 MySQL為什么選擇B+樹作為索引結構?
MySQL為什么選擇B+樹作為索引結構?
前言
在MySQL中,無論是Innodb還是MyIsam,都使用了B+樹作索引結構(這里不考慮hash等其他索引)。本文將從最普通的二叉查找樹開始,逐步說明各種樹解決的問題以及面臨的新問題,從而說明MySQL為什么選擇B+樹作為索引結構。
一、二叉查找樹(BST):不平衡
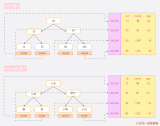
二叉查找樹(BST,Binary Search Tree),也叫二叉排序樹,在二叉樹的基礎上需要滿足:任意節點的左子樹上所有節點值不大于根節點的值,任意節點的右子樹上所有節點值不小于根節點的值。如下是一顆BST(圖片來源)。
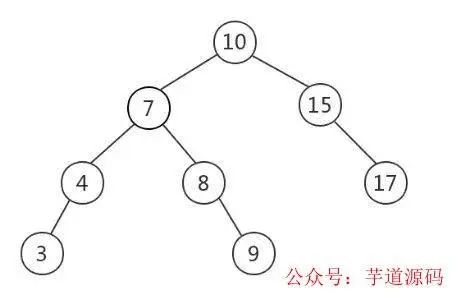
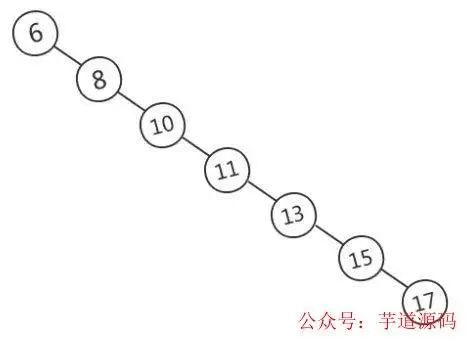
當需要快速查找時,將數據存儲在BST是一種常見的選擇,因為此時查詢時間取決于樹高,平均時間復雜度是O(lgn)。然而BST 可能長歪而變得不平衡,如下圖所示(圖片來源),此時BST退化為鏈表,時間復雜度退化為O(n)。
為了解決這個問題,引入了平衡二叉樹。
二、平衡二叉樹(AVL):旋轉耗時
AVL樹是嚴格的平衡二叉樹,所有節點的左右子樹高度差不能超過1;AVL樹查找、插入和刪除在平均和最壞情況下都是O(lgn)。
AVL實現平衡的關鍵在于旋轉操作:插入和刪除可能破壞二叉樹的平衡,此時需要通過一次或多次樹旋轉來重新平衡這個樹。當插入數據時,最多只需要1次旋轉(單旋轉或雙旋轉);但是當刪除數據時,會導致樹失衡,AVL需要維護從被刪除節點到根節點這條路徑上所有節點的平衡,旋轉的量級為O(lgn)。
由于旋轉的耗時,AVL樹在刪除數據時效率很低 ;在刪除操作較多時,維護平衡所需的代價可能高于其帶來的好處,因此AVL實際使用并不廣泛。
三、紅黑樹:樹太高
與AVL樹相比,紅黑樹并不追求嚴格的平衡,而是大致的平衡:只是確保從根到葉子的最長的可能路徑不多于最短的可能路徑的兩倍長。從實現來看,紅黑樹最大的特點是每個節點都屬于兩種顏色(紅色或黑色)之一,且節點顏色的劃分需要滿足特定的規則(具體規則略)。紅黑樹示例如下(圖片來源):
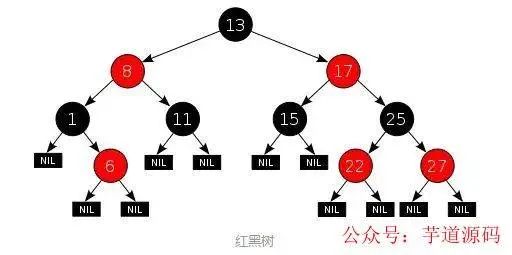
與AVL樹相比,紅黑樹的查詢效率會有所下降,這是因為樹的平衡性變差,高度更高。但紅黑樹的刪除效率大大提高了,因為紅黑樹同時引入了顏色,當插入或刪除數據時,只需要進行O(1)次數的旋轉以及變色就能保證基本的平衡,不需要像AVL樹進行O(lgn)次數的旋轉。總的來說,紅黑樹的統計性能高于AVL。
因此,在實際應用中,AVL樹的使用相對較少,而紅黑樹的使用非常廣泛。例如,Java中的TreeMap使用紅黑樹存儲排序鍵值對;Java8中的HashMap使用鏈表+紅黑樹解決哈希沖突問題(當沖突節點較少時,使用鏈表,當沖突節點較多時,使用紅黑樹)。
對于數據在內存中的情況(如上述的TreeMap和HashMap),紅黑樹的表現是非常優異的。但是對于數據在磁盤等輔助存儲設備中的情況(如** **MySQL****等數據庫),紅黑樹并不擅長,因為紅黑樹長得還是太高了 。當數據在磁盤中時,磁盤IO會成為最大的性能瓶頸,設計的目標應該是盡量減少IO次數;而樹的高度越高,增刪改查所需要的IO次數也越多,會嚴重影響性能。
