 基于擴散模型的圖像生成過程
基于擴散模型的圖像生成過程
近年來,擴散模型在文本到圖像生成方面取得了巨大的成功,實現了更高圖像生成質量,提高了推理性能,也可以激發擴展創作靈感。
不過僅憑文本來控制圖像的生成往往得不到想要的結果,比如具體的人物姿勢、面部表情等很難用文本指定。
最近,谷歌發布了MediaPipe Diffusion插件,可以在移動設備上運行「可控文本到圖像生成」的低成本解決方案,支持現有的預訓練擴散模型及其低秩自適應(LoRA)變體
背景知識
基于擴散模型的圖像生成過程可以認為是一個迭代去噪過程。
從噪聲圖像開始,在每個步驟中,擴散模型會逐漸對圖像進行降噪以生成符合目標概念的圖像,將文本提示作為條件可以大大提升圖像生成的效果。
對于文本到圖像生成,文本嵌入通過交叉注意層連接到圖像生成模型上,不過仍然有部分信息難以通過文本提示來描述,比如物體的位置和姿態等。
為了解決這個問題,研究人員提出引入額外的模型添加到擴散模型中,在條件圖像中注入控制信息。
常用的控制文生圖方法包括:
1. 即插即用(Plug-and-Play)用到去噪擴散隱式模型(DDIM)inversion方法,從輸入圖像開始反轉生成過程來導出初始噪聲輸入,然后采用擴散模型(Stable Diffusion1.5的情況下需要8.6億參數)對來自輸入圖像的條件進行編碼。
即插即用從復制的擴散中提取具有自注意力的空間特征,并將其注入到文本轉圖像的擴散過程中。
2. ControlNet會創建擴散模型編碼器的一個可訓練副本,通過零初始化參數后的卷積層連接,將傳遞到解碼器層的條件信息進行編碼。
3. T2I Adapter是一個較小的網絡(7700萬參數),在可控生成中可以實現類似的效果,只需要將條件圖像作為輸入,其輸出在所有擴散迭代中共享。
不過T2I適配器模型并不是為便攜式移動設備設計的。
MediaPipe Diffusion插件
為了使條件生成更高效、可定制且可擴展,研究人員將MediaPipe擴散插件設計為一個單獨的網絡:
1. 可插入(Plugable):可以很容易地與預訓練基礎模型進行連接;
2. 從零開始訓練(Trained from scratch):不使用來自基礎模型的預訓練權重;
3. 可移植性(Portable):可以在移動設備上運行基礎模型,并且推理成本相比原模型來說可以忽略不計。

即插即用、ControlNet、T2I適配器和MediaPipe擴散插件的對比,*具體數字會根據選用模型不同而發生變化
簡單來說,MediaPipe擴散插件就是一個用于文本到圖像生成的,可在便攜式設備上運行的模型,從條件圖像中提取多尺度特征,并添加到相應層次擴散模型的編碼器中;當連接到文生圖擴散模型時,插件模型可以向圖像生成提供額外的條件信號。
插件網絡是一個輕量級的模型,只有600萬參數,使用MobileNetv2中的深度卷積和反向瓶頸(inverted bottleneck)在移動設備上實現快速推理。
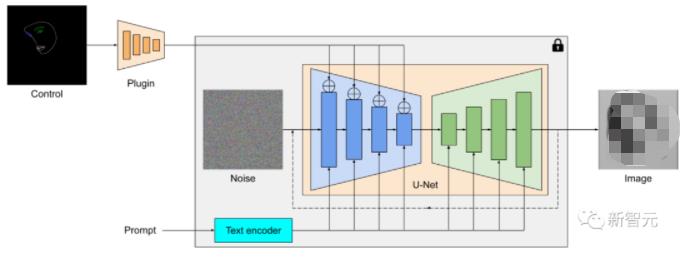
MediaPipe擴散模型插件是一個單獨的網絡,輸出可以插入到預訓練的文本到圖像生成模型中,提取的特征應用于擴散模型的相關下采樣層(藍色)。
與ControlNet不同,研究人員在所有擴散迭代中注入相同的控制功能,所以對于圖像生成過程只需要運行一次插件,節省了計算量。
下面的例子中可以看到,控制效果在每個擴散步驟都是有效的,即使在前期迭代步中也能夠控制生成過程;更多的迭代次數可以改善圖像與文本提示的對齊,并生成更多的細節。
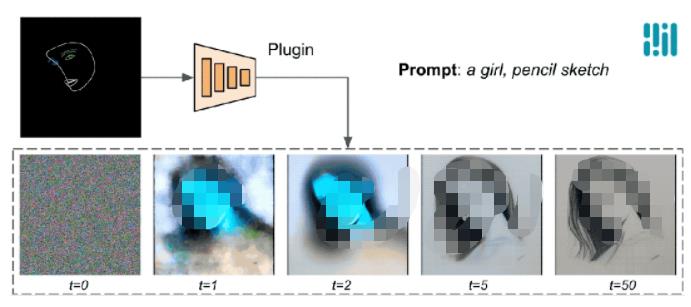
使用MediaPipe擴散插件進行生成過程的演示
示例
在這項工作中,研究人員開發了基于擴散的文本到圖像生成模型與MediaPipe face landmark,MediaPipe holistic landmark,深度圖和Canny邊緣的插件。
對于每個任務,從超大規模的圖像-文本數據集中選擇約10萬張圖像,并使用相應的MediaPipe解決方案計算控制信號,使用PaLI優化后的描述來對插件進行訓練。
Face Landmark
MediaPipe Face Landmarker任務計算人臉的478個landmark(具有注意力)。
研究人員使用MediaPipe中的drawing utils來渲染人臉,包括臉部輪廓、嘴巴、眼睛、眉毛和虹膜,并使用不同的顏色進行表示。
下面這個例子展現了通過調節面網格和提示隨機生成的樣本;作為對比,ControlNet和Plugin都可以在給定條件下控制文本到圖像的生成。
用于文本到圖像生成的Face-landmark插件,與ControlNet進行比較。
Holistic Landmark
MediaPipe Holistic Landmark任務包括身體姿勢、手和面部網格的landmark,可以通過調節整體特征來生成各種風格化的圖像。

