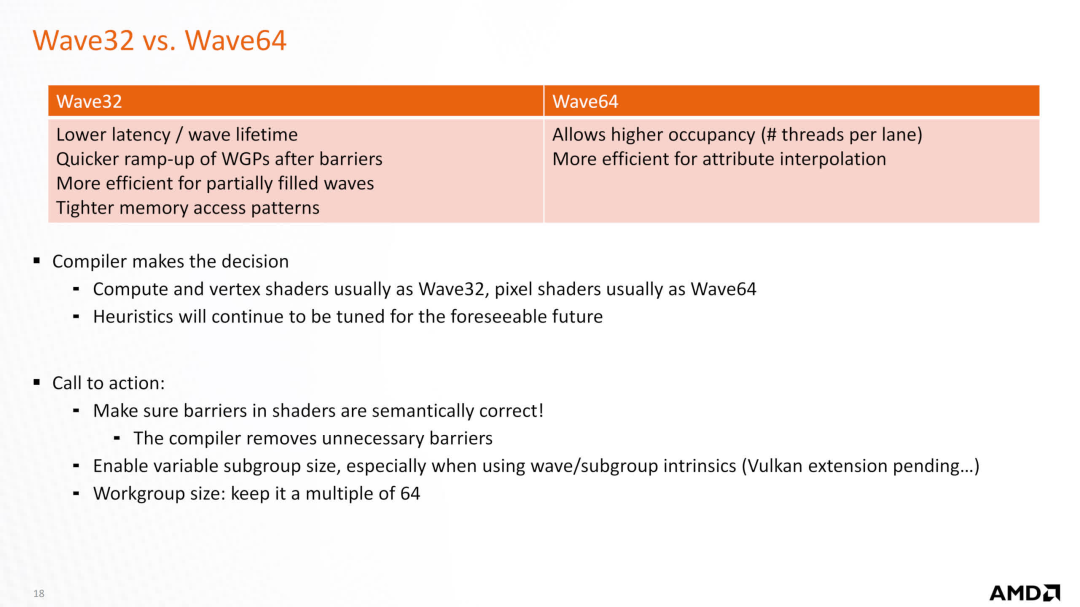
在之前的文檔中,AMD 表示 Wave32 通常用于計(jì)算和頂點(diǎn)著色器(也可能用于光線著色器),而 Wave 64 主要用于像素著色器,驅(qū)動(dòng)程序會(huì)相應(yīng)地編譯著色器。因此,轉(zhuǎn)向單周期 Wave64 指令問(wèn)題將為嚴(yán)重依賴像素著色器的游戲帶來(lái)推動(dòng)。
然而,所有這些額外的可用功率都需要正確利用才能充分利用。所有 GPU 架構(gòu)都是如此,并且它們都需要大量線程負(fù)載,才能做到這一點(diǎn)(這也有助于隱藏與 DRAM 相關(guān)的固有延遲)。
因此,隨著 ALU 數(shù)量增加一倍,AMD 推動(dòng)了程序員盡可能使用指令級(jí)并行性的需求。這在圖形領(lǐng)域并不是什么新鮮事,但 RDNA 相對(duì)于 AMD 舊的 GCN 架構(gòu)的一個(gè)顯著優(yōu)勢(shì)是,它不需要那么多的運(yùn)行線程來(lái)達(dá)到充分利用。鑒于現(xiàn)代渲染在游戲中變得多么復(fù)雜,開發(fā)人員在編寫著色器代碼時(shí)需要做更多的工作。
二、Intel Alchemist
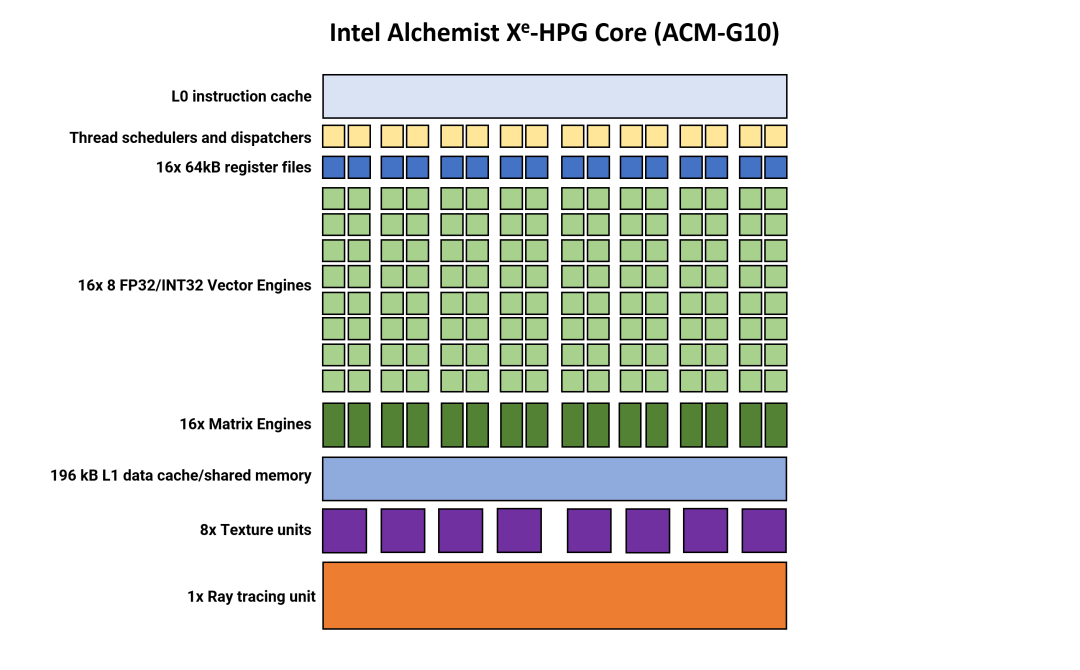
現(xiàn)在讓我們轉(zhuǎn)向英特爾,看看 Alchemist 架構(gòu)中的 DCU 等效項(xiàng),稱為Xe Core(我們將其縮寫為 XEC)。乍一看,與 AMD 的結(jié)構(gòu)相比,這些看起來(lái)絕對(duì)是巨大的。
RDNA 3 中的單個(gè) DCU 包含四個(gè) SIMD64 塊,而英特爾的 XEC 包含16 個(gè)SIMD8 單元,每個(gè)單元都由自己的線程調(diào)度程序和調(diào)度系統(tǒng)管理。與 AMD 的流處理器一樣,Alchemist 中所謂的矢量引擎可以處理整數(shù)和浮點(diǎn)數(shù)據(jù)格式。不支持 FP64,但這在游戲中不是什么大問(wèn)題。
英特爾一直使用相對(duì)較窄的 SIMD——Gen11 中使用的 SIMD 僅為 4 寬(即同時(shí)處理 4 個(gè)線程),而 Gen 12 的寬度僅加倍(例如,在其 Rocket Lake CPU 中使用)。
但考慮到游戲行業(yè)已經(jīng)使用 SIMD32 GPU 多年,因此游戲也進(jìn)行了相應(yīng)的編碼,因此保留狹窄執(zhí)行塊的決定似乎會(huì)適得其反。
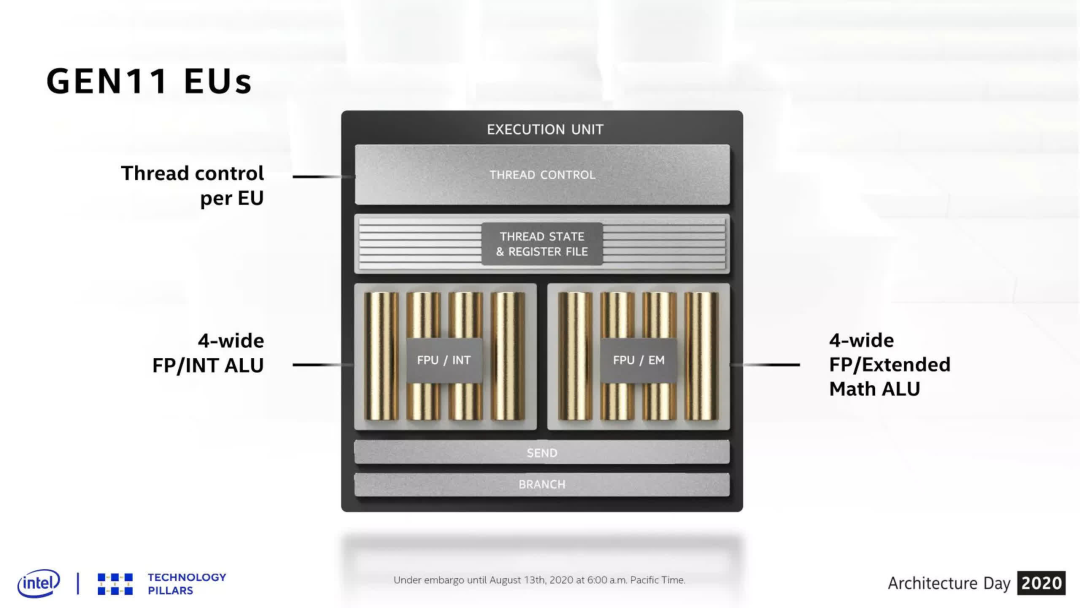
AMD 的 RDNA 3 和 Nvidia 的 Ada Lovelace 的處理塊可以在一個(gè)周期內(nèi)發(fā)出 64 或 32 個(gè)線程,而英特爾的架構(gòu)需要 4 個(gè)周期才能在一個(gè) VE 上實(shí)現(xiàn)相同的結(jié)果,因此每個(gè) XEC 有 16 個(gè) SIMD 單元。
然而,這意味著如果游戲的編碼方式不能確保 VE 被完全占用,SIMD 和相關(guān)資源(緩存、帶寬等)將處于閑置狀態(tài)。英特爾Arc 系列顯卡的基準(zhǔn)測(cè)試結(jié)果的一個(gè)共同主題是,它們往往在更高的分辨率和/或具有大量復(fù)雜的現(xiàn)代著色器例程的游戲中表現(xiàn)更好。
這在一定程度上是由于單位細(xì)分和資源共享程度較高。Chips and Cheese網(wǎng)站的微基準(zhǔn)分析表明,盡管擁有豐富的 ALU,該架構(gòu)仍難以實(shí)現(xiàn)適當(dāng)?shù)睦谩?/p>
轉(zhuǎn)到 XEC 的其他方面,尚不清楚 0 級(jí)指令緩存有多大,但 AMD 的指令緩存是 4 路(因?yàn)樗?wù)于四個(gè) SIMD 塊),而 Intel 的緩存必須是 16 路,這增加了復(fù)雜性緩存系統(tǒng)的。
英特爾還選擇為處理器提供用于矩陣運(yùn)算的專用單元,每個(gè)向量引擎對(duì)應(yīng)一個(gè)單元。擁有如此多的單元意味著芯片的很大一部分專門用于處理矩陣數(shù)學(xué)。

AMD 使用 DCU 的 SIMD 單元來(lái)完成此操作,而 Nvidia 每個(gè) SM 有四個(gè)相對(duì)較大的張量/矩陣單元,而英特爾的方法似乎有點(diǎn)過(guò)分,因?yàn)樗麄冇幸粋€(gè)單獨(dú)的架構(gòu),稱為 X e-HP,用于計(jì)算應(yīng)用程序。
另一個(gè)奇怪的設(shè)計(jì)似乎是處理塊中的加載/存儲(chǔ)(LD/ST)單元。我們的圖表中未顯示,它們管理來(lái)自線程的內(nèi)存指令,在寄存器文件和 L1 緩存之間移動(dòng)數(shù)據(jù)。Ada Lovelace 與 Ampere 相同,每個(gè) SM 分區(qū)有 4 個(gè),總共 16 個(gè)。RDNA 3 也與其前身相同,每個(gè) CU 都有專用的 LD/ST 電路作為紋理單元的一部分。
