

導(dǎo)讀繼卷積神經(jīng)網(wǎng)絡(luò)之后,Transformer又推進(jìn)了圖像識別的發(fā)展,成為視覺領(lǐng)域的又一主導(dǎo)。最近有人提出Transformer的這種優(yōu)越性應(yīng)歸功于Self-Attention的架構(gòu)本身,本文帶著質(zhì)疑的態(tài)度對Transformer進(jìn)行了仔細(xì)研究,提出了3種高效的架構(gòu)設(shè)計,將這些組件結(jié)合在一起構(gòu)建一種純粹的CNN架構(gòu),其魯棒性甚至比Transformer更優(yōu)越。

視覺Transformer最近的成功動搖了卷積神經(jīng)網(wǎng)絡(luò)(CNNs)在圖像識別領(lǐng)域十年來的長期主導(dǎo)地位。具體而言,就out-of-distribution樣本的魯棒性而言,最近的研究發(fā)現(xiàn),無論不同的訓(xùn)練設(shè)置如何,Transformer本質(zhì)上都比神經(jīng)網(wǎng)絡(luò)更魯棒。此外,人們認(rèn)為Transformer的這種優(yōu)越性在很大程度上應(yīng)該歸功于它們類似Self-Attention的架構(gòu)本身。在本文中,作者通過仔細(xì)研究Transformer的設(shè)計來質(zhì)疑這種信念。作者的發(fā)現(xiàn)導(dǎo)致了3種高效的架構(gòu)設(shè)計,以提高魯棒性,但足夠簡單,可以在幾行代碼中實現(xiàn),即:將這些組件結(jié)合在一起,作者能夠構(gòu)建純粹的CNN架構(gòu),而無需任何像Transformer一樣魯棒甚至比Transformer更魯棒的類似注意力的操作。作者希望這項工作能夠幫助社區(qū)更好地理解魯棒神經(jīng)架構(gòu)的設(shè)計。代碼:https://github.com/UCSC-VLAA/RobustCNN
對輸入圖像進(jìn)行拼接
擴(kuò)大kernel-size
減少激活層和規(guī)范化層
1、簡介
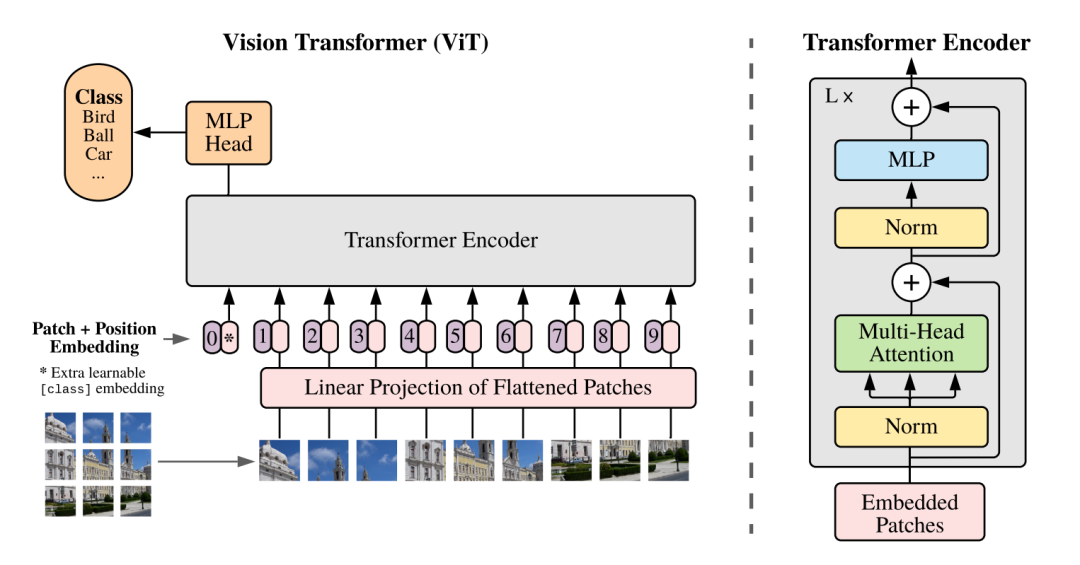
深度學(xué)習(xí)在計算機(jī)視覺中的成功很大程度上是由卷積神經(jīng)網(wǎng)絡(luò)(CNNs)推動的。從AlexNet這一里程碑式的工作開始,CNNs不斷地向計算機(jī)視覺的前沿邁進(jìn)。有趣的是,最近出現(xiàn)的視覺Transformer(ViT)挑戰(zhàn)了神經(jīng)網(wǎng)絡(luò)的領(lǐng)先地位。ViT通過將純粹的基于Self-Attention的架構(gòu)應(yīng)用于圖像Patch序列,提供了一個完全不同的路線圖。與CNN相比,ViT能夠在廣泛的視覺基準(zhǔn)上獲得有競爭力的性能。最近關(guān)于out-of-distribution魯棒性的研究進(jìn)一步加劇了神經(jīng)網(wǎng)絡(luò)和Transformer之間的爭論。與兩種模型緊密匹配的標(biāo)準(zhǔn)視覺基準(zhǔn)不同,Transformer在開箱測試時比神經(jīng)網(wǎng)絡(luò)更強(qiáng)大。此外,Bai等人認(rèn)為,這種強(qiáng)大的out-of-distribution魯棒性并沒有從中提供的高級訓(xùn)練配置中受益,而是與Transformer的類似Self-Attention的架構(gòu)內(nèi)在地聯(lián)系在一起。例如,簡單地將純CNN“升級”為混合架構(gòu)(即同時具有CNN塊和Transformer塊)可以有效地提高out-of-distribution魯棒性。盡管人們普遍認(rèn)為架構(gòu)差異是導(dǎo)致Transformer和CNNs之間魯棒性差距的關(guān)鍵因素,但現(xiàn)有的工作并沒有回答Transformer中的哪些架構(gòu)元素應(yīng)該歸因于這種更強(qiáng)的魯棒性。最相關(guān)的分析都指出,Self-Attention操作是中樞單元的Transformer塊對魯棒性至關(guān)重要。盡管如此,給定-
Transformer塊本身已經(jīng)是一個復(fù)合設(shè)計
-
Transformer還包含許多其他層(例如,Patch嵌入層),魯棒性和Transformer的架構(gòu)元素之間的關(guān)系仍然令人困惑。
-
首先,將圖像拼接成不重疊的Patch可以顯著地提高out-of-distribution魯棒性;更有趣的是,關(guān)于Patch大小的選擇,作者發(fā)現(xiàn)越大越好;
-
其次,盡管應(yīng)用小卷積核是一種流行的設(shè)計方法,但作者觀察到,采用更大的卷積核(例如,從3×3到7×7,甚至到11×11)對于確保out-of-distribution樣本的模型魯棒性是必要的;
-
最后,受最近工作的啟發(fā),作者注意到減少規(guī)范化層和激活函數(shù)的數(shù)量有利于out-of-distribution魯棒性;同時,由于使用的規(guī)范化層較少,訓(xùn)練速度可能會加快23%。
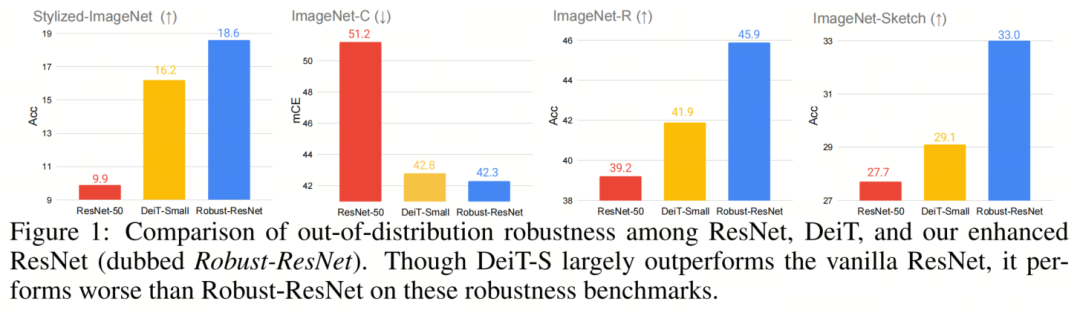 作者的實驗驗證了所有這3個體系結(jié)構(gòu)元素在一組CNN體系結(jié)構(gòu)上一致有效地提高了out-of-distribution魯棒性。據(jù)報道,最大的改進(jìn)是將所有這些集成到CNNs的架構(gòu)設(shè)計中,如圖1所示,在不應(yīng)用任何類似Self-Attention的組件的情況下,作者的增強(qiáng)型ResNet(稱為Robust-ResNet)能夠在Stylized-ImageNet上比類似規(guī)模的Transformer DeiT-S高2.4%(16.2%對18.6%),在ImageNet-C上高0.5%(42.8%對42.3%),ImageNet-R上為4.0%(41.9%對45.9%),ImageNet Sketch上為3.9%(29.1%對33.0%)。作者希望這項工作能幫助社區(qū)更好地理解設(shè)計魯棒神經(jīng)架構(gòu)的基本原理。
