") CVPR 2023 | 完全無監(jiān)督的視頻物體分割 RCF
CVPR 2023 | 完全無監(jiān)督的視頻物體分割 RCF

TLDR:視頻分割一直是重標(biāo)注的一個 task,這篇 CVPR 2023 文章研究了完全不需要標(biāo)注的視頻物體分割。僅使用 ResNet,RCF模型在 DAVIS16/STv2/FBMS59 上提升了 7/9/5%。文章里還提出了不需要標(biāo)注的調(diào)參方法。代碼已公開可用。
 ?
?
?論文標(biāo)題:Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
?
?
?論文標(biāo)題:Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
論文鏈接:
https://arxiv.org/abs/2304.08025
作者機構(gòu):
UC Berkeley, MSRA, UMich
分割效果視頻:
https://people.eecs.berkeley.edu/~longlian/RCF_video.html
項目主頁:
https://rcf-video.github.io/
代碼鏈接:
https://github.com/TonyLianLong/RCF-UnsupVideoSeg

視頻物體分割真的可以不需要人類監(jiān)督嗎?
視頻分割一直是重標(biāo)注的一個 task,可是要標(biāo)出每一幀上的物體是非常耗時費力的。然而人類可以輕松地分割移動的物體,而不需要知道它們是什么類別。為什么呢?
Gestalt 定律嘗試解釋人類是怎么分割一個場景的,其中有一條定律叫做 Common Fate,即移動速度相同的物體屬于同一類別。比如一個箱子從左邊被拖到右邊,箱子上的點是均勻運動的,人就會把這個部分給分割出來理解。然而人并不需要理解這是個箱子來做這個事情,而且就算是嬰兒之前沒有見過箱子也能知道這是一個物體。
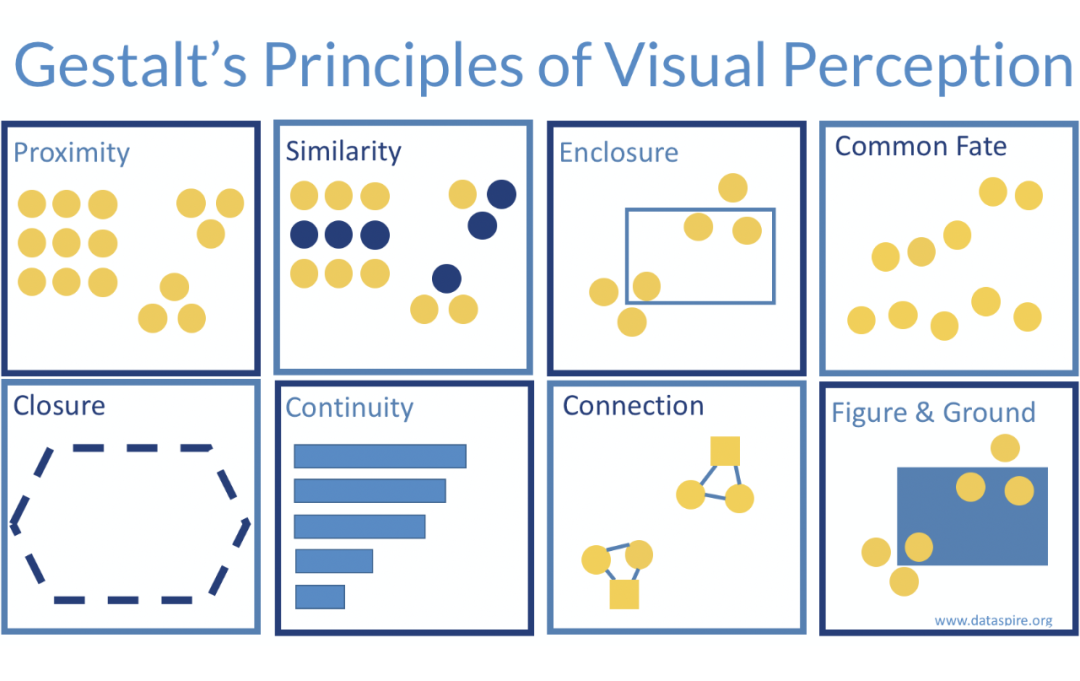

