 圖像識別技術原理 圖像識別算法有哪些
圖像識別技術原理 圖像識別算法有哪些
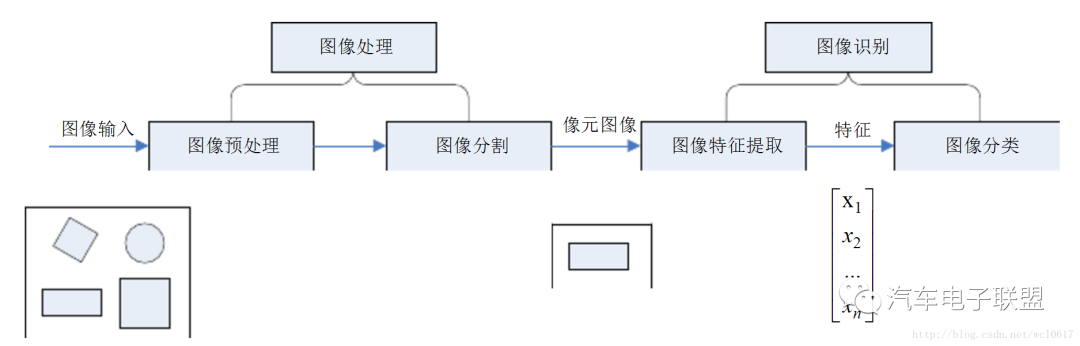
圖像識別過程分為圖像處理和圖像識別兩個部分。
01
圖像處理
圖像處理(imageProcessing)利用計算機對圖像進行分析,以達到所需的結果。
圖像處理可分為模擬圖像處理和數字圖像處理,而圖像處理一般指數字圖像處理。
這種處理大多數是依賴于軟件實現的。
其目的是去除干擾、噪聲,將原始圖像編程適于計算機進行特征提取的形式,主要包括圖像采樣、圖像增強、圖像復原、圖像編碼與壓縮和圖像分割。
1)圖像采集
圖像采集是數字圖像數據提取的主要方式。數字圖像主要借助于數字攝像機、掃描儀、數碼相機等設備經過采樣數字化得到的圖像,也包括一些動態圖像,并可以將其轉為數字圖像,和文字、圖形、聲音一起存儲在計算機內,顯示在計算機的屏幕上。圖像的提取是將一個圖像變換為適合計算機處理的形式的第一步。
2)圖像增強
圖像在成像、采集、傳輸、復制等過程中圖像的質量或多或少會造成一定的退化,數字化后的圖像視覺效果不是十分滿意。為了突出圖像中感興趣的部分,使圖像的主體結構更加明確,必須對圖像進行改善,即圖像增強。通過圖像增強,以減少圖像中的圖像的噪聲,改變原來圖像的亮度、色彩分布、對比度等參數。圖像增強提高了圖像的清晰度、圖像的質量,使圖像中的物體的輪廓更加清晰,細節更加明顯。圖像增強不考慮圖像降質的原因,增強后的圖像更加賞欣悅目,為后期的圖像分析和圖像理解奠定基礎。
3)圖像復原
圖像復原也稱圖像恢復,由于在獲取圖像時環境噪聲的影響、運動造成的圖像模糊、光線的強弱等原因使得圖像模糊,為了提取比較清晰的圖像需要對圖像進行恢復,圖像恢復主要采用濾波方法,從降質的圖像恢復原始圖。圖像復原的另一種特殊技術是圖像重建,該技術是從物體橫剖面的一組投影數據建立圖像。
4)圖像編碼與壓縮
數字圖像的顯著特點是數據量龐大,需要占用相當大的存儲空間。但基于計算機的網絡帶寬和的大容量存儲器無法進行數據圖像的處理、存儲、傳輸。為了能快速方便地在網絡環境下傳輸圖像或視頻,那么必須對圖像進行編碼和壓縮。目前,圖像壓縮編碼已形成國際標準,如比較著名的靜態圖像壓縮標準JPEG,該標準主要針對圖像的分辨率、彩色圖像和灰度圖像,適用于網絡傳輸的數碼相片、彩色照片等方面。由于視頻可以被看作是一幅幅不同的但有緊密相關的靜態圖像的時間序列,因此動態視頻的單幀圖像壓縮可以應用靜態圖像的壓縮標準。圖像編碼壓縮技術可以減少圖像的冗余數據量和存儲器容量、提高圖像傳輸速度、縮短處理時間。
5)圖像分割技術
圖像分割是把圖像分成一些互不重疊而又具有各自特征的子區域,每一區域是像素的一個連續集,這里的特性可以是圖像的顏色、形狀、灰度和紋理等。圖像分割根據目標與背景的先驗知識將圖像表示為物理上有意義的連通區域的集合。即對圖像中的目標、背景進行標記、定位,然后把目標從背景中分離出來。目前,圖像分割的方法主要有基于區域特征的分割方法、基于相關匹配的分割方法和基于邊界特征的分割方法。由于采集圖像時會受到各種條件的影響會是圖像變的模糊、噪聲干擾,使得圖像分割是會遇到困難。在實際的圖像中需根據景物條件的不同選擇適合的圖像分割方法。圖像分割為進一步的圖像識別、分析和理解奠定了基礎。
02
圖像識別
圖像識別將圖像處理得到的圖像進行特征提取和分類。識別方法中基本的也是常用的方法有統計法(或決策理論法)、句法(或結構)方法、神經網絡法、模板匹配法和幾何變換法。
1)統計法(StatisticMethod)
該方法是對研究的圖像進行大量的統計分析,找出其中的規律并提取反映圖像本質特點的特征來進行圖像識別的。它以數學上的決策理論為基礎,建立統計學識別模型,因而是一種分類誤差最小的方法。常用的圖像統計模型有貝葉斯(Bayes)模型和馬爾柯夫(Markow)隨機場(MRF)模型。但是,較為常用的貝葉斯決策規則雖然從理論上解決了最優分類器的設計問題,其應用卻在很大程度受到了更為困難的概率密度估計問題的限制。同時,正是因為統計方法基于嚴格的數學基礎,而忽略了被識別圖像的空間結構關系,當圖像非常復雜、類別數很多時,將導致特征數量的激增,給特征提取造成困難,也使分類難以實現。尤其是當被識別圖像(如指紋、染色體等)的主要特征是結構特征時,用統計法就很難進行識別。