英特爾的 Xe-HPG 演示顯示每個(gè) XEC 僅一個(gè) LD/ST,但實(shí)際上,它內(nèi)部可能由更多分立單元組成。然而,在他們的OneAPI優(yōu)化指南中,一張圖表表明 LD/ST 一次循環(huán)一個(gè)單獨(dú)的寄存器文件。如果是這種情況,那么 Alchemist 將始終難以實(shí)現(xiàn)最大緩存帶寬效率,因?yàn)椴⒎撬形募纪瑫r(shí)得到服務(wù)。
三、Nvidia Ada Lovelace
最后一個(gè)需要關(guān)注的處理模塊是 Nvidia 的流式多處理器(SM:Streaming Multiprocessor ) – DCU/XEC 的 GeForce 版本。這個(gè)結(jié)構(gòu)與2018年的圖靈架構(gòu)相比并沒有太大的改變。事實(shí)上,它幾乎與Ampere相同。
一些單元已經(jīng)過(guò)調(diào)整以提高其性能或功能集,但在大多數(shù)情況下,沒有太多新的東西可以談?wù)摗J聦?shí)上,可能有,但眾所周知,英偉達(dá)不愿透露太多有關(guān)其芯片的內(nèi)部操作和規(guī)格的信息。英特爾提供了更多細(xì)節(jié),但這些信息通常隱藏在其他文檔中。
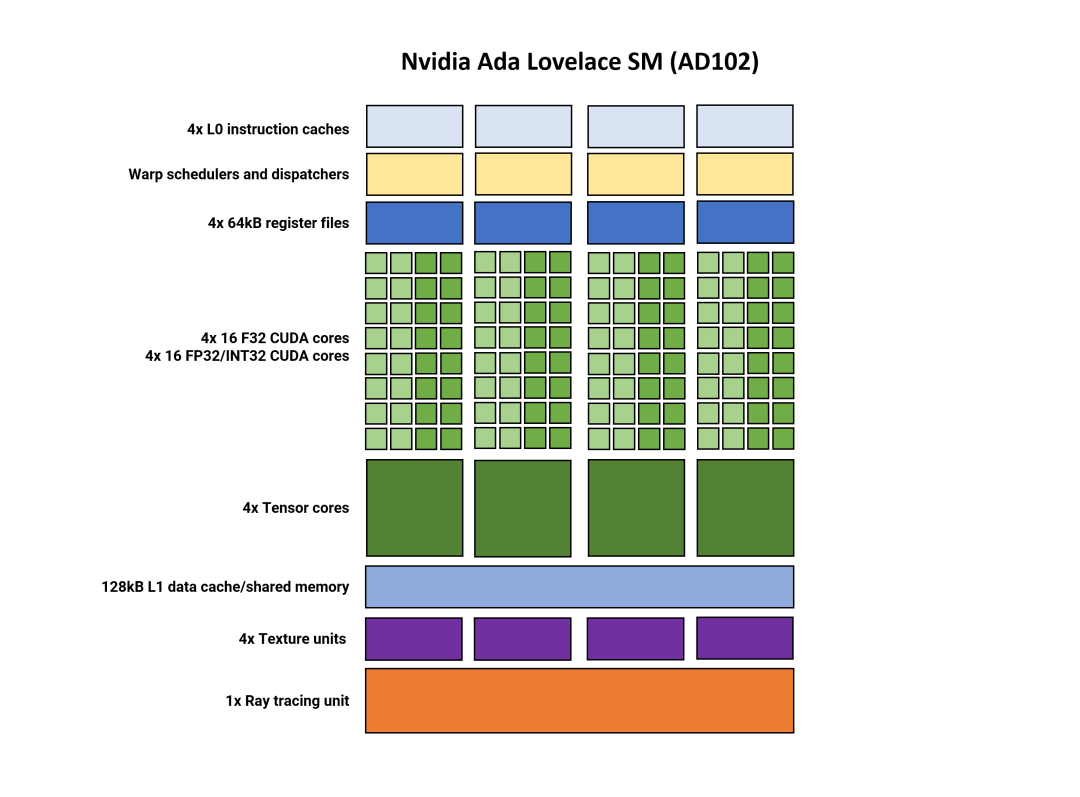
但總結(jié)一下結(jié)構(gòu),SM 分為四個(gè)分區(qū)。每個(gè)處理器都有自己的 L0 指令緩存、線程調(diào)度程序和分派單元,以及與 SIMD32 處理器配對(duì)的 64 kB 寄存器文件部分。
正如AMD的RDNA 3一樣,SM支持雙發(fā)出指令,其中每個(gè)分區(qū)可以同時(shí)處理兩個(gè)線程,一個(gè)使用FP32指令,另一個(gè)使用FP32或INT32指令。
Nvidia 的 Tensor 核心現(xiàn)已進(jìn)入第四版,但這一次,唯一顯著的變化是包含了Hopper 芯片中的FP8 Transformer 引擎,原始吞吐量數(shù)據(jù)保持不變。
低精度浮點(diǎn)格式的加入意味著GPU應(yīng)該更適合AI訓(xùn)練模型。Tensor 核心還提供Ampere 的稀疏功能,可提供高達(dá)兩倍的吞吐量。
另一個(gè)改進(jìn)在于光流加速器 (OFA:Optical Flow Accelerator) 引擎(圖中未顯示)。該電路生成光流場(chǎng)( optical flow field),用作DLSS算法的一部分。OFA 的安培性能提高了一倍,額外的吞吐量被用在最新版本的臨時(shí)抗鋸齒升頻器 DLSS 3 中。
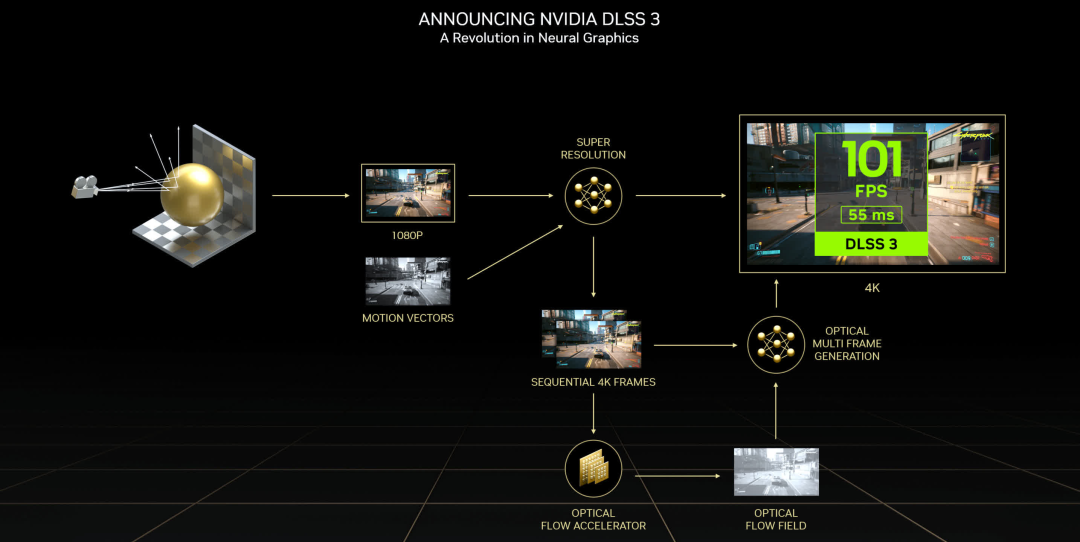
DLSS 3已經(jīng)面臨相當(dāng)多的批評(píng),主要集中在兩個(gè)方面:DLSS 生成的幀不是“真實(shí)的”,并且該過(guò)程給渲染鏈增加了額外的延遲。第一個(gè)并不是完全無(wú)效,因?yàn)橄到y(tǒng)的工作原理是首先讓 GPU 渲染兩個(gè)連續(xù)的幀,將它們存儲(chǔ)在內(nèi)存中,然后使用神經(jīng)網(wǎng)絡(luò)算法確定中間幀的樣子。
然后,當(dāng)前鏈返回到第一個(gè)渲染幀并顯示該幀,然后是 DLSS 幀,然后是渲染的第二幀。由于游戲引擎尚未在中幀循環(huán),因此屏幕會(huì)在沒有任何潛在輸入的情況下刷新。而且由于需要停止而不是呈現(xiàn)兩個(gè)連續(xù)的幀,因此為這些幀輪詢的任何輸入也將停止。
DLSS 3 是否會(huì)變得流行或普遍還有待觀察。
盡管 Ada 的 SM 與 Ampere 非常相似,但 RT 內(nèi)核有顯著的變化,我們將很快解決這些變化。現(xiàn)在我們來(lái)總結(jié)一下AMD、Intel、Nvidia的GPU重復(fù)結(jié)構(gòu)的計(jì)算能力。
處理塊比較
我們可以通過(guò)查看每個(gè)時(shí)鐘周期的標(biāo)準(zhǔn)數(shù)據(jù)格式的操作數(shù)量來(lái)比較 SM、XEC 和 DCU 的功能。請(qǐng)注意,這些是峰值數(shù)字,實(shí)際上不一定可以實(shí)現(xiàn)。
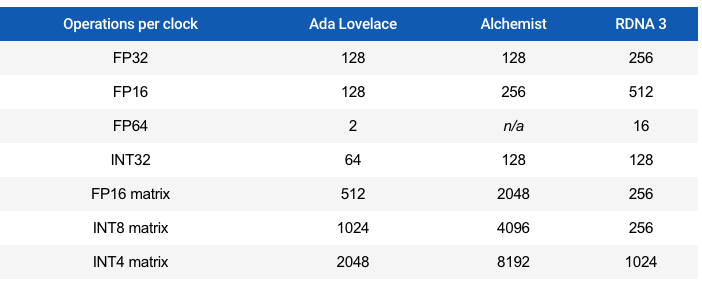
Nvidia 的數(shù)字與 Ampere 相比沒有變化,而 RDNA 3 的數(shù)字在某些領(lǐng)域增加了一倍。然而,Alchemist在矩陣運(yùn)算方面處于另一個(gè)水平,盡管應(yīng)該再次強(qiáng)調(diào)這些是峰值理論值的事實(shí)。
