 進一步了解大規模部署AI的更優解:Habana? Gaudi?2
進一步了解大規模部署AI的更優解:Habana? Gaudi?2
大語言模型(Large Language Model,下文簡稱為:LLM)的發展如火如荼。以ChatGPT為代表的LLM可執行更為廣泛的任務并具有更高的智能化程度,刷新了人們對AI技術的新認知。當然,LLM規模龐大,通常包含數十億參數,需要海量的訓練數據與強大算力支撐才能達到預期的效果。
其實,無論LLM還是其他應用越來越廣泛的深度學習模型,從模型訓練到推理應用,都需要高性能、可擴展的基礎設施作為底層支撐,這往往也意味著高昂的成本。近日,英特爾發布的最新Habana Gaudi2,專為訓練大語言模型而構建,并為數據中心大規模擴展而設計,同時為深度學習訓練和推理工作負載提供極具性價比的解決方案。
在6月公布的MLCommonsMLPerf基準測試中,Gaudi2在GPT-3模型、計算機視覺模型ResNet-50(使用8個加速器)、Unet3D(使用8個加速器),以及自然語言處理模型BERT(使用8個和64個加速器)上均取得了優異的訓練結果。與市場上其他面向大規模生成式AI和大語言模型的產品相比,Gaudi2擁有卓越的性能與領先的性價比優勢,能夠幫助用戶提升運營效率的同時,降低運營成本。
Gaudi2實現性能、可擴展性和能效飛躍
第二代Gaudi AI深度學習夾層卡 HL-225B 專為數據中心實現大規模橫向擴展而設計。其AI處理器基于第一代 Gaudi的高效架構打造而成,目前采用7納米制程工藝,在性能、可擴展性和能效方面均實現了飛躍。
夾層卡搭載的HL-2080 處理器擁有24個完全可編程的第四代張量處理器核心(TPC)。這些核心原生設計便能夠為廣泛的深度學習工作負載加速,同時還賦予用戶按需進行優化和創新的靈活性。此外,它還集成了96GB HBM2e內存和48MB SRAM,支持600瓦夾層卡級熱設計功耗(TDP)。
Gaudi2 處理器具備出色的2.1 Tbps 網絡容量可擴展性,原生集成21個100 Gbps RoCE v2 RDMA端口,可通過直接路由實現Guadi 處理器間通信。Gaudi2處理器集成了專用媒體處理器,用于圖像和視頻解碼及預處理。
此外,Gaudi2 深度學習夾層卡符合OCP OAM 1.1(開放計算平臺之開放加速器模塊)等多種規范,可以為客戶帶來系統設計的靈活性。