作者的實驗驗證了所有這3個體系結(jié)構(gòu)元素在一組CNN體系結(jié)構(gòu)上一致有效地提高了out-of-distribution魯棒性。據(jù)報道,最大的改進(jìn)是將所有這些集成到CNNs的架構(gòu)設(shè)計中,如圖1所示,在不應(yīng)用任何類似Self-Attention的組件的情況下,作者的增強(qiáng)型ResNet(稱為Robust-ResNet)能夠在Stylized-ImageNet上比類似規(guī)模的Transformer DeiT-S高2.4%(16.2%對18.6%),在ImageNet-C上高0.5%(42.8%對42.3%),ImageNet-R上為4.0%(41.9%對45.9%),ImageNet Sketch上為3.9%(29.1%對33.0%)。作者希望這項工作能幫助社區(qū)更好地理解設(shè)計魯棒神經(jīng)架構(gòu)的基本原理。2、SETTINGS
在本文中,使用ResNet和ViT對CNN和Transformer之間的魯棒性進(jìn)行了徹底的比較。2.1、CNN Block Instantiations
如圖2所示,本文作者考慮4種不同的塊實例化。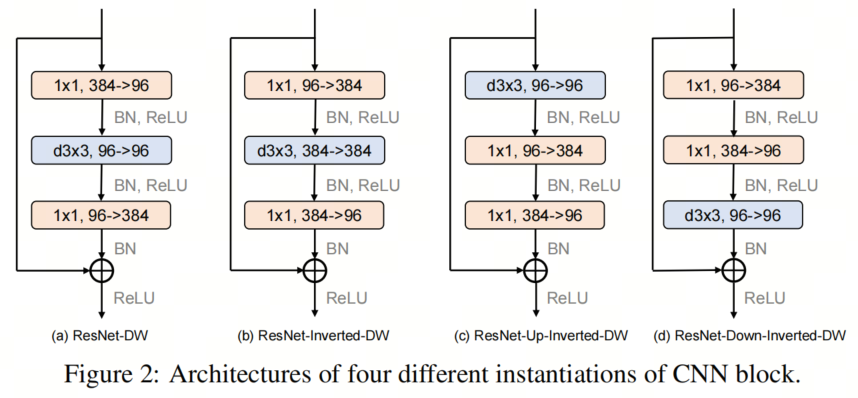
-
第1個Block是Depth-wise ResNet Bottleneck block,其中3×3卷積層被3×3深度卷積層取代;
-
第2個Block是Inverted Depth-wise ResNet Bottleneck block,其中隱藏維度是輸入維度的4倍;
-
第3個Block基于第2個Block,深度卷積層在ConvNeXT中的位置向上移動;
-
基于第2個Block,第4 Block向下移動深度卷積層的位置。
2.2、Computational Cost
在這項工作中,作者使用FLOP來測量模型大小。在這里,作者注意到,由于使用了深度卷積,用上述4個實例化塊直接替換ResNet Bottleneck 塊將顯著減少模型的總FLOP。為了減少計算成本損失并提高模型性能,遵循ResNeXT的精神,作者將每個階段的通道設(shè)置從(64,128,256,512)更改為(96,192,384,768)。 然后,作者在第3階段調(diào)整塊數(shù),以保持 Baseline 模型的總FLOP與DeiT-S大致相同。作者的 Baseline模型的最終FLOP如表1所示。除非另有說明,否則本工作中考慮的所有模型都與DEITS具有相似的規(guī)模。
然后,作者在第3階段調(diào)整塊數(shù),以保持 Baseline 模型的總FLOP與DeiT-S大致相同。作者的 Baseline模型的最終FLOP如表1所示。除非另有說明,否則本工作中考慮的所有模型都與DEITS具有相似的規(guī)模。2.3、Robustness Benchmarks
在這項工作中,作者使用以下基準(zhǔn)廣泛評估了模型在out-of-distribution魯棒性方面的性能:-
Stylized-ImageNet,它包含具有形狀-紋理沖突線索的合成圖像;
-
ImageNet-C,具有各種常見的圖像損壞;
-
ImageNet-R,它包含具有不同紋理和局部圖像統(tǒng)計的ImageNet對象類的自然呈現(xiàn);
-
ImageNet Sketch,其中包括在線收集的相同ImageNet類的草圖圖像。
2.4、Training Recipe
神經(jīng)網(wǎng)絡(luò)可以通過簡單地調(diào)整訓(xùn)練配置來實現(xiàn)更好的魯棒性。因此,在這項工作中,除非另有說明,否則作者將標(biāo)準(zhǔn)的300-epoch DeiT訓(xùn)練配置應(yīng)用于所有模型,因此模型之間的性能差異只能歸因于架構(gòu)差異。2.5、Baseline Results
為了簡單起見,作者使用“IN”、“S-IN”、”INC“、”IN-R“和”IN-SK“作為“ImageNet”、“Styleized ImageNet”,“ImageNet-C”、“ImageNet-R”和“ImageNet Sketch”的縮寫。結(jié)果如表1所示,DeiT-S表現(xiàn)出比ResNet50更強(qiáng)的魯棒性泛化。此外,作者注意到,即使配備了更強(qiáng)的深度卷積層,ResNet架構(gòu)也只能在clean圖像上實現(xiàn)相當(dāng)?shù)木龋瑫r保持明顯不如DeiT架構(gòu)的魯棒性。這一發(fā)現(xiàn)表明,視覺Transformer令人印象深刻的魯棒性的關(guān)鍵在于其架構(gòu)設(shè)計。3、COMPONENT DIAGNOSIS
3.1、PATCHIFY STEM