四、B樹:為磁盤而生
B樹也稱B-樹(其中-不是減號),是為磁盤等輔存設備設計的多路平衡查找樹,與二叉樹相比,B樹的每個非葉節點可以有多個子樹。 因此,當總節點數量相同時,B樹的高度遠遠小于AVL樹和紅黑樹(B樹是一顆“矮胖子”),磁盤IO次數大大減少。
定義B樹最重要的概念是階數(Order),對于一顆m階B樹,需要滿足以下條件:
每個節點最多包含 m 個子節點。
如果根節點包含子節點,則至少包含 2 個子節點;除根節點外,每個非葉節點至少包含 m/2 個子節點。
擁有 k 個子節點的非葉節點將包含 k - 1 條記錄。
所有葉節點都在同一層中。
可以看出,B樹的定義,主要是對非葉結點的子節點數量和記錄數量的限制。
下圖是一個3階B樹的例子(圖片來源):
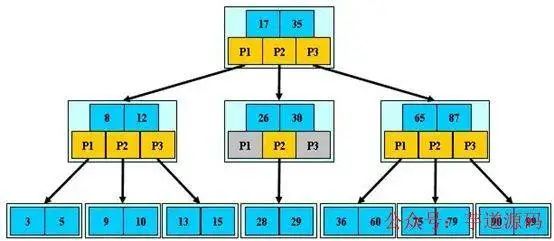
B樹的優勢除了樹高小,還有對訪問局部性原理的利用。所謂局部性原理,是指當一個數據被使用時,其附近的數據有較大概率在短時間內被使用。B樹將鍵相近的數據存儲在同一個節點,當訪問其中某個數據時,數據庫會將該整個節點讀到緩存中;當它臨近的數據緊接著被訪問時,可以直接在緩存中讀取,無需進行磁盤IO;換句話說,B樹的緩存命中率更高。
B樹在數據庫中有一些應用,如mongodb的索引使用了B樹結構。但是在很多數據庫應用中,使用了是B樹的變種B+樹。
五、B+樹
B+樹也是多路平衡查找樹,其與B樹的區別主要在于:
B樹中每個節點(包括葉節點和非葉節點)都存儲真實的數據,B+樹中只有葉子節點存儲真實的數據,非葉節點只存儲鍵。在MySQL中,這里所說的真實數據,可能是行的全部數據(如Innodb的聚簇索引),也可能只是行的主鍵(如Innodb的輔助索引),或者是行所在的地址(如MyIsam的非聚簇索引)。
B樹中一條記錄只會出現一次,不會重復出現,而B+樹的鍵則可能重復重現——一定會在葉節點出現,也可能在非葉節點重復出現。
B+樹的葉節點之間通過雙向鏈表鏈接。
B樹中的非葉節點,記錄數比子節點個數少1;而B+樹中記錄數與子節點個數相同。
由此,B+樹與B樹相比,有以下優勢:
更少的IO次數:B+樹的非葉節點只包含鍵,而不包含真實數據,因此每個節點存儲的記錄個數比B數多很多(即階m更大),因此B+樹的高度更低,訪問時所需要的IO次數更少。此外,由于每個節點存儲的記錄數更多,所以對訪問局部性原理的利用更好,緩存命中率更高。
更適于范圍查詢:在B樹中進行范圍查詢時,首先找到要查找的下限,然后對B樹進行中序遍歷,直到找到查找的上限;而B+樹的范圍查詢,只需要對鏈表進行遍歷即可。
更穩定的查詢效率:B樹的查詢時間復雜度在1到樹高之間(分別對應記錄在根節點和葉節點),而B+樹的查詢復雜度則穩定為樹高,因為所有數據都在葉節點。
B+樹也存在劣勢:由于鍵會重復出現,因此會占用更多的空間。但是與帶來的性能優勢相比,空間劣勢往往可以接受,因此B+樹的在數據庫中的使用比B樹更加廣泛。
六、感受B+樹的威力
