 AI芯片上利用Poly進行軟硬件優化的一些問題
AI芯片上利用Poly進行軟硬件優化的一些問題
1. 關于IR
我們在這篇文章中主要關注的是Poly的IR。在之前的內容中,我們主要基于Poly傳統的schedule tree表示介紹了如何實現AI芯片上的軟硬件優化。Google MLIR[29]針對schedule tree的不足,提出了一種簡化的Poly IR。以圖22中所示的代碼為例,用schedule tree對該部分代碼進行表示,可以得到如圖23所示的IR形式,而MLIR則是將其表示成圖24的形式。(注:圖23中的schedule tree與圖18-21表示的內容一樣,只不過這里用文字的形式表示出圖的內容,圖23中schedule后的標量維度可以對應為圖18-21中的sequence節點。)

圖22 另一個簡單用例

圖23 圖22代碼的scheduletree表示

圖24MLIR對圖22中的簡化Poly IR
通過對比可以看出,MLIR的Poly IR對循環進行了更加顯式的表達,而省略了schedule tree中的domain、schedule等信息。這種Poly IR簡化了Poly在實現循環變換之后的代碼生成過程。例如,在實現傾斜變換時,MLIR可以直接基于圖24生成如圖25所示的Poly IR。

圖25 經過傾斜后的MLIR的Poly IR
但是相比于傳統的schedule tree表示,循環變換的過程更復雜了。在schedule tree上,循環變換,如這里的傾斜,可以直接修改schedule的仿射函數來實現,可參考圖6;但在MLIR中卻要對應地修改顯式表達的循環變量及對應的下標信息。
筆者對這種方案存在兩點疑問。一是在Poly的整個流程中,雖然代碼生成也比較復雜,但是循環變換的時間開銷可能比代碼生成的開銷更高,雖然簡化了代碼生成,但是循環變換更加復雜,不知道這樣的代價是否值當?當然,Google MLIR團隊集結了編譯領域最頂級的專家和最熟悉Poly的研究團隊,筆者相信他們提出這種簡化的Poly IR肯定是經過深思熟慮的,可能后期需要向Google MLIR的Poly專家再請教之后才可能解答這個疑惑。二是這種簡化的Poly IR是為了簡化從ML Function到CFGFunction的代碼生成過程,那如果Poly變換之后的輸出不是基于LLVM IR的框架是否還有必要采用這種簡化的Poly IR?畢竟,目前深度學習框架的“IR之爭”還沒有結束。
2. 關于循環變換
Poly的調度算法[19-22]基于線性整數規劃來求解新的調度仿射函數,而這個過程中會考慮到幾乎所有的循環變換及多個循環變換之間的組合。以圖26[30]為例是線性整數規劃問題求解的示意圖,其中藍色的點表示整個空間上的整數,而圖中的斜邊可以看作是循環邊界等信息給出的約束,這些約束構成了一個可行解區間(圖中綠色部分)。那么調度問題可以抽象成在這個綠色的解空間內尋找一個目標問題(紅色箭頭)的最優解(在Poly 里,就是尋找按字典序最小的整數解)。