CNN或Transformer通常在網(wǎng)絡(luò)開始時對輸入圖像進(jìn)行下采樣,以獲得適當(dāng)?shù)奶卣鲌D大小。標(biāo)準(zhǔn)的ResNet架構(gòu)通過使用Stride為2的7×7卷積層,然后使用Stride為2中的3×3最大池化來實現(xiàn)這一點,從而降低了4倍的分辨率。另一方面,ViT采用了一種更積極的下采樣策略,將輸入圖像劃分為p×p個不重疊的Patch,并用線性層投影每個Patch。在實踐中,這是通過具有 kernel-size p和Stride p的卷積層來實現(xiàn)的,其中p通常設(shè)置為16。這里,ViT中的典型ResNet Block或Self-Attention塊之前的層被稱為Backbone。雖然之前的工作已經(jīng)研究了神經(jīng)網(wǎng)絡(luò)和Transformer中Stem設(shè)置的重要性,但沒有人從魯棒性的角度來研究這個模塊。為了進(jìn)一步研究這一點,作者將 Baseline 模型中的ResNet-style stem替換為 ViT-style patchify stem。具體來說,作者使用 kernel-size 為p和Stride為p的卷積層,其中p從4到16不等。作者保持模型的總Stride固定,因此224×224的輸入圖像將始終在最終全局池化層之前產(chǎn)生7×7的特征圖。特別地,原始ResNet在階段2、3和4中為第1個塊設(shè)置Stride=2。當(dāng)使用8×8 patchify Stem時,作者在第2階段為第1個塊設(shè)置Stride=1,當(dāng)使用16×16 patchify stem時,在第2和第3階段為第1塊設(shè)置Stride=1。為了確保公平的比較,作者在第3階段添加了額外的塊,以保持與以前類似的FLOP。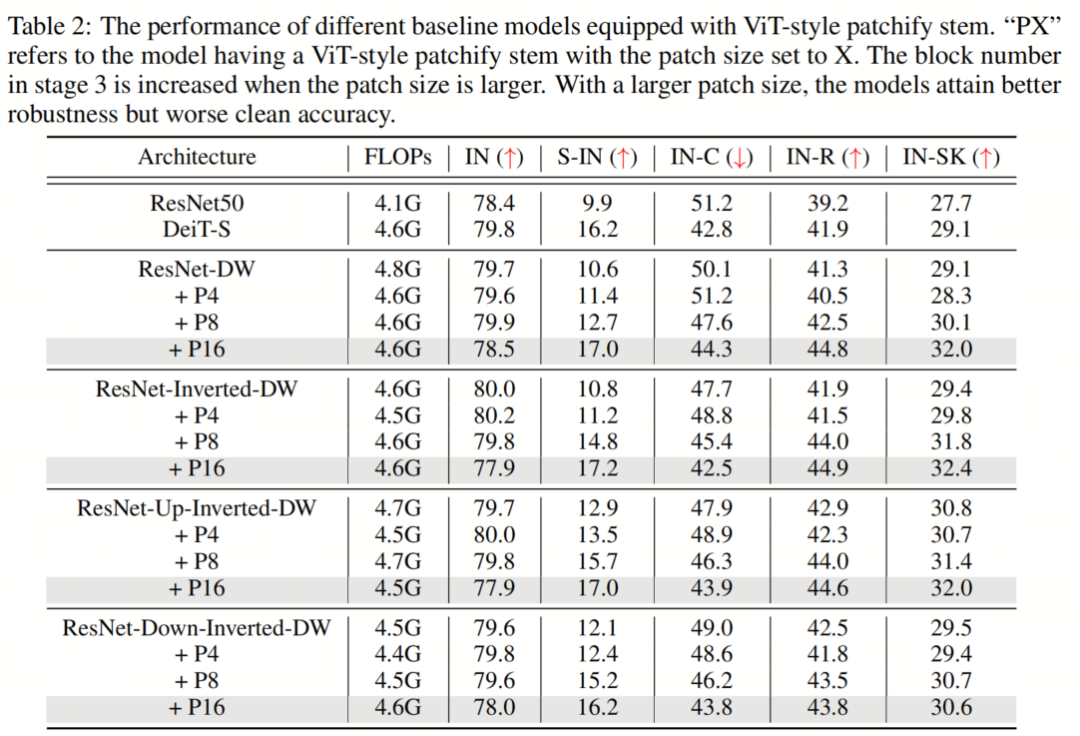 在表2中,作者觀察到,增加ViT-style Patch Stem的Patch大小會提高魯棒性基準(zhǔn)的性能,盡管可能會以clean準(zhǔn)確性為代價。具體而言,對于所有 Baseline 模型,當(dāng)Patch大小設(shè)置為8時,所有魯棒性基準(zhǔn)的性能至少提高了0.6%。當(dāng)Patch大小增加到16時,所有魯棒性基準(zhǔn)的性能提高了至少1.2%,其中最顯著的改進(jìn)是Stylized-ImageNet的6.6%。根據(jù)這些結(jié)果,作者可以得出結(jié)論,這種簡單的Patch操作在很大程度上有助于ViT的強(qiáng)大魯棒性,同時,可以在縮小CNNs和Transformers之間的魯棒性差距方面發(fā)揮重要作用。作者還對 Advanced patchify stems進(jìn)行了實驗。令人驚訝的是,雖然這些Stem提高了相應(yīng)的干凈圖像的準(zhǔn)確性,但作者發(fā)現(xiàn)它們對out-of-distribution魯棒性的貢獻(xiàn)很小。這一觀察結(jié)果表明,clean準(zhǔn)確性和out-of-distribution的魯棒性并不總是表現(xiàn)出正相關(guān)性。換言之,增強(qiáng)clean精度的設(shè)計可能不一定會帶來更好的魯棒性。強(qiáng)調(diào)了探索除了提高clean精度之外還可以提高魯棒性的方法的重要性。
在表2中,作者觀察到,增加ViT-style Patch Stem的Patch大小會提高魯棒性基準(zhǔn)的性能,盡管可能會以clean準(zhǔn)確性為代價。具體而言,對于所有 Baseline 模型,當(dāng)Patch大小設(shè)置為8時,所有魯棒性基準(zhǔn)的性能至少提高了0.6%。當(dāng)Patch大小增加到16時,所有魯棒性基準(zhǔn)的性能提高了至少1.2%,其中最顯著的改進(jìn)是Stylized-ImageNet的6.6%。根據(jù)這些結(jié)果,作者可以得出結(jié)論,這種簡單的Patch操作在很大程度上有助于ViT的強(qiáng)大魯棒性,同時,可以在縮小CNNs和Transformers之間的魯棒性差距方面發(fā)揮重要作用。作者還對 Advanced patchify stems進(jìn)行了實驗。令人驚訝的是,雖然這些Stem提高了相應(yīng)的干凈圖像的準(zhǔn)確性,但作者發(fā)現(xiàn)它們對out-of-distribution魯棒性的貢獻(xiàn)很小。這一觀察結(jié)果表明,clean準(zhǔn)確性和out-of-distribution的魯棒性并不總是表現(xiàn)出正相關(guān)性。換言之,增強(qiáng)clean精度的設(shè)計可能不一定會帶來更好的魯棒性。強(qiáng)調(diào)了探索除了提高clean精度之外還可以提高魯棒性的方法的重要性。3.2、LARGE KERNEL SIZE
將Self-Attention運算與經(jīng)典卷積運算區(qū)分開來的一個關(guān)鍵特性是,它能夠?qū)φ麄€輸入圖像或特征圖進(jìn)行運算,從而產(chǎn)生全局感受野。甚至在Vision Transformer出現(xiàn)之前,就已經(jīng)證明了捕獲長期依賴關(guān)系對神經(jīng)網(wǎng)絡(luò)的重要性。一個值得注意的例子是 Non-local 神經(jīng)網(wǎng)絡(luò),它已被證明對靜態(tài)和序列圖像識別都非常有效,即使只配備了一個non-local block。然而,CNN中最常用的方法仍然是堆疊多個3×3卷積層,以隨著網(wǎng)絡(luò)的深入逐漸增加網(wǎng)絡(luò)的感受野。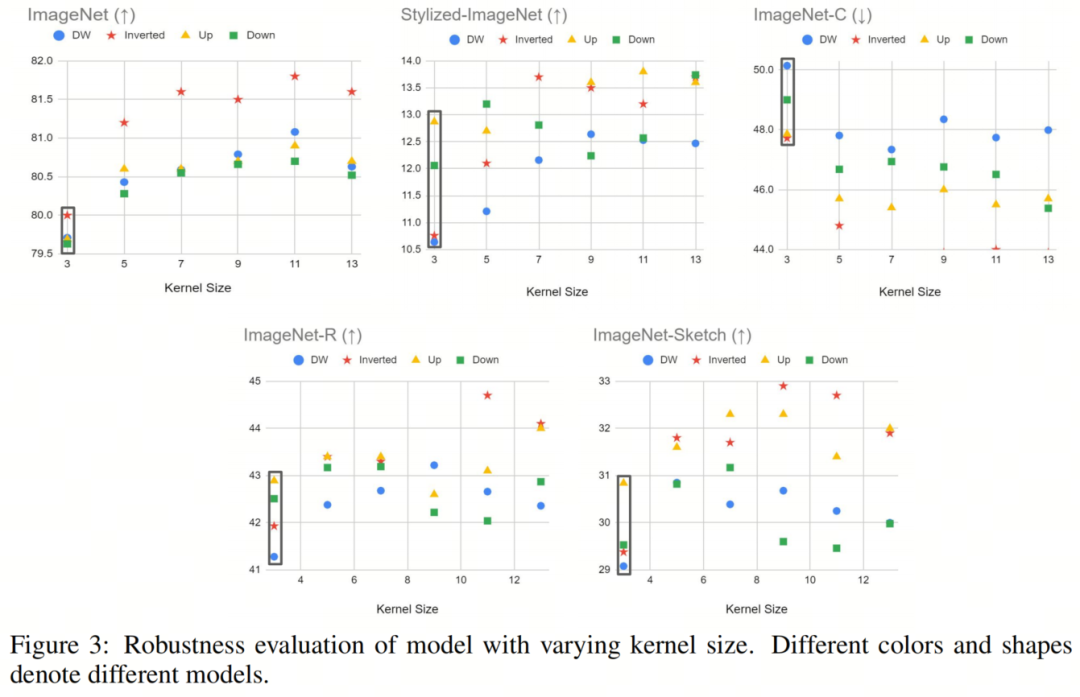
在本節(jié)中,作者旨在通過增加深度卷積層的內(nèi) kernel-size 來模擬Self-Attention塊的行為。如圖3所示,作者對不同大小的Kernel進(jìn)行了實驗,包括5、7、9、11和13,并在不同的魯棒性基準(zhǔn)上評估了它們的性能。作者的研究結(jié)果表明,較大的 kernel-size 通常會帶來更好的clean精度和更強(qiáng)的魯棒性。盡管如此,作者也觀察到,當(dāng) kernel-size 變得太大時,性能增益會逐漸飽和。