前面說到,B樹/B+樹與紅黑樹等二叉樹相比,最大的優勢在于樹高更小。實際上,對于Innodb的B+索引來說,樹的高度一般在2-4層。下面來進行一些具體的估算。
樹的高度是由階數決定的,階數越大樹越矮;而階數的大小又取決于每個節點可以存儲多少條記錄。Innodb中每個節點使用一個頁(page),頁的大小為16KB,其中元數據只占大約128字節左右(包括文件管理頭信息、頁面頭信息等等),大多數空間都用來存儲數據。
對于非葉節點,記錄只包含索引的鍵和指向下一層節點的指針。假設每個非葉節點頁面存儲1000條記錄,則每條記錄大約占用16字節;當索引是整型或較短的字符串時,這個假設是合理的。延伸一下,我們經常聽到建議說索引列長度不應過大,原因就在這里:索引列太長,每個節點包含的記錄數太少,會導致樹太高,索引的效果會大打折扣,而且索引還會浪費更多的空間。
對于葉節點,記錄包含了索引的鍵和值(值可能是行的主鍵、一行完整數據等,具體見前文),數據量更大。這里假設每個葉節點頁面存儲100條記錄(實際上,當索引為聚簇索引時,這個數字可能不足100;當索引為輔助索引時,這個數字可能遠大于100;可以根據實際情況進行估算)。
對于一顆3層B+樹,第一層(根節點)有1個頁面,可以存儲1000條記錄;第二層有1000個頁面,可以存儲10001000條記錄;第三層(葉節點)有10001000個頁面,每個頁面可以存儲100條記錄,因此可以存儲10001000100條記錄,即1億條。而對于二叉樹,存儲1億條記錄則需要26層左右。
七、總結
最后,總結一下各種樹解決的問題以及面臨的新問題:
二叉查找樹(BST):解決了排序的基本問題,但是由于無法保證平衡,可能退化為鏈表;
平衡二叉樹(AVL):通過旋轉解決了平衡的問題,但是旋轉操作效率太低;
紅黑樹:通過舍棄嚴格的平衡和引入紅黑節點,解決了AVL旋轉效率過低的問題,但是在磁盤等場景下,樹仍然太高,IO次數太多;
B樹:通過將二叉樹改為多路平衡查找樹,解決了樹過高的問題;
B+樹:在B樹的基礎上,將非葉節點改造為不存儲數據的純索引節點,進一步降低了樹的高度;此外將葉節點使用指針連接成鏈表,范圍查詢更加高效。
審核編輯:劉清
-
AVL
+關注
關注
0文章
14瀏覽量
10039 -
MySQL
+關注
關注
1文章
804瀏覽量
26531 -
二叉樹
+關注
關注
0文章
74瀏覽量
12324 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9389 -
BST
+關注
關注
0文章
12瀏覽量
5897
原文標題:圖文詳解紅黑樹,還有誰不會??
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Mysql優化選擇最佳索引規則
基于B+樹的動態數據持有性證明方案

基于KD樹和R樹的多維索引結構

MySQL索引使用原則
MySQL索引的使用問題
關于MySQL ORDER BY的詳解
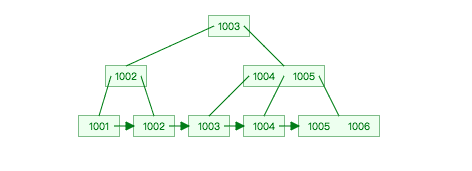
對 B+ 樹與索引在 MySQL 中的認識
Mysql索引為什么使用B+樹?
id的機制不同在mysql的索引結構以及優缺點

一文了解MySQL索引機制






 工商網監
工商網監
評論