鑒于英特爾的圖形部門像英偉達(dá)一樣嚴(yán)重依賴數(shù)據(jù)中心和計(jì)算,因此看到該架構(gòu)將如此多的芯片空間用于矩陣運(yùn)算也就不足為奇了。缺乏 FP64 功能并不是問(wèn)題,因?yàn)樵摂?shù)據(jù)格式并未真正用于游戲,并且該功能存在于其 X e -HP 架構(gòu)中。
理論上,在矩陣/張量運(yùn)算方面,Ada Lovelace 和 Alchemist 比 RDNA 3 更強(qiáng),但由于我們正在研究主要用于游戲工作負(fù)載的 GPU,因此專用單元大多只是為 DLSS 和相關(guān)算法提供加速。XeSS——它們使用卷積自動(dòng)編碼器神經(jīng)網(wǎng)絡(luò)(CAENN)來(lái)掃描圖像中的偽影并進(jìn)行糾正。
AMD 的時(shí)間升級(jí)器(FidelityFX Super Resolution, FSR))不使用 CAENN,因?yàn)樗饕贚anczos 重采樣方法,然后是通過(guò) DCU 處理的許多圖像校正例程。然而,在RDNA 3 的發(fā)布中,簡(jiǎn)要介紹了FSR 的下一版本,并引用了一項(xiàng)名為“Fluid Motion Frames”的新功能。FSR 2.0 的性能提升高達(dá)兩倍,普遍的共識(shí)是這可能涉及幀生成,如 DLSS 3 中那樣,但這是否涉及任何矩陣運(yùn)算尚不清楚。
適合每個(gè)人的光線追蹤
隨著使用 Alchemist 架構(gòu)的 Arc 顯卡系列的推出,英特爾與 AMD 和 Nvidia 一起提供 GPU,為圖形中使用光線追蹤所涉及的各種算法提供專用加速器。Ada 和 RNDA 3 都包含顯著更新的 RT 單元,因此了解一下新的和不同的內(nèi)容是有意義的。
從 AMD 開始,其光纖加速器的最大變化是添加硬件以改進(jìn)包圍體層次結(jié)構(gòu)(BVH:bounding volume hierarchies)的遍歷(traversal)。這些數(shù)據(jù)結(jié)構(gòu)用于加速確定 3D 世界中光線照射到的表面。

在 RDNA 2 中,所有這些工作都是通過(guò)計(jì)算單元處理的,并且在某種程度上仍然如此。然而,對(duì)于 DXR(微軟的光線追蹤 API)來(lái)說(shuō),有對(duì)光線標(biāo)志管理的硬件支持。
使用這些可以大大減少需要遍歷 BVH 的次數(shù),從而減少緩存帶寬和計(jì)算單元的總體負(fù)載。本質(zhì)上,AMD 專注于提高他們?cè)谥凹軜?gòu)中引入的系統(tǒng)的整體效率。

此外,硬件已更新,以改進(jìn)盒子排序(box sorting,這使得遍歷更快)和剔除算法(culling algorithms,以跳過(guò)測(cè)試空盒子)。再加上緩存系統(tǒng)的改進(jìn),AMD 表示,在相同的時(shí)鐘速度下,與 RDNA 2 相比,光線追蹤性能提高了 80%。
然而,這種改進(jìn)并不能轉(zhuǎn)化為使用光線追蹤的游戲中每秒幀數(shù)增加 80% ,這些情況下的性能受到許多因素的影響,RT 單元的功能只是其中之一。
由于英特爾是光線追蹤技術(shù)的新手,因此沒有任何改進(jìn)。相反,我們只是被告知他們的 RT 單元處理射線和三角形之間的 BVH 遍歷和相交計(jì)算。這使得它們比 AMD 的系統(tǒng)更類似于 Nvidia 的系統(tǒng),但關(guān)于它們的信息并不多。
但我們確實(shí)知道每個(gè) RT 單元都有一個(gè)未指定大小的緩存用于存儲(chǔ) BVH 數(shù)據(jù),以及一個(gè)單獨(dú)的單元用于分析和排序光線著色器線程,以提高 SIMD 利用率。
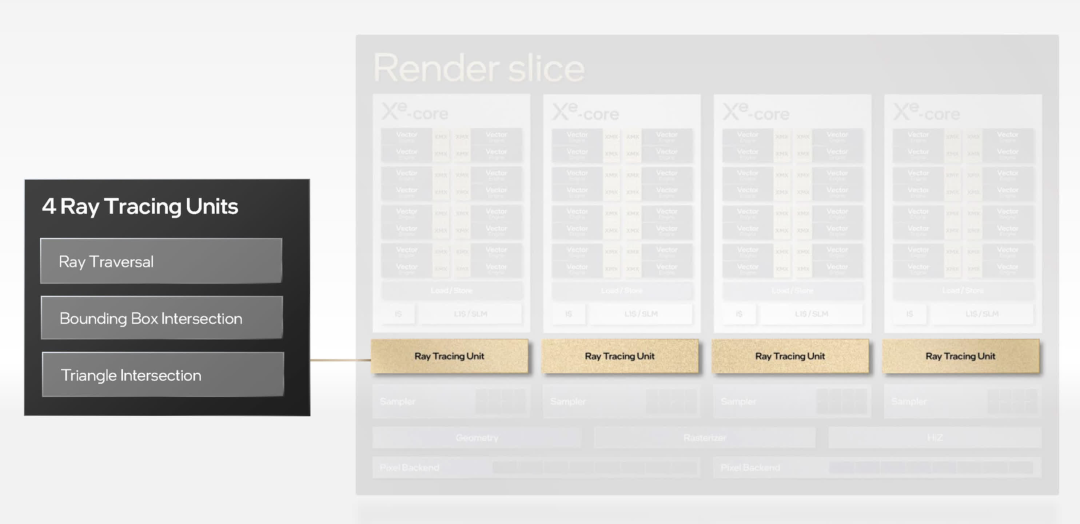
每個(gè) XEC 與一個(gè) RT 單元配對(duì),每個(gè)渲染切片總共有四個(gè)。在游戲中啟用光線追蹤的A770 的一些早期測(cè)試表明,無(wú)論英特爾采用何種結(jié)構(gòu),Alchemist 的光線追蹤整體能力至少與 Ampere 芯片一樣好,并且比 RDNA 2 型號(hào)稍好一些。
但讓我們?cè)俅沃厣辏饩€追蹤也給著色核心、緩存系統(tǒng)和內(nèi)存帶寬帶來(lái)了沉重壓力,因此不可能從此類基準(zhǔn)測(cè)試中提取 RT 單元性能。
對(duì)于 Ada Lovelace 架構(gòu),Nvidia 做出了許多改變,與 Ampere 相比,其性能提升幅度相當(dāng)大。據(jù)稱,用于射線-三角形相交計(jì)算的加速器的吞吐量提高了一倍,并且現(xiàn)在據(jù)說(shuō)非不透明表面的 BVH 遍歷速度提高了一倍。后者對(duì)于使用帶有 alpha channel (透明度)的紋理的對(duì)象很重要,例如樹上的葉子。