值得注意的是,使用具有較大Kernel的(標(biāo)準(zhǔn))卷積將導(dǎo)致計算量的顯著增加。例如,如果作者直接將ResNet50中的 kernel-size 從3更改為5,則生成的模型的總FLOP將為7.4G,這比Transformer的對應(yīng)模型大得多。
然而,在使用深度卷積層的情況下,將內(nèi) kernel-size 從3增加到13通常只會使FLOP增加0.3G,與DeiT-S(4.6G)的FLOP相比相對較小。
這里唯一的例外情況是ResNet-Inverted-DW:由于其Inverted Bottleneck設(shè)計中的大通道尺寸,將 kernel-size 從3增加到13帶來了1.4G FLOP的增加,這在某種程度上是一個不公平的比較。順便說一句,使用具有大Patchvsize的Patch Stem可以減輕大 kernel-size 所產(chǎn)生的額外計算成本。
因此,作者的最終模型仍將處于與DeiT-S相同的規(guī)模。對于具有多個擬議設(shè)計的模型。
3.3、減少激活層和規(guī)范化層
與ResNet塊相比,典型的Vision Transformer塊具有更少的激活和規(guī)范化層。這種架構(gòu)設(shè)計選擇也被發(fā)現(xiàn)在提高ConvNeXT的性能方面是有效的。受此啟發(fā),作者采用了在所有4個塊實例化中減少激活和規(guī)范化層的數(shù)量的想法,以探索其對魯棒性泛化的影響。具體而言,ResNet塊通常包含一個規(guī)范化層和每個卷積層之后的一個激活層,導(dǎo)致一個塊中總共有3個規(guī)范化和激活層。在作者的實現(xiàn)中,作者從每個塊中移除了兩個規(guī)范化層和激活層,從而只產(chǎn)生了一個規(guī)范化和激活層。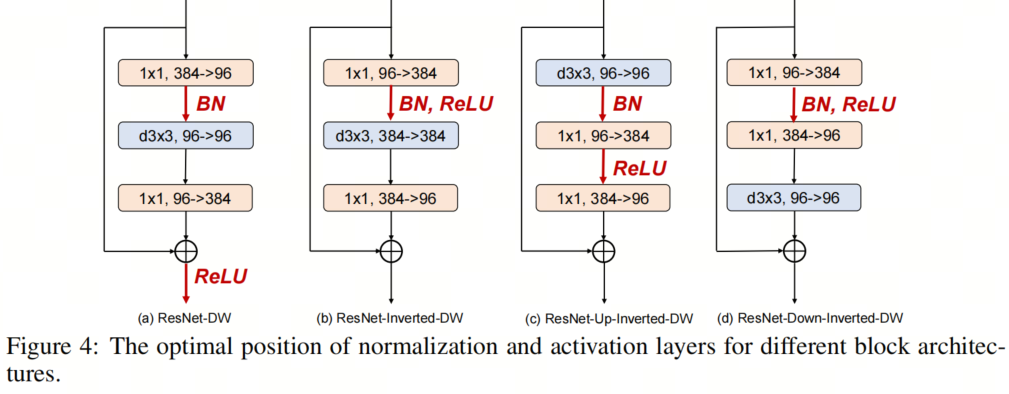 如圖4所示,作者用去除激活層和規(guī)范化層的不同組合進(jìn)行了實驗,并根據(jù)經(jīng)驗發(fā)現(xiàn),在通道維度擴(kuò)展的卷積層之后只留下一個激活層(即輸出通道的數(shù)量大于輸入通道的數(shù)量),在第一次卷積之后留下一個規(guī)范化層,可以獲得最佳結(jié)果層最佳配置。具有不同去除層的模型的結(jié)果如表3和表4所示。
如圖4所示,作者用去除激活層和規(guī)范化層的不同組合進(jìn)行了實驗,并根據(jù)經(jīng)驗發(fā)現(xiàn),在通道維度擴(kuò)展的卷積層之后只留下一個激活層(即輸出通道的數(shù)量大于輸入通道的數(shù)量),在第一次卷積之后留下一個規(guī)范化層,可以獲得最佳結(jié)果層最佳配置。具有不同去除層的模型的結(jié)果如表3和表4所示。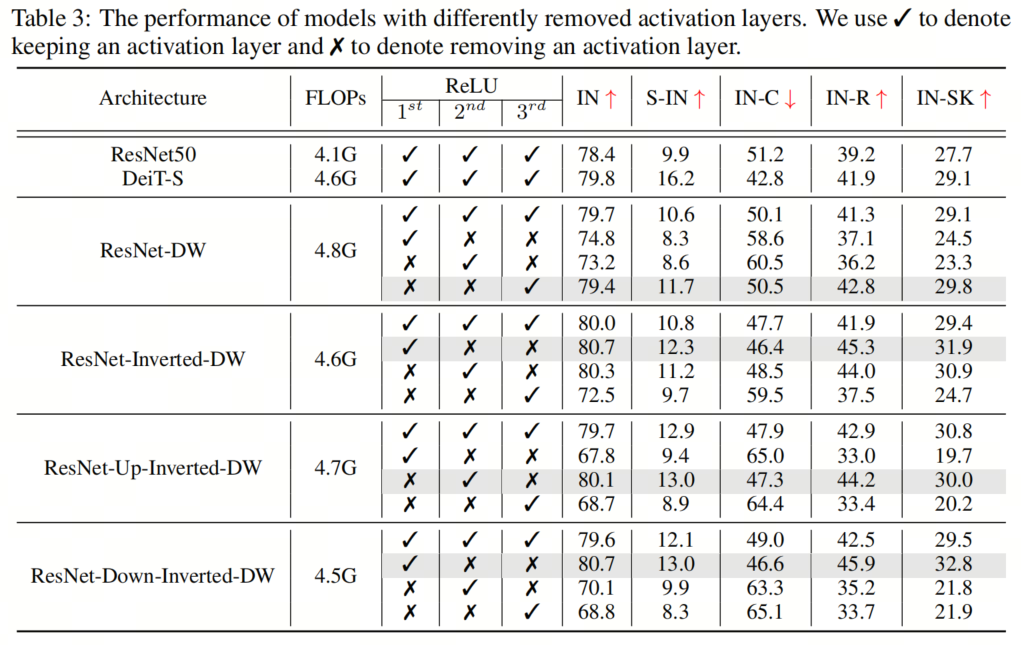
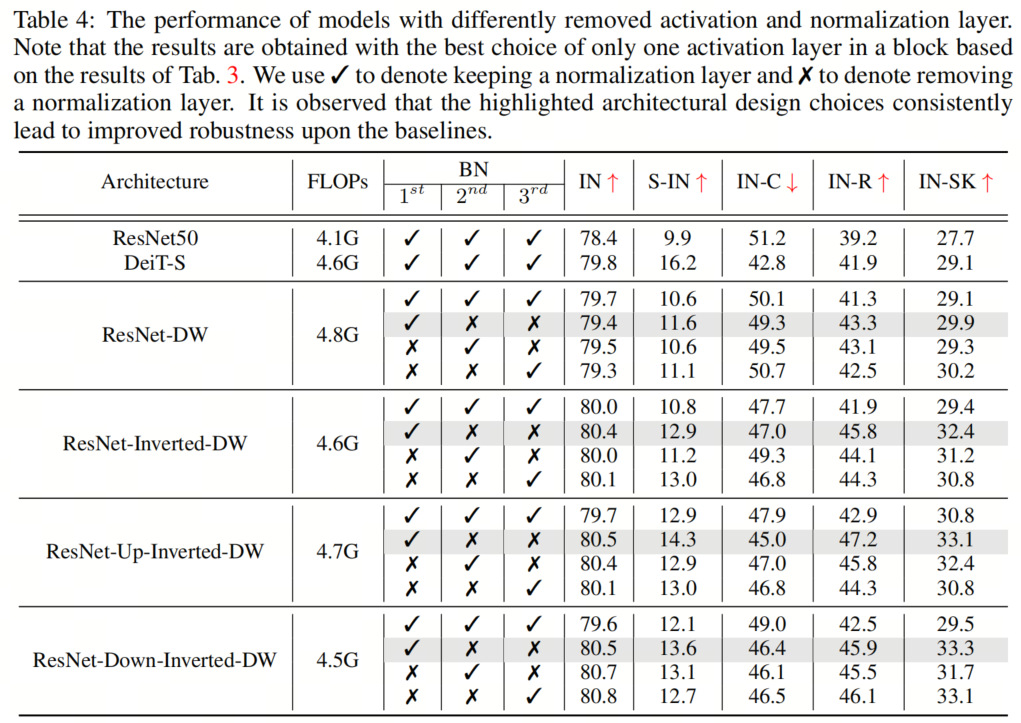 例如,對于 ResNet-Up-Inverted-DW,作者觀察到Stylized-ImageNet上有1.4%的顯著改進(jìn)(14.3%對12.9%),ImageNet-C上有2.9%的改進(jìn)(45.0%對47.9%),ImageNet-R上有4.3%的改進(jìn)(47.2%對42.9%),而ImageNet Sketch上有2.3%的改進(jìn)(33.1%對30.8%)。此外,減少規(guī)范化層的數(shù)量會降低GPU內(nèi)存使用率并加快訓(xùn)練,通過簡單地去除幾個規(guī)范化層來實現(xiàn)高達(dá)23%的加速。
例如,對于 ResNet-Up-Inverted-DW,作者觀察到Stylized-ImageNet上有1.4%的顯著改進(jìn)(14.3%對12.9%),ImageNet-C上有2.9%的改進(jìn)(45.0%對47.9%),ImageNet-R上有4.3%的改進(jìn)(47.2%對42.9%),而ImageNet Sketch上有2.3%的改進(jìn)(33.1%對30.8%)。此外,減少規(guī)范化層的數(shù)量會降低GPU內(nèi)存使用率并加快訓(xùn)練,通過簡單地去除幾個規(guī)范化層來實現(xiàn)高達(dá)23%的加速。4、組件組合
在本節(jié)中,作者將探討組合所有建議的組件對模型性能的影響。具體來說,作者采用了16×16的Patch Stem和11×11的 kernel-size ,以及為所有架構(gòu)放置規(guī)范化和激活層的相應(yīng)最佳位置。這里的一個例外是ResNet-Inverted-DW,作者使用7×7的 kernel-size ,因為作者根據(jù)經(jīng)驗發(fā)現(xiàn),使用過大的 kernel-size (例如,11×11)會導(dǎo)致不穩(wěn)定的訓(xùn)練。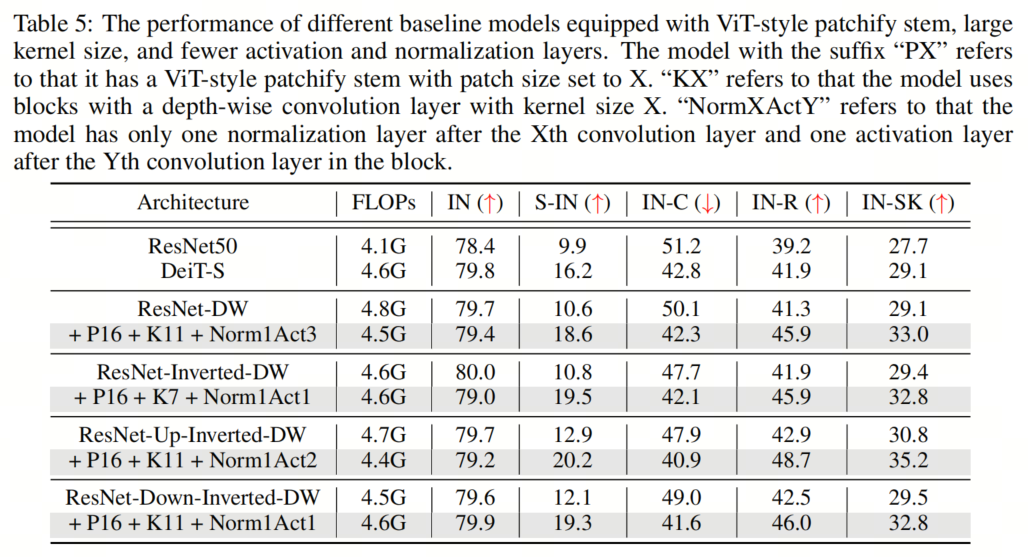
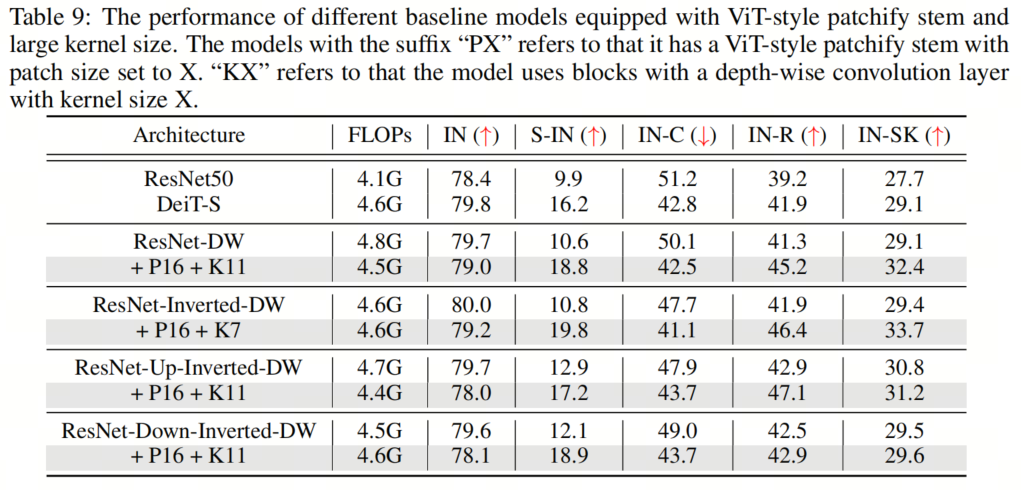
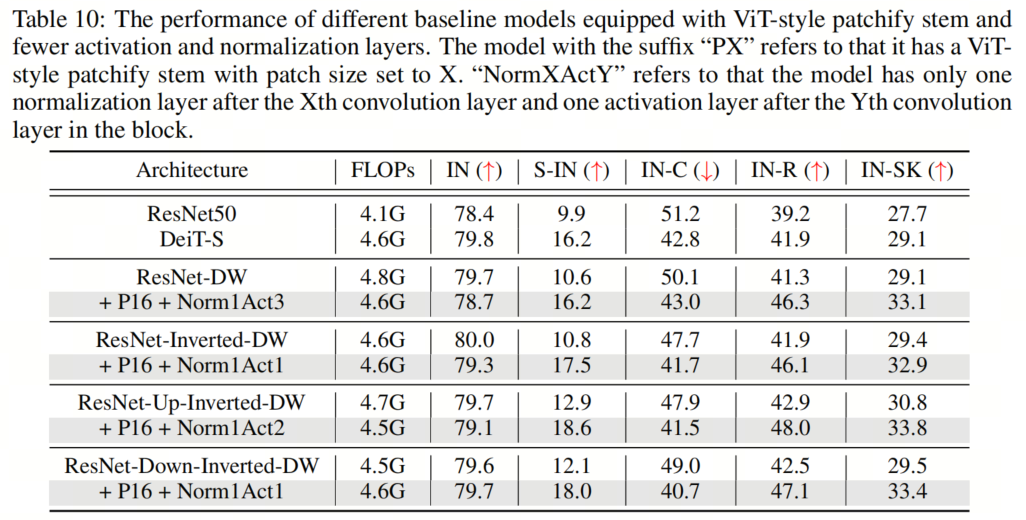
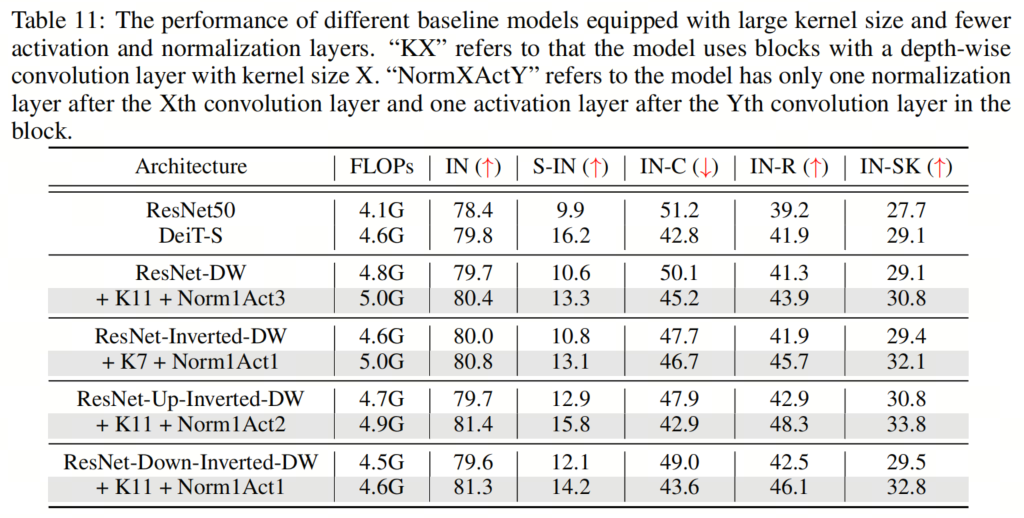 如表5和表9、表10、表11所示,作者可以看到這些簡單的設(shè)計不僅在單獨應(yīng)用于ResNet時效果良好,而且在一起使用時效果更好。此外,通過采用所有3種設(shè)計,ResNet現(xiàn)在在所有4個out-of-distribution基準(zhǔn)測試上都優(yōu)于DeiT。這些結(jié)果證實了作者提出的架構(gòu)設(shè)計的有效性,并表明沒有任何類Self-Attention塊的純CNN可以實現(xiàn)與ViT一樣好的魯棒性。