運用Common Fate來分割視頻
這個定律啟發(fā)了基于運動的無監(jiān)督分割。然而,Common Fate 并不是物體性質(zhì)的可靠指標(biāo):關(guān)節(jié)可動(articulated)/可變形物體(deformable objects)的一些 part 可能不以相同速度移動,而物體的陰影/反射(shadows/reflections)始終隨物體移動,但并非其組成部分。
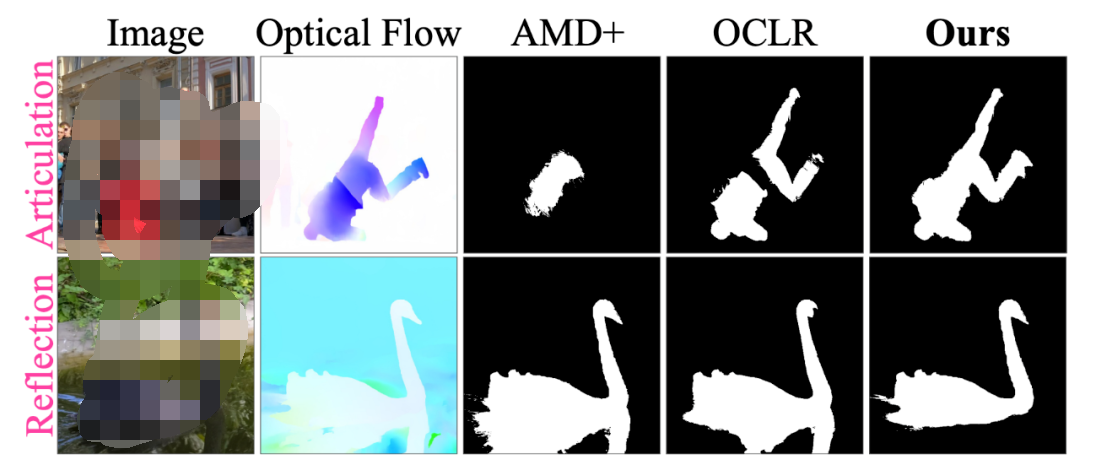
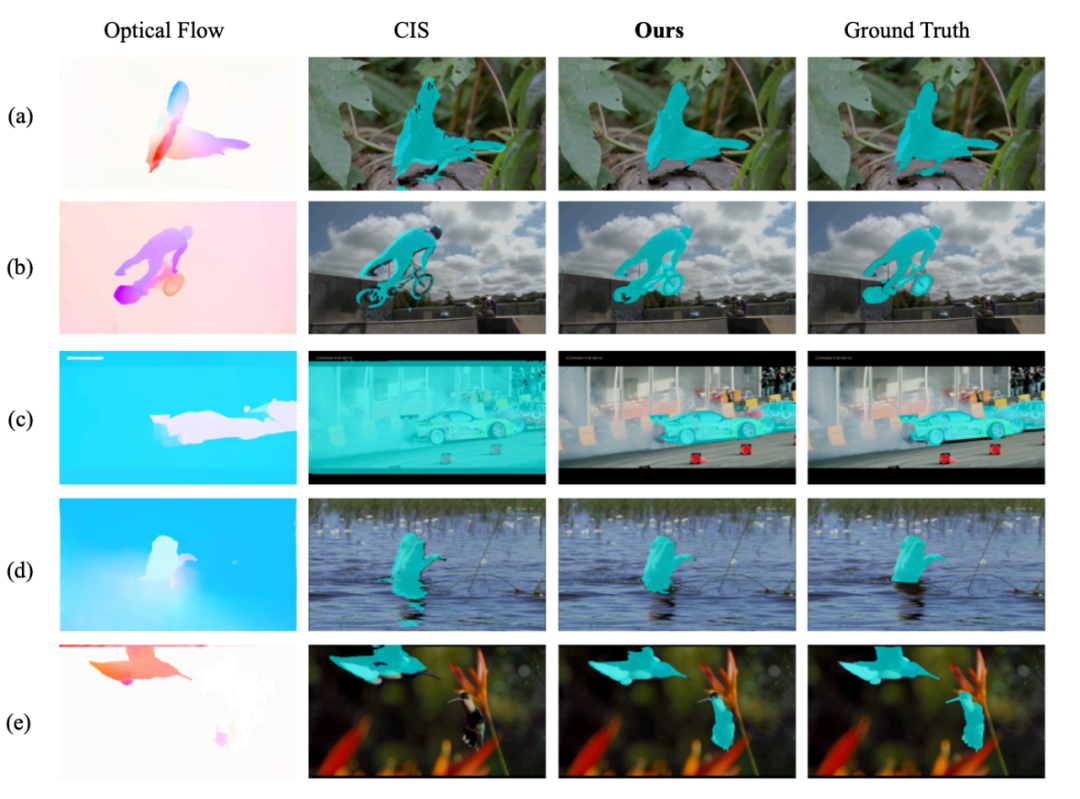
舉個例子,下面這個人的腿和身子的運動是不同的(Optical Flow 可視化出來顏色不同)。這很常見,畢竟人有關(guān)節(jié)嘛(articulated),要是這個處理不了的話,很多視頻都不能分割了。然而很多 baseline 是處理不了這點的(例如 AMD+ 和 OCLR),他們把人分割成了幾個部分。