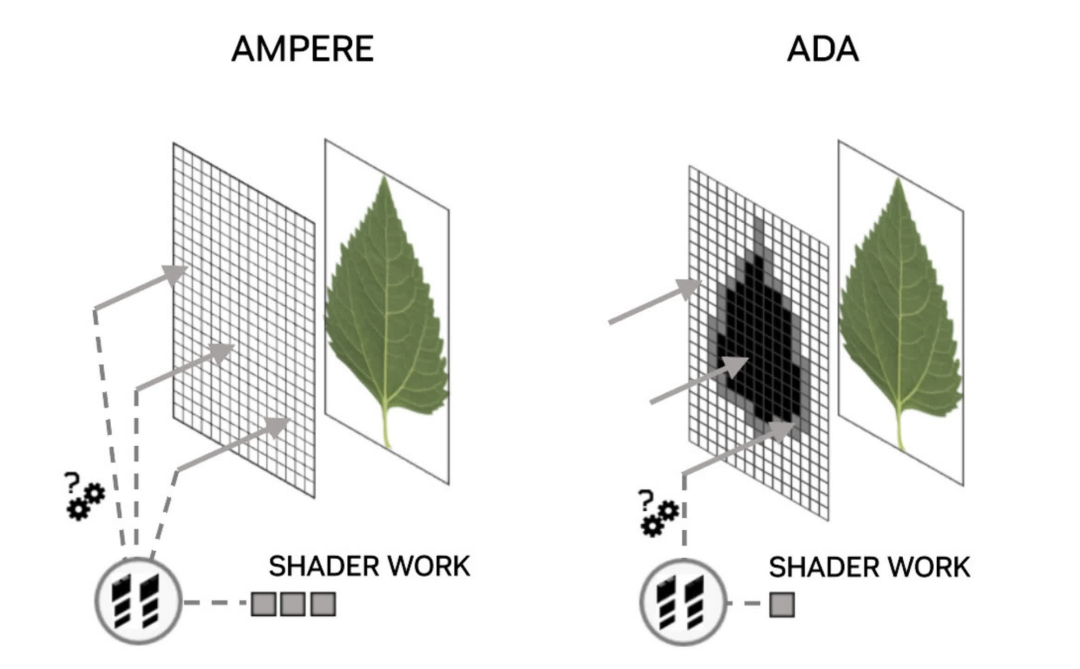
光線擊中此類表面的完全透明部分不應(yīng)導(dǎo)致?lián)糁薪Y(jié)果——光線應(yīng)直接穿過(guò)。然而,為了在當(dāng)前使用光線追蹤的游戲中準(zhǔn)確確定這一點(diǎn),需要處理多個(gè)其他著色器。Nvidia 的新不透明度微貼圖引擎將這些表面分解成更多的三角形,然后確定到底發(fā)生了什么,從而減少了所需的光線著色器的數(shù)量。
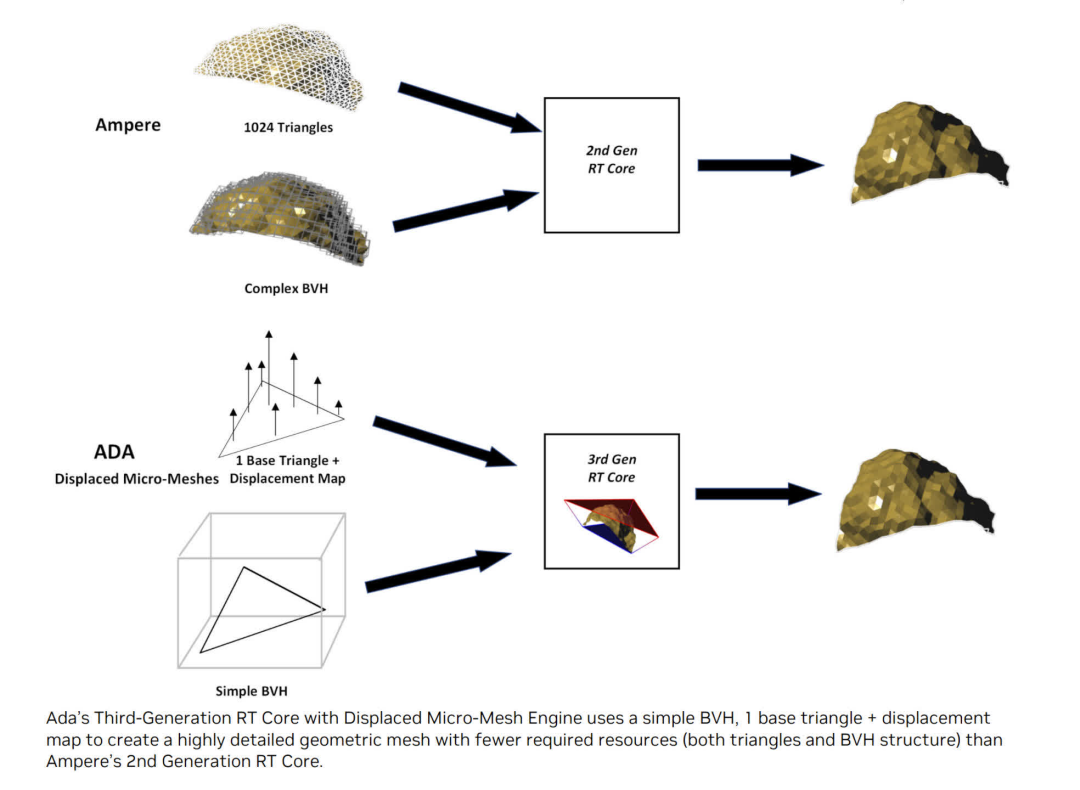
Ada 光線追蹤功能的另外兩個(gè)附加功能是減少 BVH 的構(gòu)建時(shí)間和內(nèi)存占用(聲稱速度分別加快 10 倍和縮小 20 倍),以及為光線著色器重新排序線程的結(jié)構(gòu),從而提高效率。然而,前者不需要開發(fā)人員對(duì)軟件進(jìn)行任何更改,而后者目前只能通過(guò) Nvidia 的 API 訪問(wèn),因此對(duì)當(dāng)前的 DirectX 12 游戲沒有任何好處。
當(dāng)我們測(cè)試 GeForce RTX 4090 的光線追蹤性能時(shí),啟用光線追蹤后幀速率的平均下降略低于 45%。使用 Ampere 驅(qū)動(dòng)的 GeForce RTX 3090 Ti 時(shí),下降了 56%。然而,這種改進(jìn)不能完全歸因于 RT 核心的改進(jìn),因?yàn)?4090 比以前的型號(hào)具有更多的著色吞吐量和緩存。
我們還沒有看到 RDNA 3 的光線追蹤改進(jìn)會(huì)產(chǎn)生什么樣的差異,但值得注意的是,沒有一家 GPU 制造商期望單獨(dú)使用 RT – 即仍然需要使用升級(jí)來(lái)實(shí)現(xiàn)高幀速率。
光線追蹤的粉絲可能會(huì)有些失望,因?yàn)樾乱惠喌膱D形處理器在這一領(lǐng)域沒有取得任何重大進(jìn)展,但自 2018 年 Nvidia 圖靈架構(gòu)首次出現(xiàn)以來(lái),已經(jīng)取得了很多進(jìn)展。
內(nèi)存:沿著數(shù)據(jù)高速公路行駛
GPU 處理數(shù)據(jù)的方式與其他芯片不同,而讓 ALU 保持?jǐn)?shù)據(jù)輸入對(duì)其性能至關(guān)重要。在 PC 圖形處理器的早期,內(nèi)部幾乎沒有任何緩存,全局內(nèi)存(整個(gè)芯片使用的 RAM)是非常慢的 DRAM。即使就在10年前,情況也沒有好多少。
因此,讓我們從 AMD 新架構(gòu)中的內(nèi)存層次結(jié)構(gòu)開始,深入了解當(dāng)前的情況。自第一次迭代以來(lái),RDNA 使用了復(fù)雜的多級(jí)內(nèi)存層次結(jié)構(gòu)。最大的變化發(fā)生在一年前,當(dāng)時(shí) GPU 中添加了大量的 L3 緩存,在某些型號(hào)中高達(dá) 128MB。
第三輪的情況仍然如此,但有一些微妙的變化。
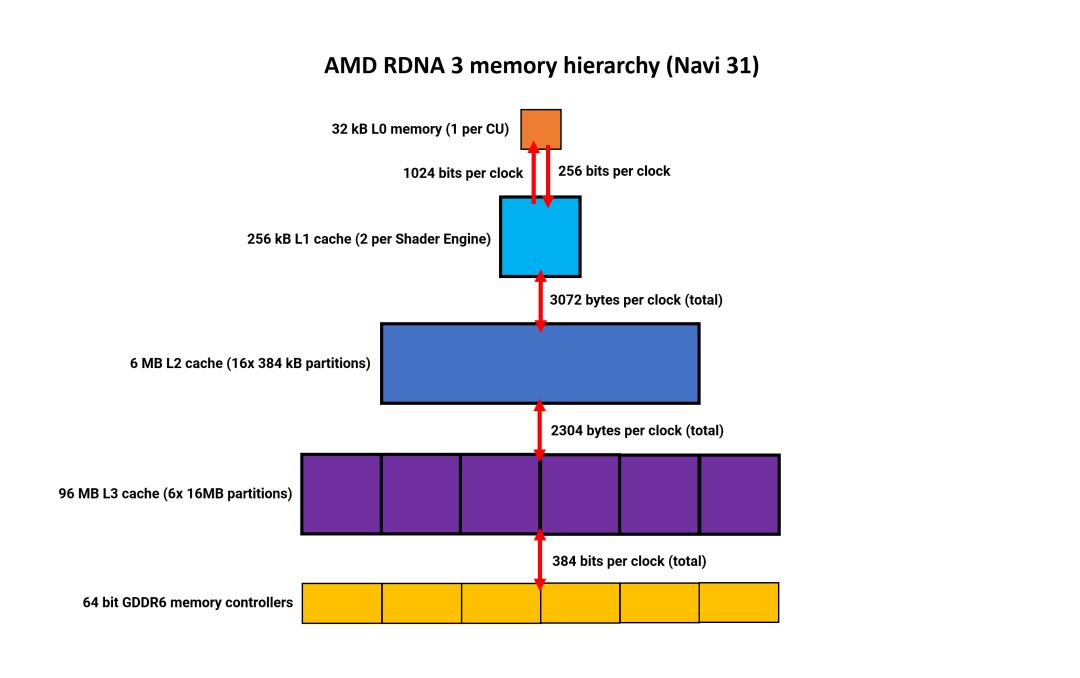
Nvidia 保留了與 Ampere 中使用的相同的內(nèi)存結(jié)構(gòu),每個(gè) SM 具有 128kB 的緩存,充當(dāng) L1 數(shù)據(jù)存儲(chǔ)、共享內(nèi)存和紋理緩存。可用于不同角色的數(shù)量是動(dòng)態(tài)分配的。目前尚未提及 L1 帶寬的任何變化,但在 Ampere 中,每個(gè) SM 每個(gè)時(shí)鐘周期為 128 字節(jié)。Nvidia 從未明確明確這一數(shù)字是累積的、結(jié)合讀寫的,還是僅針對(duì)一個(gè)方向的。
如果 Ada 至少與 Ampere 相同,那么所有 SM 的總 L1 帶寬將達(dá)到每個(gè)時(shí)鐘 18 kB,遠(yuǎn)大于 RDNA 2 和 Alchemist。
但必須再次強(qiáng)調(diào)的是,這些芯片不具有直接可比性,因?yàn)橛⑻貭柕男酒亲鳛橹卸水a(chǎn)品定價(jià)和銷售的,而 AMD 已明確表示Navi 31 的設(shè)計(jì)目的從來(lái)不是為了與 Nvidia 的 AD102 競(jìng)爭(zhēng)。它的競(jìng)爭(zhēng)對(duì)手是 AD103,它比 AD102 小得多。
內(nèi)存層次結(jié)構(gòu)的最大變化是,在完整的 AD102 芯片中,L2 緩存已增加到 96MB,是其前身 GA102 的 16 倍。與英特爾的系統(tǒng)一樣,L2 進(jìn)行分區(qū)并與 32 位 GDDR6X 內(nèi)存控制器配對(duì),以實(shí)現(xiàn)高達(dá) 384 位的 DRAM 總線寬度。
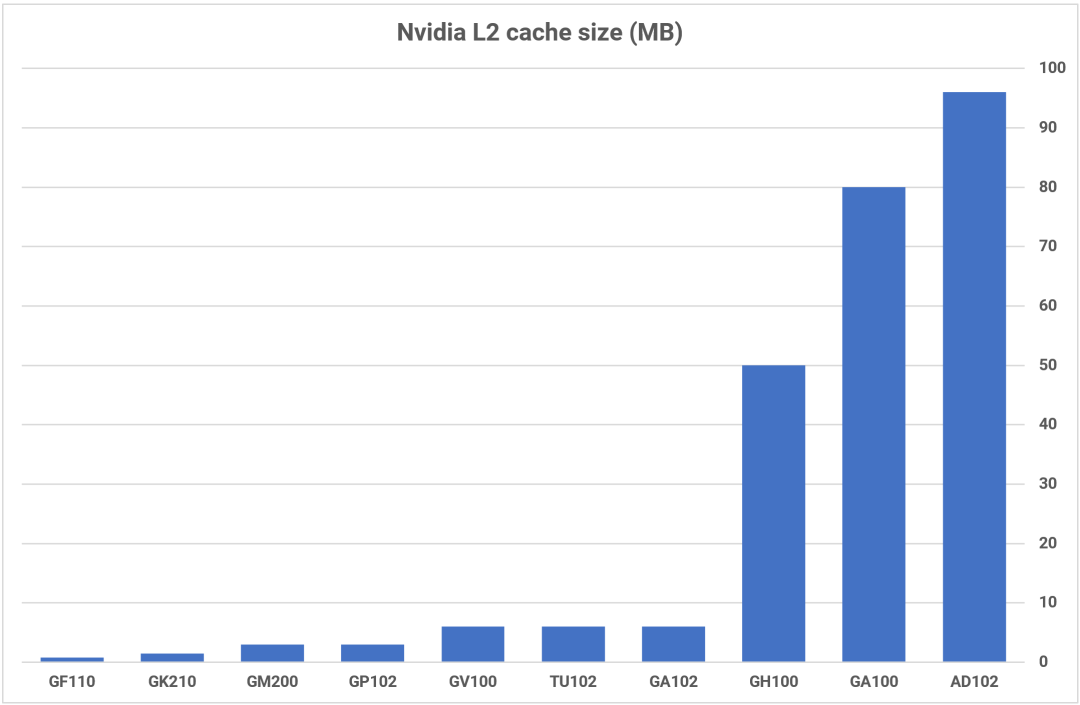