如表5和表9、表10、表11所示,作者可以看到這些簡單的設(shè)計不僅在單獨應(yīng)用于ResNet時效果良好,而且在一起使用時效果更好。此外,通過采用所有3種設(shè)計,ResNet現(xiàn)在在所有4個out-of-distribution基準(zhǔn)測試上都優(yōu)于DeiT。這些結(jié)果證實了作者提出的架構(gòu)設(shè)計的有效性,并表明沒有任何類Self-Attention塊的純CNN可以實現(xiàn)與ViT一樣好的魯棒性。5、知識蒸餾
知識蒸餾是一種通過轉(zhuǎn)移更強(qiáng)的教師模型的知識來訓(xùn)練能力較弱的學(xué)生模型的技術(shù)。通常情況下,學(xué)生模型可以通過知識蒸餾獲得與教師模型相似甚至更好的性能。然而,直接應(yīng)用知識蒸餾讓ResNet-50(學(xué)生模型)向DeiT-S(教師模型)學(xué)習(xí)在增強(qiáng)魯棒性方面效果較差。
令人驚訝的是,當(dāng)模型角色切換時,學(xué)生模型DeiT-S在一系列魯棒性基準(zhǔn)上顯著優(yōu)于教師模型ResNet-50,從而得出結(jié)論,實現(xiàn)DeiT良好魯棒性的關(guān)鍵在于其架構(gòu),因此不能通過知識蒸餾將其轉(zhuǎn)移到ResNet。
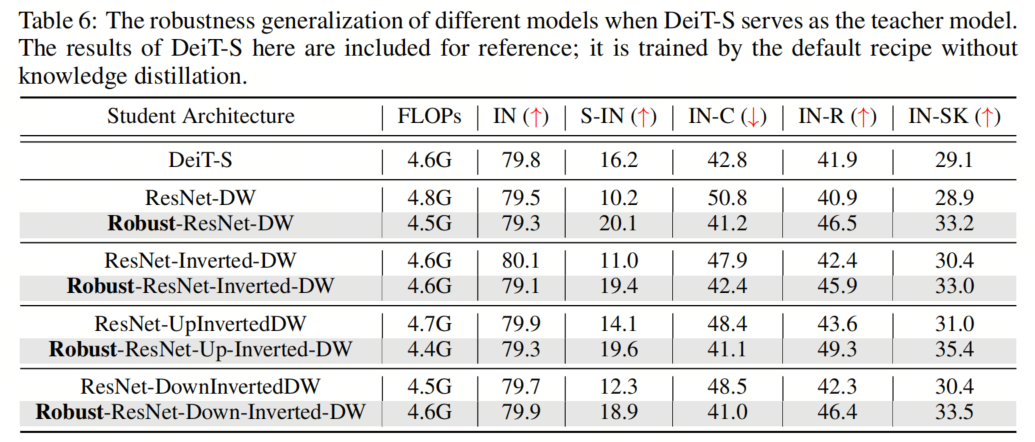 為了進(jìn)一步研究這一點,作者用將所有3種提出的建筑設(shè)計相結(jié)合的模型作為學(xué)生模型,并用DeiT-S作為教師模型來重復(fù)這些實驗。如表所示,作者觀察到,在ViT提出的架構(gòu)組件的幫助下,作者得到的Robust ResNet系列現(xiàn)在可以在out-of-distribution樣本上始終比DeiT表現(xiàn)得更好。相比之下,盡管 Baseline 模型在clean ImageNet上取得了良好的性能,但不如教師模型DeiT那樣魯棒。
為了進(jìn)一步研究這一點,作者用將所有3種提出的建筑設(shè)計相結(jié)合的模型作為學(xué)生模型,并用DeiT-S作為教師模型來重復(fù)這些實驗。如表所示,作者觀察到,在ViT提出的架構(gòu)組件的幫助下,作者得到的Robust ResNet系列現(xiàn)在可以在out-of-distribution樣本上始終比DeiT表現(xiàn)得更好。相比之下,盡管 Baseline 模型在clean ImageNet上取得了良好的性能,但不如教師模型DeiT那樣魯棒。6、更大的模型
為了證明作者提出的模型在更大尺度上的有效性,作者進(jìn)行了實驗來匹配DeiT Base的總FLOP。具體而言,作者將基本通道維度增加到(128、256、512和1024),并在網(wǎng)絡(luò)的第3階段添加20多個塊,同時使用ConvNeXT-B配置進(jìn)行訓(xùn)練。作者將調(diào)整后的模型的性能與DeiT-B進(jìn)行了比較,如表7所示。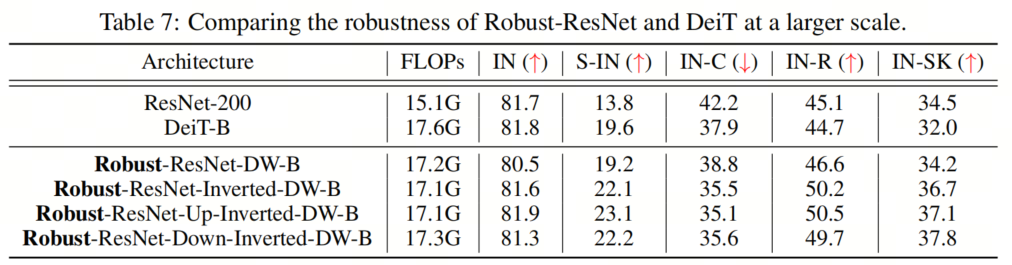 作者的結(jié)果表明,即使在更大的規(guī)模上,作者提出的Robust-ResNet家族也能很好地對抗DeiT-B,這表明作者的方法在擴(kuò)大模型規(guī)模方面有很大的潛力。
作者的結(jié)果表明,即使在更大的規(guī)模上,作者提出的Robust-ResNet家族也能很好地對抗DeiT-B,這表明作者的方法在擴(kuò)大模型規(guī)模方面有很大的潛力。7、更多STEM實驗
最近的研究表明,用少量stacked 2-stride 3×3 convolution layers取代ViT-style patchify stem可以極大地簡化優(yōu)化,從而提高clean精度。為了驗證其在魯棒性基準(zhǔn)上的有效性,作者還實現(xiàn)了ViT-S的卷積Backbone,使用4個3×3卷積層的堆棧,Stride為2。結(jié)果如表8所示。令人驚訝的是,盡管卷積stem的使用確實獲得了更高的clean精度,但在out-of-distribution魯棒性方面,它似乎不如ViT-style patchify stem有幫助。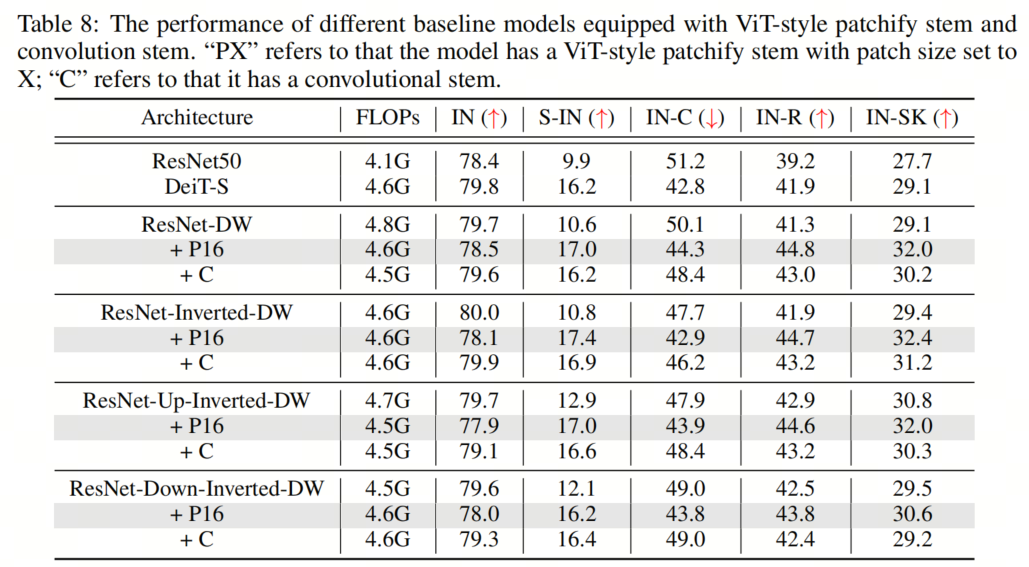
8、與其他模型的比較
除了DeiT,這里作者還評估了作者提出的Robust-ResNet模型,ConvNeXt和Swin-Transformer,在out-of-distribution魯棒性。如表12中所示,4個模型中,所有的out-of-distribution測試的性能都類似于ConvNeXt或Swin-Transformer或更好。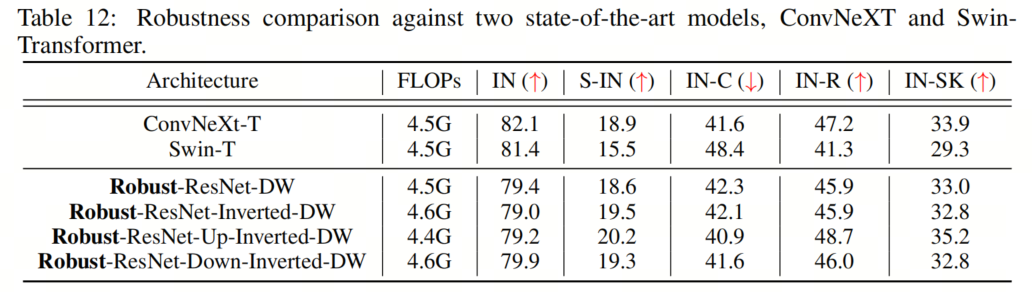
9、重復(fù)實驗
為了證明作者提出的組件所實現(xiàn)的魯棒性改進(jìn)的統(tǒng)計意義,作者用不同的隨機(jī)種子進(jìn)行了3次實驗,并在表13中報告了平均值和標(biāo)準(zhǔn)差。作者在3次運行中只觀察到很小的變化,這證實了作者提出的模型實現(xiàn)了一致和可靠的性能增益。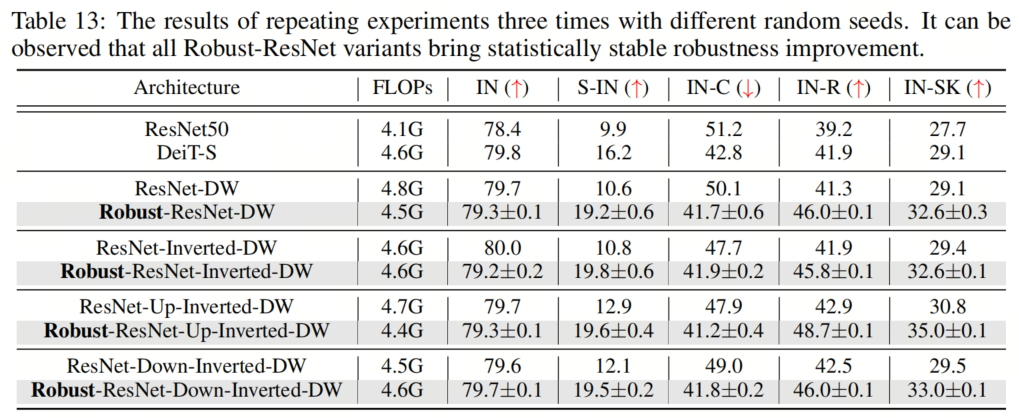
10、Imagenet評估
ImageNet-A數(shù)據(jù)集包括一組自然對抗性樣本,這些樣本對機(jī)器學(xué)習(xí)模型的性能有相當(dāng)大的負(fù)面影響。在表14中,作者比較了作者的Robust-ResNet模型和DeiT在ImageNet-A數(shù)據(jù)集上的性能。值得注意的是,雖然Robust ResNet模型在輸入分辨率為224的情況下不如DeiT執(zhí)行得好,但將輸入分辨率增加(例如,增加到320)顯著縮小了Robust ResNet和ImageNet-A上的DeiT之間的差距。作者推測這是因為ImageNet-A中感興趣的目標(biāo)往往比標(biāo)準(zhǔn)ImageNet中的目標(biāo)小。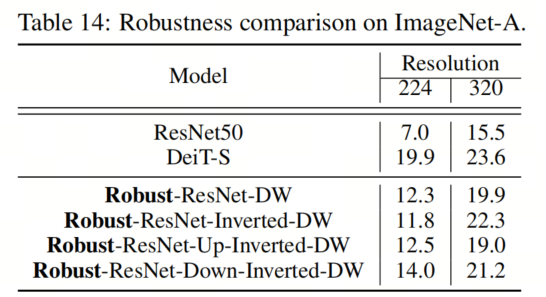