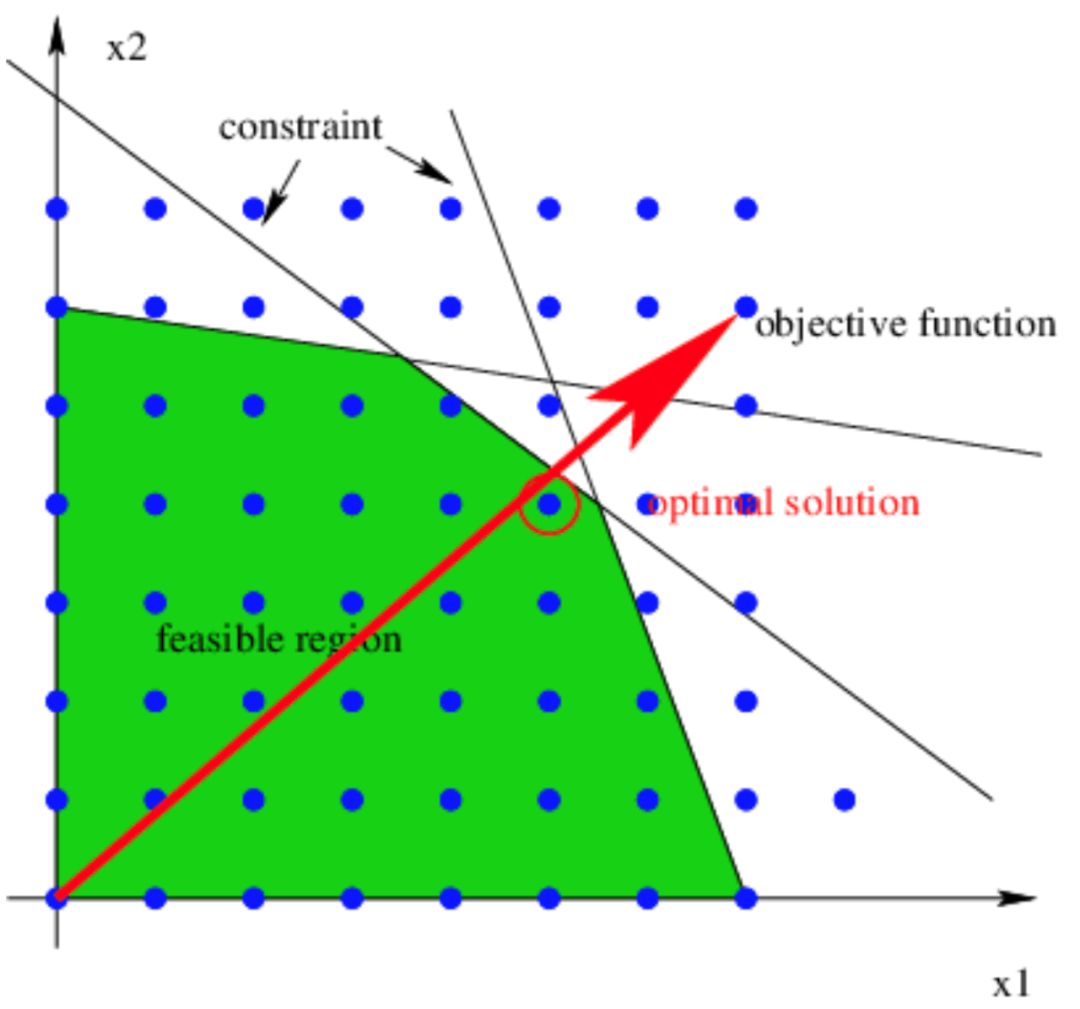
圖26 線性整數規劃問題示意圖
但是,一個重要的前提條件是Poly是面向通用程序設計語言的編譯數學模型,如果我們將Poly應用到如深度學習這樣的特定領域,是否需要考慮和通用語言一樣的循環變換集合?一個很簡單的例子是對于一個卷積算子,卷積核的循環嵌套會嵌套在輸入圖像的循環嵌套內部,而卷積核的循環維度范圍可能會比輸入圖像的循環維度范圍小很多。當Poly計算新的調度時,輸入圖像的循環維度和卷積核的循環維度可能發生傾斜變換,但這種傾斜似乎對卷積計算后面的變形、代碼生成等問題都不太友好。所以,Poly調度算法考慮的循環變換,在深度學習領域是否都需要,還是只需要比較核心的、對性能提升比較關鍵的幾種變換?如果我們減少了需要考慮的循環變換個數及其組合,也就是說在圖26中我們縮小了可行解的區間,那么求解起來是不是會更高效一些?
如果上面問題的答案是肯定的,那么筆者認為目前而言Poly能實現的循環變換中,對深度學習應用最關鍵的循環變換應該是分塊和合并(可能有待商榷)。假設只考慮分塊和合并這兩種循環變換,這種情況下問題似乎簡單一些。但是編譯優化中還有一個比較關鍵的問題就是如何決定實現的循環變換的順序。是先做合并后做分塊,還是先做分塊再做合并?事實上,對于循環變換的順序判定問題,傳統的Poly中間表示沒有給出明確的答案,而不幸的是,MLIR也沒有解決這個問題。當然,這只是極簡情況下的假設。只有分塊和合并顯然是不夠的,因為循環變換后的代碼生成還要借助distribution(分布)來保證向量化等問題的發掘。
3. 關于分塊
我們前面針對GPU、TPU以及昇騰910的架構都進行了分析,(多級)緩存是目前市場上AI芯片采用的架構趨勢,而專用AI芯片如TPU、昇騰910等專用計算單元的設計似乎也引領了AI芯片的另一種方向。可以說,在當前的AI芯片上,分塊是軟件棧必須實現的一種優化手段了。
而針對分塊這一種變換而言,仍然還有很多值得研究的問題。比如,以圖27[31]中的二維卷積為例,卷積核(kernel)通過在輸入圖像(input)上進行“滑動”來計算輸出圖像(output)的結果。當卷積核針對輸入圖像的某一個像素點(圖中深藍色的方塊)進行計算時,需要通過對其周邊特定區域的像素點(圖中淺藍色的方塊)進行加權(即卷積操作)后得到輸出圖像上的一個像素點(圖中紅色方塊)。由于卷積核需要在輸入圖像上進行滑動,這種滑動的過程在大多數情況下會導致輸入圖像的數據被多次訪問。以圖27為例,當滑動的步長(stride)為1時,除輸入圖像上第一列和最后一列的像素點之外所有的像素點都會被重復計算。如果我們按照卷積核的大小對輸入圖像進行分塊,那么分塊之后輸入圖像的每個分塊之間都會存在overlap(數據重疊)問題。如何利用Poly在深度學習應用中自動實現這種滿足數據重疊的分塊?