2)句法識別法(Syntactic Recognition)
該方法是對統計識別方法的補充,在用統計法對圖像進行識別時,圖像的特征是用數值特征描述的,而句法方法則是用符號來描述圖像特征的。它模仿了語言學中句法的層次結構,采用分層描述的方法,把復雜圖像分解為單層或多層的相對簡單的子圖像,主要突出被識別對象的空間結構關系信息。模式識別源于統計方法,而句法方法則擴大了模式識別的能力,使其不僅能用于對圖像的分類,而且可以用于對景物的分析與物體結構的識別。但是,當存在較大的干擾和噪聲時,句法識別方法抽取子圖像(基元)困難,容易產生誤判率,難以滿足分類識別精度和可靠度的要求。
3)神經網絡方法(NeuralNetwork)
該方法是指用神經網絡算法對圖像進行識別的方法。神經網絡系統是由大量的,同時也是很簡單的處理單元(稱為神經元),通過廣泛地按照某種方式相互連接而形成的復雜網絡系統,雖然每個神經元的結構和功能十分簡單,但由大量的神經元構成的網絡系統的行為卻是豐富多彩和十分復雜的。它反映了人腦功能的許多基本特征,是人腦神經網絡系統的簡化、抽象和模擬。句法方法側重于模擬人的邏輯思維,而神經網絡側重于模擬和實現人的認知過程中的感知覺過程、形象思維、分布式記憶和自學習自組織過程,與符號處理是一種互補的關系。由于神經網絡具有非線性映射逼近、大規模并行分布式存儲和綜合優化處理、容錯性強、獨特的聯想記憶及自組織、自適應和自學習能力,因而特別適合處理需要同時考慮許多因素和條件的問題以及信息不確定性(模糊或不精確)問題。在實際應用中,由于神經網絡法存在收斂速度慢、訓練量大、訓練時間長,且存在局部最小,識別分類精度不夠,難以適用于經常出現新模式的場合,因而其實用性有待進一步提高。
4)模板匹配法(TemplateMatching)
它是一種最基本的圖像識別方法。所謂模板是為了檢測待識別圖像的某些區域特征而設計的陣列,它既可以是數字量,也可以是符號串等,因此可以把它看為統計法或句法的一種特例。所謂模板匹配法就是把已知物體的模板與圖像中所有未知物體進行比較,如果某一未知物體與該模板匹配,則該物體被檢測出來,并被認為是與模板相同的物體。模板匹配法雖然簡單方便,但其應用有一定的限制。因為要表明所有物體的各種方向及尺寸,就需要較大數量的模板,且其匹配過程由于需要的存儲量和計算量過大而不經濟。同時,該方法的識別率過多地依賴于已知物體的模板,如果已知物體的模板產生變形,會導致錯誤的識別。此外,由于圖像存在噪聲以及被檢測物體形狀和結構方面的不確定性,模板匹配法在較復雜的情況下往往得不到理想的效果,難以絕對精確,一般都要在圖像的每一點上求模板與圖像之間的匹配量度,凡是匹配量度達到某一閾值的地方,表示該圖像中存在所要檢測的物體。經典的圖像匹配方法利用互相關計算匹配量度,或用絕對差的平方和作為不匹配量度,但是這兩種方法經常發生不匹配的情況,因此,利用幾何變換的匹配方法有助于提高穩健性。
5)典型的幾何變換方法主要有霍夫變換HT (Hough Transform)。
霍夫變換是一種快速形狀匹配技術,它對圖像進行某種形式的變換,把圖像中給定形狀曲線上的所有點變換到霍夫空間,而形成峰點,這樣,給定形狀的曲線檢測問題就變換為霍夫空間中峰點的檢測問題,可以用于有缺損形狀的檢測,是一種魯棒性(Robust)很強的方法。為了減少計算量和和內存空間以提高計算效率,又提出了改進的霍夫算法,如快速霍夫變換(FHT)、自適應霍夫變換(AHT)及隨機霍夫變換(RHT)。其中隨機霍夫變換RHT(RandomizedHough Transform)是20世紀90年代提出的一種精巧的變換算法,其突出特點不僅能有效地減少計算量和內存容量,提高計算效率,而且能在有限的變換空間獲得任意高的分辨率。
-
編碼器
+關注
關注
45文章
3638瀏覽量
134428 -
存儲器
+關注
關注
38文章
7484瀏覽量
163765 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
變換器
+關注
關注
17文章
2097瀏覽量
109268 -
圖像處理器
+關注
關注
1文章
104瀏覽量
15496
發布評論請先 登錄
相關推薦
基于DSP的快速紙幣圖像識別技術研究
基于DSP的快速紙幣圖像識別技術研究






 工商網監
工商網監
評論