較大的緩存通常比較小的緩存具有更長(zhǎng)的延遲,但由于時(shí)鐘速度的提高和總線的一些改進(jìn),Ada Lovelace 顯示出比 Ampere更好的緩存性能。
如果我們比較所有三個(gè)系統(tǒng),英特爾和 Nvidia 對(duì) L1 緩存采取相同的方法 -——它可以用作只讀數(shù)據(jù)緩存或計(jì)算共享內(nèi)存。對(duì)于后者,需要通過(guò)軟件明確指示 GPU 以這種格式使用它,并且數(shù)據(jù)僅在使用它的線程處于活動(dòng)狀態(tài)時(shí)保留。這增加了系統(tǒng)的復(fù)雜性,但對(duì)計(jì)算性能產(chǎn)生了有用的提升。
在 RDNA 3 中,“L1”數(shù)據(jù)緩存和共享內(nèi)存被分為兩個(gè) 32kB L0 矢量緩存和一個(gè) 128kB 本地?cái)?shù)據(jù)共享。AMD 所謂的 L1 緩存實(shí)際上是一組四個(gè) DCU 和 L2 緩存之間用于只讀數(shù)據(jù)的共享墊腳石(shared stepping stone)。
雖然緩存帶寬沒有 Nvidia 的那么高,但多層方法有助于解決這個(gè)問(wèn)題,尤其是在 DCU 未得到充分利用的情況下。

巨大的處理器范圍的緩存系統(tǒng)通常不是 GPU 的最佳選擇,這就是為什么我們?cè)谝郧暗募軜?gòu)中沒有看到超過(guò) 4 或 6MB 的緩存系統(tǒng),但 AMD、Intel 和 Nvidia 都在最后一層是應(yīng)對(duì) DRAM 速度增長(zhǎng)相對(duì)不足的問(wèn)題。
向 GPU 添加大量?jī)?nèi)存控制器可以提供充足的帶寬,但代價(jià)是芯片尺寸增加和制造費(fèi)用增加,而 HBM3 等替代方案的使用成本要高得多。
我們還沒有看到 AMD 的系統(tǒng)最終表現(xiàn)如何,但他們?cè)?RDNA 2 中的四層方法在與 Ampere 的對(duì)抗中表現(xiàn)良好,并且比英特爾的系統(tǒng)要好得多。然而,隨著 Ada 加入了更多的 L2,競(jìng)爭(zhēng)不再那么簡(jiǎn)單。
芯片封裝和工藝節(jié)點(diǎn):建造的不同方式
AMD、英特爾和 Nvidia 有一個(gè)共同點(diǎn)——他們都使用臺(tái)積電來(lái)制造 GPU。
AMD在Navi 31中的GCD和MCD使用了兩種不同的節(jié)點(diǎn),前者使用N5節(jié)點(diǎn),后者使用N6(N7的增強(qiáng)版本)。英特爾還在其所有 Alchemist 芯片中使用 N6。在 Ampere 中,Nvidia 使用了三星舊的 8nm 工藝,但在 Ada 中,他們轉(zhuǎn)回臺(tái)積電及其 N4 工藝,這是 N5 的變體。
N4 擁有所有節(jié)點(diǎn)中最高的晶體管密度和最佳的性能功耗比,但當(dāng) AMD 推出 RDNA 3 時(shí),他們強(qiáng)調(diào)只有邏輯電路的密度出現(xiàn)了顯著增加。
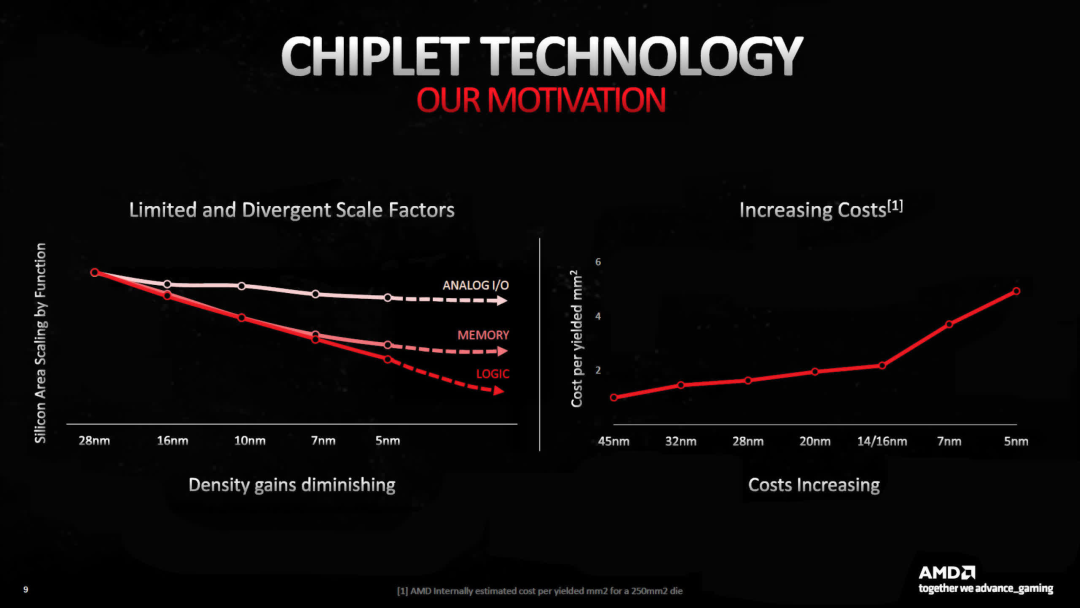
SRAM(用于高速緩存)和模擬系統(tǒng)(用于存儲(chǔ)器、系統(tǒng)和其他信號(hào)電路)微縮相對(duì)較小。再加上新工藝節(jié)點(diǎn)每晶圓價(jià)格的上漲,AMD 決定使用稍舊且更便宜的 N6 來(lái)制造 MCD,因?yàn)檫@些小芯片主要是 SRAM 和 I/O。
就芯片尺寸而言,GCD比Navi 21 小 42%,為 300 mm 2。每個(gè) MCD 僅 37mm 2,因此 Navi 31 的組合芯片面積與其前身大致相同。AMD 僅公布了所有小芯片的晶體管總數(shù),但這款新 GPU 數(shù)量達(dá)到 580 億個(gè),是他們有史以來(lái)“最大的”消費(fèi)類圖形處理器。
為了將每個(gè) MCD 連接到 GCD,AMD 使用了所謂的高性能扇出——密集的走線,占用的空間非常小。Infinity Links(AMD 專有的互連和信號(hào)系統(tǒng))運(yùn)行速度高達(dá) 9.2Gb/s,每個(gè) MCD 的鏈路寬度為 384 位,MCD 到 GCD 的帶寬達(dá)到 883GB/s(雙向)。
對(duì)于單個(gè) MCD,這相當(dāng)于高端顯卡的全局內(nèi)存帶寬。Navi 31 中全部有 6 個(gè),L2 到 MCD 的總帶寬達(dá)到 5.3TB/s。
與傳統(tǒng)的單片芯片相比,使用復(fù)雜的扇出意味著芯片封裝的成本將會(huì)更高,但該工藝是可擴(kuò)展的——不同的 SKU 可以使用相同的 GCD,但 MCD 的數(shù)量不同。較小尺寸的單個(gè)小芯片芯片應(yīng)該會(huì)提高晶圓產(chǎn)量,但沒有跡象表明 AMD 是否在 MCD 的設(shè)計(jì)中納入了任何冗余。