還有就是影子和反射,比如上面這只天鵝,它的倒影跟它的運動是一致的(Optical Flow 可視化顏色一樣),所以之前的方法認為天鵝跟倒影是一個物體。很多視頻里是有這類現(xiàn)象的(畢竟大太陽下物體都有個影子嘛),如果這個處理不了的話,很多視頻也不能分割了。

那怎么解決?放松。Relax.
長話短說,那我們的方法是怎么解決這個問題的呢?無監(jiān)督學(xué)習(xí)的一個特性是利用神經(jīng)網(wǎng)絡(luò)自己內(nèi)部的泛化和擬合能力進行學(xué)習(xí)。既然 Common Fate 有自己的問題,那么我們沒有必要強制神經(jīng)網(wǎng)絡(luò)去擬合 Common Fate。于是我們提出了 Relaxed Common Fate,通過一個比較弱的學(xué)習(xí)方式讓神經(jīng)網(wǎng)絡(luò)真正學(xué)到物體的特性而不是 noise。
具體來說,我們的方法認為物體運動由兩部分組成:物體總體的 piecewise-constant motion (也就是 Common Fate)和物體內(nèi)部的 segment motion。比如你看下圖這個舞者,他全身的運動就可以被理解成 piecewise-constant motion 來建模,手部腿部這些運動就可以作為 residual motion 進行擬合,最后合并成一個完整的 flow,跟 RAFT 生成的 flow 進行比較來算 loss。我們用的 RAFT 是用合成數(shù)據(jù)(FlyingChairs 和 FlyingThings)進行訓(xùn)練的,不需要人工標(biāo)注。
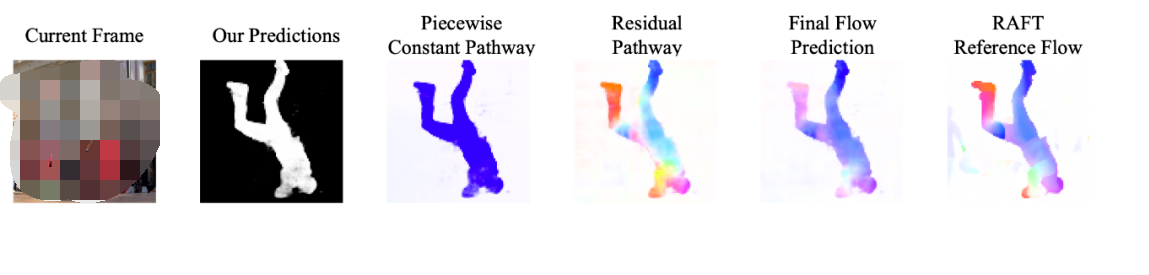