11、結(jié)構(gòu)化重參
最近的一系列工作通過結(jié)構(gòu)重參化促進(jìn)了訓(xùn)練多分支但推理plain模型架構(gòu)的想法。RepLKNet特別表明,使用小Kernel的重參化可以緩解與大Kernel卷積層相關(guān)的優(yōu)化問題,而不會產(chǎn)生額外的推理成本。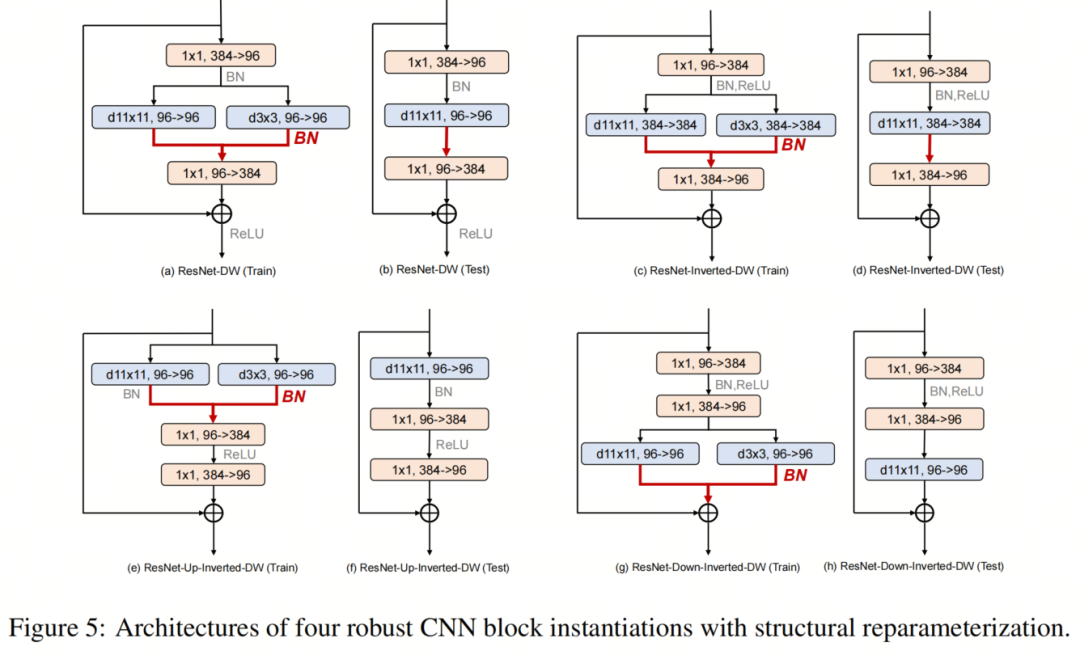 考慮到Robust ResNet模型也使用大Kernel,作者在這里試驗了結(jié)構(gòu)重參化的想法,并利用訓(xùn)練時間多分支塊架構(gòu)來進(jìn)一步提高模型性能。塊架構(gòu)如圖5所示。
考慮到Robust ResNet模型也使用大Kernel,作者在這里試驗了結(jié)構(gòu)重參化的想法,并利用訓(xùn)練時間多分支塊架構(gòu)來進(jìn)一步提高模型性能。塊架構(gòu)如圖5所示。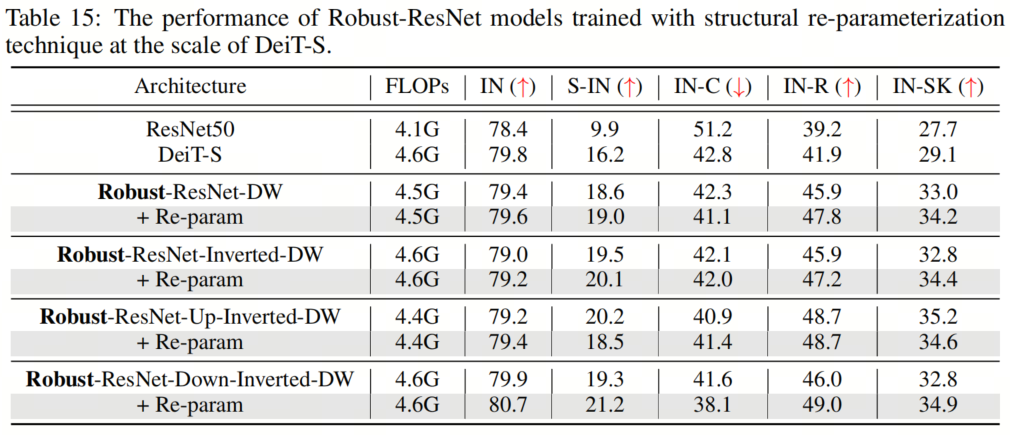
 表15和表16顯示了兩種不同模型尺度的結(jié)果,表明這種重參化方法總體上提高了性能。一個例外可能是Robust ResNet-Up-Inverted-DW,它偶爾會在重參化的情況下表現(xiàn)出稍差的魯棒性。值得注意的是,通過重參化技術(shù),作者能夠使用 kernel-size 為11的卷積來訓(xùn)練Robust-ResNet-Up-Inverted-DW模型。
表15和表16顯示了兩種不同模型尺度的結(jié)果,表明這種重參化方法總體上提高了性能。一個例外可能是Robust ResNet-Up-Inverted-DW,它偶爾會在重參化的情況下表現(xiàn)出稍差的魯棒性。值得注意的是,通過重參化技術(shù),作者能夠使用 kernel-size 為11的卷積來訓(xùn)練Robust-ResNet-Up-Inverted-DW模型。12、總結(jié)
最近的研究聲稱,Transformer在out-of-distribution樣本上的表現(xiàn)優(yōu)于神經(jīng)網(wǎng)絡(luò),類Self-Attention架構(gòu)是主要因素。相比之下,本文更仔細(xì)地研究了Transformer架構(gòu),并確定了Self-Attention塊之外的幾個有益設(shè)計。通過將這些設(shè)計結(jié)合到ResNet中,作者開發(fā)了一種CNN架構(gòu),該架構(gòu)可以匹配甚至超過同等大小的視覺Transformer模型的魯棒性。作者希望作者的發(fā)現(xiàn)能促使研究人員重新評估Transformers和CNNs之間的魯棒性比較,并啟發(fā)人們進(jìn)一步研究開發(fā)更具魯棒性的架構(gòu)設(shè)計。13、參考
[1].CAN CNNS BE MORE ROBUST THAN TRANSFORMERS?.14、Robust ResNet的實現(xiàn)
fromcollectionsimportOrderedDict
fromfunctoolsimportpartial
importtorch
importtorch.nnasnn
fromtimm.dataimportIMAGENET_DEFAULT_MEAN,IMAGENET_DEFAULT_STD
from.helpersimportbuild_model_with_cfg
from.layersimportSelectAdaptivePool2d,AvgPool2dSame
from.layersimportRobustResNetDWBlock,RobustResNetDWInvertedBlock,RobustResNetDWUpInvertedBlock,RobustResNetDWDownInvertedBlock
from.registryimportregister_model
__all__=['RobustResNet']#model_registrywilladdeachentrypointfntothis
def_cfg(url='',**kwargs):
return{
'url':url,
'num_classes':1000,'input_size':(3,224,224),'pool_size':(7,7),
'crop_pct':0.875,'interpolation':'bicubic',
'mean':IMAGENET_DEFAULT_MEAN,'std':IMAGENET_DEFAULT_STD,
'first_conv':'stem.0','classifier':'head.fc',
**kwargs
}
default_cfgs=dict(
small=_cfg(),
base=_cfg(),
)
defget_padding(kernel_size,stride,dilation=1):
padding=((stride-1)+dilation*(kernel_size-1))//2
returnpadding
defdownsample_conv(
in_channels,out_channels,kernel_size,stride=1,dilation=1,first_dilation=None,norm_layer=None):
norm_layer=norm_layerornn.BatchNorm2d
kernel_size=1ifstride==1anddilation==1elsekernel_size
first_dilation=(first_dilationordilation)ifkernel_size>1else1
p=get_padding(kernel_size,stride,first_dilation)