如果沒有,則意味著任何在 SRAM 中存在缺陷的小芯片,這些缺陷會(huì)導(dǎo)致內(nèi)存陣列的該部分無(wú)法使用,那么它們將必須被分類用于低端型號(hào) SKU,或者根本不使用。
AMD 迄今為止僅發(fā)布了兩款 RDNA 3 顯卡(Radeon RX 7900 XT 和 XTX),但在這兩種型號(hào)中,MCD 均具有 16MB 緩存。如果下一輪 Radeon 卡配備 256 位內(nèi)存總線和 64MB L3 緩存,那么它們也需要使用“完美”的 16MB 芯片。
然而,由于它們的面積非常小,單個(gè) 300mm 晶圓可能會(huì)產(chǎn)生超過(guò) 1500 個(gè) MCD。即使其中 50% 必須報(bào)廢,這仍然足以提供 125 個(gè) Navi 31 封裝。
我們還需要一段時(shí)間才能知道 AMD 的設(shè)計(jì)實(shí)際上具有多大的成本效益,但該公司現(xiàn)在和將來(lái)都完全致力于使用這種方法,盡管僅限于更大的 GPU。預(yù)算 RNDA 3 模型的緩存量要少得多,將繼續(xù)使用單片制造方法,因?yàn)檫@種制造方法更具成本效益。
英特爾的ACM-G10處理器尺寸為406mm 2,晶體管總數(shù)為217億個(gè),在組件數(shù)量和芯片面積方面介于AMD的Navi 21和Nvidia的GA104之間。
這實(shí)際上使它成為一個(gè)相當(dāng)大的處理器,這就是為什么英特爾選擇 GPU 的市場(chǎng)領(lǐng)域似乎有些奇怪的原因。Arc A770顯卡采用完整的 ACM-G10 芯片,與 Nvidia 的 GeForce RTX 3060等顯卡進(jìn)行競(jìng)爭(zhēng),后者使用的芯片尺寸和晶體管數(shù)量只有英特爾一半。
那么為什么它這么大呢?可能的原因有兩個(gè):16MB 的二級(jí)緩存和每個(gè) XEC 中的矩陣單元數(shù)量非常多。采用前者的決定是合乎邏輯的,因?yàn)樗鼫p輕了全局內(nèi)存帶寬的壓力,但后者很容易被認(rèn)為對(duì)其銷售的領(lǐng)域來(lái)說(shuō)是過(guò)多的。RTX 3060 有 112 個(gè) Tensor 核心,而 A770 有 512 個(gè) XMX單元。
英特爾的另一個(gè)奇怪的選擇是使用臺(tái)積電 N6 來(lái)制造 Alchemist 芯片,而不是他們自己的工廠。關(guān)于此事的官方聲明引用了成本、晶圓廠產(chǎn)能和芯片工作頻率等因素。
這表明英特爾的同等生產(chǎn)設(shè)施(使用更名后的intel 7節(jié)點(diǎn))將無(wú)法滿足預(yù)期需求,其Alder和Raptor Lake CPU占據(jù)了大部分產(chǎn)能。
他們會(huì)將 CPU 輸出的相對(duì)下降以及這對(duì)收入的影響與使用 Alchemist 獲得的收益進(jìn)行比較。簡(jiǎn)而言之,最好付錢給臺(tái)積電制造新的 GPU。
AMD 利用其多芯片專業(yè)知識(shí)并開發(fā)了用于制造大型 RDNA 3 GPU 的新技術(shù),而 Nvidia 則堅(jiān)持 Ada 系列的單片設(shè)計(jì)。GPU 公司在制造超大型處理器方面擁有豐富的經(jīng)驗(yàn),但 608mm2 的AD102 并不是其發(fā)布的物理上最大的芯片(這一榮譽(yù)頒給了826mm2的GA100)。然而,Nvidia 擁有 763 億個(gè)晶體管,其組件數(shù)量遠(yuǎn)遠(yuǎn)領(lǐng)先于迄今為止任何消費(fèi)級(jí) GPU。
相比之下,GeForce RTX 3080 及更高版本中使用的 GA102 顯得輕量級(jí),只有 268 億。這 187% 的增長(zhǎng)得益于 SM 數(shù)量的 71% 增長(zhǎng)和 L2 緩存數(shù)量的 1500% 的提升。
如此大而復(fù)雜的芯片總是難以實(shí)現(xiàn)完美的晶圓良率,這就是為什么之前的高端 Nvidia GPU 催生了眾多 SKU。通常,隨著新架構(gòu)的推出,他們的專業(yè)顯卡系列(例如 A 系列、Tesla 等)首先發(fā)布。
當(dāng) Ampere 發(fā)布時(shí),GA102 出現(xiàn)在兩款消費(fèi)級(jí)卡中,并最終在 14 種不同的產(chǎn)品中找到了應(yīng)用。到目前為止,Nvidia 僅選擇在兩款產(chǎn)品中使用 AD102:GeForce RTX 4090和RTX 6000。不過(guò),后者自 9 月份出現(xiàn)以來(lái)一直無(wú)法購(gòu)買。
RTX 4090 使用的芯片更接近分箱過(guò)程,禁用了 16 個(gè) SM 和 24MB 二級(jí)緩存,而 RTX 6000 僅禁用了兩個(gè) SM。這就讓人不禁要問(wèn):剩下的die在哪里?