圖27 卷積操作示例
一種方式是采用PolyMage[6]類似的方法利用Poly的調度來求解這樣的overlap的區間,但是這種方式有可能會導致過多的冗余計算,而且用調度來求解分塊的形狀在某種程度上會使Poly的過程變得更加復雜,代碼生成亦如是;另一種方式是在schedule tree上利用特殊的節點來實現,但是目前這種方式的代碼實現都還沒有公開。
另外一個問題是在上一期的內容中有讀者提問到關于分塊和冗余計算的問題。冗余計算的確會給性能的提升帶來一定的影響,但是這種冗余計算的引入是為了實現分塊之間的并行。我們在前文提到過,并行性和局部性有的時候是沖突的,為了達到兩者之間的平衡,往往是需要作出一些其它的犧牲來達到目的[32]。而更重要的是,這種帶有冗余計算的分塊形狀是目前幾種分塊形狀中,實現降低內存開銷最有效的一種形狀。以圖28[6]為例,圖中列出來三種不同的分塊形狀,其中最左側的梯形分塊引入了冗余計算,但是這種分塊在一次分塊計算完成(水平方向)后,分塊內需要傳遞給下一次計算的活躍變量(紅色圓圈)總數最少,而其它形狀如中間的分裂分塊和最右側的平行四邊形分塊剩余的活躍變量總數都很多,無法實現有效降低內存開銷的目的。(注:圖中未分析鉆石分塊[25]和六角形分塊[26],但是這兩種分塊可以看作是分裂分塊的一種特殊形式。)