returnnn.Sequential(*[
nn.Conv2d(
in_channels,out_channels,kernel_size,stride=stride,padding=p,dilation=first_dilation,bias=True),
norm_layer(out_channels)
])
defdownsample_avg(
in_channels,out_channels,kernel_size,stride=1,dilation=1,first_dilation=None,norm_layer=None):
norm_layer=norm_layerornn.BatchNorm2d
avg_stride=strideifdilation==1else1
ifstride==1anddilation==1:
pool=nn.Identity()
else:
avg_pool_fn=AvgPool2dSameifavg_stride==1anddilation>1elsenn.AvgPool2d
pool=avg_pool_fn(2,avg_stride,ceil_mode=True,count_include_pad=False)
returnnn.Sequential(*[
pool,
nn.Conv2d(in_channels,out_channels,1,stride=1,padding=0,bias=True),
norm_layer(out_channels)
])
classStage(nn.Module):
def__init__(
self,block_fn,in_chs,chs,stride=2,depth=2,dp_rates=None,layer_scale_init_value=1.0,
norm_layer=nn.BatchNorm2d,act_layer=partial(nn.ReLU,partial=True),
avg_down=False,down_kernel_size=1,mlp_ratio=4.,inverted=False,**kwargs):
super().__init__()
blocks=[]
dp_rates=dp_ratesor[0.]*depth
forblock_idxinrange(depth):
stride_block_idx=depth-1ifblock_fn==RobustResNetDWDownInvertedBlockelse0
current_stride=strideifblock_idx==stride_block_idxelse1
downsample=None
ifinverted:
ifin_chs!=chsorcurrent_stride>1:
down_kwargs=dict(
in_channels=in_chs,out_channels=chs,kernel_size=down_kernel_size,
stride=current_stride,norm_layer=norm_layer)
downsample=downsample_avg(**down_kwargs)ifavg_downelsedownsample_conv(**down_kwargs)
else:
ifin_chs!=int(mlp_ratio*chs)orcurrent_stride>1:
down_kwargs=dict(
in_channels=in_chs,out_channels=int(mlp_ratio*chs),kernel_size=down_kernel_size,
stride=current_stride,norm_layer=norm_layer)
downsample=downsample_avg(**down_kwargs)ifavg_downelsedownsample_conv(**down_kwargs)
ifdownsampleisnotNone:
assertblock_idxin[0,depth-1]
blocks.append(block_fn(
indim=in_chs,dim=chs,drop_path=dp_rates[block_idx],layer_scale_init_value=layer_scale_init_value,
mlp_ratio=mlp_ratio,
norm_layer=norm_layer,act_layer=act_layer,
stride=current_stride,
downsample=downsample,
**kwargs,
))
in_chs=int(chs*mlp_ratio)ifnotinvertedelsechs
self.blocks=nn.Sequential(*blocks)
defforward(self,x):
x=self.blocks(x)
returnx
classRobustResNet(nn.Module):
#TODO:finishcommenthere
r"""RobustResNetDW
APyTorchimplof:
Args:
in_chans(int):Numberofinputimagechannels.Default:3
num_classes(int):Numberofclassesforclassificationhead.Default:1000
depths(tuple(int)):Numberofblocksateachstage.Default:[3,3,9,3]
dims(tuple(int)):Featuredimensionateachstage.Default:[96,192,384,768]
drop_rate(float):Headdropoutrate
drop_path_rate(float):Stochasticdepthrate.Default:0.