但由于沒有其他產(chǎn)品使用 AD102,我們只能假設(shè) Nvidia 正在儲(chǔ)備它們,盡管其他產(chǎn)品的用途尚不清楚。
GeForce RTX 4080使用 AD103,其尺寸為 379mm2和 459 億個(gè)晶體管,與它的大哥完全不同——更小的芯片(80 個(gè) SM、64MB 二級(jí)緩存)應(yīng)該會(huì)帶來(lái)更好的產(chǎn)量,但同樣只有一種產(chǎn)品使用它。
他們還發(fā)布了另一款 RTX 4080,其中一款使用了較小的 AD104,但由于收到的批評(píng)而取消了發(fā)布。預(yù)計(jì)這款 GPU 現(xiàn)在將用于推出RTX 4070 系列。
Nvidia 顯然擁有大量基于 Ada 架構(gòu)構(gòu)建的 GPU,但似乎也非常不愿意發(fā)貨。造成這種情況的原因之一可能是他們正在等待安培驅(qū)動(dòng)的顯卡上架;另一個(gè)事實(shí)是,它主導(dǎo)了一般用戶和工作站市場(chǎng),并且可能認(rèn)為它現(xiàn)在不需要提供任何其他東西。
但考慮到 AD102 和 103 提供的原始計(jì)算能力有了顯著提高,Ada 專業(yè)卡的數(shù)量如此之少就有些令人費(fèi)解了——該行業(yè)總是渴望更多的處理能力。
Superstar DJs: 顯示和媒體引擎
當(dāng)談到 GPU 的媒體和顯示引擎時(shí),與 DirectX 12 功能或晶體管數(shù)量等方面相比,它們通常采用幕后營(yíng)銷方法。但隨著游戲流媒體行業(yè)產(chǎn)生數(shù)十億美元的收入,我們開始看到更多的努力來(lái)開發(fā)和推廣新的顯示功能。
對(duì)于 RDNA 3,AMD 更新了許多組件,最值得注意的是對(duì) DisplayPort 2.1 和 HDMI 2.1a 的支持。鑒于監(jiān)督 DisplayPort 規(guī)范的組織 VESA在 2022 年底才發(fā)布 2.1 版本,GPU 供應(yīng)商如此迅速地采用該系統(tǒng)是一個(gè)不尋常的舉動(dòng)。

新顯示引擎支持的最快 DP 傳輸模式是 UHBR13.5,最大 4 通道傳輸速率為 54 Gbps。對(duì)于標(biāo)準(zhǔn)時(shí)序下 4K 分辨率、144Hz 刷新率、無(wú)任何壓縮的情況來(lái)說(shuō),這已經(jīng)足夠了。
使用 DSC(顯示流壓縮:Display Stream Compression),DP2.1 連接允許高達(dá) 4K@480Hz 或 8K@165Hz - 比 RDNA 2 中使用的 DP1.4a 有了顯著改進(jìn)。
英特爾的 Alchemist 架構(gòu)采用具有 DP 2.0(UHBR10,40 Gbps)和 HDMI 2.1 輸出的顯示引擎,盡管并非所有使用該芯片的 Arc 系列顯卡都可以利用最大功能。
雖然ACM-G10并不針對(duì)高分辨率游戲,但采用最新的顯示連接規(guī)格意味著可以在沒有任何壓縮的情況下使用電子競(jìng)技顯示器(例如1080p、360Hz)。該芯片可能無(wú)法在此類游戲中呈現(xiàn)如此高的幀速率,但至少顯示引擎可以。
AMD 和英特爾對(duì) DP 和 HDMI 中快速傳輸模式的支持正是您對(duì)全新架構(gòu)的期望,因此 Nvidia 選擇不對(duì) Ada Lovelace 這樣做有點(diǎn)不協(xié)調(diào)。
AD102 對(duì)于所有晶體管(幾乎與 Navi 31 和 ACM-G10 加在一起相同)僅具有具有 DP1.4a 和 HDMI 2.1 輸出的顯示引擎。對(duì)于 DSC,前者對(duì)于 4K@144Hz 來(lái)說(shuō)已經(jīng)足夠好了,但是當(dāng)競(jìng)爭(zhēng)對(duì)手支持不壓縮的情況下,這顯然是錯(cuò)失機(jī)會(huì)。
GPU 中的媒體引擎負(fù)責(zé)視頻流的編碼和解碼,所有三個(gè)供應(yīng)商在其最新架構(gòu)中都擁有豐富的功能集。
在 RDNA 3 中,AMD 添加了針對(duì) AV1 格式的完整同步編碼/解碼(僅在之前的 RDNA 2 中進(jìn)行解碼)。關(guān)于新媒體引擎的信息并不多,只是它可以同時(shí)處理兩個(gè) H.264/H.265 流,并且 AV1 的最大速率為 8K@60Hz。AMD 還簡(jiǎn)要提到了“AI 增強(qiáng)”視頻解碼,但沒有提供更多細(xì)節(jié)。
英特爾的 ACM-G10 具有類似的功能范圍,可用于 AV1、H.264 和 H.265 的編碼/解碼,但與 RDNA 3 一樣,細(xì)節(jié)非常少。對(duì) Arc 桌面顯卡中的首批 Alchemist 芯片的一些早期測(cè)試表明,媒體引擎至少與 AMD 和 Nvidia 在其先前架構(gòu)中提供的媒體引擎一樣好。
Ada Lovelace 也采用了 AV1 編碼和解碼,Nvidia 聲稱新系統(tǒng)的編碼效率比 H.264 高 40%,表面上看,使用新格式時(shí)視頻質(zhì)量提高了 40%。
高端 GeForce RTX 40 系列顯卡將配備配備兩個(gè) NVENC 編碼器的 GPU,您可以選擇以 60Hz 編碼 8K HDR,或改進(jìn)視頻導(dǎo)出的并行化,每個(gè)編碼器同時(shí)處理半幀。
GPU 的下一步是什么?
桌面 GPU 市場(chǎng)上已經(jīng)有三個(gè)供應(yīng)商了,很明顯,每個(gè)供應(yīng)商都有自己的圖形處理器設(shè)計(jì)方法,盡管英特爾和 Nvidia 也采取了類似的思維方式。
對(duì)于他們來(lái)說(shuō),Ada 和 Alchemist 在某種程度上是萬(wàn)事通,可用于各種游戲、科學(xué)、媒體和數(shù)據(jù)工作負(fù)載。ACM-G10 中對(duì)矩陣和張量計(jì)算的高度重視以及不愿完全重新設(shè)計(jì)其 GPU 布局表明英特爾更傾向于科學(xué)和數(shù)據(jù),而不是游戲,但考慮到這些領(lǐng)域的潛在增長(zhǎng),這是可以理解的。
對(duì)于最后三種架構(gòu),Nvidia 專注于改進(jìn)已經(jīng)很好的架構(gòu),并減少整體設(shè)計(jì)中的各種瓶頸,例如內(nèi)部帶寬和延遲。雖然 Ada 是對(duì) Ampere 的自然改進(jìn)(Nvidia 多年來(lái)一直遵循這一主題),但當(dāng)你觀察晶體管數(shù)量的絕對(duì)規(guī)模時(shí),AD102 卻顯得異常進(jìn)化。
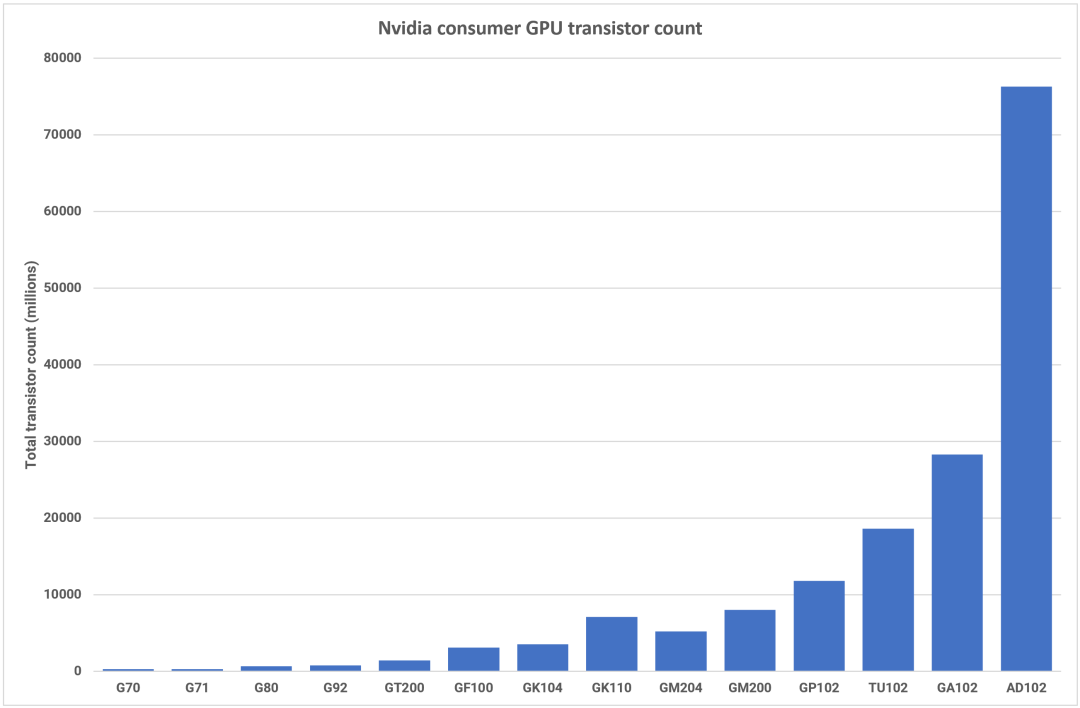
與 GA102 相比,差異非常顯著,但這種巨大的飛躍引發(fā)了許多問(wèn)題。首先,對(duì)于 Nvidia 的最高端消費(fèi)產(chǎn)品來(lái)說(shuō),AD103 是否是比 AD102 更好的選擇?
與 RTX 4080 中使用的 AD103 相比,AD103 的性能比 RTX 3090 有了相當(dāng)大的改進(jìn),并且與它的大哥一樣,64MB 的二級(jí)緩存有助于抵消相對(duì)較窄的 256 位全局內(nèi)存總線寬度。它的尺寸為 379mm2,比 GeForce RTX 3070 中使用的 GA104 小,因此制造利潤(rùn)比 AD102 高得多。它還包含與 GA102 相同數(shù)量的 SM,并且該芯片最終在 15 種不同的產(chǎn)品中得到了應(yīng)用。
另一個(gè)值得問(wèn)的問(wèn)題是,Nvidia 在架構(gòu)和制造方面將走向何方?他們能否在仍堅(jiān)持使用單片芯片的情況下實(shí)現(xiàn)類似的縮放水平?