用于文本到圖像生成的Holistic landmark插件。
深度
深度插件的文本到圖像生成。
Canny Edge
用于生成文本到圖像的Canny-edge插件。
評估
研究人員對face landmark插件進行定量評估以證明該模型的性能,評估數據集包含5000張人類圖像,使用的評估指標包括Fréchet起始距離(FID)和CLIP分數。
基礎模型使用預訓練的文本到圖像擴散模型Stable Diffusion v1.5
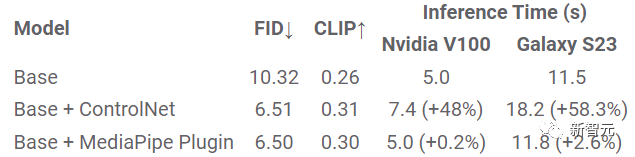
FID、CLIP和推理時間的定量比較
從實驗結果中的FID和CLIP分數來看,ControlNet和MediaPipe擴散插件生成的樣本質量比基礎模型好得多。
與ControlNet不同,插件模型只需要為每個生成的圖像運行一次,不需要在每個去噪步中都運行,所以推理時間只增加了2.6%
研究人員在服務器機器(使用Nvidia V100 GPU)和移動端設備(Galaxy S23)上測量了三種模型的性能:在服務器上,使用50個擴散步驟運行所有三個模型;在移動端上,使用MediaPipe圖像生成應用程序運行20個擴散步驟。
與ControlNet相比,MediaPipe插件在保持樣本質量的同時,在推理效率方面表現出明顯的優勢。
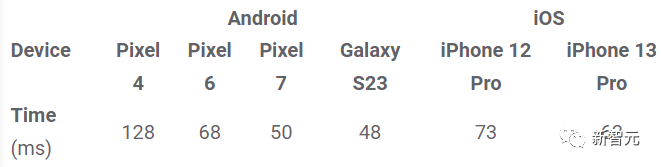
插件在不同移動的設備上的推理時間(ms)
總結
在這項工作中,研究人員提出了MediaPipe,一個可在移動端使用的、有條件的文本到圖像生成插件,將從條件圖像中提取的特征注入擴散模型,從而控制圖像的生成過程。
便攜式插件可以連接到在服務器或設備上運行的預訓練的擴散模型,通過在設備上完全運行文本到圖像生成和插件,可以更靈活地應用生成式AI
責任編輯:彭菁
-
解碼器
+關注
關注
9文章
1143瀏覽量
40718 -
編碼器
+關注
關注
45文章
3638瀏覽量
134428 -
服務器
+關注
關注
12文章
9123瀏覽量
85329 -
AI
+關注
關注
87文章
30728瀏覽量
268892 -
模型
+關注
關注
1文章
3226瀏覽量
48809
原文標題:推理效率比ControlNet高20+倍!谷歌發布MediaPipe Diffusion插件,「移動端」可用的圖像生成控制模型
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在PyTorch中使用擴散模型生成圖像

基于圖像局部結構的擴散平滑
基于生成器的圖像分類對抗樣本生成模型

基于生成式對抗網絡的圖像補全方法
擴散模型在視頻領域表現如何?
如何改進和加速擴散模型采樣的方法2
新晉圖像生成王者擴散模型
擴散模型和其在文本生成圖像任務上的應用
蒸餾無分類器指導擴散模型的方法
基于文本到圖像模型的可控文本到視頻生成

DDFM:首個使用擴散模型進行多模態圖像融合的方法

基于DiAD擴散模型的多類異常檢測工作






 工商網監
工商網監
評論