 HBM在數據中心的出現:AMD的創新如何幫助Nvidia
HBM在數據中心的出現:AMD的創新如何幫助Nvidia
生成式人工智能即將到來,它將改變世界。自從 ChatGPT 席卷全球并激發了我們對人工智能可能性的想象力以來,我們看到各種各樣的公司都在爭先恐后地訓練人工智能模型并將生成式人工智能部署到內部工作流程或面向客戶的應用程序中。不僅僅是大型科技公司和初創公司,許多財富500強非科技公司也在研究如何部署基于LLM的解決方案。
當然,這需要大量的 GPU 計算。GPU 的銷量像火箭一樣猛增,而供應鏈卻難以滿足對 GPU 的需求。公司正在爭先恐后地獲得 GPU 或云實例。
即使 OpenAI 也無法獲得足夠的 GPU,這嚴重阻礙了其近期路線圖。由于 GPU 短缺,OpenAI 無法部署其多模態模型。由于 GPU 短缺,OpenAI 無法部署更長的序列長度模型(8k 與 32k)。
與此同時,中國公司不僅投資部署自己的LLM,還在美國出口管制進一步收緊之前進行儲備。例如,據新聞報道,中國公司字節跳動據稱從 Nvidia 訂購了價值超過 10 億美元的 A800/H800。
雖然數十萬個專門用于人工智能的 GPU 有許多合法的用例,但也有很多情況是人們急于購買 GPU 來嘗試構建他們不確定是否有合法市場的東西。在某些情況下,大型科技公司正試圖趕上 OpenAI 和谷歌,以免落后。對于沒有經過驗證的商業用例的初創公司來說,有大量的風險投資資金。我們知道有十幾家企業正在嘗試利用自己的數據訓練自己的LLM。最后,這也適用于沙特阿拉伯和阿聯酋今年也試圖購買數億美元的 GPU 的國家。
盡管 Nvidia 試圖大幅提高產量,但最高端的 Nvidia GPU H100 直到明年第一季度仍將售空。Nvidia 每季度將增加 400,000 個 H100 GPU 的出貨量。

Nvidia 的 H100 采用 CoWoS-S 上的7-die封裝。中間是H100 GPU ASIC,其芯片尺寸為814mm2 ,周圍是 6 個內存堆棧HBM。不同 SKU 之間的 HBM 配置有所不同,但 H100 SXM 版本使用 HBM3,每個堆棧為 16GB,總內存為 80GB。H100 NVL 將具有兩個封裝,每個封裝上有 6 個活躍的 HBM 堆棧。
在只有 5 個激活 HBM 的情況下,非 HBM 芯片可以使用虛擬硅,為芯片提供結構支撐。這些芯片位于硅中介層的頂部,該硅中介層在圖片中不清晰可見。該硅中介層位于封裝基板上,該封裝基板是 ABF 封裝基板。
GPU Die和 TSMC晶圓廠
Nvidia GPU 的主要數字處理組件是處理器芯片本身,它是在稱為“4N”的定制臺積電工藝節點上制造的。它是在臺積電位于臺灣臺南的 Fab 18 工廠制造的,與臺積電 N5 和 N4 工藝節點共享相同的設施,但這不是生產的限制因素。
由于 PC、智能手機和非 AI 相關數據中心芯片的嚴重疲軟,臺積電 N5 工藝節點的利用率降至 70% 以下。英偉達在確保額外的晶圓供應方面沒有遇到任何問題。
事實上,Nvidia 已經訂購了大量用于 H100 GPU 和 NVSwitch 的晶圓,這些晶圓立即開始生產,遠遠早于運送芯片所需的晶圓。這些晶圓將存放在臺積電的芯片組中,直到下游供應鏈有足夠的產能將這些晶圓封裝成完整的芯片。
基本上,英偉達正在吸收臺積電的部分低利用率,并獲得一些定價優勢,因為英偉達已承諾進一步購買成品。
Wafer bank,也被稱為die bank,是半導體行業的一種做法,其中存儲部分處理或完成的晶圓,直到客戶需要它們為止。與其他一些代工廠不同的是,臺積電將通過將這些晶圓保留在自己的賬簿上幾乎完全加工來幫助他們的客戶。這種做法使臺積電及其客戶能夠保持財務靈活性。由于僅進行了部分加工,因此晶圓庫中保存的晶圓不被視為成品,而是被歸類為 WIP。只有當這些晶圓全部完成后,臺積電才能確認收入并將這些晶圓的所有權轉讓給客戶。
這有助于客戶修飾他們的資產負債表,使庫存水平看起來處于控制之中。對于臺積電來說,好處是可以幫助保持更高的利用率,從而支撐利潤率。然后,隨著客戶需要更多的庫存,這些晶圓可以通過幾個最終加工步驟完全完成,然后以正常銷售價格甚至稍有折扣的價格交付給客戶。
HBM 在數據中心的出現:
AMD 的創新如何幫助 Nvidia
GPU 周圍的高帶寬內存是下一個主要組件。HBM 供應也有限,但正在增加。HBM 是垂直堆疊的 DRAM 芯片,通過硅通孔 (TSV) 連接并使用 TCB進行鍵合(未來更高的堆疊數量將需要混合鍵合)。DRAM 裸片下方有一顆充當控制器的基本邏輯裸片。
通常,現代 HBM 具有 8 層內存和 1 個基本邏輯芯片,但我們很快就會看到具有 12+1 層 HBM 的產品,例如 AMD 的 MI300X 和 Nvidia 即將推出的 H100 更新。