Relaxed Common Fate
首先我們使用一個 backbone 來進行特征提取,然后通過一個簡單的 full-convolutional network 獲得 Predicted Masks (下圖里的下半部分),和一般的分割框架是一樣的,也可以切換成別的框架。 那我們怎么優(yōu)化這些 Masks 呢?我們先提取、合并兩幀的特征,放入一個 residual flow prediction head 來獲得 Residual Flow (下圖里的上半部分)。 然后我們對 RAFT 獲得的 Flow 用 Predicted Masks 進行 Guided Pooling,獲得一個 piecewise-constant flow,再加上預(yù)測的 residual flow,就是我們的 flow prediction 了。最后把 flow prediction 和 RAFT 獲得的 Flow 的差算一個 L1 norm Loss 進行優(yōu)化,以此來學(xué)習(xí) segmentation。 在測試的時候,只有 Predicted Masks 是有用的,其他部分是不用的。
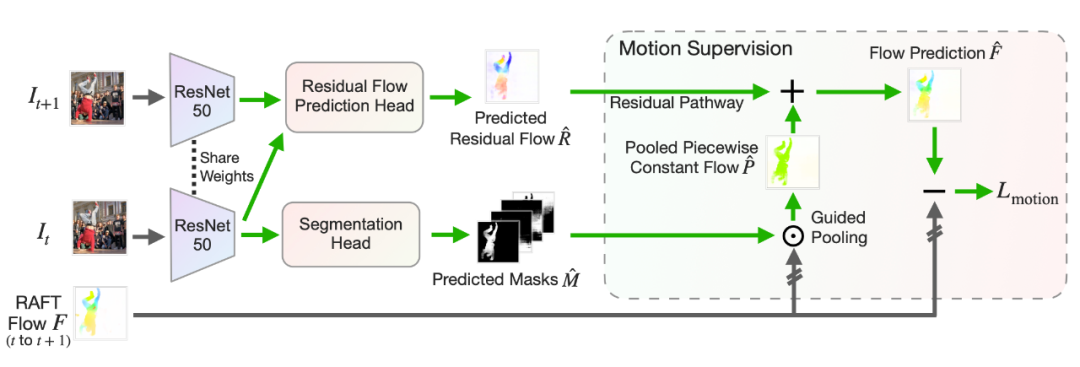 ?
?這里的 Residual Flow 會盡量初始化得小一些,來鼓勵先學(xué) piecewise-constant 的部分(有點類似 ControlNet),再慢慢學(xué)習(xí) residual 部分。

引入Appearance信息來幫助無監(jiān)督視頻分割
光是 Relaxed Common Fate 就能在 DAVIS 上相對 baseline 提 5%了,但這還不夠。前面說 Relaxed Common Fate 的只用了 motion 而沒有使用 appearance 信息。
讓我們再次回到上面這個例子。這個舞者的手和身子是一個顏色,然而 AMD+ 直接把舞者的手忽略了。下面這只天鵝和倒影明明在 appearance 上差別這么大,卻在 motion 上沒什么差別。如果整合 appearance 和 motion,是不是能提升分割質(zhì)量呢?
因此我們引入了 Appearance 來進行進一步的監(jiān)督。在學(xué)習(xí)完 motion 信息之后,我們直接把取得的 Mask 進行兩步優(yōu)化:一個是 low-level 的 CRF refinement,強調(diào)顏色等細節(jié)一致的地方應(yīng)該屬于同一個 mask(或背景),一個是 semantic constraint,強調(diào) Unsupervised Feature 一直的地方應(yīng)該屬于同一個 mask。
把優(yōu)化完的 mask 再和原 mask 進行比較,計算 L2 Loss,再更新神經(jīng)網(wǎng)絡(luò)。這樣訓(xùn)練的模型的無監(jiān)督分割能力可以進一步提升。具體細節(jié)歡迎閱讀原文。
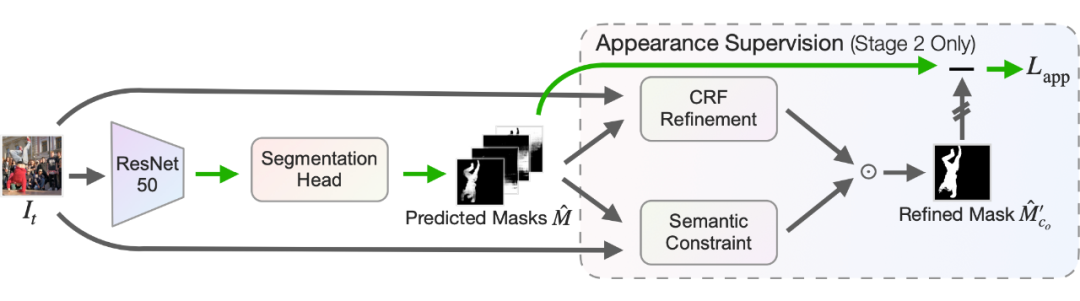