layer_scale_init_value(float):InitvalueforLayerScale.Default:1e-6.
head_init_scale(float):Initscalingvalueforclassifierweightsandbiases.Default:1.
"""
def__init__(
self,block_fn,in_chans=3,num_classes=1000,global_pool='avg',output_stride=32,
patch_size=16,stride_stage=(3,),
depths=(3,3,9,3),dims=(96,192,384,768),layer_scale_init_value=1e-6,
head_init_scale=1.,head_norm_first=False,
norm_layer=nn.BatchNorm2d,act_layer=partial(nn.ReLU,inplace=True),
drop_rate=0.,drop_path_rate=0.,mlp_ratio=4.,block_args=None,
):
super().__init__()
assertblock_fnin[RobustResNetDWBlock,RobustResNetDWInvertedBlock,RobustResNetDWUpInvertedBlock,RobustResNetDWDownInvertedBlock]
self.inverted=Trueifblock_fn!=RobustResNetDWBlockelseFalse
assertoutput_stride==32
self.num_classes=num_classes
self.drop_rate=drop_rate
self.feature_info=[]
block_args=block_argsordict()
print(f'usingblockargs:{block_args}')
assertpatch_size==16
self.stem=nn.Conv2d(in_chans,dims[0],kernel_size=patch_size,stride=patch_size)
curr_stride=patch_size
self.stages=nn.Sequential()
dp_rates=[x.tolist()forxintorch.linspace(0,drop_path_rate,sum(depths)).split(depths)]
prev_chs=dims[0]
stages=[]
#4featureresolutionstages,eachconsistingofmultipleresidualblocks
foriinrange(4):
stride=2ifiinstride_stageelse1
curr_stride*=stride
chs=dims[i]
stages.append(Stage(
block_fn,prev_chs,chs,stride=stride,
depth=depths[i],dp_rates=dp_rates[i],layer_scale_init_value=layer_scale_init_value,
norm_layer=norm_layer,act_layer=act_layer,mlp_ratio=mlp_ratio,
inverted=self.inverted,**block_args)
)
prev_chs=int(mlp_ratio*chs)ifnotself.invertedelsechs
self.feature_info+=[dict(num_chs=prev_chs,reduction=curr_stride,module=f'stages.{i}')]
self.stages=nn.Sequential(*stages)
assertcurr_stride==output_stride
self.num_features=prev_chs
self.norm_pre=nn.Identity()
self.head=nn.Sequential(OrderedDict([
('global_pool',SelectAdaptivePool2d(pool_type=global_pool)),
#('norm',norm_layer(self.num_features)),
('flatten',nn.Flatten(1)ifglobal_poolelsenn.Identity()),
('drop',nn.Dropout(self.drop_rate)),
('fc',nn.Linear(self.num_features,num_classes)ifnum_classes>0elsenn.Identity())
]))
self.resnet_init_weights()
defresnet_init_weights(self):
forn,minself.named_modules():
ifisinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
nn.init.zeros_(m.bias)
elifisinstance(m,nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
defget_classifier(self):
returnself.head.fc
defreset_classifier(self,num_classes=0,global_pool='avg'):
#pool->norm->fc
self.head=nn.Sequential(OrderedDict([
('global_pool',SelectAdaptivePool2d(pool_type=global_pool)),
('norm',self.head.norm),
('flatten',nn.Flatten(1)ifglobal_poolelsenn.Identity()),
('drop',nn.Dropout(self.drop_rate)),
('fc',nn.Linear(self.num_features,num_classes)ifnum_classes>0elsenn.Identity())
]))
defforward_features(self,x):
x=self.stem(x)
x=self.stages(x)
x=self.norm_pre(x)
returnx
defforward(self,x):
x=self.forward_features(x)
x=self.head(x)
returnx
def_create_robust_resnet(variant,pretrained=False,**kwargs):
model=build_model_with_cfg(
RobustResNet,variant,pretrained,
default_cfg=default_cfgs[variant],
feature_cfg=dict(out_indices=(0,1,2,3),flatten_sequential=True),
**kwargs)
returnmodel
@register_model
defrobust_resnet_dw_small(pretrained=False,**kwargs):
'''
4.49GFLOPsand38.6MParams
'''
assertnotpretrained,'nopretrainedmodels!'
model_args=dict(block_fn=RobustResNetDWBlock,depths=(3,4,12,3),dims=(96,192,384,768),
block_args=dict(kernel_size=11,padding=5),
patch_size=16,stride_stage=(3,),
norm_layer=nn.BatchNorm2d,act_layer=partial(nn.ReLU,inplace=True),
**kwargs)
model=_create_robust_resnet('small',pretrained=pretrained,**model_args)
returnmodel
@register_model
defrobust_resnet_inverted_dw_small(pretrained=False,**kwargs):
'''
4.59GFLOPsand33.6MParams
'''
assertnotpretrained,'nopretrainedmodels!'
model_args=dict(block_fn=RobustResNetDWInvertedBlock,depths=(3,4,14,3),dims=(96,192,384,768),
block_args=dict(kernel_size=7,padding=3),
patch_size=16,stride_stage=(3,),
norm_layer=nn.BatchNorm2d,act_layer=partial(nn.ReLU,inplace=True),
**kwargs)
model=_create_robust_resnet('small',pretrained=pretrained,**model_args)
returnmodel
@register_model
defrobust_resnet_up_inverted_dw_small(pretrained=False,**kwargs):
'''
4.43GFLOPsand34.4MParams
'''
assertnotpretrained,'nopretrainedmodels!'
model_args=dict(block_fn=RobustResNetDWUpInvertedBlock,depths=(3,4,14,3),dims=(96,192,384,768),
block_args=dict(kernel_size=11,padding=5),
patch_size=16,stride_stage=(3,),
norm_layer=nn.BatchNorm2d,act_layer=partial(nn.ReLU,inplace=True),
**kwargs)
model=_create_robust_resnet('small',pretrained=pretrained,**model_args)
returnmodel
@register_model
defrobust_resnet_down_inverted_dw_small(pretrained=False,**kwargs):
'''
4.55GFLOPsand24.3MParams
'''
assertnotpretrained,'nopretrainedmodels!'
model_args=dict(block_fn=RobustResNetDWDownInvertedBlock,depths=(3,4,15,3),dims=(96,192,384,768),
block_args=dict(kernel_size=11,padding=5),
patch_size=16,stride_stage=(2,),
norm_layer=nn.BatchNorm2d,act_layer=partial(nn.ReLU,inplace=True),
**kwargs)
model=_create_robust_resnet('small',pretrained=pretrained,**model_args)
returnmodel
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4789瀏覽量
101664 -
計算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1703瀏覽量
46272 -
Transformer
+關(guān)注
關(guān)注
0文章
147瀏覽量
6183
發(fā)布評論請先 登錄
相關(guān)推薦
大語言模型背后的Transformer,與CNN和RNN有何不同

一文詳解CNN
BROCADE DCX 8510 BACKBONE 部署選項,運行可靠

視覺新范式Transformer之ViT的成功
一種可以編碼局部信息的結(jié)構(gòu)T2T module,并證明了T2T的有效性
我們可以使用transformer來干什么?
如何使用Transformer來做物體檢測?
使用跨界模型Transformer來做物體檢測!

Pelee:移動端實時檢測Backbone

利用Transformer和CNN 各自的優(yōu)勢以獲得更好的分割性能
BEV+Transformer對智能駕駛硬件系統(tǒng)有著什么樣的影響?
掌握基于Transformer的目標(biāo)檢測算法的3個難點

基于M55H的定制化backbone模型AxeraSpine

自動駕駛中一直說的BEV+Transformer到底是個啥?

transformer專用ASIC芯片Sohu說明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論