有趣的是,盡管 Nvidia 和 Google 是當今使用量最大的用戶,但 AMD 率先推出了 HBM。2008 年,AMD 預測,為了匹配游戲 GPU 性能而不斷擴展內存帶寬將需要越來越多的功率,而這些功率需要從 GPU 邏輯中轉移出來,從而降低 GPU 性能。AMD 與 SK Hynix 以及供應鏈中的其他公司(例如 Amkor)合作,尋找一種能夠以更低功耗提供高帶寬的內存解決方案。這驅使 SK 海力士于 2013 年開發了 HBM。
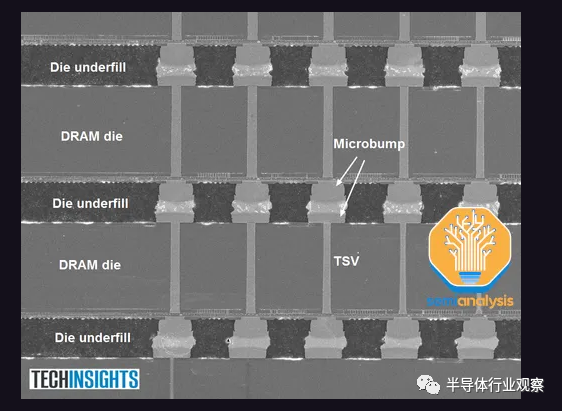
SK Hynix 于 2015 年首次為 AMD Fiji 系列游戲 GPU 提供 HBM,該 GPU 由 Amkor 進行 2.5D 封裝。隨后,他們在2017 年推出了使用 HBM2 的 Vega 系列。然而,HBM 并沒有對游戲 GPU 性能產生太大的改變。由于沒有明顯的性能優勢以及更高的成本,AMD 在 Vega 之后重新在其游戲卡中使用 GDDR。如今,Nvidia 和 AMD 的頂級游戲 GPU 仍在使用更便宜的 GDDR6。
然而,AMD 的最初預測在某種程度上是正確的:擴展內存帶寬已被證明是 GPU 的一個問題,只是這主要是數據中心 GPU 的問題。對于消費級游戲 GPU,Nvidia 和 AMD 已轉向使用大型緩存作為幀緩沖區(large caches for the frame buffer),使它們能夠使用帶寬低得多的 GDDR 內存。
正如我們過去所詳述的,推理和訓練工作負載是內存密集型的。隨著人工智能模型中參數數量的指數級增長,僅權重的模型大小就已達到 TB 級。因此,人工智能加速器的性能受到從內存中存儲和檢索訓練和推理數據的能力的瓶頸:這個問題通常被稱為“內存墻”。
為了解決這個問題,領先的數據中心 GPU 與高帶寬內存 (HBM) 共同封裝。Nvidia 于 2016 年發布了首款 HBM GPU P100。HBM 通過在傳統 DDR 內存和片上緩存之間找到中間立場,以容量換取帶寬來解決內存墻問題。通過大幅增加引腳數以達到每個 HBM 堆棧 1024 位寬的內存總線,可以實現更高的帶寬,這是每個 DIMM 64 位寬的 DDR5 的 18 倍。同時,通過大幅降低每比特傳輸能量 (pJ/bit) 來控制功耗。這是通過更短的走線長度來實現的,HBM 的走線長度以毫米為單位,而 GDDR 和 DDR 的走線長度以厘米為單位。
如今,許多面向HPC的芯片公司正在享受AMD努力的成果。具有諷刺意味的是,AMD 的競爭對手 Nvidia 作為 HBM 用量最大的用戶,或許會受益最多。