圖28 不同分塊形狀分塊內活躍變量的分析對比
除此之外,分塊面臨的問題還有很多。比如,Poly中實現的分塊都是計算的分塊,而數據分塊只是通過計算分塊和計算與數據之間的仿射函數來計算得到,這種結果能夠保證數據的分塊是最優的嗎?在分布式結構上呢?而針對TPU和昇騰910等專用AI加速芯片,多級分塊應該如何實現才能更好的發揮這些加速芯片的特征呢?
4. 關于合并
循環的合并是一個挖掘局部性的過程。我們仍然想強調的問題是,局部性和并行性是加速芯片上兩個非常重要的變換目標,但是這兩個目標有的時候是互斥的,就如我們在圖10和圖11中所示的例子一樣。合并的循環越多,破壞計算并行性的可能性越大;而如果要保持計算的并行性,可能就要放棄一些循環的合并。
然而,在不同的架構上哪些合并是最優的,似乎靜態判定是不太可能的。就如我們在第一部分分享的那樣,在CPU上生成OpenMP代碼可能一層并行就足矣,這時局部性的效果可能就比并行性的效果更好;而在GPU上,由于有兩層并行硬件的抽象,可能并行性的收益比局部性的效果更佳。所以,現在許多深度學習軟件棧也采用了Auto-tuning的方式來通過實際的多次運行來判定哪種策略是最優的。然而,即便是Auto-tuning的方式,能夠保證遍歷到所有的合并形式嗎?如何選擇一個合適的合并策略,是必須要通過調優的方式來確定嗎?利用靜態分析的方式來遍歷所有合并策略的工作也研究過[33],但是這種動態規劃的方式是不是又會帶來時間復雜度的問題?
5. 關于Poly時間復雜度和對Poly的擴展
關于Poly的時間復雜度問題,我們在上文中已經提到Poly的調度實質是線性整數規劃問題的求解過程,而實際上Poly的代碼生成過程也會涉及到線性整數規劃問題的求解。我們在討論深度學習領域是否需要所有的循環變換及其組合的時候,設想從減少循環變換的個數來減小解空間,以此來加速調度的過程;另外,MLIR的初衷也是為了降低代碼生成的復雜度。而文獻[34, 35]也試圖對特定情況或者將線性整數規劃問題簡化為線性規劃問題來降低時間復雜度。不過,諸此種種都沒有從實質上解決掉問題的關鍵,因為問題的實質仍然是NP級別的難題。想要從質上改變這個現狀,可能還需要一段比較長的時間,其它的計算機科學領域的方法比如constraint programming說不定也能是一個解決的方法。
另外,Poly的靜態仿射約束對稀疏tensor等領域的擴展也提出了挑戰。關于稀疏tensor的工作目前也有了一定的研究[36, 37],但Poly無法直接應用于含有非規則下標的tensor的情況,怎么樣在這個領域對Poly進行擴展也可能是深度學習利用Poly優化的另一個需要解決的問題。因為Poly在解決稀疏矩陣問題的研究時,有了一定的進展[38-41],這說明Poly的non-affine擴展還是可行的,而深度學習框架的可定制性給這個問題也創造了更多的機會。
-
變換器
+關注
關注
17文章
2100瀏覽量
109354 -
交換機
+關注
關注
21文章
2645瀏覽量
99737 -
gcc編譯器
+關注
關注
0文章
78瀏覽量
3395 -
AI芯片
+關注
關注
17文章
1889瀏覽量
35074 -
OpenMP
+關注
關注
0文章
12瀏覽量
5636
發布評論請先 登錄
相關推薦
閑談Vitis AI|DPU在UltraScale平臺下的軟硬件流程(1)
【HarmonyOS HiSpark AI Camera】“智慧”電子巡察機--基于HiSpark AI Camera和STM32的無人機軟硬件系統
軟硬件協同優化,平頭哥玄鐵斬獲MLPerf四項第一
談一談對AI芯片軟硬件協同與AI編譯軟件棧的泛泛看法
利用FPGA軟硬件協同系統驗證SoC系統的過程和方法
基于FPGA的軟硬件協同測試設計影響因素分析與設計實現
軟硬件協同設計是系統芯片的基礎設計方法學
軟硬件融合的概念和內涵





 工商網監
工商網監
評論