 人工神經網絡(感知機算法的意義)
人工神經網絡(感知機算法的意義)
因為支持向量機算是通過所有數據尋找最優分類方式的算法,而感知機算法是尋找某一分類方式的算法,所以,多數情況下,支持向量機求得的分類超平面優于感知機算法求得的分類超平面。 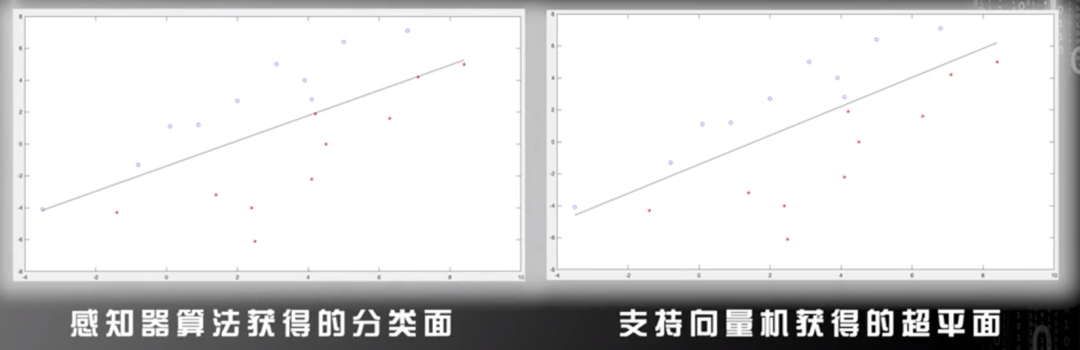
圖片來源:中國慕課大學《機器學習概論》
因為感知機算法的性能較差,所以感知機算法已經不再被使用。但感知機算法對于機器學習算法的發展具有如下意義。
一、提出機器學習算法框架
假設某系統的輸入為X,輸出為Y。機器學習算法的目的尋找預測函數f(X,θ),預測函數的形式通過人為設定的方式確定,機器學習算法的求解過程是通過訓練數據集(Xi,yi),i=1~N求解θ。 
圖片來源:中國慕課大學《機器學習概論》
在感知機算法中,待估及參數θ=(W,b),f(X,θ)=sgn(WTX+b),其中,sgn代表符號函數(x>0,sgn(x)=1;x=0,sgn(x)=0;x<0,sgn(x)=-1)。若X的維度為M,則θ的維度為M+1。此機器學習框架可應用于強化學習、無監督學習等機器學習領域。 ?
當訓練數據的分布較復雜,所選取的f(X,θ)較簡單時,無論θ為何值均不可全面模擬訓練數據的分布。此種訓練數據比預測函數復雜的情況被稱為模型欠擬合(Underfit)。
當訓練數據的復雜度和f(X,θ)的復雜度相匹配時,模型預測能力最佳。
當訓練數據的分布較簡單,所選取的f(X,θ)較復雜時,預測函數可以準確擬合數據,但在沒有訓練數據的區域,預測函數也會出現復雜函數值分布,不能反映訓練數據分布的真實情況。此種預測函數比訓練數據復雜的情況被稱為模型過擬合(Overfit)。模型過擬合時,預測函數可以精確預測訓練數據,但無法精確預測測試數據。
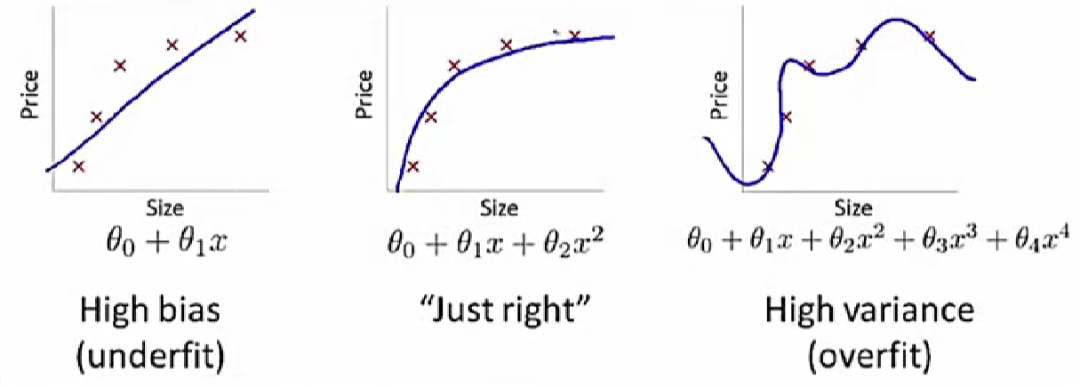
圖片來源:中國慕課大學《機器學習概論》
二、感知機算法是消耗較少內存資源算法的先驅
2014年,Meta(Facebook)公司的DeepFace人臉識別系統需要通過超過400萬張的人臉圖片求解維度超過1800萬的參數θ(個人理解:需要求解一個未知數超過1800萬個的問題)。
上述求解問題若采用支持向量機算法進行求解,需要將超過400萬張的人臉圖片的數據均輸入至計算機,并需要計算機求解全局優化問題,此全局優化問題對計算機的存儲資源和計算資源消耗較大。 
圖片來源:中國慕課大學《機器學習概論》
相比較而言,感知機算法只需存儲W和b,并通過訓練數據調整W和b的值(感知機算法通過加減法的方式調整W和b的值,此方式需要的計算資源較少),再循環調整W和b值過程,即可完成求解。其所需要的存儲資源和計算資源較小。 目前,機器學習領域的訓練數據量較大,類似感知機算法的求解方式,即每次輸送小部分數據訓練并循環的算法逐漸受到歡迎。而類似支持向量機,即針對所有數據進行全局優化的算法逐漸不占優勢。
審核編輯:劉清
-
向量機
+關注
關注
0文章
166瀏覽量
20887 -
人工神經網絡
+關注
關注
1文章
119瀏覽量
14639 -
機器學習
+關注
關注
66文章
8422瀏覽量
132743
原文標題:機器學習相關介紹(25)——人工神經網絡(感知機算法的意義)
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論