HBM市場:SK海力士占據主導地位
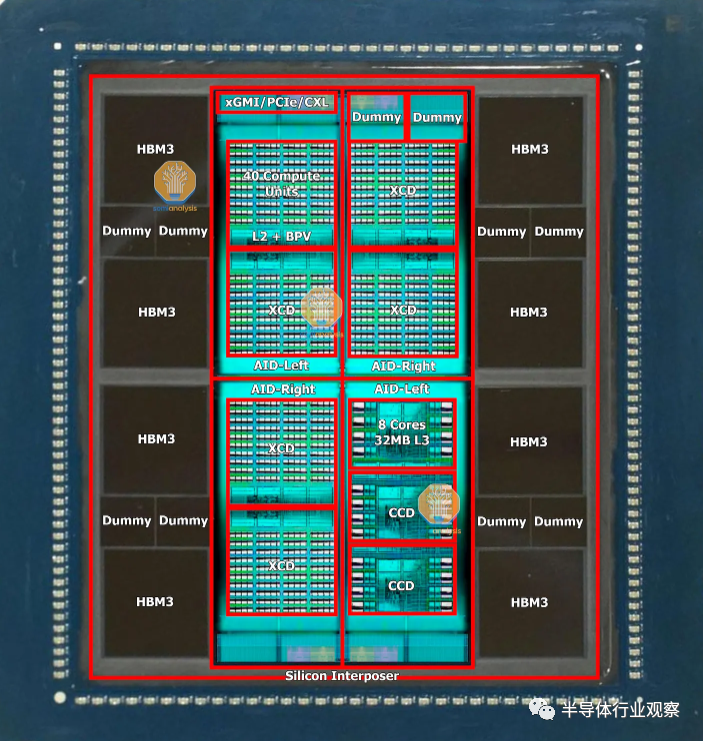
作為HBM的先驅,SK海力士是擁有最先進技術路線的領導者。SK 海力士于 2022 年 6 月開始生產 HBM3,是目前唯一一家批量出貨 HBM3 的供應商,擁有超過 95% 的市場份額,這是大多數 H100 SKU 所使用的。HBM 現在的最大配置為 8 層 16GB HBM3 模塊。SK Hynix 正在為 AMD MI300X 和 Nvidia H100 刷新生產數據速率為 5.6 GT/s 的 12 層 24GB HBM3。

HBM 的主要挑戰是存儲器的封裝和堆疊,這是 SK 海力士所擅長的,他們過去在這方面積累了最強大的工藝流程知識。
三星緊隨 Hynix 之后,預計將在 2023 年下半年發貨 HBM3。我們相信它們是為 Nvidia 和 AMD GPU 設計的。他們目前在銷量上與 SK 海力士存在很大差距,但他們正在緊鑼密鼓地前進,并正在大力投資以追趕市場份額。三星正在投資以追趕并成為 HBM 市場份額第一,就像他們在標準內存方面一樣。我們聽說他們正在與一些加速器公司達成優惠協議,以試圖獲得更多份額。
他們展示了 12 層 HBM 以及未來的混合鍵合 HBM。三星 HBM-4 路線圖的一個有趣的方面是,他們希望在內部 FinFET 節點上制作邏輯/外圍設備。這顯示了他們擁有內部邏輯和 DRAM 代工廠的潛在優勢。