無監(jiān)督調(diào)參
很多無監(jiān)督方法都需要使用有標(biāo)注的數(shù)據(jù)集來調(diào)參,而我們的方法提出可以利用前面說的 motion 和 appearance 的一致性來進行調(diào)參。簡單地說,motion 學(xué)習(xí)出的 mask 在 appearance 上不一致代表這個參數(shù)可能不是最優(yōu)的。具體方法是在 Unsupervised Feature 上計算 Normalized Cuts (但是不用算出最優(yōu)值),Normalized Cuts 越小越代表分割效果好。原文里面對此有詳細描述。

方法效果
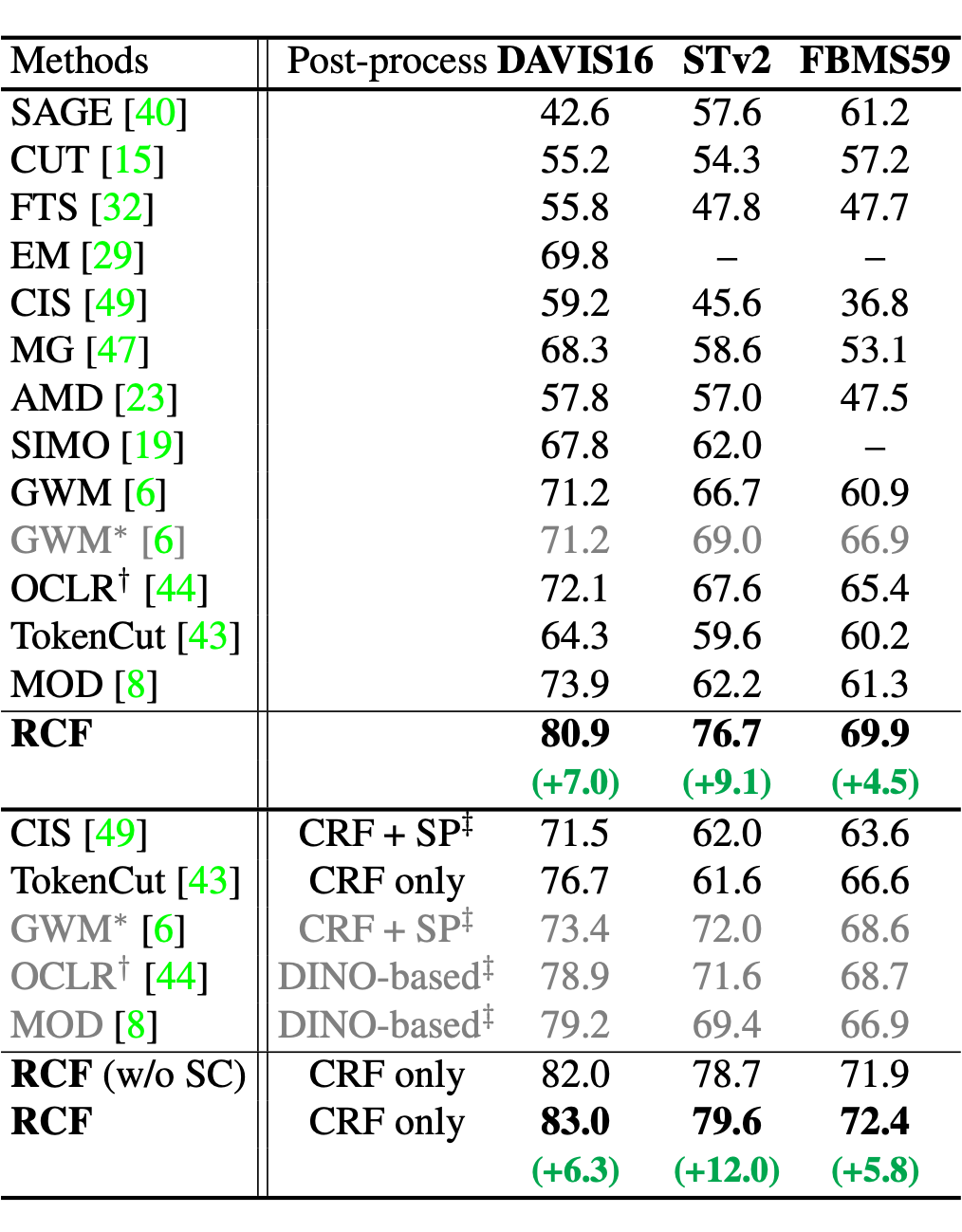
無論是否有 Post-processing,我們的方法在三個視頻分割數(shù)據(jù)集上都有很大提升,在 STv2 上更是提升了 12%。
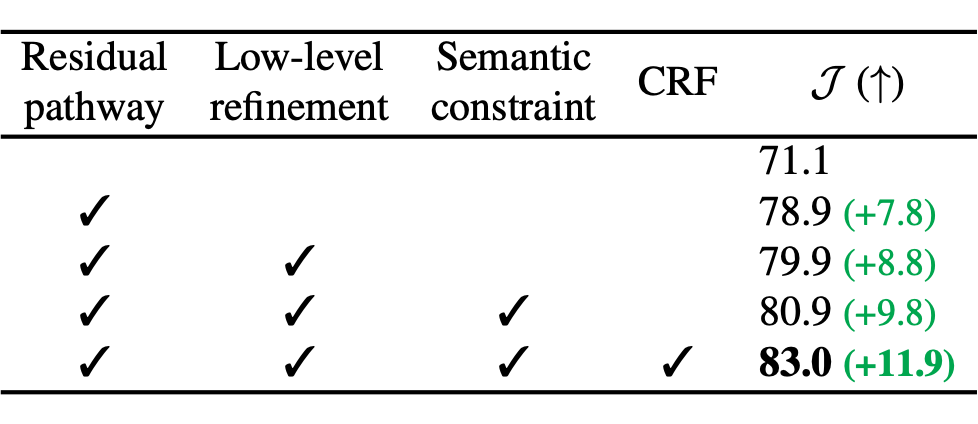
Ablation 可以看出 Residual pathway (Relaxed Common Fate)的貢獻是最大的,其他部分總計貢獻了 11.9% 的增長。
Visualizations