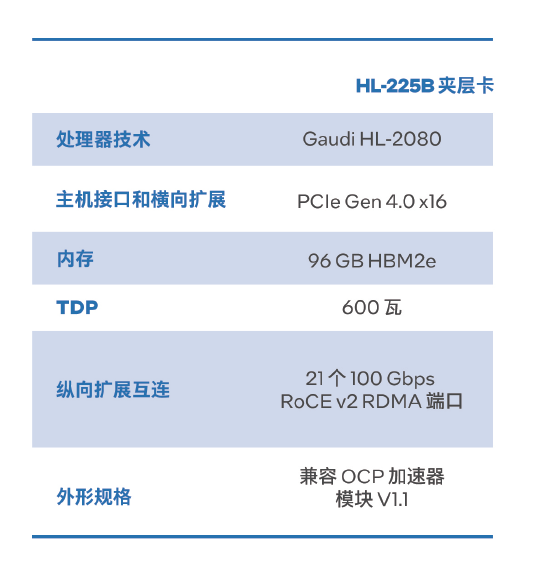
圖:Gaudi2 深度學習夾層卡 HL-225B 主要參數
多維度技術創新,實現卓越性價比
Gaudi2 處理器是一款高性能、完全可編程的AI處理器,它整合了多項技術創新,從計算架構、內存和擴展能力三個維度打造全新的AI 專用處理器。同時,它具有高內存帶寬/容量和基于標準以太網技術的縱向擴展能力,支持使用外接網卡通過PCIe接口實現橫向擴展,滿足多節點集群需要。
[ 性能更高的計算架構 ]
Gaudi2 采用經過驗證的高性能深度學習AI訓練處理器架構,利用Habana完全可編程的TPC和GEMM引擎,支持面向AI的高級數據類型:FP8、BF16、FP16、TF32和FP32。TPC核心旨在支持深度學習訓練和推理工作負載。TPC是一款VLIW SIMD矢量處理器,其指令集和郵件經過定制,可高效處理上述工作負載。
[ 更先進的內存技術 ]
內存帶寬和容量與計算能力同樣重要。Gaudi2 采用先進的HBM內存技術,內存容量高達96GB,內存帶寬高達2.4TB/s。Gaudi先進的HBM控制器已針對隨機訪問和線性訪問進行了優化,在各種訪問模式下均可提供高內存帶寬。
[ 通過集成RDMA實現縱向擴展 ]
Gaudi AI訓練處理器芯片上集成了RDMA(RoCEv2),可與成熟且廣泛使用的以太網進行連接。HL-2080芯片互連技術基于42對56 Gbps Tx/Rx PAM4 SerDes(配置為21個100 GbE端口)發揮作用。
與廣泛的軟件生態一起,
幫助簡化模型的開發和遷移
為支持客戶輕松構建模型,或將當前基于GPU的模型業務和系統遷移到基于全新Gaudi2服務器,并幫助保護軟件開發投入,SynapseAI軟件套件針對Gaudi平臺深度學習業務進行了優化,旨在與廣泛的軟件生態系統一起,幫助簡化模型的開發和遷移。
SynapseAI 軟件套件旨在提高 Habana AI處理器的易用性和支持高性能訓練,能夠將神經網絡拓撲高效映射到Gaudi系列硬件上。該軟件套件包括Habana 的圖編譯器和運行時、經過性能優化的TPC算子庫、固件和驅動程序以及開放工具,例如用于自定義核心開發的TPC 編程工具套件和SynapseAI 圖編譯器。SynapseAI與TensorFlow和PyTorch等主流框架集成,并已針對基于Gaudi AI 處理器家族產品的訓練進行了優化。數據科學家和開發人員在這里可以找到開始基于Gaudi AI 處理器進行訓練所需的各類信息資料,包括教程、參考模型、操作指南、文檔等。

擴展AI產品陣容,加速AI落地
Gaudi2不僅以高性能為AI模型的訓練與推理加速,其高擴展性和性價比,也將加速AI應用落地的進程。多年來,借助強大的軟硬件基礎,英特爾基于全面的AI產品和解決方案,與廣泛合作伙伴一同構建開放生態,為越來越多不同需求和場景的AI應用落地提供更多元的解決方案,持續引領產品技術發展,進一步加速大規模深度學習部署,助力中國本地AI市場發展。

想看更多“芯”資訊
-
英特爾
+關注
關注
61文章
9978瀏覽量
171883 -
cpu
+關注
關注
68文章
10873瀏覽量
212052
原文標題:進一步了解大規模部署AI的更優解:Habana? Gaudi?2
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英特爾將進一步分離芯片制造和設計業務

RFTOP進一步擴充波導同軸轉換器產品線
IBM Cloud將部署英特爾Gaudi 3 AI芯片
iPhone 15在美國市場需求進一步減弱
西門子與微軟進一步擴展戰略合作關系
Arm計劃2025年大規模銷售AI芯片
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
安霸發布5nm制程的CV75S系列芯片,進一步拓寬AI SoC產品路線圖
Arbe在中國上海設立分公司,進一步增強企業影響力
隆基攜手DAT Group與SPower進一步加速越南高效能量綠色轉型
英飛凌重組銷售與營銷組織,進一步提升以客戶為中心的服務及領先的應用支持能力

明星產品還想進一步了解?關于DGW412的重點Q&A






 工商網監
工商網監
評論