美光科技在HBM方面排名墊底。
他們在混合存儲立方體 (HMC) 技術上投入了更多資金。這是與 HBM 競爭的技術,其概念非常相似,大約在同一時間開發。然而,HMC周圍的生態系統是封閉的,導致圍繞HMC的IP很難開發。此外,還存在一些技術缺陷。HBM 的采用率要高得多,因此 HBM 勝出,成為 3D 堆疊 DRAM 的行業標準。
直到 2018 年,美光才開始從 HMC 轉向 HBM 路線圖。這就是美光科技落在最后面的原因。他們仍然停留在HBM2E(SK海力士在2020年中期開始量產)上,他們甚至無法成功制造HBM2E。
在最近的財報電話會議中,美光對其 HBM 路線圖做出了一些大膽的聲明:他們相信,他們將在 2024 年憑借 HBM3E 從落后者變為領先者。HBM3E 預計將在第三季度/第四季度開始為 Nvidia 的下一代 GPU 發貨。
“我們的 HBM3 斜坡實際上是下一代 HBM3,與當今業界生產的 HBM3 相比,它具有更高水平的性能、帶寬和更低的功耗。該產品,即我們行業領先的產品,將從 2024 年第一季度開始銷量大幅增加,并對 24 財年的收入產生重大影響,并在 2025 年大幅增加,即使是在 2024 年的水平基礎上。我們的目標也是在 HBM 中獲得非常強勁的份額,高于行業中 DRAM 的非自然供應份額。”美光首席商務官Sumit Sadana說。
他們希望在 HBM 中擁有比一般 DRAM市場份額更高的市場份額的聲明非常大膽。鑒于他們仍在努力大批量生產頂級 HBM2E,我們很難相信美光聲稱他們將在 2024 年初推出領先的 HBM3,甚至成為第一個 HBM3E。在我們看來,盡管Nvidia GPU 服務器的內存容量比英特爾/AMD CPU 服務器要低得多,但美光科技似乎正在試圖改變人們對人工智能失敗者的看法。
我們所有的渠道檢查都發現 SK 海力士在新一代技術方面保持最強,而三星則非常努力地通過大幅供應增加、大膽的路線圖和削減交易來追趕。
真正的瓶頸 - CoWoS
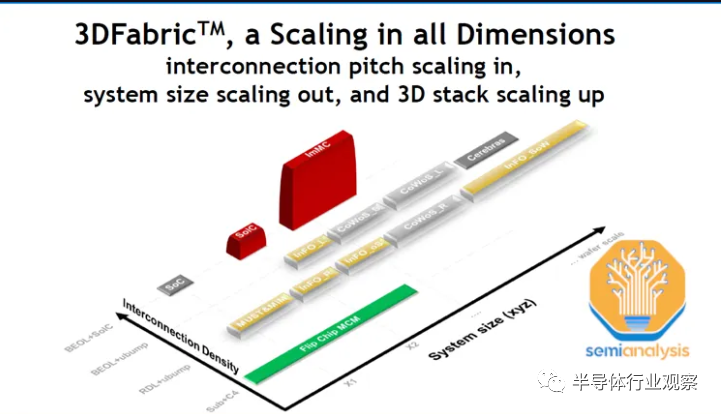
下一個瓶頸是 CoWoS 產能。CoWoS(Chip on Wafer on Substrate)是臺積電的一種“2.5D”封裝技術,其中多個有源硅芯片(active silicon)(通常的配置是邏輯和 HBM 堆棧)集成在無源硅中介層上。中介層充當頂部有源芯片的通信層。然后將中介層和有源硅連接到包含要放置在系統 PCB 上的 I/O 的封裝基板。
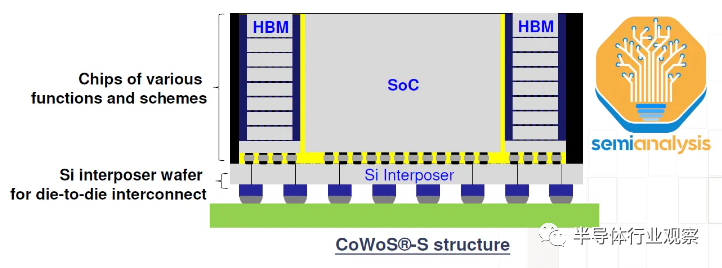
HBM 和 CoWoS 是互補的。HBM 的高焊盤數(high pad count)和短走線長度要求需要 CoWoS 等 2.5D 先進封裝技術來實現 PCB 甚至封裝基板上無法實現的密集、短連接。CoWoS是主流封裝技術,能夠以合理的成本提供最高的互連密度和最大的封裝尺寸。由于目前幾乎所有 HBM 系統都封裝在 CoWoS 上,并且所有高級 AI 加速器都使用 HBM,因此,幾乎所有領先的數據中心 GPU 都由臺積電在 CoWoS 上封裝。百度確實有一些先進的加速器,三星的版本也有。