總結(jié)
這篇 CVPR 2023 文章研究了完全不需要標(biāo)注的視頻物體分割。通過 Relaxed Common Fate 來利用 motion 信息,再通過改進和利用 appearance 信息來進一步優(yōu)化,RCF 模型在 DAVIS16/STv2/FBMS59 上提升了 7/9/5%。文章里還提出了不需要標(biāo)注的調(diào)參方法。代碼和模型已公開可用。
原文標(biāo)題:CVPR 2023 | 完全無監(jiān)督的視頻物體分割 RCF
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2909文章
44578瀏覽量
372912
原文標(biāo)題:CVPR 2023 | 完全無監(jiān)督的視頻物體分割 RCF
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
畫面分割器怎么調(diào)試
畫面分割器怎么連接
畫面分割器和視頻分配器有何區(qū)別
畫面分割器和分屏器有什么區(qū)別
畫面分割器的主要功能
圖像分割和語義分割的區(qū)別與聯(lián)系
圖像分割與語義分割中的CNN模型綜述
機器人視覺技術(shù)中常見的圖像分割方法
機器人視覺技術(shù)中圖像分割方法有哪些
ESP8685的射頻部分完全無法使用了怎么解決?
OpenCV攜Orbbec 3D相機亮相CVPR 2024,加速AI視覺創(chuàng)新
AI視頻年大爆發(fā)!2023年AI視頻生成領(lǐng)域的現(xiàn)狀全盤點

Meta發(fā)布新型無監(jiān)督視頻預(yù)測模型“V-JEPA”
語言模型的弱監(jiān)督視頻異常檢測方法
- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論