AMD 對(duì) RDNA 3 的選擇凸顯了競(jìng)爭(zhēng)的潛在路線。通過(guò)將芯片中規(guī)模最差的部分(在新工藝節(jié)點(diǎn)中)轉(zhuǎn)移到單獨(dú)的小芯片中,AMD 已經(jīng)能夠成功地延續(xù) RDNA 和 RDNA 2 之間的大型制造和設(shè)計(jì)飛躍。
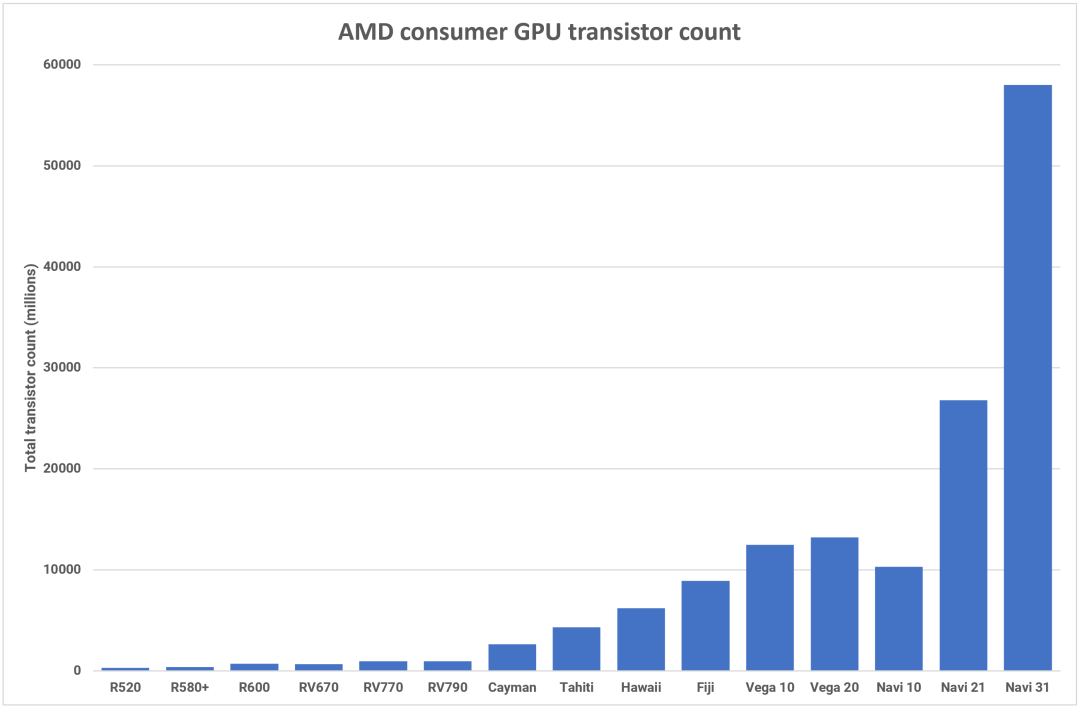
雖然它不像 Nvidia 的 AD102 那么大,但 AMD Navi 31 的硅片價(jià)值仍然高達(dá) 580 億個(gè)晶體管,是 Navi 21 的兩倍多,也是我們最初的 RDNA GPU Navi 10 的 5 倍多(盡管這不是 Navi 21 的兩倍)。
AMD 和 Nvidia 的成就并不是孤立取得的。GPU 晶體管數(shù)量如此大幅增加的唯一原因是臺(tái)積電和三星之間作為半導(dǎo)體設(shè)備主要制造商的激烈競(jìng)爭(zhēng)。兩者都致力于提高邏輯電路的晶體管密度,同時(shí)繼續(xù)降低功耗。臺(tái)積電對(duì)于當(dāng)前的節(jié)點(diǎn)改進(jìn)及其下一步的主要工藝有明確的路線圖。
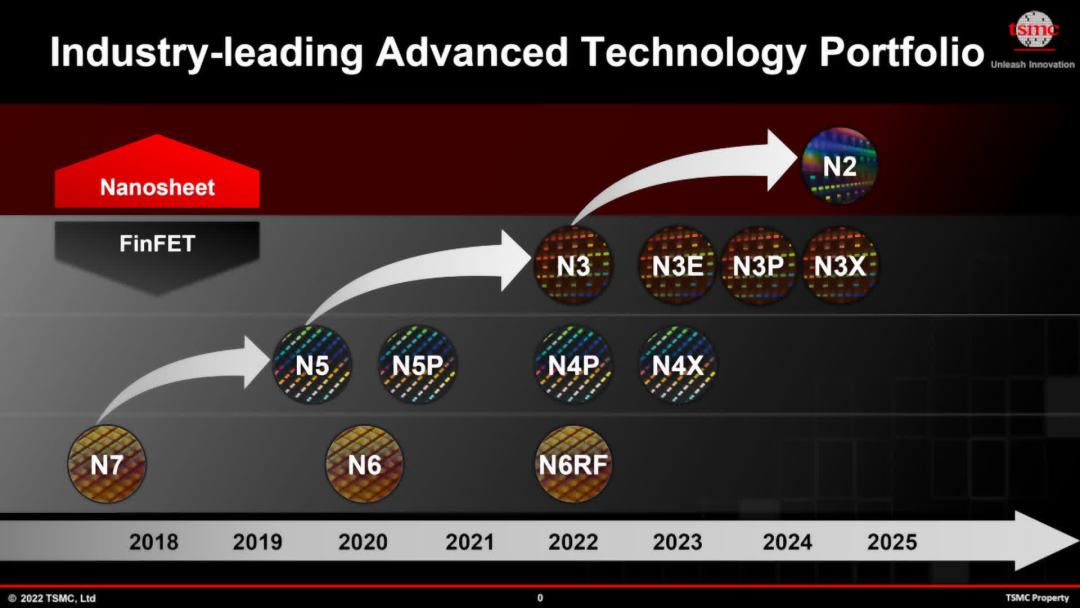
目前尚不清楚 Nvidia 是否會(huì)效仿 AMD 的做法,并在 Ada 的繼任者中采用小芯片布局,但接下來(lái)的一兩年可能會(huì)起到?jīng)Q定性作用。如果 RDNA 3 被證明在財(cái)務(wù)上取得了成功,無(wú)論是在收入還是總出貨量方面,那么 Nvidia 很可能會(huì)效仿。
然而,第一個(gè)使用 Ampere 架構(gòu)的芯片是 GA100——一款數(shù)據(jù)中心 GPU,尺寸為829mm2 ,擁有 542 億個(gè)晶體管。它由 TSMC 使用其 N7 節(jié)點(diǎn)制造(與 RDNA 和大多數(shù) RDNA 2 系列相同)。使用 N4 來(lái)制造 AD102,使得 Nvidia 能夠設(shè)計(jì)出晶體管密度幾乎是其前身的兩倍的 GPU。
在下一個(gè)架構(gòu)中使用 N2 可以實(shí)現(xiàn)這一目標(biāo)嗎?有可能,但緩存的大幅增長(zhǎng)(擴(kuò)展性非常差)表明,即使臺(tái)積電在未來(lái)的節(jié)點(diǎn)上取得了一些引人注目的成績(jī),控制 GPU 大小也將變得越來(lái)越困難。
英特爾已經(jīng)在使用小芯片,但僅限于其巨大的Ponte Vecchio數(shù)據(jù)中心 GPU。由47塊不同的tiles組成,當(dāng)中有些是臺(tái)積電制造的,有些是英特爾自己制造的,其參數(shù)相當(dāng)高。例如,完整的雙 GPU 配置擁有超過(guò) 1000 億個(gè)晶體管,這使得 AMD 的 Navi 31 看起來(lái)非常“小”。當(dāng)然,它不適用于任何類型的臺(tái)式電腦,嚴(yán)格來(lái)說(shuō)也“不僅僅是”GPU——這是一個(gè)數(shù)據(jù)中心處理器,重點(diǎn)關(guān)注矩陣和張量工作負(fù)載。

在轉(zhuǎn)向“Xe Next”之前,其 Xe-HPG 架構(gòu)至少還要進(jìn)行兩次修訂,我們很可能會(huì)在英特爾消費(fèi)類顯卡中看到平鋪的使用。
不過(guò),目前,我們將讓 Ada 和 Alchemist 使用傳統(tǒng)的單片芯片,而 AMD 則將混合芯片系統(tǒng)用于中高端卡,并為其預(yù)算 SKU 使用單芯片。
到本世紀(jì)末,我們可能會(huì)看到幾乎所有類型的圖形處理器,它們都是由精選的不同tile和小芯片構(gòu)建而成,全部使用各種工藝節(jié)點(diǎn)制成。GPU 仍然是臺(tái)式電腦中最引人注目的工程壯舉之一——晶體管數(shù)量沒有顯示出增長(zhǎng)放緩的跡象,而今天普通顯卡的計(jì)算能力在大約 10 年前只能是夢(mèng)想。
讓我們進(jìn)入下一場(chǎng)三向架構(gòu)之戰(zhàn)吧!
-
英特爾
+關(guān)注
關(guān)注
61文章
9953瀏覽量
171699 -
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128897 -
圖形處理器
+關(guān)注
關(guān)注
0文章
198瀏覽量
25541
原文標(biāo)題:GPU巨頭,拼什么?
文章出處:【微信號(hào):wc_ysj,微信公眾號(hào):旺材芯片】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
《CST Studio Suite 2024 GPU加速計(jì)算指南》
拼多多第三季度財(cái)報(bào)發(fā)布:營(yíng)收增長(zhǎng)44%
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】--了解算力芯片GPU
【一文看懂】大白話解釋“GPU與GPU算力”

常見GPU問(wèn)題及解決方法
如何選擇適合的GPU
ARM進(jìn)軍GPU領(lǐng)域,挑戰(zhàn)英偉達(dá)與英特爾

三星首次批準(zhǔn)GPU投資提案
三星電子進(jìn)軍GPU領(lǐng)域,與NVIDIA展開正面競(jìng)爭(zhēng)
大模型時(shí)代,國(guó)產(chǎn)GPU面臨哪些挑戰(zhàn)

NVLink技術(shù)之GPU與GPU的通信

激光拼焊如何提高汽車制造工藝?

gpu是什么和cpu的區(qū)別
巨頭豪購(gòu)35萬(wàn)塊NVIDIA最強(qiáng)GPU H100






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論