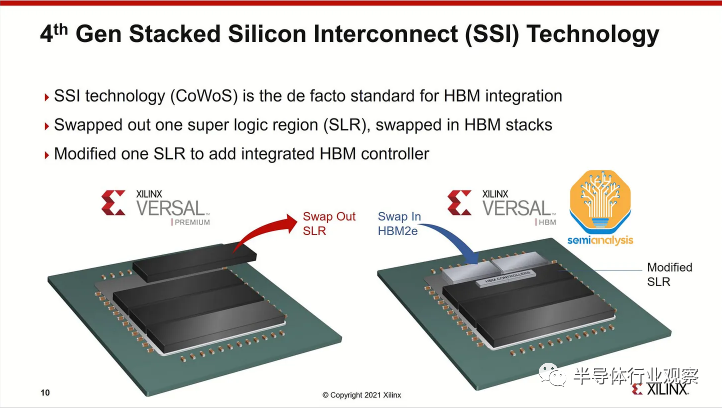
雖然臺積電 (TSMC) 的 SoIC 等 3D 封裝技術可以將芯片直接堆疊在邏輯之上,但由于散熱和成本的原因,這對于 HBM 來說沒有意義。SoIC 在互連密度方面處于不同的數量級,并且更適合通過芯片堆疊擴展片上緩存,如 AMD 的 3D V-Cache 解決方案所示。AMD 的 Xilinx 也是多年前 CoWoS 的第一批用戶,用于將多個 FPGA 小芯片組合在一起。
雖然還有一些其他應用使用 CoWoS,例如網絡(其中一些用于網絡 GPU 集群,如 Broadcom 的 Jericho3-AI )、超級計算和 FPGA,但絕大多數 CoWoS 需求來自人工智能。與半導體供應鏈的其他部分不同,其他主要終端市場的疲軟意味著有足夠的閑置空間來吸收 GPU 需求的巨大增長,CoWoS 和 HBM 已經是大多數面向人工智能的技術,因此所有閑置產能已在第一季度被吸收。隨著 GPU 需求的爆炸式增長,供應鏈中的這些部分無法跟上并成為 GPU 供應的瓶頸。
“就在最近這兩天,我接到一個客戶的電話,要求大幅增加后端容量,特別是在 CoWoS 中。我們仍在評估這一點。”臺積電首席執行官C.C Wei早起那說。
臺積電一直在為更多的封裝需求做好準備,但可能沒想到這一波生成式人工智能需求來得如此之快。6月,臺積電宣布在竹南開設先進后端Fab 6。該晶圓廠占地 14.3 公頃,足以容納每年 100 萬片晶圓的 3D Fabric 產能。這不僅包括 CoWoS,還包括 SoIC 和 InFO 技術。有趣的是,該工廠比臺積電其他封裝工廠的總和還要大。雖然這只是潔凈室空間,遠未配備齊全的工具來實際提供如此大的容量,但很明顯,臺積電正在做好準備,預計對其先進封裝解決方案的需求會增加。
稍微有幫助的是晶圓級扇出封裝產能(主要用于智能手機 SoC)的閑置,其中一些產能可以在某些 CoWoS 工藝步驟中重新利用。特別是,存在一些重疊的工藝,例如沉積、電鍍、背面研磨、成型、放置和RDL形成,這將趨勢設備供應鏈發生了有意義的轉變。
雖然市場上還有來自英特爾、三星和 OSAT (例如 ASE 的 FOEB)提供的其他 2.5D 封裝技術,但CoWoS 是唯一一種大批量使用的技術,因為臺積電是迄今為止最主要的 AI 加速器代工廠。甚至Intel Habana的加速器也是由臺積電制造和封裝的。然而,一些客戶正在尋找臺積電的替代品。
CoWoS 擁有幾種變體,但原始 CoWoS-S 仍然是大批量生產中的唯一配置。這是如上所述的經典配置:邏輯芯片 + HBM 芯片通過帶有 TSV 的硅基中介層連接。然后將中介層放置在有機封裝基板上。
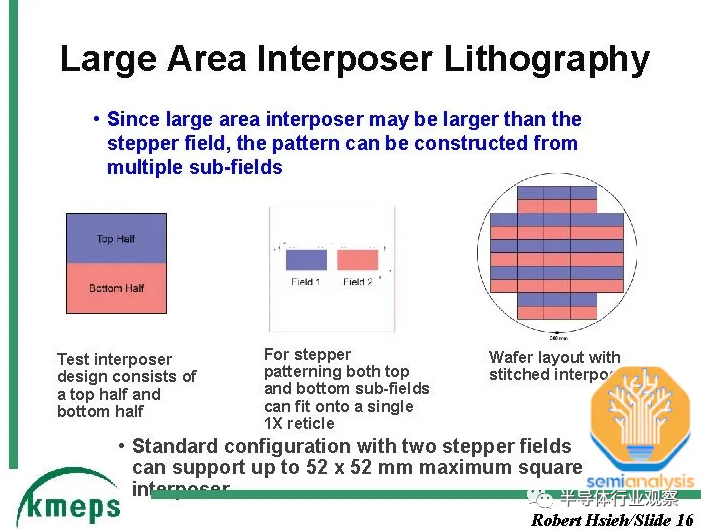
硅中介層的一項支持技術是一種稱為“reticle stitching”的技術。由于光刻工具slit/scan最大尺寸芯片的最大尺寸通常為26mm x 33mm 。隨著 GPU 芯片本身接近這一極限,并且還需要在其周圍安裝 HBM,中介層需要很大,并且將遠遠超出這一標線極限。TSMC 通過reticle stitching解決了這個問題,這使得他們能夠將中介層圖案化為標線限制的數倍(截至目前,AMD MI300 最高可達 3.5 倍)。
CoWoS-R 在具有重新分布層 (RDL) 的有機基板上使用,而不是硅中介層。這是一種成本較低的變體,由于使用有機 RDL 而不是硅基中介層,因此犧牲了 I/O 密度。正如我們所詳述的,, AMD 的 MI300 最初是在 CoWoS-R 上設計的,但我們認為,由于翹曲和熱穩定性問題,AMD 必須改用 CoWoS-S。
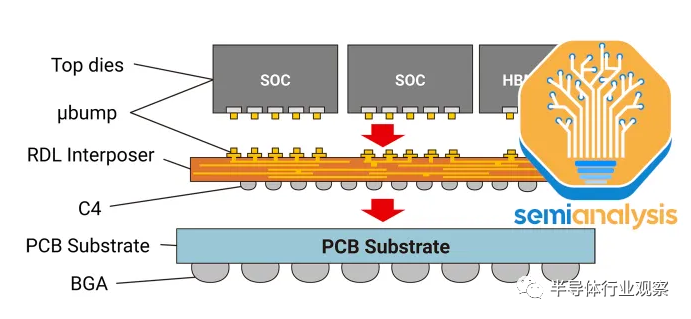
CoWoS-L 預計將在今年晚些時候推出,并采用 RDL 中介層,但包含嵌入中介層內部的用于芯片間互連的有源和/或無源硅橋。這是臺積電相當于英特爾EMIB封裝技術。隨著硅中介層變得越來越難以擴展,這將允許更大的封裝尺寸。MI300 CoWoS-S 可能接近單硅中介層的極限。
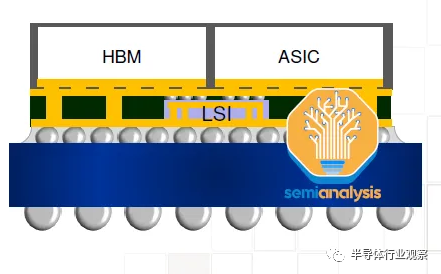
對于更大的設計來說,使用 CoWoS-L 會更加經濟。臺積電正在開發6x reticle尺寸的 CoWoS-L 超級載具中介層。對于 CoWoS-S,他們沒有提到 4x reticle 之外的任何內容。這是因為硅中介層的脆弱性。這種硅中介層只有 100 微米厚,并且在工藝流程中隨著中介層尺寸增大而存在分層或破裂的風險。
審核編輯:劉清
-
DRAM芯片
+關注
關注
1文章
84瀏覽量
18011 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238297 -
TSV技術
+關注
關注
0文章
17瀏覽量
5673 -
OpenAI
+關注
關注
9文章
1082瀏覽量
6485 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7604
原文標題:GPU大缺貨,背后的真正原因!
文章出處:【微信號:IC大家談,微信公眾號:IC大家談】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電力模塊如何在數據中心建設中創新使用?為設計提供思路

史上首次,AMD在數據中心市場的銷售額超過了英特爾!

AMD數據中心業務收入超越Intel
AMD數據中心業務首超英特爾,Nvidia異軍突起
NVIDIA 在 Hot Chips 大會展示提升數據中心性能和能效的創新技術

半導體存儲器在數據中心中的應用


技術在數據中心的應用:如何節省資源和成本


多業務光端機在數據中心的應用:提升網絡效率的關鍵
集中電源控制器在數據中心的應用


光纖KVM在數據中心的應用與優勢






 工商網監
工商網監
評論